鸿蒙中基础耗时分析:Time分析
耗时分析(Time Profiling)是应用性能优化的核心手段,它通过测量代码执行时间,帮助开发者定位性能瓶颈。无论是在Web、安卓还是鸿蒙开发中,有效的耗时分析都能显著提升应用响应速度和用户体验
1 理解耗时分析:为什么它至关重要?
应用的响应速度直接影响用户体验。过长的加载时间或卡顿会导致用户流失。耗时分析的核心目标是精准定位性能瓶颈,从而进行有针对性的优化。
-
性能基准:不同场景对耗时有着不同的敏感度。例如,在鸿蒙应用开发中,官方建议Web页面的点击响应时延应控制在100ms以内1,而Web加载完成时延建议不超过900ms。这些指标为优化提供了明确的目标。
-
常见性能瓶颈:
-
CPU密集型任务:如复杂的算法计算(例如未优化的递归)、大量的数据操作。
-
不必要的渲染阻塞:如同步网络请求、庞大的DOM操作、长时间运行的JavaScript任务。
-
资源加载策略不佳:未压缩的图片、未合并的CSS/JS文件、串行的网络请求。
-
2 耗时分析常用工具
工欲善其事,必先利其器。以下是各平台常用的强大耗时分析工具:
| 工具平台 | 工具名称 | 主要特点 |
|---|---|---|
| Web | Chrome DevTools | 提供Network、Performance、Main等泳道分析,擅长分析资源加载、JS执行、渲染性能 |
| Android | Android Profiler | 集成于Android Studio,可监控CPU、内存、网络实时状态,支持方法级CPU跟踪 |
| HarmonyOS | DevEco Profiler | 鸿蒙自带,提供Time、Allocation、Network等分析模板,深度集成鸿蒙框架,支持ARKTS/Native调用栈跟踪 |
2.1 鸿蒙利器:DevEco Profiler
DevEco Profiler是鸿蒙开发的性能分析神器,其Time分析模板可以:
-
录制应用运行时的CPU占用和函数调用栈。
-
可视化展示:以火焰图(Flame Chart)或列表形式展示函数耗时,直观看到“最重”的调用栈。
-
精准定位:支持跳转到高耗时对应的源码位置,极大简化了排查流程。
3 耗时分析关键流程
3.1 明确场景与目标
首先确定要分析的具体场景,如页面冷启动、列表滑动、按钮点击响应或Web页面加载。并设定一个可衡量的目标,例如“将详情页加载时间从2300ms优化至900ms以内”。
3.2 录制性能数据
使用上述工具在目标场景下进行录制。在鸿蒙中,可以使用DevEco Profiler的Time模板任务进行录制。
3.3 分析数据与定位瓶颈
这是最关键的一步,需要仔细查看工具提供的数据:
-
查看“Heaviest Stack”:寻找最耗时的函数调用栈。
-
检查网络请求(Network泳道):观察是否有资源加载过慢、请求是否串行、响应体是否过大。
-
剖析主线程(Main泳道):发现长任务(Long Tasks)、频繁的布局重排(Reflow)或耗时的JS解析执行。
3.4 实施优化并验证
根据找到的瓶颈实施相应的优化方案后,必须重新录制数据进行对比,以量化优化效果(例如,优化后耗时降低了多少毫秒或百分比)
4:函数耗时分析及优化
开发应用或元服务过程中,如果遇到卡顿、加载耗时等性能问题,开发者通常会关注相关函数执行的耗时情况。DevEco Profiler提供的Time场景分析任务,可在应用/元服务运行时,展示热点区域内基于CPU和进程耗时分析的调用栈情况,并提供跳转至相关代码的能力,使开发者更便捷地进行代码优化。
在设备连接完成后,可按照如下方法查看耗时分析结果:
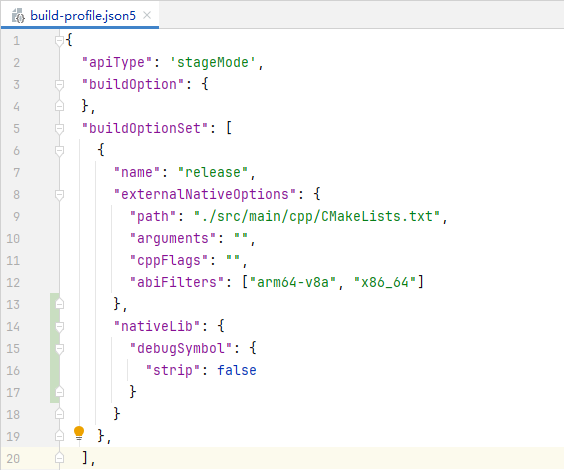
- 安装应用请参考模块级build-profile.json5文件,增加strip字段并赋值为false(strip:是否移除当前模块.so文件中的符号表、调试信息,配置为false代表不移除)。采集函数栈解析符号需要附带符号表信息,无符号表信息可能采集不到函数名称,或ArkTS Callstack泳道无法关联到Native调用栈,因此请按照下图进行配置。
- 创建Time任务并录制相关数据,操作方法可参考性能问题定位:深度录制。或在会话区选择Open File,导入历史数据。
Time分析任务支持在录制前单击

指定要录制的泳道:
- User Trace:用户自定义打点泳道,基于时间轴展示当前时段内用户使用hiTraceMeter接口自定义的打点任务的具体运行情况。
- ArkTS Callstack:方舟运行时函数调用泳道,基于时间轴展示CPU使用率和虚拟机的执行状态,以及当前调用栈名称和调用类型。由于隐私安全政策,已上架应用市场的应用不支持录制此泳道。
调用栈分类从语言层面分为ArkTS、NAPI以及Native,从归属层面分为开发者代码以及系统代码。从这两个方面可以将调用栈类型归类如下:
- ArkTS:程序正在执行ArkTS代码;
- NAPI:程序正在执行的NAPI代码;
- Native:程序正在执行的Native代码;
其中每一个类型的亮色和灰色分别代表开发者和系统的代码。
- Callstack:ArkTS和Native混合函数调用泳道。基于时间轴展示各线程的CPU使用率,以及在一段时间内的混合调用栈。调用栈类型会分为开发者或系统的ArkTS以及Native代码两类。由于隐私安全政策,已上架应用市场的应用不支持录制此泳道。
说明
Callstack基于采样模式采集数据,默认采样间隔是500微秒。耗时小于500微秒的函数,Details区域时间相关数据可能存在误差,可通过录制过程中多次触发该函数,根据其耗时百分比判断是否为热点函数。
- Energy:展示应用能耗的构成,结合应用生命周期,识别潜在能耗问题。该泳道暂不支持在TV设备上进行应用性能分析。
说明
- 在任务分析窗口,可以通过“Ctrl+鼠标滚轮”缩放时间轴,通过“Shift+鼠标滚轮”左右移动时间轴。或使用快捷键W/S放大或缩小时间轴,使用A键/D键可以左右移动时间轴。
- 将鼠标悬停在泳道任意位置,可以通过M键添加单点时间标签。
- 鼠标框选要关注的时间段,可以通过“Shift+M”添加时间段时间标签。
- 在任务分析窗口,可以通过“Ctrl+, ”向前选中单点时间标签,通过“Ctrl+. ”向后选中单点时间标签。
- 在任务分析窗口,可以通过“Ctrl+[ ”向前选中时间段时间标签,通过“Ctrl+]”向后选中时间段时间标签。
- 将鼠标置于ArkTS Callstack泳道和Callstack泳道任意位置,可查看到对应时间点的CPU使用率。
- 单击任意泳道名称后方的
 可将其置顶。
可将其置顶。
- 在“ArkTS Callstack”泳道和“ArkTS Callstack”子泳道上长按鼠标左键并拖拽,框选要分析的时间段。
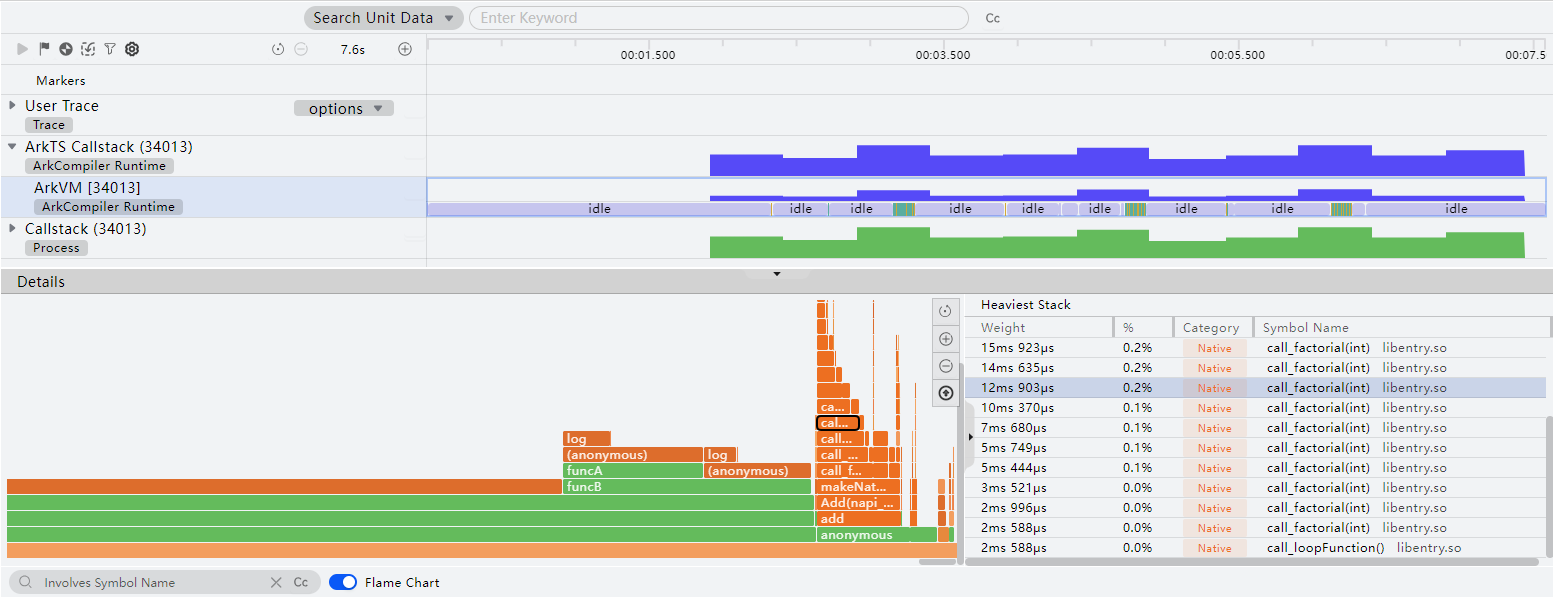
Details区域会显示所选时间段内的函数栈耗时分布情况,Heaviest Stack区域会展示出“Details”区域选择节点所处的耗时最长的完整调用栈。
其中函数栈耗时分布有三种展现方式:
- 默认为Call Tree方式,其中“Weight”字段表示当前函数的总执行时间,“Self”字段表示函数自身的执行时间,两者之差为当前函数所调用的子函数执行时间之和,“Average Duration”字段表示函数自身的平均执行时间,“Category”字段表示函数调用类型。
- 打开页面下方的Flame Chart开关,函数调用栈将以火焰图的形式展示。其中,横轴表示函数的执行时长,纵轴表示调用栈的深度。
说明
- 火焰图条块支持搜索,搜索结果不匹配的条块会被置灰。
- “Ctrl+鼠标滚轮”的操作,或单击该区域右上角的
 、
、 可放大和缩小火焰图的时间轴比例,单击
可放大和缩小火焰图的时间轴比例,单击 可恢复时间轴比例为初始状态。
可恢复时间轴比例为初始状态。 - “Shift+鼠标滚轮”的操作可左右横向调整可视区间,单独操作滚轮可上下纵向调整可视区间。
- 选中节点,单击该区域右上角的
 ,点击添加面包屑。添加面包屑后,该节点成为根节点,耗时占比为100%,子节点的耗时占比相对于该节点重新计算。
,点击添加面包屑。添加面包屑后,该节点成为根节点,耗时占比为100%,子节点的耗时占比相对于该节点重新计算。 - 在火焰图中选中任一节点,使用“Alt+鼠标左键”可将该节点左置底并将其占比放大到100%,其上从属节点按同比例放大显示。
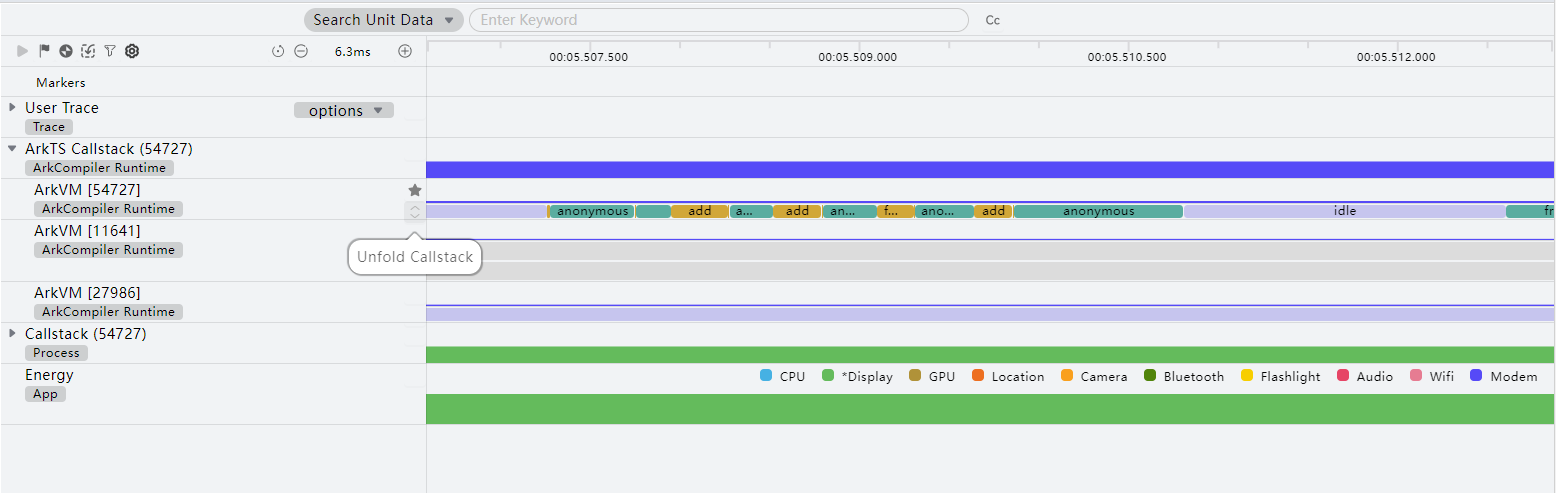
- 在“ArkTS Callstack”子泳道或“Callstack”子泳道上点击Unfold CallStack按钮,可以在时间轴上将函数调用栈以冰锥图的形式展示。其中调用栈的先后顺序与实际调用时序保持一致。
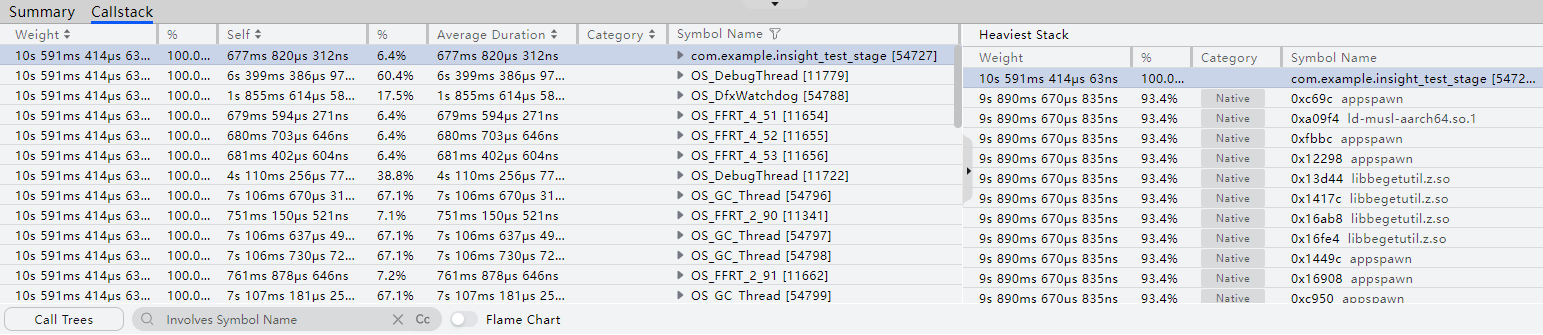
- 在Callstack泳道上长按鼠标左键并拖拽,框选要分析的时间段。
- Summary列表展示框选时段内,所有Native线程的CPU占用率的峰值、谷值、平均值。
- Callstack列表展示框选时段内,所有Native线程的函数热点。
- 悬浮到节点,显示以此节点为根按钮,点击添加面包屑。添加面包屑后,该节点成为根节点,耗时占比为100%,子节点的耗时占比相对于该节点重新计算。
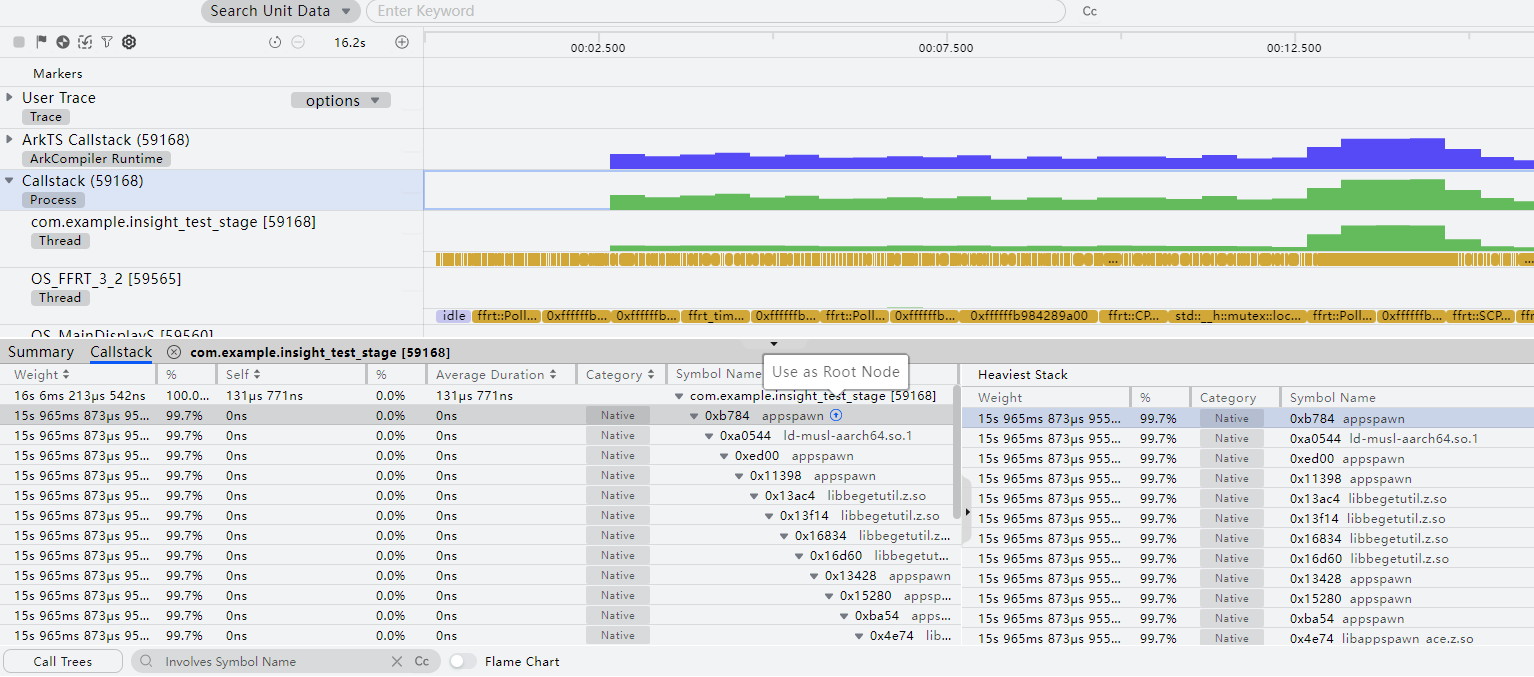
- 在Callstack子泳道上长按鼠标左键并拖拽,框选要展示分析的时间段。
- Top Down页签显示所选时间段内的函数栈耗时分布情况,Heaviest Stack区域会展示出“Details”区域选择节点所处的耗时最长的完整调用栈。
- Bottom UP页签显示函数列表,展开任一函数节点可查看其调用方及每个调用方的耗时。
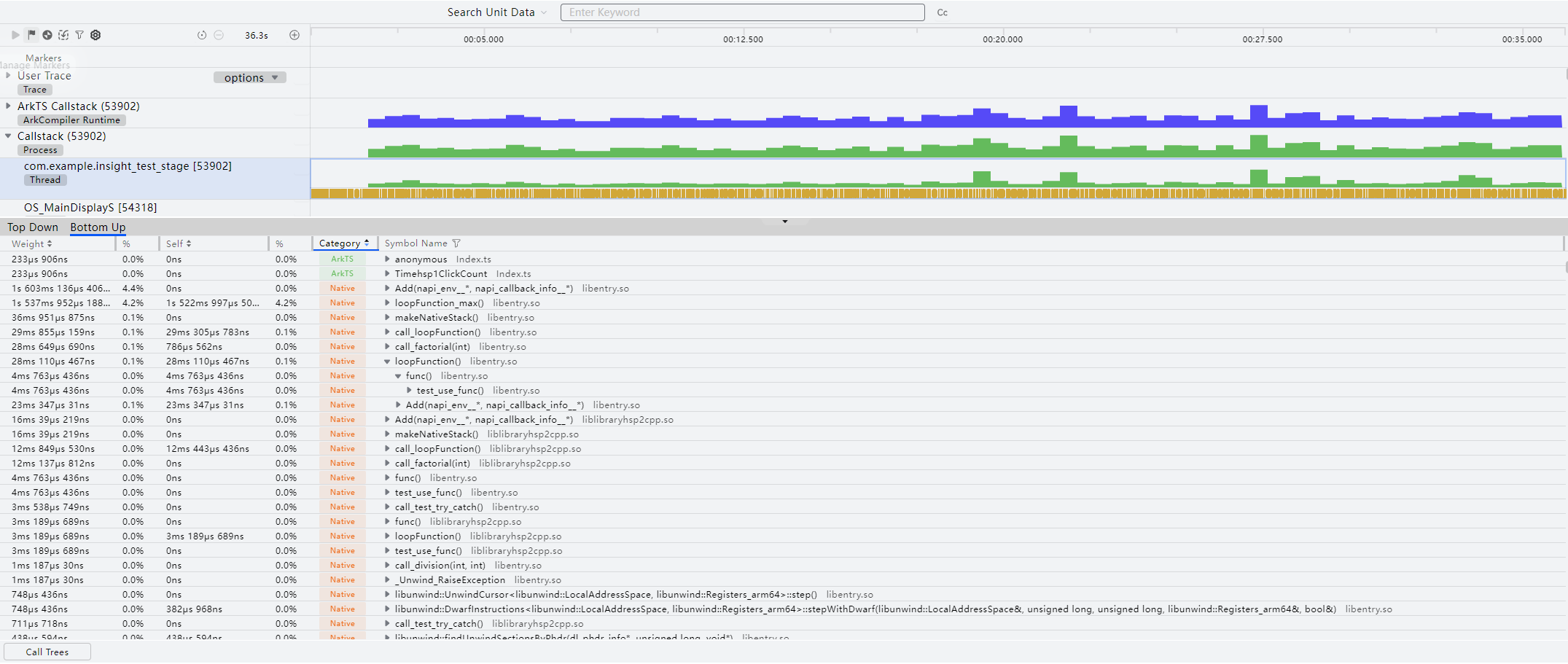
- (可选)在Details中双击需要优化的节点(例如耗时超过预期),可快速跳转至对应工程源码,为开发者节省定位代码路径的时间。
说明
- Release应用暂不支持跳转到用户侧Native代码。
- 静态链接的系统库无法支持源码跳转。如libunwind.a,在编译过程中该系统库会以静态链接的方式集成。该系统库的符号信息在调用栈中会被识别成用户侧定义的函数,实际上无法跳转到源码。
总结
耗时分析是一项至关重要的开发技能,它要求我们从用户感知的角度出发,用数据驱动决策,系统地定位和解决性能问题。无论是Web、安卓还是鸿蒙开发,其核心思想都是相通的:明确目标 -> 录制数据 -> 分析瓶颈 -> 实施优化 -> 验证效果。
鸿蒙平台的 DevEco Profiler 提供了强大且深度集成的性能分析能力,结合 Web 标准的 Chrome DevTools,开发者可以全方位地洞察应用性能表现,从而打造出流畅高效的应用体验
华为开发者学堂