Python笔记 第三方库之Pandas的数据组合与缺失数据处理篇
第二章Pandas③篇!!!
数据组合
1.1 数据清理
1. 在动手进行数据分析工作之前,需要进行数据清理工作
每个观测值成一行
每个变量成一列
每种观测单元构成一张表格
2. 数据整理好之后,可能需要多张表格组合到一起才能进行某些问题的分析
一张表保存公司名称,另一张表保存股票价格
单个数据集也可能会分割成多个,比如时间序列数据,每个日期可能在一个单独的文件中
2.1 连接介绍
1. 组合数据的一种方法是使用“连接”(concatenation)
连接是指把某行或某列追加到数据中
数据被分成了多份可以使用连接把数据拼接起来
把计算的结果追加到现有数据集,可以使用连接
2.2 添加行-DataFrame连接
1. 加载多份数据,并连接起来
import pandas as pd# 读取三个CSV文件到DataFrame对象中
# 这里三个DataFrame都从同一个文件读取,实际使用中可能是不同的文件
df1 = pd.read_csv('data/concat_1.csv')
df2 = pd.read_csv('data/concat_1.csv')
df3 = pd.read_csv('data/concat_1.csv')# 打印三个DataFrame的内容到控制台
print(df1)
print(df2)
print(df3)2. 可以使用concat函数将上面3个DataFrame连接起来
需将3个DataFrame放到同一个列表中
# 将三个DataFrame按行进行拼接
# 使用pandas的concat函数将df1、df2、df3三个DataFrame在行方向上进行连接
row_concat = pd.concat([df1, df2, df3])# 打印拼接后的结果
print(row_concat)3. 通过 iloc ,loc等方法取出连接后的数据的子集
row_concat.iloc[3,]
row_concat.loc[3,]
2.3 添加行-DataFrame和Series连接
1. 使用concat连接DataFrame和Series
# 创建一个新的pandas Series对象,包含四个字符串元素
new_series = pd.Series(['n1', 'n2', 'n3', 'n4'])# 打印输出Series对象的内容
print(new_series)由于Series是列数据,concat方法默认是添加行,但是Series数据没有行索引, 所以添加了一个新列,缺失的数据用NaN填充
NaN是Python用于表示“缺失值”的方法
2. 如果想将['n1','n2','n3','n4']作为行连接到df1后,可以创建DataFrame并指定列名
# 创建一个新的DataFrame对象,包含一行数据
# 数据内容为['n1', 'n2', 'n3'],列名为['A', 'B', 'C', 'D']
# 注意:数据列数与列名数量不匹配,会导致创建的DataFrame中存在NaN值
new_row_df = pd.DataFrame([['n1', 'n2', 'n3']], columns=['A', 'B', 'C', 'D'])
print(new_row_df)2.4 添加行-append函数
1. concat可以连接多个对象,如果只需要向现有DataFrame追加一个对象,可以通过append函数来实现 df1.append(new_row_df)
# 将两个DataFrame进行追加操作并打印结果
# 该操作将df2的所有行添加到df1的末尾
print(df1.append(df2))# 将新的行数据追加到df1并打印结果
# new_row_df通常是一个包含新行数据的DataFrame
print(df1.append(new_row_df))2. 使用Python字典添加数据行
DataFrame中append一个字典的时候,必须传入ignore_index = True
# 创建一个字典,包含键值对数据
data_dict = {'A': 'n1', 'B': 'n2', 'C': 'n3', 'D': 'n4'}# 将字典数据追加到DataFrame中,忽略原始索引并重新生成索引
df1.append(data_dict, ignote_index=True)2.5 添加行-重置索引
1. 如果是两个或者多个DataFrame连接,可以通过ignore_index = True参数,忽略后面DataFrame的索引
# 将多个DataFrame按行拼接,并忽略原始索引
# 使用pd.concat函数将df1、df2、df3三个DataFrame进行垂直拼接
# ignore_index=True参数表示重新生成连续的整数索引,不保留原始索引
row_concat_ignore_index = pd.concat([df1, df2, df3], ignore_index=True)
print(row_concat_ignore_index)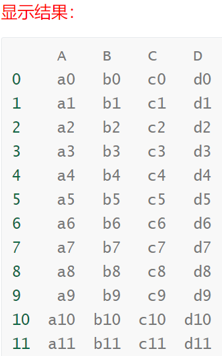
2.6 添加列-concat函数
1. 使用concat函数添加列,与添加行的方法类似
需要多传一个axis参数 axis的默认值是index 按行添加,传入参数 axis = columns 即可按列添加
# 将三个DataFrame按列进行拼接
# 使用pd.concat函数将df1、df2、df3三个DataFrame沿着列轴(axis=1)方向进行拼接
# 拼接后的结果存储在col_concat变量中,并打印输出
col_concat = pd.concat([df1, df2, df3], axis=1)
print(col_concat)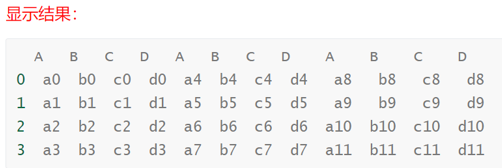
2. 通过列名获取子集
print(col_concat['A'])2.7 添加列-通过dataframe['列名'] = ['值']
1. 向DataFrame添加一列,不需要调用函数,通过dataframe['列名'] = ['值'] 即可
# 为DataFrame添加新的列数据
# 将列表['n1', 'n2', 'n3', 'n4']赋值给col_concat DataFrame的'new_col'列
col_concat['new_col'] = ['n1', 'n2', 'n3', 'n4']# 打印输出更新后的DataFrame
print(col_concat)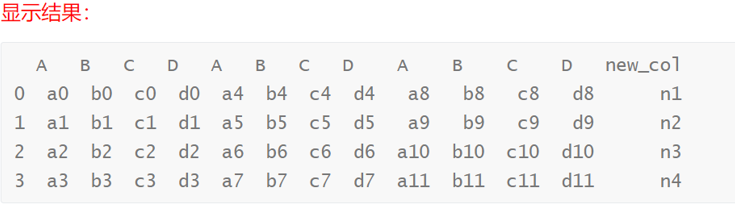
2.8 添加列-通过dataframe['列名'] = Series对象
1. 通过dataframe['列名'] = Series对象 这种方式添加一列
# 创建一个新的Series对象并赋值给DataFrame的new_col_series列
col_concat['new_col_series'] = pd.Series(['n1', 'n2', 'n3', 'n4'])# 打印输出更新后的DataFrame
print(col_concat)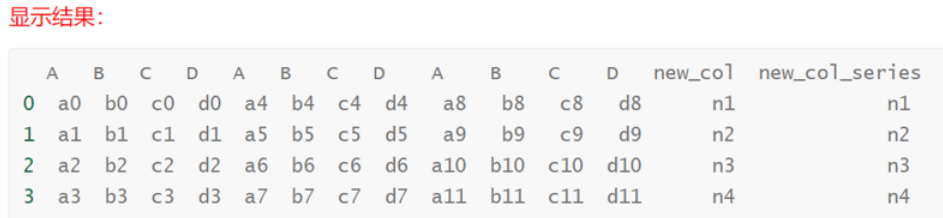
2.9 添加列-重置索引
1. 按列合并数据之后,可以重置列索引,获得有序索引
# 将三个DataFrame对象进行拼接操作
# 参数说明:
# [df1, df2, df3] - 需要拼接的DataFrame列表
# axis = 'colums' - 指定拼接轴为列方向
# ignore_index=True - 用于在数据操作后重置索引,让索引重新从 0 开始连续编号
# 返回值说明:
# 返回拼接后的DataFrame对象
print(pd.concat([df1, df2, df3], axis = 'colums', lgonre_index=True))
合并多个数据集
3.1 简介
1. 在使用concat连接数据时,涉及到了参数join(join = 'inner',join = 'outer')
2. 数据库中可以依据共有数据把两个或者多个数据表组合起来,即join操作
3. DataFrame 也可以实现类似数据库的join操作
4. Pandas可以通过pd.join命令组合数据,也可以通过pd.merge命令组合数据
5. merge更灵活,如果想依据行索引来合并DataFrame可以考虑使用join函数
3.2 加载数据
1. 从数据库加载数据
import sqllite3
# 连接到SQLite数据库文件
con = sqlite3.connect("data/chinook.db")
# 从数据库中查询tracks表的所有数据并加载到DataFrame中
tracks = pd.read_sql_query("SELECT * from tracks", con)
# 打印显示tracks数据的前5行
print(tracks.head())2. read_sql_query函数
从数据库中读取表,第一个参数是表名,第二个参数是数据库连接对象
# 从数据库中读取所有音乐流派信息并打印显示
# 该代码块执行以下操作:
# 1. 使用SQL查询从genres表中获取所有记录
# 2. 将查询结果存储在pandas DataFrame中
# 3. 打印显示查询到的流派数据
genres = pd.read_sql_query("SELECT * from genres", con)
print(genres)3.3 一对一合并
最简单的合并只涉及两个DataFrame——把一列与另一列连接,且要连接的列不含任何重复值
1. 先从tracks中提取部分数据,使其不含重复的'GenreId’值
# 从tracks数据集中选择指定索引的行,创建子集并打印输出
# 该代码块实现了数据子集的选择和展示功能
tracks_subset = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359],]
print(tracks_subset)2. 通过'GenreId'列合并数据,how参数指定连接方式
how = ’left‘ 对应SQL中的 left outer 保留左侧表中的所有key
how = ’right‘ 对应SQL中的 right outer 保留右侧表中的所有key
how = 'outer' 对应SQL中的 full outer 保留左右两侧侧表中的所有key
how = 'inner' 对应SQL中的 inner 只保留左右两侧都有的key
3. Left
# 将音乐流派信息与音轨信息进行关联合并
# 通过GenreId字段将genres数据框与tracks_subset数据框进行左连接
# 合并后的数据包含流派信息以及对应的音轨ID、流派ID和播放时长信息
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']],
on='GenreId', how='left')
print(genre_track)4. right
# 将genres数据框与tracks_subset数据框进行合并操作
# 通过GenreId字段进行右连接,保留tracks_subset中的所有记录
# 合并后的数据框包含TrackId、GenreId、Milliseconds和genre相关信息
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']],
on='GenreId', how='right')
print(genre_track)3.4 多对一合并
1. 使用tracks的全部数据
# 将genres数据框与tracks数据框进行左连接合并
# 通过GenreId字段关联两个数据框
# 保留tracks中的TrackId、GenreId和Milliseconds字段
genre_tracks = genres.merge(tracks[['TrackId', 'GenreId', 'Milliseconds']],
on='GenreId', how='left')# 打印合并后的结果
print(genre_track)2. 转换时间单位 如上面结果所示,Name的值在合并后的数据中被复制了
计算每种类型音乐的平均时长
to_timedelta 将Milliseconds列转变为timedelta数据类型
参数unit='ms' 时间单位 dt.floor('s') dt.floor() 时间类型数据,按指定单位截断数据
# 计算每个音乐流派的平均播放时长并进行格式化处理
#
# 该代码块执行以下操作:
# 1. 按音乐流派名称分组,计算每首歌曲的平均播放时长(毫秒)
# 2. 将平均时长转换为时间格式,向下取整到秒级别,并按时间长短排序
#
# 返回值:
# pandas.Series: 索引为音乐流派名称,值为格式化后的时间对象,按时间升序排列genre_time = genre_track.groupby('Name')['Milliseconds'].mean()
pd.to_timedelta(genre_time, unit='ms').dt.floor('s').sort_values()3. 计算每名用户的平均消费
从三张表中获取数据,用户表获取用户id,姓名
发票表,获取发票id,用户id
发票详情表,获取发票id,单价,数量
# 从数据库中读取客户信息,包含客户ID、名字和姓氏
cust = pd.read_sql_query("SELECT CustomerId,FirstName,LastName from customers",con)# 从数据库中读取发票信息,包含发票ID和对应的客户ID
invoice = pd.read_sql_query('SELECT InvoiceId,CustomerId from invoices',con)# 从数据库中读取发票项目信息,包含发票ID、单价和数量
ii = pd.read_sql_query('SELECT InvoiceId,UnitPrice,Quantity from invoice_items',con)
3.5 join合并
使用join合并,可以是依据两个DataFrame的行索引, 或者一个DataFrame的行索引另一个DataFrame的列索引进行数据合并
1. 加载数据
stocks_2016 = pd.read_csv('data/stocks_2016.csv')
stocks_2017 = pd.read_csv('data/stocks_2017.csv')
stocks_2018 = pd.read_csv('data/stocks_2018.csv')
2. 依据两个DataFrame的行索引
如果合并的两个数据有相同的列名,需要通过lsuffix,和rsuffix,指定合并后的列名的后缀
stocks_2016.join(stocks_2017, lsuffix='_2016', rsuffix='_2017', how='outer’)3. 将两个DataFrame的Symbol设置为行索引,再次join数据
stocks_2016.set_index('Symbol').join(stocks_2018.set_index('Symbol'),
lsuffix='_2016', rsuffix='_2018’)4. 将一个DataFrame的Symbol列设置为行索引,与另一个DataFrame的Symbol列进行join
stocks_2016.join(stocks_2018.set_index('Symbol'),lsuffix='_2016',
rsuffix='_2018',on='Symbol')缺失数据处理
介绍
1. 好多数据集都含缺失数据。缺失数据有多重表现形式
数据库中,缺失数据表示为NULL
在某些编程语言中用NA表示
缺失值也可能是空字符串(’ ’)或数值 在Pandas中使用NaN表示缺失值
1.2 NaN简介
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan,他们都一样 缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串,
1. 查看NaN,NAN,nan
from numpy import NaN.NAN,nan
print(NaN==True)
print(NaN==False)
print(NaN==0)
print(NaN=='')加载缺失值
2.1 缺失值来源
1. 缺失值的来源有两个
原始数据包含缺失值
数据整理过程中产生缺失值
2.2 加载包含缺失的数据
1. 加载数据时可以通过keep_default_na 与 na_values 指定加载数据时的缺失值
pd.read_csv('data/survey_visited.csv')
2. 加载数据,不包含默认缺失值
pd.read_csv('data/survey_visited.csv',keep_default_na = False)
3. 加载数据,手动指定缺失值
pd.read_csv('data/survey_visited.csv',na_values=[""],keep_default_na = False)
处理缺失值
3.1 加载数据
train=pd.read_csv('data/titanic_train.csv')test=pd.read_csv('data/titanic_test.csv')print(train.shape)print(train.head())
3.2 字段说明

3.3 查看数据
1. 查看是否获救数据
train['Survived'].value_counts()2. 检测数据集中每一列中缺失值的百分比
定义missing_values_table,计算每列缺失百分比
查看训练集缺失情况
# 调用missing_values_table函数计算训练数据集中的缺失值信息
train_missing = missing_values_table(train)# 打印训练数据集的缺失值统计结果
print(train_missing)查看测试集缺失情况
# 调用missing_values_table函数处理test数据集,检测并统计缺失值信息
test_missing = missing_values_table(test)# 打印缺失值统计结果
print(test_missing)训练集和测试集的缺失值比例基本相似
3.4 缺失值可视化
1. 导入模块import missingno as msno
2. 条形图
import missingno as msno# 生成训练数据缺失值分布的条形图
# 该代码使用missingno库的bar函数可视化数据集中各特征的缺失值情况
# 参数: train - 包含训练数据的DataFrame,其中可能包含缺失值
# 返回值: 返回一个matplotlib图表对象,显示各列缺失值的比例
print(msno.bar(train))条形图提供了数据集完整性的可视化图形。
我们可以看到“年龄”,“客舱号码”和“登船的港口”列包含值缺失
3.5 查看缺失值之间相关性
3. 数据缺失原因 通过计算缺失值间相关性判断缺失原因
msno.heatmap(train)
3.6 删除缺失值
1. 删除缺失值
删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值
2. 按行删除:删除包含缺失值的记录
train_1 = train.copy() 复制一份数据
train_1.dropna(subset=['Age'],how='any',inplace=True)
train_1['Age'].isnull().sum()
train_1.shape
3. 按列删除
当一列包含了很多缺失值的时候(比如超过80%),可以将该列删除,但最好不要删除数据
train_1.drop(['Age'],axis = 1).head()
3.7 填充缺失值
填充缺失值是指用一个估算的值来去替代缺失数
1. 非时间序列数据 使用常量来替换(默认值)
train_constant = train.copy()
train_constant.fillna(0,inplace = True)
train_constant.isnull().sum()
train_constant[train_constant['Cabin']==0].shape
2. 非时间序列数据
使用统计量替换(缺失值所处列的平均值、中位数、众数)
train_mean = train.copy()
train_mean['Age'].fillna(train_mean['Age'].mean(),inplace = True)
train_mean.isnull().sum()
3. 时间序列数据介绍
我们同样可以使用pandas的fillna来处理这类情况
用时间序列中空值的上一个非空值填充
用时间序列中空值的下一个非空值填充
线性插值方法
4. 时间序列数据
加载时间序列数据,数据集为印度城市空气质量数据(2015-2020)
city_day = pd.read_csv('data/city_day.csv',parse_dates=['Date'],index_col='Date')
city_day1=city_day.copy()
city_day.head()
用之前封装的方法,查看数据缺失情况
city_day_missing= missing_values_table(city_day)
city_day_missing
时间序列数据 数据中有很多缺失值,比如Xylene(二甲苯)和 PM10 有超过50%的缺失值 查看包含缺失数据的部分 city_day['Xylene'][50:64]
5. 时间序列数据
数据中有很多缺失值,比如Xylene(二甲苯)和 PM10 有超过50%的缺失值
查看包含缺失数据的部分
city_day['Xylene'][50:64]
6. 时间序列数据
使用ffill 填充,用时间序列中空值的上一个非空值填充
NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81 city_day.fillna(method='ffill',inplace=True)
city_day['Xylene'][50:65]
7. 时间序列数据
使用bfill填充,用时间序列中空值的下一个非空值填充
NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209
city_day.fillna(method='bfill',inplace=True)
city_day['AQI'][20:30]
8.时间序列数据
线性插值方法填充缺失值
时间序列数据,数据随着时间的变化可能会较大。
使用bfill和ffill进行插补并不是解决缺失值问题的最优方案。
线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系。
利用相邻数据点中的非缺失值来计算缺失数据点的值。
9. 时间序列数据
线性插值方法填充缺失值
city_day1.interpolate(limit_direction="both",inplace=True)
city_day1['Xylene'][50:65]
10. 其它填充缺失值的方法
除了上面介绍的填充缺失值的方法外,还可以使用机器学习算法预测来进行缺失值填充
后续再介绍用算法来填充缺失值的方法