【Feed-forward optimization】 in Visual Geometry Grounded and 3DGS
文章目录
- 1. VGGT:Visual Geometry Grounded Transformer
- 摘要和结论
- 引言
- 相关工作
- 模型框架
- 3.1 Backbone Architecture
- 3.2 Prediction Heads
- 3.3 Training Strategy
- 3.4 Inference
- over-complete predictions
- 实验
- 2. Continuous 3D Perception Model with Persistent State
- Cut3R 论文中的相关工作总结表
- 模型框架
- 3.1 状态–输入交互机制(State-Input Interaction Mechanism)
- 3.2 用虚拟视角查询状态(Querying the State with Unseen Views, Raymap)
- 3.3 训练目标(Training Objective)
- 3.4 训练策略(Training Strategy)
- 3.5 架构细节(Heads 与调制、位置编码)
- 备注:坐标系与尺度
- 实验
- 3. AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
- 相关工作 (Related Work)
- 方法
- 实验
- 一些其他的FFD-3DGS方法(不依赖VGGT)
1. VGGT:Visual Geometry Grounded Transformer
VGGT 是一个大型前馈变换器,具有最小的 3D 归纳偏差,并在大量带 3D 注释的数据上进行训练。它能够接收多达数百张图像,并在不到一秒的时间内同时预测所有图像的摄像头(intrinsic extrinsic)、点图(point map)、深度图和点轨迹,其性能通常优于基于优化的替代方案,无需进一步处理。
不依赖传统优化,快,好,不需要先验,从图像序列中一次性输出3d场景信息

摘要和结论
基于前向的 新视角合成(与传统的基于几何优化的方法相比,要快很多倍了)

引言

传统的3D重建方法是基于 视觉几何的。(复杂的几何后处理)

DUSt3R 和 MASt3R :它们的核心输入形式是两张图像一对一对地进入模型,模型学习的是两张图像之间的几何关系。
-
DUSt3R:给定一对图像,它预测 dense depth maps,并在两个视角之间做对齐,从而得到一致的点云。它的推理逻辑是 pairwise——先两张图之间估深度和匹配,再把多对图像的结果逐步融合成场景点云 。
-
MASt3R:在 DUSt3R 的基础上扩展,依旧是 pairwise matching 的思想。它从图像对里估计 metric-scale 的 dense point maps,然后通过跨 pair 的融合来得到大规模的点云或稠密重建 。
所以,本质上还是处理成对图片:
-
模型的输入单元是两张图像,而不是同时处理所有视角。
-
多视角场景的重建是通过重复 pairwise 推理 + 融合来实现的,而不是一次性在统一的全局上下文里解决。
相比之下,VGGT 用一个多视角 Transformer,一次性 ingest N 张图片,在统一空间里直接预测相机位姿、深度、点轨迹等,避免了 pairwise 推理的冗余,也几乎不依赖后端几何优化 。
我们还证明,当进一步结合 BA 后处理时,VGGT 能够全面实现 SOTA 结果,即使与专注于特定 3D 任务子集的方法相比,通常也能显著提高质量。
相关工作
| 方向 | 代表方法 / 工作 | 特点 | 局限性(VGGT 视角) |
|---|---|---|---|
| Structure-from-Motion (SfM) | COLMAP、传统 BA 管线 | 基于特征匹配 + 捆绑调整 (Bundle Adjustment) 的几何优化 | 需要大量 pairwise 匹配和复杂后端优化,计算昂贵 |
| Learning-based Multi-View Stereo (MVS) | MVSNet、DeepMVS 等 | 通过深度学习替代手工代价体构建与匹配,提升稠密深度估计 | 通常仍需 pairwise 代价体推理,难以统一处理多视角 |
| Pairwise Image Matching Models | DUSt3R、MASt3R | 输入图像对,预测 dense 3D 点图 (metric-scale point maps) 并融合 | 本质仍是 pairwise,需多次推理 + 融合,不能直接处理全局多视角 |
| End-to-end 直接预测 3D | Depth-from-single-image、pose-from-image | 单视角或少量视角直接预测深度/位姿 | 精度有限,难以在复杂场景中泛化 |
| Transformers in Vision & 3D | Vision Transformers、MViT 等 | 全局上下文建模,适合多视角场景 | 之前工作主要在 2D 或 pairwise 3D,未做到统一多任务 |
| Large Reconstruction Models | 最近的通用 3D 学习框架 | 试图用大规模预训练增强泛化 | 多依赖外部几何优化或 pairwise matching,端到端性不足 |
VGGT 的不同点:它避免了上述方法的 pairwise 或繁重几何后处理,一次性输入多张图片,用统一 Transformer 预测深度、相机位姿、点轨迹等,从而能在不依赖 SfM/MVS 后端的情况下,直接解决多种 3D 任务。
模型框架
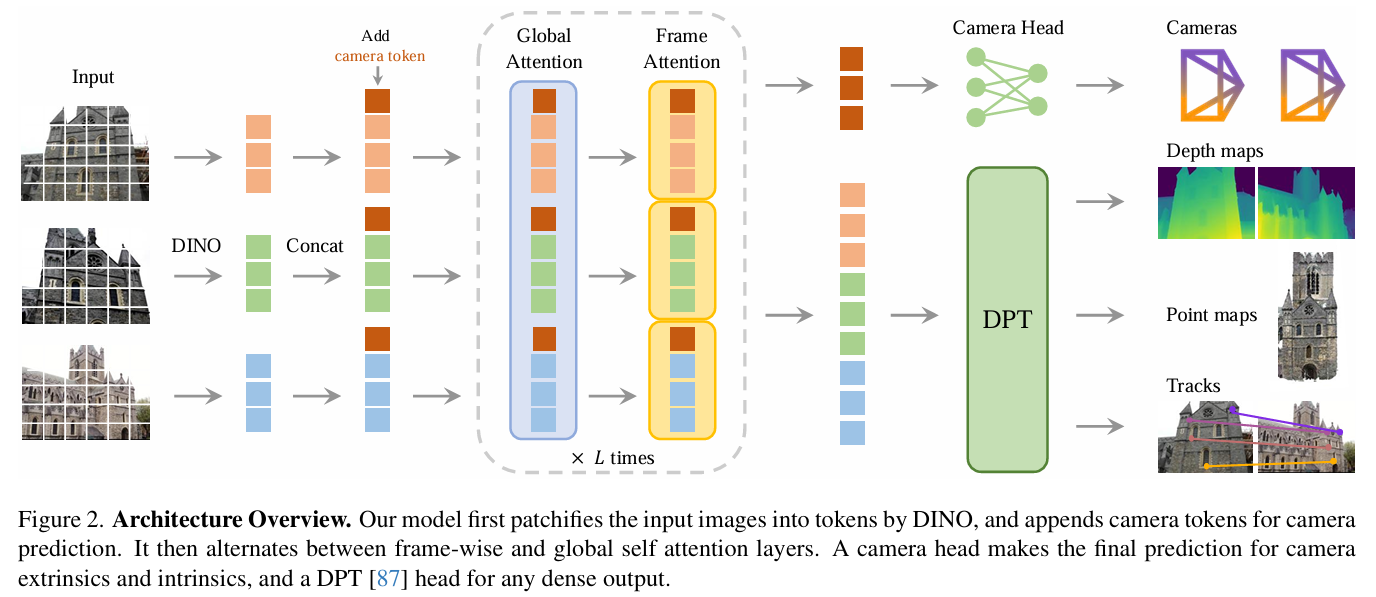
足够详细了:VGGT[CVPR 2025 BEST PAPER] 论文 + 代码 最详细解析 新手小白友好型
3.1 Backbone Architecture
- 使用 纯 Transformer 作为骨干网络。
- 输入是多张图像序列,输出是统一的 token 表示。
- 特殊设计的 geometry-grounded tokens 保留空间几何信息,用于后续 3D 任务。
3.2 Prediction Heads
-
在 backbone 的输出上,附加多个 head,分别预测:
- 相机参数(内参 & 外参)
- 稠密深度图
- 3D 点轨迹 (point tracks)
-
这些 head 共享 backbone 特征,实现多任务统一。
3.3 Training Strategy
- 同时监督相机、深度和点轨迹,采用联合损失。
- 利用大规模数据(多视角、多场景)进行训练,从而保证泛化。
- 相比 SfM/MVS,不需要后端几何优化作为依赖。
3.4 Inference
- 推理时,给定若干张图像,VGGT 直接一次性输出相机、深度和点轨迹结果。
- 输出可直接用于 3D reconstruction、tracking、novel view synthesis 等下游任务。
- 不需要额外的 pairwise 匹配或 BA 优化。
总结:VGGT 方法的核心在于:一个统一的 Transformer backbone,多个预测头端到端监督,避免 pairwise pipeline 和几何后处理,直接一次性预测所有 3D 关键信息。
OrderofPredictions. 输入序列中图像的顺序是任意的,但选择第一幅图像作为参考帧。该网络架构设计为对除第一帧以外的所有帧都具有置换等变性。
over-complete predictions
在 point map 已经存在的情况下,相机参数并不是“必须单独预测”的,而是可以从 point map 中解算得到。因此 VGGT 同时预测二者。
在训练时显式地监督所有这些子任务,有助于网络学习更一致、更准确的几何表征

实验
point map估算的效果。如下图所示,DUSt3R输入多张image的时候是成对的处理的,因此当32张图输入,时间爆炸式增长到200s。但是VGGT仍然是0.6s。相比起单张或者两张图片的输入,时间增长并没有DUSt3R那么大。

2. Continuous 3D Perception Model with Persistent State

给定一个图像流,这种不断演化的状态可用于以在线方式为每个新输入生成度量尺度的点图(每像素 3D 点)。
这些点图位于一个共同的坐标系中,并且可以累积成一个连贯、密集的场景重建,并随着新图像的到来而更新。
Cut3R 论文中的相关工作总结表
| 类别 | 代表方法/论文 | 特点 | 局限性 |
|---|---|---|---|
| 传统 SfM + MVS | COLMAP、OpenMVG | 精确估计相机位姿和稠密深度 | 计算耗时、依赖特征匹配,难以扩展到稀疏/无纹理场景 |
| 学习增强的传统管线 | 学习型特征替代 SIFT [21,24,78,91],学习 priors [17,95,96,98,118,124,133],端到端优化系统 [94,96,103,119] | 融合深度学习提升鲁棒性 | 仍依赖传统 SfM 结构,难以端到端推理 |
| 直接预测 3D | 单/双图像预测深度或点云 [8,31,37,61,62,67,71,74,88,92,93,107,123,128,134] | 利用学习直接输出 3D 表示 | 通常仅限单张或少量输入,难以多视角一致 |
| Pose-free 方法 | DUSt3R、MASt3R | 无需外参,直接预测 point maps 和相对位姿 | 稀疏视角下几何一致性不足,需要后处理/优化 |
| NeRF 系列 | NeRF, InstantNGP, 3DGS | 通过体渲染获得高质量视图合成和几何 | 需多视角密集采样,训练和优化代价高 |
| 端到端 Transformer | VGGT | 输入多张图像,直接预测点云/相机参数 | 更高效,但在复杂场景/几何一致性上仍有限制 |
| Cut3R | 本文方法 | 级联 Transformer,联合预测相机和 metric-scale 点图;几何一致性增强 | 静态场景表现优异,但动态/4D 场景尚未覆盖 |
模型框架
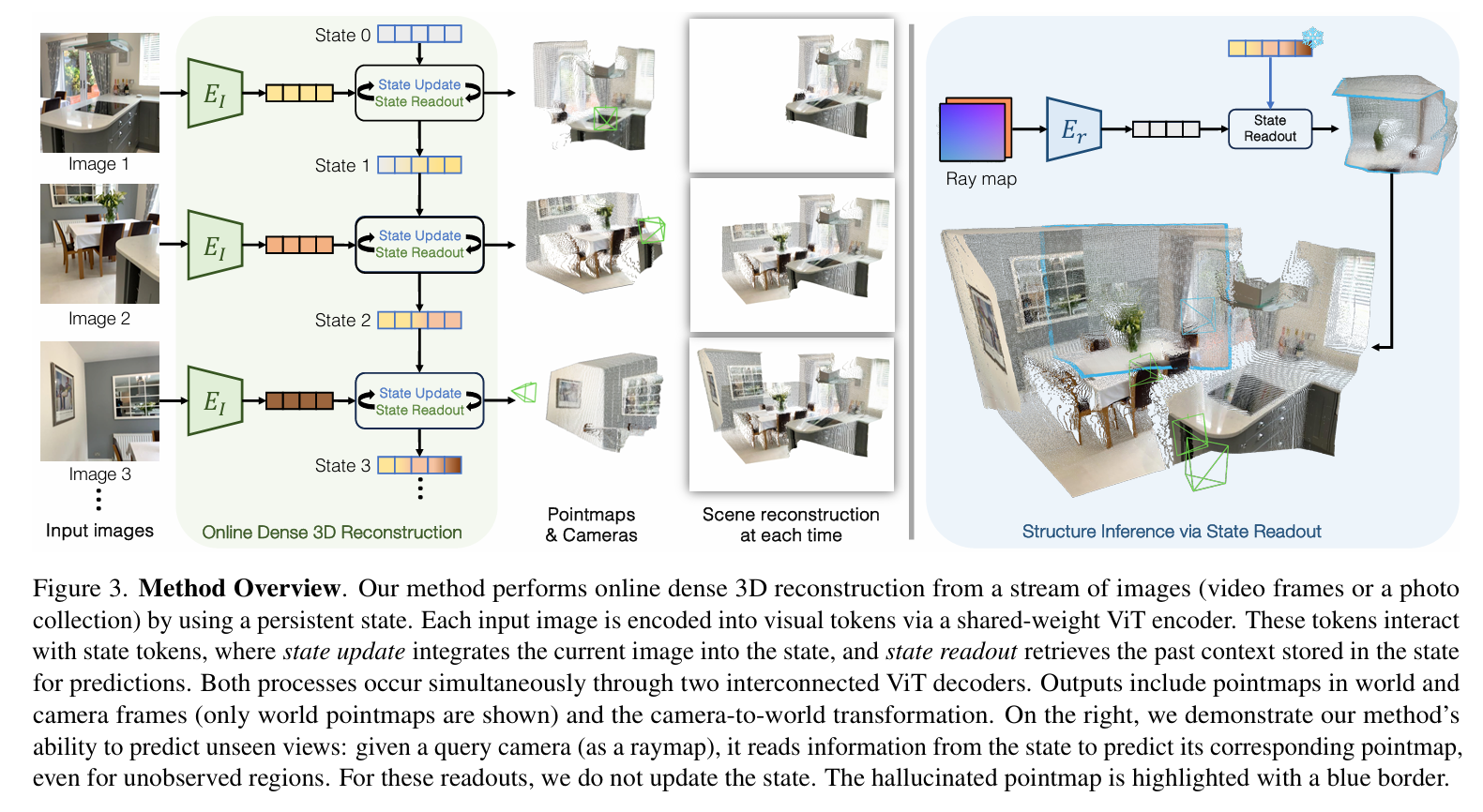
Cut3R 设计了一种 级联 Transformer 架构,在没有已知相机外参的情况下,从多张输入图像直接推理出 相机参数 和 metric-scale 点图 (point maps)。其核心思想是逐层增强视角间的几何一致性,并用端到端的自监督方式训练,而不依赖外部 SfM/MVS 。
给你一份尽量贴近论文原文结构与公式的「3. Method」精炼版。分小节对应论文 3.1–3.4,并补上实现要点。引文都给出行号方便核对。
3.1 状态–输入交互机制(State-Input Interaction Mechanism)
输入流与编码
给定一段图像流 ItI_tIt,先用共享权重的 ViT 编码器得到图像 token:
Ft=Encoderi(It).F_t=\mathrm{Encoder}_i(I_t). Ft=Encoderi(It).
持久化状态与双向交互
模型维护一组可学习的状态 token sts_tst(初始为跨场景共享的可学习参数)。每个时刻,图像 token 与状态 token 通过两套互联的 Transformer 解码器进行双向交互:一支做 state-update(把当前观测写入状态),一支做 state-readout(从状态读出上下文):
[zt′,Ft′],st=Decoders([z,Ft],st−1).[z_t',\,F_t'],\ s_t \;=\; \mathrm{Decoders}([z,\,F_t],\,s_{t-1}). [zt′,Ft′], st=Decoders([z,Ft],st−1).
其中 zzz 是预置在图像 token 前的pose token,zt′z_t'zt′ 捕获图像级别的场景/自运动信息;两支解码器在每个 block 内交叉注意力以保证信息流动。
显式 3D 表征与相机预测(两坐标系+位姿)
从 (Ft′,zt′)(F_t', z_t')(Ft′,zt′) 中,模型同时预测两套点图(pointmaps)与置信度,以及当前帧到世界的 6DoF 位姿:
(X^tself,C^tself)=Headself(Ft′)(X^tworld,C^tworld)=Headworld(Ft′,zt′)P^t=Headpose(zt′).\begin{aligned} (\hat X_t^{\text{self}},\,\hat C_t^{\text{self}}) &= \mathrm{Head}_{\text{self}}(F_t') \\ (\hat X_t^{\text{world}},\,\hat C_t^{\text{world}}) &= \mathrm{Head}_{\text{world}}(F_t',\,z_t') \\ \hat P_t &= \mathrm{Head}_{\text{pose}}(z_t'). \end{aligned} (X^tself,C^tself)(X^tworld,C^tworld)P^t=Headself(Ft′)=Headworld(Ft′,zt′)=Headpose(zt′).
两套点图分别定义在相机自身坐标系与世界坐标系。世界系被定义为首帧的相机坐标系(训练/推理时固定为参考帧)。
设计动机:同时预测 X^tself,X^tworld,P^t\hat X_t^{\text{self}}, \hat X_t^{\text{world}}, \hat P_tX^tself,X^tworld,P^t 虽然“冗余”,但简化训练,让每个量都可直接受监督,并容纳部分标注数据集(例如只有位姿或只有单视深度的场景)。所有点图与位姿都在**metric scale(米)**下定义。
在线重建与结构外推(方法总览)
随着图像流进入,模型在同一世界坐标系下不断输出点图与相机,在线累积为稠密重建;同时还能对未观测视角做“读取”(见 3.2)。
3.2 用虚拟视角查询状态(Querying the State with Unseen Views, Raymap)
除常规“用图像作为输入”外,Cut3R 还支持以虚拟相机的射线图(raymap)作为查询,不更新状态,仅从状态中读出该视角的点图,实现未见区域的结构推断;在大视差下仍能跟随视角几何变化,并对输入未见到的区域“补全”合理结构(如地面、灶台、凳子等),体现模型学到的通用 3D 场景先验。
Raymap 训练启用条件
只有当训练数据具备metric-scale 3D 标注时才启用 raymap 模式(随机把序列中部分帧替换为对应 raymap),以避免与状态中场景尺度不一致;若标注尺度未知,则禁用 raymap 查询。
3.3 训练目标(Training Objective)
训练输入与记号
给定长度为 NNN 的序列(视频或无序照片集),本节不区分由图像或 raymap 触发的预测。令
X={X^self,X^world},X^self={X^tself}t=1N,X^world={X^tworld}t=1N,\mathcal{X}=\{\hat X^{\text{self}},\hat X^{\text{world}}\},\quad \hat X^{\text{self}}=\{\hat X_t^{\text{self}}\}_{t=1}^N,\; \hat X^{\text{world}}=\{\hat X_t^{\text{world}}\}_{t=1}^N, X={X^self,X^world},X^self={X^tself}t=1N,X^world={X^tworld}t=1N,
对应置信度为 C\mathcal{C}C。
(1) 3D 回归(置信度加权)
遵循 MASt3R 的做法,对点图使用置信度感知回归,并加入尺度归一化项以处理不同数据源的尺度(在 metric 标注时令两尺度相等以学习绝对尺度):
Lconf=∑(x^,c)∈(X^,C)(c∥x^s^−xs∥22−αlogc).\mathcal{L}_{\text{conf}} =\sum_{(\hat x, c)\in(\hat{\mathcal{X}},\mathcal{C})}\Big( c\,\lVert \hat x_{\hat s}-x_{s}\rVert_2^2-\alpha\log c \Big). Lconf=(x^,c)∈(X^,C)∑(c∥x^s^−xs∥22−αlogc).
其中 s,s^s,\hat ss,s^ 为尺度归一化因子;当 GT 为 metric 时令 s^:=s\hat s:=ss^:=s 以学习 metric-scale 点图。
(2) 位姿损失
将位姿 P^t\hat P_tP^t 参数化为四元数 q^t\hat q_tq^t 与平移 τ^t\hat \tau_tτ^t,做 L2 损失;平移同样做尺度对齐:
Lpose=∑t=1N(∥q^t−qt∥22+∥τ^ts^−τts∥22).\mathcal{L}_{\text{pose}} =\sum_{t=1}^N\Big(\lVert \hat q_t-q_t\rVert_2^2 +\big\lVert \hat \tau_t\,\hat s-\tfrac{\tau_t}{s}\big\rVert_2^2\Big). Lpose=t=1∑N(∥q^t−qt∥22+τ^ts^−sτt22).
(3) 颜色重建损失(raymap 专用)
当输入是 raymap 时,另外监督预测像素颜色与 GT 的均方误差:
Lrgb=∥I^r−Ir∥22.\mathcal{L}_{\text{rgb}}=\lVert \hat I_r - I_r\rVert_2^2. Lrgb=∥I^r−Ir∥22.
训练时序:序列采样覆盖视频与照片集;在有 metric 标注的数据上,以一定概率把除首帧外的帧替换为对应 raymap,以促使模型在统一尺度下学会“被查询”。
3.4 训练策略(Training Strategy)
课程式训练(Curriculum)
四阶段课程:
1)先以 224×224、4 视角、静态为主训练;
2)加入动态场景与部分标注数据;
3)升分辨率到长边 512、可变宽高比;
4)冻结编码器,在 4–64 视角的长序列上只训解码器与头,强化长上下文推理与处理长序列能力。
实现细节(关键超参)
- 图像编码器:ViT-L(初始化自 DUSt3R 编码器),解码器:ViT-B,patch 大小 16;状态:768 个 token × 维度 768;raymap 编码器为 2-block 轻量模块。优化器 AdamW,初始 lr 1e−41\mathrm{e}{-4}1e−4,线性 warmup + 余弦退火;多卡 A100 训练。
3.5 架构细节(Heads 与调制、位置编码)
- Headself_\text{self}self 与 Headworld_\text{world}world:前两个阶段为线性头,后两个阶段切换为 DPT 结构;
- Headworld_\text{world}world 在层归一化中引入基于 pose token zt′z_t'zt′ 的调制(受 LRM 启发),以把姿态信息显式融入、实现隐式刚体变换;
- 位置编码:在每次 attention 前对 Q,KQ,KQ,K 施加 ROPE。
- 具体维度:dim(zt′)=768\dim(z_t')=768dim(zt′)=768;Headpose_\text{pose}pose 为 2 层 MLP(hidden 768)。
备注:坐标系与尺度
- 世界坐标系取首帧相机系为参考;
- 模型同时预测 X^self,X^world,P^\hat X^{\text{self}}, \hat X^{\text{world}}, \hat PX^self,X^world,P^ 以便对不同类型的标注分别施加监督;
- 所有点图与位姿在米制尺度下定义,支持绝对尺度学习与评测。
实验


3. AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views

AnySplat和 VGGT 的关系:
- AnySplat 的 几何 backbone 基本是基于 VGGT 的 Visual Geometry Grounded Transformer。
- VGGT 能同时输出深度、相机姿态、点图(point maps),但是它的输出不是直接可渲染的 3D 表达。
- AnySplat 在此基础上加了 Gaussian Head,直接预测 3D Gaussian 参数(中心、尺度、方向、SH颜色),并通过 体素化聚合 来转化为可高效渲染的表示。
AnySplat 是一个前馈(feed-forward)的 3D 场景重建与新视角合成方法。输入无需相机参数或逐场景优化,只需一次前向推理即可同时预测 3D Gaussian primitives 与对应的相机内外参。通过自监督蒸馏和体素化裁剪,大幅减少计算量,同时保持渲染质量,实现稀疏和稠密视角下的快速、鲁棒重建。
相关工作 (Related Work)
基于优化的 NVS:NeRF、3DGS,效果好但慢,需已知相机姿态(colmap)。
可泛化 3D 重建:分为
- Pose-aware 方法:依赖已知相机参数(如 PixelSplat, MVSplat, LRM)。
- Pose-free 方法:输入仅图像,同时估计相机姿态与几何(如 DUSt3R, MASt3R, CUT3R, VGGT, Fast3R)。但多存在纹理表现不足、多视角对齐差的问题。 这严重阻碍了其新视图合成的性能。
方法
AnySplat 提供更强的几何一致性与渲染质量。
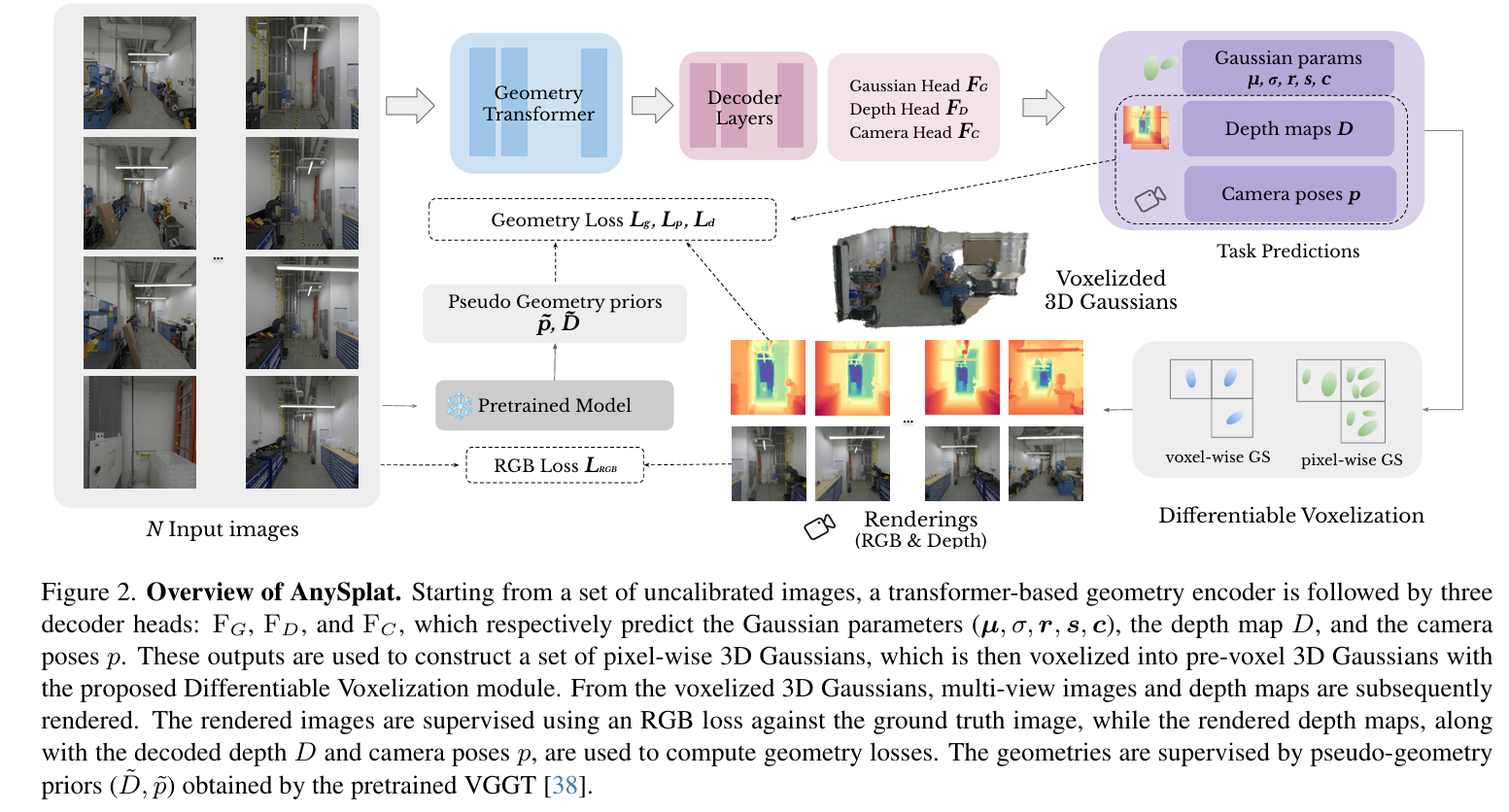
3.1 问题设定
输入 N 张无标定图像,输出:
- 一组 3D Gaussians (中心、透明度、方向、尺度、SH颜色系数)。
- 每张图像的相机参数(内外参)。
3.2 网络结构与流程
几何 Transformer: 基于 VGGT,提取多视角特征,带相机 token 与 register token。
解码头:
Camera Head:预测相机参数。
Depth Head:预测深度图与置信度。
Gaussian Head:预测每像素的 Gaussian 参数(中心由深度+相机投影得到)。
可微体素化 (Differentiable Voxelization):将像素级 Gaussians 聚合到体素级,减少 30–70% 冗余,提高效率与稳定性。
3.3 训练与推理
几何一致性损失:强制预测深度与渲染深度对齐,避免几何层叠伪影。

知识蒸馏:从预训练 VGGT 蒸馏相机与几何先验,增强稳定性。

训练目标:RGB 损失 + 几何损失 + 蒸馏损失。
【AnySplat 采用自监督训练方法进行训练,无需任何 3D 监督。】
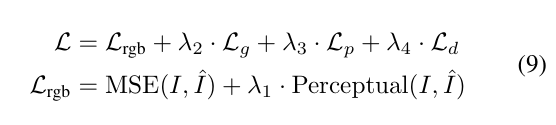
推理:单次前向即可输出完整结果;可选后优化进一步提升质量。
实验

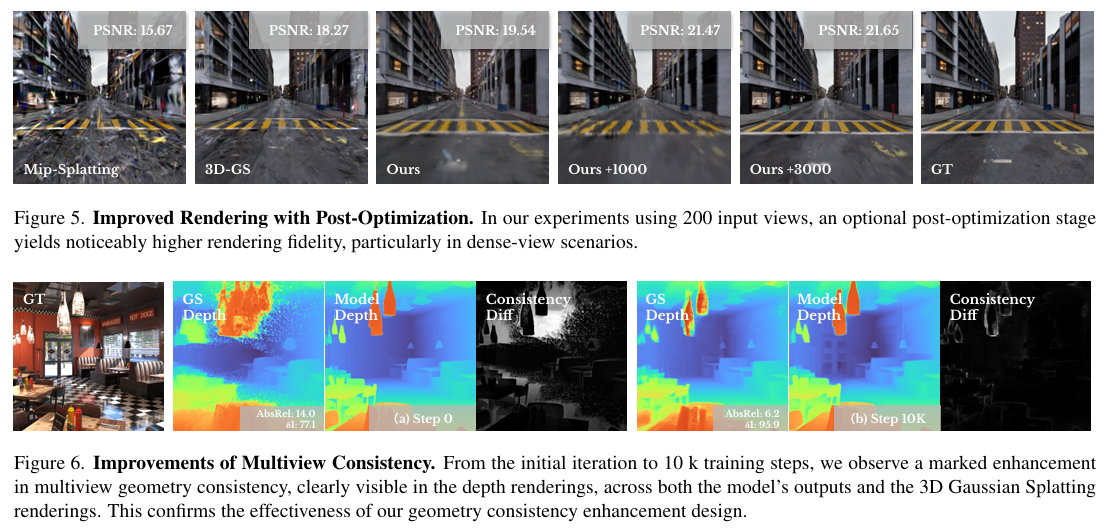
一些其他的FFD-3DGS方法(不依赖VGGT)
| 方法 | 主要任务 | 前向/是否逐场景优化 | 输入假设(训练/推理) | 对外部先验/基础模型的依赖 |
|---|---|---|---|---|
| PF3plat | 从无姿态稀疏图像做新视图合成(直接生成像素对齐 3DGS) | 单次前向;训练/推理都不需要GT位姿或深度;不做逐场景优化。 | 仅需未配准多视图(需相机内参,用于像素反投影成高斯中心)。 | 用单目深度与对应点的现成模型做“粗对齐”,随后再可微细化(深度/位姿)。 |
| DrivingForward | 驾驶场景环视输入 → 前向重建与渲染(像素对齐 3DGS) | 训练学到先验;推理只前向(深度网+高斯网);不做逐场景优化。 | 稀疏环视帧、帧数可变;训练时自监督学“真实尺度深度”;推理单帧/多帧皆可。 | 不依赖LiDAR/外参标注;仅RGB,自监督学习尺度一致性。 |
| ZPressor | 给任意前向3DGS骨干做“视图维压缩/扩展能力增强” | 一次前向的可插拔模块(锚-支持视图压缩到潜变量 Z),不改变前向范式;无逐场景优化。 | 多视输入(可很密集);把各视图特征压到少量“锚视图”上再预测高斯。 | 与骨干无关,可直接插到 pixelSplat/MVSplat/DepthSplat 等。 |
| FCGS(Fast Feedforward 3DGS Compression) | 压缩已训练好的 3DGS(而非重建) | 前向压缩(autoencoder + 上下文熵模型),不需要逐场景微调;秒级完成压缩。 | 输入是现成3DGS(无论它来自优化式还是前向式生成),直接前向得到码流。 | 不依赖外部基础模型;关键在 MEM 多路径熵 与 Inter/Intra-Gaussian 上下文建模。 |
| 方法 | “前向3DGS”的关键实现 | 扩展性/鲁棒性 | 指标与速度/内存(示例) | 主要局限 |
|---|---|---|---|---|
| PF3plat | 粗对齐:单目深度+对应点→鲁棒相对位姿;细化:可微深度/位姿残差;几何置信度 S_geo 以条件化预测不透明度/协方差/颜色,误差可回流到几何。 | 天然支持 N-view 扩展(>2 视图),场景/数据集泛化良好。 | 对 RE10K/ACID/DL3DV,较 CoPoNeRF +4 dB PSNR;推理 2 视→单视渲染 ≈0.39s;也优于优化式基线。 | 大基线/天空等弱纹理场景仍具挑战;粗对齐质量影响上限。 |
| DrivingForward | 尺度感知定位学“真实尺度深度”→像素对齐定位高斯中心;各图像独立预测其余高斯参数;端到端可微训练,推理仅保留深度网+高斯网前向一次。 | 帧数可变环视输入;弱重叠也稳;仅 RGB、无 LiDAR/外参标注。 | 6×352×640 环视设置:推理更快、画质更优;无“尺度感知”将 PSNR 大幅下降(消融)。 | 场景特化(驾驶),在极端动态/恶劣天气下仍需更多鲁棒性验证。 |
| ZPressor | 视图维信息瓶颈:FPS 选“锚视图”,其余为“支持视图”;交叉注意力把支持特征压到锚→紧凑潜变量 Z→原像素对齐高斯头。架构无关/即插即用。 | 把前向3DGS可扩到100+视 @480p (80GB);密集视图下显著更稳。 | RE10K:DepthSplat + ZPressor 在 36 视 +4.65dB,耗时↓≈70%/显存↓≈80%;pixelSplat 原本 >8 视 OOM,加 ZPressor 后可跑且更好。 | 属“中间件”范式:需与前向骨干搭配;若骨干本身定位不准,压缩不能单独修复几何误差。 |
| FCGS | Autoencoder + 上下文熵模型:几何属性走保真通道,颜色可走压缩通道(MEM);Inter/Intra-Gaussian 上下文建模消除冗余;单次前向压缩现有 3DGS。 | 可压缩优化式或前向式生成的 3DGS(例如 MVSplat/LGM 的结果)。 | 报告20×+ 压缩比且优于多数逐场景压缩方法;秒级完成压缩。 | 目标是“码率-失真”而非提升重建几何;对输入 3DGS 的质量有依赖。 |