医学影像分析中的持续学习:近期进展与未来展望综述|文献速递-深度学习人工智能医疗图像
Title
题目
Continual learning in medical image analysis: A comprehensive review ofrecent advancements and future prospects
医学影像分析中的持续学习:近期进展与未来展望综述
01
文献速递介绍
在不断发展的医学影像分析领域,医疗数据的动态特性对机器学习/深度学习模型在新数据/新领域的泛化能力构成了严峻挑战(Miotto 等,2017;Zhou 等,2021a)。数据驱动的方法面临诸多挑战,因为用于训练的足够大规模且多样化的医疗数据在获取和可及性方面存在限制(Miotto 等,2017;Guan 和 Liu,2022;Zhou 等,2021a;Chauhan 和 Goyal,2020,2021)。此外,由于扫描仪制造商不同、染色和成像协议有别、切片厚度各异以及患者群体多样等因素导致的源数据变异性,使得医疗数据具有异质性。若训练数据集和测试数据集来自不同数据源,这会在两者之间引入偏差和差异,进而导致模型性能下降(Oliveira 等,2023;Zhou 等,2021a)。为解决模型泛化问题,领域自适应方法逐渐兴起,其旨在将知识从一个领域迁移到其他未见过的数据源或领域(Lai 等,2023a,b;Guan 和 Liu,2022;Wachinger 等,2016;Becker 等,2014;Feng 等,2023)。然而,由于医疗数据的敏感性和复杂性,领域自适应面临独特挑战(Azad 等,2022)。最常见的相关问题包括:用于训练的带标签医疗数据数量有限;数据源的异质性导致显著的领域偏移;临床差异和人群差异;以及评分者间差异。此外,源域数据中存在的偏差可能会传播到目标域,因此确保在不同患者群体中做出公平且无偏的预测成为关键问题。而且,医疗数据涵盖多种模态,包括影像、电子健康记录和基因组数据,这使得调整模型以处理多模态数据并确保互操作性的任务异常复杂。再者,由于医疗领域严格的隐私法规,源数据的可访问性可能仅限于短时间,甚至完全被禁止(Thandiackal 等,2024)。因此,需要源数据和目标数据同时可用的领域自适应方法可能并不可行。 另一种相关的学习范式——迁移学习,已在医疗领域被广泛采用,以应对数据可用性有限的挑战(Yu 等,2022;Ghafoorian 等,2017)。它将从源任务中获得的知识迁移到目标任务,以改善目标任务的学习效果或性能。与仅数据分布发生变化的领域自适应不同,迁移学习涵盖源域和目标域在特征空间、标签空间以及数据分布上的变化(Kouw 和 Loog,2018;Zhou 等,2022;Guan 和 Liu,2022)。在小规模的医学疾病分类数据集中,纳入从在大规模带标签自然图像数据集(ImageNet)上训练的模型中获得的知识可能是有益的。与仅在医学疾病数据集上从头开始训练相同模型相比,该模型在医学疾病数据集上的性能可能更好。但与此同时,该模型在 ImageNet 数据集上的性能无法得到保证(这在迁移学习中也并非目的)。在迁移学习中,重点是利用先前的知识而非保留它,因此在源数据上的性能可能会受损。通常,学习具有偏移分布的新数据集会导致在源数据集上的性能急剧下降,这也被称为深度神经网络的“灾难性遗忘”(McCloskey 和 Cohen,1989;Goodfellow 等,2013)。第 2.2 节将详细描述灾难性遗忘。 在现实世界中,人们可能希望能够在不需要源数据的情况下,依次适应多个目标域。在这一方向上,持续学习(CL)——对新信息的持续适应,已成为提高医学影像分析系统性能和可靠性的重要维度。与迁移学习不同,持续学习同时关注源域和目标域。持续学习方法旨在保留从先前见过的任务中获得的知识,同时适应新任务并避免灾难性遗忘问题。持续学习模型用于预测分析,特别是在可以自动获取临床结果并将其纳入算法的情况下(Lee 和 Lee,2020)。这种能力通过从实时患者数据中学习来增强模型的预测能力。持续学习方法还可用于利用多模态数据集,以实现更好的可解释性和分析效果。近年来,在计算机视觉任务的各个子领域中,越来越多的持续学习方法得到探索和提出。图 3 展示了基于持续学习不同方面的论文分布,并通过多年来不断增加的出版物数量显示了在医学领域探索的增长。在本文中,我们讨论了持续学习的各个方面,特别考虑了其在医学领域的应用和意义。在此,我们旨在为关于调整和改进机器学习模型以在动态医疗环境中保持有效性的持续讨论做出贡献。通过强调持续学习,我们推荐的模型不仅最初表现出强劲的性能,而且具备随时间演变和改进的能力。医学影像分析中的持续学习代表了一种强大的方法,用于开发能够进化、学习和适应医疗复杂性的智能系统,最终有助于改善患者预后和增强临床决策。我们讨论了现有方法的局限性和挑战,并探索了可用于开发稳健算法的方法/技术。对现有文献的全面搜索凸显了我们工作的独特性,即首次对应用于医学影像分析的持续学习技术进行全面综述。这项学术努力不仅旨在贡献新的见解,还旨在为研究人员建立一个基础参考,提供一个能够指导未来探索并激发学术界学术兴趣的路线图。我们学术追求的主要贡献如下: - 在范围上具有开创性,本综述论文首次全面探索了持续学习在医学影像分析领域的应用。我们的重点在于提供全面概述,涵盖所有相关论文,并阐明医学影像分析中知名方法的细节。 - 我们在学术界引入了对持续学习模型的严格分类,提出了一种系统的分类法,根据不同的持续学习策略对研究进行分类。我们的分类区分了各种持续学习技术,如重放策略、正则化方法、架构调整方法和混合方法。此外,我们将这些技术置于各种医学子领域中进行情境分析,提供了细致的学术视角。 - 除了以应用为中心的讨论外,我们的探索还深入研究了医学影像分析中持续学习的学术挑战和开放问题。通过解决学术复杂性,包括数据标注成本、时间漂移和对基准数据集的需求,我们为学术讨论做出了贡献。此外,我们确定了引发开放问题的新兴学术趋势,塑造了持续学习应用于医学影像分析未来学术研究的轨迹。 本综述的动机和独特性 在过去几十年中,计算机视觉任务中的持续学习方法取得了重大进展,导致众多综述论文探索用于计算机视觉任务的深度持续学习模型(Qu 等,2021;Wang 等,2023b;De Lange 等,2021;Mai 等,2022)。虽然其中一些综述专注于特定应用,如分类(De Lange 等,2021;Mai 等,2022),但其他综述则采用更通用的方法来评估策略(Mundt 等,2021)或概念和实践视角(Wang 等,2023b)。值得注意的是,这些综述中没有一篇专门涉及持续学习技术在医学影像分析中的应用,这在文献中留下了显著空白。我们认为,来自视觉领域成功持续学习模型的见解可能对医学界有益,指导对持续学习过去和未来研究方向的回顾性分析(Verma 等,2023;Lee 和 Lee,2020)。持续学习已证明其在开发统一且可持续的深度模型方面的潜力,这些模型能够处理各种应用领域中非平稳环境中的新类别、新任务和数据的演变性质。我们的综述旨在通过提供有价值的见解来弥合这一差距,这些见解可以帮助医学研究人员,包括放射科医生,在其领域采用最新方法。在我们的综述中,我们分析了医疗数据中各种漂移源,定义了医学图像中的持续学习场景。我们通过将技术分为基于重放策略、正则化方法、架构调整方法和混合策略的方法,呈现了持续学习的多视角观点。讨论不仅限于应用,还包括所提出方法的基本工作原理、挑战和成像模态。我们强调了这些额外信息如何帮助研究人员整合整个领域的文献。我们论文的简要概述如图 6 所示。 搜索策略 为进行全面的文献搜索,我们遵循了 Azad 等在 Azad 等(2023b,2023a)中提出的相同策略,并利用 DBLP、Google Scholar 和 Arxiv Sanity Preserver,采用自定义搜索查询来检索与我们主题——持续学习相关的学术出版物。我们的搜索查询为(continual learning | medical | sequence of tasks)(segmentation | classification | medical | lifelong learning)。这些平台允许我们将结果过滤到不同类别,如同行评审期刊论文、会议或研讨会论文集、非同行评审论文和预印本。我们通过两步过程过滤搜索结果:首先筛选标题和摘要,然后根据以下特定标准审查全文:1. 与持续学习的相关性:重点关注对持续学习或相关领域(如终身学习、增量学习和在线学习)的重大贡献。2. 发表 venue:优先考虑在以高质量研究著称的知名期刊和会议上发表的论文。3. 新颖性和贡献:纳入呈现新颖研究、方法或应用的论文。4. 实验严谨性:论文必须包括全面的实验和结果来验证其主张。5. 理论基础:优先考虑具有强大理论基础的论文,包括正式定义和分析。 论文结构 本手稿中使用的所有缩写及其扩展在表 1 中列出。第 2 节提供了关于医疗数据中各种漂移源、灾难性遗忘问题、持续学习、持续学习框架管道以及持续学习应用的背景知识。然后在第 3 节中详细阐述了在医学领域探索的各种持续学习场景。此外,我们在第 4 节中涵盖了各类持续学习技术及其在医学领域的适用性。第 5 节提供了关于不同提出的框架所需监督水平的详细信息。第 6 节提供了全面的实用信息,如实验设置、训练过程以及用于衡量持续学习框架可塑性和稳定性的评估指标。第 7 节讨论了持续学习文献中的当前挑战和未来方向。最后一节提供了本综述的结论。
Abatract
摘要
Medical image analysis has witnessed remarkable advancements, even surpassing human-level performancein recent years, driven by the rapid development of advanced deep-learning algorithms. However, whenthe inference dataset slightly differs from what the model has seen during one-time training, the modelperformance is greatly compromised. The situation requires restarting the training process using both theold and the new data, which is computationally costly, does not align with the human learning process,and imposes storage constraints and privacy concerns. Alternatively, continual learning has emerged as acrucial approach for developing unified and sustainable deep models to deal with new classes, tasks, andthe drifting nature of data in non-stationary environments for various application areas. Continual learningtechniques enable models to adapt and accumulate knowledge over time, which is essential for maintainingperformance on evolving datasets and novel tasks. Owing to its popularity and promising performance, it is anactive and emerging research topic in the medical field and hence demands a survey and taxonomy to clarifythe current research landscape of continual learning in medical image analysis. This systematic review paperprovides a comprehensive overview of the state-of-the-art in continual learning techniques applied to medicalimage analysis. We present an extensive survey of existing research, covering topics including catastrophicforgetting, data drifts, stability, and plasticity requirements. Further, an in-depth discussion of key componentsof a continual learning framework, such as continual learning scenarios, techniques, evaluation schemes,and metrics, is provided. Continual learning techniques encompass various categories, including rehearsal,regularization, architectural, and hybrid strategies. We assess the popularity and applicability of continuallearning categories in various medical sub-fields like radiology and histopathology. Our exploration considersunique challenges in the medical domain, including costly data annotation, temporal drift, and the crucial needfor benchmarking datasets to ensure consistent model evaluation. The paper also addresses current challengesand looks ahead to potential future research directions.
医学影像分析在先进深度学习算法的快速发展推动下,近年来取得了显著进步,甚至在某些方面超越了人类水平。然而,当推理数据集与模型一次性训练时所见的数据存在细微差异时,模型性能会大幅下降。这种情况下,需要使用新旧数据重新启动训练过程,这不仅计算成本高昂,与人类的学习过程不符,还存在存储限制和隐私问题。 相比之下,持续学习已成为开发统一且可持续的深度模型的关键方法,用于应对非平稳环境中各类应用场景下的新类别、新任务以及数据的漂移特性。持续学习技术使模型能够随时间推移适应并积累知识,这对于在不断演变的数据集和新任务上保持性能至关重要。由于其受欢迎程度和良好的性能表现,持续学习已成为医学领域一个活跃且新兴的研究课题,因此需要通过综述和分类来阐明医学影像分析中持续学习的当前研究格局。 本文通过系统综述,全面概述了应用于医学影像分析的最先进持续学习技术。我们对现有研究进行了广泛调研,涵盖灾难性遗忘、数据漂移、稳定性和可塑性需求等主题。此外,还深入探讨了持续学习框架的关键组成部分,如持续学习场景、技术方法、评估方案和指标。持续学习技术包括多种类别,如重放策略、正则化方法、架构调整和混合策略等。我们评估了这些持续学习类别在放射学、组织病理学等多个医学子领域的普及度和适用性。 我们的研究还考虑了医学领域的独特挑战,包括高昂的数据标注成本、时间漂移问题,以及对基准数据集的迫切需求——这些数据集是确保模型评估一致性的关键。最后,本文还探讨了当前存在的挑战,并展望了未来潜在的研究方向。
Background
背景
2.1. Medical data drifts
In clinical practices, the data distribution evolves over time, reflecting the dynamic nature of the healthcare environment (Sahiner et al.,2023a; Lacson et al., 2022; Moreno-Torres et al., 2012). Inconsistenciesin data collection procedures across different healthcare settings or institutions contribute to data drift. Also, the introduction of new medicalimaging devices, diagnostic tools, and data acquisition techniques leadsto a shift in the technological landscape (Derakhshani et al., 2022; Lacson et al., 2022). Moreover, the advancement in medical research andthe discovery of new diseases/treatment methods raise the understanding of healthcare. This new knowledge can influence the characteristicsof medical data that cause shifts in the underlying distribution (Lacsonet al., 2022; Moreno-Torres et al., 2012). Also, data sources can havetheir dynamics and, therefore, are inherently non-constant. For instance, cardiac CT images are captured under time-varying factors suchas breathing and heart rates. Non-homogeneous data is another challenge, as individual health differences among patients can vary overtime due to factors like genetics, age, occupation, and lifestyle (Lacson et al., 2022; Sahiner et al., 2023b). Additionally, variations insample preparation or pre-processing methods contribute to distinctions among imaging datasets. In digital histopathology, differencesin staining policies across labs introduce undesired stain variancesin whole-slide images (Nakagawa et al., 2023; Madabhushi and Lee,2016). The imaging solution may also influence the final digital visualization throughout the entire learning process over time. Nonlinearaugmentation of computed radiography occurs at various degrees dueto the differing physical and chemical properties of contrast mediums from different brands. Variables like sensor signal-to-noise ratio(SNR), customized parameter settings in imaging software, and storagefriendly distortions can all impact the quality of the resultant image.For instance, in digital histopathology, billion-pixel whole slide images(WSI) at a fixed magnification have seen variations in storage size,ranging from megabytes to gigabytes per image over the years, consequently enhancing the dataset quality in terms of micron-per-pixel(MPP) for continual learning tasks (Nakagawa et al., 2023).Data drifts can be broadly categorized as the covariate, label, andconcept shift. We provide their explanation along with examples inTable 2. The medical data drifts can have significant implications forthe performance and reliability of machine learning and deep learningmodels (Sahiner et al., 2023b). Traditional machine learning oftenrelies heavily on static data and feature engineering, where humanexperts manually select the relevant features. In the case of data drift,these handcrafted features may become less informative, and the modelmay struggle to adapt to new patterns (Bayram et al., 2022). Morespecifically, for both machine learning and deep learning, this issueis particularly prevalent in dynamic and non-stationary environments,where the statistical properties of the data evolve. Understanding thesources of drift, such as inconsistencies in data collection and technological advancements, is crucial for developing robust models (Sahineret al., 2023b). Proactive strategies, including regular model updatesand continuous monitoring, are essential to ensure that machine learning models remain effective and reliable in navigating the evolvinghealthcare landscape by addressing medical data drift and developingmachine learning models that can adapt to the ever-changing nature ofclinical data, ultimately enhancing patient care and outcomes.
2.2. Catastrophic forgetting
Throughout a lifetime, a human brain continuously acquires knowledge, and learning new concepts or tasks has no detrimental effecton previously learned ones. Instead, learning several closely relatedconcepts even boosts the learning of all associated ones. In contrast,artificial neural networks, although inspired by the human brain, oftensuffer from ’catastrophic forgetting’, a tendency to overwrite or forgetthe knowledge acquired in the past upon learning new concepts (McCloskey and Cohen, 1989; Ratcliff, 1990). This can be attributed to thefact that the model entirely optimizes for the given dataset. In otherwords, a model with optimized weights for a task T1, when trained ona new task T2, will freely optimize the existing weights to meet theobjectives in task T2, which may now no longer be optimal for theprevious task T1. This can be a significant challenge, especially in scenarios where an AI system is expected to learn and adapt to a stream of
tasks or datasets over time. Catastrophic forgetting in neural networks
is an interesting phenomenon that has attracted lots of attention inrecent research (Goodfellow et al., 2013; Kumari et al., 2024a). Medicaldata often come from different sources with varying imaging protocols,equipment, and patient populations. For example, MRI scans fromdifferent hospitals may have distinct characteristics, leading to domainshifts that can cause a model to forget previously learned features whenintroduced to new data. Also, medical datasets are often limited in sizeand can be highly imbalanced, with some conditions being much morecommon than others. This imbalance can exacerbate catastrophic forgetting, as the model may overly specialize in newly introduced, morefrequent classes at the expense of older, less frequent ones. Addressing catastrophic forgetting is crucial for the development of reliableand effective medical AI systems. By implementing strategies such asregularization, rehearsal, generative replay, dynamic architectures, anddomain adaptation, researchers can enhance the robustness of modelsagainst forgetting, ensuring consistent and accurate performance inmedical applications. This is essential for maintaining diagnostic consistency, adapting to new medical knowledge, and providing trustworthyclinical decision support.
2.3. Continual learning overview
A naive solution to deal with catastrophic forgetting can be retraining the model collectively on old and new data from scratch eachtime new data with drifted distribution or classes are encountered (Leeand Lee, 2020). This process mostly gives the desired classificationor segmentation performance; however, it causes an intense burdenon computing and storage requirements and, hence, is impractical fordeployment. Additionally, the retraining process requires storing thepast data and thus causes privacy violations, which can be a majorbottleneck of such a strategy in healthcare applications.Alternately, CL, also termed as ‘continuously learning’, ‘incrementallearning’, ‘sequential learning’ or ‘lifelong learning’, has emerged asa promising solution in various fields to deal with the catastrophicforgetting issue (De Lange et al., 2021; Mai et al., 2022). It helpsin efficiently leveraging existing knowledge and incorporating newinformation without the need for extensive retraining. The primarygoal of CL is to develop techniques and strategies that allow a neuralnetwork to learn new tasks while retaining knowledge of previoustasks. In other words, it aims to enable the network to continuallyadapt to new information without completely erasing or degradingits performance on earlier tasks. Overall, CL helps to address theissue of catastrophic forgetting and minimizes the need for additionalresources to store historical data. CL offers a range of strategies andmethods, such as regularization (constraining weight update to avoidforgetting learned concepts), rehearsal (partially using some form ofold data to replay with current data), and architectural modifications(reserving or partitioning network for different tasks), to help neuralnetworks remember and consolidate knowledge from past tasks. Thesestrategies help prevent or reduce catastrophic forgetting and improvethe generalization ability of the model.
2.4. Continual learning pipeline
The design of a CL pipeline is illustrated in Fig. 1 which provides anoverview of the key components and stages involved in the constructionof the CL pipeline. Given a problem statement, first, we need to identifywhich CL scenarios it falls under, i.e., whether there is a possibilityof domain shifts in future data, inclusion of new classes, or the endapplication, i.e., the task itself may change. For example, if we wantto develop a breast cancer classification model to be able to work onthe H&E dataset from different centers then the datasets across centersmay have drift and hence fall into the domain incremental scenario ofCL. Detailed information about CL scenarios is provided in Section 3.Once we have identified the CL scenario, training, and testing, datasetsneed to be prepared to mimic a continual stream of datasets arrivingone after another. The sequence of datasets is frequently referred to astasks, experiences, or episodes in literature. We also use these termsinterchangeably in this manuscript. For each episode, separate trainingand testing data is prepared; thus, for a given sequence of four datasets,the pipeline requires four train-test pairs to develop and evaluate aCL model. Once the datasets are ready, a CL strategy suitable to theapplication at hand is identified and deployed in any off-the-shelfdeep classification or segmentation model. There are various CL strategies, some offering privacy-preserved learning, while some offer betterperformance but at the cost of more resources, storage, and privacyviolations as they store some past data. Typically, the model is trainedon the first training episode and evaluated on testing data from all theepisodes. After this, the training shifts to the next episode, where theinclusion of partial training data from the previous episode is possible.Here, updating the model with new training data, the evaluation isagain done on all the testing data, and the process repeats until the lastepisode. Application-specific performance metrics (e.g., accuracy, dicesimilarity coefficient, etc.) computed on testing data of each episodeare observed and analyzed over the sequence. Then, we can computevarious metrics on top of it to quantify forgetting and forward transfer.Lastly, the CL framework is evaluated against state-of-the-art worksand non-CL methods offering upper and lower bounds of performance.Joint or cumulative training gives the highest average performance,whereas naively finetuning on the current episode gives the lowestperformance (Kaustaban et al., 2022; Lenga et al., 2020).
2.5. Application of continual learning
CL has numerous applications across various domains due to itsability to mitigate catastrophic forgetting. The efficiency and robustnessof CL in real-time scenarios derive from its ability to adapt, reduce computational overhead, and address the challenges of dynamic data. Thismakes it a valuable approach for applications where time constraints,adaptability, and efficiency are of great importance. In the medicaldomain, CL has been widely explored for various segmentation andclassification applications (Fig. 2) and continuously exhibited its meritsover static models as reflected by the increasing number of researchcontributions over the year (Fig. 3). CL can improve the diagnosis anddecision-making ability in a resource-constrained environment. Further, it is beneficial in real-time monitoring of patients, telemedicine,and maintaining a dynamic knowledge base. This section presents themost prominent applications of CL in medical settings in terms of thenumber of publications.
2.1 医疗数据漂移 在临床实践中,数据分布会随时间演变,反映出医疗环境的动态特性(Sahiner 等,2023a;Lacson 等,2022;Moreno-Torres 等,2012)。不同医疗场景或机构的数据收集流程不一致会导致数据漂移。此外,新医疗成像设备、诊断工具和数据采集技术的引入,也会引发技术格局的变化(Derakhshani 等,2022;Lacson 等,2022)。再者,医学研究的进展以及新疾病/治疗方法的发现,加深了对医疗健康的理解,这种新知识可能影响医疗数据的特征,导致其潜在分布发生偏移(Lacson 等,2022;Moreno-Torres 等,2012)。数据源本身也具有动态性,因此本质上是非恒定的。例如,心脏 CT 图像的采集会受到呼吸、心率等时变因素的影响。非均质数据是另一大挑战,患者个体健康差异会因遗传、年龄、职业和生活方式等因素随时间变化(Lacson 等,2022;Sahiner 等,2023b)。此外,样本制备或预处理方法的差异也会导致成像数据集之间的区别。在数字组织病理学中,不同实验室染色方案的差异会在全切片图像中引入不必要的染色变异(Nakagawa 等,2023;Madabhushi 和 Lee,2016)。成像解决方案也可能在整个学习过程中随时间影响最终的数字可视化效果。由于不同品牌造影剂的物理和化学性质不同,计算机放射成像的非线性增强程度各异。传感器信噪比(SNR)、成像软件中的自定义参数设置以及存储优化相关的失真等变量,都会影响最终图像质量。例如,在数字组织病理学中,固定放大倍数下的十亿像素级全切片图像(WSI)的存储大小多年来从兆字节到千兆字节不等,这也相应地提高了数据集在微米每像素(MPP)方面的质量,有利于持续学习任务(Nakagawa 等,2023)。 数据漂移大致可分为协变量漂移、标签漂移和概念漂移。我们在表 2 中对其进行解释并附实例说明。医疗数据漂移可能对机器学习和深度学习模型的性能和可靠性产生重大影响(Sahiner 等,2023b)。传统机器学习通常严重依赖静态数据和特征工程,由人类专家手动选择相关特征。在数据漂移情况下,这些手工设计的特征可能信息量下降,模型难以适应新模式(Bayram 等,2022)。更具体地说,对于机器学习和深度学习而言,在数据统计特性不断演变的动态和非平稳环境中,这一问题尤为突出。了解漂移来源(如数据收集不一致和技术进步)对于开发稳健的模型至关重要(Sahiner 等,2023b)。积极的策略(包括定期模型更新和持续监测)对于确保机器学习模型在应对医疗数据漂移时保持有效和可靠至关重要,通过开发能够适应临床数据不断变化特性的机器学习模型,最终可改善患者护理和治疗效果。 ### 2.2 灾难性遗忘 人类大脑在一生中不断获取知识,学习新概念或任务不会对先前学到的内容产生不利影响。相反,学习几个密切相关的概念甚至会促进所有相关概念的学习。相比之下,人工神经网络虽受人类大脑启发,但往往存在“灾难性遗忘”问题,即学习新概念时容易覆盖或遗忘过去获得的知识(McCloskey 和 Cohen,1989;Ratcliff,1990)。这是因为模型会完全针对给定数据集进行优化。换句话说,一个针对任务 T1 优化权重的模型,在训练新任务 T2 时,会随意优化现有权重以满足任务 T2 的目标,而这些权重可能不再适合先前的任务 T1。这可能是一个重大挑战,尤其是在 AI 系统需要随时间学习和适应一系列任务或数据集的场景中。神经网络中的灾难性遗忘是一个有趣的现象,在近期研究中引起了广泛关注(Goodfellow 等,2013;Kumari 等,2024a)。医疗数据通常来自不同来源,成像协议、设备和患者群体各不相同。例如,不同医院的 MRI 扫描可能具有独特特征,导致领域偏移,使模型在接触新数据时忘记先前学到的特征。此外,医疗数据集通常规模有限且高度不平衡,某些疾病的病例远多于其他疾病。这种不平衡会加剧灾难性遗忘,因为模型可能过度专注于新引入的、更常见的类别,而牺牲旧的、较罕见的类别。解决灾难性遗忘问题对于开发可靠有效的医疗 AI 系统至关重要。通过实施正则化、重放、生成式重放、动态架构和领域自适应等策略,研究人员可以增强模型抗遗忘的稳健性,确保其在医疗应用中保持一致准确的性能。这对于维持诊断一致性、适应新医学知识以及提供可信的临床决策支持至关重要。 ### 2.3 持续学习概述 应对灾难性遗忘的一种简单解决方案是,每当遇到具有漂移分布或新类别的数据时,就使用旧数据和新数据从头开始重新训练模型(Lee 和 Lee,2020)。这种方法通常能达到预期的分类或分割性能,但会给计算和存储带来巨大负担,因此在实际部署中并不可行。此外,重新训练过程需要存储历史数据,这会导致隐私泄露,而这在医疗应用中可能成为此类策略的主要瓶颈。 相反,持续学习(CL)——也称为“连续学习”“增量学习”“序列学习”或“终身学习”——已在多个领域成为解决灾难性遗忘问题的有前景的方案(De Lange 等,2021;Mai 等,2022)。它有助于高效利用现有知识并整合新信息,而无需大量重新训练。持续学习的主要目标是开发技术和策略,使神经网络能够学习新任务的同时保留先前任务的知识。换句话说,它旨在使网络能够持续适应新信息,而不会完全抹去或降低在早期任务上的性能。总体而言,持续学习有助于解决灾难性遗忘问题,并减少存储历史数据所需的额外资源。持续学习提供了一系列策略和方法,如正则化(约束权重更新以避免遗忘已学概念)、重放(部分使用旧数据形式与当前数据一起重放)和架构修改(为不同任务预留或划分网络),以帮助神经网络记住和巩固来自过去任务的知识。这些策略有助于防止或减少灾难性遗忘,并提高模型的泛化能力。 ### 2.4 持续学习流程 持续学习流程的设计如图 1 所示,概述了构建持续学习流程所涉及的关键组件和阶段。给定一个问题陈述,首先需要确定它属于哪种持续学习场景,即未来数据是否可能存在领域偏移、是否会纳入新类别,或者最终应用(即任务本身)是否可能发生变化。例如,如果我们想要开发一个乳腺癌分类模型,使其能够处理来自不同中心的 H&E 数据集,那么不同中心的数据集可能存在漂移,因此属于持续学习的领域增量场景。关于持续学习场景的详细信息见第 3 节。 确定持续学习场景后,需要准备训练和测试数据集,以模拟数据集按顺序逐个到达的持续流。在文献中,数据集序列通常被称为任务、经验或片段,本手稿中这些术语可互换使用。对于每个片段,需准备单独的训练和测试数据;因此,对于给定的四个数据集序列,该流程需要四个训练-测试对来开发和评估持续学习模型。数据集准备就绪后,需确定适合具体应用的持续学习策略,并将其部署到现有的深度分类或分割模型中。持续学习策略多种多样,有些提供隐私保护学习,有些则性能更好,但代价是需要更多资源、存储且存在隐私泄露风险(因为它们存储部分历史数据)。通常,模型首先在第一个训练片段上训练,并在所有片段的测试数据上评估。之后,训练转向下一个片段,此时可能会纳入前一个片段的部分训练数据。在使用新训练数据更新模型后,再次在所有测试数据上评估,此过程重复直至最后一个片段。观察并分析每个片段的测试数据上计算的特定应用性能指标(如准确率、骰子相似系数等)在序列中的变化。然后,我们可以基于这些指标计算各种量化指标,以衡量遗忘和正向迁移。最后,将持续学习框架与最先进的方法以及非持续学习方法进行对比评估,后者提供了性能的上限和下限。联合或累积训练可获得最高的平均性能,而在当前片段上简单微调则性能最低(Kaustaban 等,2022;Lenga 等,2020)。 ### 2.5 持续学习的应用 由于持续学习能够缓解灾难性遗忘问题,因此在多个领域有众多应用。持续学习在实时场景中的效率和稳健性源于其适应能力、减少计算开销的能力以及应对动态数据挑战的能力。这使其成为时间约束、适应性和效率至关重要的应用场景中的宝贵方法。在医疗领域,持续学习已被广泛探索用于各种分割和分类应用(图 2),并且随着每年研究贡献的增加,其相对于静态模型的优势不断显现(图 3)。持续学习可以在资源受限的环境中提高诊断和决策能力。此外,它在患者实时监测、远程医疗和动态知识库维护方面也大有裨益。本节根据出版物数量介绍持续学习在医疗场景中最突出的应用。
Conclusion
结论
It has been proved and accepted by the research community that traditional machine learning models are ill-suited to handle the dynamicnature of data, and CL offers a promising solution. The systematicreview in this manuscript provides a comprehensive overview of thestate-of-the-art research in the field of CL in medical image analysis.We have explored various aspects of this evolving topic, including thechallenges posed by changing data distributions, hardware, imagingprotocols, data sources, tasks, and concept shifts in clinical practiceand the need for models to adapt seamlessly. Through a meticulousanalysis of the existing literature, we have examined the CL scenarios,strategies, level of supervision, experimental setup, evaluation schemes,and metrics employed to deal with the drifting nature of medicalimage data. Furthermore, diverse applications of CL in medical imageanalysis are discussed, ranging from disease classification and detectionto intricate tasks of image segmentation. Each application area presentsunique challenges and opportunities for research and development, andour review has shed light on the progress made in these domains.Additionally, a thorough collection and analysis of various evaluationmatrices for forward and backward transfer facilitate robust evaluationand benchmarking of approaches.In conclusion, this systematic review provides valuable insights intothe current state of CL adaptation in medical image processing tasks,unexplored challenges, and promising future research directions. Asmedical image analysis technology continues to advance, the development of CL models will be crucial for improving diagnostic accuracy,patient care, and overall healthcare outcomes.
研究界已证实并认可,传统机器学习模型难以应对数据的动态特性,而持续学习(CL)为此提供了一种极具前景的解决方案。本文献中的系统性综述全面概述了医学影像分析领域持续学习的最新研究进展。 我们深入探讨了这一不断发展的主题的多个方面,包括数据分布变化、硬件设备更新、成像协议调整、数据来源差异、任务类型演变以及临床实践中概念迁移所带来的挑战,同时强调了模型实现无缝适应的必要性。通过对现有文献的细致分析,我们考察了持续学习的应用场景、技术策略、监督级别、实验设置、评估方案以及用于应对医学影像数据漂移特性的各类指标。此外,本文还讨论了持续学习在医学影像分析中的多种应用,涵盖从疾病分类、检测到复杂图像分割任务等多个领域。每个应用领域都面临着独特的挑战和研发机遇,而我们的综述揭示了这些领域已取得的进展。 另外,本文对正向迁移和反向迁移的各类评估矩阵进行了全面收集与分析,为相关方法的稳健评估和基准测试提供了支持。 综上所述,本系统性综述为持续学习在医学影像处理任务中的应用现状、尚未探索的挑战以及极具前景的未来研究方向提供了宝贵见解。随着医学影像分析技术的不断进步,持续学习模型的开发对于提高诊断准确性、改善患者护理以及优化整体医疗健康 outcomes 至关重要。
Figure
图
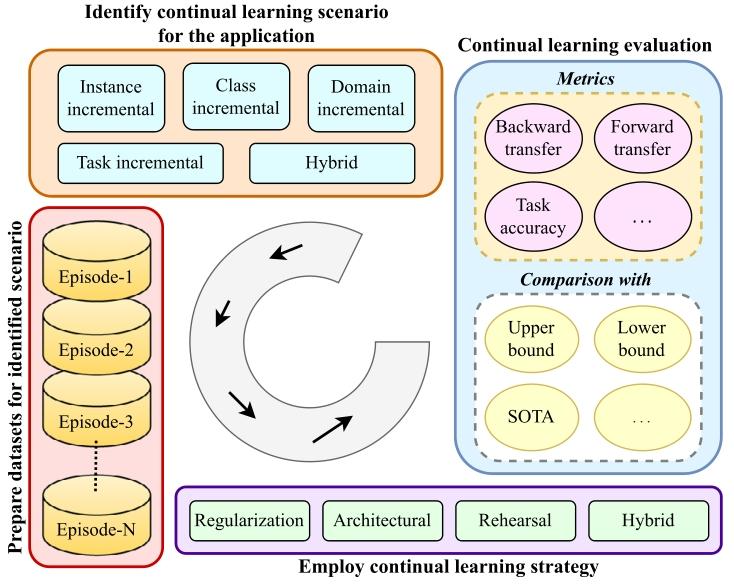
Fig. 1. A coarse level flowchart for designing a CL pipeline.
图1 设计持续学习(CL)流程的粗粒度流程图。
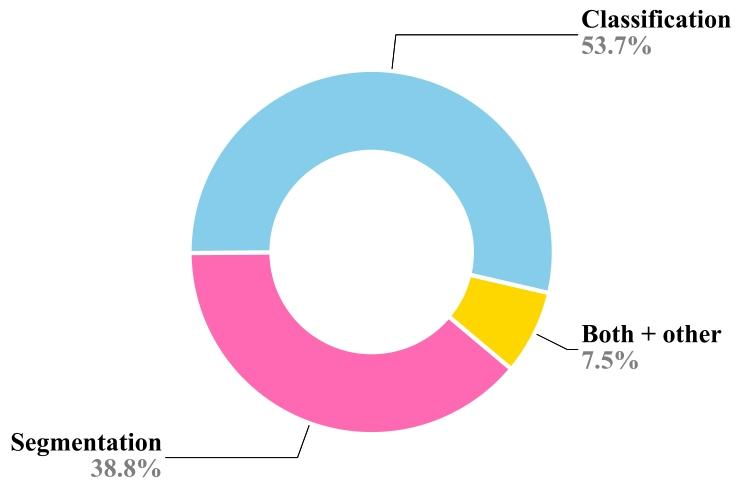
Fig. 2. Ratio of CL-based research for downstream applications
图2 基于持续学习(CL)的研究在下游应用中的占比。
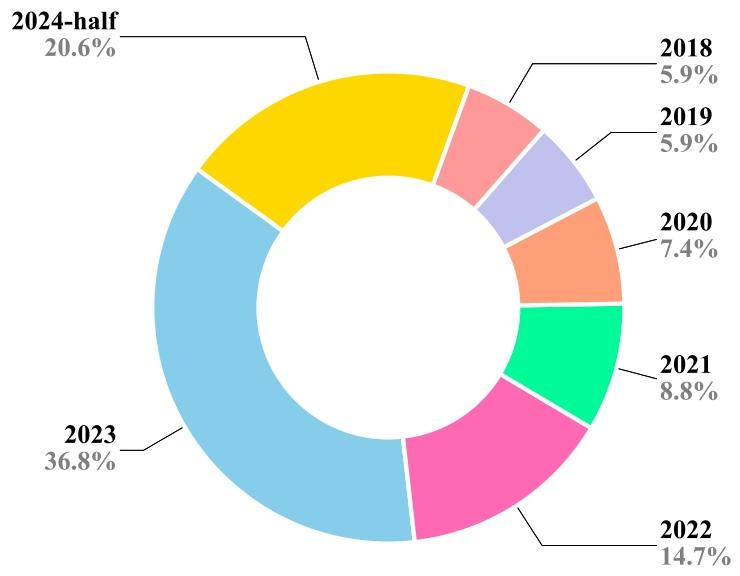
Fig. 3.CL-based research contributions over the years. Percentages represent thenumber of CL papers in the medical domain each year, showing the increasing trendand growing importance of CL research.
图3历年基于持续学习(CL)的研究贡献。百分比代表每年医学领域中持续学习相关论文的数量占比,体现了持续学习研究日益增长的趋势及其重要性的提升。
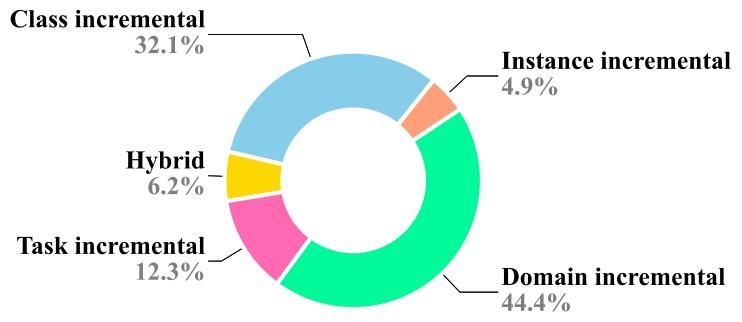
Fig. 4. Ratio of CL-based works for different incremental scenarios.
图4 不同增量场景下基于持续学习(CL)的研究占比。
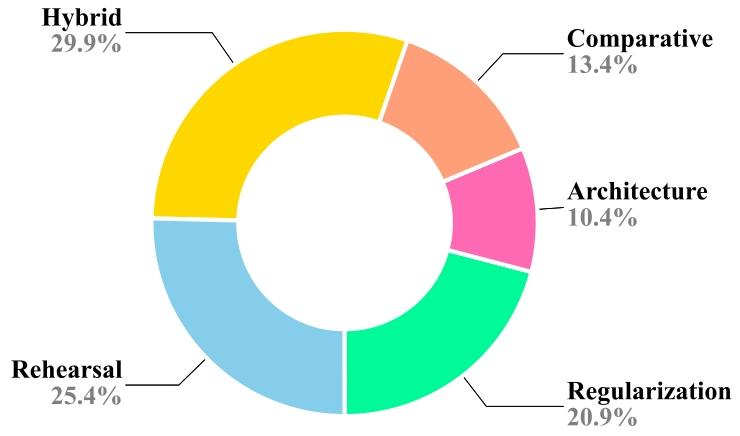
Fig. 5. Popularity of different CL strategies for medical image analysis.
图5 不同持续学习(CL)策略在医学影像分析中的普及度。
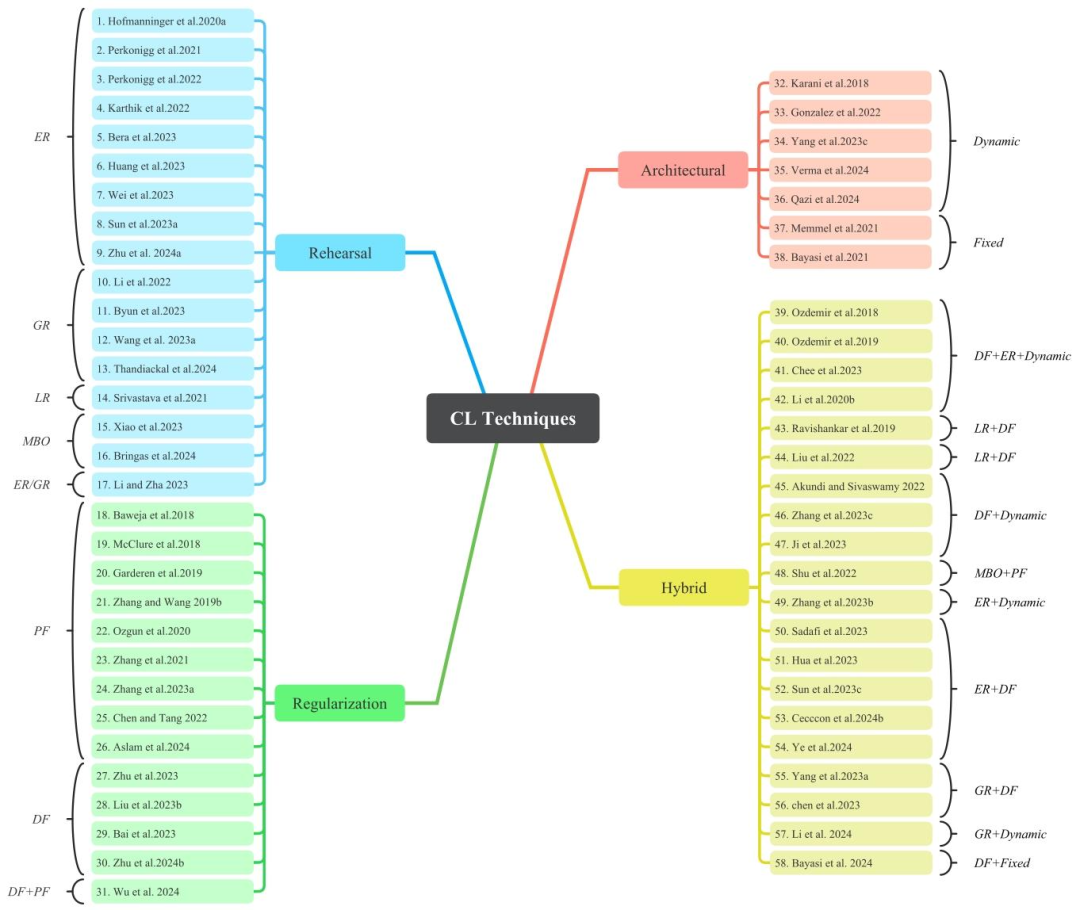
Fig. 6. The proposed CL taxonomy categorizes various CL models according to their underlying design principles. The abbreviations used are as follows: ER for Experience-replay,GR for Generative-replay, LR for Latent-replay, PF for Prior-focused, DF for Data-focused, and MBO for Memory Buffer Optimization. 1. Hofmanninger et al. (2020a), 2. Perkonigget al. (2021), 3. Perkonigg et al. (2022), 4. Karthik et al. (2022), 5. Bera et al. (2023), 6. Huang et al. (2023), 7. Wei et al. (2023), 8. Sun et al. (2023a), 9. Zhu et al. (2024a),Li et al. (2022), 11. Byun et al. (2023) 12. Wang et al. (2023a) 13. Thandiackal et al. (2024) 14. Srivastava et al. (2021) 15. Xiao et al. (2023) 16. Bringas et al. (2024)Li and Jha (2023) 18. Baweja et al. (2018), 19. McClure et al. (2018), 20. van Garderen et al. (2019), 21. Zhang and Wang (2019b) 22. Özgün et al. (2020), 23. Zhang et al.(2021), 24. Zhang et al. (2023a), 25. Chen and Tang (2022), 26. Aslam et al. (2024) 27. Zhu et al. (2023), 28. Liu et al. (2023a), 29. Bai et al. (2023) 30. Zhu et al. (2024b)Wu et al. (2024) 32. Karani et al. (2018), 33. González et al. (2022), 34. Yang et al. (2023a) 35. Verma et al. (2024) 36. Qazi et al. (2024) 37. Memmel et al. (2021),Bayasi et al. (2021), 39. Ozdemir et al. (2018), 40. Ozdemir and Goksel (2019), 41. Chee et al. (2023), 42. Li et al. (2020b), 43. Ravishankar et al. (2019), 44. Liu et al.(2022), 45. Akundi and Sivaswamy (2022), 46. Zhang et al. (2023c) 47. Ji et al. (2023) 48. Shu et al. (2022) 49. Zhang et al. (2023b), 50. Sadafi et al. (2023), 51. Hua et al.(2023) 52. Sun et al. (2023c) 53. Ceccon et al. (2024b) 54. Ye et al. (2024) 55. Yang et al. (2023b), 56. Chee et al. (2023), 57. Li et al. (2024), 58. Bayasi et al. (2024b).
图6 本文提出的持续学习(CL)分类法根据各类持续学习模型的底层设计原理对其进行分类。所使用的缩写如下:ER 代表经验重放(Experience-replay)、GR 代表生成式重放(Generative-replay)、LR 代表潜在重放(Latent-replay)、PF 代表优先聚焦(Prior-focused)、DF 代表数据聚焦(Data-focused)、MBO 代表记忆缓冲优化(Memory Buffer Optimization)。 1. Hofmanninger 等(2020a) 2. Perkonigg 等(2021) 3. Perkonigg 等(2022) 4. Karthik 等(2022) 5. Bera 等(2023) 6. Huang 等(2023) 7. Wei 等(2023) 8. Sun 等(2023a) 9. Zhu 等(2024a) 10. Li 等(2022) 11. Byun 等(2023) 12. Wang 等(2023a) 13. Thandiackal 等(2024) 14. Srivastava 等(2021) 15. Xiao 等(2023) 16. Bringas 等(2024) 17. Li 和 Jha(2023) 18. Baweja 等(2018) 19. McClure 等(2018) 20. van Garderen 等(2019) 21. Zhang 和 Wang(2019b) 22. Özgün 等(2020) 23. Zhang 等(2021) 24. Zhang 等(2023a) 25. Chen 和 Tang(2022) 26. Aslam 等(2024) 27. Zhu 等(2023) 28. Liu 等(2023a) 29. Bai 等(2023) 30. Zhu 等(2024b) 31. Wu 等(2024) 32. Karani 等(2018) 33. González 等(2022) 34. Yang 等(2023a) 35. Verma 等(2024) 36. Qazi 等(2024) 37. Memmel 等(2021) 38. Bayasi 等(2021) 39. Ozdemir 等(2018) 40. Ozdemir 和 Goksel(2019) 41. Chee 等(2023) 42. Li 等(2020b) 43. Ravishankar 等(2019) 44. Liu 等(2022) 45. Akundi 和 Sivaswamy(2022) 46. Zhang 等(2023c) 47. Ji 等(2023) 48. Shu 等(2022) 49. Zhang 等(2023b) 50. Sadafi 等(2023) 51. Hua 等(2023) 52. Sun 等(2023c) 53. Ceccon 等(2024b) 54. Ye 等(2024) 55. Yang 等(2023b) 56. Chee 等(2023) 57. Li 等(2024) 58. Bayasi 等(2024b)
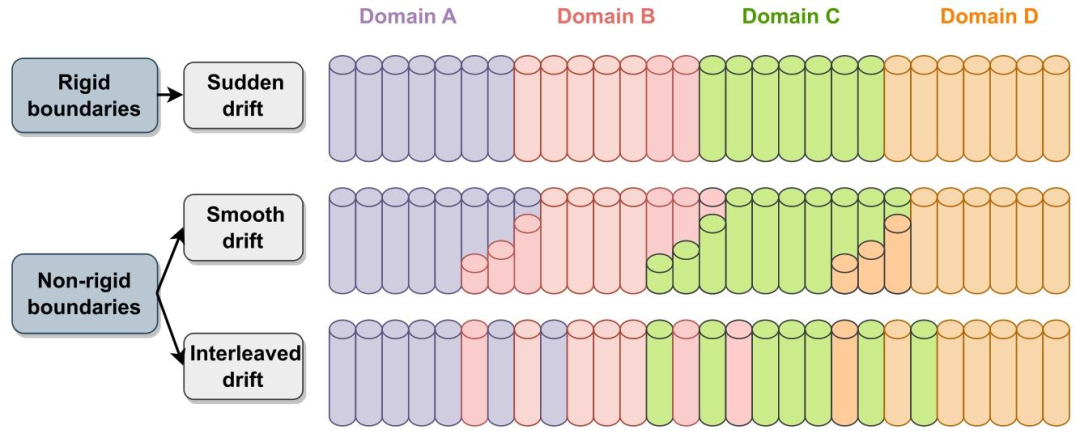
Fig. 7. A demonstration for rigid and non-rigid task/domain boundaries for an example sequence of four domains in a CL pipeline.
图7 持续学习(CL)流程中四个领域序列的刚性与非刚性任务/领域边界示例演示。
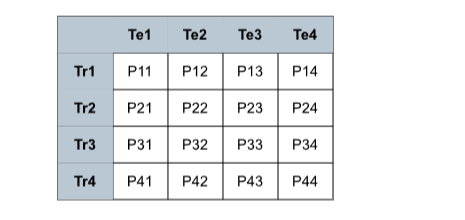
Fig. 8. Train-test performance matrix.
图8 训练-测试性能矩阵。
Table
表
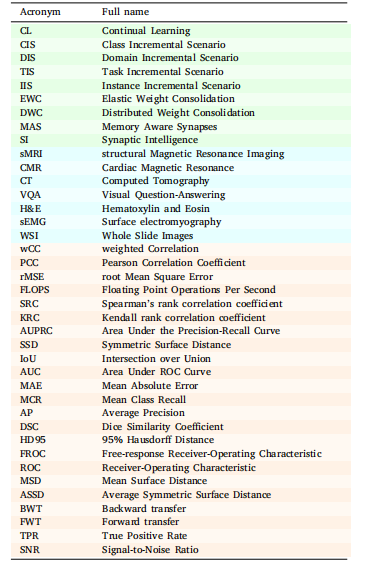
Table 1Abbreviations and their expansion. Green rows signify abbreviationsrelated to CL (scenarios and techniques), cyan corresponds to imagingmodalities and techniques, while orange is associated with evaluationmetrics.
表1 缩写及其全称。绿色行表示与持续学习(CL)相关的缩写(场景和技术),青色行对应成像模态和技术,橙色行则与评估指标相关。

Table 2Data drift categorization.
表2 数据漂移分类表。
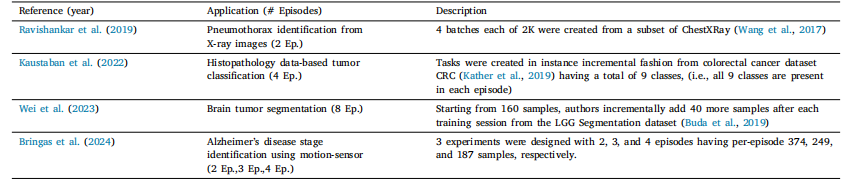
Table 3List of various instance incremental scenarios in literature
表3 文献中各类实例增量场景的列表。
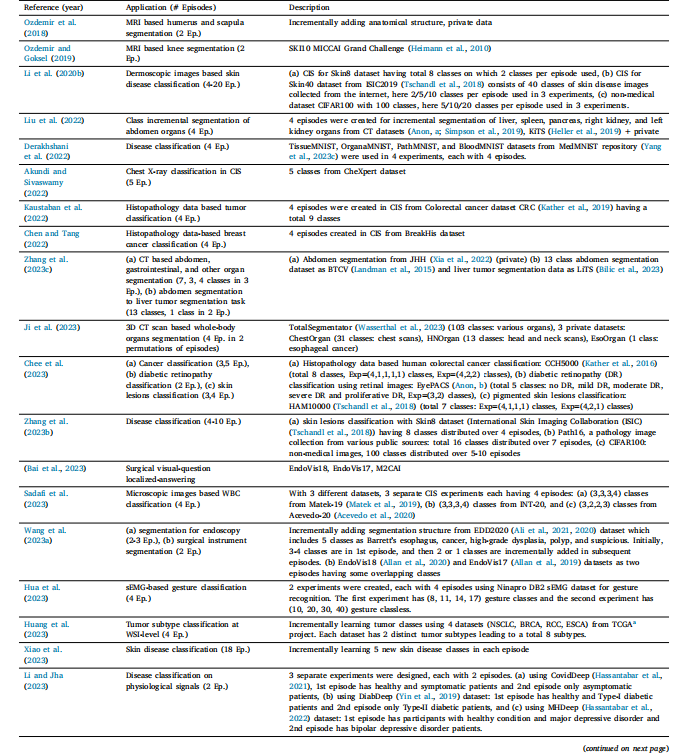
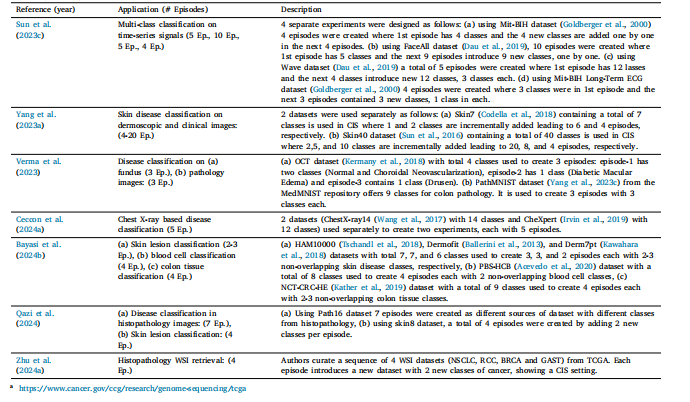
Table 4List of various class incremental scenarios in literature.
表4文献中各类类别增量场景的列表。
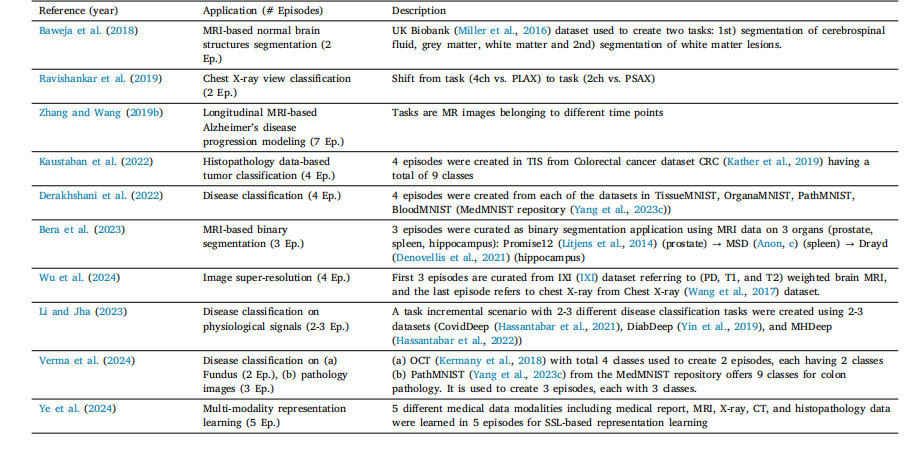
Table 5List of various task incremental scenarios in literature
表5 文献中各类任务增量场景的列表。
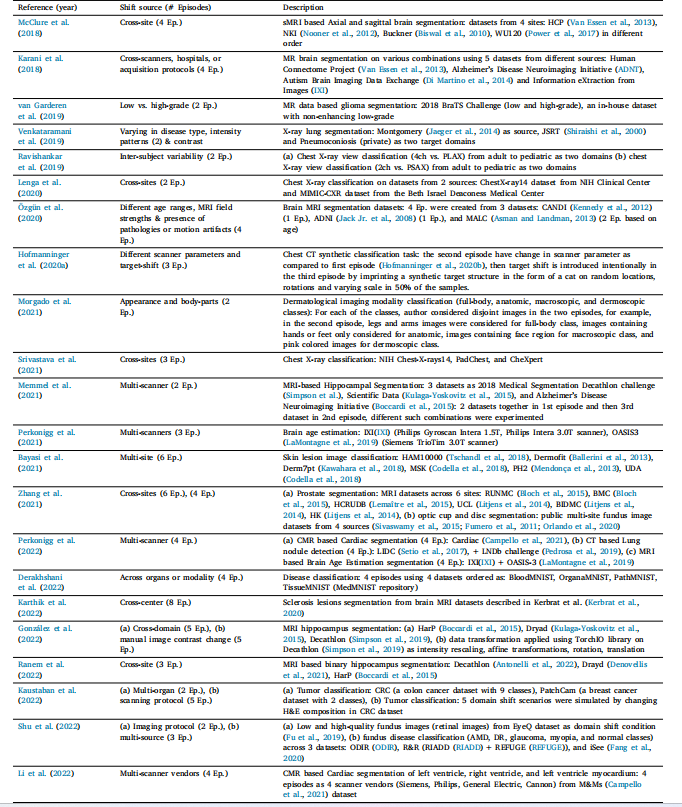
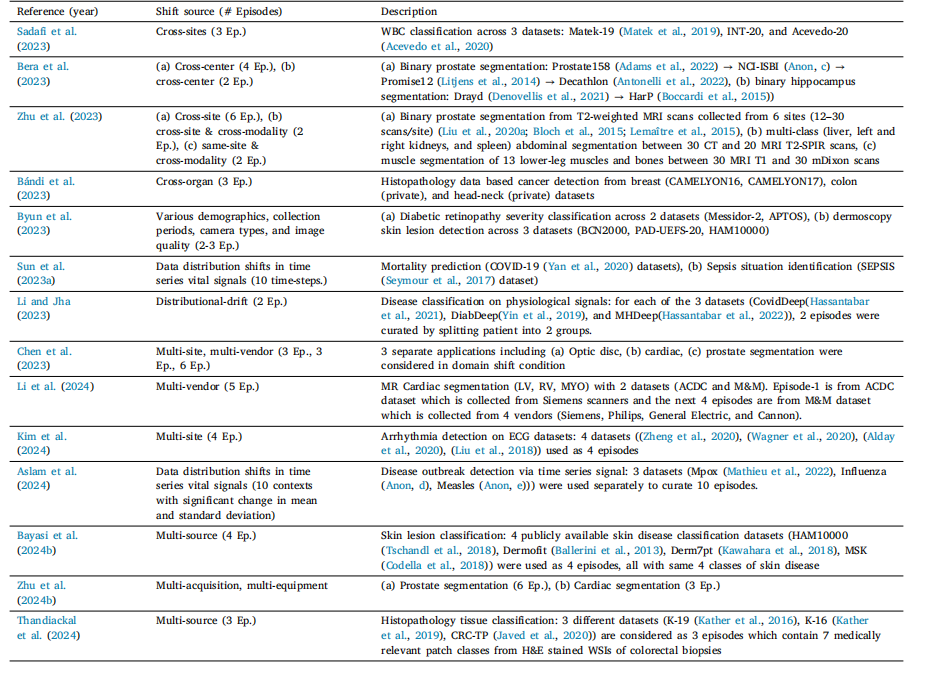
Table 6List of various domain shift scenarios in literature
表6 文献中各类领域偏移场景的列表。
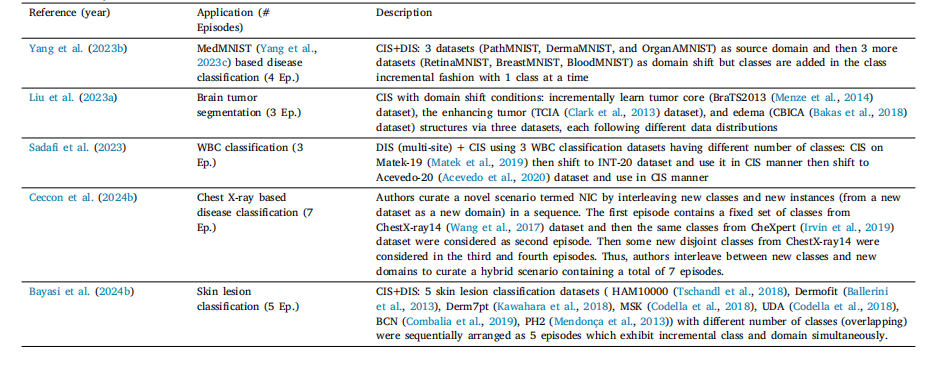
Table 7List of various hybrid CL scenarios in literature
表7 文献中各类混合持续学习(CL)场景的列表。
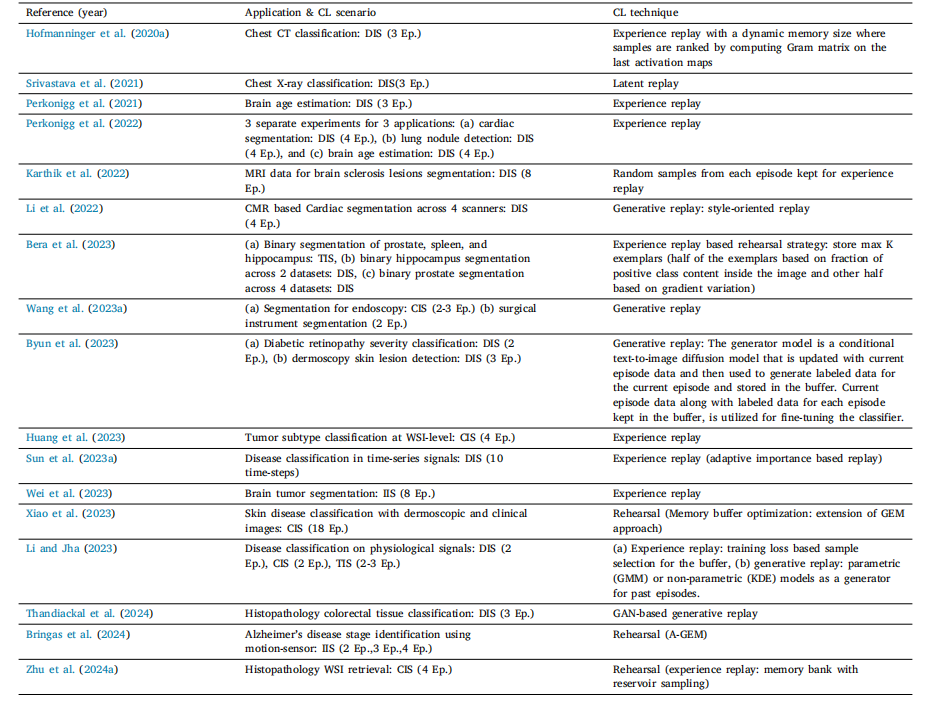
Table 8List of various rehearsal based works in literature
表8 文献中各类基于重放策略的研究列表。
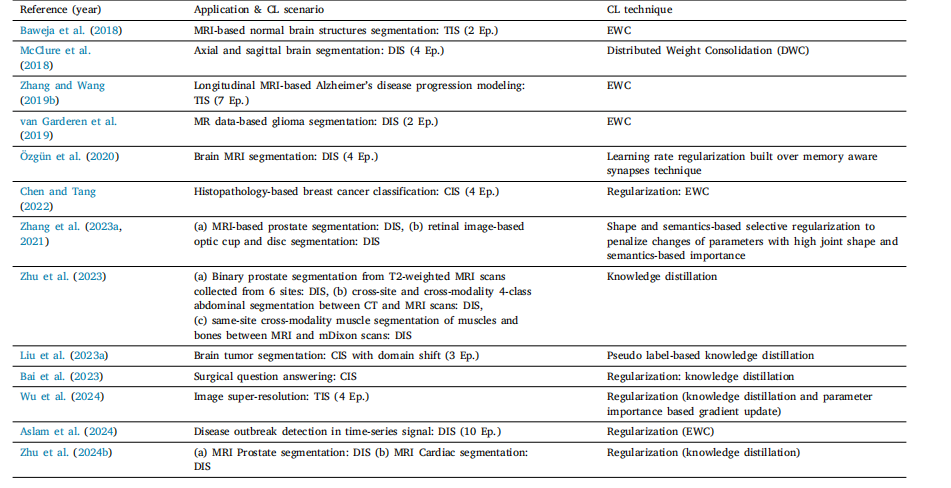
Table 9List of various regularization based works in literature
表9 文献中各类基于正则化方法的研究列表。
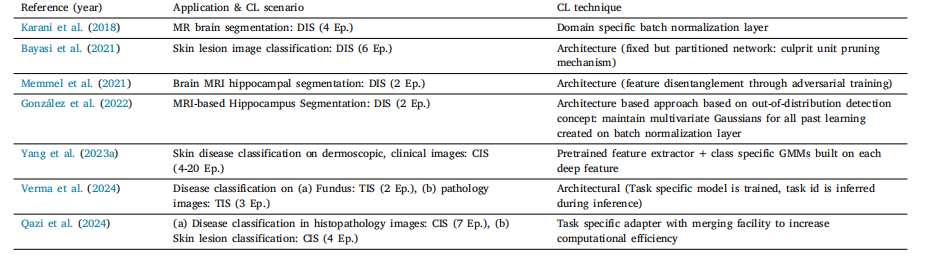
Table 10List of various architecture based works in literature
表10 文献中各类基于架构调整的研究列表。
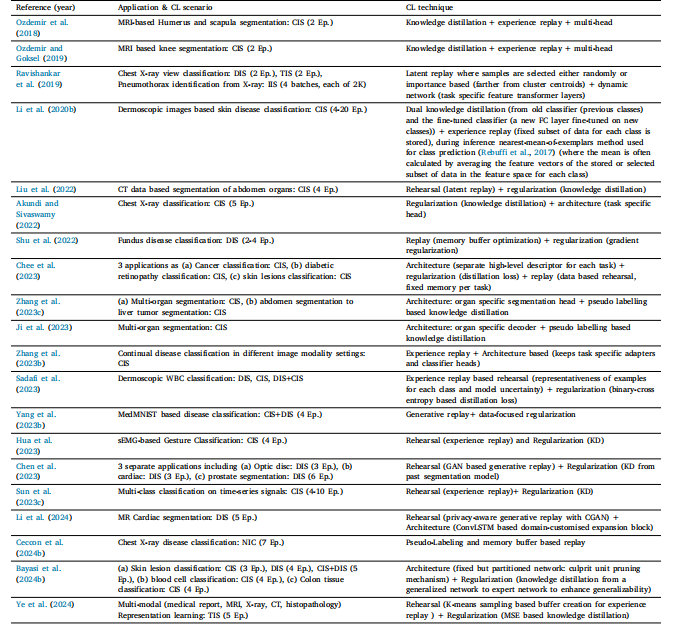
Table 11List of various hybrid CL technique based works in literature
表 11 文献中各类基于混合持续学习(CL)技术的研究列表
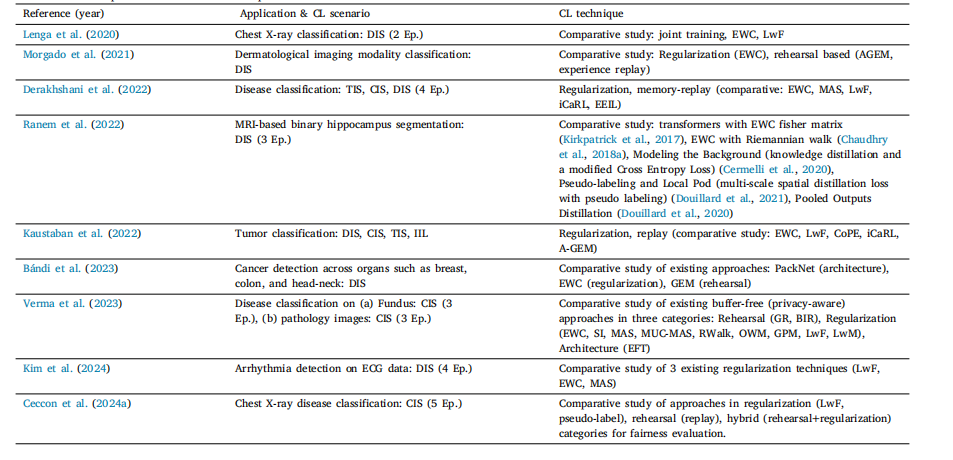
Table 12List of various comparative studies of CL techniques in literature
表 12 文献中各类持续学习(CL)技术的对比研究列表

Table 13Metrics for backward transfer. For ease of readability, terms in equations are color-coded to refer to the corresponding cells in the matrix (last column).
表13 反向迁移指标。为便于阅读,公式中的术语采用彩色编码,对应矩阵中的相应单元格(最后一列)。

Table 14Metrics for forward transfer. For ease of readability, terms in equations are color-coded to refer to the corresponding cells in the matrix (last column)
表14 正向迁移指标。为便于阅读,公式中的术语采用彩色编码,对应矩阵中的相应单元格(最后一列)。
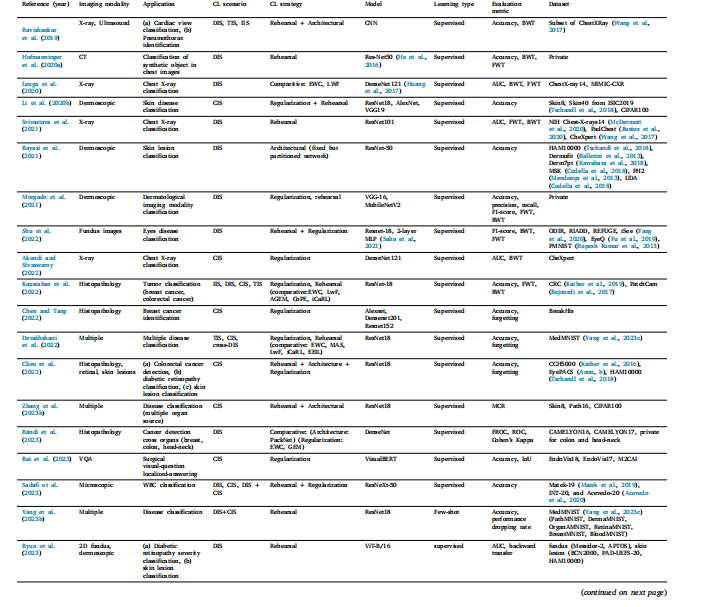
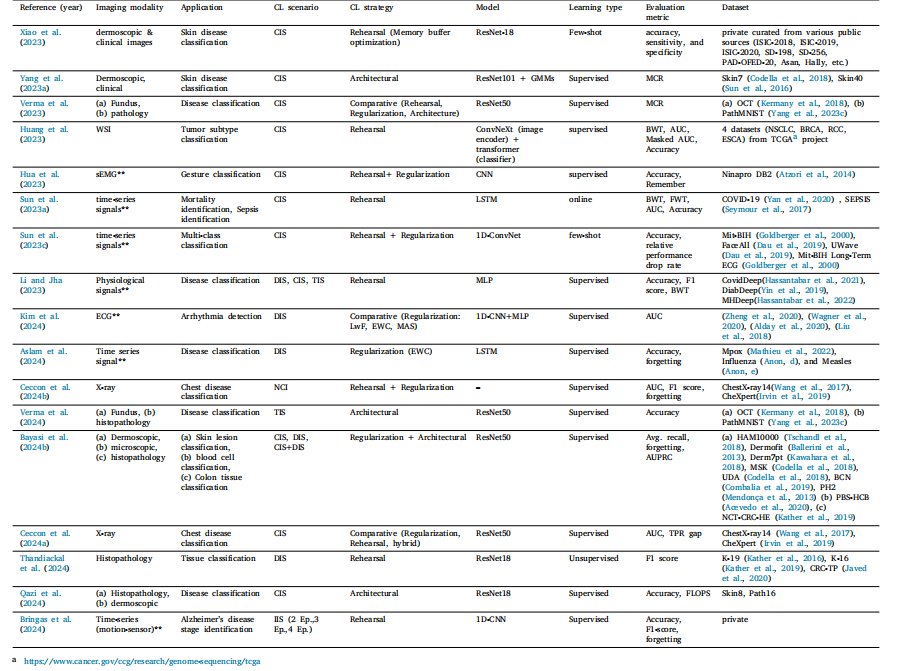
Table 15Literature for CL based classification. (**) indicates non-imaging modality
表 15 基于持续学习(CL)的分类研究文献。(**)表示非成像模态
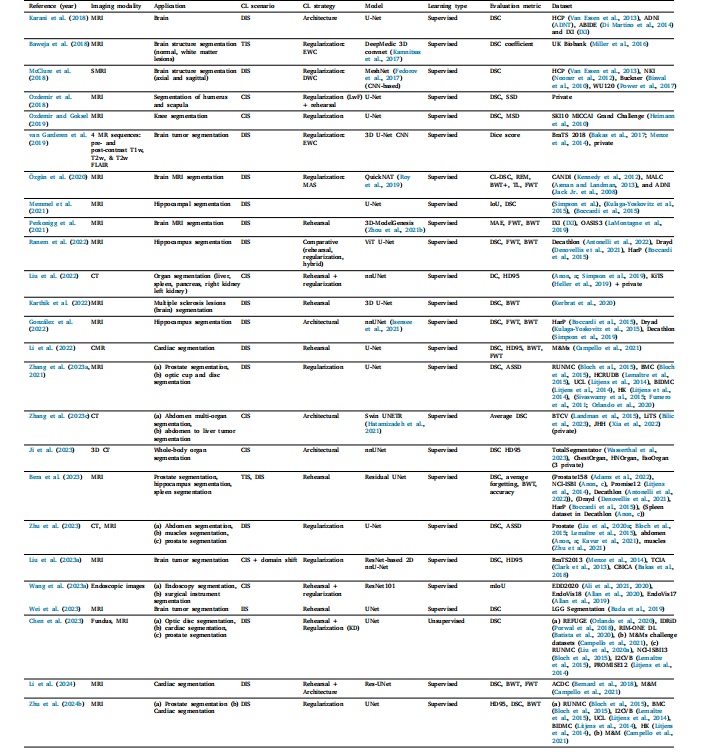
Table 16Literature for CL based segmentation
表16 基于持续学习(CL)的分割研究文献
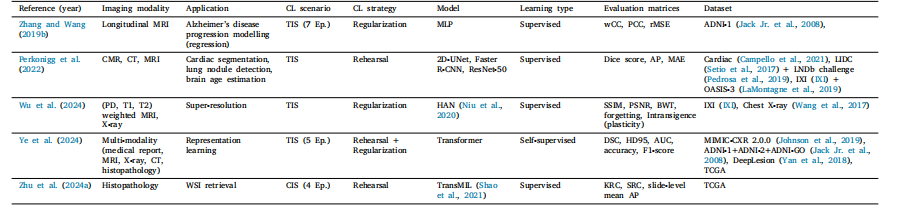
Table 17CL Literature for classification + segmentation and other application.
表 17 用于分类 + 分割及其他应用的持续学习文献