阿德莱德多模态大模型导航能力挑战赛!NavBench:多模态大语言模型在具身导航中的能力探索
- 作者: Yanyuan Qiao1^{1}1, Haodong Hong2,3^{2,3}2,3, Wenqi Lyu1^{1}1, Dong An4^{4}4, Siqi Zhang5^{5}5, Yutong Xie4^{4}4, Xinyu Wang1^{1}1, Qi Wu1^{1}1
- 单位:1^{1}1阿德莱德大学,2^{2}2昆士兰大学,3^{3}3CSIRO Data61,4^{4}4穆罕默德·本·扎耶德人工智能大学,5^{5}5同济大学
- 论文标题:NavBench: Probing Multimodal Large Language Models for Embodied Navigation
- 论文链接:https://arxiv.org/abs/2506.01031
- 项目主页:https://navbench.github.io/
- 代码链接:https://github.com/NavBench/Evaluation_Code (coming soon)
主要贡献

- 提出 NavBench 基准测试,用于在零样本设置下评估 MLLMs 具身导航能力的基准测试,填补了现有研究的空白。
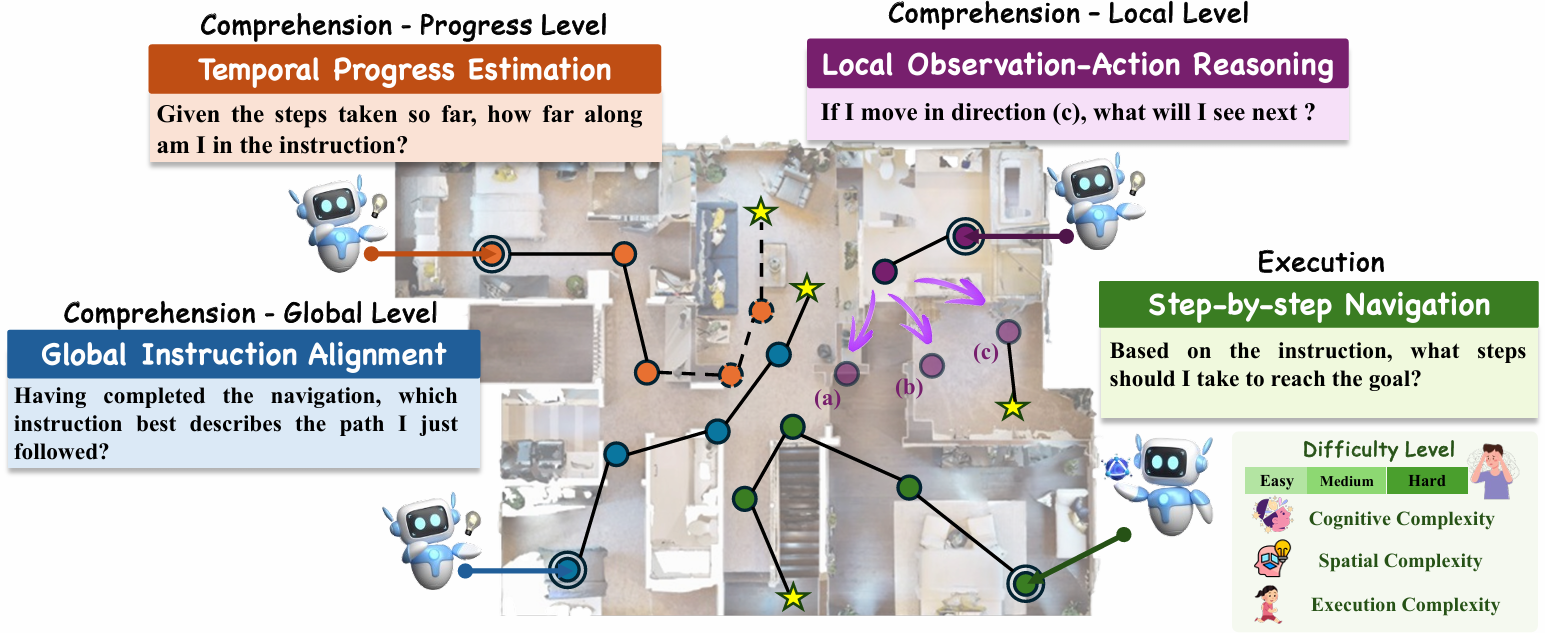
- 分解评估为两个部分,导航理解和导航执行。导航理解包括三个任务,分别评估全局指令对齐、时间进度估计和局部观察-行动推理;导航执行则评估模型在不同难度水平下的逐步决策能力。
- 设计了一个将 MLLMs 的输出转换为机器人动作的实用导航管道流程,包括航点选择模块、基于 MLLM 的导航器和低级控制器。
- 对闭源和开源 MLLMs 进行详细评估和分析,揭示了模型在具身导航中的推理和执行性能趋势,包括理解与执行能力的相关性、时间推理的挑战以及紧凑开源模型的潜力。
研究背景
- 多模态大模型(MLLMs)的发展:MLLMs 在视觉-语言任务中表现出强大的泛化能力,但在具身环境中的理解和行动能力尚未得到充分探索。
- 具身导航的重要性:导航是一个核心的具身任务,涉及解释自然语言指令、分析视觉观察,并做出一系列决策以达到目标。然而,现有的具身导航基准测试大多依赖于任务特定的监督,且主要关注最终的成功率,缺乏对模型中间推理过程的深入分析。
- 研究动机:为了更好地理解 MLLMs 在具身导航中的能力,需要一个能够系统评估模型在指令理解、序列决策、不同难度水平下的泛化能力以及真实世界部署能力的基准测试。
基准设计
任务定义
导航理解

评估模型对导航行为的理解能力,包括三个任务:
- 全局指令对齐:给定一个导航轨迹和多个候选指令,模型需要确定哪个指令与执行的路径最匹配。这一任务测试模型对导航行为的整体意图和结构连贯性的理解。
- 时间进度估计:提供部分轨迹和分割后的子指令列表,模型必须识别出最近完成的子指令。这一任务评估模型监控任务进度和理解指令时间结构的能力。
- 局部观察-行动推理:评估模型对单个行动的空间后果的推理能力。包括两个变体:
- 未来观察预测:模型观察当前视图和一个行动,选择正确的结果视图。
- 未来行动预测:模型观察两个连续视图,识别导致视觉转换的行动。
导航执行
- 评估模型在具身环境中基于当前观察和指令做出准确的逐步决策的能力。在 Matterport3D 模拟器中进行零样本设置的评估,并根据空间、认知和执行复杂度对任务进行分类。
- 模型在每个步骤中接收当前全景观察、自然语言指令和候选可导航视点列表,必须选择下一个移动位置,逐步执行指令直到达到目标。
数据集构建
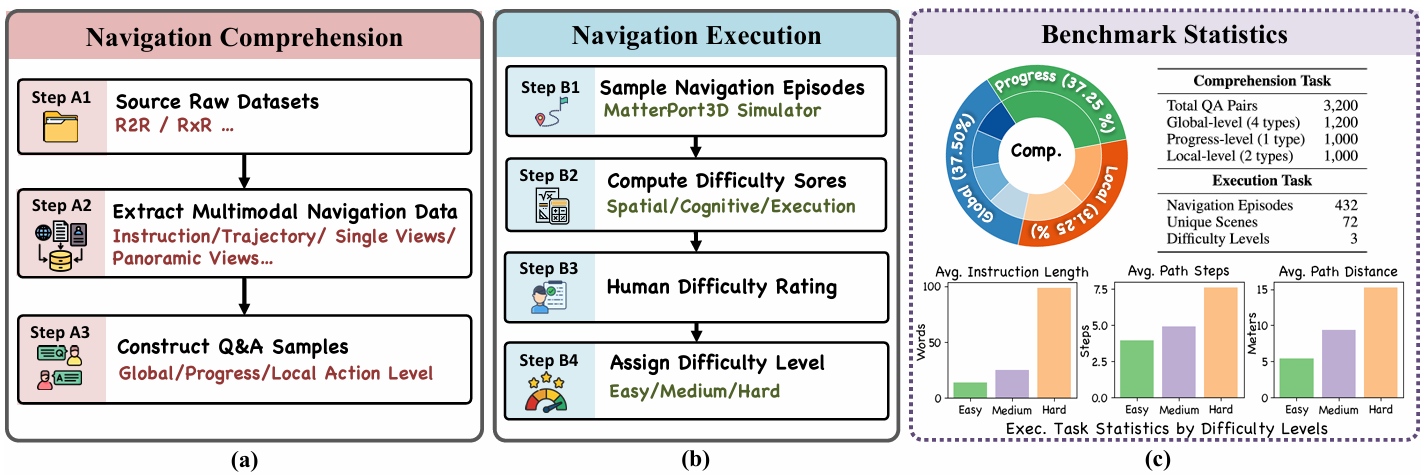
数据来源
- NavBench 通过重新组织和丰富细粒度导航数据构建,这些数据包含多模态观察,以支持 MLLMs 的零样本评估。
- 从多个具身导航基准测试(如 R2R、RxR、GEL-R2R 和 FGR2R)中收集指令-轨迹对,并使用 Matterport3D 模拟器提取与导航轨迹对齐的全景和单视点 RGB 图像。
- 所有视觉和文本数据被组织成统一的结构,支持多种推理任务和一致的问答生成。
统计信息
报告了 NavBench 的统计信息,包括导航理解子任务的分布、场景和导航案例的覆盖范围等,反映了基准测试在推理水平和场景方面的规模和多样性。
问答对收集
为了评估导航理解能力,设计了三个诊断任务,共收集了 3200 个问答对。
- 全局指令对齐:
- 构建了一个包含 1200 个示例的多项选择数据集,每个示例包括一个全景轨迹和五个候选指令(一个真实指令和四个干扰项)。
- 干扰项通过四种扰动策略生成,以测试模型的全局相关性、方向性、对象轨迹基础和时间结构理解。
- 时间进度估计:
- 该任务评估模型的时间推理和监控执行进度的能力。将完整的导航指令分割成一系列子指令,并将每个子指令与代理轨迹的一部分对齐。
- 通过在特定子指令结束时截断轨迹来构建评估示例,模型需要预测最后完成的子指令索引。共收集了 1000 个这样的示例。
- 局部观察-行动推理:
- 设计了两个多项选择推理任务,分别评估模型对局部空间和行动推理的推理能力。
- 在“未来观察预测”任务中,模型接收当前视图和一个行动,必须从一组候选视图中选择正确的结果视图;在“未来行动预测”任务中,模型观察两个连续视图,选择最能解释转换的行动。
- 每个任务收集了 500 个样本,总共 1000 个样本。所有问题都格式化为多项选择查询,以确保评估任务之间的一致性。
导航案例收集
-
从 Matterport3D 模拟器中的 72 个独特场景中采样了 432 个导航案例。为了系统地评估每个案例的难度,定义了一个综合复杂度分数,跨越三个正交维度:空间复杂度、认知复杂度和执行复杂度。
-
每个维度的分数是根据环境的结构属性或指令中的语言线索计算得出的。
-
空间复杂度:量化导航轨迹的几何和拓扑挑战。考虑四个特征:总路径长度 ddd、转弯角度的标准差 θ\thetaθ、垂直范围 zzz(作为楼层变化的代理)和路径覆盖的 2D 空间面积 AAA。还包括一个二进制指标 IpzI_{pz}Ipz,用于捕捉楼层转换等显著的垂直变化。空间复杂度分数定义为:
Φspatial=α1⋅log(1+d)+α2⋅log(1+θ)+α3⋅Ipz1.5+α4⋅log(1+A)\Phi_{\text{spatial}} = \alpha_1 \cdot \log(1 + d) + \alpha_2 \cdot \log(1 + \theta) + \alpha_3 \cdot I_{pz}^{1.5} + \alpha_4 \cdot \log(1 + A)Φspatial=α1⋅log(1+d)+α2⋅log(1+θ)+α3⋅Ipz1.5+α4⋅log(1+A) -
认知复杂度:反映导航指令的语言难度。使用依赖解析提取五个特征:指令长度 LLL、动词数量 VVV、空间术语数量 SSS(例如“左”、“向上”)、地标提及数量 MMM(例如“厨房”)和从句数量 CCC(例如“relcl”、“advcl”)。认知复杂度分数定义为:
Φcognitive=β1⋅log(1+L)+β2⋅log(1+V)+β3⋅log(1+S)+β4⋅log(1+M)+β5⋅C\Phi_{\text{cognitive}} = \beta_1 \cdot \log(1 + L) + \beta_2 \cdot \log(1 + V) + \beta_3 \cdot \log(1 + S) + \beta_4 \cdot \log(1 + M) + \beta_5 \cdot CΦcognitive=β1⋅log(1+L)+β2⋅log(1+V)+β3⋅log(1+S)+β4⋅log(1+M)+β5⋅C -
执行复杂度:衡量完成导航所需的行为努力。考虑四个特征:步数 NNN、转弯次数 TTT、楼层变化指标 FFF 和决策点数量 DDD。执行复杂度分数定义为:
Φexecution=γ1⋅log(1+N)+γ2⋅log(1+T)+γ3⋅F+γ4⋅D\Phi_{\text{execution}} = \gamma_1 \cdot \log(1 + N) + \gamma_2 \cdot \log(1 + T) + \gamma_3 \cdot F + \gamma_4 \cdot DΦexecution=γ1⋅log(1+N)+γ2⋅log(1+T)+γ3⋅F+γ4⋅D -
归一化:每个原始复杂度分数 Φ\PhiΦ 使用非线性映射归一化到范围 [1,9][1, 9][1,9]:
Φ^=round(1+8⋅log(1+Φ)−log(1+Φmin)log(1+Φmax)−log(1+Φmin))\hat{\Phi} = \text{round}\left(1 + 8 \cdot \frac{\log(1 + \Phi) - \log(1 + \Phi_{\min})}{\log(1 + \Phi_{\max}) - \log(1 + \Phi_{\min})}\right)Φ^=round(1+8⋅log(1+Φmax)−log(1+Φmin)log(1+Φ)−log(1+Φmin))
权重 α\alphaα、β\betaβ 和 γ\gammaγ 是通过实验设置的,以平衡每个因素的贡献。 -
人类评估:为了补充自动评分,进行了人类评估以验证难度注释。一组注释者独立地根据三个定义的维度对每个案例进行评分,使用 1-9 级量表,并提供与评分方法一致的详细指南。
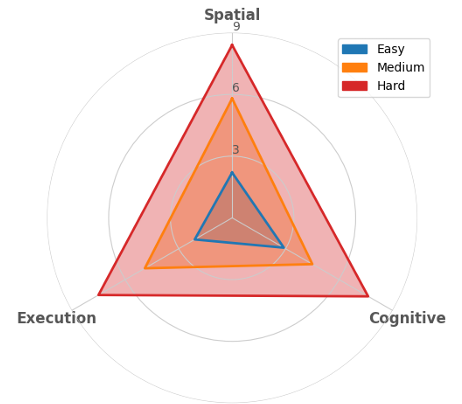
- 难度分类:基于最终分数,每个案例被分类为三个难度水平之一,如图 4 所示:
- 简单(Easy,分数 1-3):路径短,指令简单,步骤少,空间推理少,地标清晰。
- 中等(Medium,分数 4-6):指令长度适中,包含多个地标或空间短语,路径长度中等。
- 困难(Hard,分数 7-9):长轨迹,由复杂的多步指令引导,通常涉及楼层转换和多个空间
真实世界部署

为了验证多模态大语言模型(MLLMs)在真实世界中的导航能力,研究者们设计了一个模块化的导航管道流程,将模拟环境中的评估结果与真实机器人部署相结合。
- 航点预测器:负责从机器人的传感器(如RGB-D相机)获取输入数据,并生成候选航点。这些航点是机器人可以移动到的潜在位置。
- MLLM决策模块:基于当前的导航指令和视觉观察,从Waypoint Predictor提供的候选航点中选择最优的航点。这个模块是整个导航系统的核心,它利用MLLM的强大推理能力来做出决策。
- 低级控制器:将MLLM决策模块选择的航点转换为具体的运动命令,驱动机器人执行实际的移动操作。
NavBench 评估
设置
- 模型选择:评估了包括闭源模型(如GPT-4o和GPT-4o-mini)和开源模型(如InternVL2.5-2B/8B、Qwen2.5-VL-3B/7B、LLaVA-OneVision-7B等)在内的多种MLLMs。
- 实现细节:闭源模型通过API访问,开源模型使用vLLM和lmdeploy在单个NVIDIA A6000 GPU上部署。模拟器评估在Matterport3D模拟器中进行,该模拟器基于真实室内环境的高分辨率RGB-D扫描构建。对于真实世界部署,使用双臂移动机器人,配备了Intel RealSense D435相机和Water Drop双轮底盘。在受控的室内实验室环境中进行,以评估系统的鲁棒性和有效性。
- 评估指标:对于多选问答任务,使用准确率(Accuracy)作为主要指标;对于执行任务,使用成功率(SR)和路径长度加权成功率(SPL)作为评估指标。
性能分析
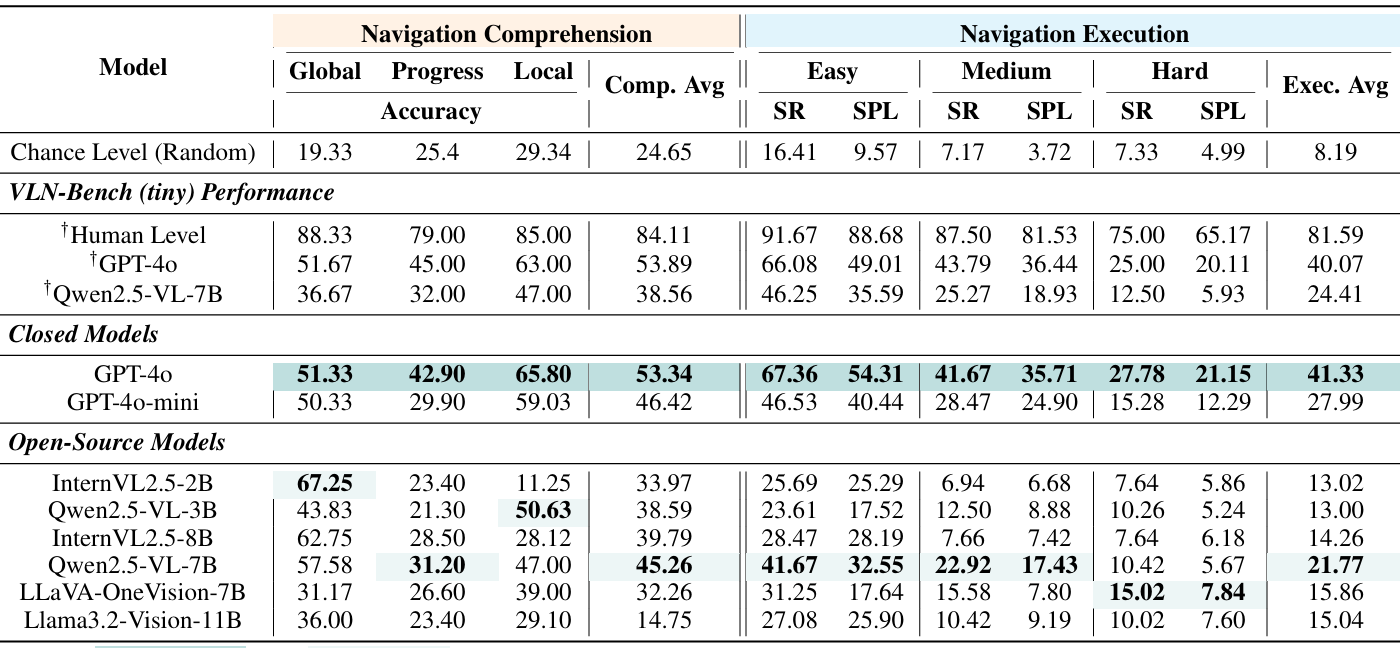
- 导航理解与执行的关系:研究发现,模型在导航理解任务和导航执行任务上的表现密切相关。例如,GPT-4o在导航理解任务中平均准确率为53.34%,在导航执行任务中平均成功率为41.33%,均高于其他模型。
- 不同难度水平的表现:大多数开源模型只能可靠地完成简单难度的任务,而GPT-4o在所有难度水平上都表现出较强的结果,表明其在具身导航中具有更好的泛化能力。
- 时间推理的挑战:除了GPT-4o外,其他模型在时间进度估计任务上的表现都不理想,这表明当前MLLMs在时间推理方面存在局限性。

讨论
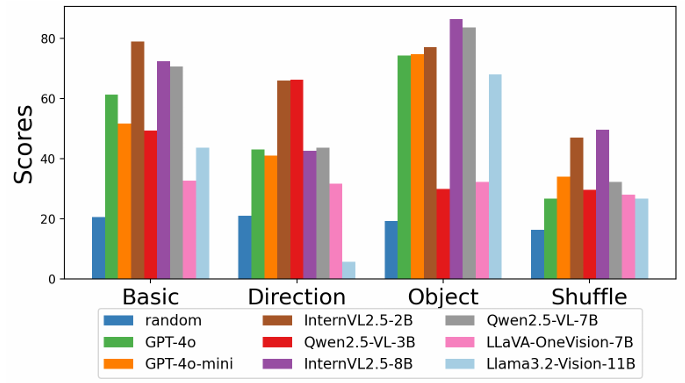
- 指令对齐任务中的干扰项分析:研究者们进一步分析了模型在全局指令对齐任务中对不同类型干扰项的表现。结果显示,模型在处理方向和对象扰动时表现不一致,而在子指令顺序被打乱的情况下,模型的表现显著下降,这进一步证实了它们在时间结构理解上的不足。
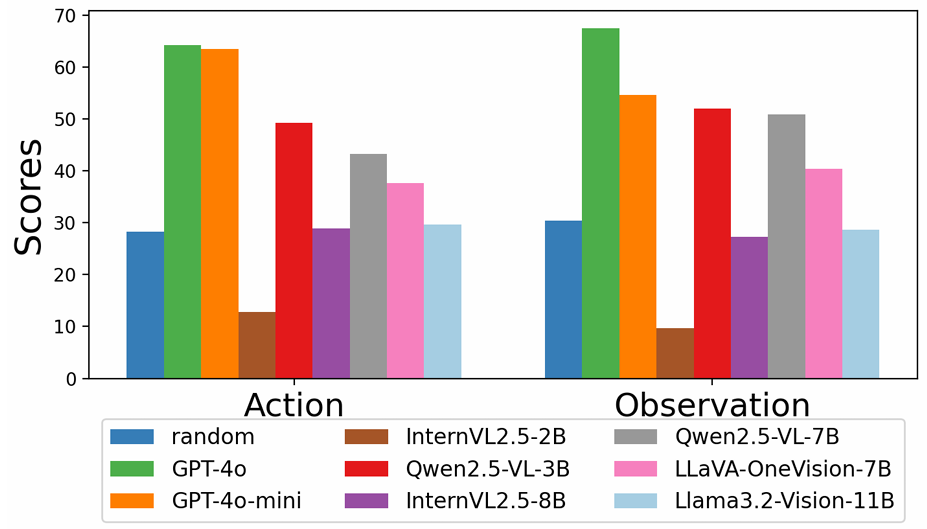
- 局部观察-行动推理任务:在这一任务中,GPT-4o的表现优于其他模型,这表明其在推理空间转换和行动后果方面具有更强的能力。
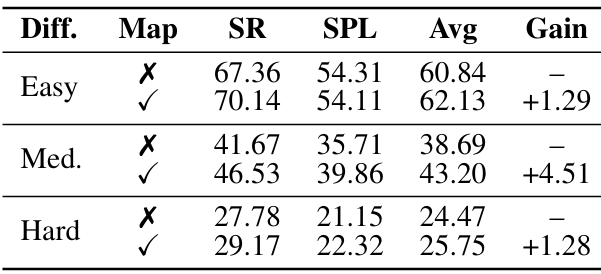
- 地图信息的影响:实验发现,提供地图信息可以提高模型在中等难度场景下的决策准确性,平均成功率提高了4.86个百分点。这表明结构化的空间上下文可以帮助模型进行更好的高级推理和规划。
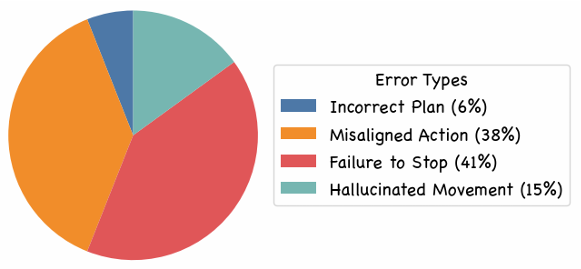
- 错误分析:通过对失败案例的手动分析,识别出四种常见的错误类型:计划错误、行动不一致、未能停止和幻觉运动。这些错误类型与模型在理解任务中的弱点相对应,例如未能停止错误反映了时间进度估计的不足。
- 真实世界验证:在室内环境中使用GPT-4o和Qwen2.5-VL-7B进行了真实世界部署的试点研究,分别取得了60%和40%的成功率。这表明NavBench的模拟评估能够可靠地反映真实世界的具身导航性能。
结论与未来工作
- 结论:
- NavBench 作为一个诊断性基准测试,揭示了 MLLMs 在具身导航中的时间理解和行动基础方面的局限性,这些局限性无法通过标准的成功率指标来捕捉。
- 此外,研究还表明,轻量级开源模型在简单导航场景中可以表现出与闭源模型相媲美的性能,这为实际应用中的资源高效模型提供了潜力。
- 未来工作:
- 尽管 NavBench 为评估 MLLMs 的具身导航能力提供了一个全面的框架,但未来的研究可以进一步扩展这个基准测试,例如探索更多类型的导航任务、增加更多真实世界环境的数据以及开发更先进的模型以克服当前的局限性。
- 此外,还可以研究如何将 MLLMs 与其他技术(如强化学习)结合起来,以提高具身导航的性能和鲁棒性。
