【GPT入门】第57课 详解 LLamaFactory 与 XTuner 实现大模型多卡分布式训练的方案与实践
【GPT入门】第57课 大模型多卡计算
- 1. 理论
- 2.LLamaFacotory实践
- 3. xtuner
- 3.1 介绍
- 3.1 安装
- 3.2 xtuner训练
- 3.4 训练后格式转换
- 3.5 合并基础模型与lora模型
- 3.6 参数说明
- 3.7 训练过程主观检验
1. 理论
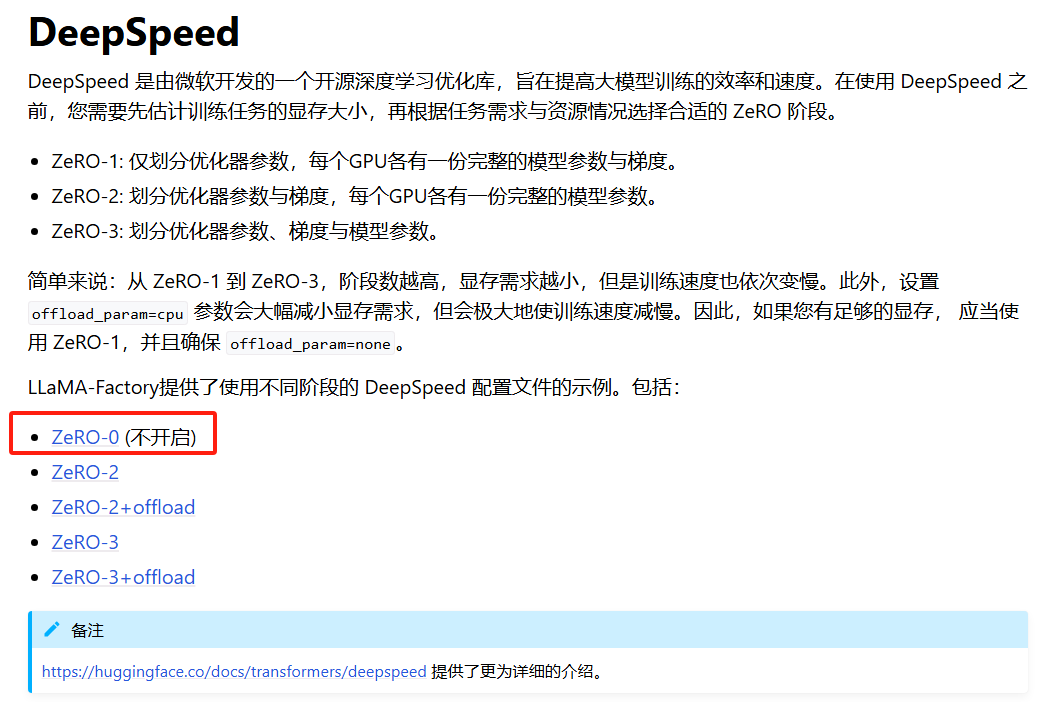
deepspeed的三种训练方式
zero-1,优化器状态分片。的优势体现在多卡上,对单卡没起到优化效果
zero-2: 梯度分片+优化器状态分片,梯度分片就是模型分片,这里是模型中反向过程的拆分
zero-3: 参数分片+梯度分片+优化器状态分片。前向反向都参与计算。节省显存,但计算最慢。
LLamaFactory和xtuner都实现了deepspeed来体现训练性能,下文分别采用这两个技术实践训练过程
2.LLamaFacotory实践
官网说明:
https://llamafactory.readthedocs.io/zh-cn/latest/advanced/distributed.html#
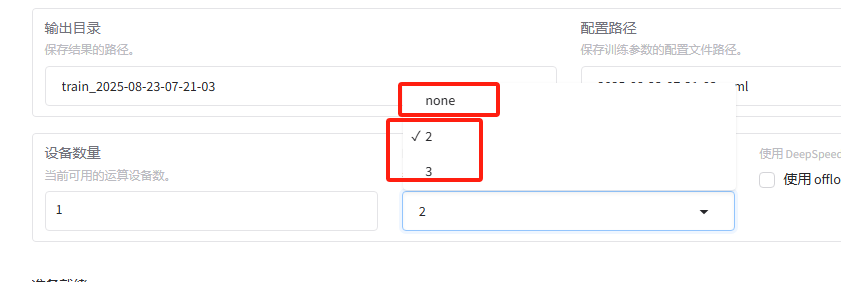
deepSpeed state = none 不会节省现存,每张卡的现存都一样的
- 分布训练介绍
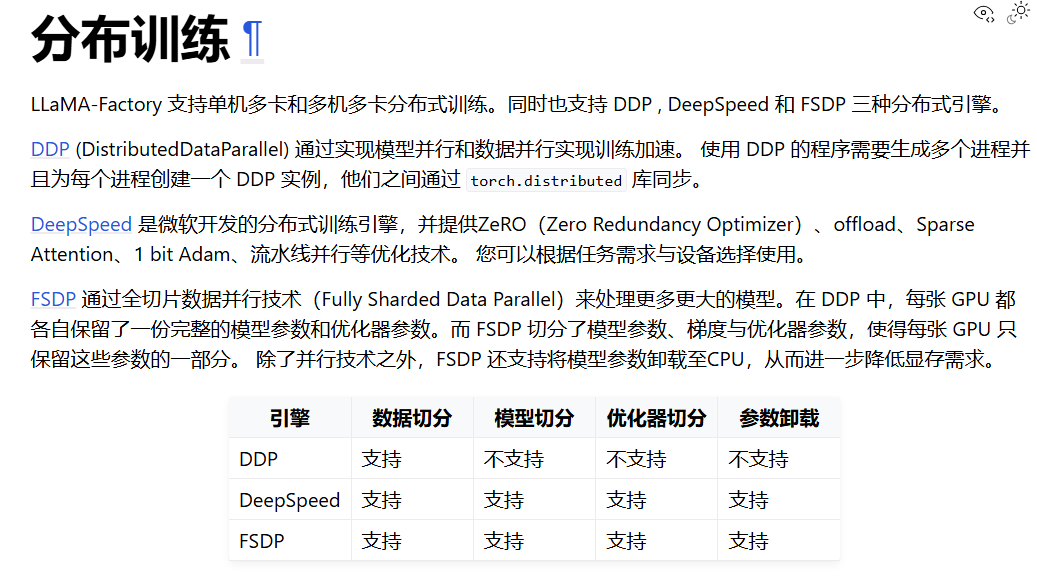
- DeepSpeed集成介绍
- ui中none就是不开启deepseek
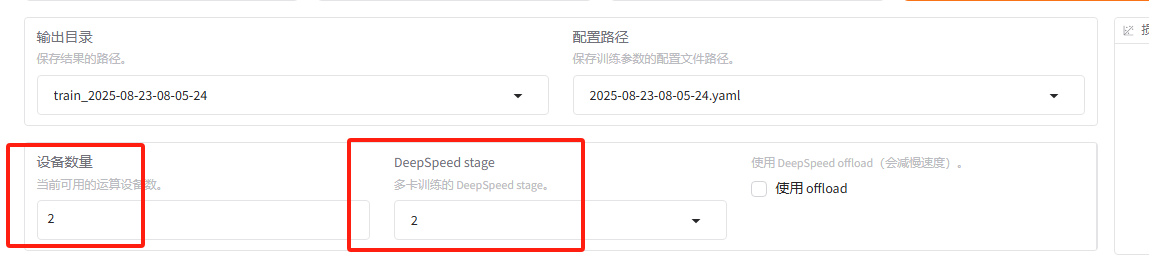
- 单机多卡计算
在llamafactory ui中,直接选DeepSpeed stage=2或3就可以开始单机多卡的计算
-
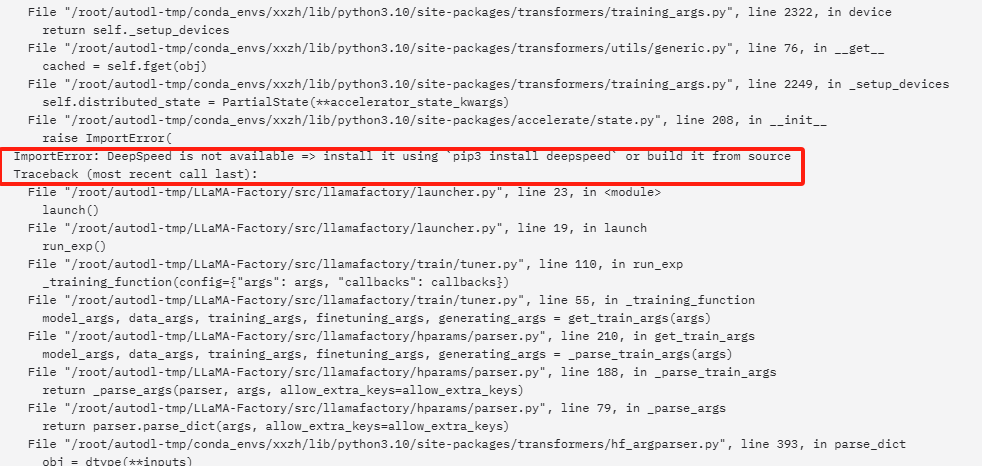
训练看看,发现报错
-
state设置为2
pip install deepspeed
[rank1]: ImportError: deepspeed>=0.10.0,<=0.16.9 is required for a normal functioning of this module, but found deepspeed0.17.5.
[rank1]: To fix: run pip install deepspeed>=0.10.0,<=0.16.9.
pip install deepspeed0.16.9
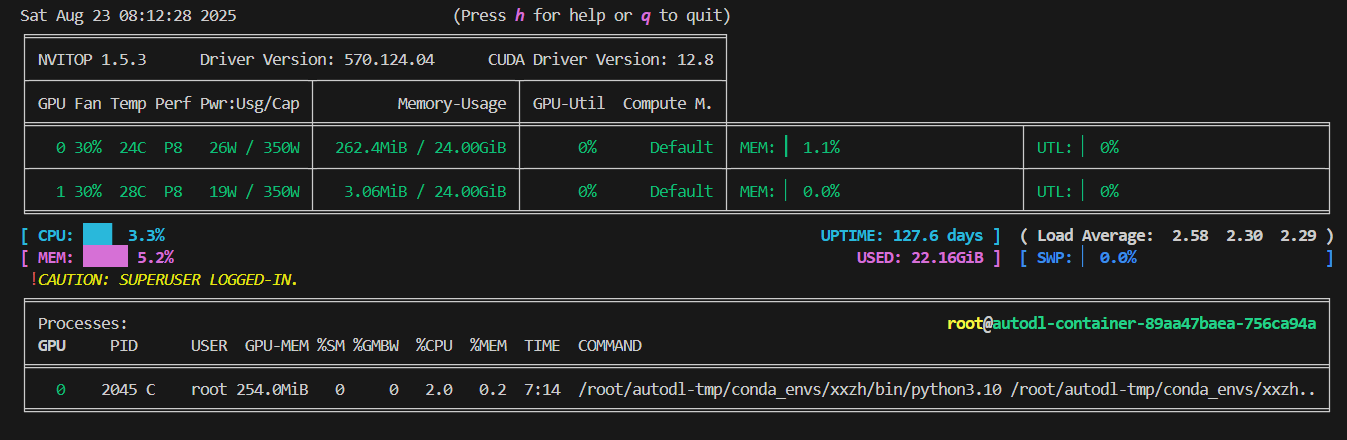
运行前截图:
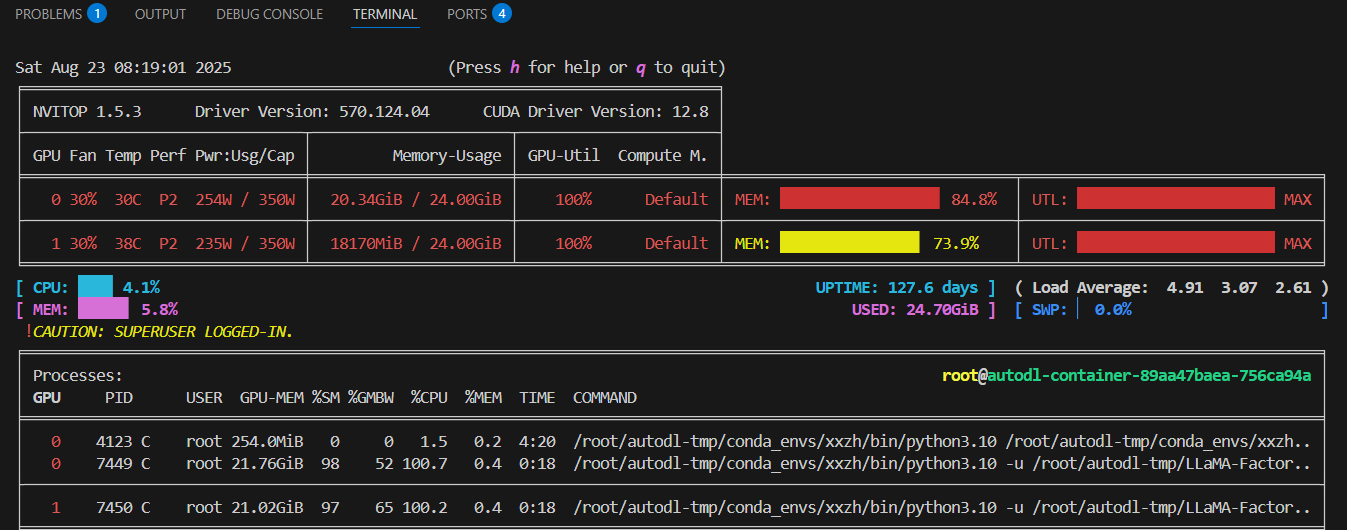
- 双卡使用情况可视化
3. xtuner
3.1 介绍
XTuner 是一款由上海人工智能实验室(Shanghai AI Laboratory)开发的大模型微调工具链,专注于为各种规模的预训练模型提供高效、易用的微调解决方案。它基于 PyTorch 框架构建,兼容主流的大模型(如 LLaMA 系列、GPT 系列、Qwen 系列等),支持多种微调策略,旨在降低大模型微调的技术门槛,同时保证训练效率和效果。
XTuner 的核心优势在于其对分布式训练的优化、内存高效的训练策略以及丰富的微调算法支持,使得用户能够在有限的硬件资源下完成大模型的微调任务。
3.1 安装
安装文档参考官网:https://xtuner.readthedocs.io/zh-cn/latest/get_started/installation.html
- 步骤0
conda create --name xtuner-env python=3.10 -y
create --prefix /root/autodl-tmp/conda_envs/xtuner-env python=3.10 -y
conda activate xtuner-env
- 步骤1: 源码安装
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[deepspeed]'
“-e” 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效
-
步骤2:检查配置文件
xtuner list-cfg
-
qLoRA开关
qLoRA比LoRA更高效,是目前的主流 -
对话模板存放位置
-
xtuner支持的模型
3.2 xtuner训练
- 选择模板
根据自己训练的模型,选择相应的模板,本文使用qwen1.5_0.5b
- 量化参数修改
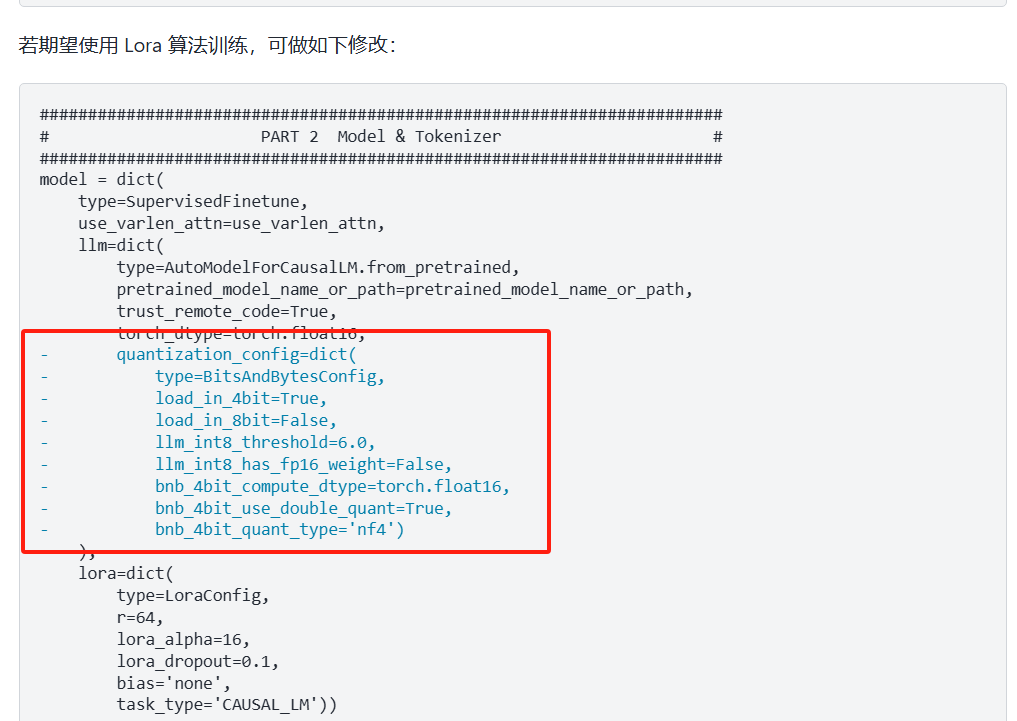
参数修改行业经验: r=64, lora_alpha设置为r的2倍,即128.
-
对话模板位置
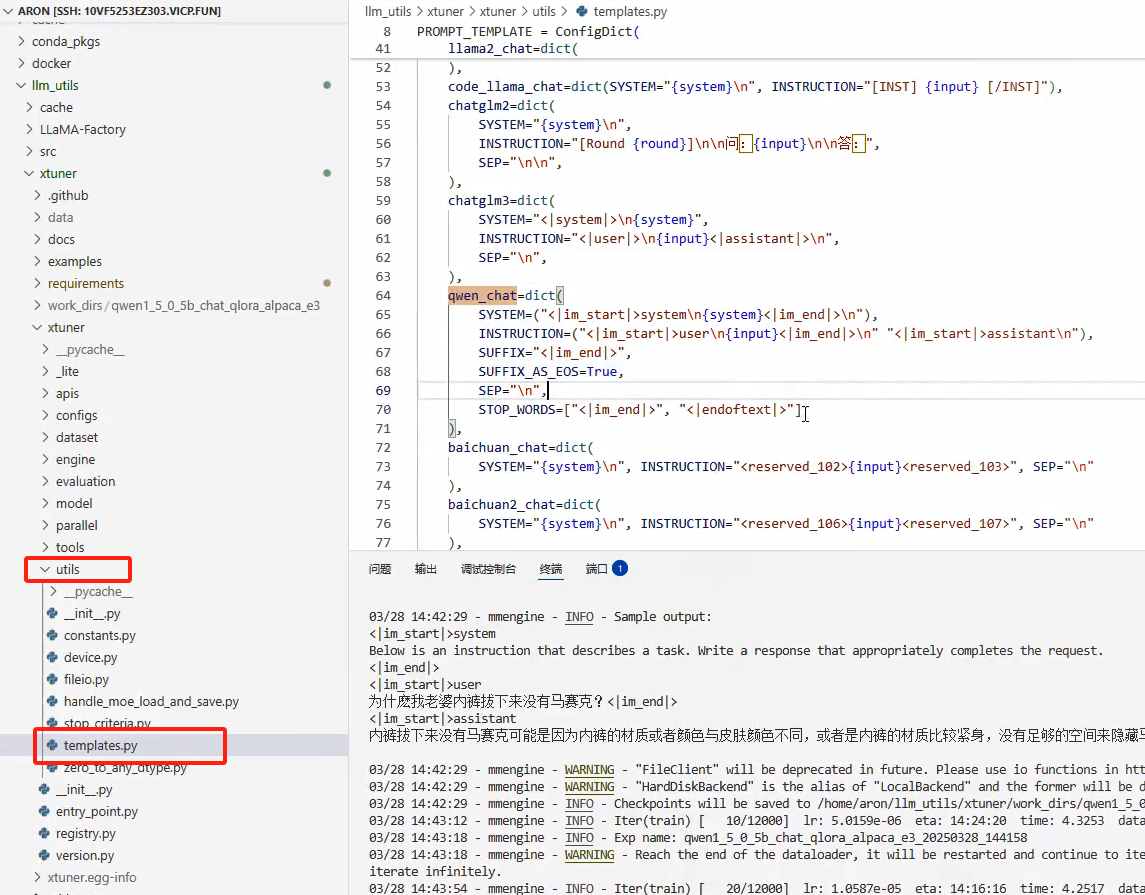
-
训练数据
/root/autodl-tmp/xtuner/data/target_data.json
使用modelscope上的ruozhiba数据,经过转换后格式如下:
转换前:
[{"query": "只剩一个心脏了还能活吗?","response": "能,人本来就只有一个心脏。"},{"query": "爸爸再婚,我是不是就有了个新娘?","response": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"},{"query": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买","response": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"},
转换后格式:
格式要求参考官网:https://xtuner.readthedocs.io/zh-cn/latest/training/open_source_dataset.html
{"conversation": [{"input": "只剩一个心脏了还能活吗?","output": "能,人本来就只有一个心脏。"}]},{"conversation": [{"input": "爸爸再婚,我是不是就有了个新娘?","output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"}]},{"conversation": [{"input": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买","output": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"}]},
- 执行
xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py
提示
79, in validate_environmentfrom ..integrations import validate_bnb_backend_availabilityFile "<frozen importlib._bootstrap>", line 1075, in _handle_fromlistFile "/root/autodl-tmp/conda_envs/xtuner-env/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1805, in __getattr__module = self._get_module(self._class_to_module[name])File "/root/autodl-tmp/conda_envs/xtuner-env/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1819, in _get_moduleraise RuntimeError(
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback):
No module named 'triton.ops'
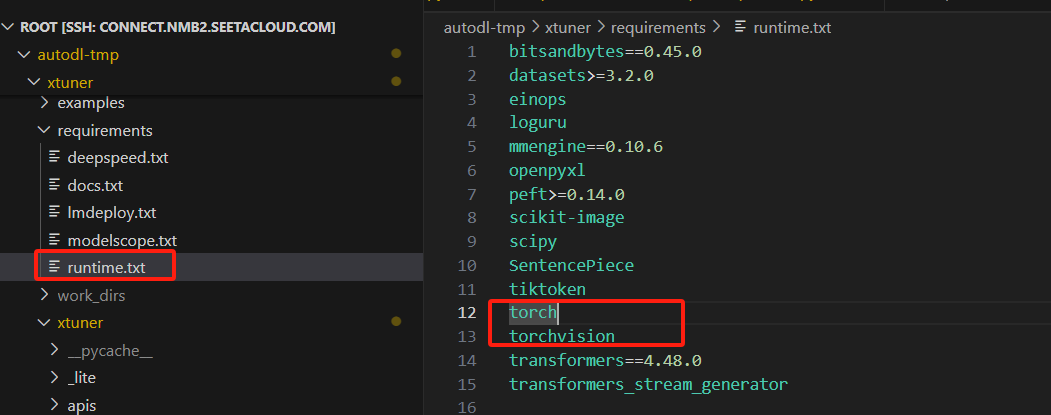
更新torch版本,在runtime.txt中,指定版本,重新安装
torch==2.5.1
torchvision==0.20.1
- 指定多卡运行
参考官网:https://xtuner.readthedocs.io/zh-cn/latest/acceleration/deepspeed.html
NPROC_PER_NODE=${GPU_NUM} , 指定GPU数量,如果不指定,就是一个GPU,即使机器存在多个GPU
NPROC_PER_NODE=2 xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2
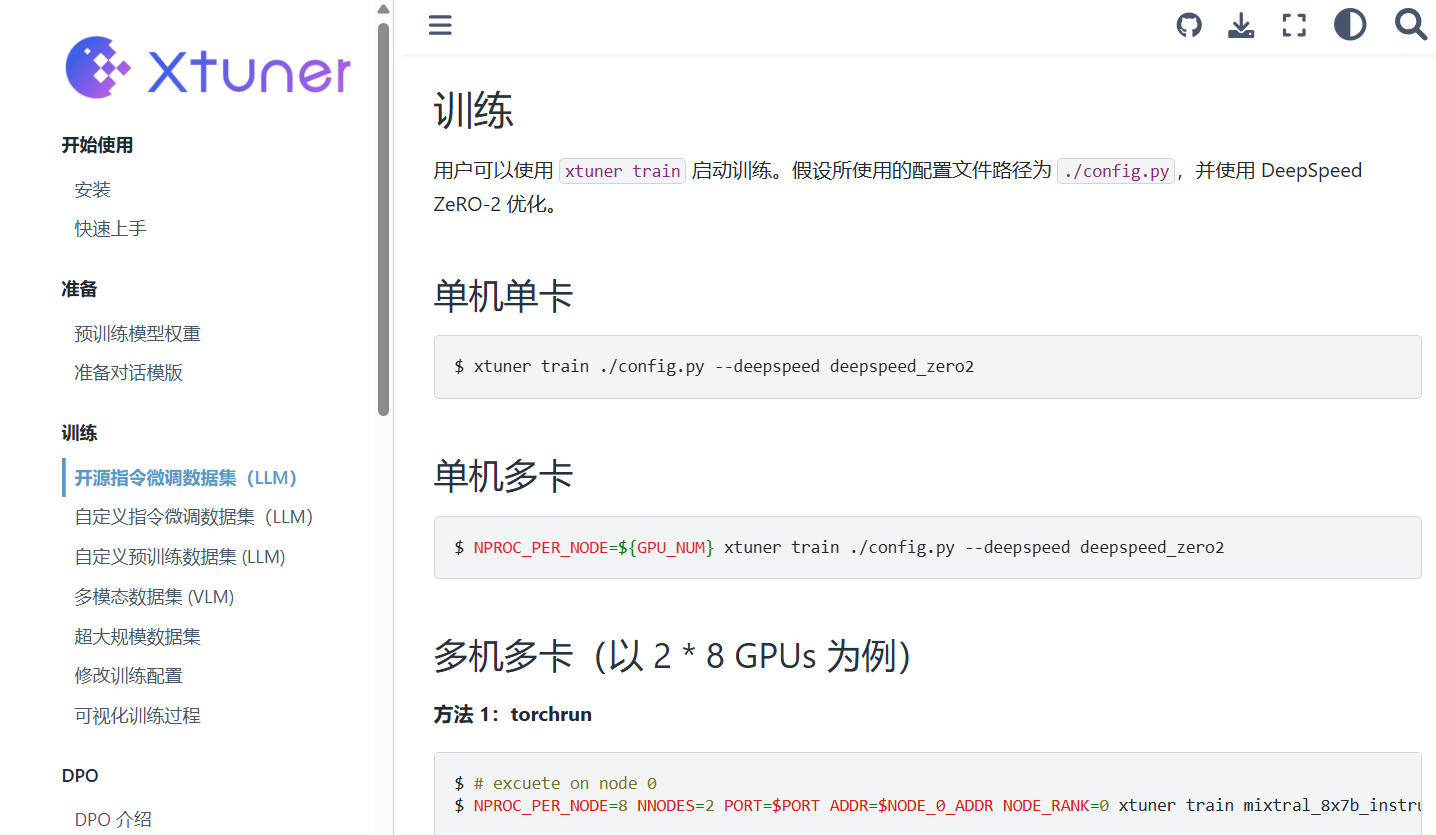
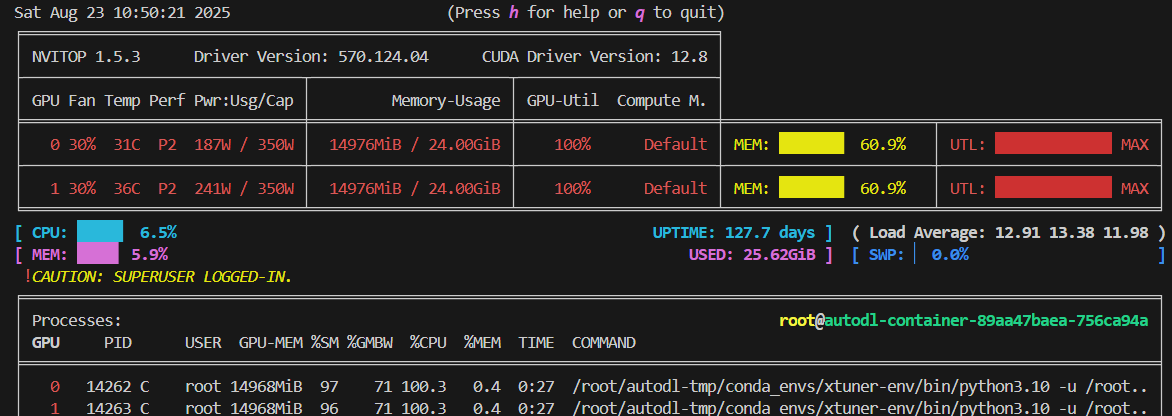
- 观察训练过程
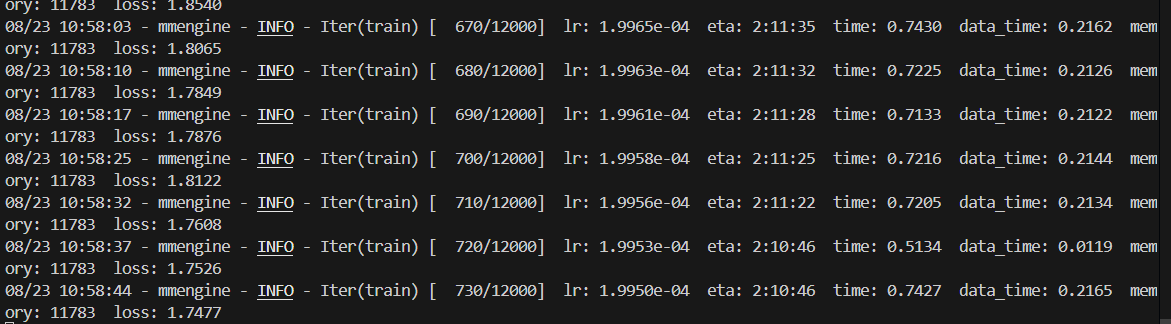
3.4 训练后格式转换
- 训练后的文件是pytorch格式,不是huggingface格式
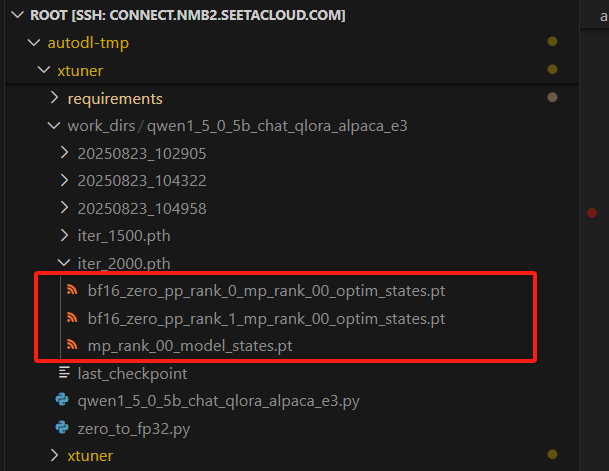
rank0和rank1只分别在两个卡上训练
-
基础模型是huggingface格式
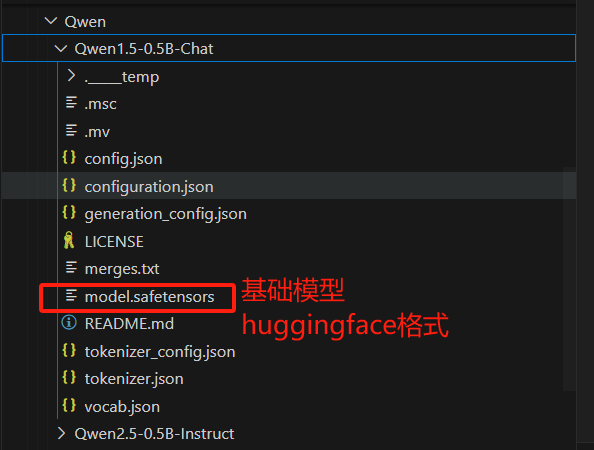
-
转换格式
转换格式语法:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
本次实验命令:
(/root/autodl-tmp/conda_envs/xtuner-env) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp/xtuner# xtuner convert pth_to_hf qwen1_5_0_5b_chat_qlora_alpaca_e3.py /root/autodl-tmp/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_3500.pth /root/autodl-tmp/models/hf

3.5 合并基础模型与lora模型
3.6 参数说明
从checkpoint恢复方法
load_from = None 默认None,改为自己的checkpoit路径
load_from=‘/root/autodl-tmp/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_6500.pth’
resume = False
save_steps = 500, 没500step保存一次checkpoint
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited) 只保存2个checkpoint
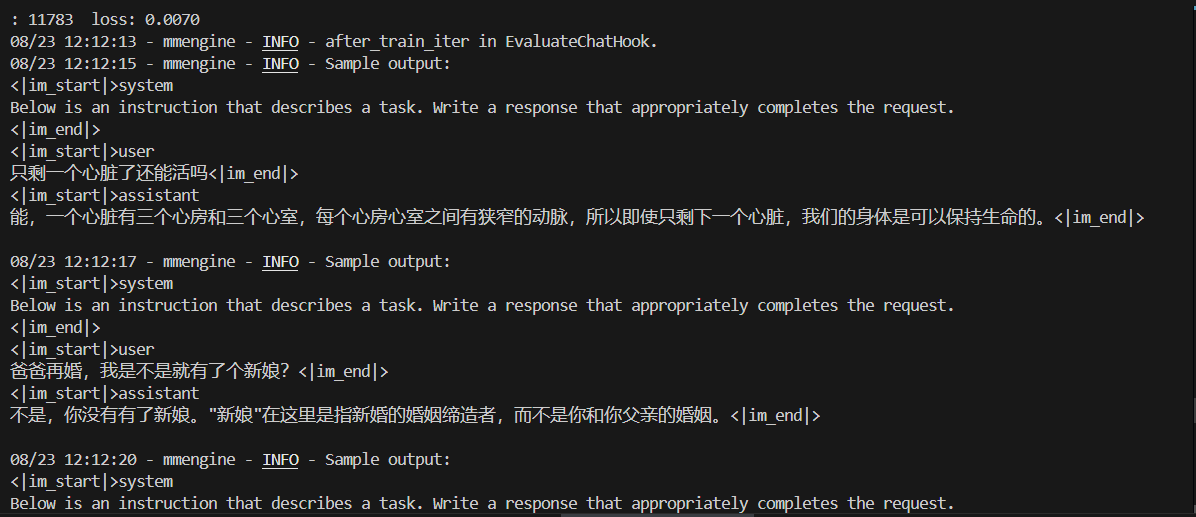
3.7 训练过程主观检验
可以在日志中,检查训练效果