语义分割开山之作:FCN网络从入门到精通
我们将分三部分来彻底搞懂全卷积网络(FCN, Fully Convolutional Network)。FCN可以说是现代图像语义分割领域的开山之作,理解它对于学习后续更复杂的网络至关重要。
我将从基础,深入,进阶三个部分进行讲解,现在,我们开始
第一部分:FCN基础 —— 它是什么,解决了什么问题?
在FCN出现之前,深度学习在计算机视觉领域最成功的应用是图像分类。像AlexNet、VGG这样的网络,你给它一张图片,它能告诉你图片里有什么,比如“猫”、“狗”或“汽车”。
1. 传统分类网络的“问题”
这些分类网络都有一个共同的特点:网络的最后几层通常是全连接层(Fully Connected Layers)。这些全连接层会把前面卷积层提取到的特征图(feature map)“压扁”成一个一维向量,然后通过这个向量来判断图片的类别。
这个“压扁”的动作有一个致命的缺点:它丢失了所有空间信息。换句话说,网络知道图片里有只猫,但它不知道这只猫在图片的哪个位置,它的轮廓是怎样的。
2. FCN要解决的新问题:语义分割(Semantic Segmentation)
我们想做的不仅仅是识别出图片里有什么,还想知道“什么东西在哪儿”。具体来说,我们希望网络能给图像中的每一个像素都分配一个类别。比如,在一张街景图片中,所有属于“汽车”的像素都被标记成蓝色,所有属于“道路”的像素都被标记成灰色,所有属于“天空”的像素都被标记成天蓝色。
这项任务就叫做语义分割。它的输出不再是一个简单的标签,而是一张与原图大小相同的分割图(Segmentation Map)。
3. FCN的核心思想:用卷积层取代全连接层
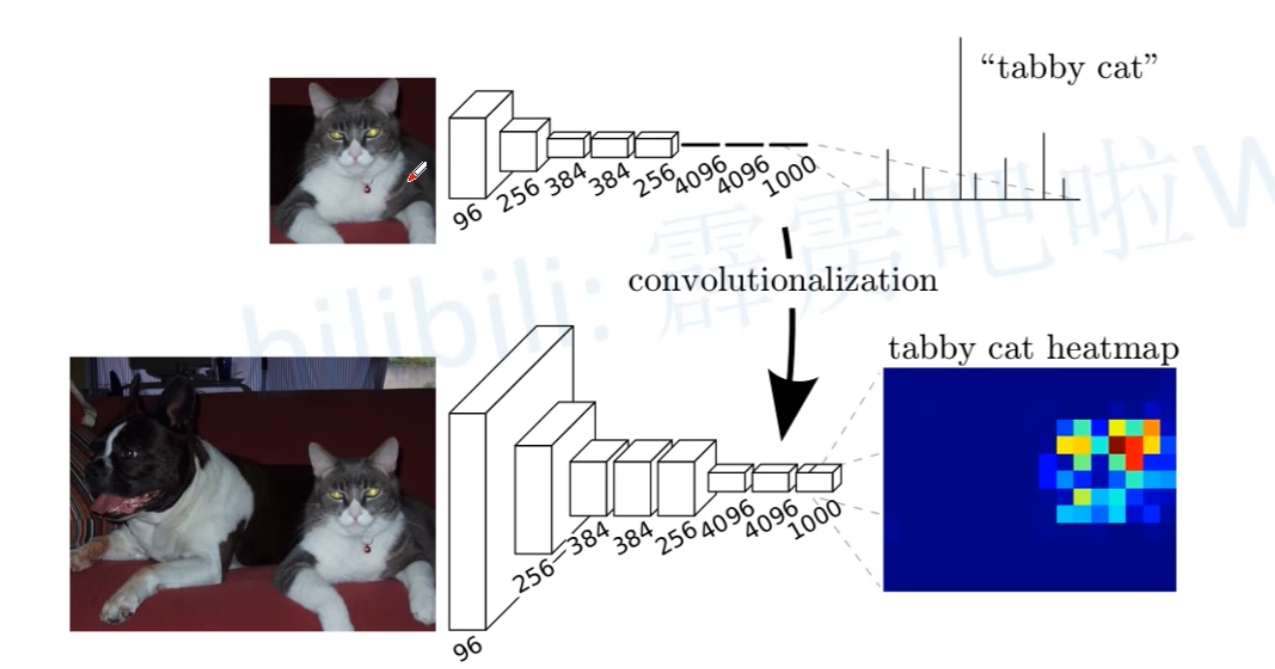
为了解决这个问题,FCN的作者们提出了一个革命性的想法:把分类网络最后的那些全连接层全部换成卷积层。
这就是“全卷积网络”这个名字的由来。
为什么要这么做? 因为卷积层可以保持特征图的空间结构。一个5x5的特征图经过卷积后,输出的还是一个2D的特征图,而不是一个被压扁的一维向量。
如何替换? 比如,一个需要4096个输入和1000个输出的全连接层,可以被一个核大小为1x1、输入通道为4096、输出通道为1000的卷积层完美替代。
通过这个改造,一个本来只能输出单一分类结果的VGG网络,现在可以输出一张粗糙的热力图(heatmap)。这张热力图上的每个“像素”都对应着原图一个区域的类别预测,从而保留了空间信息。
如图:上方为目标检测,下方为语义分割。
第一部分小结:
目标: FCN的目标是完成语义分割任务,即对图像中的每个像素进行分类。
痛点: 传统的分类网络(如VGG)因为最后的全连接层,会丢失空间信息,无法进行像素级别的预测。
核心创新: FCN将分类网络的全连接层替换为卷积层,使得网络能够接受任意尺寸的输入,并输出一张保留了空间信息的预测图(热力图)。
第二部分:深入FCN核心技术剖析
FCN的基本工作流程可以概括为:“编码器(下采样)→ 解码器(上采样)”。
编码器
作用: 提取图像的层次化特征(从低级边缘纹理到高级语义信息)。
结构: FCN直接迁移并改造当时成熟的图像分类网络(如VGG16, AlexNet, GoogLeNet)。移除其最后的全连接层,保留前面的卷积层和池化层。
改造过程(以VGG16为例):
原始VGG16有多个卷积块(每个块包含几个 3x3卷积层和 2x2最大池化层)和3个全连接层。
改造: 将最后3个全连接层(fc6, fc7, fc8)替换为对应的 1x1卷积层。
fc6(原 4096维全连接) → 替换为 4096个 1x1卷积核的卷积层。
fc7(原 4096维全连接) → 替换为 4096个 1x1卷积核的卷积层。
fc8(原 1000维输出) → 替换为 N个 1x1卷积核的卷积层(其中 N是分割的类别数+背景)。
输出: 经过改造后的网络(编码器)输入一张任意大小的图像(如 H x W x 3),会输出一个空间分辨率降低(缩小了 32倍,因为经过了5次 2x2池化)的特征图(如 (H/32) x (W/32) x N)。这个特征图中的每个像素位置(i, j),其通道向量(N维)可以看作是原图中以 (i*32, j*32)为中心的某个区域的语义分类分数。
问题: 这个输出尺寸太小(1/32),丢失了大量的空间细节信息,直接对其进行放大(插值)得到的分割图会非常粗糙。这就是FCN最初版本(FCN-32s)的问题。
解码器 与 上采样
为了得到和原图尺寸一致的分割结果,必须将编码器输出的低分辨率特征图上采样回原始分辨率。
简单上采样(FCN-32s):
直接将编码器输出的 1/32分辨率特征图(包含最高层语义信息)通过双线性插值(Bilinear Interpolation) 放大 32倍到原图尺寸。
缺点: 结果非常粗糙,物体的边界丢失严重。双线性插值无法恢复编码过程中丢失的细节信息。
改进:引入跳级连接(Skip Connections) (FCN-16s / FCN-8s):
核心思想: 融合编码器不同阶段的特征图(包含不同空间尺度和信息量)。
做法:
选择中间层: 利用编码器中(在多次池化之前)提取到的特征图。例如,VGG16的 pool4(步长为16,尺寸 1/16)和 pool3(步长为8,尺寸 1/8)包含更多的空间细节信息。
上采样与融合:
将深层的、高语义但低分辨率的特征图(如 1/32输出)通过转置卷积(Transposed Convolution / Deconvolution)(详见下文)上采样到 1/16分辨率。
将上采样后的特征图与浅层的、空间细节丰富但语义性稍弱的特征图(如 pool4)进行逐元素相加(Element-wise Addition) 或 通道拼接(Channel-wise Concatenation)。
对融合后的特征图进行一个或多个 1x1卷积(可选)来调整通道数或平滑特征。
对融合后的特征图再进行上采样(如从 1/16到 1/8),然后继续融合更浅层的特征(如 pool3),最后再上采样到原图尺寸。
效果: FCN-8s的效果最好,它融合了深层语义信息 (1/32层)、中层轮廓信息 (pool4) 和浅层细节信息 (pool3),输出的分割边界更精细准确。
1. 深入上采样(Upsampling)
既然特征图变小了,那我们自然要想办法把它再放大回原来的尺寸。这个过程就叫做上采样。
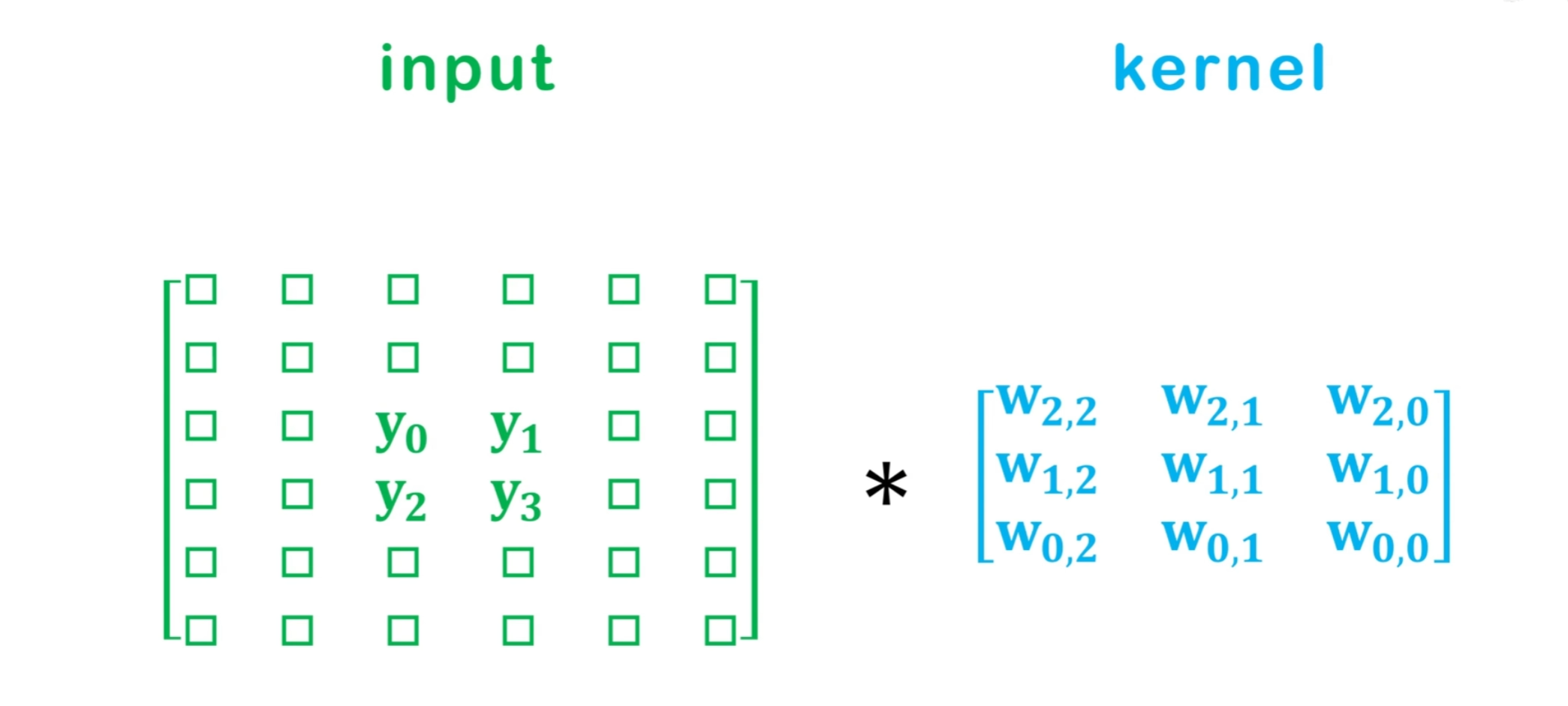
你可能会想,直接用传统的插值方法(比如双线性插值)放大不就行了吗?可以,但这不够“智能”。FCN采用了一种更巧妙的方法,叫做转置卷积(Transposed Convolution),有时也被(不准确地)称为反卷积(Deconvolution)。
它本质上还是一个卷积操作,但它通过巧妙的方式实现了放大的效果。我们可以理解为两个步骤:
第一步:填充与“扩张” 在输入的低分辨率特征图的像素之间,以及图像的周围,插入大量的0进行填充(padding)。这个步长(stride)决定了放大的倍数。例如,如果上采样倍数为2,就在每两个像素之间插入一个像素(值为0)。
第二步:标准卷积 在“扩张”后的特征图上,进行一次标准的卷积操作。
举个简单的例子:
假设我们有一个2x2的输入特征图,想用一个3x3的卷积核将它上采样到4x4。
扩张输入:首先在2x2输入的像素之间和周围插入0,将其变成一个更大的中间特征图。
卷积:然后用3x3的卷积核在这个扩张后的特征图上进行滑动计算。因为卷积核的尺寸大于1,它的计算会覆盖到那些插入的0,从而在输出中“创造”出新的、被插值的信息。
关键点:转置卷积核里的那些权重,和普通卷积核一样,都是通过反向传播学习得到的。这意味着网络会自己学会“什么才是最好的放大图像细节的方式”,而不是使用固定不变的插值算法。
如图
2. 深入跳跃连接(Skip Connections)
仅仅把粗糙的、充满语义信息的深层特征图放大,得到的结果依然会很模糊,物体的边缘会像打了马赛克一样不清晰。
为了解决这个问题,FCN的作者们想出了一个绝妙的主意:把不同深度的特征图融合起来
浅层特征(比如网络前面的卷积层输出):分辨率高,包含丰富的空间细节,如边缘、角点等信息。但它不知道这些边缘属于什么物体。
深层特征(比如网络后面的卷积层输出):分辨率低,空间细节模糊。但它有很强的语义信息,知道图像区域对应的是“人”还是“车”。
跳跃连接就是一座桥梁,它将浅层的高分辨率、细节丰富的特征图,直接“跳跃”到后面,与经过上采样的深层特征图进行融合(通常是相加)。
我刚才说“将浅层特征与深层特征进行融合”。但这里有一个非常重要的问题:它们的尺寸和通道数都不一样,怎么融合?
这正是实现的细节所在:
尺寸对齐:深层特征图(如 pool5 的输出)尺寸小,浅层特征图(如 pool4 的输出)尺寸大。在融合前,必须先将深层特征图上采样,使其尺寸与浅层特征图完全一致。例如,在FCN-16s中,pool5 的输出要先经过一个2倍的转置卷积,放大到和 pool4 一样大。
通道对齐:不同层的特征图通道数也不同。例如在VGG中,pool4 的输出是512个通道,而 pool5 经过分类层改造后可能是21个通道(假如是PASCAL VOC数据集,20个类别+1个背景)。你不能把一个512通道的张量和一个21通道的张量直接相加。
解决方案:在浅层特征图(如 pool4)上也接一个1x1的卷积层。这个1x1卷积的作用就是“降维”或“升维”,它不改变特征图的长宽,只改变通道数,将其调整到与要融合的深层特征图的通道数完全一致。
逐元素相加(Element-wise Addition):在尺寸和通道都对齐后,就可以将两个张量对应位置的元素直接相加了。这样,深层的语义信息和浅层的空间信息就真正地融合在了一起。
所以,FCN-16s的完整流程是:
pool5 -> 2x上采样 -> 得到 A
pool4 -> 1x1卷积调整通道 -> 得到 B
融合结果 = A + B3. FCN是如何学习的?—— 像素级的损失函数 (Pixel-wise Loss)
我们知道,FCN的最终输出是一张 (H, W, C) 的分割图,其中 H 和 W 是图像高宽,C 是类别总数。这张图的每一个像素 (i, j) 位置上,都有一个长度为 C 的向量,代表该像素属于每个类别的分数(score)。
那么,如何判断它预测得对不对呢?
这就需要用到像素级的交叉熵损失(Pixel-wise Cross-Entropy Loss)。
它的工作方式是:
1.对网络输出的 (H, W, C) 分数图,在每个像素 (i, j) 上都独立进行一次 Softmax 操作,将分数向量转换成概率向量。
2.我们有一个同样大小的真值标签图(Ground Truth),尺寸为 (H, W)。这张图的每个像素 (i, j) 的值就是一个整数,代表这个像素的真实类别(比如0代表背景,1代表猫,2代表狗...)。
3.然后,计算网络预测的概率图和真值标签图之间的交叉熵损失。这个过程是逐个像素独立计算的,最后再将所有像素的损失求和或求平均,得到整个图像的最终损失值。
4.根据这个最终的损失值,进行反向传播,更新网络中所有卷积核(包括转置卷积核)的参数。
第三部分:进阶篇 —— FCN的局限与演进
一、 审视FCN的局限性
FCN作为开山之作,无疑是伟大的,但它也并非完美。正是它的这些不足,为后来的研究指明了方向。
1.分割结果不够精细 (Coarse Segmentation) 尽管有跳跃连接,但FCN的上采样过程依然是比较“粗暴”的。从一个缩小了8倍的特征图直接放大8倍恢复细节,很多精细的边界信息其实已经永久丢失了。这导致FCN的分割结果在物体边缘处通常比较模糊、粗糙,无法做到像素级别的完美贴合。
2.对上下文信息的理解不足 (Lack of Global Context) FCN中每个像素的预测主要依赖于其周围的局部信息(即卷积核的感受野)。这会导致一些问题。比如,把沙发上的一块黄色靠垫误识别成“香蕉”,因为从局部看它们的纹理和颜色可能相似。如果网络能拥有更大的感受野,看到“靠垫”是在“沙发”上,就更容易做出正确的判断。FCN缺乏一个有效的机制来聚合多尺度的上下文信息。
3.无法区分同类别的不同实例 (No Instance Awareness) 这是FCN一个根本性的任务限制。它做的是语义分割,不是实例分割。这意味着,如果图片上有三只猫紧挨在一起,FCN只会告诉你“这些像素都属于猫”,输出一整块“猫”的掩码。它无法告诉你这里有“猫A”、“猫B”和“猫C”三个独立的个体。
二、 继往开来:FCN如何启发了后世的模型
正是为了解决上述局限,CV(计算机视觉)社区涌现出了一系列优秀的后续工作。
U-Net:为更精细的边缘而生
解决问题:分割结果不够精细。
核心思想:U-Net针对医学图像分割(如细胞分割)这种对边缘精度要求极高的场景设计。它提出了一个优美的对称U型编解码结构。在左侧的编码器(下采样)路径中,每一层的特征图都被通过一个超大带宽的跳跃连接,直接拼接(Concatenate)到右侧解码器(上采样)路径中相对应的层。
相比FCN的进步:FCN的跳跃连接只是浅尝辄止地融合了2-3层,而U-Net则是在每一个尺度上都进行了彻底的、深度的特征融合,这使得解码器在恢复图像尺寸的每一步,都有最原始、最丰富的细节信息作为参考,因此分割边缘极其清晰。
DeepLab系列:扩大视野,理解全局
解决问题:对上下文信息的理解不足。
核心思想:DeepLab系列引入了空洞卷积/带孔卷积(Atrous/Dilated Convolution)。这种卷积允许在不增加计算量和参数的情况下,指数级地扩大卷积核的感受野。你可以想象成一个“打了孔”的卷积核,它跳过了一些像素去采样,从而能看到更广阔的区域。
相比FCN的进步:通过并联多个不同“空洞率”的空洞卷积(这个结构被称为ASPP, Atrous Spatial Pyramid Pooling),DeepLab可以在同一个像素位置上,同时捕捉到近处的细节、中距离的区域和远处的全局背景信息。这极大地减少了因缺乏上下文而导致的误判。
Mask R-CNN:从语义分割到实例分割的飞跃
解决问题:无法区分同类别的不同实例。
核心思想:Mask R-CNN巧妙地将目标检测和语义分割结合起来,是一个两阶段(Two-Stage)的方法。
第一阶段 (Region Proposal):先用一个网络(RPN)找出图中所有可能存在物体的候选框(Bounding Box)。
第二阶段 (Classify & Mask):对每一个候选框,再用一个网络分支去判断框里物体的类别,并同时并行地运行一个小型的FCN,在这个框内生成像素级的掩码(Mask)。
相比FCN的进步:它通过“先检测、再分割”的思路,天然地将不同的实例隔离开来。因为每个实例都是在一个独立的候选框内完成分割的,所以它完美地解决了同类物体粘连的问题,将分割任务从“类别级”推进到了“实例级”。
接下来推出FCN的pytorch实现