【LINUX网络】UDP协议基础原理
在已经简单实现了UDP\TCP\HTTP的简单服务之后,我们重谈一些理论内容,理解UDP和TCP的底层。UDP比TCP简单很多,我们逐步学习。
1. 重新理解端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序;
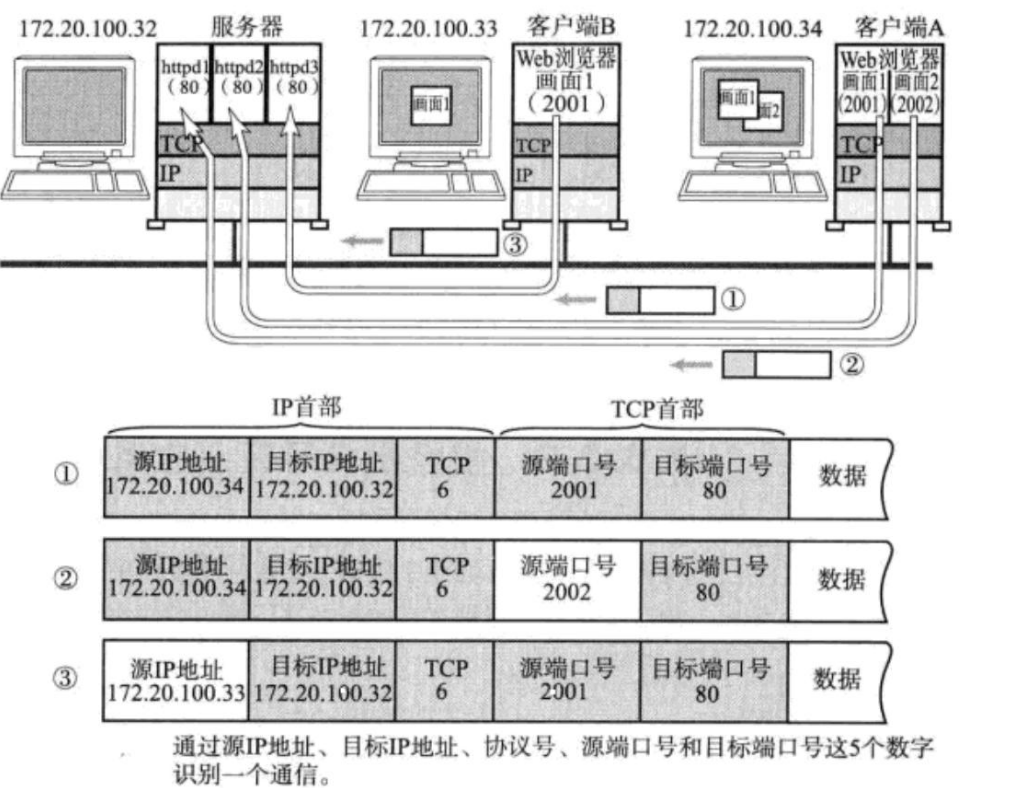
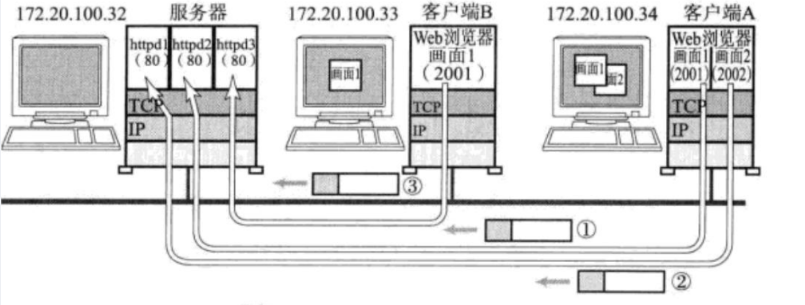
在 TCP/IP 协议中, 用 "源 IP", "源端口号", "目的 IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信(可以通过 netstat -n 查看)
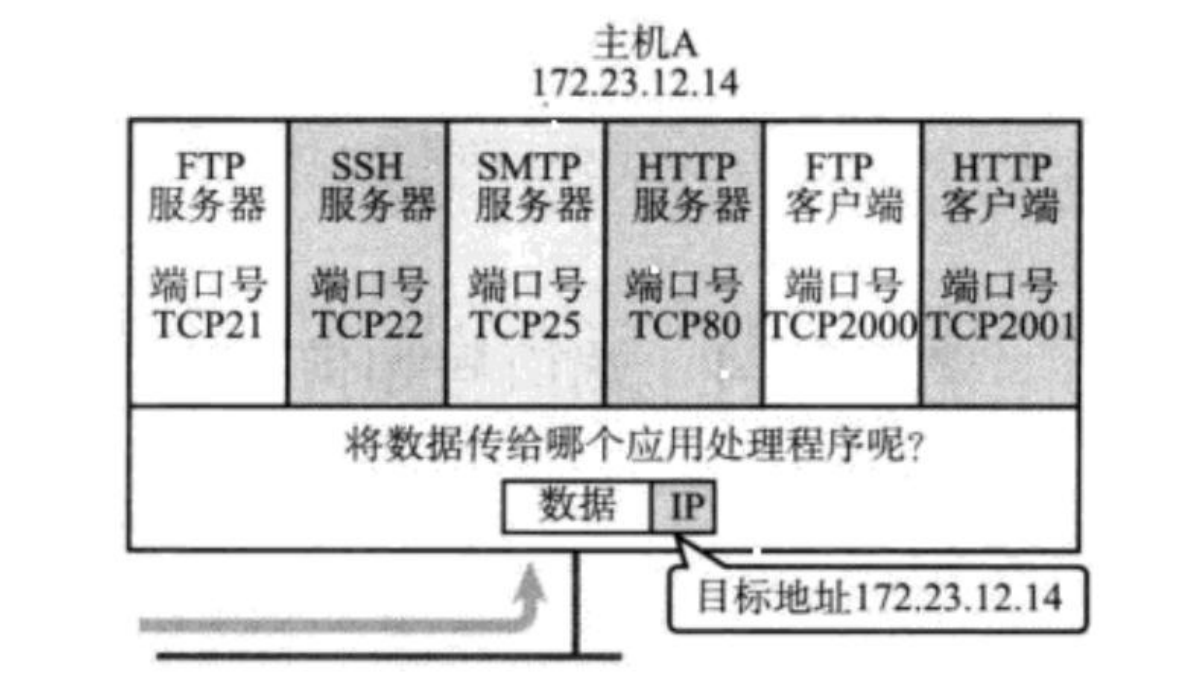
什么是协议号?
协议号(Protocol Number)是 IP 数据报中的一个字段,用于标识该数据报所使用的传输层协议。它是一个 8 位的数字,位于 IP 数据报的头部。
常见的协议号
TCP(传输控制协议):协议号为 6。TCP 是一种面向连接的、可靠的、基于字节流的传输层通信协议,广泛用于互联网中的数据传输。
UDP(用户数据报协议):协议号为 17。UDP 是一种无连接的、不可靠的传输层协议,适用于对实时性要求较高的应用,如视频流、语音通信等。
ICMP(互联网控制消息协议):协议号为 1。ICMP 主要用于发送错误消息和相关信息,帮助网络管理员诊断网络问题,例如
ping命令就是基于 ICMP 协议实现的。
帮助读者复习一下:
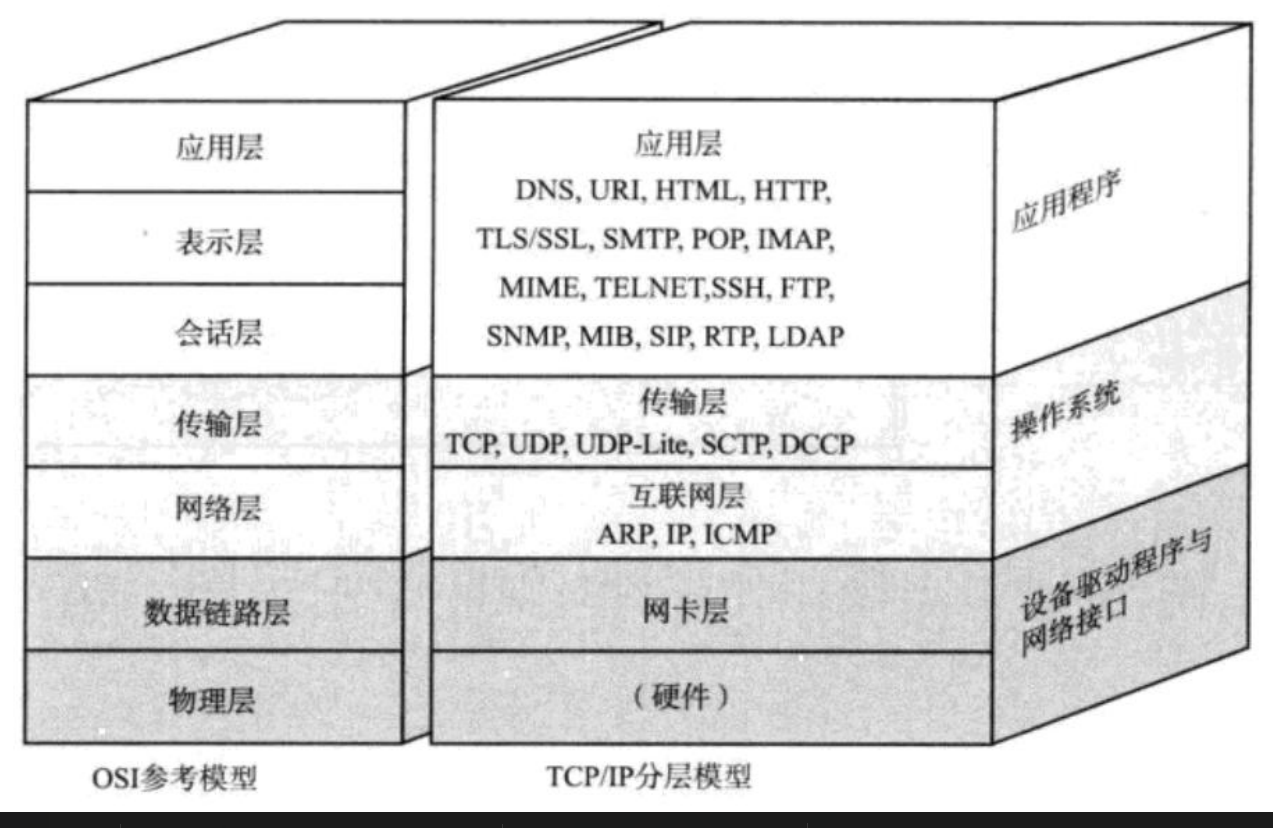
对于TCP/IP协议簇,一般我们只讨论:应用层、传输层、网络层。UDP和TCP是共同位于传输层的协议,传输层主要是负责两台主机之间数据的收发
如上图,今天有三个http请求,客户端B一个,A两个
可以让服务器根据AB端口号不一致区分是B的请求还是A的请求,可以通过Port知道要去的服务器端口或者是是客户端的哪个port发出来的。
0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的端口号都是固定的.•1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的
2. UDP结构
从两个问题引入:
一个进程是否可以 bind 多个端口号?可以,一个进程可以绑定多个端口号。这在实际应用中是比较常见的,尤其是在多线程或多进程的服务器程序中。例如,一个服务器进程可能需要监听多个不同的服务端口,以提供不同的服务。
假设你有一个 Web 服务器进程,它可能需要监听以下端口:
80:用于 HTTP 服务。
443:用于 HTTPS 服务。
8080:用于开发环境中的 HTTP 服务。
一个端口号是否可以被多个进程 bind?一般情况下不可以,在大多数操作系统中,一个端口号在同一时间只能被一个进程绑定。如果尝试让多个进程绑定同一个端口号,操作系统会拒绝后续的绑定请求,并返回一个错误
很类似于函数的概念,端口号是一种x自变量,进程是一个y因变量。同一个y可以被多个端口号映射,而一个x不能去映射多个y。
前置背景:
操作系统是C语言写的,所以协议都是结构体struct,不可能是class。
但是UDP的报文是一定需要被管理起来的,所以采用一个结构体管理:
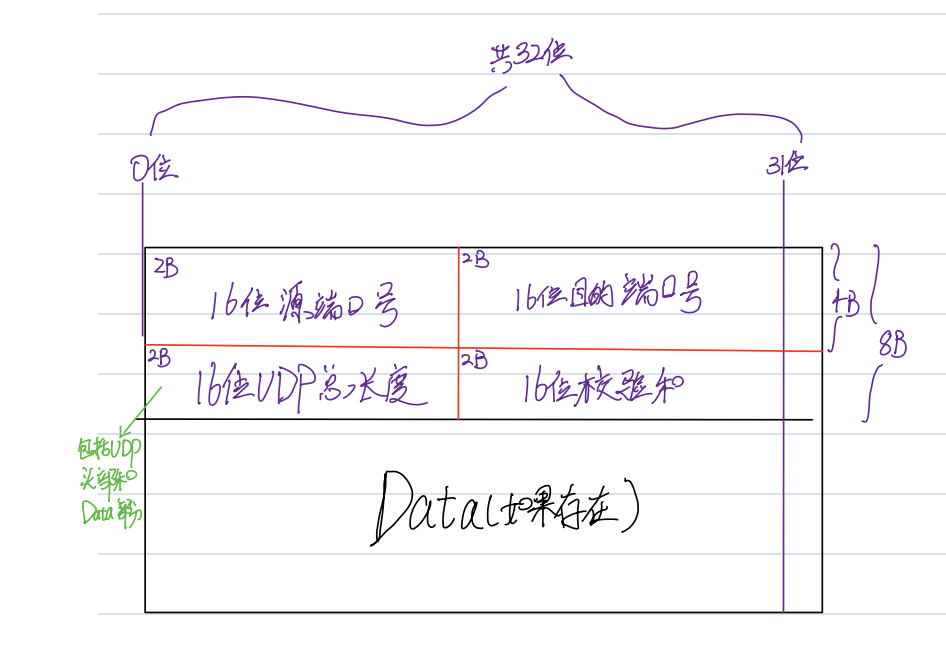
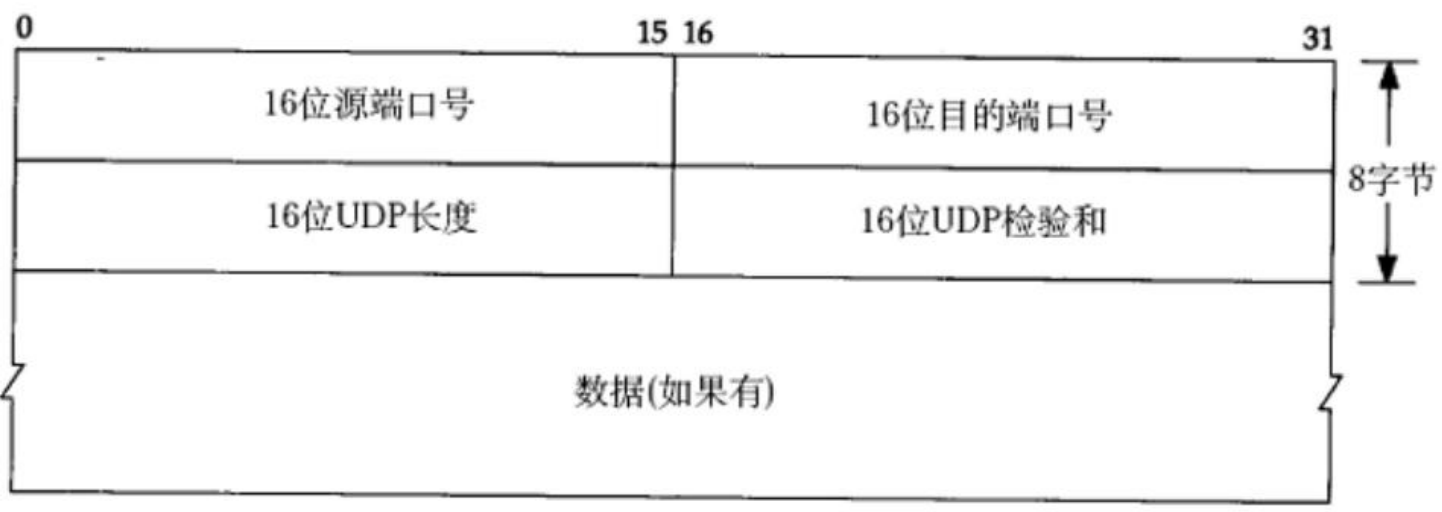
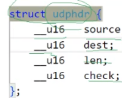
UDP的报头一共是4个双字节,也就是8B。因为UDP是应用层之下、网络层之上的协议,需要记录这个报文来自哪个端口(以及端口背后对应的进程xxxServer.cc)
16位源端口号,记录的就是发送这个报文的端口号;16位目的端口号记录的就是报文的目标主机的端口号。如果对之前的demo有印象的话,端口号我们使用的类型就是uint16_t(表示无符号的 16 位整数) 。
接着是16位UDP数据报的总长度以及16位的校验和。
发送方的校验和会将原来的UDP报头和一个伪报头相拼接,得到一个假数据报,经过一系列计算得到一个数并取反,接收方照着相同的办法计算,但是不取反,最后相加,检查是否为0。但UDP本身是一种无连接的、不可靠的传输协议,它本身不提供错误恢复机制。因此,当接收方发现校验和不匹配时,它只能根据应用层的逻辑来处理这种情况。
我们注意到, UDP 协议首部中有一个 16 位的最大长度. 也就是说一个 UDP 能传输的数据最大长度是 64K(包含 UDP 首部).然而 64K 在当今的互联网环境下, 是一个非常小的数字.如果我们需要传输的数据超过 64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装
3. 理解UDP在传输中的位置
之前讲过,网络每一层之间就是通过不停的解包和分用来垂直传递的。
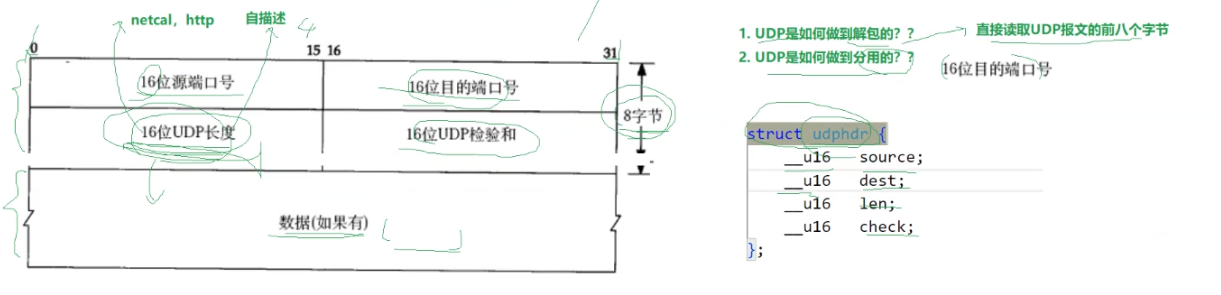
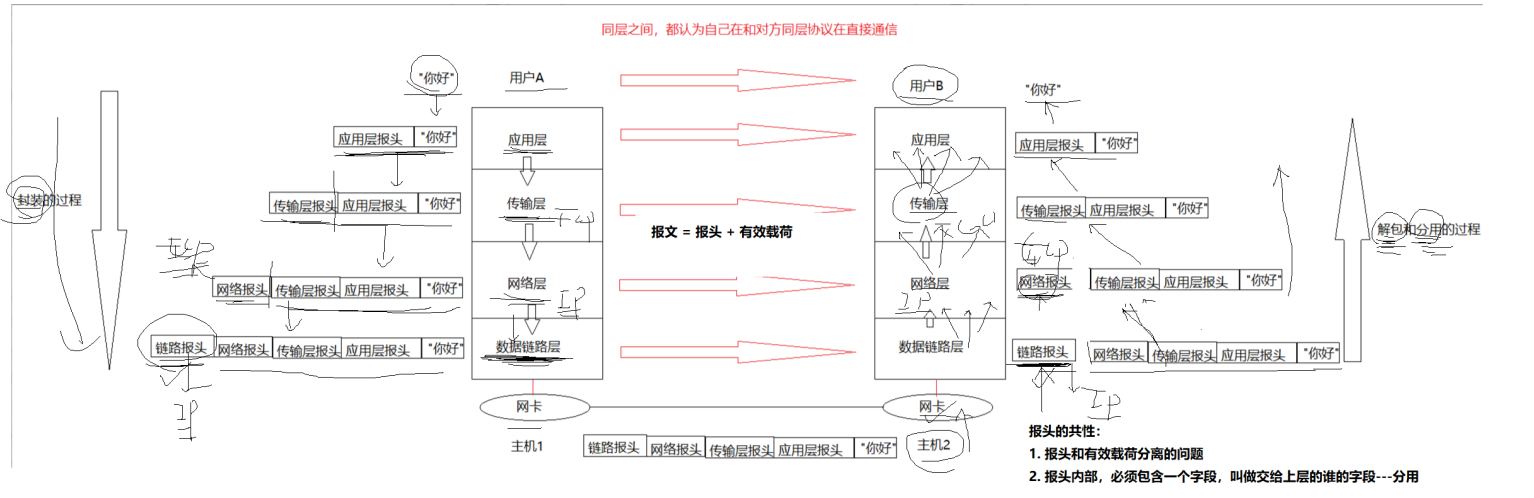
面对现在的UDP报头,我们可以理解:
1、之所以现在的报文里根本没有IP的数据,是因为IP的信息是在网络层才会封装进去的。
2、UDP的解包,就是直接读取前八个字节;分用(解包之后该往哪里传),就使用UDP报头中的第二个16位信息——目的端口即可。
学习底层代码不难发现,udp的header的确非常简单,并且确实是结构体。
4. sk_buff
1.
sk_buff的作用
sk_buff(socket buffer)是 Linux 内核中用于表示网络数据包的数据结构。它不仅存储了网络数据包的实际数据,还包含了与数据包相关的各种元数据,如数据包的长度、协议类型、时间戳等。sk_buff是网络协议栈中数据包处理的基础,贯穿了从网络设备驱动到协议栈各个层次的整个数据处理流程。操作系统为了管理这个sk_buff,采用的也是先组织、再管理,所以所有的sk_buff都是被一个双链表管理起来的。
2.
sk_buff的主要字段
sk_buff结构体定义在内核源码的include/linux/skbuff.h文件中。以下是一些重要的字段:
data和tail:
data:指向数据包数据的起始位置。
tail:指向数据包数据的结束位置。这两个指针用于管理数据包的实际数据部分。
head和end:
head:指向sk_buff分配的内存块的起始位置。
end:指向sk_buff分配的内存块的结束位置。这两个指针用于管理
sk_buff的内存分配范围。
next和prev:
用于将
sk_buff链接到链表中,便于批量处理数据包。3.
sk_buff的生命周期
sk_buff的生命周期从数据包的接收开始,贯穿整个网络协议栈,直到数据包被处理完毕并释放。3.1 数据包接收
当网络设备(如网卡)接收到一个数据包时,设备驱动程序会分配一个
sk_buff,并将数据包的数据复制到sk_buff的数据区域。然后,驱动程序将sk_buff提交给网络协议栈进行处理。3.2 协议栈处理
数据包在协议栈中逐层处理,每层协议(如链路层、网络层、传输层)都会对
sk_buff进行操作(分用和解包)。例如:
链路层会解析以太网头部。
网络层会解析 IP 头部。
传输层会解析 TCP 或 UDP 头部。
每层协议可能会修改
sk_buff的字段,如protocol和cb。3.3 数据包发送
当应用程序发送数据时,内核会创建一个
sk_buff,并将数据复制到sk_buff的数据区域。然后,协议栈逐层处理sk_buff,最终将其传递给网络设备驱动程序,由驱动程序将数据包发送到网络上。3.4 释放
一旦数据包处理完毕,
sk_buff会被释放,释放其占用的内存资源。4.
sk_buff的操作内核提供了许多函数来操作
sk_buff,以下是一些常见的操作:
数据操作:
skb_put(skb, len):在sk_buff的尾部添加len字节的空间,并将tail指针向前移动。
skb_pull(skb, len):从sk_buff的头部移除len字节的数据,并将data指针向前移动。
skb_push(skb, len):在sk_buff的头部添加len字节的空间,并将data指针向后移动。链表操作:
skb_queue_head(queue, skb):将sk_buff添加到链表的头部。
skb_dequeue(queue):从链表的头部移除一个sk_buff
添加报头:
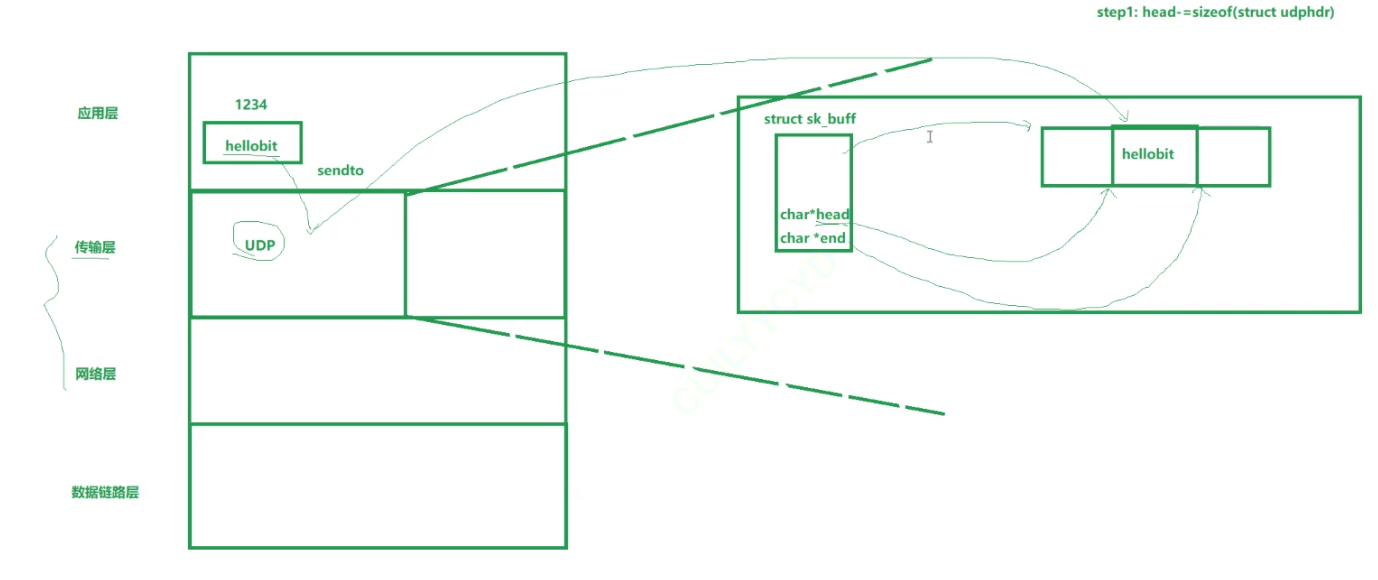
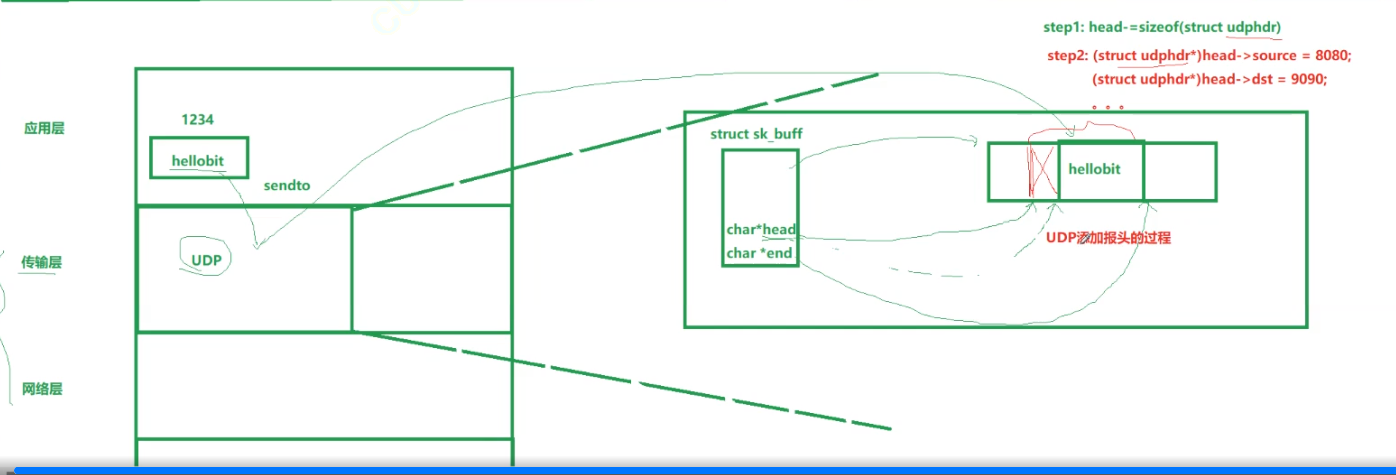
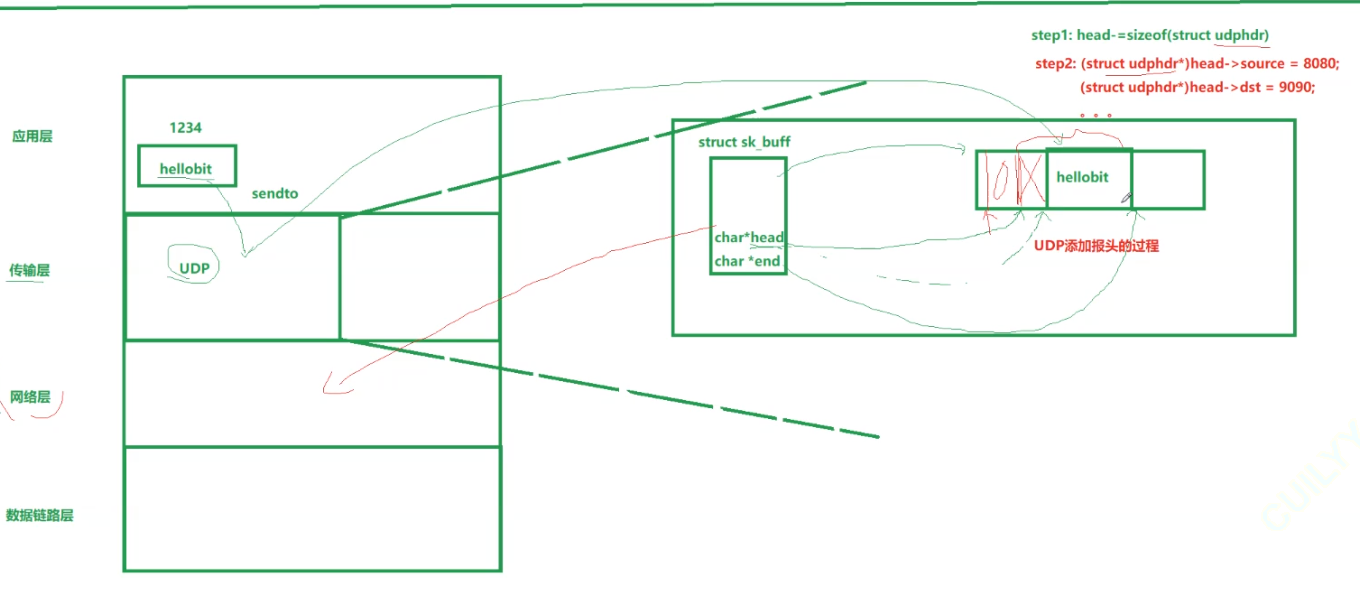
添加好报头之后就可以发往下一层:
5.UDP的特点
UDP 传输过程可以类比为寄信:
无连接特性
只需知道目标 IP 和端口号即可直接传输,无需预先建立连接。不可靠性
- 缺乏确认和重传机制
- 若因网络故障导致传输失败,UDP 协议层不会向应用层反馈任何错误信息(如刚刚的校验码错误但是依然依赖应用层)
面向数据报
无法灵活控制读写数据的次数和数量:
- 应用层交给 UDP 的报文会原样发送,既不拆分也不合并
- 示例:传输 100 字节数据时
- 发送端调用一次 sendto(100B)
- 接收端必须对应调用一次 recvfrom(100B)
- 不能分 10 次调用 recvfrom(每次 10B)
UDP 缓冲区机制
- 发送缓冲区:不存在真正意义上的发送缓冲区,调用 sendto 会直接交由内核处理
带来的坏处是:如果内核无法立即发送数据(例如,网络拥塞或套接字已关闭),数据可能会丢失;TCP拥有缓冲区,其实就是为了处理数据、暂存数据,保证数据不丢失。
- 接收缓冲区:用于存储收到的UDP报文
- 不保证报文接收顺序与发送顺序一致
- 缓冲区满载时,新到达的 UDP 数据将被丢弃
UDP socket 支持读写双向操作,这种特性称为全双工通信。
当然,在现实网络世界中,UDP没有想象的那么不可靠,并且也更简单一点。TCP既然需要保证连接不出错,一定会做更多工作,因此一定会更慢。
所以为了在一些需要效率并且又可以容忍一小部分数据丢失的情况下:比如视频和音频直播。画面出现抖动、马赛克等,就是UDP短暂的丢包了,这些都是可以接受的。