Agent Lightning:让任何AI智能体通过强化学习实现高效训练
Agent Lightning:让任何AI智能体通过强化学习实现高效训练
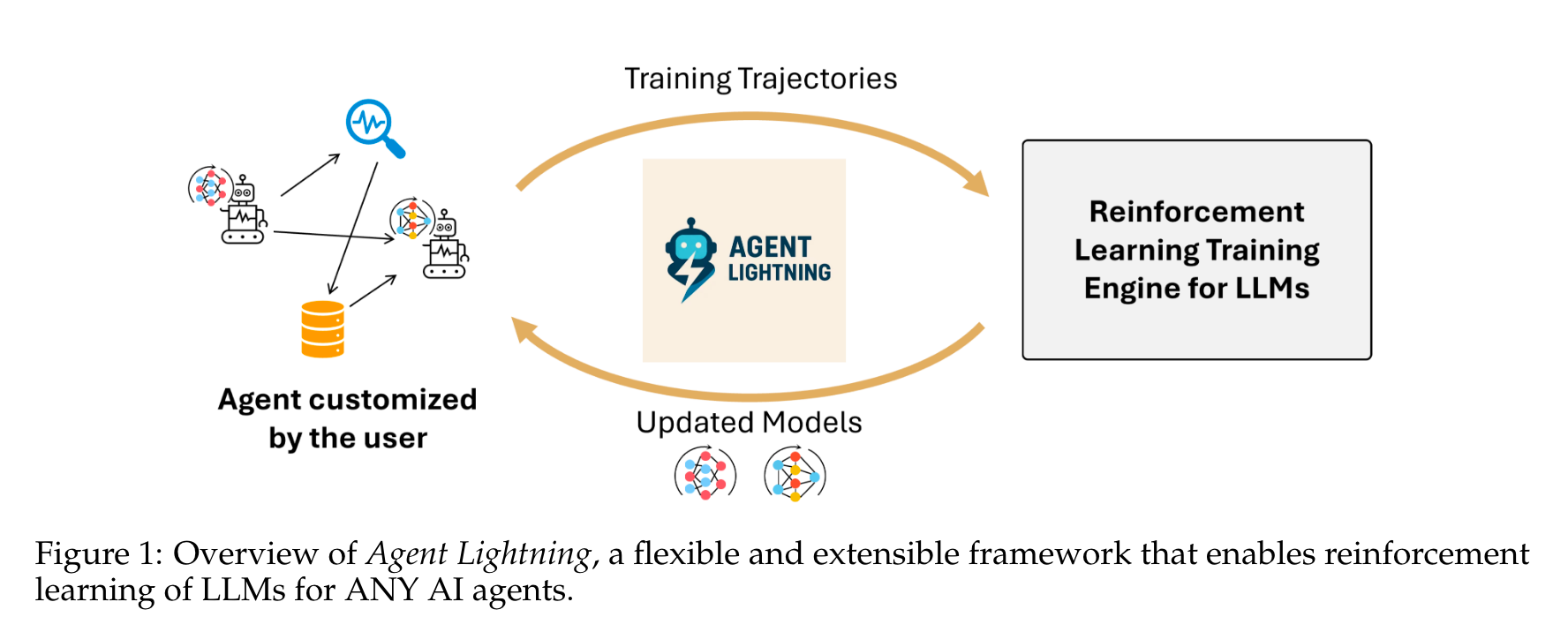
本文将深入解析微软研究院提出的Agent Lightning框架,该框架实现了智能体执行与强化学习训练的完全解耦,能无缝集成各类现有智能体,无需大量代码修改即可进行训练。通过创新的层级RL算法和系统架构,为真实世界智能体的训练与部署提供了新可能。
论文标题:Agent Lightning: Train ANY AI Agents with Reinforcement Learning
来源:arXiv:2508.03680 [cs.AI],链接:https://arxiv.org/abs/2508.03680
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大型语言模型(LLMs)的进步使AI智能体在搜索、代码生成和工具使用等复杂任务中表现出显著灵活性。尽管提示工程能提升性能,但LLMs在多轮编码流程、私有域数据集或不熟悉工具等未明确训练的场景中仍易出错,难以可靠解决端到端软件开发等复杂现实任务。同时,智能体执行过程中产生的丰富交互数据,在规模和多样性上超越传统人工标注数据集,为LLM训练提供关键资源,而强化学习(RL)为智能体场景下的LLMs优化提供了强大范式。
研究问题
- 现有LLMs的RL方法和框架主要针对静态单调用任务,难以应对智能体执行中涉及多轮LLM调用、与外部工具/API/环境交互的复杂逻辑。
- 智能体因应用需求不同而具有多样性,导致RL难以大规模应用于智能体的LLM调优。
- 现有RL框架与智能体开发框架耦合紧密,迁移现有智能体到RL框架需大量手动适配,过程繁琐且易出错,难以在异构智能体生态中扩展。
主要贡献
- 首次实现智能体与RL训练的完全解耦,能无缝应用于任何AI智能体,几乎无需代码修改,通过与智能体执行逻辑对齐,直接提升其在实际应用中的性能。
- 提出统一数据接口和层级RL算法LightningRL,基于MDP公式化智能体执行过程,将任何智能体生成的轨迹分解为训练过渡,处理多智能体场景和动态工作流等复杂交互逻辑。
- 引入训练-智能体分离(TA Disaggregation)架构,包含Lightning Server和Lightning Client,提供标准化训练服务,支持可观测性框架集成,增强可扩展性和灵活性。
思维导图
方法论精要
统一数据接口
数据驱动的智能体优化依赖于智能体执行过程中生成的数据,Agent Lightning定义了适用于任何AI智能体数据收集的统一数据接口。
-
状态与调用
- 状态被定义为智能体执行的快照,包含程序计数器、变量值等,可抽象为随执行时间演变的变量集。对于任务$ x的第的第的第k次执行,时间步次执行,时间步次执行,时间步t包含包含包含V$个变量的状态表示为:
statet(x,k)={variableix,k,t}i=1Vstate_{t}(x, k)=\left\{ variable_{i}^{x, k, t}\right\}_{i=1}^{V}statet(x,k)={variableix,k,t}i=1V - 语义变量(Semantic Variable)是指被组件使用或修改并代表关键语义的关键变量,其变化通过智能体的组件调用来实现。
- 任务xxx的第kkk次执行包含NNN个组件调用,第iii个组件调用定义为:
callix,k=(metaix,k,inputix,k,outputix,k),with outputix,k=Ci(inputix,k)call_{i}^{x, k}=\left(meta_{i}^{x, k}, input_{i}^{x, k}, output_{i}^{x, k}\right) , \text{ with } output_{i}^{x, k}=C_{i}\left( input_{i}^{x, k}\right)callix,k=(metaix,k,inputix,k,outputix,k), with outputix,k=Ci(inputix,k)
其中Ci∈M∪TC_{i} \in M \cup TCi∈M∪T表示被调用的组件,inputix,kinput_{i}^{x, k}inputix,k和outputix,koutput_{i}^{x, k}outputix,k分别为输入和输出数据,metaix,kmeta_{i}^{x, k}metaix,k包含调用的元信息。
- 状态被定义为智能体执行的快照,包含程序计数器、变量值等,可抽象为随执行时间演变的变量集。对于任务$ x的第的第的第k次执行,时间步次执行,时间步次执行,时间步t包含包含包含V$个变量的状态表示为:
-
奖励与数据集
- 为使智能体从执行过程中收集的数据学习,引入奖励信号衡量任务完成质量。每个智能体执行都附加标量奖励{r1,...,rN}\{r_{1}, ..., r_{N}\}{r1,...,rN},带奖励信号的执行表示为:
executionR(x,k)={(callix,k,rix,k)}i=1Nexecution^{R}(x, k)=\left\{\left(call_{i}^{x, k}, r_{i}^{x, k}\right)\right\}_{i=1}^{N}executionR(x,k)={(callix,k,rix,k)}i=1N - 奖励可在中间步骤或执行结束时提供,训练或评估数据集由任务集X={x1,...,x∣X∣}X=\{x_{1}, ..., x_{|X|}\}X={x1,...,x∣X∣}和奖励函数组成。
- 为使智能体从执行过程中收集的数据学习,引入奖励信号衡量任务完成质量。每个智能体执行都附加标量奖励{r1,...,rN}\{r_{1}, ..., r_{N}\}{r1,...,rN},带奖励信号的执行表示为:
-
示例说明
以典型的检索增强生成(RAG)智能体为例,其包含生成式策略模型(LLM)和搜索工具,执行流程为:用户提交任务→LLM生成搜索查询→搜索工具检索相关段落→LLM生成最终答案。统一数据接口捕获所有状态变化,支持灵活的优化方法。
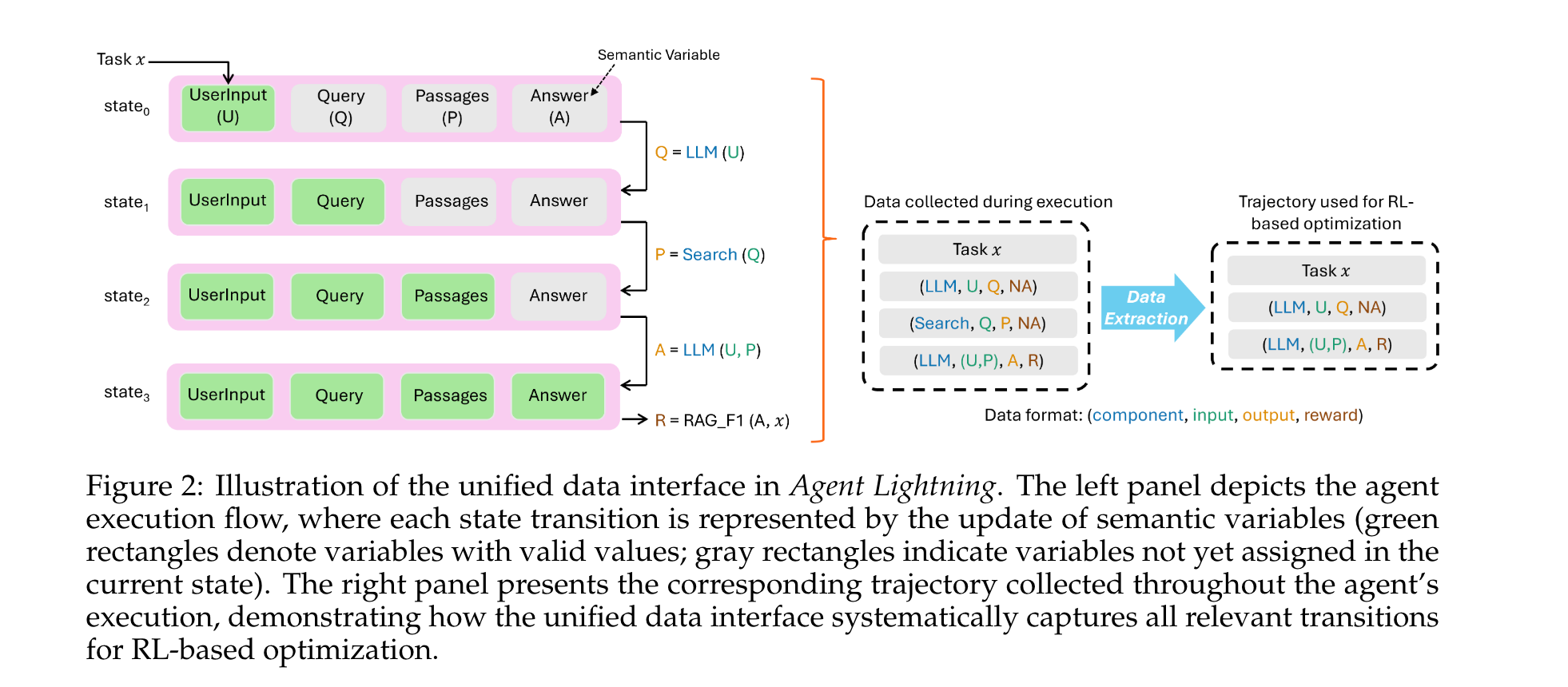
智能体中的马尔可夫决策过程
- 公式化定义
对于包含单个待优化LLM的智能体,将其视为策略模型时,决策过程可建模为部分可观测马尔可夫决策过程(POMDP),其元组M=(S,O,A,P,R)M = (S, O, A, P, R)M=(S,O,A,P,R)定义为:
-SSS是状态空间,对应所有可能的状态,即statet∈Sstate_{t} \in Sstatet∈S
-OOO是观测空间,对应策略LLM的所有可能输入,即inputt∈Oinput_{t} \in Oinputt∈O
-AAA是动作空间,单个动作定义为单次调用策略LLM生成的整个token序列,即outputt∈Aoutput_{t} \in Aoutputt∈A
-T(s′∣s,a)T(s' | s, a)T(s′∣s,a)定义到新状态的转移动态(通常未知)
-R(s,a)R(s, a)R(s,a)是奖励函数,将状态-动作对映射到标量奖励
回报定义为奖励之和:R=∑t=1TrtR=\sum_{t=1}^{T} r_{t}R=∑t=1Trt,策略模型的目标是最大化回报。 - RL数据提取
从每次执行中提取更新策略LLM(参数化为θ\thetaθ)所需的相关信息:LLM调用的原始输入、输出及其奖励,表示为:
executionRL(x,k)={(inputtx,k,outputtx,k,rtx,k)}t=1Texecution^{RL}(x, k)=\left\{\left( input_{t}^{x, k}, output_{t}^{x, k}, r_{t}^{x, k}\right)\right\}_{t=1}^{T}executionRL(x,k)={(inputtx,k,outputtx,k,rtx,k)}t=1T
其中outputtx,k=πθ(inputtx,k)output_{t}^{x, k}=\pi_{\theta}\left( input_{t}^{x, k}\right)outputtx,k=πθ(inputtx,k),πθ\pi_{\theta}πθ是待优化的LLM,TTT是该轨迹中的调用次数。 - 扩展应用
- 单LLM多智能体场景:LLM可在执行的不同阶段基于提示承担多个角色,Agent Lightning能有选择地优化多智能体系统中的智能体。
- 多LLM场景:可将每个LLM视为独立MDP分别优化,或使用多智能体强化学习(MARL)更好地捕捉LLM间的交互动态。
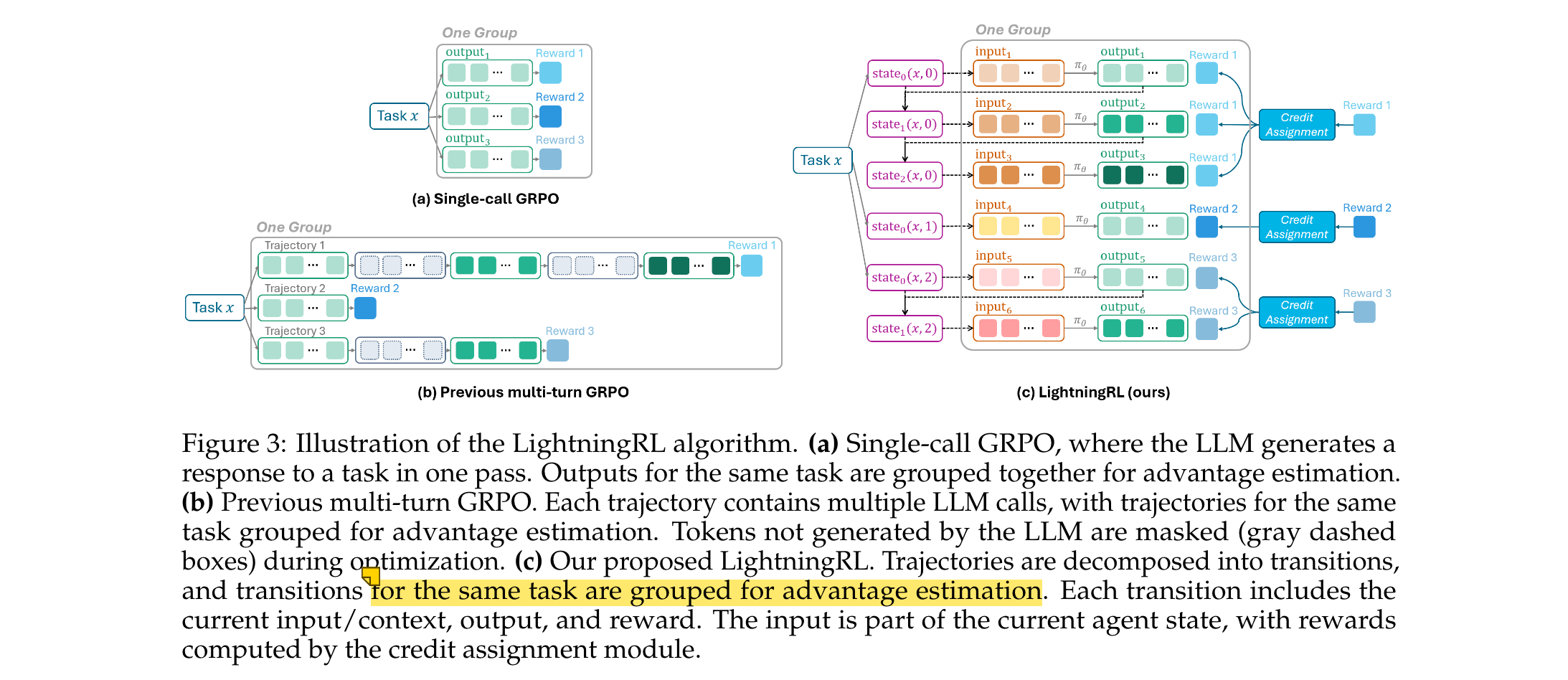
LightningRL:用于优化智能体中LLMs的层级RL方法
- 单轮LLMs强化学习基础
近期LLMs的RL进展集中在单调用问题上,模型根据提示生成响应。给定任务xxx,LLM从策略πθ\pi_{\theta}πθ逐token生成响应output=(y1,...,yN)output=(y_{1}, ..., y_{N})output=(y1,...,yN),响应生成后基于解决方案的正确性或质量分配标量奖励r(x,output,g)r(x, output, g)r(x,output,g)。典型的token级损失简化为:
L(θ)=−Ex∼X,output∼πθ(⋅∣x)[∑j=1Nlogπθ(yj∣x,y<j)⋅Aj]\mathcal{L}(\theta)=-\mathbb{E}_{x \sim \mathcal{X}, output \sim \pi_{\theta}(\cdot | x)}\left[\sum_{j=1}^{N} \log \pi_{\theta}\left(y_{j} | x, y_{<j}\right) \cdot A_{j}\right]L(θ)=−Ex∼X,output∼πθ(⋅∣x)[∑j=1Nlogπθ(yj∣x,y<j)⋅Aj]
其中AjA_{j}Aj是token级优势估计,不同算法的核心区别在于优势项AtA_{t}At的估计方式。 - 通过LightningRL扩展到智能体场景
LightningRL是一种简单的层级强化学习(HRL)方法,将数据按过渡组织,每个过渡定义为(inputtx,k,outputtx,k,rtx,k)(input_{t}^{x,k}, output_{t}^{x,k}, r_{t}^{x,k})(inputtx,k,outputtx,k,rtx,k),通过两步机制实现扩展:- episode级回报RRR由信用分配模块跨动作分配
- 进一步在每个动作的token间分解,产生token级监督信号
该设计允许直接使用任何单轮RL算法,支持灵活构建策略观测,提供更稳健和可扩展的实现,缓解长上下文问题。
Agent Lightning的系统设计
- 训练-智能体分离架构
该架构将计算密集型的LLM生成与轻量级且多样灵活的传统编程语言编写的应用逻辑和工具分离,前者由RL框架管理并向后者暴露类OpenAI API,后者可独立管理和执行。- 实现了训练框架与智能体的相互独立,训练框架与智能体逻辑解耦,智能体也独立于训练框架的实现细节。
- 包含Agent Lightning Server和Agent Lightning Client,服务器与RL框架集成,管理训练过程和LLM优化;客户端封装智能体,使其独立于训练框架运行。
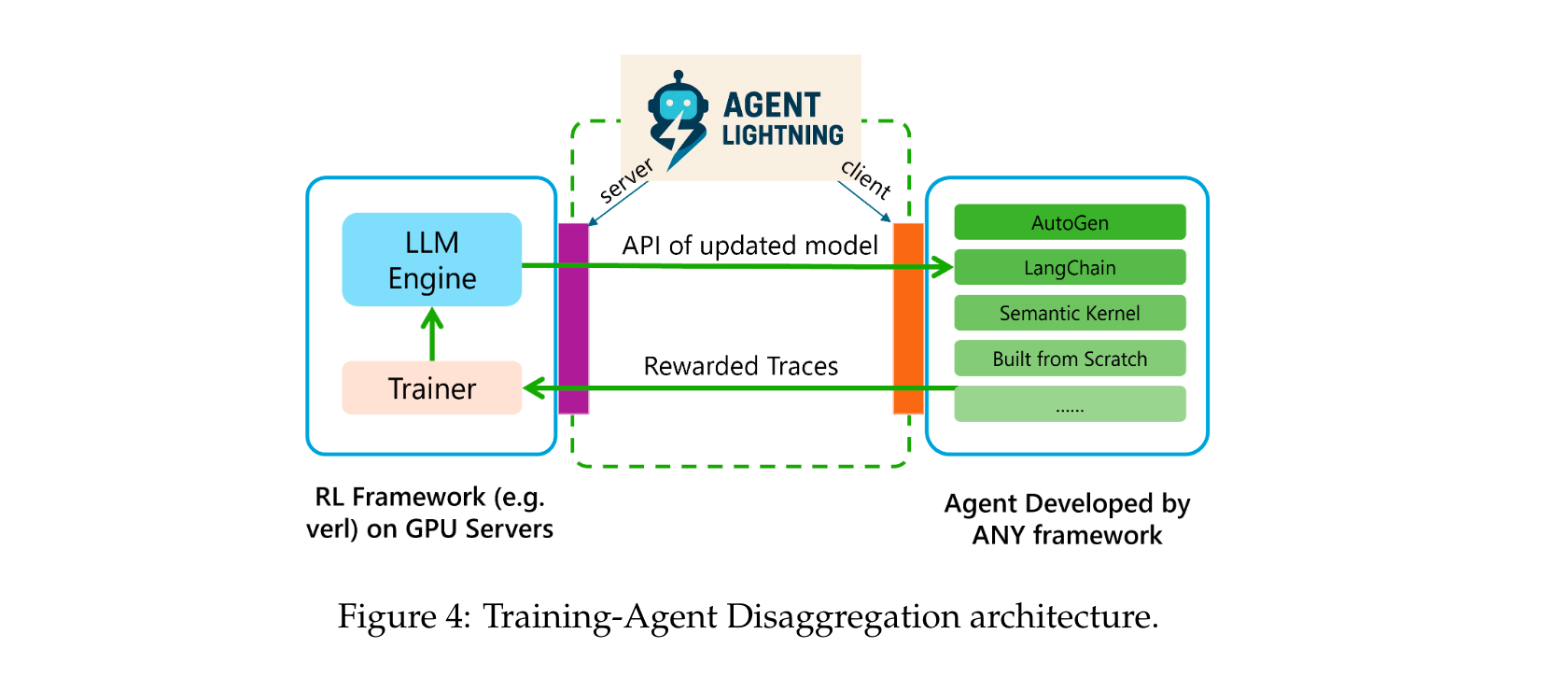
- 智能体运行时
Agent Lightning客户端是智能体的运行时管理器,协调执行、捕获数据、处理错误并与服务器通信。- 智能体执行的数据并行:采用两级并行策略(节点内并行和节点间并行),高效管理多个智能体实例并发执行。
- 无需代码修改的数据捕获:采用基于OpenTelemetry和AgentOps的工具化技术,或嵌入类OpenAI API端点的基本跟踪机制,捕获相关数据。
- 错误处理与稳健性:包含全面的错误处理机制,检测并处理代理代码未妥善处理的故障,确保训练过程的稳定性和可靠性。
- 自动中间奖励(AIR):将系统监控数据转换为中间奖励,为训练框架提供更频繁和信息丰富的信号。
- 环境和奖励服务的可扩展性:支持将轻量级环境和奖励函数与智能体实例在同一工作器中执行,对资源密集型的则作为共享服务托管。
实验洞察
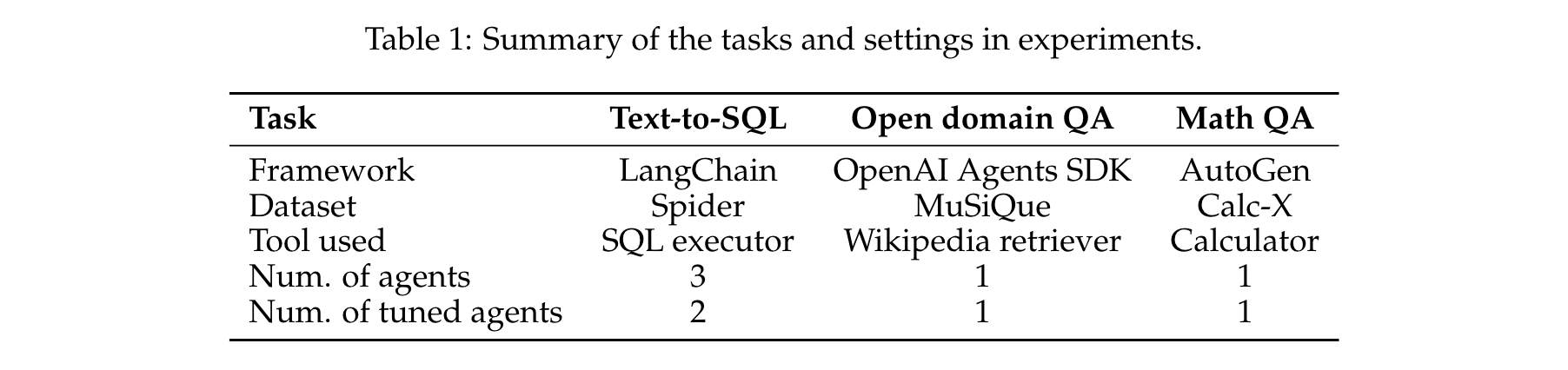
实验任务与设置
实验在三个不同任务上验证Agent Lightning的有效性,每个任务使用不同的智能体框架实现,具体设置如下表所示:
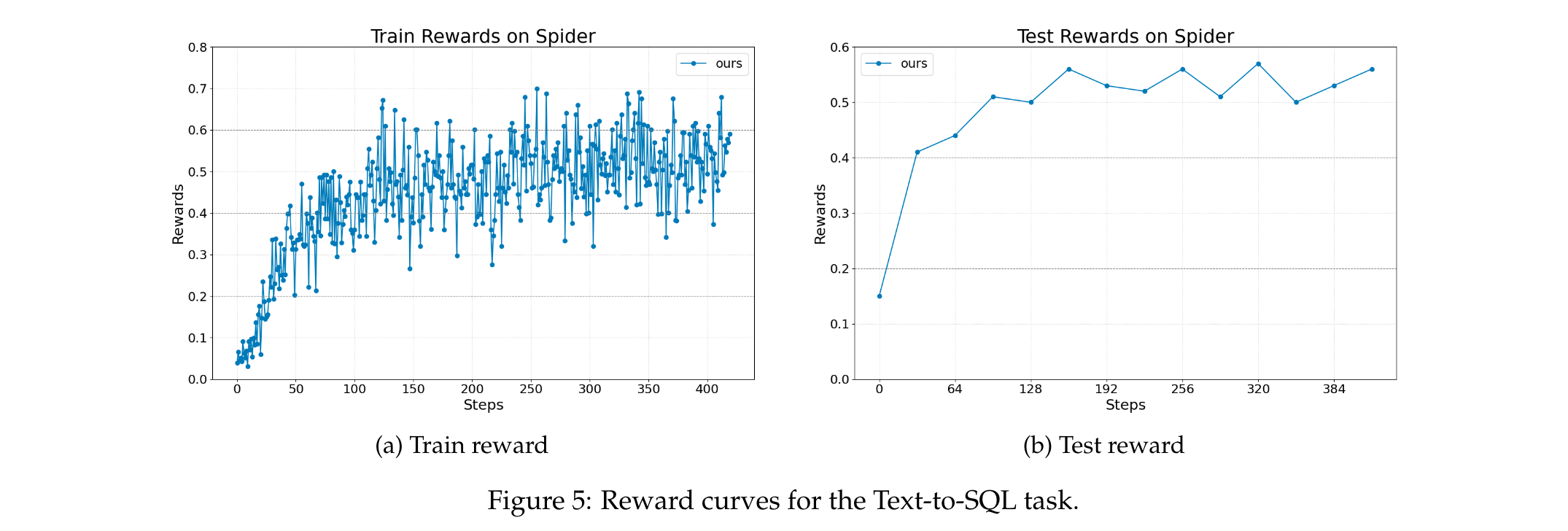
Text-to-SQL(基于LangChain)
- 任务描述:给定自然语言问题和数据库,智能体需生成SQL查询检索相关信息并回答问题,使用Spider数据集(包含10,000多个问题,覆盖200个数据库和138个不同领域),基础模型为Llama-3.2-3B-Instruct。
- 智能体设计:多智能体系统,包含SQL编写智能体、检查智能体和重写智能体,训练中仅优化SQL编写和重写智能体。
- 奖励与评估:奖励由问题最终答案的正确性决定,模型性能通过测试集上的答案准确率评估。
- 结果:如图5所示,Agent Lightning实现了稳定的奖励提升,表明其能优化涉及代码生成和工具使用的复杂多步骤决策。
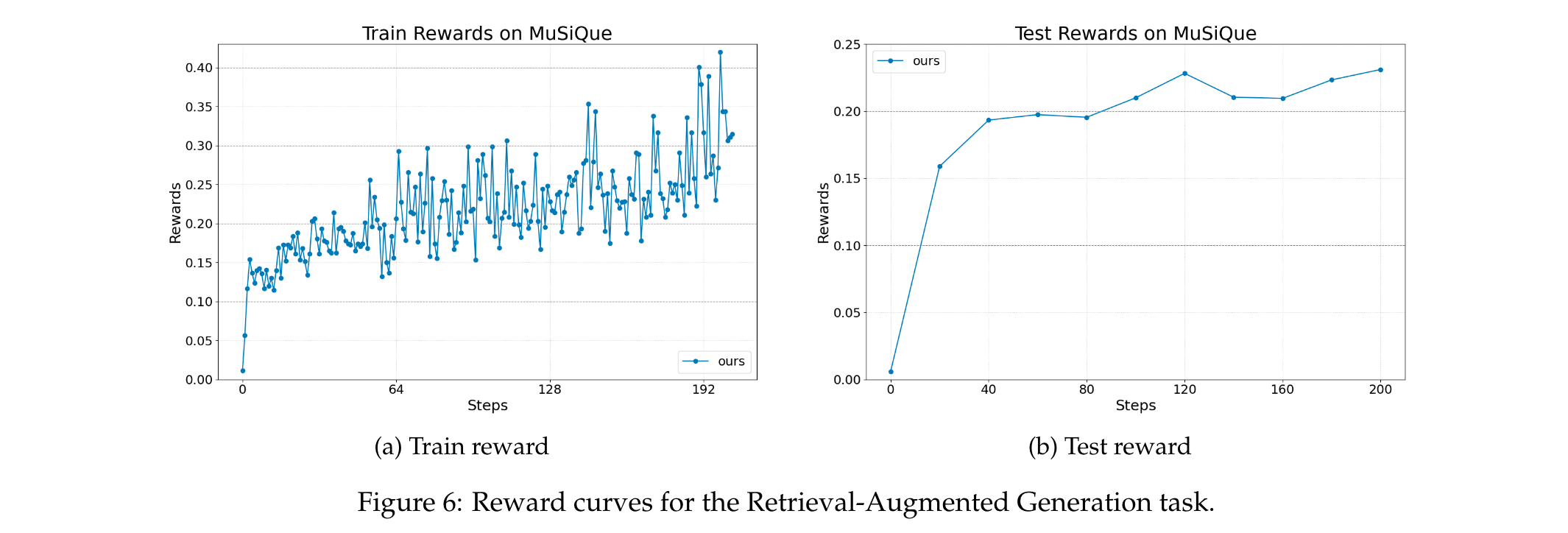
检索增强生成(基于OpenAI Agents SDK)
- 任务描述:给定问题和文档数据库,智能体先生成自然语言查询使用现有检索工具检索支持文档,使用MuSiQue数据集(多跳问答基准),数据库为整个Wikipedia(含2100万文档),检索工具基于BGE模型生成的嵌入和余弦相似度,基础模型为Llama-3.2-3B-Instruct。
- 智能体设计:单LLM智能体,需生成查询并根据检索文档决定是否优化查询或生成答案。
- 奖励计算:训练奖励为格式分数RformatR_{format}Rformat和正确性分数的加权组合,R=0.9×Rcorrectness+0.1×RformatR=0.9 × R_{correctness} + 0.1 × R_{format}R=0.9×Rcorrectness+0.1×Rformat,其中格式分数在LLM按特定格式输出时为1,正确性分数为预测答案与黄金答案的词级F1分数。
- 结果:如图6所示,Agent Lightning在该具有挑战性的任务上实现了稳定的性能提升,证明其在更复杂和开放的RAG场景中的有效性。
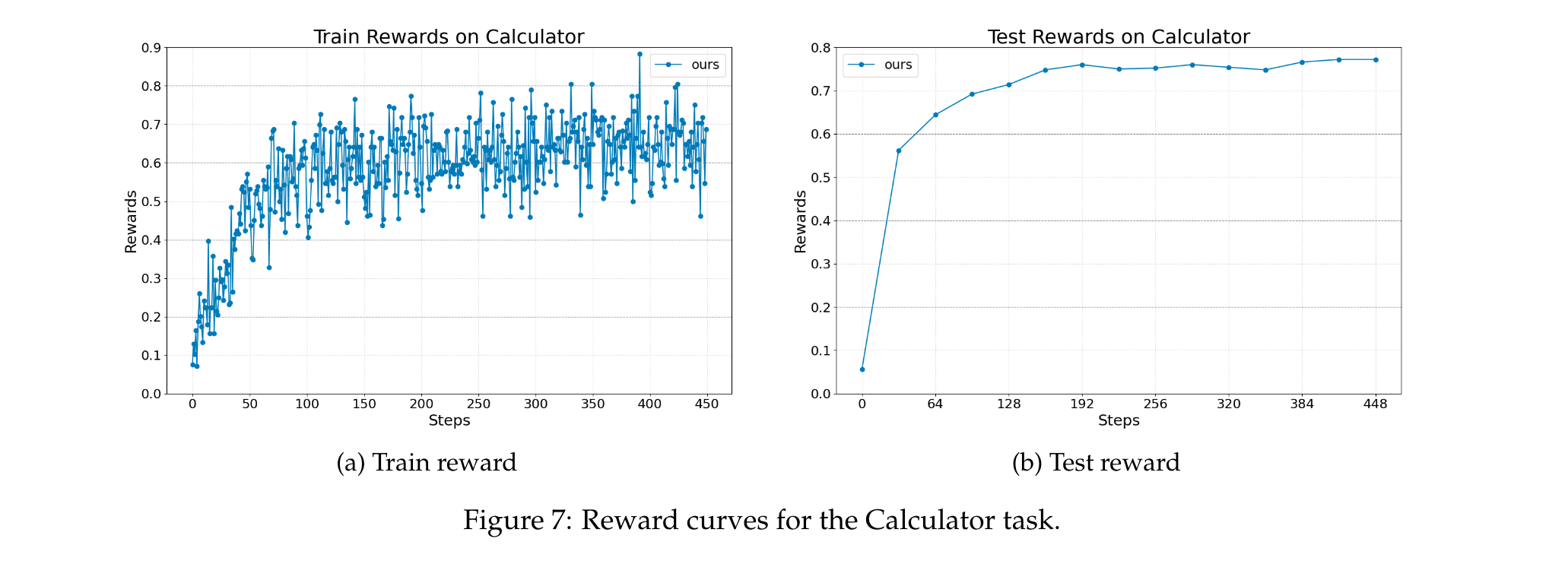
带工具使用的数学QA(基于AutoGen)
- 任务描述:评估智能体调用工具(计算器)解决算术和符号问题的能力,使用Calc-X数据集(包含多种数学问题,强调将外部工具集成到推理工作流中),基础模型为Llama-3.2-3B-Instruct。
- 智能体设计:单LLM智能体,负责生成工具调用、解释工具输出并形成最终答案。
- 奖励与评估:最终奖励基于智能体是否正确回答问题,模型性能通过测试集上的答案准确率评估。
- 结果:如图7所示,Agent Lightning在训练过程中持续提高性能,证明其在工具增强场景中的有效性,该场景既需要精确的外部函数调用又需要推理能力。
实验结论
实验结果表明,Agent Lightning在不同智能体场景中均能实现持续稳定的性能提升,展示了解决现实世界任务的巨大潜力,其设计能够有效支持各种复杂交互逻辑和不同框架实现的智能体的强化学习训练。