LLM应用场景能力边界趋势全览
前言:最近在大模型使用、科研结合上有些迷惑,担心用的模型不对,从事的方向不对,毕竟大模型像打了鸡血一样疯狂更新,产品很多,需要在短时间内根据自己需求来正确抉择大模型的使用。那如何选择是个问题。需要知道大模型的应用场景及自己的业务需求,自己困难在哪,模型擅长什么,成熟应用有什么,未来趋势是什么,这些都是需要认真思考的,想在大模型浪潮里乘风破浪,得精准拿捏它的”技能树”和咱们的“需求清单”。本文旨在窥探大模型的场景化应用、技术前沿探索、构建完整知识体系,以期为面临类似困惑的科研工作者与技术从业者提供有价值的参考与启发。
目录
- 大模型分类
- 模型部署
- 应用
- 应用领域
- Agent
- AIGC
- 行业应用
- prompt
- 学术前沿
- 模型汇总
- 1. 超长文档(Long Context Handling)
- 2. Coding 神器
- 3. 科学计算(Scientific Computing)
- 4. 中文本土
- Reference
大模型分类
- 语言大模型
NLP - 视觉大模型
CV - 多模态大模型
CV + NLP
按照应用领域
- 通用大语言模型
- 行业大语言模型
- 垂直大语言模型
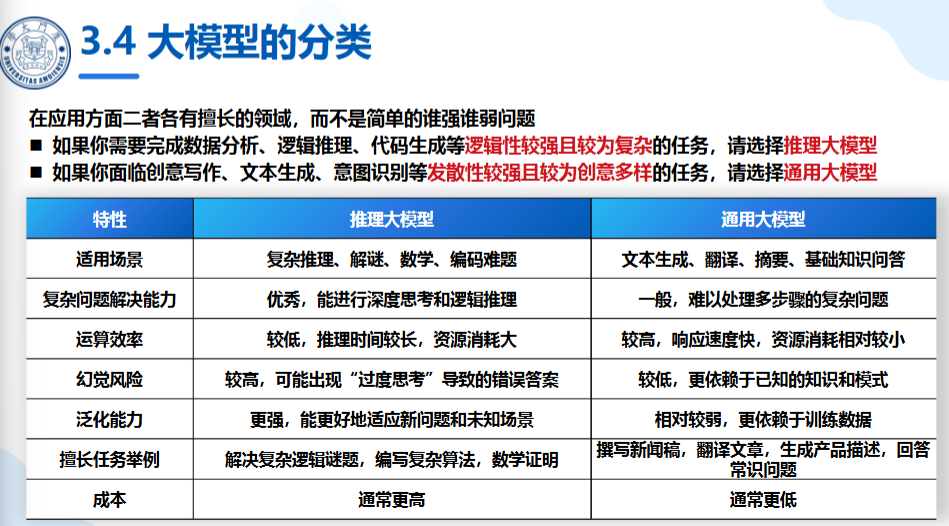
LLM分类
- 推理大模型
推理模型的核心在于处理那些需要多步骤逻辑推导才能解决的复杂问题。
模型在回复用户之前,在内部会有一长串的思维链过程。
例子:
| 非推理问题: |
|---|
| 法国的首都是哪里?(答案直接、无需推导) |
| 推理问题: |
|---|
| 一列火车以每小时60英里的速度行驶3小时,行驶距离是多少?(需先理解”距离=速度x时间”的关系,再分步计算) |
推理问题:
”一列火车以每小时60英里的速度行驶3小时,行驶距离是多少?(需先理解”距离=速度x时间”的关系,再分步计算)
- 通用大模型
当前模型总结
Summary of current models: View the full data (Google sheets)
模型部署
为应对特定任务上的表现不精准,采用1.模型微调, 2. 知识库
- 模型微调
1. 监督微调:在监督微调阶段,模型会学习一个 指令-响应(Instruction-Response)数据集,该数据集包含大量人类编写的任务示例,例如“请解释相对论的基本概念”及其标准答案通过这种方式,模型能够理解不同类型的任务并提供符合预期的回答。指令-响应(InstructionResponse)数据集用于训练模型理解任务指令并生成符合预期的响应
2. 强化学习
不足:数据准备成本过高(微调需要大量特定数据的预处理);时效性问题(知识更新频繁,需要不断微调) - 知识库
RAG(Retrieval-Augmented Generation)
其核心思想是:在生成答案前,先从外部知识库中检索相关信息,再将检索结果与用户输入结合,指导生成模型输出更可靠的回答。简单地说,就是利用已有的文档、内部知识生成向量知识库,在提问的时候结合库的内容一起给大模型,让其回答的更准确,它结合了信息检索和大模型技术
graph TDA[用户] -->|以提问做查询| B[向量化数据库]C[私有知识] -->|分割、分块、建立索引| D[Embedding]D --> BB -->|提问+检索结果| E[LLM大模型]E -->|RAG回答| Aps:csdn怎么渲染不了流程图语法???
通用LLM使用流程图
知识库LLM使用流程图
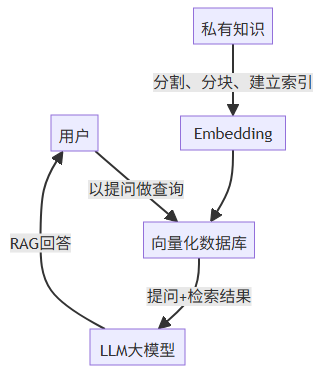
知识库与LLM结合也成了垂直大语言模型、特定领域大模型部署的主要训练手段
应用
应用领域
- 自动驾驶
大模型可以用于自动驾驶中的感知、决策等任务。通过学习大量的驾驶数据,大模型可以实现对车辆周围环境的感知和识别,以及进行决策和控制,提高自动驾驶的安全性和效率 - 医疗健康
大模型可以用于医疗影像诊断、疾病预测等任务。通过学习大量的医学影像数据,大模型可以辅助医生进行疾病诊断和治疗方案制定,提高医疗水平和效率 - 金融风控
大模型可以用于信用评估、欺诈检测等任务。通过分析大量的金融数据,大模型可以评估用户的信用等级和风险水平,以及检测欺诈行为,提高金融系统的安全性和稳定性 - 工业制造
大模型可以用于质量控制、故障诊断等任务。通过学习大量的工业制造数据,大模型可以辅助工程师进行产品质量控制和故障诊断,提高生产效率和产品质量 - 生物信息学
在生物信息学领域,大模型可以用于基因序列分析(识别基因中的功能元件和变异位点)、蛋白质结构预测(推测蛋白质的二级和三级结构)、药物研发(预测分子与靶点的相互作用)等 - 气候研究
在气候研究领域,大模型可以处理气象数据,进行天气预测和气候模拟。它们能够分析复杂的气象现象,提供准确的气象预报,帮助人们做出应对气候变化的决策
Agent
Agent(智能体)是基于大模型(如GPT-5、DeepSeek、Doubao等)构建的自主决策与执行系统,能够理解复杂任务、规划步骤、调用工具并完成目标。
1.核心架构
-
感知层(Perception)
输入理解:解析用户指令(文本、语音、图像等)。
环境感知:获取实时数据(如天气API、股票行情)。
示例:
用户说:“帮我订明天北京飞上海的机票,预算3000元。”
Agent理解:时间(明天)、地点(北京→上海)、约束(预算≤3000元)。 -
认知层(Cognition)
任务拆解:将目标分解为子任务(查航班→比价→下单)。
工具调用:选择API或外部工具(如携程API、支付系统)。
示例:
任务链:搜索航班 → 筛选符合预算的选项 → 预订并支付。 -
执行层(Action)
自动化操作:通过API、RPA(机器人流程自动化)完成任务。
结果验证:检查是否成功(如收到机票确认邮件)。 -
学习层(Learning)
记忆存储:记录历史任务数据(如用户偏好靠窗座位)。
策略优化:通过强化学习(RLHF)改进决策。
2.Agent与Model的训练/推理范式区别
Language Model:输入→输出,过程结束。
Language Agent:感知环境→生成动作→执行→环境反馈→循环。
3.常见Agent分类
Coding Agent:如Cursor、Wind Surf,用于代码生成、调试。
Search Agent:如OpenAI Deep Research,用于信息检索。
To Use Agent:如Kimi K2、ChatGPT Agent,用于网页操作(订机票、预约餐厅等)。
Computer Use Agent:如Operator,用于浏览器自动化操作。
AIGC
AIGC的全称为“Artificial Intelligence Generated Content”
AIGC的核心思想是利用人工智能算法生成具有一定创意和质量的内容。通过训练模型和大量数据的学习,AIGC可以根据输入的条件或指导,生成与之相关的内容。例如,通过输入关键词、描述或样本,AIGC可以生成与之相匹配的文章、图像、音频等。
AIGC与大模型的关系是什么?
- AIGC的生成能力依赖于大模型的计算能力、数据训练和算法优化。
- 大模型(如GPT-5、DeepSeek、Doubao等)与AIGC(人工智能生成内容)是技术实现与应用场景的关系。
- 大模型是AIGC的“大脑”,提供底层AI能力;AIGC是大模型的“手脚”,让技术真正落地应用。
行业应用
1.DeepResearch
相关产品–AI文献综述
- AI学术工具 by 清华大学和北京航空航天大学的研究团队
https://pan.baidu.com/s/1kPrFGhpWuwB2eiGuP33Qjg?pwd=0417 - 元知AI综述工具
https://yuanzhi.zeelin.cn/#/ - 中科院Pub Scholar平台
https://pubscholar.cn/ - 知网研学平台
- 斯坦福STORM
对比:

本质:
以多agent实现从数据采集到可视全流程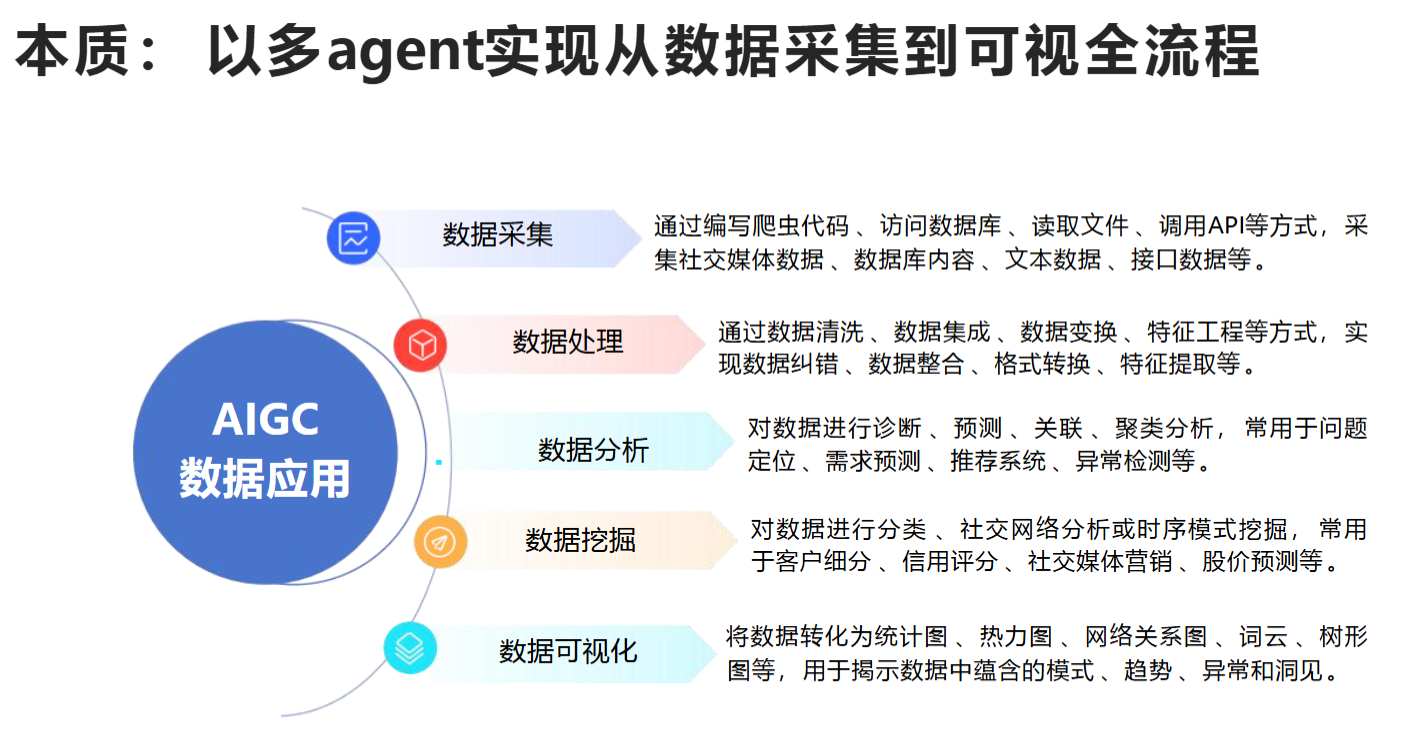
爬虫数据采集:
prompt
你需要完成以下两个任务
1.阅读网页【网址】源代码【对应网页源代码】。提取所有包含“春运2025 |X月X日,全社会跨区域人员流动量完成X万人次”的网址进行去重、筛选,合并成网址列表
2.撰写python脚本,基于步骤1输出的网址列表提取所有网址内容“截至目前 2025 年春运(2025年1月14日到2月8日)相关数据(如日期、全社会跨区域人员流动量、铁路客运量、公路人员流动量、水路客运量、民航客运量等)”完成数据提取并写入文件“2025春运数据.txt’
该实验中不同模块采用不同的LLM(交叉应用,协同互补),结论:
目前DeepSeek R1、Open Al o3mini、Kimi k1.5支持联网査询网址,Claude 3.5 sonnet暂不支持;
四个模型均能根据上传的网页代码,对多个网址链接进行筛选、去重,完全提取出符合指令要求的所有网址链接并形成列表;
在复杂爬虫任务上,DeepSeek R1与Open Al o3min生成的代码均能正常执行数据采集任务,03响应速度更快,R1数据采集结果更加完整准确;其他2个模型都存在多次调试但代码仍然运行不成功的问题,如代码中罗列URL不全、输出文本中提取数据为空等。
2.服务业-客户服务与支持
自动回复客户咨询:电商平台使用DeepSeek自动回答客户关于订单状态、退货政策等问题
自动处理订单、自动处理投诉、情感支持、客户反馈分析…
3.个性化推荐
购物、音乐…
4.教培
辅导、个性化定制学习计划、监考…
5.医疗健康
初诊断、医疗知识库、心理…
6.金融投资
7.内容创作与媒体
prompt
1.学术论文
- 撰写文章标题指令
: 我想让您担任学术期刊编辑,我将向您提供一份手稿摘要,您将向我提供5个好的研究论文英文标题,并解释为什么这个标题是好的。请将输出结果以Markdown 表格的形式提供,表格有两列,标题为中文。第一列给出英文标题,第二列给出中文解释。以下文本为摘要:【指令后加上文章的摘要】
- 改写降重
: 我想让你充当科研写作专家,并提供一些英文或中文段落,你的任务是用原文改写段落。 你应该使用人工智能工具(如自然语言处理) 、修辞知识和你在有效科学写作技巧方面的专业知识来回答。 请只提供改写后的文本,不作任何解释,请用科研语气风格重写下面的文字:
学术前沿
1.大模型安全
重点关注语言模型面临的多维度安全威胁及其防御机制研究进展,涵盖提取攻击、越狱攻击等攻击方式与差分隐私、对抗训练等防御策略。
Kaixiang Zhao等(2023)提出,针对语言模型的提取攻击会威胁知识产权和用户隐私,他们通过系统分类攻击与防御方法并建立专门评估指标,揭示了现有方法的局限性,从而为开发平衡安全性与实用性的自适应防御机制指明了研究方向[1]。Zhiyu Liao等(2023)强调大型语言模型(LLMs)面临的多维度安全威胁(如对抗提示攻击、模型窃取等)与防御策略的局限性,指出动态威胁环境与资源约束导致现有防御体系难以兼顾鲁棒性与可用性,呼吁通过跨学科协作开发可解释、可扩展的标准化防御框架以应对实际应用中的伦理风险[2]。Kevin Kurian等(2023)研究表明,基于强化学习的查询优化方法显著提升了大型语言模型指纹识别攻击的准确性,而通过语义保持输出过滤的防御策略有效降低了模型被识别的风险,这为提升指纹识别工具能力和制定防御策略提供了实践路径[3]。Francisco Aguilera-Martínez等(2023)强调,大型语言模型在训练和部署阶段面临的安全威胁需通过预防性和检测性防御机制进行针对性缓解,这为构建安全框架提供了系统指导,同时也揭示了应对新兴威胁需进一步研究的领域[4]。Xiaohu Li等(2023)提出基于大语言模型中间层嵌入的线性可分特性,通过生成对抗网络学习安全判断边界,使得攻击成功率平均达88.85%、防御成功率平均达84.17%,从而揭示了模型内部安全机制并为增强安全性提供了新思路[5]。Nishit V. Pandya等(2025)表明,基于微调的大语言模型提示注入防御方法在对抗白盒优化攻击时存在严重漏洞,其构建的新型注意力攻击算法对SecAlign和StruQ等防御系统的成功率高达70%,这使得当前依赖指令数据分离的防御策略无法提供声称的安全保障[6]。Shuyang Hao等(2023)提出通过将安全指令嵌入图像(ESIII)的方法,将视觉空间从漏洞来源转变为主动防御机制,使得视觉和文本维度的安全指令协同作用,从而在保持模型正常任务性能的同时显著提升了大型视觉语言模型对抗恶意攻击的鲁棒性[7]。Aysan Esmradi等(2023)研究表明,大型语言模型(LLMs)存在的安全漏洞可能被攻击者利用,这使得开发主动网络安全防御措施成为保障AI模型安全的当务之急[8]。Rui Wen等(2023)研究表明,针对上下文学习(ICL)设计的成员推理攻击仅需生成文本即可实现高达95%的识别准确率,这暴露出ICL的隐私风险显著高于基于概率的攻击,而结合数据、指令和输出的多维度防御措施能有效降低隐私泄露风险[9]。Andrii Balashov等(2023)表明,企业环境中部署的大型语言模型面临多阶段提示推理攻击的安全威胁,攻击者通过看似无害的连续查询逐步提取机密数据,这使得传统单轮提示过滤的防护措施失效,从而凸显了需要采用统计异常检测、细粒度访问控制等纵深防御策略的必要性[10]。Badhan Chandra Das等(2023)研究表明,大型语言模型(LLMs)的系统提示易受精心设计的查询攻击而导致隐私泄露,这促使他们开发了SPE-LLM框架来系统评估攻击风险并提出三种防御技术,从而为安全部署LLMs提供了解决方案[11]。Boyi Deng等(2023)提出一种结合人工与自动方法的集成方案,通过上下文学习指导大语言模型模拟人类攻击提示,并开发防御框架进行对抗性微调,从而有效降低红队攻击风险并提升模型安全性[12]。Neel Jain等(2023)研究表明,大型语言模型现有的离散文本优化器弱点与高昂优化成本相结合,使得标准自适应攻击更具挑战性,这凸显了开发更强大优化器或增强过滤防御的迫切需求[13]。Jing Cui等(2023)强调大型语言模型的安全漏洞和新兴威胁模型可能影响安全评估并造成虚假的安全感,因此通过分析当前攻击向量和防御策略的优缺点,为未来增强模型安全性提出了研究方向[14]。Yihe Zhou等(2023)强调大型语言模型(LLMs)在广泛应用中面临的后门攻击安全威胁,通过系统分类训练阶段白盒后门攻击方法及相应防御策略,为构建更鲁棒的LLMs提供了研究框架和发展方向[15]。Jiawei Zhao等(2023)提出一种即插即用的前缀引导(PG)防御框架,通过直接设置模型输出的前几个标记来识别有害提示,从而有效抵御越狱攻击,同时保持模型性能,解决了现有防御方法效果不足或影响模型能力的问题[16]。Guy Amit等(2023)研究表明,微调大型语言模型会因包含敏感数据而增加隐私风险,但采用差分隐私和低秩适配器相结合的训练方法能显著降低成员推理攻击的威胁[18]。Frank Weizhen Liu等(2023)强调大型语言模型面临的安全漏洞(如提示注入和越狱攻击)会威胁AI系统稳定性,因此需要构建稳健的防御框架来增强其抗攻击能力[19]。Hanrong Zhang等(2024)提出基于大语言模型的智能代理存在严重安全漏洞,其开发的Agent Security Bench框架揭示攻击成功率最高达84.30%,而现有防御措施效果有限,这凸显了智能代理在系统提示、工具使用等环节的安全风险亟待解决[20]。Yupei Liu等(2023)提出一个形式化提示注入攻击的框架,通过系统评估5种攻击方式和10种防御措施,发现现有攻击均是该框架的特例,从而为量化评估未来攻击与防御提供了基准平台[21]。Arijit Ghosh Chowdhury等(2023)强调,大型语言模型面临对抗攻击、数据投毒和隐私泄露等多重安全威胁,这些漏洞不仅损害模型完整性,还严重影响用户信任,亟需开发更强大的防御机制来应对风险[22]。Qin Liu等(2023)提出一种基于集成学习的端到端后门防御框架DPoE,通过浅层模型捕获后门捷径并阻止主模型学习这些特征,使得该方法能有效抵御包括词级、句级和句法触发在内的多种后门攻击,同时其去噪设计解决了后门攻击导致的标签翻转问题[23]。Lin Lu等(2023)提出通过有向无环图系统分析越狱攻击与防御的依赖关系,构建了三个自动化框架,使得集成攻击与混合防御策略的性能显著超越现有方法[24]。Qiusi Zhan等(2023)表明,当前针对大型语言模型间接提示注入攻击的防御措施存在严重漏洞,其自适应攻击测试成功率持续超过50%,这凸显了在设计防御机制时进行自适应攻击评估的必要性,以确保系统的鲁棒性和可靠性[25]。Linbao Li等(2024)提出了一种名为ArrAttack的新型攻击方法,该方法通过自动生成能够绕过多种防御措施的鲁棒越狱提示,使得大型语言模型的安全对齐机制面临更严峻的挑战,从而揭示了当前防御策略的局限性[26]。Xiang Li等(2023)提出通过对抗性提示蒸馏方法,将大型语言模型的越狱能力迁移至小型语言模型,这不仅揭示了模型的脆弱性,还为大型语言模型安全研究提供了新思路[28]。Bocheng Chen等提出一种基于动态解码超参数的移动目标防御方法,通过持续调整语言模型的解码策略和系统提示,使得模型能够在不依赖内部结构或额外训练的情况下有效抵御越狱攻击,同时保持较低的推理成本和响应质量[29]。Iyiola E. Olatunji等(2024)研究表明,大语言模型与图结构数据整合时存在对抗攻击漏洞,其中LLAGA模型的节点序列模板设计增加了其脆弱性,而GRAPHPROMPTER的GNN编码器表现出更强鲁棒性,但两者均易受特征扰动攻击影响,这促使研究者开发出结合特征校正与GNN防御的GALGUARD端到端防护框架[30]。Zhao Xu等(2024)提出JailTrickBench评估框架,通过系统分析越狱攻击的八个关键因素对LLM性能的影响,表明缺乏标准化基准测试会阻碍防御增强型大语言模型的评估,从而强调建立统一评估体系的必要性[31]。Yifan Zeng等(2023)提出一种多智能体防御框架AutoDefense,通过任务分工和协作机制增强语言模型的指令遵循能力,使得开源小模型能够有效防御大语言模型的越狱攻击,将GPT-3.5的攻击成功率从55.74%降至7.95%[32]。Kevin Eykholt等(2023)认为,机器学习领域过于宽松的攻击假设和过于严格的防御威胁模型阻碍了防御技术的发展,这使得针对现实场景的防御措施难以取得实质性进展[33]。Chen Xiong等(2023)提出了一种新型防御性提示补丁(DPP)方法,通过设计可解释的后缀提示有效抵御各类越狱攻击,在保持大语言模型高实用性的同时显著降低攻击成功率,为解决模型安全性与功能性平衡问题提供了可扩展的解决方案[34]。Zhengchun Shang等表明,大型语言模型(LLMs)的广泛使用引发了安全担忧,特别是越狱攻击会绕过安全措施生成有害内容,因此他们通过评估开源和闭源模型的安全性能,探讨了模型版本迭代、规模大小及多防御策略整合对安全性的影响[35]。Yihao Zhang等(2023)提出动量加速梯度攻击(MAC),通过引入动量项优化对抗提示生成过程,显著提升了攻击成功率和优化效率,使得大语言模型在面对对抗攻击时更加脆弱[36]。Sarbartha Banerjee等(2024)强调,复合AI系统中跨层攻击向量的组合会显著降低威胁模型的假设要求,这使得构建全面防御策略成为确保系统安全部署的必要条件[37]。Yulin Chen等(2023)提出通过逆向利用提示注入攻击技术开发新型防御方法,使得模型能够有效忽略注入指令而执行原始输入指令,从而显著提升了防御性能并达到当前最优效果[38]。Yuqi Jia等(2023)表明,现有的大型语言模型提示注入防御措施因缺乏跨攻击有效性和模型通用性的系统评估方法,导致其实际防护效果被高估,这为未来防御策略的开发提供了重要评估框架[39]。Nikolaus Howe等(2023)研究表明,尽管模型规模的增大提升了语言模型的样本效率,但未进行显式安全训练的更大模型并未表现出更强的鲁棒性,同时攻击计算资源的增加会持续提高攻击成功率,这使得未来需通过对抗性训练来平衡攻防关系[40]。Muzhi Dai等(2023)提出Secure Tug-of-War(SecTOW)防御-攻击迭代训练框架,通过强化学习驱动的对抗训练机制动态扩展越狱数据并优化防御模型,使得多模态大语言模型在保持通用性能的同时显著提升安全性[41]。Guang Lin等(2023)提出一种名为LLAMOS的新型防御技术,通过净化对抗性文本样本并采用代理指令和防御引导策略,显著提升大语言模型的对抗鲁棒性,使得模型即使未学习对抗样本也能有效抵御攻击,从而保障语言模型的安全应用[42]。Zhifan Luo等(2024)表明,大型语言模型推理加速中的键值缓存机制虽提升效率,却因存在输入数据重构漏洞而造成严重隐私风险,为此提出的KV-Cloak防御方案通过可逆矩阵混淆技术有效阻截攻击,在保障模型性能的同时实现可靠安全防护[43]。Fenghua Weng等(2023)提出MMJ-Bench评估框架,通过统一标准揭示多模态大语言模型越狱攻击的脆弱性及其防御机制的有效性,为相关研究提供了首个公开基准,并发现现有评估方法的分散性导致不同方法难以直接比较[44]。Erfan Shayegani等(2024)强调,大型语言模型(LLMs)尽管经过安全对齐训练,仍易受对抗性攻击(如文本攻击和多模态攻击)的影响,这会利用模型漏洞误导AI系统,从而凸显了在复杂系统集成背景下加强LLMs安全研究的紧迫性[45]。Zihui Wu等(2024)揭示大语言模型的函数调用功能存在严重安全漏洞,其提出的"越狱函数"攻击方法利用对齐差异和缺乏安全过滤机制,导致六种主流模型的平均攻击成功率超过90%,这一发现凸显了加强AI功能调用安全防护的紧迫性[46]。Rui Ye等(2023)揭示联邦指令调优(FedIT)存在安全漏洞,提出一种自动化攻击方法能够显著降低大语言模型的安全对齐性(降幅达70%),并开发出新型防御机制使安全性能最高提升69%,表明现有联邦学习防御方法对这类攻击最多仅能产生4%的改善效果[47]。Hao Li等(2023)提出了一种名为NotInject的评估数据集和InjecGuard防御模型,研究表明现有提示防护模型因触发词偏见导致过度防御问题,使得准确率降至接近随机猜测水平(60%),而他们提出的MOF训练策略显著降低了触发词偏见,使得InjecGuard在多种基准测试中的性能超越现有最佳模型30.8%[48]。
–>大语言模型与安全攻防.docx
2.攻防
3.安全协议
4.联邦学习
模型汇总
当前大模型有哪些?各自优势是什么?
1. 超长文档(Long Context Handling)
这些模型擅长处理百万级token上下文,适合长文档分析、代码库审查或视频转录。
| 模型名称 | 开发者 | 主要优势 | 区别与比较点 |
|---|---|---|---|
| kimi 1.5 | Moonshot | 200 万字上下文(≈10 M token) | 全球最长 |
| Gemini 2.5 Pro | 上下文窗口超1M token,支持多模态长文档(如视频+文本);高效处理大型数据集和搜索集成。 | 闭源,顶尖上下文长度;区别于Claude:多模态更强,但推理深度稍逊;优于Llama在视频处理。 | |
| Claude 4 Sonnet | Anthropic | 200K+ token上下文,强调安全长链推理;适合复杂文档重构和减少幻觉。 | 闭源,平衡速度与准确;区别于Gemini:更可靠于企业文档,但上下文短;优于DeepSeek在安全机制。 |
| Llama 4 Scout | Meta | 开源,256K+ token上下文;灵活部署,长文档总结和多语言支持。 | 开源,便于微调;区别于Gemini:成本低,但多模态弱;优于Falcon在社区支持。 |
| DeepSeek R1 | DeepSeek | 128K+ token,MoE架构高效;专注长形式内容生成和推理。 | 开源,低成本;区别于Claude:更专注效率,但安全弱;优于Magic LTM在数学文档。 |
| Magic LTM-2 | Magic | 超长上下文(具体未公开,但领先基准);适合大规模文档QA。 | 闭源,新兴;区别于Llama:更创新,但成熟度低。 |
| Falcon | TII | 开源,长文档稳定性和量化支持;适合规模化总结。 | 开源,速度快;区别于Gemini:更轻量,但上下文短。 |
2. Coding 神器
这些模型在代码生成、调试和算法任务上领先,常集成到Copilot或Cursor。
| 模型名称 | 开发者 | 主要优势 | 区别与比较点 |
|---|---|---|---|
| Claude 4 Opus | Anthropic | 复杂代码重构、多步调试顶尖;理解大型代码库,减少错误。 | 闭源,HumanEval~90%+;区别于Gemini:更可靠推理,但速度慢;优于GPT在安全编码。 |
| Gemini 2.5 Pro | 算法和竞争编程领先,多模态代码分析(如截图);上下文长达1M+。 | 闭源,顶尖基准;区别于Claude:更快响应,多模态强;优于DeepSeek在搜索集成。 | |
| GPT-4o / o3 | OpenAI | 通用代码生成、解释和快速原型;Chain-of-Thought提升准确。 | 闭源,Pass@1~80-90%;区别于Gemini:更注重自然语言混合,但成本高;优于GLM在全球基准。 |
| DeepSeek R1/V3 | DeepSeek | 编码专用,MoE高效;低成本,开源微调。 | 开源,HumanEval~95%;区别于Claude:更专注算法,但通用弱;优于Claude 3.7在成本。 |
| Claude 3.7 Sonnet | Anthropic | 实世界任务优化,非LeetCode式编码;结构化输出。 | 闭源,平衡实用;区别于GPT:更注重任务,但基准稍低。 |
| GLM-4-32B | Zhipu AI | 本地编码强,开源;适合小型团队部署。 | 开源,高效本地;区别于Gemini:更轻量,但上下文短。 |
3. 科学计算(Scientific Computing)
这些模型在数学、物理、材料科学等推理和计算上突出,可辅助工具调用(如Wolfram Alpha)。
| 模型名称 | 开发者 | 主要优势 | 区别与比较点 |
|---|---|---|---|
| Qwen Math 2.5 | Alibaba | 数学专用,匹配GPT-4o水平;多语言计算支持。 | 开源,GSM8K~90%+;区别于o1:更专注数学,但通用弱;优于Mathstral在多语。 |
| DeepSeek R1 | DeepSeek | 推理和数学顶尖,MoE高效;适合物理模拟。 | 开源,低成本;区别于Qwen:更广科学领域,但中文偏好;优于Llama在基准。 |
| OpenAI o1 | OpenAI | 高级推理,Chain-of-Thought;物理和材料科学强。 | 闭源,顶尖问题解决;区别于DeepSeek:更通用,但需工具辅助算术;优于Claude在复杂计算。 |
| Mathstral 7B | Mistral | 数学和逻辑领先,开源轻量;快速部署。 | 开源,高效;区别于o1:更小规模,但成本低;优于Llama在纯数学。 |
| Llama 3.1 70B | Meta | 科学问题解决,CURIE基准强;开源微调。 | 开源,平衡;区别于Qwen:更全球,但数学稍逊。 |
| Claude 4 | Anthropic | 科学可视化和推理;ChatVis集成提升。 | 闭源,安全强;区别于DeepSeek:更注重可视,但计算深度逊。 |
4. 中文本土
这些模型由中国开发者主导,中文处理和本土应用领先,支持多语但偏好中文。
| 模型名称 | 开发者 | 主要优势 | 区别与比较点 |
|---|---|---|---|
| Qwen3 | Alibaba | 超100语言支持,中文顶尖;数学和编码强。 | 开源,235B参数;区别于DeepSeek:更通用中文,但成本高;优于Ernie在开源。 |
| DeepSeek V3 | DeepSeek | 开源高效,中文推理和编码领先;低成本。 | 开源,MoE架构;区别于Qwen:更专注效率,但多语弱;优于Kimi在基准。 |
| GLM-4 | Zhipu AI | 中文对话和代理推理顶尖;本地部署强。 | 开源,32B-70B;区别于Qwen:更轻量代理,但通用逊;优于ChatGLM在更新。 |
| Kimi | Moonshot AI | 中文长上下文和搜索集成;用户友好。 | 闭源,本土优化;区别于DeepSeek:更注重搜索, |
| Ernie Bot 4.0 | Baidu | 中文生成和多模态;企业级应用。 | 闭源,集成Baidu生态;区别于GLM:更商业,但灵活低。 |
| ChatGLM | Zhipu AI | 开源中文对话;适合聊天和内容生成。 | 开源,便宜;区别于Qwen:更专注对话,但推理逊。 |
总体总结:超长文档类以Gemini/Claude为主导;Coding以Claude/Gemini领先;科学计算偏向Qwen/DeepSeek;中文本土以Qwen/DeepSeek为代表。中国模型(如Qwen)常跨类(如Coding和科学)。参考LMSYS或Hugging Face leaderboard获取最新更新。
Reference
[1] DeepSeek大型模型及其商业应用实践. (n.d.). Retrieved from https://10ms.edu.cn/res/deepseek/ref/REF-XMU-003-DeepSeek%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E4%BC%81%E4%B8%9A%E5%BA%94%E7%94%A8%E5%AE%9E%E8%B7%B5.pdf
[2] (张小珺商业访谈录, 2025). 逐段讲解Kimi K2报告并对照ChatGPT Agent、Qwen3-Coder等:“系统工程的力量” [影片]. bilibili. https://www.bilibili.com/video/BV1cc8kzmEBs
[3] DeepSeek+DeepResearch:让科研像聊天一样简单. https://io.neepu.edu.cn/info/1133/4663.htm
[4] kimi k2. KIMI K2:OPEN AGENTIC INTELLIGENCE. https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
[5] https://lmarena.ai/leaderboard