自动驾驶感知——BEV感知(学习笔记)
1.BEV好处
BEV感知由于其固有的优势,提供直观的世界表现 和 利于数据融合 的形式,而引起了工业界和学术界的极大兴趣。
a.将 不同视角在 BEV 下统一与表征 是很自然的描述,包含了丰富的语义信息、精确的定位和绝对尺度。方便后续规划控制模块任务;
b.BEV 下的物体 没有图像视角下的尺度和遮挡问题,且非常适合融合,如:不同模态(lidar、图像),不同视角(环视图),不同时间维度(时序融合),不同代理任务(分割检测一体化)。BEV表示在合并来自多个来源的不同信息方面起着至关重要的作用。
2.BEV算法分类
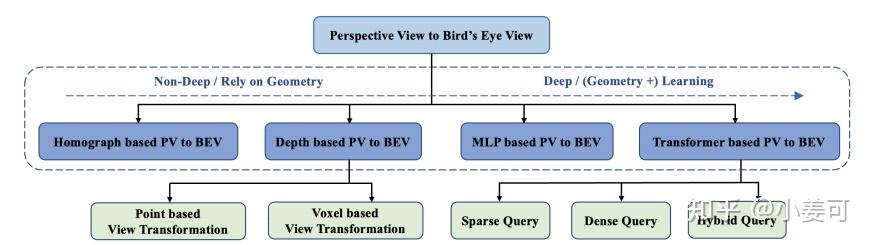
BEV算法分类
a.几何方法:(非深度学习)
对于低成本的自动驾驶系统,以视觉为中心的BEV感知是一个长期的挑战,因为摄像头通常放置在自车上,与地面平行,面向外部。图像在与BEV正交的透视图(PV)中获取,并且两个视图之间的变换是不适定问题。最早的工作用 单应矩阵 以物理和数学方式将平坦地面从PV转换为BEV。多年来,这种方法一直占据主导地位,直到 刚性平地硬约束 无法满足复杂真实场景的自主驾驶要求。
b.基于深度的方法:(深度学习)
就是先对每一个 2d 像素预测一个Z值,然后就直接利用 内参矩阵 进行转换得到 3d 坐标。然后再降维得到 BEV 即可。
c.基于MLP的方法:(深度学习)
一种简单的方法是利用 MLP 来将 PV 特征投射到 BEV 。基于MLP的方法实现起来很简单,但在具有遮挡和多视图输入设置的复杂场景中难以泛化。
基于深度和MLP的方法都是正向方式进行转换,就是自下而上,这里理解就是由2d到3d。
d.基于Transformer的方法:(深度学习)
采用自上而下的方式,直接构建BEV查询,并使用 交叉注意机制在透视图像中搜索相应的特征。
3.基于几何的方法
空间中的点可以通过透视映射转换到图像空间,而将图像像素投影到三维空间的逆问题是无法确定的。逆透视映射(Inverse Perspective Mapping, IPM)是在 基于额外约束条件(逆映射的点位于水平平面上,IPM严重依赖于平坦地面假设)下提出的解决数学上不可能的映射问题的方法,这是将前视图图像扭曲为鸟瞰图像的先驱性工作。该变换应用了相机旋转单应性和各向异性缩放。单应矩阵可以由相机的内参和外参物理推导出来。
前置知识:单应矩阵讲解:从零开始一起学习SLAM | 神奇的单应矩阵 - 知乎 (zhihu.com)
单应矩阵描述的就是 同一个平面的点在不同图像之间的映射 关系
关于如何获取bev,传统方法是进行逆透视变换(IPM),即 通过多相机的内外参标定,求得相机平面到地平面的单应性矩阵,实现平面到平面的转换,再进行多视角图像的拼接。
IPM相关的技术已比较成熟,并广泛运用在 自动泊车(自我理解因为比较近)等场景中,但也有不小的局限性,比如同样依赖于 标定的准确性且内外参必须固定 ,而且从原理上说,IPM只能表征地平面的信息,有一定高度的目标都会在图片上产生畸变,所以同样需要假设地面平坦、目标接地,这就意味着难以应用在 较远距离 的感知任务中。
这种方法依赖很多假设和先验知识:
假设1:地面平坦,没有起伏和坑洞
假设2:目标接地,且可以看到接地点
先验1:目标的实际高度(或宽度,可以通过分类的方式与经验平均值回归得到),或照相机高度
先验2:相机的焦距
满足了以上假设并且已知相关先验,即可通过2D检测的结果,经过相似三角形关系,估算目标大致深度(深度Z=H *f / h),再通过内参转换,估算出3D box的位置。
一些方法使用卷积神经网络提取透视图图像的语义特征,并估计图像中的垂直消失点和地平线(地平面消失线)来确定单应性矩阵。
总结:基于几何方法主要基于PV和BEV之间 地面平坦 的物理映射,具有良好的可解释性。IPM在下游感知任务的图像投影或特征投影中起作用。为了减少地平面以上区域的失真,充分探索了语义信息,并广泛使用GAN来提高BEV特征的质量。核心映射过程通过矩阵乘法简单明了,无需学习,是一种高效的选择。但由于从PV到BEV的实际转换是不适定的,IPM的硬假设解决了部分问题。PV整个特征图的有效BEV映射仍有待解决。
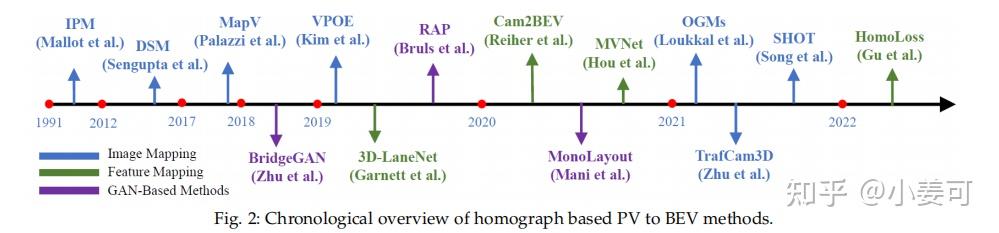
几何方法
4.基于深度的方法
基于逆透视映射的方法建立在 所有点位于地面上 的假设上。这提供了一个可行的路径来连接2D透视空间和3D空间的鸟瞰视图,但 牺牲了重要的高度区分能力 。为了避免这个问题,深度是将2D像素或特征提升到3D空间所必需的。基于这一观点,PV-BEV转换的一种重要方法类型是基于深度预测来实现的。与基于激光雷达的3D检测一样,基于所使用的表示,这些方法可以分为两种类型:基于点的方法和基于体素的方法。
a.基于点的视图转换
基于点的方法 直接利用深度估计将像素转换为点云,并分布在连续的3D空间中 。它们更直观,更容易整合单目深度估计和基于LiDAR的3D检测的成熟经验。
开创性的工作Pseudo-LiDAR 首先将深度图转换为伪LiDAR点,然后将其输入到最先进的基于LiDAR的3D检测器中 。进一步的工作Pseudo-LiDAR++通过使用立体深度估计网络和损失函数提高了深度的准确性。AM3D提出使用补充的RGB特征来装饰伪点云。PatchNet 分析了深度图和3D坐标之间的差异,并提出将3D坐标作为额外的输入数据通道来实现类似的结果。
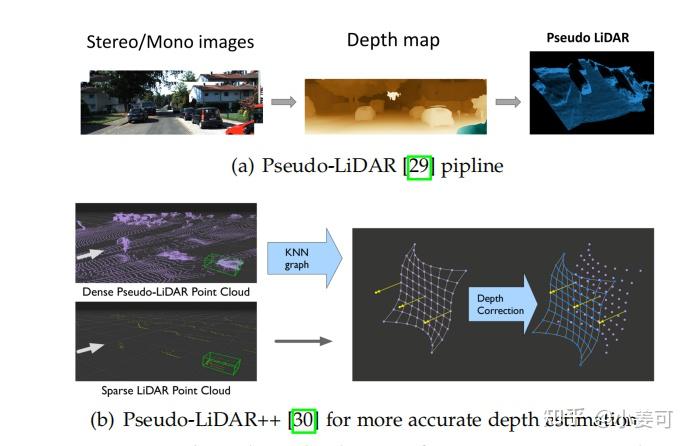
问题:
1)数据泄漏问题。错误地使用来自深度估计的KITTI深度估计基准深度估计的数据,导致数据泄漏到下游三维检测评估,导致此类方法在验证集上的非正常高性能。
2)该流程由于 两个阶段(伪标签生成和3D检测)的梯度截断 ,在训练和部署过程中可能变得复杂,不能端到端调优。
3)生成的伪激光雷达通常是不准确的,因此具有误导性。它也比真实的激光雷达点密度更大,给三维检测阶段带来了 很大的计算负担。
b.基于体素的视图变换
另一种范式明确地预测了深度分布,并使用它来仔细地构建三维特征。
LSS 是早期的比较直接的尝试,即 先估计每个像素(实际上并不是用 原图像素 进行Lift操作,而是用经过backbone提取特征且下采样的特征点,论文中为了让读者容易想象,形象地把它称为体素,其实就是图像特征点)的深度,再通过内外参投影到bev空间。只是 因为不存在深度标签,这里并没有直接回归深度值,而是对每个像素点预测一系列的离散深度值的概率(文中是1-50m),概率最大的深度值即为估计结果 。如下图所示:
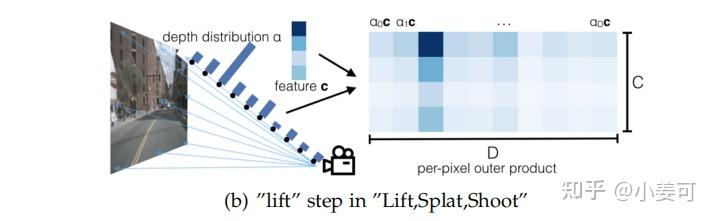
Lift
此时我们可以得到深度分布特征α和图像特征c,将二者做外积,可以得到一个视锥特征(frustum-shaped point cloud),如下图所示(因为近大远小的特点)。这一步作者称为 lift 。
其中的BEV网格尺寸大小:
- 感知范围 x轴方向的感知范围 -50m ~ 50m;y轴方向的感知范围 -50m ~ 50m;z轴方向的感知范围 -10m ~ 10m;
- BEV单元格大小 x轴方向的单位长度 0.5m;y轴方向的单位长度 0.5m;z轴方向的单位长度 20m;
- BEV的网格尺寸 200 x 200 x 1;
- 深度估计范围 由于LSS需要显式估计像素的离散深度,论文给出的范围是 4m ~ 45m,间隔为1m,也就是算法会估计41个离散深度;
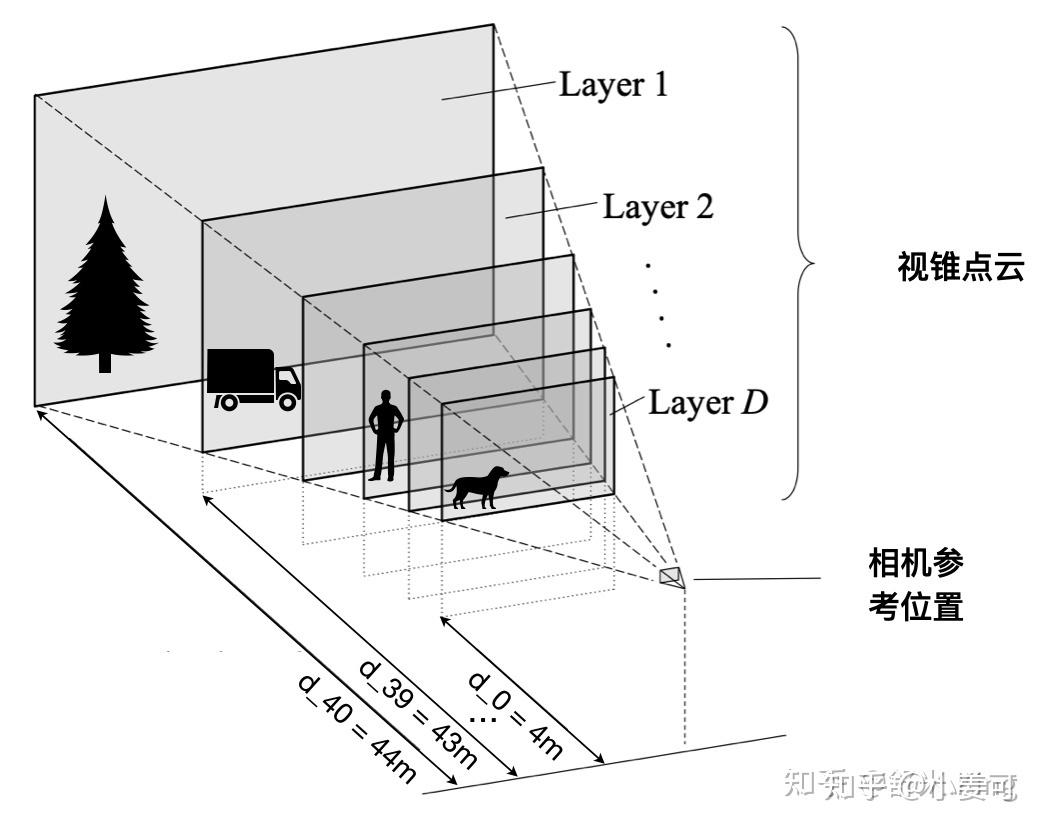
借鉴其他博主的图,非常清晰
2.基于深度估计的方法
5.基于MLP的方法
多层感知器(MLP)通常被认为是一个 复杂的映射函数 ,倾向于利用MLP来学习相机校准的隐式表示,从而在PV和BEV之间进行转换,(纯纯诠释MLP无所不能学)。
简单点理解就是直接忽视任何几何信息,直接从图像透视图 WH----> 200*200BEV 空间,具体的不一定映射到200*200,比如多视图,前视图覆盖前100*200即可,需要后处理累加特征,性能没有 Transformer 的好。
我也准备了一个可以帮你三个月入门到深度学习的籽料包:
【1.超详细的人工智能学习大纲】:一个月精心整理,快速理清学习思路!
【2.基础知识】:Python基础+高数基础
【3.机器学习入门】:机器学习经典算法详解
【4.深度学习入门】:神经网络基础(CNN+RNN+GAN)
【5.项目实战合集】:34个机器学习+36深度学习项目实战
可以关住我的公//粽//呺【迪哥谈AI】回复333 无偿获取!

6.基于Transformer的方法
Transformer 和 MLP方法的不同之处:
首先,由于训练的参数矩阵网络在推理过程中是固定的,因此 MLP学习到的映射不依赖于数据 ;相反,变压器中的交叉注意是 依赖于数据 的,即训练的参数矩阵网络依赖于输入数据。这个数据依赖性属性使转换器更具表现性,但难以训练。
其次,交叉注意是排列不变的,这意味着transformer 需要位置编码 来区分输入的顺序;MLP自然对排列 很敏感。
最后,MLP自下而上,而基于 Transformer 的方法采用了自上而下的策略,通过注意力机制构造查询和搜索相应的图像特征。