C++高频知识点(三十二)
文章目录
- 156. SYN 洪泛攻击了解吗?是什么原理?什么是半连接队列?
- 洪泛攻击
- 如何防御SYN洪泛攻击?
- 157. 什么是内存池?请描述一下你如何实现内存池。
- 如何实现内存池?
- 实现示例代码
- 158. 说说unordered_map的扩容过程
- 扩容过程详解
- 示例代码(不同编译器,结果可能不一样)
- 159. 匿名函数的本质是什么?他的优点是什么?
- 匿名函数的优点
- 160. 请简要描述HTTP协议的工作原理。
- 请求-响应模型
156. SYN 洪泛攻击了解吗?是什么原理?什么是半连接队列?
洪泛攻击

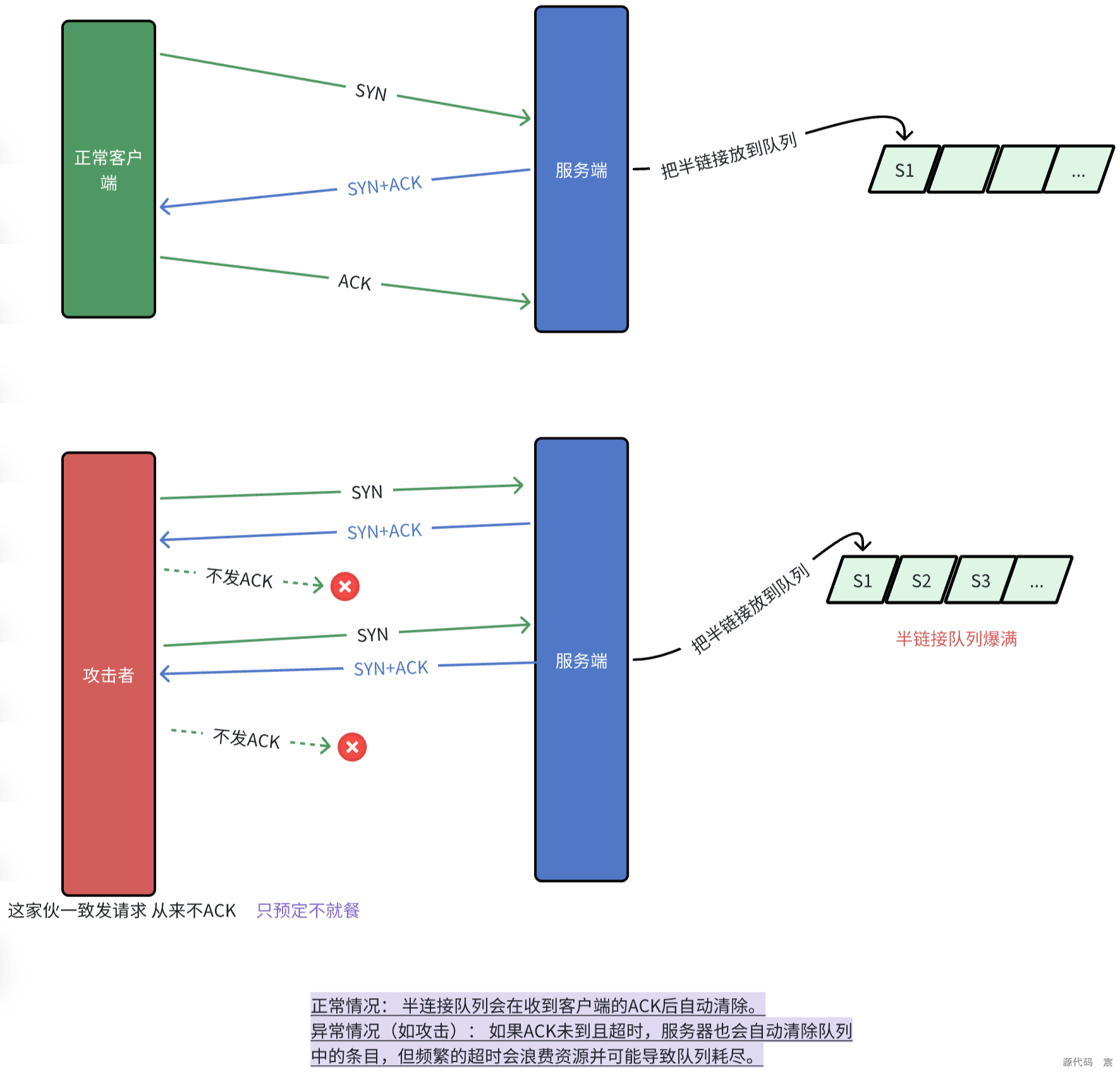
如何防御SYN洪泛攻击?

157. 什么是内存池?请描述一下你如何实现内存池。
内存池(Memory Pool)是一种预先分配和管理内存块技术,通过预先分配一块连续的内存区域,并在程序运行时从中按需分配和回收内存块,而不是直接依赖操作系统频繁调用malloc或new来动态分配内存。它的主要目的是提高内存分配效率、减少内存碎片,并提升程序的性能,尤其是在需要频繁分配和释放小块内存的场景下,比如游戏开发、网络服务器或嵌入式系统。



如何实现内存池?

实现示例代码
假设我们要实现一个固定块大小的内存池,用于分配16字节的对象:
reinterpret_cast 用于指针、引用或整型的低级别转换。它会强制类型转换为与目标类型完全不同的类型。通常用在一些底层操作,比如内存操作、位级别操作等。
#include <iostream>
#include <cstddef>
#include <mutex> // 引入互斥锁支持class MemoryPool {
private:// 内存块的节点结构,用于空闲链表struct Block {Block* next; // 指向下一个空闲块};char* pool; // 内存池的起始地址Block* freeList; // 空闲块链表头size_t blockSize; // 每个块的大小(字节)size_t poolSize; // 内存池总大小(字节)std::mutex mtx; // 互斥锁,用于线程安全public:// 构造函数:初始化内存池// numBlocks:块的总数,sizePerBlock:每块的大小// 确保块大小至少能存BlockMemoryPool(size_t numBlocks, size_t sizePerBlock) : blockSize(sizePerBlock > sizeof(Block) ? sizePerBlock : sizeof(Block)), poolSize(numBlocks * blockSize) { // 计算总内存大小pool = new char[poolSize]; // 一次性分配整个内存池freeList = nullptr; // 初始化空闲链表为空// 将内存池分割成块并链接成空闲链表for (size_t i = 0; i < numBlocks; ++i) {// reinterpret_cast 用于指针、引用或整型的低级别转换。它会强制类型转换为与目标类型完全不同的类型。通常用在一些底层操作,比如内存操作、位级别操作等。Block* block = reinterpret_cast<Block*>(pool + i * blockSize); // 定位到第i个块block->next = freeList; // 当前块指向之前的链表头freeList = block; // 更新链表头为当前块}}// 析构函数:释放内存池~MemoryPool() {delete[] pool; // 释放整个内存池}// 分配一个内存块(线程安全)void* allocate() {std::lock_guard<std::mutex> lock(mtx); // 加锁,保护共享资源if (!freeList) { // 如果空闲链表为空return nullptr; // 返回空指针,表示无可用内存}Block* block = freeList; // 取链表头的块freeList = freeList->next; // 更新链表头为下一个块return block; // 返回分配的块地址}// 回收一个内存块(线程安全)void deallocate(void* ptr) {if (!ptr) return; // 如果指针为空,直接返回std::lock_guard<std::mutex> lock(mtx); // 加锁,保护共享资源Block* block = static_cast<Block*>(ptr); // 将指针转为Block类型block->next = freeList; // 将块插回链表头freeList = block; // 更新链表头}// 禁止拷贝和赋值,避免意外复制整个内存池MemoryPool(const MemoryPool&) = delete;MemoryPool& operator=(const MemoryPool&) = delete;
};// 测试代码
int main() {MemoryPool pool(10, 16); // 创建10个16字节块的内存池void* p1 = pool.allocate(); // 分配第一个块void* p2 = pool.allocate(); // 分配第二个块std::cout << "Allocated: " << p1 << ", " << p2 << std::endl;pool.deallocate(p1); // 回收第一个块pool.deallocate(p2); // 回收第二个块std::cout << "Deallocated, ready for reuse." << std::endl;return 0;
}



158. 说说unordered_map的扩容过程
std::unordered_map是C++标准库中的哈希表容器,底层通常基于桶数组(bucket array)和链表(或类似结构)实现。当插入元素导致负载因子(load factor)超过某个阈值时,它会触发扩容。
扩容过程详解
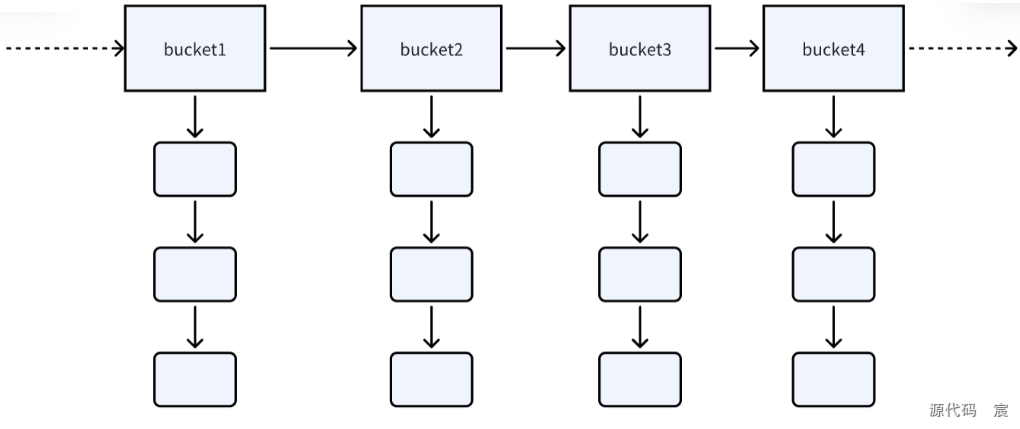

Load Factor=元素数量桶数量\text{Load Factor} = \frac{\text{元素数量}}{\text{桶数量}}Load Factor=桶数量元素数量



示例代码(不同编译器,结果可能不一样)
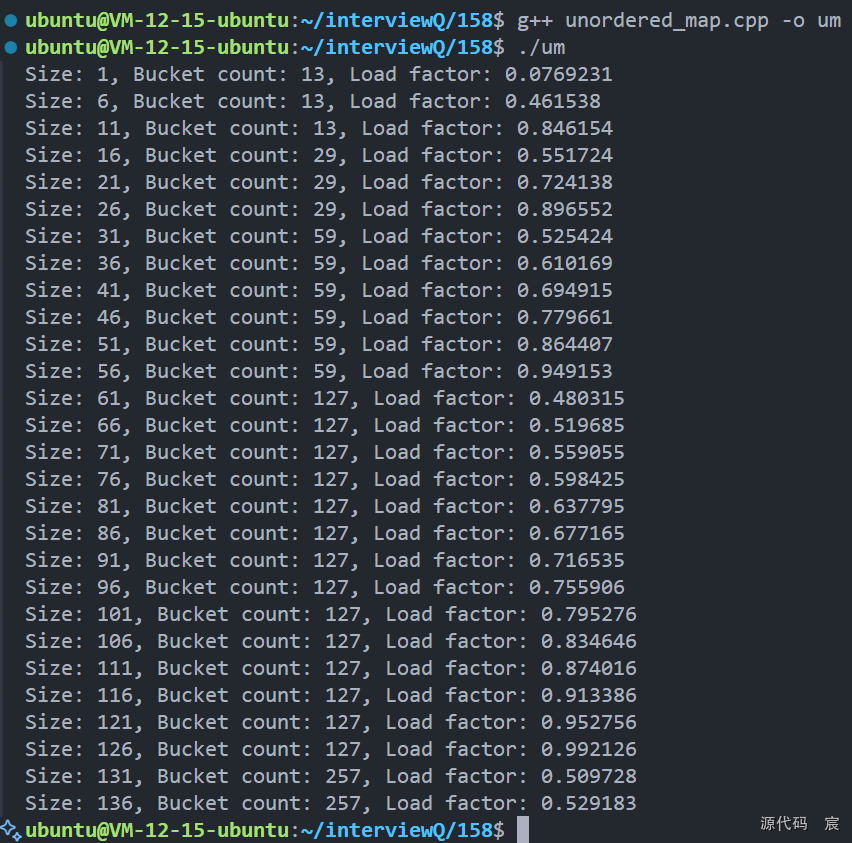
以下是一个简单的示例,展示 std::unordered_map 的扩容行为:
#include <iostream>
#include <unordered_map>void printInfo(const std::unordered_map<int, int>& umap) {std::cout << "Size: " << umap.size()<< ", Bucket count: " << umap.bucket_count()<< ", Load factor: " << umap.load_factor() << "\n";
}int main() {std::unordered_map<int, int> umap;// 插入元素并观察扩容过程for (int i = 0; i < 140; ++i) {umap[i] = i;if (i % 5 == 0) {printInfo(umap);}}return 0;
}
159. 匿名函数的本质是什么?他的优点是什么?

举个例子:
int a = 5;
int b = 10;
auto add = [a, &b](int x) { return x + 1; };
编译器可能会生成类似这样的东西(伪代码):
class Lambda {
public:int a; // 按值捕获的aint& b; // 按引用捕获的b的引用Lambda(int a_, int& b_) : a(a_), b(b_) {} // 构造函数初始化捕获int operator()(int x) const { return x + 1; }
};
然后add就是这个匿名类的实例,调用add(5)其实是调用了operator()(5)。
所以,lambda的本质是一个语法糖,让开发者能快速定义小型函数对象,而不用显式写一个完整的类。它跟传统的函数指针不一样,因为它还能捕获上下文环境。
匿名函数的优点


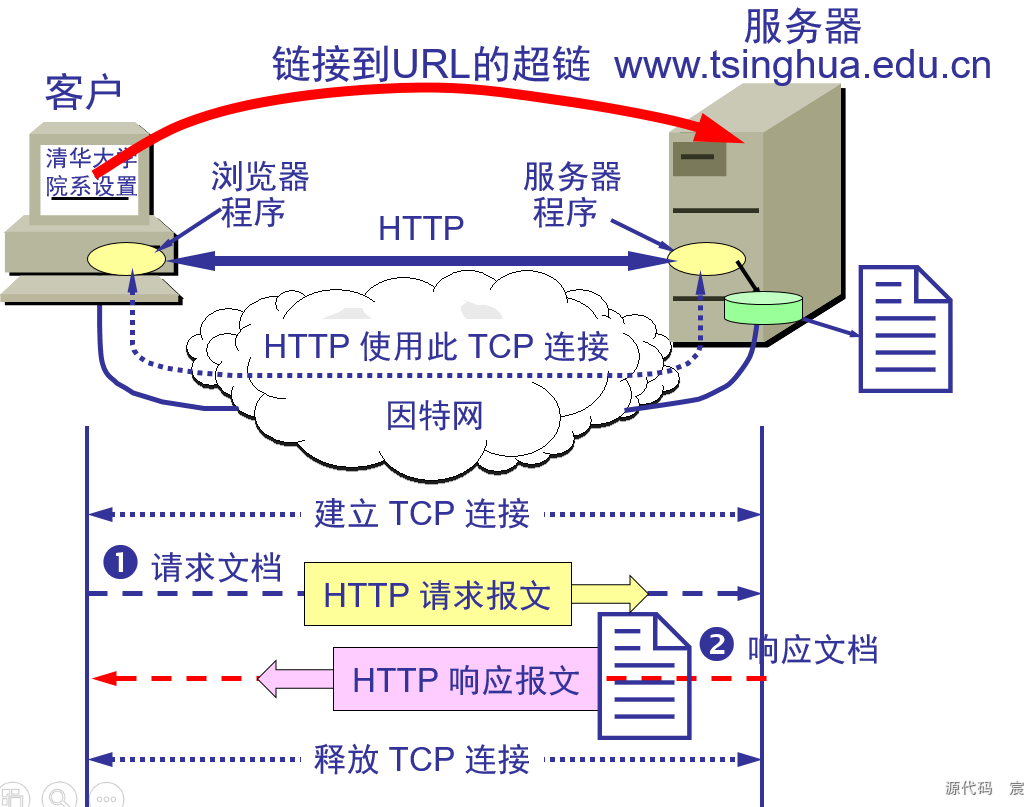
160. 请简要描述HTTP协议的工作原理。
HTTP 是一种应用层协议,基于客户端-服务器模型,用于在 Web 浏览器(客户端)和 Web 服务器之间传输超文本(HTML、图片、视频等)数据。它通常运行在 TCP/IP 协议之上,工作在 80 端口(默认,HTTPS 使用 443 端口)。
请求-响应模型


之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!