VLN领域的“ImageNet”打造之路:从MP3D数据集、MP3D仿真器到Room-to-Room(R2R)、RxR、VLN-CE
第一部分 从MP3D数据集、MP3D仿真器到Room-to-Room(R2R)
2017年11月,为了推动和促进视觉与语言方法在解释基于视觉的导航指令问题中的应用,来自1 Australian National University、2 University of Adelaide、3 Queensland University of Technology、4 Macquarie University的研究者提出了 Matterport3D Simulator——一个基于真实图像(Matterport3D数据集)的大规模RL环境[11]
- 其对应的项目网站为:bringmeaspoon.org
- 其对应的paper为:Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments
利用该模拟器(未来可支持多种具身视觉与语言任务),作者首次提供了针对真实建筑中基于视觉的自然语言导航的基准数据集——Room-to-Room(R2R)数据集
而该R2R数据集与RxR数据集,被人合称为 VLN 领域的“ImageNet”
- 近年来循环神经网络方法在图像与自然语言联合理解方面的成功,推动了视觉-语言导航(VLN)任务的发展,并促成了下文所述的 Room-to-Room(R2R)数据集的出现。该数据集的设计目标,正是为了简化视觉与语言方法在此类看似遥远问题上的应用
- 以往针对机器人自然语言指令的研究,往往忽视了视觉信息处理这一关键环节。例如,使用渲染图像而非真实图像 [7,27,62],限制了视觉信息的获取范围
1.1 Matterport3D数据集
Matterport3D,是一个大规模RGB-D数据集
- 首先,获取大规模、多样化的 RGB-D 数据集对于训练 RGB-D 场景理解算法至关重要。然而,现有的数据集仍然只涵盖了有限的视角或受限规模的空间
而Matterport3D,是一个大规模的 RGB-D 数据集,包含来自 90 个建筑规模场景的 194,400 张 RGB-D 图像的 10,800 个全景视图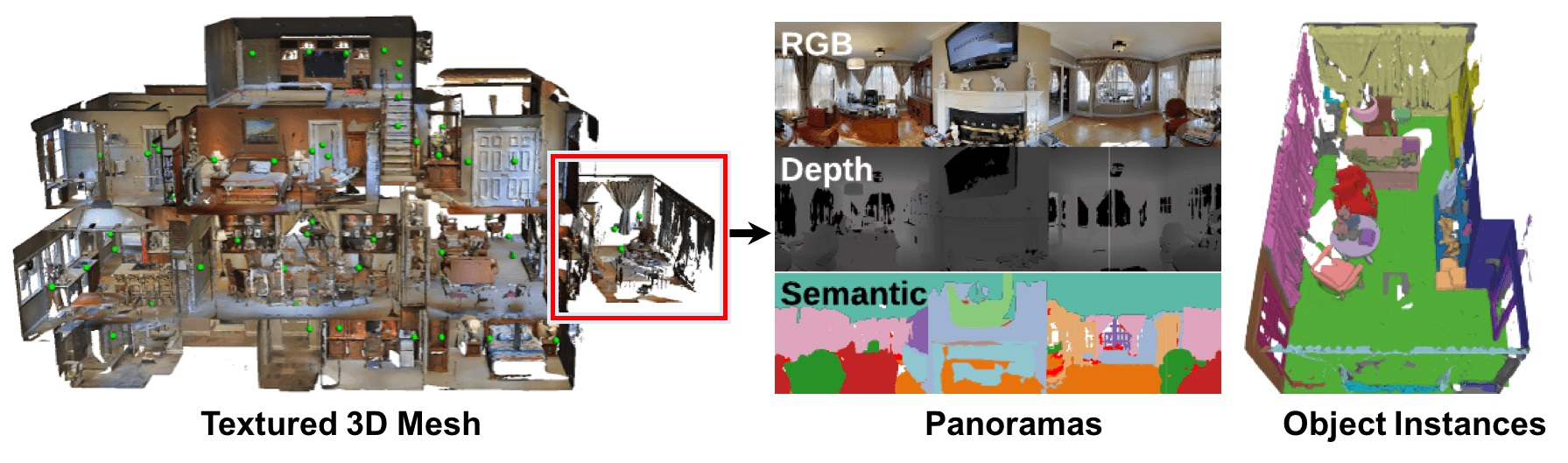
该数据集提供了表面重建、相机姿态以及 2D 和 3D 语义分割的注释。精确的全局对齐以及覆盖整个建筑的全面、多样化的全景视图集,使得包括关键点匹配、视图重叠预测、从颜色预测法线、语义分割和场景分类在内的各种有监督和自监督计算机视觉任务成为可能 - 其对应的paper为:Matterport3D: Learning from RGB-D Data in Indoor Environments
其对应的GitHub为:github.com/niessner/Matterport
其用于加载和查看数据的代码见:github.com/niessner/Matterport/tree/master/code
// 待更
1.2 Matterport3D 仿真器:基于Matterport3D数据集构建的RL环境
为了实现可复现的VLN方法评估,作者提出了Matterport3D模拟器。该模拟器是一个基于Matterport3D数据集[11-Matterport3d:Learning from rgb-d data in indoor environments]构建的大规模交互式RL环境,该数据集包含90个真实建筑规模室内环境的10,800张高密度采样全景RGB-D图像
与合成RL环境[7,27,62]相比,采用真实世界的图像数据能够保留视觉和语言的丰富性,从而最大化训练Agent迁移到现实应用的潜力
1.2.1 对Matterport3D 数据集的回顾
如上所述,大多数 RGB-D 数据集均源自视频序列,例如NYUv2 [42]、SUN RGB-D [48] 和 ScanNet[15]。这些数据集通常只提供一到两条穿越场景的路径,因此难以用于模拟机器人运动
与这些数据集相比,最近发布的 Matterport3D 数据集[11] 提供了全面的全景视图。据作者所知,截止到2017年11月,它也是目前可用的最大规模 RGB-D 研究数据集
- 具体而言,Matterport3D 数据集由 90 个建筑级场景的194,400 张 RGB-D 图像构建而成,共包含 10,800 个全景视图——点位分布在每个场景可步行的整个平面上,平均间隔为 2.25 米
每个全景视图由 18 张 RGB-D 图像组成,这些图像均从单一三维位置、约等于站立者高度进行采集
每张图像都带有精确的六自由度(6 DoF)相机位姿标注,整体上这些图像覆盖了除极点外的整个球面 - 数据集还包括全局对齐的有纹理三维网格,并对区域(房间)和物体进行了类别和实例分割标注。在视觉多样性方面,所选的 Matterport 场景涵盖了包括住宅、公寓、酒店、办公室和教堂等多种类型和规模的建筑,这些建筑具有极高的视觉多样性,对计算机视觉提出了真正的挑战
数据集中许多场景可在 Matterport 3Dspaces gallery2 中进行浏览
1.2.2 仿真器:观测、动作空间、实现细节、偏差
1.2.2.1 观测
- 为了构建模拟器,作者允许一个具身智能体通过采用与全景视角重合的姿态,在场景中虚拟“移动”。智能体的姿态由三维位置
、朝向
以及相机俯仰角
,其中
是三维位置的集合与场景中全景视点相关的点
- 在每一步,模拟器输出与智能体第一人称摄像头视角对应的RGB图像观测。图像是通过对每个视点预先计算的立方体贴图图像进行透视投影生成的。未来对模拟器的扩展还将支持深度图像观测(RGB-D),以及以渲染的对象类别和对象实例分割形式的额外工具(基于底层Matterport3D网格注释)
1.2.2.2 动作空间
实现模拟器的主要挑战在于确定与状态相关的动作空间
- 显然,咱们希望防止智能体穿越墙壁和地板,或进入其他不可通行的空间区域。因此,在每一步,模拟器还会输出一组下一步可达的视点
。智能体通过选择一个新的视点
,并指定相机的朝向
和俯仰角(
)调整来与模拟器交互。动作是确定性的
- 为了确定
,对于每个场景,模拟器包含一个加权无向图,该图覆盖全景视点,记为
,其中边的存在表示机器人可以在两个视点之间导航转换——该边的权重反映了它们之间的直线距离
为了构建这些图,作者在Matterport3D场景网格中对各视点之间进行了光线追踪,以检测中间的障碍物
给定导航图G,下一个可达视点的集合定义如下:
其中,是当前视点,
是由摄像机在第
步时视锥体左右边界所包围的空间区域。实际上,智能体被允许沿导航图中的任意边移动,只要目标位置位于当前视野范围内,或者通过上下转动摄像机可以看到。或者,智能体也可以选择始终停留在同一视点,仅仅移动摄像机
图3展示了一个典型导航图的部分示例

每个导航图平均包含117个视点,平均顶点度为4.1。相比之下,网格世界的导航图由于存在墙壁和障碍物,平均度必须小于4
- 因此,尽管智能体的移动被离散化,但在大多数高级任务的背景下,这并不构成显著限制。即使在实际机器人中,也未必实际或必要在每获得新的RGB-D相机视图时就持续重新规划高层目标
- 实际上,即使是在理论上支持连续运动的3D模拟器中,智能体在实际操作时通常也采用离散化的动作空间 [62,16,18,47]
1.2.2.3 实现细节
Matterport3D 模拟器使用 C++ 和 OpenGL 编写
- 除了 C++ API 外,还提供了 Python 绑定,使得该模拟器可以轻松与 Caffe [25] 和TensorFlow [1] 等深度学习框架,以及 ParlAI[39] 和 OpenAI Gym [9] 等强化学习平台结合使用
用户可针对图像分辨率、视场角等参数进行多种配置 - 此外,作者还开发了一个基于 WebGL的浏览器可视化库,用于通过 AmazonMechanical Turk 收集导航轨迹的文本标注,并计划向其他研究人员开放该工具
1.2.2.4 偏差
作者不愿意引入一个新的数据集(在本例中为模拟器),而不至少尝试解决其局限性和偏差 [54]。在 Matterport3D 数据集中,作者观察到几种选择性偏差
- 首先,大多数被采集的居住空间都极为整洁、有序,且通常较为豪华
- 其次,该数据集包含的人物和动物极少,而这些元素在许多其他视觉和语言数据集中却占据重要地位 [14,4]
- 最后,作者还观察到一定的采集偏差,因为所选视点通常能够俯瞰环境(因此不一定是机器人可能处于的位置)
为在一定程度上缓解这些局限性,该模拟器可以通过采集更多建筑扫描数据进行扩展。有关最近使用 Matterport 相机采集的学术数据集实例,请参见 Stanford 2D-3D-S [5]
1.3 Room-to-Room(R2R)数据集:基于Matterport3D环境(仿真器)收集
基于Matterport3D环境,作者收集了Room-to-Room(R2R)数据集,该数据集包含21,567条开放词汇、众包的导航指令,平均长度为29个单词。每条指令描述了一条通常穿越多个房间的轨迹
如深蓝具身智能所总结的,在R2R数据集诞生前,视觉语言导航研究深陷「数据孤岛」困境——各实验室自建仿真环境与私有指令集,导致跨研究对比如同「鸡同鸭讲」
- 为解决这一问题,澳大利亚国立大学团队以ImageNet为蓝本,历时18个月打造了VLN领域的首个黄金标准:R2R
- 其核心在于真实家庭场景的毫米级复刻(涵盖90个多样户型,27类语义标注)与人类导航思维的数据化翻译——标注员通过路径视频撰写自然语言指令,包含地标参照、方位指示与动作描述,并经过第三方验证确保指令与路径偏差小于3米
这一标准化平台为VLN研究提供了统一基准,包含三大核心指标:
- 导航成功率(Success Rate):
定义:智能体最终是否成功到达目标位置(通常以一定半径范围内判定)
计算:成功轨迹的比例,二值衡量(成功/失败)
变体:部分研究使用加权成功率(Success weighted by Path Length, SPL),结合路径效率(路径长度与最优路径的比值)调整成功率- 路径长度(Path Length,PL):
定义:智能体实际行走的路径总长度
作用:与最优路径(最短路径)对比,衡量效率。通常用于计算SPL或其他效率指标- 导航误差(Navigation Error, NE):
定义:终点位置与目标位置的欧氏距离(单位:米)
作用:量化最终位置的精确度,数值越小越好
1.3.1 任务:VLN领域的首个黄金标准
如图1所示

R2R任务要求具身智能体根据自然语言指令,从起始姿态导航至Matterport3D模拟器中的目标位置
- 具体而言,在每个回合开始时,智能体会接收到一条自然语言指令
,其中
为指令长度,
为单个词元
智能体观察到的初始RGB图像由其初始姿态决定,该姿态由三维位置、航向和俯仰角组成的元组
表示
- 智能体必须执行一系列动作
,其中每个动作导致新的位置
,并生成新的图像观测
当智能体选择特殊的动作时,回合结束,该动作被添加到上文《「2.1.2.2 动作空间」——对应于原论文第3.2.2节》中定义的模拟器动作空间中
如果动作序列使智能体接近目标位置,则任务被认为成功完成(评估细节见第4.4节)
1.3.2 数据收集
为了生成导航数据,作者利用 Matterport3D 区域注释,从不同房间中采样起始位姿和目标位置对
对于每一对,作者在相关的加权无向导航图G 中找到最短路径,并舍弃长度小于 5 米的路径,以及包含少于四条或多于六条边的路径,最终作者共采样了 7,189 条路径,覆盖了数据集中大部分视觉多样性
如图 5 所示
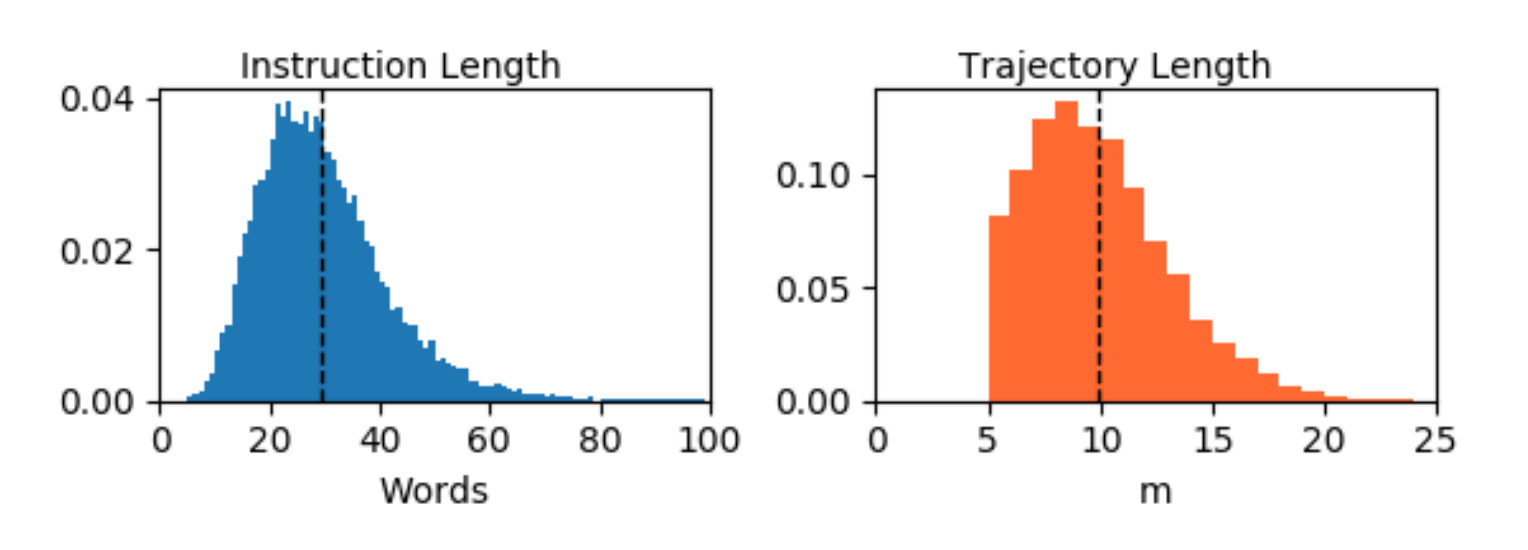
平均路径长度为 10 米
对于每条路径,作者使用亚马逊机械土耳其(AMT)收集三条相关的导航指令
- 最后,作者为工作人员提供了一个交互式3D WebGL环境,用彩色标记展示从起始位置到目标位置的路径。工作人员可以像“飞行穿越”一样与轨迹互动,或在路径上的任意视角平移和旋转摄像头,以获得更多上下文信息
- 随后,作者要求工作人员“编写指令,使智能机器人能够从相同的起始位置出发后找到目标位置”。工作人员还被告知不必严格按照所示路径行进,只需到达目标即可。同时,还提供了视频演示。完整的数据收集界面(作为补充材料附带)是经过多轮实验后形成的
- 仅使用了美国本土的AMT工作人员,并根据他们在以往任务中的表现进行了筛选。共有400多名工作人员参与了数据收集,累计贡献了约1600小时的标注时间
1.3.3 R2R 数据集分析
作者共收集了21,567条导航指令,平均长度为29个单词。这一长度明显长于视觉问答数据集,其中大多数问题的长度在四到十个单词之间[4]。
然而,鉴于任务的专注性,指令的词汇量相对有限,大约包含3,100个词(其中约1,200个词出现频率在五次及以上)
- 如图4所示,指令的抽象程度差异较大。这很可能反映了人们对“智能机器人”工作方式的心理模型存在差异[43],因此处理这些差异成为该任务的重要方面
- 基于指令首词的导航指令分布如图6所示。尽管作者将R2R数据集与Matterport3D仿真器结合使用,但从技术角度看,没有理由该数据集不能与其他基于Matterport数据集的仿真器一起使用[11]
// 待更
1.4 RxR
// 待更
第二部分 VLN-CE
// 待更