基于Python对酷狗音乐排行榜数据分析可视化【源码+LW+部署】
作者主页:编程千纸鹤
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码

项目编号:2024-2025-BS-PT-015
一,环境介绍
语言环境:Python3.8
数据库:Mysql: mysql5.7
WEB框架:Django
开发工具:IDEA或PyCharm
开发技术:Python+爬虫+可视化分析+Flask
二,项目简介
随着我国目前信息技术的飞速跃进与数字音乐领域的广泛渗透,各个著名的音乐平台的音乐排行榜已成为评估音乐作品受欢迎程度的关键参照。作为国内享有盛誉的音乐服务平台,酷狗音乐所提供的排行榜数据,深度蕴藏着用户的偏好动向及音乐市场的潜在趋势,为分析者提供了宝贵的洞察视角。然而,这些海量数据往往以非结构化的形式存在,难以直接洞察其内在规律和趋势。因此,本选题旨在利用Python强大的数据处理和可视化能力,对酷狗音乐排行榜数据进行深入挖掘和分析,以揭示音乐市场的动态变化和用户偏好,为音乐产业的相关决策提供科学依据。
在当今这个信息技术日新月异的时代,众多信息化与技术驱动的大型平台中,蕴藏着海量且富有潜力的客户行为数据资源,这些数据在大数据技术兴起之前往往被忽视或由于高昂的存储成本而被遗弃,错失了通过数据挖掘将这些数据转化为实际价值的良机。要对这些数据进行分析,有效利用这些数据资源,首先要获得这些数据。Python语言的爬虫技术目前可以比较方便的从互联网平台中抓取自己需要的相关数据,为数据挖掘开辟了广阔天地,使得能够深入探索酷狗音乐平台的用户数据,揭示这些数据背后的深层意义,并据此提炼出数据特征,为平台的运营决策层提供更为精准、丰富且有益的决策支持与建议。本研究的价值在于,通过构建大数据分析可视化的Web平台,以直观易懂的方式展现酷狗用户行为数据的分析结果,既便于数据查询,又增添了观赏性与实用性,实现了数据价值的最大化展现。
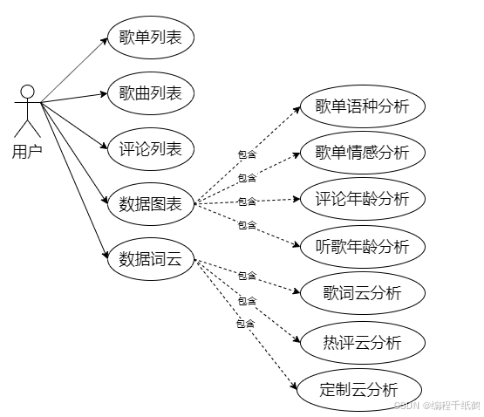
(1)歌曲列表:查询经过数据清洗并存储在数据库中的歌曲数据,以分页形式来进行展示。
(2)歌单列表:查询经过数据清洗并存储在数据库中的歌单数据,以分页形式来进行展示。
(3)评论列表:查询经过数据清洗并存储在数据库中的歌曲评论数据,以分页形式来进行展示。
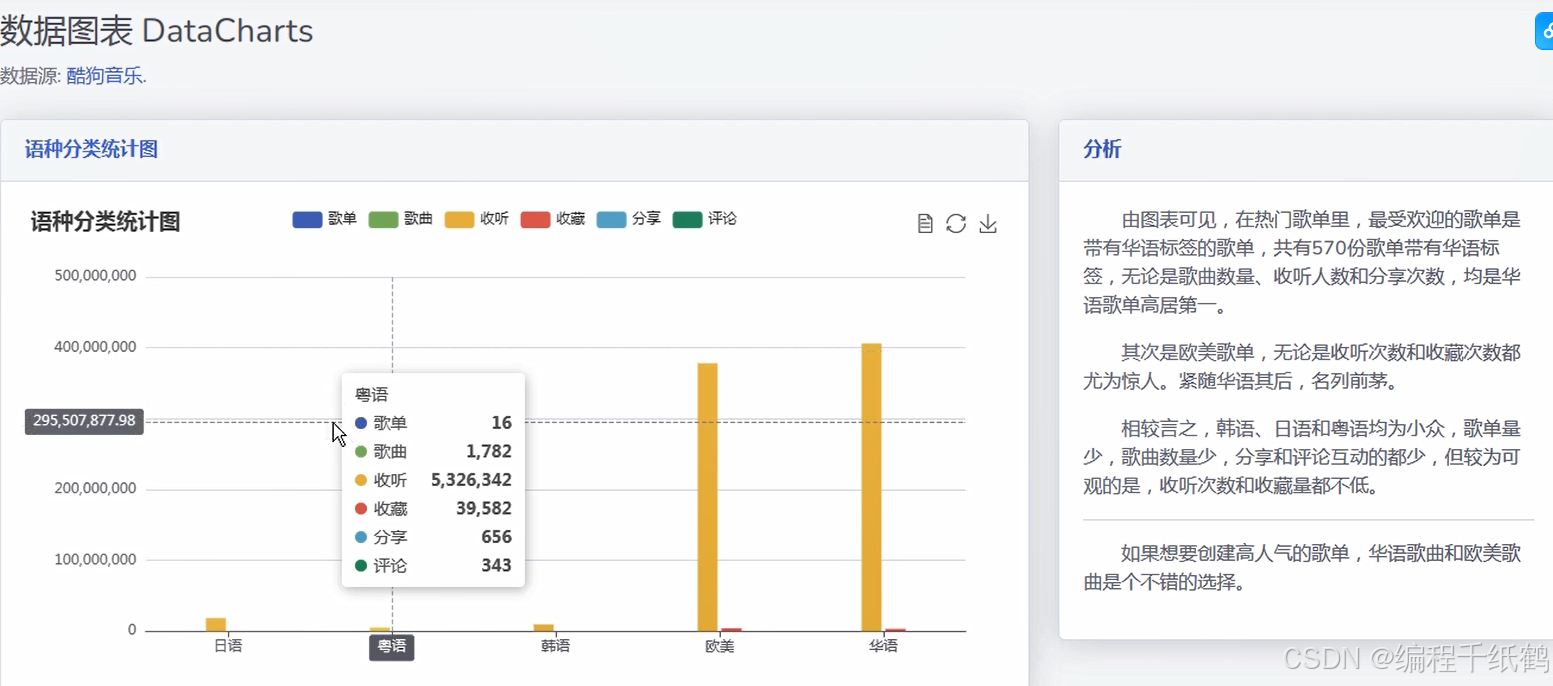
(4)歌单语种分析:通过柱状图的形式来分析展示最爱欢迎的语种是哪种,以及各语种的占比情况。
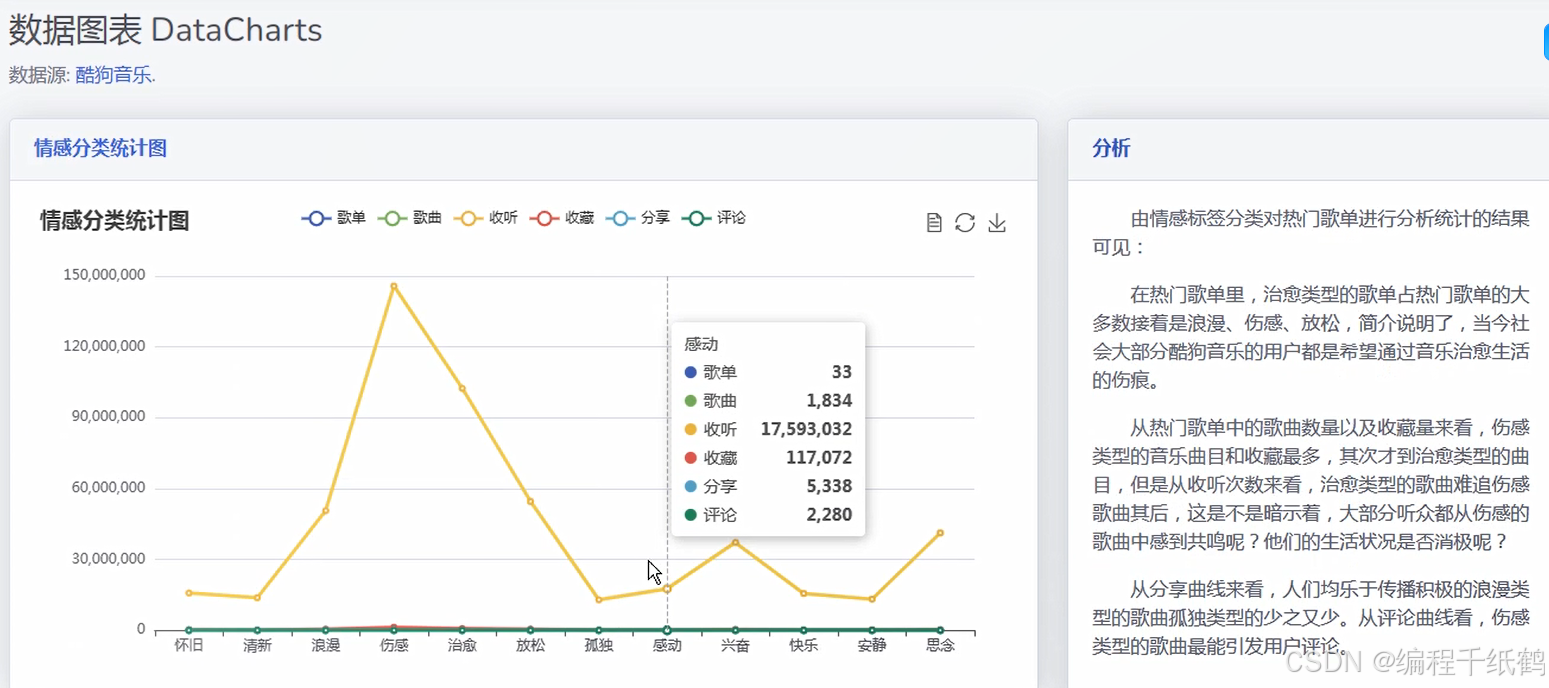
(5)歌单情感分析:通过折线图的形式来分析展示各种情感的音乐收听情况,伤感的、爱情的、励志的等进行分类展示。
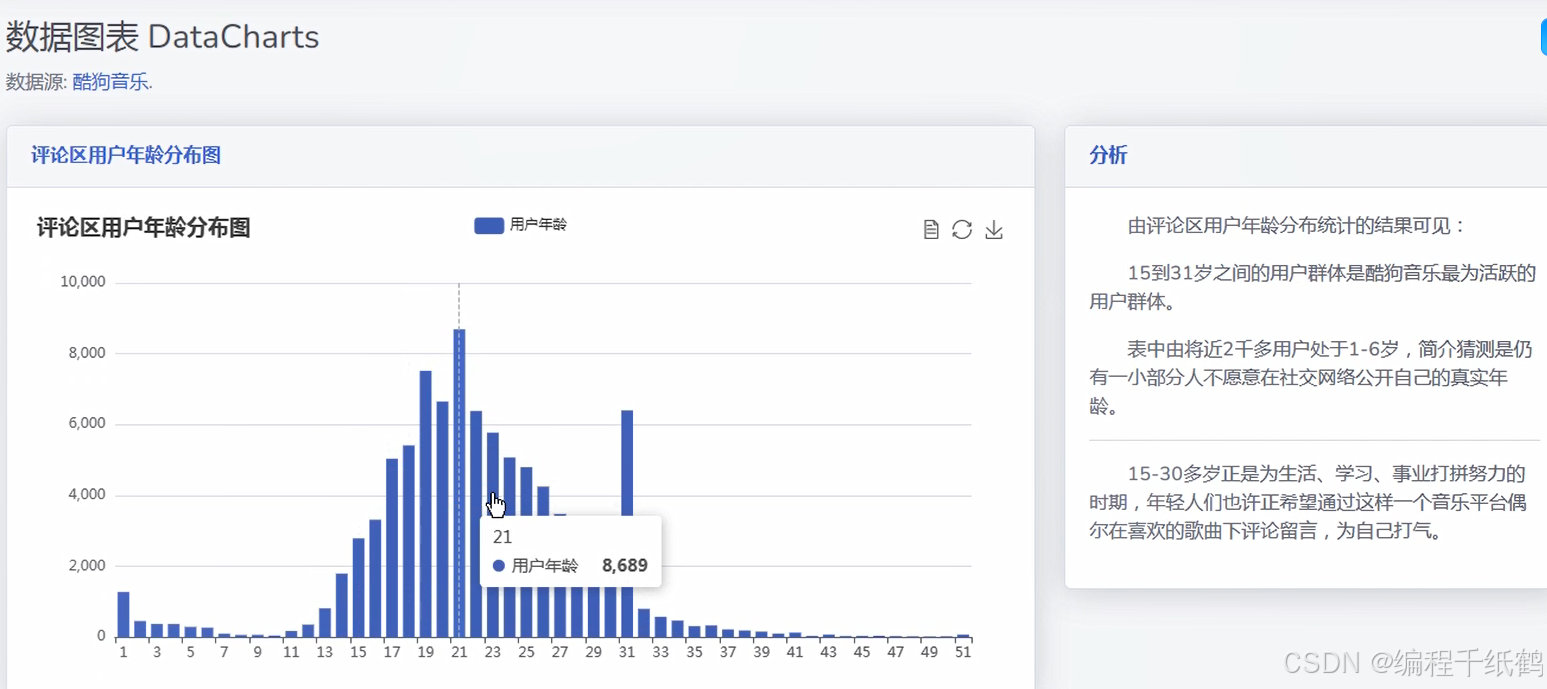
(6)评论年龄分析:通过柱状连续图的形式来分析展示各种年龄阶段评论音乐的比例并进行可视化展示。
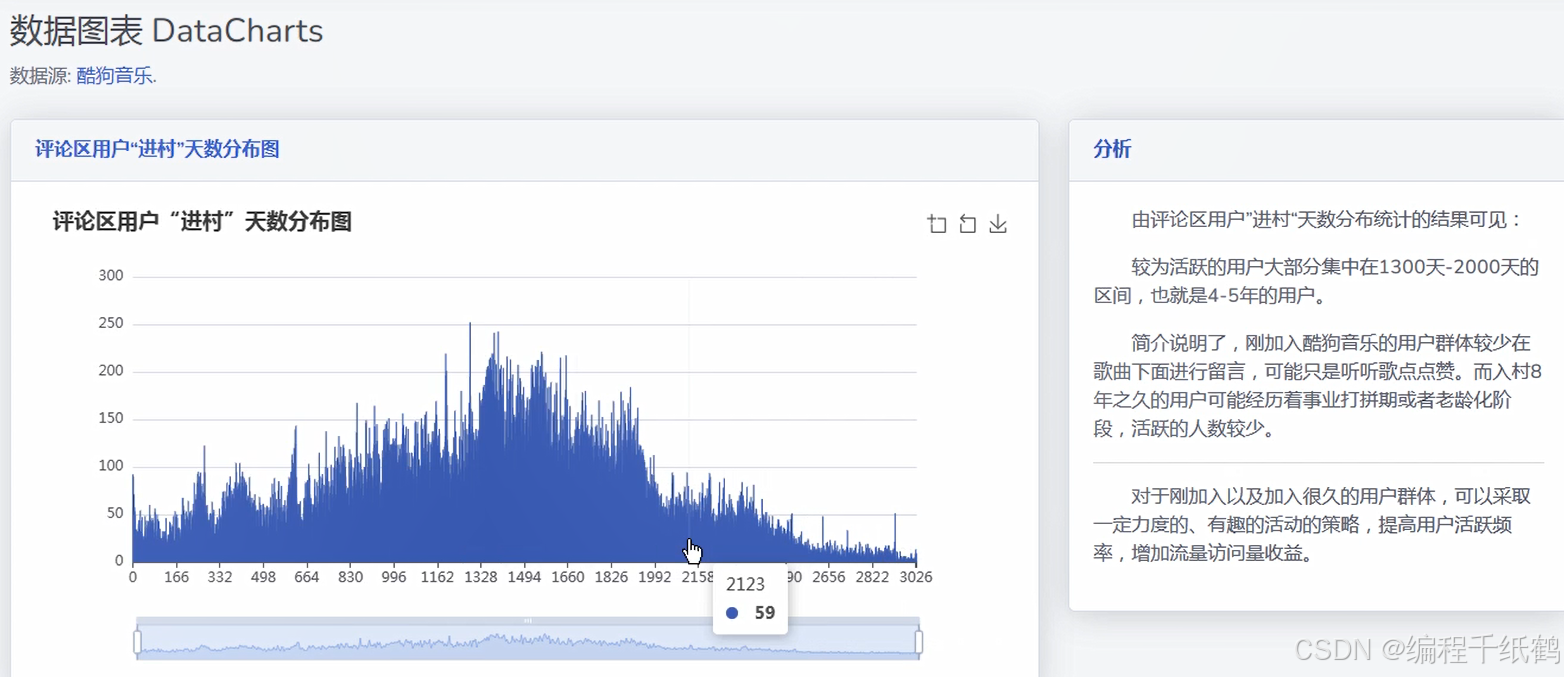
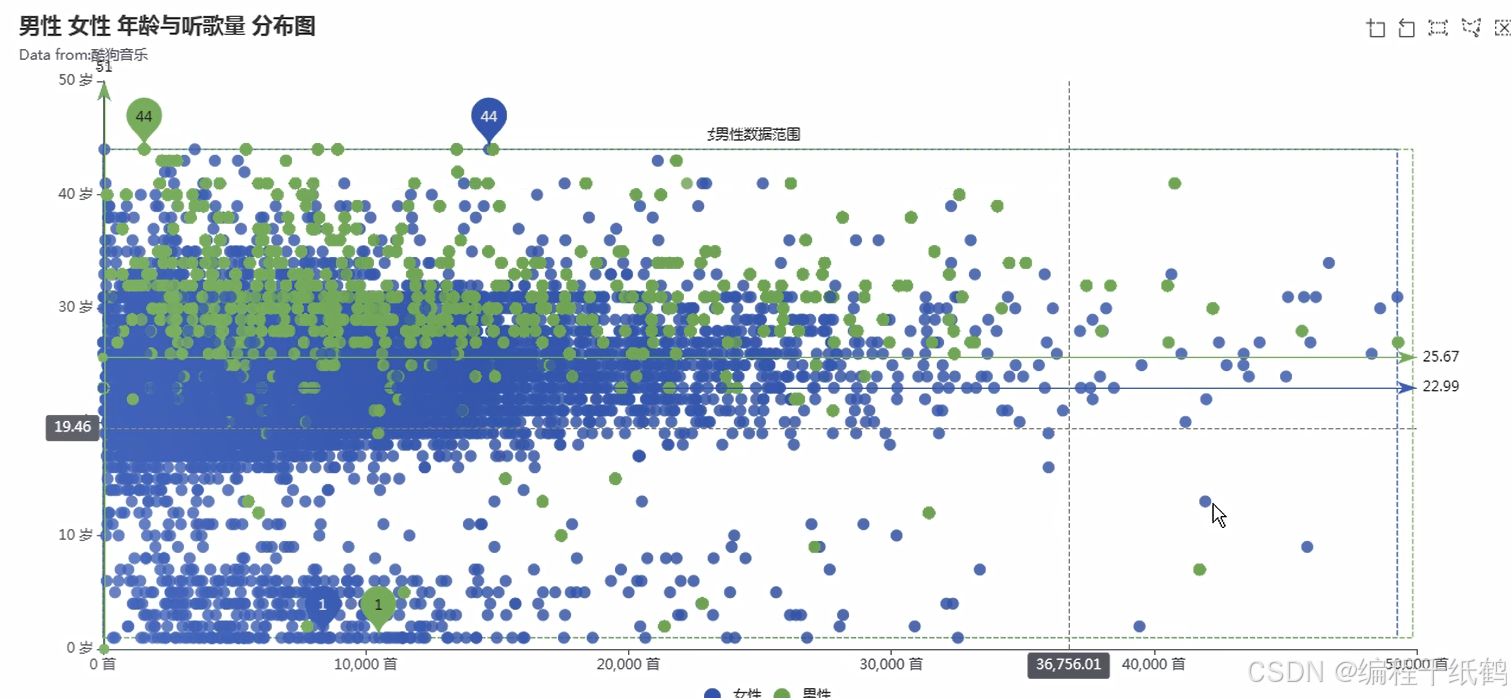
(7)听歌年龄分析:通过散点图的形式来分析展示各种年龄阶段收听音乐的比例并进行可视化展示。
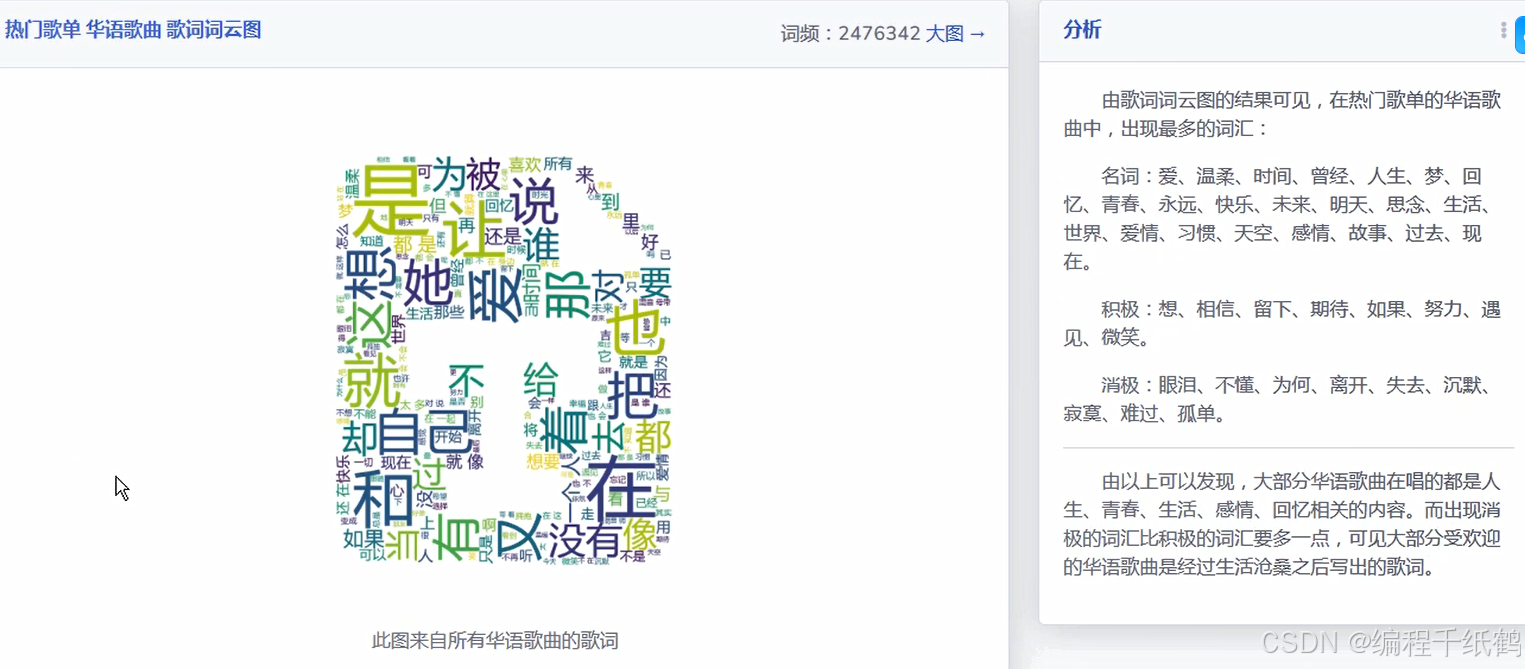
(8)歌词云图分析:通过云的形式来分析展示各种音乐中相应的关键词出现的数量,以此来了解各种歌曲的主题风格。
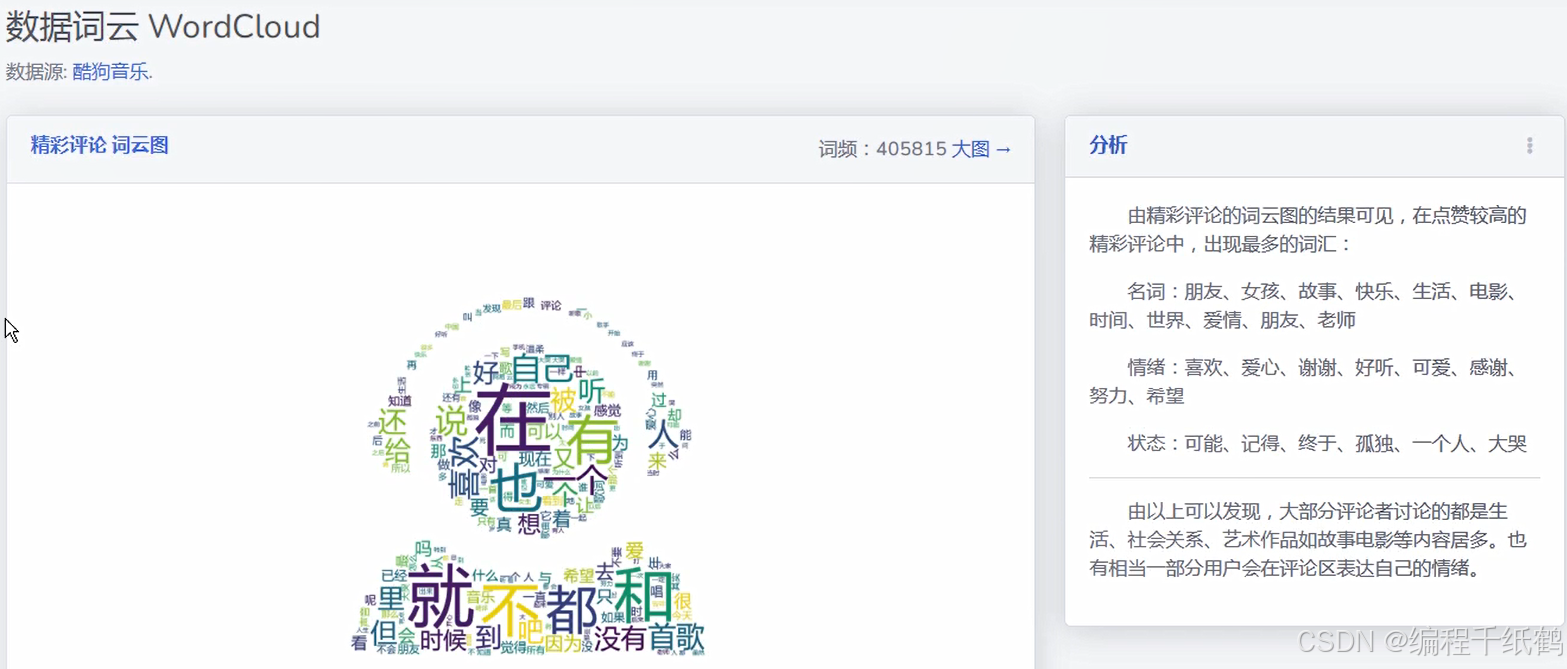
(9)热评云图分析:通过云的形式来分析展示各种音乐评论中相应的关键词出现的数量,以此来了解用户对音乐评论的倾向性。
(10)歌词云图分析:通过云的形式来分析展示用户输入的指定歌曲名称的评论词云分析,体现根据客户需求来进行分的功能。
三,系统展示
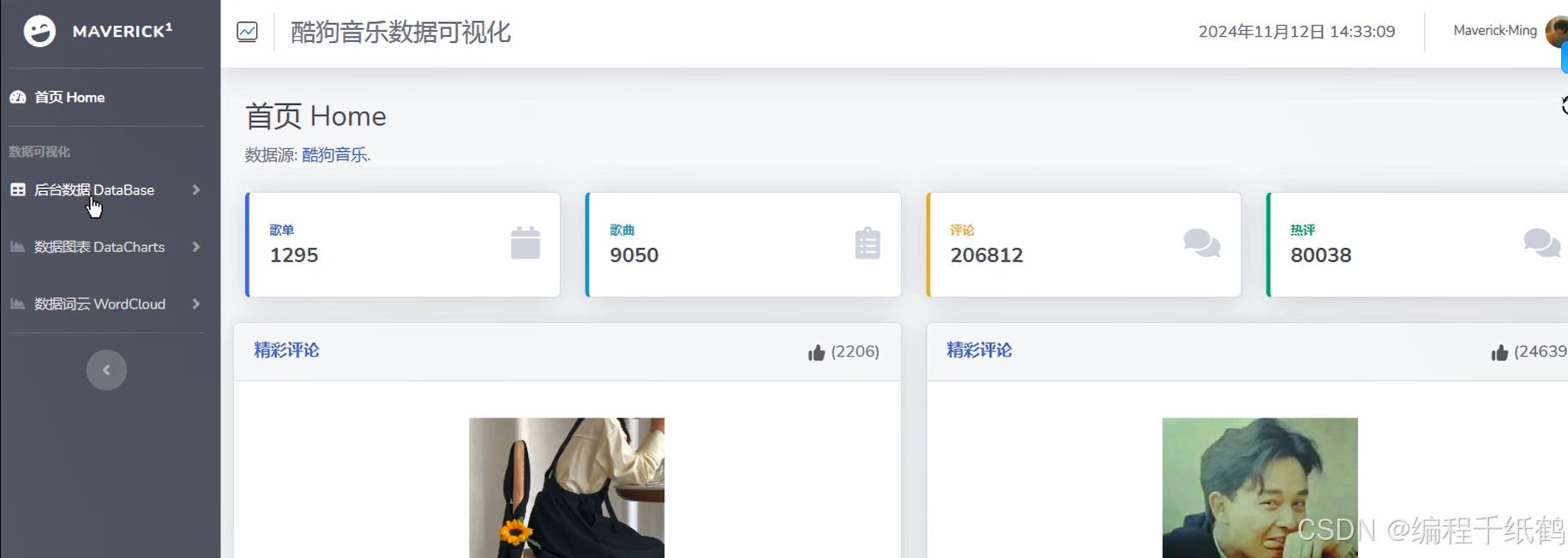
四,核心代码展示
# _*_ coding:utf-8 _*_
# 开发团队: Mavericks
# 开发人员:Maverick·Ming
# 开发IDE: PyCharm
# 项目名:酷狗音乐数据可视化
# 文件名:01playlist.py
# 开发时间:2024/11/7 16:33# 引入所需模块
import time
import random # 模拟人类停歇操作
from selenium import webdriver # 浏览器驱动对象,负责获取元素、操作元素、
import sqlite3 # 操作数据库,读取数据"""
主要负责爬取歌单浏览页的信息,包括歌单url,单主url
"""# 获取所有歌单的url
def get_playlist_url(db_path):"""此方法负责爬取网易云歌单页面所有歌单的url、歌单创作者的url:param db_path: 数据库所在位置"""# options = webdriver.ChromeOptions()# options.add_argument('--headless') # 无头模式,不显示浏览器窗口# # options.binary_location = 'chrome_path' # 设置 Chrome 浏览器的路径browser = webdriver.Chrome(executable_path=r'chromedriver')# browser = webdriver.Chrome('chromedriver.exe') # 配置浏览器page_one_url = 'https://www.kugou.com/#/discover/playlist/?order=hot&cat=全部&limit=35&offset=0' # 歌单列表首页datalist = [] # 存储歌单列表页面的所有item的url# 遍历所有歌单浏览页1-38页next_page_url = page_one_url # 传入首页urlpage_count = 1 # 统计已爬取的页数,方便开发人员查看进度list_count = 0 # 统计已爬取的歌单数量,方便查看进度while next_page_url != 'javascript:void(0)':browser.get(next_page_url) # 访问歌单首分页/下一分页的urltime.sleep(random.randint(8, 12)) # 模拟人类操作,随机停顿等待加载完成iframe = browser.find_element_by_class_name('g-iframe')iframe.send_keys(u'ue010') # 下拉到页面低端,方便看到下一页按钮browser.switch_to.frame(iframe) # 切换到iframe里面# 计算页数pages = browser.find_elements_by_xpath('//*[@id="m-pl-pager"]/div/a')[-2].text# 获取下一页的urlnext_page_url = browser.find_element_by_xpath('//*[@id="m-pl-pager"]/div/a[11]').get_attribute('href')# 定位所需的提取内容的所有容器(循环要用)item_all = browser.find_elements_by_xpath('//ul[@id="m-pl-container"]/li') # 获取所有歌单li元素# 获取歌单列表页面的信息for item in item_all:data = []list_url = item.find_element_by_xpath('./p[@class="dec"]/a').get_attribute('href') # 获取每个歌单详情的urldata.append(list_url) # 爬取歌单详情的url,方便后期查找歌单详情的数据list_id = list_url.replace('https://www.kugou.com/playlist?id=', '') # 歌单id# list_id = int(list_id)data.append(list_id) # 保存歌单idlist_name = item.find_element_by_xpath('./p[@class="dec"]/a').get_attribute('title') # 获取歌单名data.append(list_name) # 保存歌单名list_img = item.find_element_by_xpath('./div/img').get_attribute('src') # 获取歌单封面data.append(list_img) # 保存封面author_url = item.find_element_by_xpath('./p[2]/a').get_attribute('href') # 获取歌单创建人urldata.append(author_url) # 保存歌单创建者urlauthor_id = author_url.replace('https://www.kugou.com/user/home?id=', '') # 提取歌单author的id# author_id = int(author_id)data.append(author_id) # 保存歌单创建者idauthor_name = item.find_element_by_xpath('./p[2]/a').get_attribute('title') # 获取歌单创建人名称data.append(author_name)visit_count = item.find_element_by_xpath('./div/div/span[2]').text # 获取歌单创建人名称visit_count = visit_count.replace('万', '0000')data.append(visit_count)list_count += 1 # 至此爬取完一个歌单,累加1datalist.append(data) # 保存一个歌单的概要信息print(data[2], data[6], data[7])save_playlist_url(datalist, db_path) # 取一页存一页,降低资源占用率datalist.clear() # 清楚占用资源print('完成!共' + pages + '页!已爬取', page_count, '页,含有', list_count, '个歌单信息!')page_count += 1 # 累加器print('完成!已爬取所有分页歌单的基础信息')browser.close()def save_playlist_url(datalist, db_path):"""get_playlist_url函数每获取一页歌单信息,就调用此方法保存数据,降低资源占用率。:param datalist: 需要存入数据库的数据:param db_path: 数据库位置:return:"""# 插入数据conn = sqlite3.connect(db_path)cur = conn.cursor()for data in datalist: # datalist是二重列表,列表中嵌套列表for index in range(len(data)): # 操作子列表if index == 1 or index == 5 or index == 7: # 这两个index所在的位置存的是数值内容,所以不需要加""continue # 因为有id自动生成,所以index因该是4,5data[index] = '"' + data[index] + '"' # 在内容前后加上"",才符合sql语句的规则sql = '''insert into playlist(list_url,list_id,list_name,list_img,author_url, author_id,author_name,visit_count) VALUES (%s)''' % ",".join(data)cur.execute(sql)conn.commit()cur.close()conn.close()print('成功!将歌单信息保存到数据库!')# 初始化数据库,创建数据库
def init_db(path):"""在爬取信息之前,调用此函数创建数据表table:param path: 数据库位置:return: none"""# os.remove(path) # 数据库已经存在,则删除【不应该轻易删除,应该删除table优先】conn = sqlite3.connect(path) # 连接数据库c = conn.cursor() # 获取操作数据库的游标sql = '''drop table if exists playlist;'''c.execute(sql)sql = ''' create table playlist(id integer primary key autoincrement,list_url text,list_id numeric,list_name text,list_img text,author_url text,author_id numeric,author_name text,visit_count numeric );'''c.execute(sql)conn.commit()conn.close()print('创建/初始化数据库表成功!')def main(): # 整体工作流程"""所有操作流程按照此函数开始:return: none"""# 初始化数据库db_path = '../data/NEC_Music.db'# init_db(db_path)# 获取热门歌单,同时保存数据库get_playlist_url(db_path) # 里面调用save_playlist_url()# 程序入口,确保程序执行的流程
if __name__ == '__main__': # 当程序被调用执行时, 按照此语句入口的顺序执行程序,不至于乱序调用# 调用函数main()五,相关作品展示
基于Java开发、Python开发、PHP开发、C#开发等相关语言开发的实战项目
基于Nodejs、Vue等前端技术开发的前端实战项目
基于微信小程序和安卓APP应用开发的相关作品
基于51单片机等嵌入式物联网开发应用
基于各类算法实现的AI智能应用
基于大数据实现的各类数据管理和推荐系统







