大模型之原理篇——Transformer基础、分词器
写在前面
本文主要介绍Transformer基础、如何简单查看大模型的层结构、分词器。由于网上资料比较多,这里只做我的简单理解。
Transformer基础
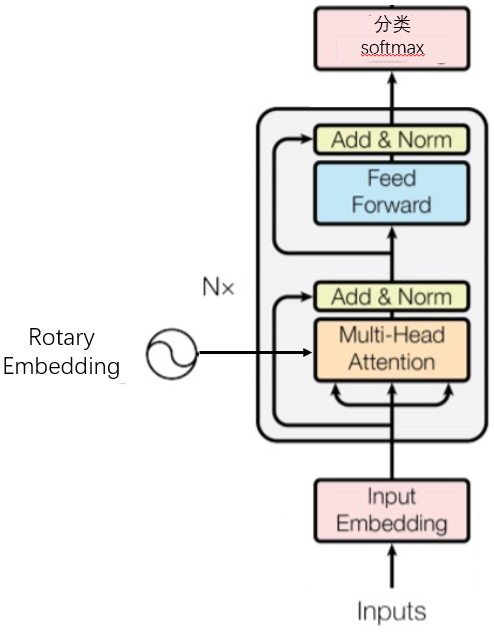
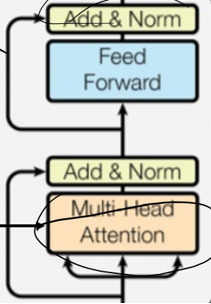
Transformer结构如下,llm一般都采用Transformer结构作为基础,稍加改变。中间包含了N个Transformer块,最左边是旋转自编码模块。
MHA
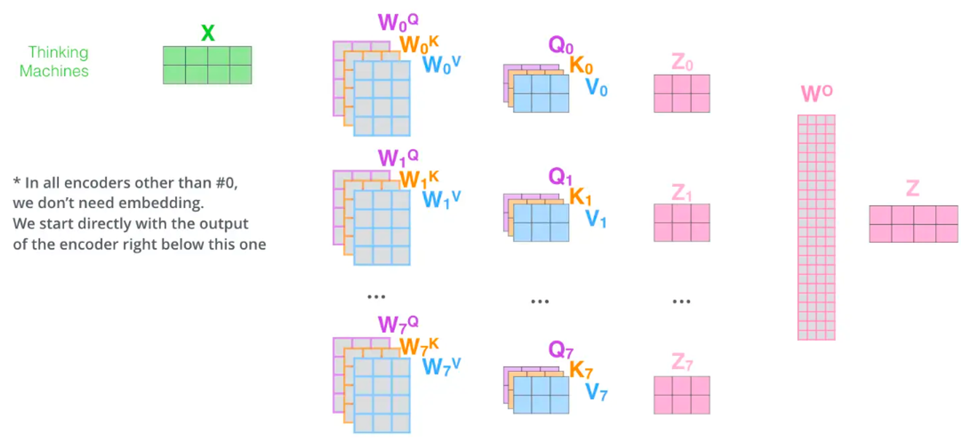
Attention 通过语义,找到上下文信息,通过不同的权重得到QKV矩阵,然后通过Z=X+Y的到输出矩阵,这里注意X Y Z的维度大小需要一致。
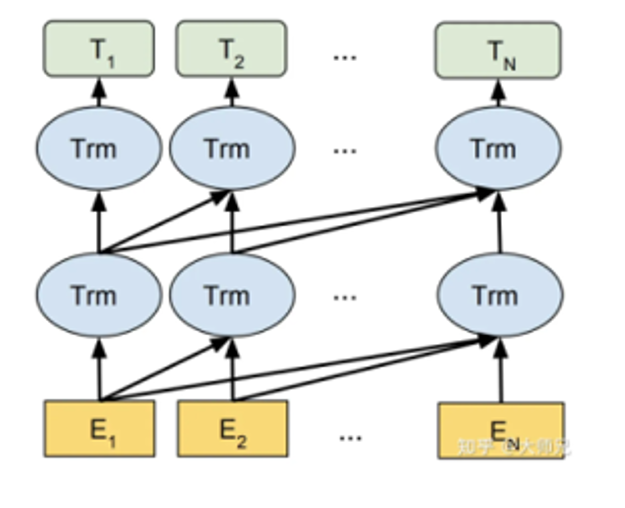
一般来说,Attention在计算时采用decode only,如下图,在生成式llm中是看不到后面的内容的,所以训练时只关心前面的内容。也有encode olny模型,比如bert模型。
激活函数
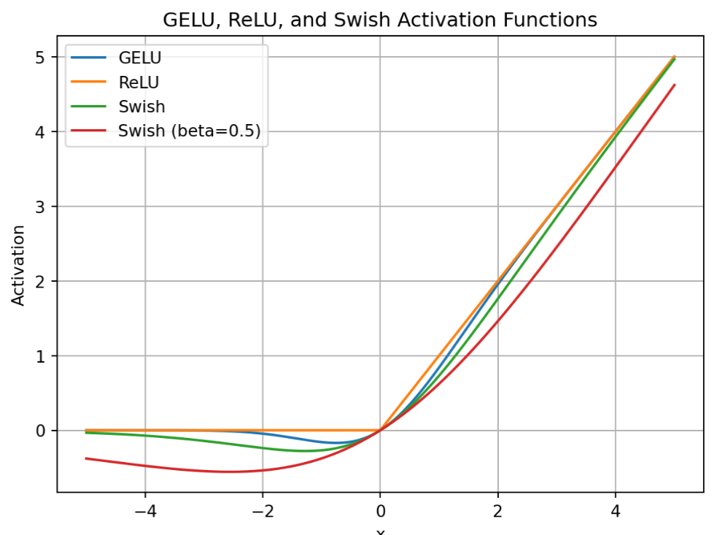
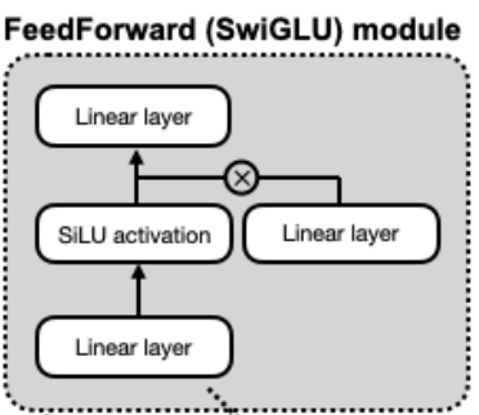
由于ReLU存在不可导的点,所以部分模型对激活函数会选取其变体,比如qwen3 llama deepseek都采用silu函数。
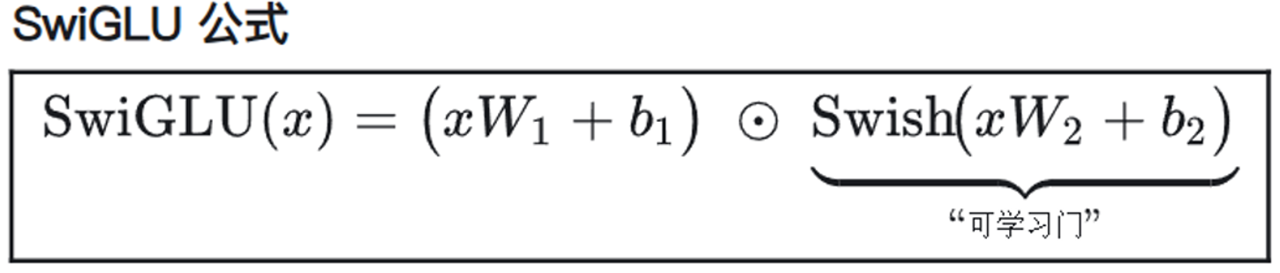
看懂大模型参数
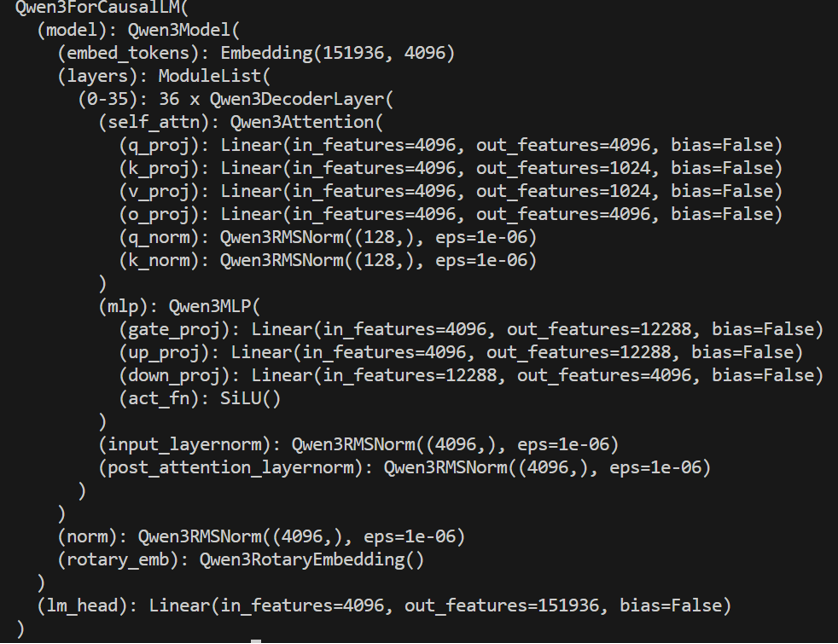
通过print(model)可以得到模型的参数信息,比如下图中,整个DecoderLayer代表下下图的,其中Qwen3Attrension代表MHA,MLP代表前向层 q\k\v 代表QKV矩阵,是拼接之后的,所以只有一个 o代表输出矩阵,MLP代表下下下图中的silu激活函数的三个线性层,激活函数是SiLu,两个Norm对应图中的两个norm层,emb代表旋转位置编码,在attensiong里面 输入输出都是4096的向量,但是最后转成了151936的向量,和输入的词表大小一致。
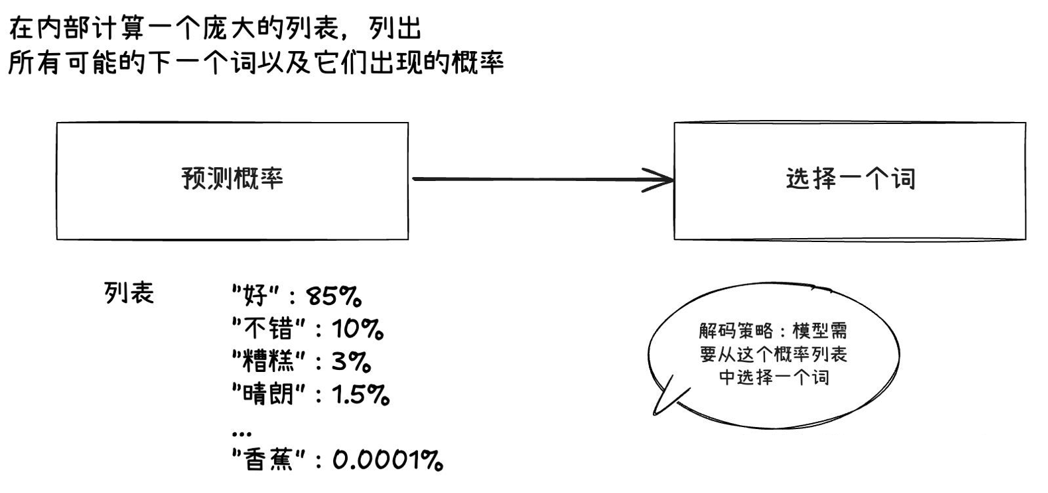
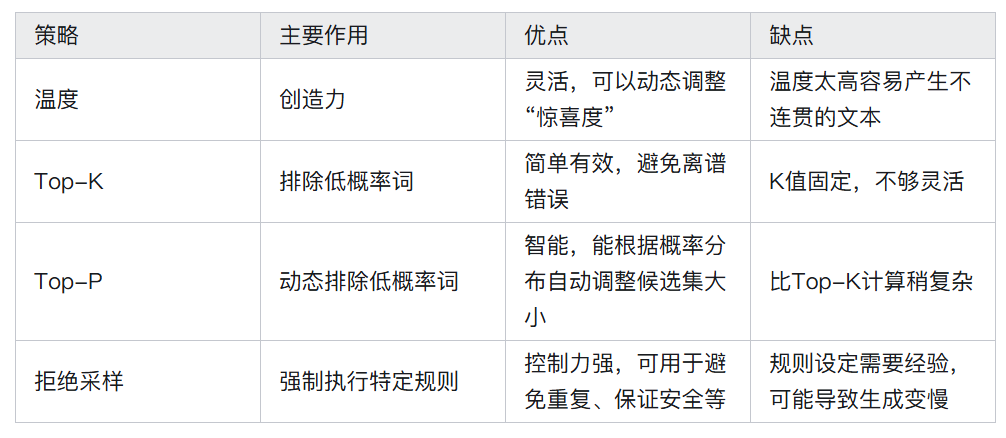
采样策略
贪心采样
通过transformer架构得到下个词的概率之后,如果选取最大概率预测词作为输出,输出会固定。比如说一个模型训练好了之后,参数固定,输入什么就会给定输出词的概率,然后取最大也是固定了。
top-K
top-K就是在前K个预测词中采样,但top-K 的一个缺点:K 值是固定的。有时候概率分布很“平”,我们可能需要一个很大的 K 值才能包含所有合理的选项;有时候概率分布很“尖”,可能前2个词就占了99%的概率,此时一个大的 K 值反而会纳入不必要的词。

引入温度参数
温度参数是下图中的T,引入之后T越大,总体的值会越平均,反之总值之间会拉的越开,所以T越大,预测词多样性会越多,幻觉问题越大,反之越保守。
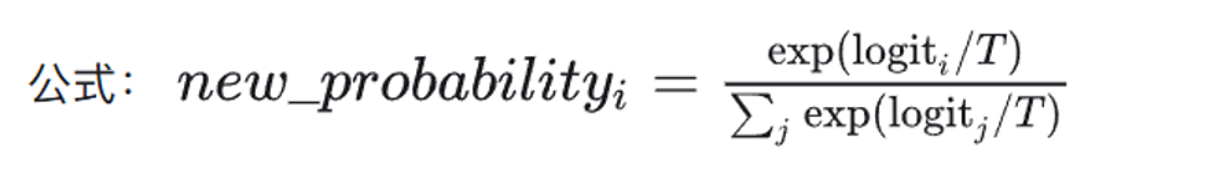
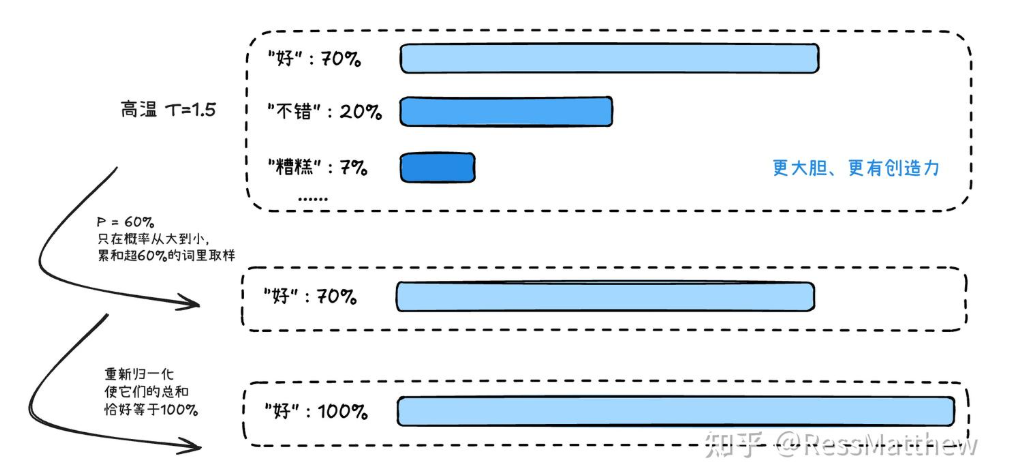
TOP-P
TOP-K是排名前K个值,也可以用概率大于P的值进行筛选,这个P值一般都很小很小,试想词表大小为1万,平均下来一个词的概率才万分之一,所以P值一般都很小很小。当前采用最多的还是TOP-P。
总结
分词方法
分词最开始的方法是BPE,但存在生僻字在词表中不存在的问题,后续都采用BBPE方法,这种方法对UTF-8的编码进行字节划分,UTF-8是包含了世界的语言,所以能够涵盖所有字体。这部分自行查找相关资料。
分词密度 = 字数/token数
词表越大,token密度越大,上下文长度越长,运行效率越慢