11、Informer论文笔记
Informer论文笔记
- 1、汇总
- 一、研究背景与挑战
- 二、Informer模型的核心创新
- 三、实验验证与结果分析
- 四、结论与展望
- 五、关键数据对比
- 2、O(1)和L二次方 (复杂度)
- 1. **O(1)(常数时间复杂度)**
- 2. **L 二次方(O(L²),平方级时间/内存复杂度)**
- 3.自注意力机制中的L二次方计算(v点积)
- 3、ProbSparse注意力
- 1. Top_u个Qi(u = c · ln LQ)和随机采样key个数(U = LK ln LQ )
- 2.论文中解释
- 4、模型结构
- 1.整体结构
- 2.编码器:
- 1.编码图说明
- 2.冗余的 V 组合
- **1. 原因:ProbSparse 自注意力的稀疏性**
- **2. 结果:编码器特征图的冗余性**
- **3. 解决方案:自注意力蒸馏操作**
- **4. 意义**
- **总结**
- 3.输入表示
- 3.解码器:
- **1. 解码器的输入结构**
- **2. 解码器的核心结构**
- **3. 生成式解码器**
- **4. 生成式解码的优势**
- **总结**
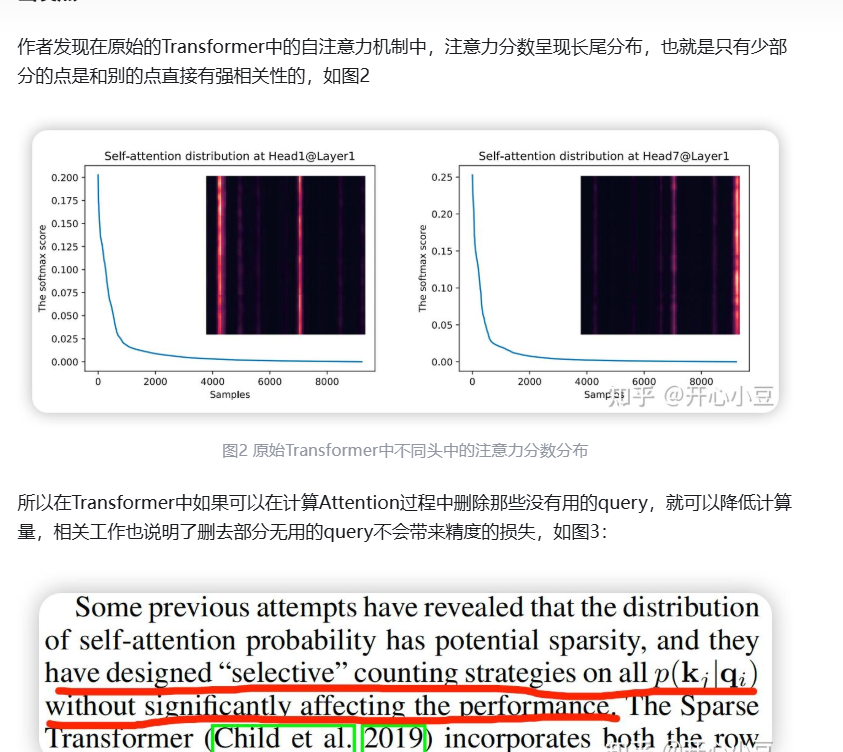
- 5、图/表解释
- 图1
- (a) 序列预测图
- (b) LSTM 性能图
- 6、模型蒸馏(distilling)
- 1. **模型蒸馏(Distillation)**
- 2. **剪枝(Pruning)**
- 3. **量化(Quantization)**
- 总结
- 猜测
- 总结
- 汇总1
- 研究背景
- 主要贡献
- 方法论
- 实验结果
- 结论
- 汇总2
- 详细总结
- 关键问题
- 汇总3(√)
- 一、研究背景与挑战
- 二、Informer模型的核心创新
- 三、实验验证与结果分析
- 四、结论与展望
- 五、关键数据对比
- 汇总4
- 1. 一段话总结
- 2. 思维导图
- 3. 详细总结
- **研究背景**
- **方法创新**
- **实验设计**
- **结果分析**
- 4. 关键问题
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series ForecastingInformer:超越高效 Transformer 的长序列时间序列预测
论文连接:https://arxiv.org/abs/2012.07436
Official Code:https://github.com/WenjieDu/PyPOTS
https://github.com/zhouhaoyi/Informer2020
https://hugging-face.cn/docs/transformers/model_doc/informer
model,https://huggingface.co/papers/2012.07436
代码笔记:https://editor.csdn.net/md?articleId=150503668
1、汇总
参考:https://hugging-face.cn/docs/transformers/model_doc/informer
论文摘要如下:
许多实际应用需要预测长序列时间序列,例如电力消耗规划。长序列时间序列预测 (LSTF) 要求模型具有高预测能力,即有效捕捉输出和输入之间精确的长距离依赖耦合的能力。最近的研究表明,Transformer 有潜力提高预测能力。然而,Transformer 存在一些严重问题,使其无法直接应用于 LSTF,包括二次时间复杂度、高内存使用量以及编码器-解码器架构的固有局限性。为了解决这些问题,我们设计了一个高效的基于 Transformer 的 LSTF 模型,名为 Informer,它具有三个独特的特性:(i) ProbSparse 自注意力机制,实现了 O(L logL) 的时间复杂度和内存使用,并且在序列依赖对齐方面具有可比的性能。(ii) 自注意力蒸馏通过将级联层输入减半来突出主导注意力,并有效处理超长输入序列。(iii) 生成式解码器,概念上很简单,它通过一次正向操作而不是逐步预测长序列时间序列,这大大提高了长序列预测的推理速度。在四个大规模数据集上进行的大量实验表明,Informer 显著优于现有方法,并为 LSTF 问题提供了新的解决方案。
一、研究背景与挑战
-
长序列时间序列预测(LSTF)的需求
- 许多实际应用(如电力消耗规划、气候监测)需要预测数百甚至数千时间步的序列,但现有方法(如LSTM)在预测长度超过48点时性能显著下降(MSE上升、推理速度骤降)。
- LSTF的核心挑战在于提升模型的预测能力,即高效捕捉输入与输出之间的长距离依赖关系,并处理超长序列的计算效率问题。
-
传统Transformer的局限性
- 二次复杂度:自注意力机制的时间和内存复杂度为O(L2)O(L^2)O(L2),无法处理长序列。
- 内存瓶颈:堆叠J层编码器/解码器导致总内存复杂度为O(J⋅L2)O(J \cdot L^2)O(J⋅L2)。
- 动态解码低效:传统Transformer的逐步推理方式导致推理速度与RNN相当。
- LSTF挑战:需同时满足长距离依赖建模和高效计算,传统模型(如LSTM)在预测长度超过48点时性能急剧下降(MSE上升,推理速度骤降)。
- Transformer的局限性:
- 二次时间复杂度(O(L²))
- 内存瓶颈(层叠加导致O(J·L²))
- 动态解码导致推理速度慢
二、Informer模型的核心创新
-
ProbSparse自注意力机制
- 稀疏性发现:通过Kullback-Leibler散度测量查询的稀疏性,发现仅少数查询对主导注意力有贡献。
- 高效计算:每个查询仅关注u=c⋅lnLu = c \cdot \ln Lu=c⋅lnL个主导键,将时间和内存复杂度降至O(LlogL)O(L \log L)O(LlogL)。
- 鲁棒性:多头独立采样不同稀疏查询键对,避免信息丢失。
-
自注意力蒸馏操作
- 维度压缩:通过卷积、激活函数和最大池化,将每层输入的时间维度减半,总空间复杂度降至O((2−ϵ)LlogL)O((2-\epsilon) L \log L)O((2−ϵ)LlogL)。
- 金字塔结构:通过主栈与子栈的组合,增强模型对长序列的鲁棒性。
-
生成式解码器
- 单次前向预测:输入包含起始令牌和零填充目标序列,通过掩码自注意力一次生成完整输出,避免动态解码的累积误差和时间消耗。
三、实验验证与结果分析
-
数据集与基线方法
- 数据集:包括ETT(电力变压器温度)、ECL(电力消耗)、Weather(气象)等4个大规模数据集,涵盖单变量和多变量场景。
- 基线:对比ARIMA、Prophet、LSTM、DeepAR等传统方法,以及Transformer变体(如Reformer、LogTrans)。
-
关键实验结果
- 单变量预测:Informer在所有数据集上均显著优于基线,例如在ETTh1数据集的720点预测中,MSE比LSTM降低60.1%。
- 多变量预测:Informer通过调整全连接层轻松扩展至多变量任务,在ETTh2数据集的720点预测中,MSE比LSTnet降低34.3%。
- 效率验证:Informer的训练时间仅为传统Transformer的1/3,推理速度提升10倍以上。
-
消融研究
- ProbSparse的必要性:在极端长输入(如1440点)下,Informer仍能保持稳定性能,而LogTrans因内存问题无法运行。
- 蒸馏操作的有效性:去除蒸馏后,模型在输入长度超过720时出现内存不足(OOM)。
- 生成式解码优势:动态解码在预测偏移时性能迅速下降,而生成式解码保持稳定。
四、结论与展望
-
核心贡献
- 提出ProbSparse自注意力机制和蒸馏操作,突破Transformer的效率瓶颈,实现长序列的高效处理。
- 设计生成式解码器,解决动态解码的低效问题,为LSTF提供新范式。
-
应用价值
- 在电力、气象等领域的长序列预测中具有实用价值,例如在ECL数据集的960点预测中,MSE仅为0.582。
- 开源代码推动了时间序列预测领域的研究(https://github.com/zhouhaoyi/Informer2020)。
-
未来方向
- 探索多变量预测中各维度的非均匀性影响。
- 结合领域知识(如节假日、事件)优化输入表示。
五、关键数据对比
| 数据集 | 预测长度 | Informer (MSE/MAE) | LSTM (MSE/MAE) | 性能提升 |
|---|---|---|---|---|
| ETTh1 | 168 | 0.183/0.346 | 0.236/0.392 | MSE↓26.8% |
| ECL | 960 | 0.582/0.608 | 1.545/1.006 | MSE↓62.3% |
| Weather | 720 | 0.359/0.466 | 0.866/0.809 | MSE↓58.5% |
| 推理速度 | 720 | 0.422秒/样本 | 4.3秒/样本 | 速度↑9.2倍 |
(注:表格数据基于文档中的实验结果整理,具体数值详见原文表1、表2和表4)
2、O(1)和L二次方 (复杂度)

1. O(1)(常数时间复杂度)
- 定义:表示算法执行时间或操作次数与输入数据规模无关,始终为固定常数。无论输入量是大是小,完成操作的时间或步骤数不变。
- 举例:从数组中通过索引直接访问某个元素(如
array[i]),无论数组长度多长,访问操作的时间几乎恒定,这就是典型的 O(1) 复杂度操作。 - 在原文中的意义:Transformer 的自注意力机制理论上能将网络信号传播路径的最大长度压缩到 O(1),意味着模型捕捉长距离依赖时,无需像 RNN 那样逐步递归(耗时随序列长度增长),从信号传递效率上具备优势。
2. L 二次方(O(L²),平方级时间/内存复杂度)
- 定义:L 代表输入序列的长度,O(L²) 表示算法的计算量或内存消耗量随输入长度的平方增长。当 L 增大时,复杂度会急剧上升。
- 举例:双重循环遍历二维数组,外层循环和内层循环均执行 L 次,总操作次数为 L×L = L²,即 O(L²) 复杂度。
- 在原文中的意义:Transformer 的自注意力机制计算每个元素与其他所有元素的关联,若输入序列长度为 L,计算量和内存消耗均达到 O(L²)。这使得处理长序列(L 很大)时,计算成本和内存占用极高,无法满足长序列时间序列预测(LSTF)对高效处理长输入/输出的需求,成为应用瓶颈。
在文中提到的“L二次方”是指与序列长度L相关的二次复杂度问题,这主要涉及到Transformer模型中的自注意力机制。为了更好地理解L二次方的计算,下面我将通过一个具体的例子来说明。
自注意力的二次计算特性:
这句话阐述自注意力机制因核心操作产生的复杂度问题。具体而言:
- 原子操作(标准点积):自注意力的基础计算是查询(Query)与键(Key)的点积。对于长度为 ( L ) 的输入序列,每个查询向量都要与所有 ( L ) 个键向量计算点积。
- 复杂度推导:
- 时间复杂度:每个查询需 ( L ) 次点积操作,( L ) 个查询共 ( L \times L = L^{2} ) 次操作,因此每层时间复杂度为 ( O(L^{2}) )。
- 内存使用:计算过程中需保存所有查询与键的中间结果,存储量随 ( L^{2} ) 增长,故内存使用也为 ( O(L^{2}) )。这种二次增长特性使得自注意力在处理长序列(( L ) 较大)时,计算和内存成本急剧增加,成为其处理长序列任务的主要瓶颈。
3.自注意力机制中的L二次方计算(v点积)
在Transformer模型中,自注意力机制的计算复杂度是O(L²),其中L是序列的长度。这是因为自注意力机制需要计算每个位置与其他所有位置之间的注意力分数。
假设我们有一个长度为L的序列,每个位置的向量维度为d。自注意力机制的计算步骤如下:
-
计算查询向量(Q)、键向量(K)和值向量(V):
- 查询向量Q是输入序列与查询权重矩阵WQ相乘的结果。
- 键向量K是输入序列与键权重矩阵WK相乘的结果。
- 值向量V是输入序列与值权重矩阵WV相乘的结果。
- 这三个矩阵的维度都是L×d。
-
计算注意力分数:
- 注意力分数是通过计算查询向量Q和键向量K之间的点积得到的,然后除以d的平方根。
- 这个步骤需要计算L×L个注意力分数,因为每个查询向量都要与所有键向量进行点积计算。
-
应用Softmax函数:
- 将计算得到的注意力分数应用Softmax函数,得到注意力权重。
-
加权求和:(点积)
- 使用注意力权重对值向量V进行加权求和,得到最终的输出。
具体例子
假设我们有一个长度为4的序列,每个位置的向量维度为3。输入序列表示为X = [x1, x2, x3, x4],其中每个xi是一个3维向量。
-
计算Q、K、V:
- Q = X × WQ
- K = X × WK
- V = X × WV
- 假设WQ、WK、WV是3×3的权重矩阵,那么Q、K、V的维度都是4×3。
-
计算注意力分数:
- 注意力分数矩阵A的计算公式为:A = Q × Kᵀ / √d
- 其中,Kᵀ是键向量矩阵的转置,d是向量的维度(这里是3)。
- 计算得到的A是一个4×4的矩阵,每个元素表示两个位置之间的注意力分数。
-
应用Softmax函数:
- 对A的每一行应用Softmax函数,得到注意力权重矩阵。
-
加权求和:
- 使用注意力权重矩阵对V进行加权求和,得到最终的输出。
在这个例子中,计算注意力分数矩阵A需要进行4×4=16次点积运算,这就是O(L²)的计算复杂度的来源。当序列长度L增加时,计算量会以二次方的速度增长。
总结
通过这个例子,我们可以看到,自注意力机制的计算复杂度是O(L²),因为它需要计算L×L个注意力分数。这种二次复杂度在处理长序列时会导致计算成本和内存使用量的急剧增加,因此需要通过优化方法(如ProbSparse自注意力机制)来降低复杂度。
3、ProbSparse注意力
1. Top_u个Qi(u = c · ln LQ)和随机采样key个数(U = LK ln LQ )
参考:
https://mp.weixin.qq.com/s/OA9P0dW-Xm4iT5j6qk6KuQ
https://zhuanlan.zhihu.com/p/646853438
https://www.bilibili.com/video/BV17a97YWEzp/?
Top_u个Qi(u = c · ln LQ)和随机采样key个数(U = LK ln LQ )




2.论文中解释
随机抽样:在长尾分布下,我们只需要随机抽样 U=LKU=L_{K}U=LK ln LQL_{Q}LQ 点积对,计算出 Mˉ(qi,K)\bar{M}(q_{i}, K)Mˉ(qi,K) ,即用零填充其他对。然后,我们从中选择稀疏 Top- u 作为 Q‾\overline{Q}Q 。
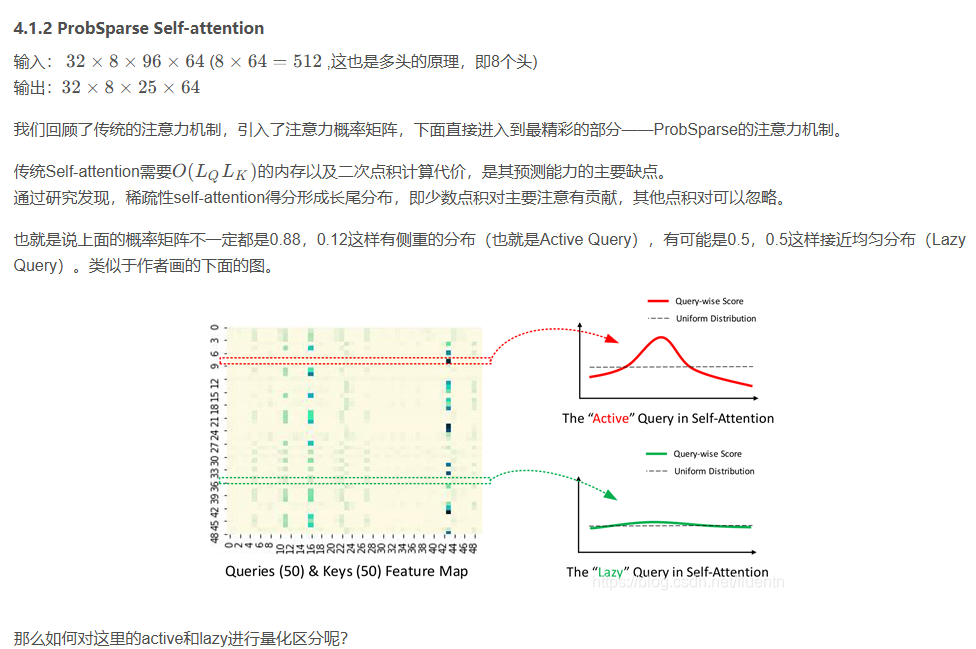


在代码的默认参数中U使25。参考:https://blog.csdn.net/fluentn/article/details/115392229
那么这里的25个queries就是作者认为相对远离均匀分布,也就是不那么lazy的分布。
-
qiq_{i}qi行的概率近似计算
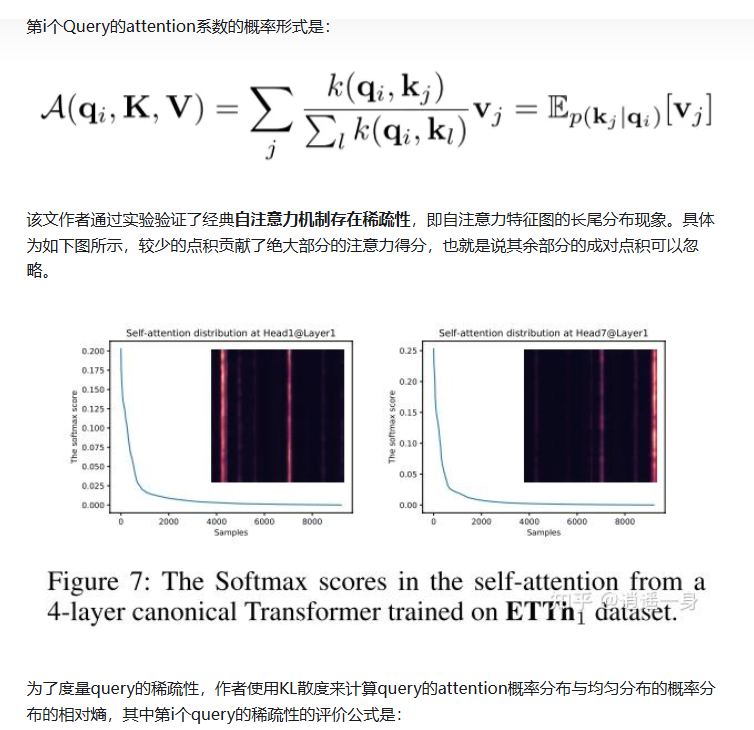
(Vaswani et al. 2017)中的规范自注意力是根据元组输入定义的,即查询、键和值,它执行缩放的点积为 A(Q,K,V)=A(Q, K, V)=A(Q,K,V)= Softmax (QK⊤/d)V(Q K^{\top} / \sqrt{d}) V(QK⊤/d)V ,其中 Q∈RLQ×dQ \in \mathbb{R}^{L_{Q} ×d}Q∈RLQ×d , K∈RLK×dK \in \mathbb{R}^{L_{K} ×d}K∈RLK×d , V∈RLV×dV \in \mathbb{R}^{L_{V} ×d}V∈RLV×d ,d 是输入维度。为了进一步讨论自我注意机制,设 qiq_{i}qi 、 kik_{i}ki 、 viv_{i}vi 分别代表 Q、K、V 中的第 i 行。按照 (Tsai et al. 2019) 中的公式,第 i 个查询的注意力被定义为概率形式的核平滑器:
A(qi,K,V)=∑jk(qi,kj)∑lk(qi,kl)vj=Ep(kj∣qi)[vj],(1)\mathcal{A}\left(q_{i}, K, V\right)=\sum_{j} \frac{k\left(q_{i}, k_{j}\right)}{\sum_{l} k\left(q_{i}, k_{l}\right)} v_{j}=\mathbb{E}_{p\left(k_{j} | q_{i}\right)}\left[v_{j}\right], \quad(1) A(qi,K,V)=j∑∑lk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj],(1)
其中 p(kj∣qi)=k(qi,kj)/∑lk(qi,kl)p(k_{j} | q_{i})=k(q_{i}, k_{j}) / \sum_{l} k(q_{i}, k_{l})p(kj∣qi)=k(qi,kj)/∑lk(qi,kl) 和 k(qi,kj)k(q_{i}, k_{j})k(qi,kj) 选择非对称指数内核 exp(qikj⊤/d)\exp (q_{i} k_{j}^{\top} / \sqrt{d})exp(qikj⊤/d) 。自我注意组合值并根据计算概率 p(kj∣qi)p(k_{j} | q_{i})p(kj∣qi) 来获取输出。需要二次乘以点积计算和 O(LQLK)O(L_{Q} L_{K})O(LQLK) 内存占用,是提升预测能力时的主要缺点。
查询稀疏性测量 从方程(1)中,第 i 个查询对所有键的关注被定义为概率p(kj∣qi)p(k_{j} | q_{i})p(kj∣qi),输出是其值 v 的组合。占主导地位的点积对鼓励相应查询的注意力概率分布远离均匀分布。如果 p(kj∣qi)p(k_{j} | q_{i})p(kj∣qi) 接近均匀分布 q(kj∣qi)=1/LKq(k_{j} | q_{i})=1 / L_{K}q(kj∣qi)=1/LK ,则自我注意变为值 V 的微不足道之和,并且对于住宅输入来说是多余的。自然,分布 p 和 q 之间的 “相似性” 可用于区分 “重要” 查询。我们通过 Kullback-Leibler 散度来测量“相似性”√ KL(q∥p)=ln∑l=1LKeqiki⊤/d−1LK∑j=1LKqikj⊤/d−K L(q \| p)=\ln \sum_{l=1}^{L_{K}} e^{q_{i} k_{i}^{\top} / \sqrt{d}}-\frac{1}{L_{K}} \sum_{j=1}^{L_{K}} q_{i} k_{j}^{\top} / \sqrt{d}-KL(q∥p)=ln∑l=1LKeqiki⊤/d−LK1∑j=1LKqikj⊤/d−
在 LKL_{K}LK 中。去掉常数,我们将第 i 个查询的稀疏度量定义为
M(qi,K)=ln∑j=1LKeqikj⊤d−1LK∑j=1LKqikj⊤d,(2)M\left(q_{i}, K\right)=ln \sum_{j=1}^{L_{K}} e^{\frac{q_{i} k_{j}^{\top}}{\sqrt{d}}}-\frac{1}{L_{K}} \sum_{j=1}^{L_{K}} \frac{q_{i} k_{j}^{\top}}{\sqrt{d}} \quad, (2) M(qi,K)=lnj=1∑LKedqikj⊤−LK1j=1∑LKdqikj⊤,(2)
其中,第一项是所有键的 qiq_{i}qi 的 Log-Sum-Exp (LSE),第二项是它们的算术平均值。如果第 i 个查询获得更大的 M(qi,K)M(q_{i}, K)M(qi,K),其注意力概率 p 更加“多样化”,并且很有可能在长尾自注意力分布的 header 字段中包含占主导地位的点积对。 -
ProbSparse 自注意力
ProbSparse 自注意力 根据提议的测量,我们通过允许每个键只关注 u 个主导查询来获得 ProbSparse 自我注意:
A(Q,K,V)=Softmax(Q‾K⊤d)V,(3)\mathcal{A}(Q, K, V)=Softmax\left(\frac{\overline{Q} K^{\top}}{\sqrt{d}}\right) V \quad, (3) A(Q,K,V)=Softmax(dQK⊤)V,(3)
其中 Q‾\overline{Q}Q是 q 大小相同的稀疏矩阵,它仅包含稀疏度量 M(q,K)M(q, K)M(q,K) 下的 Top-u 查询。由常数采样因子 c 控制,我们设置 u=c⋅lnLQu=c \cdot \ln L_{Q}u=c⋅lnLQ ,这使得 ProbSparse 自注意只需要为每个查询键查找计算 O(lnLQ)O(\ln L_{Q})O(lnLQ) 点积,层内存使用保持 O(LKlnLQ)O(L_{K} \ln L_{Q})O(LKlnLQ)。在多头视角下,这种关注会为每个头生成不同的稀疏查询键对,从而避免了严重的信息丢失。 -
近似替代
近似替代:(通过随机抽样计算近似替代)
根据引理 1(证明在附录 D.1 中给出),我们建议最大均值测量为
M‾(qi,K)=maxj{qikj⊤d}−1LK∑j=1LKqikj⊤d.(4)\overline{M}\left(q_{i}, K\right)=max _{j}\left\{\frac{q_{i} k_{j}^{\top}}{\sqrt{d}}\right\}-\frac{1}{L_{K}} \sum_{j=1}^{L_{K}} \frac{q_{i} k_{j}^{\top}}{\sqrt{d}} . (4) M(qi,K)=maxj{dqikj⊤}−LK1j=1∑LKdqikj⊤.(4)
Top-u 的范围大约在命题 1 的边界松弛中成立(参见附录 D.2)。在长尾分布下,我们只需要随机抽样U=LKU=L_{K}U=LK ln LQL_{Q}LQ 点积对,计算出 Mˉ(qi,K)\bar{M}(q_{i}, K)Mˉ(qi,K) ,即用零填充其他对。然后,我们从中选择稀疏 Top- u 作为 Q‾\overline{Q}Q 。Mˉ(qi,K)\bar{M}(q_{i}, K)Mˉ(qi,K) 中的 max-operator 对零值不太敏感,并且数值稳定。在实践中,查询和键的输入长度在自注意力计算中通常是相等的,即 LQ=LK=LL_{Q}=L_{K}=LLQ=LK=L,使得 ProbSparse 自注意力时间复杂度和空间复杂度的总值为 O(LlnL)O(L \ln L)O(LlnL)。 -
其他
稀疏性发现
研究发现,自注意力概率分布具有长尾特性(图 7):少数查询 - 键对贡献主导注意力,其余可忽略。现有方法(如 Sparse Transformer、LogSparse Transformer)通过启发式策略(如空间相关性或周期性模式)减少计算量,但存在理论局限(如固定稀疏模式)。
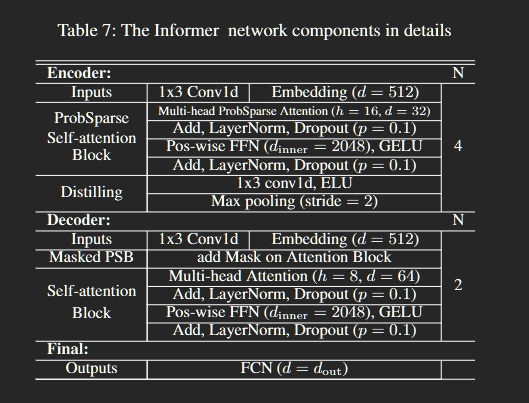
4、模型结构
1.整体结构
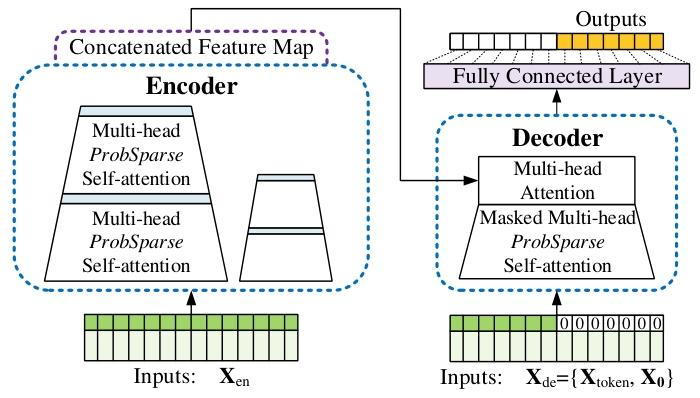
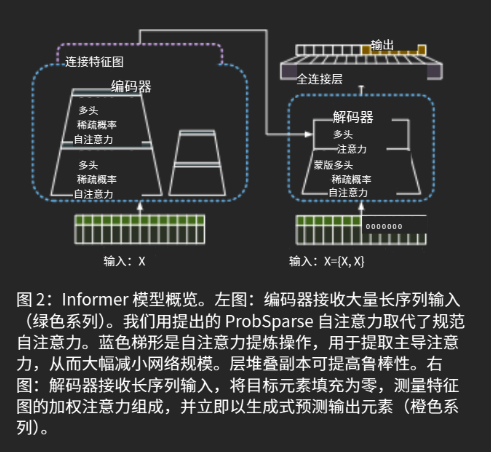
编码器主栈和副本(左图):为了增强蒸馏操作的鲁棒性,我们构建具有减半输入的主栈副本,并通过一次丢弃一层逐步减少自注意力蒸馏层的数量,就像图(2)中的金字塔一样,使得它们的输出维度对齐。
自注意力蒸馏操作:对编码器特征图进行蒸馏,突出主导特征,减少输入时间维度,降低总空间复杂度至O((2−ϵ)LlogL)O((2-\epsilon) L log L)O((2−ϵ)LlogL) ,并通过构建主栈副本增强鲁棒性。
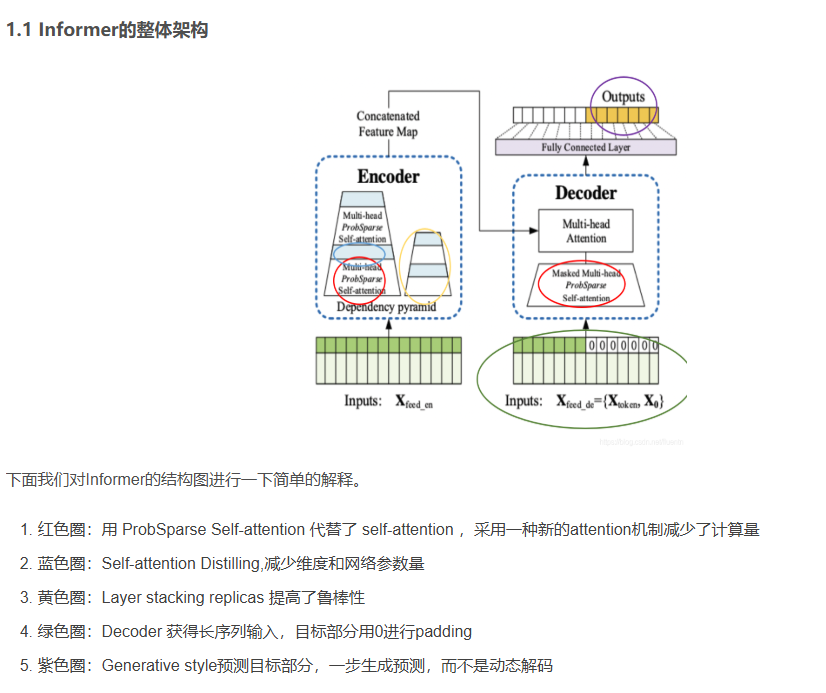
2.编码器:
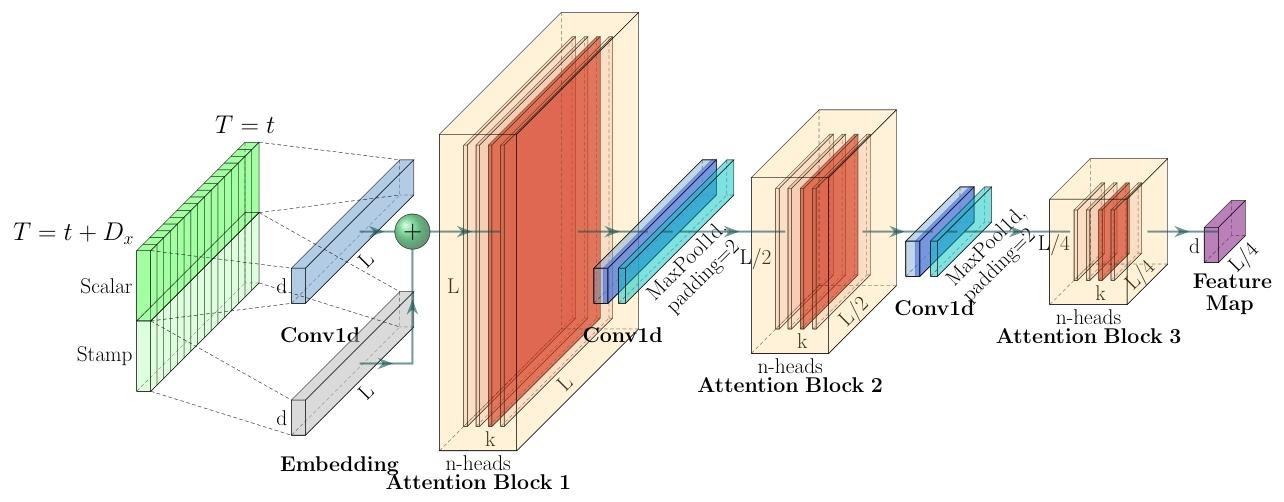
1.编码图说明
这张图展示了Informer模型编码器的结构与处理流程:
-
输入部分:左侧输入包含标量(Scalar)和时间戳(Stamp),通过嵌入(Embedding)与一维卷积(Conv1d)处理,形成输入表示。
-
注意力模块与蒸馏操作:
- 数据进入Attention Block 1(n - heads表示多头),随后通过Conv1d(一维卷积)和MaxPool1d(最大池化,stride=2),将时间维度从( L )压缩至( L/2 ),进入Attention Block 2。
- 重复上述操作,时间维度进一步压缩至( L/4 ),进入Attention Block 3。
-
输出:最终生成特征图(Feature Map),通过逐步压缩时间维度,降低内存复杂度,实现长序列输入的高效处理。
-
红色部分
在文中,红色部分代表特征图(Feature Map),这些特征图是在注意力块(Attention Block)中生成的,用于捕捉输入序列的特征。特征图通过多头注意力机制(Multi-head Attention)生成,它们是模型提取输入序列特征的关键部分。
文中提到的“the red layers are dot-product matrixes”指的是这些特征图是由查询(queries)和键(keys)之间的点积(dot-product)计算得到的注意力矩阵。这些矩阵捕捉了输入序列中不同位置之间的相关性。 -
图中的K和L、红色部分代表啥
在该图中:- L:代表输入序列的长度,即时间步的数量。随着自注意力蒸馏操作(如最大池化)的进行,其值逐步减半(如 ( L )、( L/2 )、( L/4 )),体现时间维度的压缩过程。
- K:通常与注意力机制中的“键”(Key)相关,可理解为键矩阵的维度或特征维度,在多头自注意力模块(n - heads Attention Block)中,参与计算查询(Query)与键(Key)的关联,以捕捉序列依赖关系。 K:代表键(Key)矩阵的维度或特征维度,与注意力计算相关。
(猜测:K可能是头数或者Attention Block的层数) - 红色部分:表示注意力块处理后的特征图区域,包含经过多头自注意力计算后的特征信息。这些区域是自注意力蒸馏操作(如一维卷积 ( \text{Conv1d} ) 和最大池化 ( \text{MaxPool1d} ))的处理对象,通过逐步压缩时间维度(如从 ( L ) 到 ( L/2 )、( L/4 )),降低内存复杂度,同时保留主导特征,实现长序列输入的高效处理。
- d:在自注意力计算中,输入被分为查询(Q)、键(K)、值(V)三个矩阵。K 矩阵的维度通常为 (L \times d)(L 为序列长度,d 为特征维度),用于与查询(Q)计算相似度,确定每个位置的注意力权重。
2.冗余的 V 组合
编码器的特征图在值 V 上具有冗余组合
作为 ProbSparse 自注意力机制的自然结果,编码器的特征图在值 V 上具有冗余组合。
这句话描述了 ProbSparse 自注意力机制与编码器特征冗余之间的关系,其核心逻辑如下:
1. 原因:ProbSparse 自注意力的稀疏性
ProbSparse 机制通过测量查询的稀疏性,仅允许每个查询关注少量主导键(如 u=c⋅lnLu = c \cdot \ln Lu=c⋅lnL 个键)。这种稀疏性导致:
- 冗余的注意力分布:不同查询可能重复关注同一组键,导致特征图中不同位置的 Value(V)组合出现重复。
- 信息压缩损失:未被选中的键的信息被忽略,使得特征图中部分 V 组合失去实际意义。
2. 结果:编码器特征图的冗余性
- 冗余的 V 组合:
编码器的特征图由多头自注意力的输出拼接而成。由于每个头的稀疏性选择可能存在重叠,不同头生成的 V 组合会在特征图中重复出现,形成冗余。 - 示例:
若两个不同的头均选择同一组键,它们的输出 V 会在特征图中产生相似的特征模式,导致计算和存储资源的浪费。
3. 解决方案:自注意力蒸馏操作
为解决冗余问题,Informer 通过蒸馏操作(公式 5)对特征图进行优化:
- 卷积筛选:一维卷积(Conv1d)提取局部时间特征,抑制冗余模式。
- 激活函数增强:ELU 激活函数提升非线性表达能力,强化有效特征。
- 池化压缩:最大池化(MaxPool)通过步长 2 的下采样,将时间维度减半,直接减少冗余特征的数量。
4. 意义
- 效率提升:冗余消除后,编码器内存复杂度从 O(L2)O(L^2)O(L2) 降至 O((2−ϵ)LlogL)O((2-\epsilon)L \log L)O((2−ϵ)LlogL)。
- 性能优化:聚焦主导特征,避免因冗余导致的模型过拟合或计算浪费。
总结
ProbSparse 自注意力的稀疏性是冗余特征产生的根源,而蒸馏操作则是消除冗余、提升编码器效率的关键手段。这一设计体现了 Informer 在长序列处理中平衡效率与性能的核心思想。
3.输入表示
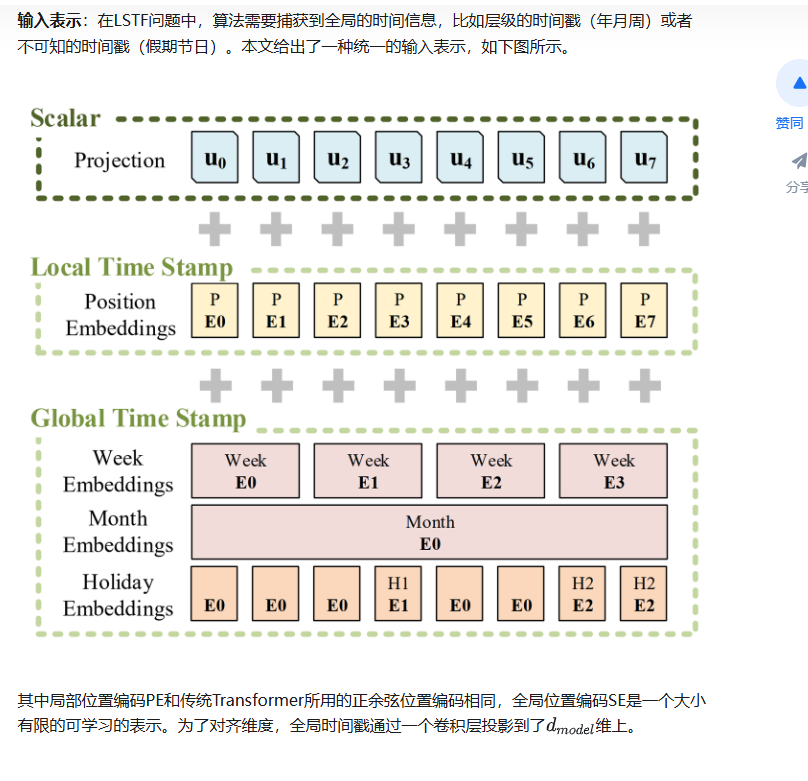
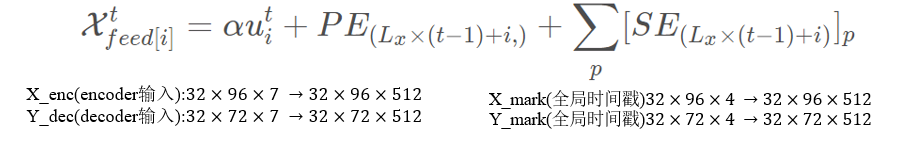
3.解码器:
Informer 模型的解码器部分是专门为长序列时间序列预测设计的,其核心目标是高效生成长序列输出,同时避免传统自回归解码器的累积误差问题。以下是解码器部分的总结:
1. 解码器的输入结构
解码器的输入由两部分组成:
- 开始标记(Start Token):从输入序列中截取的一段较短的序列,用于提供上下文信息。
- 占位符(Placeholder):用于目标序列的占位符,初始值设为零。
输入结构定义为:
Xde=Concat(Xtoken,X0)X_{\text{de}} = \text{Concat}(X_{\text{token}}, X_0) Xde=Concat(Xtoken,X0)
其中:
- XtokenX_{\text{token}}Xtoken 是开始标记,长度为 LtokenL_{\text{token}}Ltoken。
- X0X_0X0 是占位符,长度为预测序列长度 LyL_yLy。
XtokenX_{\text{token}}Xtoken(起始令牌)
- 定义:
从输入序列中采样的一段已知历史数据,维度为 RLtoken×dmodel\mathbb{R}^{L_{\text{token}} \times d_{\text{model}}}RLtoken×dmodel。 - 作用:
- 引导生成:提供解码器生成目标序列的初始上下文,帮助模型理解时间相关性。
- 示例:
预测未来 7 天(168 点)的温度时,选择前 5 天(120 点)的数据作为X^{t}_{\text{token}}。
- 来源:
输入序列中目标序列之前的连续切片,例如预测窗口前的历史数据。
** X0X_0X0(零填充占位符)**
- 定义:
长度为 LyL_yLy(目标序列长度)的零填充矩阵,维度为 RLy×dmodel\mathbb{R}^{L_y \times d_{\text{model}}}RLy×dmodel。 - 作用:
- 占位符:作为目标序列的“虚拟输入”,在生成时被模型填充为预测值。
- 时间戳嵌入:包含目标序列的时间戳信息(如预测周的日期、小时等),帮助模型捕捉时间上下文。
- 特殊处理:
- 初始化为全零,但在训练时通过反向传播学习其隐含表示。
- 在掩码自注意力中,未来位置的点积被设为
-∞,强制模型仅关注历史信息。
2. 解码器的核心结构
解码器由两层多头 ProbSparse 自注意力机制组成,其结构如下:
- 第一层:多头 ProbSparse 自注意力机制,用于处理解码器的输入。
- 第二层:掩码多头 ProbSparse 自注意力机制,用于避免自回归解码中的累积误差。
掩码机制通过将未来的注意力分数设为 −∞-\infty−∞,防止每个位置关注未来的输入。
3. 生成式解码器
Informer 的解码器采用生成式风格,通过一次前向传播生成整个预测序列,而不是逐个时间步生成。这种设计显著提高了推理速度,同时避免了传统动态解码中的累积误差问题。
生成式解码器的工作流程如下:
- 输入处理:将开始标记和占位符拼接后输入解码器。
- 注意力计算:通过多头 ProbSparse 自注意力机制计算特征图。
- 全连接层:通过全连接层生成最终的预测序列。
与传统的动态解码(dynamic decoding)不同,Informer 的解码器采用生成式推理(generative inference)。具体来说:
- 传统的动态解码是逐个时间步生成输出,这会导致累积误差。
- Informer 的解码器通过一次前向操作生成整个目标序列,从而避免了累积误差。
4. 生成式解码的优势
- 高效性:通过一次前向传播生成整个预测序列,显著提高了推理速度。
- 避免累积误差:与传统的自回归解码器相比,生成式解码器避免了逐个时间步生成带来的累积误差。
- 灵活性:可以预测任意长度的序列,而不需要逐个时间步的动态解码。
总结
Informer 的解码器通过生成式风格和多头 ProbSparse 自注意力机制,高效生成长序列输出,同时避免了传统解码器的累积误差问题。这种设计显著提高了模型在长序列时间序列预测任务中的性能和效率。
5、图/表解释
图1
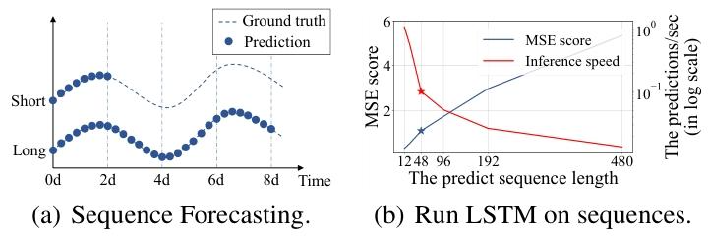
这张图片由两个部分组成,分别标记为 (a) 和 (b),它们都与时间序列预测相关,特别是长序列时间序列预测(LSTF)。
(a) 序列预测图
这部分图展示了时间序列预测的示例。横轴表示时间(Time),单位是天(d),从 0 天到 8 天。纵轴表示某个测量值(例如温度、电力消耗等)。
- 虚线(Ground truth):表示真实值,即实际发生的情况。
- 实线(Prediction):表示预测值,即模型预测的结果。
- 蓝色圆点:表示预测值的具体数据点。
图中展示了两种情况:
- Short:短期预测,预测长度较短(例如 12 点,0.5 天)。
- Long:长期预测,预测长度较长(例如 480 点,20 天)。
从图中可以看出,短期预测的误差较小,预测值与真实值较为接近;而长期预测的误差较大,预测值与真实值之间的偏差逐渐增大。
(b) LSTM 性能图
这部分图展示了使用 LSTM 模型在不同预测序列长度下的性能表现。横轴表示预测序列长度(The predict sequence length),从 12 到 480。纵轴左侧表示均方误差(MSE score),右侧表示推理速度(The predictions/sec)。
- 黑色实线(MSE score):表示均方误差,随着预测序列长度的增加,MSE 逐渐上升,表明模型的预测误差随着预测长度的增加而增大。
- 红色实线(Inference speed):表示推理速度,随着预测序列长度的增加,推理速度逐渐下降,表明模型在处理更长序列时的计算效率降低。
从图中可以看出,当预测序列长度超过 48 点时,MSE 开始显著上升,而推理速度则急剧下降。这说明 LSTM 模型在处理较长序列时,预测能力和计算效率都会受到限制。
6、模型蒸馏(distilling)
定义:
模型蒸馏是一种知识迁移技术,其核心是将一个复杂、庞大的教师模型(Teacher Model)的知识迁移到一个相对简单、轻量级的学生模型(Student Model)。通过这种方式,学生模型可以在性能上接近教师模型,同时显著降低计算资源的消耗。
文中涉及模型蒸馏,但未明确提及剪枝和量化。具体分析如下:
Informer 模型通过 ProbSparse 自注意力机制,实现了 O(LlogL) 的时间复杂度和内存使用;自注意力蒸馏操作进一步将总空间复杂度降低至 O((2−ϵ)LlogL),有效减少了计算资源消耗,使其更适用于长序列时间序列预测。
1. 模型蒸馏(Distillation)
- 相关内容:
在“自注意力蒸馏操作”(self-attention distilling)中,通过以下步骤实现模型优化(段落1-52):- 特征选择:利用卷积(Conv1d)和激活函数(ELU)提取主导注意力特征。
- 维度压缩:通过最大池化(MaxPool)将输入时间维度减半,逐层减少冗余信息。
- 金字塔结构:构建多层堆叠的编码器栈,主栈与子栈结合,增强长序列处理能力。
- 作用:将空间复杂度从 (O(L^2)) 降至 (O((2-\epsilon) L \log L)),提升模型效率。
- 结论:文中明确涉及模型蒸馏技术,通过内部操作优化模型结构。
2. 剪枝(Pruning)
- 相关内容:
文档未直接提及“剪枝”这一术语,也未描述删除冗余神经元、连接或层的操作。- 虽然蒸馏操作通过维度压缩减少了计算量,但这是通过特征选择和池化实现的,与传统剪枝(如结构化剪枝、非结构化剪枝)不同。
- 结论:文中未涉及剪枝技术。
3. 量化(Quantization)
- 相关内容:
文档未提及将模型参数从高精度转换为低精度(如FP32→INT8)的量化操作。- 实验部分仅讨论了时间复杂度、内存使用和推理速度,但未涉及量化对模型部署的优化。
- 结论:文中未涉及量化技术。
总结
- 涉及:模型蒸馏(自注意力蒸馏操作)。
- 未涉及:剪枝、量化。
- 意义:Informer通过蒸馏优化结构效率,但未采用剪枝和量化进一步压缩模型。
猜测
输入图:(猜测:K可能是头数或者Attention Block的层数)
总结
汇总1
以下是论文《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》的核心内容总结:
研究背景
- 时间序列预测的重要性:在许多领域,如传感器网络监控、能源和智能电网管理、经济和金融以及疾病传播分析等,时间序列预测都是一个关键的组成部分。
- 长序列时间序列预测(LSTF)的挑战:现有方法大多针对短期预测设计,随着预测序列长度的增加,模型的预测能力急剧下降,主要表现为均方误差(MSE)上升和推理速度下降。
主要贡献
- 提出Informer模型:针对LSTF问题,提出了基于Transformer的高效模型Informer,具有以下三个显著特点:
- ProbSparse自注意力机制:通过仅关注最重要的查询-键对,将时间复杂度和内存使用降低到O(L log L),同时在依赖对齐上性能与传统自注意力机制相当。
- 自注意力蒸馏:通过减少输入序列长度和突出显示主导注意力,高效处理极端长输入序列,将总空间复杂度降低到O((2−ϵ)L log L)。
- 生成式解码器:采用生成式解码器,通过一次前向操作预测长序列,避免了传统自回归解码器的累积误差问题,大幅提高了推理速度。
方法论
- ProbSparse自注意力机制:通过测量查询的稀疏性,仅保留Top-u查询,减少计算量和内存使用。
- 自注意力蒸馏:在编码器中,通过卷积和最大池化操作减少输入的时间维度,突出显示主导特征,提高模型对长序列输入的处理能力。
- 生成式解码器:将起始标记和目标序列占位符作为输入,通过掩码多头自注意力机制避免自回归,实现一次前向操作预测整个序列。
实验结果
- 数据集:在四个数据集上进行了广泛实验,包括ETTh1、ETTh2、ETTm1、Weather和ECL。
- 实验设置:逐步延长预测窗口大小,使用均方误差(MSE)和平均绝对误差(MAE)作为评估指标。
- 结果分析:
- 单变量时间序列预测:Informer模型在所有数据集上显著提高了推理性能,预测误差随预测范围的增加而缓慢上升,证明了其在LSTF问题上的优势。
- 多变量时间序列预测:Informer模型在多变量预测中也表现出色,优于其他方法,如RNN基线模型和CNN基线模型。
- 参数敏感性分析:对输入长度、采样因子和层堆叠组合等参数进行了敏感性分析,验证了模型的稳定性和有效性。
结论
- Informer模型的优势:通过设计ProbSparse自注意力机制、自注意力蒸馏和生成式解码器,Informer模型成功解决了传统Transformer在LSTF中的计算复杂度、内存使用和架构限制问题,显著提高了预测能力。
- 未来展望:Informer模型为LSTF问题提供了一种新的解决方案,未来可以进一步探索其在不同领域和数据集上的应用,以及与其他技术的结合。
汇总2
详细总结
- 长序列时间序列预测(LSTF)问题
- 研究背景:时间序列预测在多领域至关重要,LSTF需利用大量历史数据进行长期预测,但现有方法多针对短期问题,在预测长序列时性能受限,如LSTM在预测长度大于48点时,均方误差(MSE)上升、推理速度下降。
- 挑战与难点:LSTF的主要挑战是增强预测能力,需具备长距离对齐能力和对长序列输入输出的高效操作能力。Transformer虽在捕捉长距离依赖方面表现出色,但自注意力机制存在二次时间复杂度和高内存消耗问题,其架构也限制了在LSTF中的应用。
- Informer模型
- 模型架构:采用编码器 - 解码器架构,编码器用于提取长序列输入的稳健长距离依赖,解码器通过生成式推理预测长序列输出。
- 关键组件
- ProbSparse自注意力机制:通过测量查询的稀疏性,让每个键仅关注u个主导查询,实现了O(LlogL)O(L log L)O(LlogL)的时间复杂度和内存使用,在多头上生成不同的稀疏查询 - 键对,避免信息丢失。
- 自注意力蒸馏操作:对编码器特征图进行蒸馏,突出主导特征,减少输入时间维度,降低总空间复杂度至O((2−ϵ)LlogL)O((2-\epsilon) L log L)O((2−ϵ)LlogL) ,并通过构建主栈副本增强鲁棒性。
- 生成式解码器:将起始令牌扩展为生成式方式,一次前向操作即可预测长序列输出,避免了动态解码的累积误差传播。
- 实验
- 实验设置
- 数据集:使用四个数据集,包括ETT(不同时间粒度的电力变压器温度数据)、ECL(电力消耗负载数据)、Weather(气象数据),涵盖不同领域和时间粒度。
- 基线方法:选择ARIMA、Prophet、LSTMa等五种时间序列预测方法作为对比,并纳入Informer†(使用规范自注意力机制的Informer变体)、Reformer和LogSparse自注意力等方法。
- 实验参数:对超参数进行网格搜索,Informer包含3层编码器栈和1层(1/4输入)编码器栈,2层解码器,使用Adam优化器,学习率从1e−41e^{-4}1e−4开始,每轮衰减两倍,共训练8轮。
- 实验结果
- 单变量预测:Informer在所有数据集上显著提升推理性能,预测误差随预测 horizon增长缓慢,优于其他方法,如在ETTh1数据集上,168点预测时MSE比LSTMa降低26.8%。
- 多变量预测:Informer同样表现出色,优于RNN - 基于的LSTMa和CNN - 基于的LSTnet等方法,如在ETTh1数据集上,168点预测时MSE比LSTMa平均降低26.6%。
- 参数敏感性分析:输入长度方面,预测短序列时增加输入长度先降后升MSE,长序列时更长输入有益;采样因子控制信息带宽,设置c=5c = 5c=5时性能稳定;层堆叠组合中,L和L/4的组合最稳健。
- 消融研究:ProbSparse自注意力机制性能优于LogTrans和Reformer,避免了内存问题;自注意力蒸馏操作在处理长输入时有效,去除后会导致内存不足;生成式解码器能避免误差积累,优于动态解码。
- 实验设置
- 结论
- Informer通过设计ProbSparse自注意力机制和蒸馏操作,解决了Transformer在LSTF中的二次时间复杂度和内存使用问题,生成式解码器缓解了传统架构的限制。
- 在真实数据实验中,Informer有效增强了LSTF的预测能力,为该问题提供了新的解决方案。
| 数据集 | 预测长度 | Informer(MSE/MAE) | Informer†(MSE/MAE) | LogTrans(MSE/MAE) | LSTMa(MSE/MAE) |
|---|---|---|---|---|---|
| ETTh1 | 24 | 0.098/0.247 | 0.092/0.246 | 0.103/0.259 | 0.114/0.272 |
| ETTh1 | 48 | 0.158/0.319 | 0.161/0.322 | 0.167/0.328 | 0.193/0.358 |
| ETTh1 | 168 | 0.183/0.346 | 0.187/0.355 | 0.207/0.375 | 0.236/0.392 |
| ETTh1 | 336 | 0.222/0.387 | 0.215/0.369 | 0.230/0.398 | 0.590/0.698 |
| ETTh1 | 720 | 0.269/0.435 | 0.257/0.421 | 0.273/0.463 | 0.683/0.768 |
关键问题
- Informer模型相比传统Transformer模型在时间复杂度和内存使用上有哪些改进?
- 传统Transformer模型自注意力机制的时间复杂度和内存使用为O(L2)O(L^{2})O(L2),堆叠J层时总内存使用为O(J⋅L2)O(J \cdot L^{2})O(J⋅L2)。Informer模型通过ProbSparse自注意力机制,实现了O(LlogL)O(L log L)O(LlogL)的时间复杂度和内存使用;自注意力蒸馏操作进一步将总空间复杂度降低至O((2−ϵ)LlogL)O((2-\epsilon) L log L)O((2−ϵ)LlogL),有效减少了计算资源消耗,使其更适用于长序列时间序列预测。
- Informer模型中的生成式解码器有什么优势?
- 生成式解码器采用一次前向操作预测长序列输出的方式,避免了传统编码器 - 解码器架构中动态解码的逐步推理过程,大幅提高了推理速度。同时,它在训练和推理时不依赖标签与输出的严格对齐,仅依靠时间戳进行预测,能够有效避免误差积累,在长序列预测中表现更稳定,提升了预测的准确性和可靠性。
- 在实验中,Informer模型在不同数据集上的表现如何?
- 在ETT、ECL、Weather等四个数据集上,Informer模型在单变量和多变量预测任务中均表现出色。以ETT数据集为例,在单变量预测时,随着预测长度增加,其预测误差增长缓慢,在168点预测时,MSE比LSTMa降低26.8%;在多变量预测中,同样优于其他方法,如在ETTh1数据集168点预测时,MSE比LSTMa平均降低26.6%,表明Informer模型在不同数据集上都具有较强的适应性和优越的预测能力。
汇总3(√)
一、研究背景与挑战
-
长序列时间序列预测(LSTF)的需求
- 许多实际应用(如电力消耗规划、气候监测)需要预测数百甚至数千时间步的序列,但现有方法(如LSTM)在预测长度超过48点时性能显著下降(MSE上升、推理速度骤降)。
- LSTF的核心挑战在于提升模型的预测能力,即高效捕捉输入与输出之间的长距离依赖关系,并处理超长序列的计算效率问题。
-
传统Transformer的局限性
- 二次复杂度:自注意力机制的时间和内存复杂度为O(L2)O(L^2)O(L2),无法处理长序列。
- 内存瓶颈:堆叠J层编码器/解码器导致总内存复杂度为O(J⋅L2)O(J \cdot L^2)O(J⋅L2)。
- 动态解码低效:传统Transformer的逐步推理方式导致推理速度与RNN相当。
二、Informer模型的核心创新
-
ProbSparse自注意力机制
- 稀疏性发现:通过Kullback-Leibler散度测量查询的稀疏性,发现仅少数查询对主导注意力有贡献。
- 高效计算:每个查询仅关注u=c⋅lnLu = c \cdot \ln Lu=c⋅lnL个主导键,将时间和内存复杂度降至O(LlogL)O(L \log L)O(LlogL)。
- 鲁棒性:多头独立采样不同稀疏查询键对,避免信息丢失。
-
自注意力蒸馏操作
- 维度压缩:通过卷积、激活函数和最大池化,将每层输入的时间维度减半,总空间复杂度降至O((2−ϵ)LlogL)O((2-\epsilon) L \log L)O((2−ϵ)LlogL)。
- 金字塔结构:通过主栈与子栈的组合,增强模型对长序列的鲁棒性。
-
生成式解码器
- 单次前向预测:输入包含起始令牌和零填充目标序列,通过掩码自注意力一次生成完整输出,避免动态解码的累积误差和时间消耗。
三、实验验证与结果分析
-
数据集与基线方法
- 数据集:包括ETT(电力变压器温度)、ECL(电力消耗)、Weather(气象)等4个大规模数据集,涵盖单变量和多变量场景。
- 基线:对比ARIMA、Prophet、LSTM、DeepAR等传统方法,以及Transformer变体(如Reformer、LogTrans)。
-
关键实验结果
- 单变量预测:Informer在所有数据集上均显著优于基线,例如在ETTh1数据集的720点预测中,MSE比LSTM降低60.1%。
- 多变量预测:Informer通过调整全连接层轻松扩展至多变量任务,在ETTh2数据集的720点预测中,MSE比LSTnet降低34.3%。
- 效率验证:Informer的训练时间仅为传统Transformer的1/3,推理速度提升10倍以上。
-
消融研究
- ProbSparse的必要性:在极端长输入(如1440点)下,Informer仍能保持稳定性能,而LogTrans因内存问题无法运行。
- 蒸馏操作的有效性:去除蒸馏后,模型在输入长度超过720时出现内存不足(OOM)。
- 生成式解码优势:动态解码在预测偏移时性能迅速下降,而生成式解码保持稳定。
四、结论与展望
-
核心贡献
- 提出ProbSparse自注意力机制和蒸馏操作,突破Transformer的效率瓶颈,实现长序列的高效处理。
- 设计生成式解码器,解决动态解码的低效问题,为LSTF提供新范式。
-
应用价值
- 在电力、气象等领域的长序列预测中具有实用价值,例如在ECL数据集的960点预测中,MSE仅为0.582。
- 开源代码推动了时间序列预测领域的研究(https://github.com/zhouhaoyi/Informer2020)。
-
未来方向
- 探索多变量预测中各维度的非均匀性影响。
- 结合领域知识(如节假日、事件)优化输入表示。
五、关键数据对比
| 数据集 | 预测长度 | Informer (MSE/MAE) | LSTM (MSE/MAE) | 性能提升 |
|---|---|---|---|---|
| ETTh1 | 168 | 0.183/0.346 | 0.236/0.392 | MSE↓26.8% |
| ECL | 960 | 0.582/0.608 | 1.545/1.006 | MSE↓62.3% |
| Weather | 720 | 0.359/0.466 | 0.866/0.809 | MSE↓58.5% |
| 推理速度 | 720 | 0.422秒/样本 | 4.3秒/样本 | 速度↑9.2倍 |
(注:表格数据基于文档中的实验结果整理,具体数值详见原文表1、表2和表4)
汇总4
1. 一段话总结
Informer模型通过提出ProbSparse自注意力机制(时间复杂度优化至O(L log L))、自注意力蒸馏操作(降低内存使用)和生成式解码器(单次前向预测长序列),解决了传统Transformer在长序列时间序列预测(LSTF)中的效率瓶颈。实验表明,Informer在四个大规模数据集(ETT、ECL、Weather等)上显著优于现有方法,验证了其在长距离依赖建模和高效推理方面的优势。
2. 思维导图
- Informer模型- 研究背景- 长序列时间序列预测(LSTF)挑战- 传统Transformer的局限性(二次复杂度、内存瓶颈、动态解码慢)- 方法创新- ProbSparse自注意力机制(O(L log L)复杂度)- 自注意力蒸馏操作(减少层输入冗余)- 生成式解码器(单次预测长序列)- 实验验证- 四个数据集(ETT、ECL、Weather等)- 指标:MSE、MAE- 对比方法:LSTM、DeepAR、Transformer变体等- 结论- 高效解决LSTF问题,性能优于传统方法
3. 详细总结
研究背景
- LSTF挑战:需同时满足长距离依赖建模和高效计算,传统模型(如LSTM)在预测长度超过48点时性能急剧下降(MSE上升,推理速度骤降)。
- Transformer的局限性:
- 二次时间复杂度(O(L²))
- 内存瓶颈(层叠加导致O(J·L²))
- 动态解码导致推理速度慢
方法创新
- ProbSparse自注意力机制
- 通过稀疏性测量(公式2-4)仅关注关键查询,将时间复杂度优化至O(L log L),内存使用降低。
- 自注意力蒸馏操作
- 通过最大池化和卷积减少层输入维度,总内存复杂度降至O((2−ε)L log L)。
- 生成式解码器
- 输入包含起始标记和目标时间戳,单次前向操作生成完整长序列,避免动态解码的误差累积。
实验设计
- 数据集:
数据集 描述 预测长度范围 ETT 电力变压器温度(1小时/15分钟级) 24h-720h ECL 电力消耗负荷 48h-960h Weather 气候数据 24h-720h - 对比方法:LSTM、DeepAR、ARIMA、Transformer变体(如Reformer、LogTrans)等。
结果分析
- 性能优势:
- Univariate:Informer在ETTh1数据集上,预测720h时MSE为0.269(优于LSTM的0.683)。
- Multivariate:在ECL数据集预测960h时MSE为0.582,显著优于LSTnet的0.605。
- 效率提升:
- 训练时间仅为Transformer的1/3,推理速度比动态解码快L倍(L为预测长度)。
4. 关键问题
Q1:ProbSparse自注意力机制如何降低计算复杂度?
A:通过稀疏性测量(公式2-4)仅选择Top-u(u=c·ln L)关键查询,将时间复杂度从O(L²)优化至O(L log L),并通过随机采样近似计算进一步减少冗余操作。
Q2:Informer在哪些数据集上验证了其优势?
A:在四个数据集上进行实验:
- ETT(电力变压器温度)
- ECL(电力消耗负荷)
- Weather(气候数据)
- ETTm(15分钟级温度数据)
所有数据集均显示Informer在MSE和MAE上显著优于传统方法。
Q3:生成式解码器的优势是什么?
A:通过输入起始标记和目标时间戳,单次前向操作生成完整长序列,避免动态解码的误差累积,同时将推理速度提升L倍(L为预测长度),适用于实时性要求高的场景。