PostgreSQL 流程---更新
PostgreSQL 流程—更新
概述
更新操作是DML操作中最复杂的一个,在PostgreSQL对更新的实现方式是“先插入,再删除”,所以在PostgreSQL中更新操作实际上包含了是数据库的所有常用操作:查询、插入、删除。简单来讲,PostgreSQL的更新操作有如下3个步骤:
- 根据查询条件获取满足条件的元组。
- 根据原始元组和更新字段创建新元组,并执行插入。
- 删除原始元组。
PostgreSQL对步骤1中查询的处理和普通查询完全一致,都是基于MVCC的查询。那么现在我们考虑三个场景。
场景1
假设有一账户,用balance表示其金额,当前balance值为100元。下面有两个事务分别向账户中存入100元,具体情况如下表。
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起存款:update account set balance = balance+ 100; | |
| T4 | 发起存款:update account set balance = balance+ 100; | 完成存款:insert一条balance值为200的记录 |
| T5 | 事务快照:<事务B> | |
| T6 | 查询需要更新的元组 | 提交事务 |
| T7 | 完成存款 | |
| T8 | 提交事务 |
在上述场景中,我们要注意以下几个时间点:
-
T4
在T4时刻,事务B完成了update account set balance = balance+ 100;由于PostgreSQL的update操作是由insert + delete完成的,并且delete只会设置xmax,然后由MVCC来判断可见性。所以此时数据库中存在两条元组,balance分别为100和200。
-
T5
在T5事务A开始了update的第一个步骤,做一次事务快照,此时由于事务B还未提交,所以事务B存在于快照中。
-
T6
在T6事务A开始了update的查询操作,和普通查询一样,事务A会根据事务快照判断元组的可见性。由于事务B存在于事务快照中,所以更新后的元组对于事务A不可见,该查询会返回更新前的元组,即balance为100的元组。
-
T7
这一步非常关键,因为在这一步我们会真正执行修改操作,将balance的值加上100元,我们注意两点:
-
事务A和事务B由于修改了同一行元组,所以原则上是需要行锁的,在T6时事务B已经提交,所以T7时事务A并没有对元组加行锁(PostgreSQL只有发现元组可能已经被其他事务修改时才会加行锁,这一点会在后面说明)。
-
T6时,事务A依据MVCC查询到了修改前的元组,元组的balance为100。那么在做更新时我们应该如何更新?具体而言,我们应该更新事务A查询到了这条old tuple还是当前的new tuple,还有我们是应该使用old tuple的balance(值为100),还是应该使用new tuple的balance(值为200)?
其实这个两个问题就是所谓的更新丢失问题,也是接下来会重点阐述的问题,现在先给出结论:
由于old tuple实际已经被事务B删除了,并且该删除已经提交,所以如果事务A再去更新old tuple那么必然这个更新会丢失!所以显然不能更新old tuple,而应该更新new tuple。既然是更新new tuple,那么自然是在new tuple的balance上加上100,将balance的值更新的300,从另外一个角度上来看,如果采用old tuple的balance值,那么最终将会把balance的值更新为200,这也是更新丢失。
所以,所有的更新都应该在最新版本的tuple上执行,虽然在查询阶段可能会返回老版本的元组。
-
场景2
假设test表有一个字段id,id的初始值为1,考虑如下场景:
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起更新:update test set id = id+1 where id = 1; | |
| T4 | 事务快照:<事务B> | 发起更新:update test set id = id+1 where id = 1; |
| T5 | 查询需要更新的元组 | 事务快照:<事务A> |
| T6 | 查询需要更新的元组 | |
| T7 | 执行更新 | |
| T8 | 事务提交 | |
| T9 | 执行更新 | |
| T10 | 事务提交 |
同样,我们对几个时间点进行说明:
-
T5,T6
由于事务B在T7时才执行更新,所以T5,T6时数据库只有一个版本的元组,元组id为1。那么事务A和事务B分别于T5和T6时刻查询到了这条id为1的元组,均满足where条件。
-
T7,T8
事务B对元组执行了更新并提交,此时数据库中多了一条id为2的new tuple。这种情况在多线程\多进程下很可能发生,由于进程调度,虽然事务A比事务B先发起,但事务B先执行了更新。
-
T9
此时,事务A对元组进行更新。此时考虑一个问题:事务A还可以更新这条元组么?从场景1中,我们得到一个结论更新操作必须更新new tuple。而此时new tuple的id为2,已经不满足id = 1的条件,所以事务A不会对执行更新操作。

场景3
假设test表有一个字段id,id的初始值为1,我们对场景2进行一下修改:
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起更新:update test set id = id+1 where id = 2; | |
| T4 | 事务快照:<事务B> | 发起更新:update test set id = id+1 where id = 1; |
| T5 | 事务快照:<事务A> | |
| T6 | 查询需要更新的元组 | |
| T7 | 执行更新 | |
| T8 | 事务提交 | |
| T9 | 查询需要更新的元组 | |
| T10 | 执行更新 | |
| T11 | 事务提交 |
我们修改了事务A的查询条件,改为了where id = 2。事务A在T4时刻做的事务快照,此时事务B为活跃事务,所以事务A在T9进行查询时,虽然事务B的修改操作已经提交,但是new tuple对事务A不可见,事务A获取的是old tuple,显然old tuple不满足id = 2,所以不会对元组进行更新。
下面我们将从源代码的角度详细阐述PostgreSQL的更新流程,看看他是如何应对上述三个场景的。
更新主流程
更新操作相关函数的调用顺序为:ExecutePlan > ExecProcNode > ExecModifyTable。其中ExecModifyTable为更新操作的主要函数,该函数可以分为两个步骤:
- 调用ExecProcNode获取一条可见且合法的元组。
- 调用ExecUpdate函数执行更新操作。
源代码如下:
TupleTableSlot *
ExecModifyTable(ModifyTableState *node)
{EState *estate = node->ps.state;CmdType operation = node->operation;ResultRelInfo *saved_resultRelInfo;ResultRelInfo *resultRelInfo;PlanState *subplanstate;JunkFilter *junkfilter;TupleTableSlot *slot;TupleTableSlot *planSlot;ItemPointer tupleid;ItemPointerData tuple_ctid;HeapTupleData oldtupdata;HeapTuple oldtuple;/** This should NOT get called during EvalPlanQual; we should have passed a* subplan tree to EvalPlanQual, instead. Use a runtime test not just* Assert because this condition is easy to miss in testing. (Note:* although ModifyTable should not get executed within an EvalPlanQual* operation, we do have to allow it to be initialized and shut down in* case it is within a CTE subplan. Hence this test must be here, not in* ExecInitModifyTable.)*/if (estate->es_epqTuple != NULL)elog(ERROR, "ModifyTable should not be called during EvalPlanQual");/** If we've already completed processing, don't try to do more. We need* this test because ExecPostprocessPlan might call us an extra time, and* our subplan's nodes aren't necessarily robust against being called* extra times.*/if (node->mt_done)return NULL;/** On first call, fire BEFORE STATEMENT triggers before proceeding.*/if (node->fireBSTriggers){fireBSTriggers(node);node->fireBSTriggers = false;}/* Preload local variables */resultRelInfo = node->resultRelInfo + node->mt_whichplan;subplanstate = node->mt_plans[node->mt_whichplan];junkfilter = resultRelInfo->ri_junkFilter;/** es_result_relation_info must point to the currently active result* relation while we are within this ModifyTable node. Even though* ModifyTable nodes can't be nested statically, they can be nested* dynamically (since our subplan could include a reference to a modifying* CTE). So we have to save and restore the caller's value.*/saved_resultRelInfo = estate->es_result_relation_info;estate->es_result_relation_info = resultRelInfo;/** Fetch rows from subplan(s), and execute the required table modification* for each row.*/for (;;){/** Reset the per-output-tuple exprcontext. This is needed because* triggers expect to use that context as workspace. It's a bit ugly* to do this below the top level of the plan, however. We might need* to rethink this later.*/ResetPerTupleExprContext(estate);/* 步骤1:获取一条可见且合法的元组 */planSlot = ExecProcNode(subplanstate);if (TupIsNull(planSlot)){/* advance to next subplan if any */node->mt_whichplan++;if (node->mt_whichplan < node->mt_nplans){resultRelInfo++;subplanstate = node->mt_plans[node->mt_whichplan];junkfilter = resultRelInfo->ri_junkFilter;estate->es_result_relation_info = resultRelInfo;EvalPlanQualSetPlan(&node->mt_epqstate, subplanstate->plan,node->mt_arowmarks[node->mt_whichplan]);continue;}elsebreak;}/** If resultRelInfo->ri_usesFdwDirectModify is true, all we need to do* here is compute the RETURNING expressions.*/if (resultRelInfo->ri_usesFdwDirectModify){Assert(resultRelInfo->ri_projectReturning);/** A scan slot containing the data that was actually inserted,* updated or deleted has already been made available to* ExecProcessReturning by IterateDirectModify, so no need to* provide it here.*/slot = ExecProcessReturning(resultRelInfo, NULL, planSlot);estate->es_result_relation_info = saved_resultRelInfo;return slot;}EvalPlanQualSetSlot(&node->mt_epqstate, planSlot);slot = planSlot;tupleid = NULL;oldtuple = NULL;if (junkfilter != NULL){/** extract the 'ctid' or 'wholerow' junk attribute.*/if (operation == CMD_UPDATE || operation == CMD_DELETE){char relkind;Datum datum;bool isNull;relkind = resultRelInfo->ri_RelationDesc->rd_rel->relkind;if (relkind == RELKIND_RELATION || relkind == RELKIND_MATVIEW){datum = ExecGetJunkAttribute(slot,junkfilter->jf_junkAttNo,&isNull);/* shouldn't ever get a null result... */if (isNull)elog(ERROR, "ctid is NULL");tupleid = (ItemPointer) DatumGetPointer(datum);tuple_ctid = *tupleid; /* be sure we don't free* ctid!! */tupleid = &tuple_ctid;}/** Use the wholerow attribute, when available, to reconstruct* the old relation tuple.** Foreign table updates have a wholerow attribute when the* relation has an AFTER ROW trigger. Note that the wholerow* attribute does not carry system columns. Foreign table* triggers miss seeing those, except that we know enough here* to set t_tableOid. Quite separately from this, the FDW may* fetch its own junk attrs to identify the row.** Other relevant relkinds, currently limited to views, always* have a wholerow attribute.*/else if (AttributeNumberIsValid(junkfilter->jf_junkAttNo)){datum = ExecGetJunkAttribute(slot,junkfilter->jf_junkAttNo,&isNull);/* shouldn't ever get a null result... */if (isNull)elog(ERROR, "wholerow is NULL");oldtupdata.t_data = DatumGetHeapTupleHeader(datum);oldtupdata.t_len =HeapTupleHeaderGetDatumLength(oldtupdata.t_data);ItemPointerSetInvalid(&(oldtupdata.t_self));/* Historically, view triggers see invalid t_tableOid. */oldtupdata.t_tableOid =(relkind == RELKIND_VIEW) ? InvalidOid :RelationGetRelid(resultRelInfo->ri_RelationDesc);oldtuple = &oldtupdata;}elseAssert(relkind == RELKIND_FOREIGN_TABLE);}/** apply the junkfilter if needed.*/if (operation != CMD_DELETE)slot = ExecFilterJunk(junkfilter, slot);}switch (operation){case CMD_INSERT:slot = ExecInsert(node, slot, planSlot,node->mt_arbiterindexes, node->mt_onconflict,estate, node->canSetTag);break;case CMD_UPDATE:/* 步骤2:执行更新操作 */slot = ExecUpdate(tupleid, oldtuple, slot, planSlot,&node->mt_epqstate, estate, node->canSetTag);break;case CMD_DELETE:slot = ExecDelete(tupleid, oldtuple, planSlot,&node->mt_epqstate, estate, node->canSetTag);break;default:elog(ERROR, "unknown operation");break;}/** If we got a RETURNING result, return it to caller. We'll continue* the work on next call.*/if (slot){estate->es_result_relation_info = saved_resultRelInfo;return slot;}}/* Restore es_result_relation_info before exiting */estate->es_result_relation_info = saved_resultRelInfo;/** We're done, but fire AFTER STATEMENT triggers before exiting.*/fireASTriggers(node);node->mt_done = true;return NULL;
}
ExecProcNode
ExecProcNode函数我们在全表遍历时已经介绍过,该函数用于获取一条可见且合法的元组,但是在这里我们需要做一点扩展,因为ExecProcNode除了会返回元组,还会返回查询字段的值。例如:当前test表中id字段的值为1,我们做如下查询:
select id,id+1,id+10,id+100 from test;
ExecProcNode会返回TupleTableSlot类型的solt对象,solt中的tts_values成员就存放了上述select语句,针对当前元组计算出的查询结果:
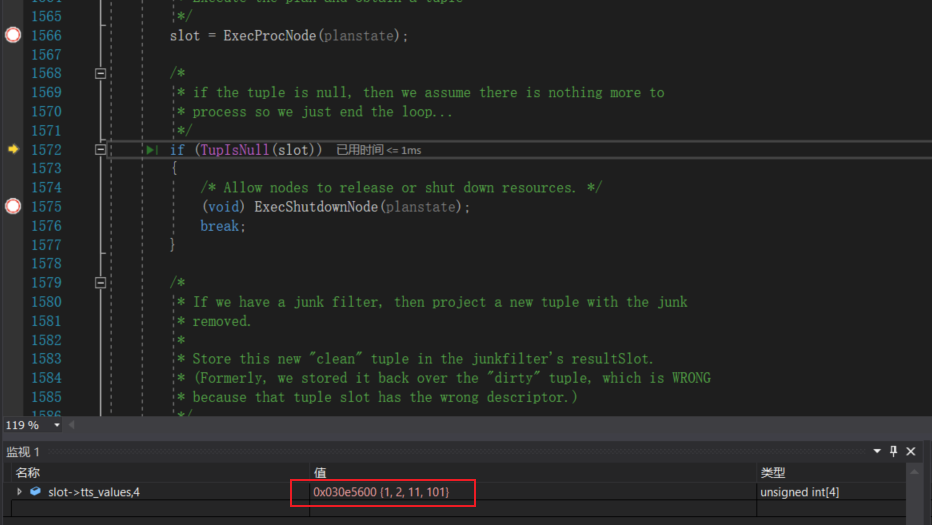
补充
其实更准确的说法是,在普通查询时ExecProcNode不返回合法元组,而只会返回查询结果,对上述select语句solt的tts_tuple成员为NULL。而对于聚合函数,ExecProcNode不返回查询结果,只返回合法元组。
而对于update操作而言,ExecProcNode返回的则是SET表达式的结果,例如:当前test表中id字段的值为1,我们做如下修改:
update test set id = id + 198;
接下来我们来看看tts_values的值是如何计算出来的。我们首先来回顾下在全表遍历中讲到的ExecScan函数,该函数有如下3个步骤:
- 调用ExecScanFetch获取一条可见的元组,存放在slot->tts_tuple中。
- 调用ExecQual判断元组是否满足where条件。
- 调用ExecProject计算查询结果。
下面我们重点来看看ExecProject的实现。
ExecProject
ExecProject用于计算当前元组对应的查询结果,主要可以分为两个步骤:
-
调用slot_getsomeattrs函数从元组中获取字段的值。
slot_getsomeattrs函数中,真正实现字段值获取的函数为:slot_deform_tuple。
-
调用ExecTargetList,根据字段值计算表达式值。
代码如下:
TupleTableSlot *
ExecProject(ProjectionInfo *projInfo, ExprDoneCond *isDone)
{TupleTableSlot *slot;ExprContext *econtext;int numSimpleVars;/** sanity checks*/Assert(projInfo != NULL);/** get the projection info we want*/slot = projInfo->pi_slot;econtext = projInfo->pi_exprContext;/* Assume single result row until proven otherwise */if (isDone)*isDone = ExprSingleResult;/** Clear any former contents of the result slot. This makes it safe for* us to use the slot's Datum/isnull arrays as workspace. (Also, we can* return the slot as-is if we decide no rows can be projected.)*/ExecClearTuple(slot);/** Force extraction of all input values that we'll need. The* Var-extraction loops below depend on this, and we are also prefetching* all attributes that will be referenced in the generic expressions.* 步骤1:调用slot_getsomeattrs函数从元组中获取字段的值*/if (projInfo->pi_lastInnerVar > 0)slot_getsomeattrs(econtext->ecxt_innertuple,projInfo->pi_lastInnerVar);if (projInfo->pi_lastOuterVar > 0)slot_getsomeattrs(econtext->ecxt_outertuple,projInfo->pi_lastOuterVar);if (projInfo->pi_lastScanVar > 0)slot_getsomeattrs(econtext->ecxt_scantuple,projInfo->pi_lastScanVar);/** Assign simple Vars to result by direct extraction of fields from source* slots ... a mite ugly, but fast ...*/numSimpleVars = projInfo->pi_numSimpleVars;if (numSimpleVars > 0){Datum *values = slot->tts_values;bool *isnull = slot->tts_isnull;int *varSlotOffsets = projInfo->pi_varSlotOffsets;int *varNumbers = projInfo->pi_varNumbers;int i;if (projInfo->pi_directMap){/* especially simple case where vars go to output in order */for (i = 0; i < numSimpleVars; i++){char *slotptr = ((char *) econtext) + varSlotOffsets[i];TupleTableSlot *varSlot = *((TupleTableSlot **) slotptr);int varNumber = varNumbers[i] - 1;values[i] = varSlot->tts_values[varNumber];isnull[i] = varSlot->tts_isnull[varNumber];}}else{/* we have to pay attention to varOutputCols[] */int *varOutputCols = projInfo->pi_varOutputCols;for (i = 0; i < numSimpleVars; i++){char *slotptr = ((char *) econtext) + varSlotOffsets[i];TupleTableSlot *varSlot = *((TupleTableSlot **) slotptr);int varNumber = varNumbers[i] - 1;int varOutputCol = varOutputCols[i] - 1;values[varOutputCol] = varSlot->tts_values[varNumber];isnull[varOutputCol] = varSlot->tts_isnull[varNumber];}}}/** If there are any generic expressions, evaluate them. It's possible* that there are set-returning functions in such expressions; if so and* we have reached the end of the set, we return the result slot, which we* already marked empty.*/if (projInfo->pi_targetlist){/* 步骤2:调用ExecTargetList,根据字段值计算表达式值 */if (!ExecTargetList(projInfo->pi_targetlist,slot->tts_tupleDescriptor,econtext,slot->tts_values,slot->tts_isnull,projInfo->pi_itemIsDone,isDone))return slot; /* no more result rows, return empty slot */}/** Successfully formed a result row. Mark the result slot as containing a* valid virtual tuple.*/return ExecStoreVirtualTuple(slot);
}
ExecUpdate
当获取了需要修改的元组,以及修改的字段值后,就可以调用ExecUpdate执行修改操作了。ExecUpdate的实现比较复杂本文开篇在概述部分介绍的三种场景的处理也在ExecUpdate中完成。为了简化描述,我们先不考虑前面的几种特殊场景,只考虑最简单的更新。如此,ExecUpdate可以概括为两个步骤:
-
调用ExecMaterializeSlot组装new tuple。
该函数与插入时构建插入元组使用的是同一个函数。
-
调用heap_update执行更新操作。
源代码如下:
static TupleTableSlot *
ExecUpdate(ItemPointer tupleid,HeapTuple oldtuple,TupleTableSlot *slot,TupleTableSlot *planSlot,EPQState *epqstate,EState *estate,bool canSetTag)
{HeapTuple tuple;ResultRelInfo *resultRelInfo;Relation resultRelationDesc;HTSU_Result result;HeapUpdateFailureData hufd;List *recheckIndexes = NIL;/** abort the operation if not running transactions*/if (IsBootstrapProcessingMode())elog(ERROR, "cannot UPDATE during bootstrap");/** get the heap tuple out of the tuple table slot, making sure we have a* writable copy* 步骤1:调用ExecMaterializeSlot组装new tuple*/tuple = ExecMaterializeSlot(slot);/** get information on the (current) result relation*/resultRelInfo = estate->es_result_relation_info;resultRelationDesc = resultRelInfo->ri_RelationDesc;/* BEFORE ROW UPDATE Triggers */if (resultRelInfo->ri_TrigDesc &&resultRelInfo->ri_TrigDesc->trig_update_before_row){slot = ExecBRUpdateTriggers(estate, epqstate, resultRelInfo,tupleid, oldtuple, slot);if (slot == NULL) /* "do nothing" */return NULL;/* trigger might have changed tuple */tuple = ExecMaterializeSlot(slot);}/* INSTEAD OF ROW UPDATE Triggers */if (resultRelInfo->ri_TrigDesc &&resultRelInfo->ri_TrigDesc->trig_update_instead_row){slot = ExecIRUpdateTriggers(estate, resultRelInfo,oldtuple, slot);if (slot == NULL) /* "do nothing" */return NULL;/* trigger might have changed tuple */tuple = ExecMaterializeSlot(slot);}else if (resultRelInfo->ri_FdwRoutine){/** update in foreign table: let the FDW do it*/slot = resultRelInfo->ri_FdwRoutine->ExecForeignUpdate(estate,resultRelInfo,slot,planSlot);if (slot == NULL) /* "do nothing" */return NULL;/* FDW might have changed tuple */tuple = ExecMaterializeSlot(slot);/** AFTER ROW Triggers or RETURNING expressions might reference the* tableoid column, so initialize t_tableOid before evaluating them.*/tuple->t_tableOid = RelationGetRelid(resultRelationDesc);}else{LockTupleMode lockmode;/** Constraints might reference the tableoid column, so initialize* t_tableOid before evaluating them.*/tuple->t_tableOid = RelationGetRelid(resultRelationDesc);/** Check any RLS UPDATE WITH CHECK policies** If we generate a new candidate tuple after EvalPlanQual testing, we* must loop back here and recheck any RLS policies and constraints.* (We don't need to redo triggers, however. If there are any BEFORE* triggers then trigger.c will have done heap_lock_tuple to lock the* correct tuple, so there's no need to do them again.)** ExecWithCheckOptions() will skip any WCOs which are not of the kind* we are looking for at this point.*/
lreplace:;if (resultRelInfo->ri_WithCheckOptions != NIL)ExecWithCheckOptions(WCO_RLS_UPDATE_CHECK,resultRelInfo, slot, estate);/** Check the constraints of the tuple*/if (resultRelationDesc->rd_att->constr)ExecConstraints(resultRelInfo, slot, estate);/** replace the heap tuple** Note: if es_crosscheck_snapshot isn't InvalidSnapshot, we check* that the row to be updated is visible to that snapshot, and throw a* can't-serialize error if not. This is a special-case behavior* needed for referential integrity updates in transaction-snapshot* mode transactions.* 步骤2:调用heap_update执行更新操作*/result = heap_update(resultRelationDesc, tupleid, tuple,estate->es_output_cid,estate->es_crosscheck_snapshot,true /* wait for commit */ ,&hufd, &lockmode);switch (result){case HeapTupleSelfUpdated:/** The target tuple was already updated or deleted by the* current command, or by a later command in the current* transaction. The former case is possible in a join UPDATE* where multiple tuples join to the same target tuple. This* is pretty questionable, but Postgres has always allowed it:* we just execute the first update action and ignore* additional update attempts.** The latter case arises if the tuple is modified by a* command in a BEFORE trigger, or perhaps by a command in a* volatile function used in the query. In such situations we* should not ignore the update, but it is equally unsafe to* proceed. We don't want to discard the original UPDATE* while keeping the triggered actions based on it; and we* have no principled way to merge this update with the* previous ones. So throwing an error is the only safe* course.** If a trigger actually intends this type of interaction, it* can re-execute the UPDATE (assuming it can figure out how)* and then return NULL to cancel the outer update.*/if (hufd.cmax != estate->es_output_cid)ereport(ERROR,(errcode(ERRCODE_TRIGGERED_DATA_CHANGE_VIOLATION),errmsg("tuple to be updated was already modified by an operation triggered by the current command"),errhint("Consider using an AFTER trigger instead of a BEFORE trigger to propagate changes to other rows.")));/* Else, already updated by self; nothing to do */return NULL;case HeapTupleMayBeUpdated:break;case HeapTupleUpdated:if (IsolationUsesXactSnapshot())ereport(ERROR,(errcode(ERRCODE_T_R_SERIALIZATION_FAILURE),errmsg("could not serialize access due to concurrent update")));if (!ItemPointerEquals(tupleid, &hufd.ctid)){TupleTableSlot *epqslot;epqslot = EvalPlanQual(estate,epqstate,resultRelationDesc,resultRelInfo->ri_RangeTableIndex,lockmode,&hufd.ctid,hufd.xmax);if (!TupIsNull(epqslot)){*tupleid = hufd.ctid;slot = ExecFilterJunk(resultRelInfo->ri_junkFilter, epqslot);tuple = ExecMaterializeSlot(slot);goto lreplace;}}/* tuple already deleted; nothing to do */return NULL;default:elog(ERROR, "unrecognized heap_update status: %u", result);return NULL;}/** Note: instead of having to update the old index tuples associated* with the heap tuple, all we do is form and insert new index tuples.* This is because UPDATEs are actually DELETEs and INSERTs, and index* tuple deletion is done later by VACUUM (see notes in ExecDelete).* All we do here is insert new index tuples. -cim 9/27/89*//** insert index entries for tuple** Note: heap_update returns the tid (location) of the new tuple in* the t_self field.** If it's a HOT update, we mustn't insert new index entries.*/if (resultRelInfo->ri_NumIndices > 0 && !HeapTupleIsHeapOnly(tuple))recheckIndexes = ExecInsertIndexTuples(slot, &(tuple->t_self),estate, false, NULL, NIL);}if (canSetTag)(estate->es_processed)++;/* AFTER ROW UPDATE Triggers */ExecARUpdateTriggers(estate, resultRelInfo, tupleid, oldtuple, tuple,recheckIndexes);list_free(recheckIndexes);/** Check any WITH CHECK OPTION constraints from parent views. We are* required to do this after testing all constraints and uniqueness* violations per the SQL spec, so we do it after actually updating the* record in the heap and all indexes.** ExecWithCheckOptions() will skip any WCOs which are not of the kind we* are looking for at this point.*/if (resultRelInfo->ri_WithCheckOptions != NIL)ExecWithCheckOptions(WCO_VIEW_CHECK, resultRelInfo, slot, estate);/* Process RETURNING if present */if (resultRelInfo->ri_projectReturning)return ExecProcessReturning(resultRelInfo, slot, planSlot);return NULL;
}
heap_update
heap_update是更新的最底层函数,其实现非常复杂,这里我们只关注几个主要步骤:
-
对需要修改的缓存页面加latch。
由于后面会将new tuple插入缓存页,所以这里显然要加上latch。
-
调用HeapTupleSatisfiesUpdate判断当前元组是否可以更新。
这是处理更新丢失的关键函数。
-
调用RelationPutHeapTuple插入new tuple。
插入新元组。
-
调用HeapTupleHeaderSetXmax设置old tuple的t_xmax。
删除旧元组。
-
释放缓存页的latch。
代码如下:
HTSU_Result
heap_update(Relation relation, ItemPointer otid, HeapTuple newtup,CommandId cid, Snapshot crosscheck, bool wait,HeapUpdateFailureData *hufd, LockTupleMode *lockmode)
{HTSU_Result result;TransactionId xid = GetCurrentTransactionId();Bitmapset *hot_attrs;Bitmapset *key_attrs;Bitmapset *id_attrs;ItemId lp;HeapTupleData oldtup;HeapTuple heaptup;HeapTuple old_key_tuple = NULL;bool old_key_copied = false;Page page;BlockNumber block;MultiXactStatus mxact_status;Buffer buffer,newbuf,vmbuffer = InvalidBuffer,vmbuffer_new = InvalidBuffer;bool need_toast;Size newtupsize,pagefree;bool have_tuple_lock = false;bool iscombo;bool satisfies_hot;bool satisfies_key;bool satisfies_id;bool use_hot_update = false;bool key_intact;bool all_visible_cleared = false;bool all_visible_cleared_new = false;bool checked_lockers;bool locker_remains;TransactionId xmax_new_tuple,xmax_old_tuple;uint16 infomask_old_tuple,infomask2_old_tuple,infomask_new_tuple,infomask2_new_tuple;Assert(ItemPointerIsValid(otid));/** Forbid this during a parallel operation, lest it allocate a combocid.* Other workers might need that combocid for visibility checks, and we* have no provision for broadcasting it to them.*/if (IsInParallelMode())ereport(ERROR,(errcode(ERRCODE_INVALID_TRANSACTION_STATE),errmsg("cannot update tuples during a parallel operation")));/** Fetch the list of attributes to be checked for HOT update. This is* wasted effort if we fail to update or have to put the new tuple on a* different page. But we must compute the list before obtaining buffer* lock --- in the worst case, if we are doing an update on one of the* relevant system catalogs, we could deadlock if we try to fetch the list* later. In any case, the relcache caches the data so this is usually* pretty cheap.** Note that we get a copy here, so we need not worry about relcache flush* happening midway through.*/hot_attrs = RelationGetIndexAttrBitmap(relation, INDEX_ATTR_BITMAP_ALL);key_attrs = RelationGetIndexAttrBitmap(relation, INDEX_ATTR_BITMAP_KEY);id_attrs = RelationGetIndexAttrBitmap(relation,INDEX_ATTR_BITMAP_IDENTITY_KEY);block = ItemPointerGetBlockNumber(otid);buffer = ReadBuffer(relation, block);page = BufferGetPage(buffer);/** Before locking the buffer, pin the visibility map page if it appears to* be necessary. Since we haven't got the lock yet, someone else might be* in the middle of changing this, so we'll need to recheck after we have* the lock.*/if (PageIsAllVisible(page))visibilitymap_pin(relation, block, &vmbuffer);/* 步骤1:对需要修改的缓存页面加latch */LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);lp = PageGetItemId(page, ItemPointerGetOffsetNumber(otid));Assert(ItemIdIsNormal(lp));/** Fill in enough data in oldtup for HeapSatisfiesHOTandKeyUpdate to work* properly.*/oldtup.t_tableOid = RelationGetRelid(relation);oldtup.t_data = (HeapTupleHeader) PageGetItem(page, lp);oldtup.t_len = ItemIdGetLength(lp);oldtup.t_self = *otid;/* the new tuple is ready, except for this: */newtup->t_tableOid = RelationGetRelid(relation);/* Fill in OID for newtup */if (relation->rd_rel->relhasoids){
#ifdef NOT_USED/* this is redundant with an Assert in HeapTupleSetOid */Assert(newtup->t_data->t_infomask & HEAP_HASOID);
#endifHeapTupleSetOid(newtup, HeapTupleGetOid(&oldtup));}else{/* check there is not space for an OID */Assert(!(newtup->t_data->t_infomask & HEAP_HASOID));}/** If we're not updating any "key" column, we can grab a weaker lock type.* This allows for more concurrency when we are running simultaneously* with foreign key checks.** Note that if a column gets detoasted while executing the update, but* the value ends up being the same, this test will fail and we will use* the stronger lock. This is acceptable; the important case to optimize* is updates that don't manipulate key columns, not those that* serendipitiously arrive at the same key values.*/HeapSatisfiesHOTandKeyUpdate(relation, hot_attrs, key_attrs, id_attrs,&satisfies_hot, &satisfies_key,&satisfies_id, &oldtup, newtup);if (satisfies_key){*lockmode = LockTupleNoKeyExclusive;mxact_status = MultiXactStatusNoKeyUpdate;key_intact = true;/** If this is the first possibly-multixact-able operation in the* current transaction, set my per-backend OldestMemberMXactId* setting. We can be certain that the transaction will never become a* member of any older MultiXactIds than that. (We have to do this* even if we end up just using our own TransactionId below, since* some other backend could incorporate our XID into a MultiXact* immediately afterwards.)*/MultiXactIdSetOldestMember();}else{*lockmode = LockTupleExclusive;mxact_status = MultiXactStatusUpdate;key_intact = false;}/** Note: beyond this point, use oldtup not otid to refer to old tuple.* otid may very well point at newtup->t_self, which we will overwrite* with the new tuple's location, so there's great risk of confusion if we* use otid anymore.*/l2:checked_lockers = false;locker_remains = false;/* 步骤2: 调用HeapTupleSatisfiesUpdate判断当前元组是否可以更新*/result = HeapTupleSatisfiesUpdate(&oldtup, cid, buffer);/* see below about the "no wait" case */Assert(result != HeapTupleBeingUpdated || wait);if (result == HeapTupleInvisible){UnlockReleaseBuffer(buffer);ereport(ERROR,(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),errmsg("attempted to update invisible tuple")));}else if (result == HeapTupleBeingUpdated && wait){TransactionId xwait;uint16 infomask;bool can_continue = false;/** XXX note that we don't consider the "no wait" case here. This* isn't a problem currently because no caller uses that case, but it* should be fixed if such a caller is introduced. It wasn't a* problem previously because this code would always wait, but now* that some tuple locks do not conflict with one of the lock modes we* use, it is possible that this case is interesting to handle* specially.** This may cause failures with third-party code that calls* heap_update directly.*//* must copy state data before unlocking buffer */xwait = HeapTupleHeaderGetRawXmax(oldtup.t_data);infomask = oldtup.t_data->t_infomask;/** Now we have to do something about the existing locker. If it's a* multi, sleep on it; we might be awakened before it is completely* gone (or even not sleep at all in some cases); we need to preserve* it as locker, unless it is gone completely.** If it's not a multi, we need to check for sleeping conditions* before actually going to sleep. If the update doesn't conflict* with the locks, we just continue without sleeping (but making sure* it is preserved).** Before sleeping, we need to acquire tuple lock to establish our* priority for the tuple (see heap_lock_tuple). LockTuple will* release us when we are next-in-line for the tuple. Note we must* not acquire the tuple lock until we're sure we're going to sleep;* otherwise we're open for race conditions with other transactions* holding the tuple lock which sleep on us.** If we are forced to "start over" below, we keep the tuple lock;* this arranges that we stay at the head of the line while rechecking* tuple state.*/if (infomask & HEAP_XMAX_IS_MULTI){TransactionId update_xact;int remain;if (DoesMultiXactIdConflict((MultiXactId) xwait, infomask,*lockmode)){LockBuffer(buffer, BUFFER_LOCK_UNLOCK);/* acquire tuple lock, if necessary */heap_acquire_tuplock(relation, &(oldtup.t_self), *lockmode,LockWaitBlock, &have_tuple_lock);/* wait for multixact */MultiXactIdWait((MultiXactId) xwait, mxact_status, infomask,relation, &oldtup.t_self, XLTW_Update,&remain);checked_lockers = true;locker_remains = remain != 0;LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);/** If xwait had just locked the tuple then some other xact* could update this tuple before we get to this point. Check* for xmax change, and start over if so.*/if (xmax_infomask_changed(oldtup.t_data->t_infomask,infomask) ||!TransactionIdEquals(HeapTupleHeaderGetRawXmax(oldtup.t_data),xwait))goto l2;}/** Note that the multixact may not be done by now. It could have* surviving members; our own xact or other subxacts of this* backend, and also any other concurrent transaction that locked* the tuple with KeyShare if we only got TupleLockUpdate. If* this is the case, we have to be careful to mark the updated* tuple with the surviving members in Xmax.** Note that there could have been another update in the* MultiXact. In that case, we need to check whether it committed* or aborted. If it aborted we are safe to update it again;* otherwise there is an update conflict, and we have to return* HeapTupleUpdated below.** In the LockTupleExclusive case, we still need to preserve the* surviving members: those would include the tuple locks we had* before this one, which are important to keep in case this* subxact aborts.*/if (!HEAP_XMAX_IS_LOCKED_ONLY(oldtup.t_data->t_infomask))update_xact = HeapTupleGetUpdateXid(oldtup.t_data);elseupdate_xact = InvalidTransactionId;/** There was no UPDATE in the MultiXact; or it aborted. No* TransactionIdIsInProgress() call needed here, since we called* MultiXactIdWait() above.*/if (!TransactionIdIsValid(update_xact) ||TransactionIdDidAbort(update_xact))can_continue = true;}else if (TransactionIdIsCurrentTransactionId(xwait)){/** The only locker is ourselves; we can avoid grabbing the tuple* lock here, but must preserve our locking information.*/checked_lockers = true;locker_remains = true;can_continue = true;}else if (HEAP_XMAX_IS_KEYSHR_LOCKED(infomask) && key_intact){/** If it's just a key-share locker, and we're not changing the key* columns, we don't need to wait for it to end; but we need to* preserve it as locker.*/checked_lockers = true;locker_remains = true;can_continue = true;}else{/** Wait for regular transaction to end; but first, acquire tuple* lock.*/LockBuffer(buffer, BUFFER_LOCK_UNLOCK);heap_acquire_tuplock(relation, &(oldtup.t_self), *lockmode,LockWaitBlock, &have_tuple_lock);XactLockTableWait(xwait, relation, &oldtup.t_self,XLTW_Update);checked_lockers = true;LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);/** xwait is done, but if xwait had just locked the tuple then some* other xact could update this tuple before we get to this point.* Check for xmax change, and start over if so.*/if (xmax_infomask_changed(oldtup.t_data->t_infomask, infomask) ||!TransactionIdEquals(xwait,HeapTupleHeaderGetRawXmax(oldtup.t_data)))goto l2;/* Otherwise check if it committed or aborted */UpdateXmaxHintBits(oldtup.t_data, buffer, xwait);if (oldtup.t_data->t_infomask & HEAP_XMAX_INVALID)can_continue = true;}result = can_continue ? HeapTupleMayBeUpdated : HeapTupleUpdated;}if (crosscheck != InvalidSnapshot && result == HeapTupleMayBeUpdated){/* Perform additional check for transaction-snapshot mode RI updates */if (!HeapTupleSatisfiesVisibility(&oldtup, crosscheck, buffer))result = HeapTupleUpdated;}if (result != HeapTupleMayBeUpdated){Assert(result == HeapTupleSelfUpdated ||result == HeapTupleUpdated ||result == HeapTupleBeingUpdated);Assert(!(oldtup.t_data->t_infomask & HEAP_XMAX_INVALID));hufd->ctid = oldtup.t_data->t_ctid;hufd->xmax = HeapTupleHeaderGetUpdateXid(oldtup.t_data);if (result == HeapTupleSelfUpdated)hufd->cmax = HeapTupleHeaderGetCmax(oldtup.t_data);elsehufd->cmax = InvalidCommandId;UnlockReleaseBuffer(buffer);if (have_tuple_lock)UnlockTupleTuplock(relation, &(oldtup.t_self), *lockmode);if (vmbuffer != InvalidBuffer)ReleaseBuffer(vmbuffer);bms_free(hot_attrs);bms_free(key_attrs);bms_free(id_attrs);return result;}/** If we didn't pin the visibility map page and the page has become all* visible while we were busy locking the buffer, or during some* subsequent window during which we had it unlocked, we'll have to unlock* and re-lock, to avoid holding the buffer lock across an I/O. That's a* bit unfortunate, especially since we'll now have to recheck whether the* tuple has been locked or updated under us, but hopefully it won't* happen very often.*/if (vmbuffer == InvalidBuffer && PageIsAllVisible(page)){LockBuffer(buffer, BUFFER_LOCK_UNLOCK);visibilitymap_pin(relation, block, &vmbuffer);LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);goto l2;}/* Fill in transaction status data *//** If the tuple we're updating is locked, we need to preserve the locking* info in the old tuple's Xmax. Prepare a new Xmax value for this.*/compute_new_xmax_infomask(HeapTupleHeaderGetRawXmax(oldtup.t_data),oldtup.t_data->t_infomask,oldtup.t_data->t_infomask2,xid, *lockmode, true,&xmax_old_tuple, &infomask_old_tuple,&infomask2_old_tuple);/** And also prepare an Xmax value for the new copy of the tuple. If there* was no xmax previously, or there was one but all lockers are now gone,* then use InvalidXid; otherwise, get the xmax from the old tuple. (In* rare cases that might also be InvalidXid and yet not have the* HEAP_XMAX_INVALID bit set; that's fine.)*/if ((oldtup.t_data->t_infomask & HEAP_XMAX_INVALID) ||HEAP_LOCKED_UPGRADED(oldtup.t_data->t_infomask) ||(checked_lockers && !locker_remains))xmax_new_tuple = InvalidTransactionId;elsexmax_new_tuple = HeapTupleHeaderGetRawXmax(oldtup.t_data);if (!TransactionIdIsValid(xmax_new_tuple)){infomask_new_tuple = HEAP_XMAX_INVALID;infomask2_new_tuple = 0;}else{/** If we found a valid Xmax for the new tuple, then the infomask bits* to use on the new tuple depend on what was there on the old one.* Note that since we're doing an update, the only possibility is that* the lockers had FOR KEY SHARE lock.*/if (oldtup.t_data->t_infomask & HEAP_XMAX_IS_MULTI){GetMultiXactIdHintBits(xmax_new_tuple, &infomask_new_tuple,&infomask2_new_tuple);}else{infomask_new_tuple = HEAP_XMAX_KEYSHR_LOCK | HEAP_XMAX_LOCK_ONLY;infomask2_new_tuple = 0;}}/** Prepare the new tuple with the appropriate initial values of Xmin and* Xmax, as well as initial infomask bits as computed above.*/newtup->t_data->t_infomask &= ~(HEAP_XACT_MASK);newtup->t_data->t_infomask2 &= ~(HEAP2_XACT_MASK);HeapTupleHeaderSetXmin(newtup->t_data, xid);HeapTupleHeaderSetCmin(newtup->t_data, cid);newtup->t_data->t_infomask |= HEAP_UPDATED | infomask_new_tuple;newtup->t_data->t_infomask2 |= infomask2_new_tuple;HeapTupleHeaderSetXmax(newtup->t_data, xmax_new_tuple);/** Replace cid with a combo cid if necessary. Note that we already put* the plain cid into the new tuple.*/HeapTupleHeaderAdjustCmax(oldtup.t_data, &cid, &iscombo);/** If the toaster needs to be activated, OR if the new tuple will not fit* on the same page as the old, then we need to release the content lock* (but not the pin!) on the old tuple's buffer while we are off doing* TOAST and/or table-file-extension work. We must mark the old tuple to* show that it's locked, else other processes may try to update it* themselves.** We need to invoke the toaster if there are already any out-of-line* toasted values present, or if the new tuple is over-threshold.*/if (relation->rd_rel->relkind != RELKIND_RELATION &&relation->rd_rel->relkind != RELKIND_MATVIEW){/* toast table entries should never be recursively toasted */Assert(!HeapTupleHasExternal(&oldtup));Assert(!HeapTupleHasExternal(newtup));need_toast = false;}elseneed_toast = (HeapTupleHasExternal(&oldtup) ||HeapTupleHasExternal(newtup) ||newtup->t_len > TOAST_TUPLE_THRESHOLD);pagefree = PageGetHeapFreeSpace(page);newtupsize = MAXALIGN(newtup->t_len);if (need_toast || newtupsize > pagefree){TransactionId xmax_lock_old_tuple;uint16 infomask_lock_old_tuple,infomask2_lock_old_tuple;bool cleared_all_frozen = false;/** To prevent concurrent sessions from updating the tuple, we have to* temporarily mark it locked, while we release the page-level lock.** To satisfy the rule that any xid potentially appearing in a buffer* written out to disk, we unfortunately have to WAL log this* temporary modification. We can reuse xl_heap_lock for this* purpose. If we crash/error before following through with the* actual update, xmax will be of an aborted transaction, allowing* other sessions to proceed.*//** Compute xmax / infomask appropriate for locking the tuple. This has* to be done separately from the combo that's going to be used for* updating, because the potentially created multixact would otherwise* be wrong.*/compute_new_xmax_infomask(HeapTupleHeaderGetRawXmax(oldtup.t_data),oldtup.t_data->t_infomask,oldtup.t_data->t_infomask2,xid, *lockmode, false,&xmax_lock_old_tuple, &infomask_lock_old_tuple,&infomask2_lock_old_tuple);Assert(HEAP_XMAX_IS_LOCKED_ONLY(infomask_lock_old_tuple));START_CRIT_SECTION();/* Clear obsolete visibility flags ... */oldtup.t_data->t_infomask &= ~(HEAP_XMAX_BITS | HEAP_MOVED);oldtup.t_data->t_infomask2 &= ~HEAP_KEYS_UPDATED;HeapTupleClearHotUpdated(&oldtup);/* ... and store info about transaction updating this tuple */Assert(TransactionIdIsValid(xmax_lock_old_tuple));HeapTupleHeaderSetXmax(oldtup.t_data, xmax_lock_old_tuple);oldtup.t_data->t_infomask |= infomask_lock_old_tuple;oldtup.t_data->t_infomask2 |= infomask2_lock_old_tuple;HeapTupleHeaderSetCmax(oldtup.t_data, cid, iscombo);/* temporarily make it look not-updated, but locked */oldtup.t_data->t_ctid = oldtup.t_self;/** Clear all-frozen bit on visibility map if needed. We could* immediately reset ALL_VISIBLE, but given that the WAL logging* overhead would be unchanged, that doesn't seem necessarily* worthwhile.*/if (PageIsAllVisible(BufferGetPage(buffer)) &&visibilitymap_clear(relation, block, vmbuffer,VISIBILITYMAP_ALL_FROZEN))cleared_all_frozen = true;MarkBufferDirty(buffer);if (RelationNeedsWAL(relation)){xl_heap_lock xlrec;XLogRecPtr recptr;XLogBeginInsert();XLogRegisterBuffer(0, buffer, REGBUF_STANDARD);xlrec.offnum = ItemPointerGetOffsetNumber(&oldtup.t_self);xlrec.locking_xid = xmax_lock_old_tuple;xlrec.infobits_set = compute_infobits(oldtup.t_data->t_infomask,oldtup.t_data->t_infomask2);xlrec.flags =cleared_all_frozen ? XLH_LOCK_ALL_FROZEN_CLEARED : 0;XLogRegisterData((char *) &xlrec, SizeOfHeapLock);recptr = XLogInsert(RM_HEAP_ID, XLOG_HEAP_LOCK);PageSetLSN(page, recptr);}END_CRIT_SECTION();LockBuffer(buffer, BUFFER_LOCK_UNLOCK);/** Let the toaster do its thing, if needed.** Note: below this point, heaptup is the data we actually intend to* store into the relation; newtup is the caller's original untoasted* data.*/if (need_toast){/* Note we always use WAL and FSM during updates */heaptup = toast_insert_or_update(relation, newtup, &oldtup, 0);newtupsize = MAXALIGN(heaptup->t_len);}elseheaptup = newtup;/** Now, do we need a new page for the tuple, or not? This is a bit* tricky since someone else could have added tuples to the page while* we weren't looking. We have to recheck the available space after* reacquiring the buffer lock. But don't bother to do that if the* former amount of free space is still not enough; it's unlikely* there's more free now than before.** What's more, if we need to get a new page, we will need to acquire* buffer locks on both old and new pages. To avoid deadlock against* some other backend trying to get the same two locks in the other* order, we must be consistent about the order we get the locks in.* We use the rule "lock the lower-numbered page of the relation* first". To implement this, we must do RelationGetBufferForTuple* while not holding the lock on the old page, and we must rely on it* to get the locks on both pages in the correct order.*/if (newtupsize > pagefree){/* Assume there's no chance to put heaptup on same page. */newbuf = RelationGetBufferForTuple(relation, heaptup->t_len,buffer, 0, NULL,&vmbuffer_new, &vmbuffer);}else{/* Re-acquire the lock on the old tuple's page. */LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);/* Re-check using the up-to-date free space */pagefree = PageGetHeapFreeSpace(page);if (newtupsize > pagefree){/** Rats, it doesn't fit anymore. We must now unlock and* relock to avoid deadlock. Fortunately, this path should* seldom be taken.*/LockBuffer(buffer, BUFFER_LOCK_UNLOCK);newbuf = RelationGetBufferForTuple(relation, heaptup->t_len,buffer, 0, NULL,&vmbuffer_new, &vmbuffer);}else{/* OK, it fits here, so we're done. */newbuf = buffer;}}}else{/* No TOAST work needed, and it'll fit on same page */newbuf = buffer;heaptup = newtup;}/** We're about to do the actual update -- check for conflict first, to* avoid possibly having to roll back work we've just done.** This is safe without a recheck as long as there is no possibility of* another process scanning the pages between this check and the update* being visible to the scan (i.e., exclusive buffer content lock(s) are* continuously held from this point until the tuple update is visible).** For the new tuple the only check needed is at the relation level, but* since both tuples are in the same relation and the check for oldtup* will include checking the relation level, there is no benefit to a* separate check for the new tuple.*/CheckForSerializableConflictIn(relation, &oldtup, buffer);/** At this point newbuf and buffer are both pinned and locked, and newbuf* has enough space for the new tuple. If they are the same buffer, only* one pin is held.*/if (newbuf == buffer){/** Since the new tuple is going into the same page, we might be able* to do a HOT update. Check if any of the index columns have been* changed. If not, then HOT update is possible.*/if (satisfies_hot)use_hot_update = true;}else{/* Set a hint that the old page could use prune/defrag */PageSetFull(page);}/** Compute replica identity tuple before entering the critical section so* we don't PANIC upon a memory allocation failure.* ExtractReplicaIdentity() will return NULL if nothing needs to be* logged.*/old_key_tuple = ExtractReplicaIdentity(relation, &oldtup, !satisfies_id, &old_key_copied);/* NO EREPORT(ERROR) from here till changes are logged */START_CRIT_SECTION();/** If this transaction commits, the old tuple will become DEAD sooner or* later. Set flag that this page is a candidate for pruning once our xid* falls below the OldestXmin horizon. If the transaction finally aborts,* the subsequent page pruning will be a no-op and the hint will be* cleared.** XXX Should we set hint on newbuf as well? If the transaction aborts,* there would be a prunable tuple in the newbuf; but for now we choose* not to optimize for aborts. Note that heap_xlog_update must be kept in* sync if this decision changes.*/PageSetPrunable(page, xid);if (use_hot_update){/* Mark the old tuple as HOT-updated */HeapTupleSetHotUpdated(&oldtup);/* And mark the new tuple as heap-only */HeapTupleSetHeapOnly(heaptup);/* Mark the caller's copy too, in case different from heaptup */HeapTupleSetHeapOnly(newtup);}else{/* Make sure tuples are correctly marked as not-HOT */HeapTupleClearHotUpdated(&oldtup);HeapTupleClearHeapOnly(heaptup);HeapTupleClearHeapOnly(newtup);}/* 步骤3:调用RelationPutHeapTuple插入new tuple */RelationPutHeapTuple(relation, newbuf, heaptup, false); /* insert new tuple *//* Clear obsolete visibility flags, possibly set by ourselves above... */oldtup.t_data->t_infomask &= ~(HEAP_XMAX_BITS | HEAP_MOVED);oldtup.t_data->t_infomask2 &= ~HEAP_KEYS_UPDATED;/* ... and store info about transaction updating this tuple */Assert(TransactionIdIsValid(xmax_old_tuple));/* 步骤4:调用HeapTupleHeaderSetXmax设置old tuple的t_xmax */HeapTupleHeaderSetXmax(oldtup.t_data, xmax_old_tuple);oldtup.t_data->t_infomask |= infomask_old_tuple;oldtup.t_data->t_infomask2 |= infomask2_old_tuple;HeapTupleHeaderSetCmax(oldtup.t_data, cid, iscombo);/* record address of new tuple in t_ctid of old one */oldtup.t_data->t_ctid = heaptup->t_self;/* clear PD_ALL_VISIBLE flags, reset all visibilitymap bits */if (PageIsAllVisible(BufferGetPage(buffer))){all_visible_cleared = true;PageClearAllVisible(BufferGetPage(buffer));visibilitymap_clear(relation, BufferGetBlockNumber(buffer),vmbuffer, VISIBILITYMAP_VALID_BITS);}if (newbuf != buffer && PageIsAllVisible(BufferGetPage(newbuf))){all_visible_cleared_new = true;PageClearAllVisible(BufferGetPage(newbuf));visibilitymap_clear(relation, BufferGetBlockNumber(newbuf),vmbuffer_new, VISIBILITYMAP_VALID_BITS);}if (newbuf != buffer)MarkBufferDirty(newbuf);MarkBufferDirty(buffer);/* XLOG stuff */if (RelationNeedsWAL(relation)){XLogRecPtr recptr;/** For logical decoding we need combocids to properly decode the* catalog.*/if (RelationIsAccessibleInLogicalDecoding(relation)){log_heap_new_cid(relation, &oldtup);log_heap_new_cid(relation, heaptup);}recptr = log_heap_update(relation, buffer,newbuf, &oldtup, heaptup,old_key_tuple,all_visible_cleared,all_visible_cleared_new);if (newbuf != buffer){PageSetLSN(BufferGetPage(newbuf), recptr);}PageSetLSN(BufferGetPage(buffer), recptr);}END_CRIT_SECTION();if (newbuf != buffer)LockBuffer(newbuf, BUFFER_LOCK_UNLOCK);/* 步骤5:释放缓存页的latch */LockBuffer(buffer, BUFFER_LOCK_UNLOCK);/** Mark old tuple for invalidation from system caches at next command* boundary, and mark the new tuple for invalidation in case we abort. We* have to do this before releasing the buffer because oldtup is in the* buffer. (heaptup is all in local memory, but it's necessary to process* both tuple versions in one call to inval.c so we can avoid redundant* sinval messages.)*/CacheInvalidateHeapTuple(relation, &oldtup, heaptup);/* Now we can release the buffer(s) */if (newbuf != buffer)ReleaseBuffer(newbuf);ReleaseBuffer(buffer);if (BufferIsValid(vmbuffer_new))ReleaseBuffer(vmbuffer_new);if (BufferIsValid(vmbuffer))ReleaseBuffer(vmbuffer);/** Release the lmgr tuple lock, if we had it.*/if (have_tuple_lock)UnlockTupleTuplock(relation, &(oldtup.t_self), *lockmode);pgstat_count_heap_update(relation, use_hot_update);/** If heaptup is a private copy, release it. Don't forget to copy t_self* back to the caller's image, too.*/if (heaptup != newtup){newtup->t_self = heaptup->t_self;heap_freetuple(heaptup);}if (old_key_tuple != NULL && old_key_copied)heap_freetuple(old_key_tuple);bms_free(hot_attrs);bms_free(key_attrs);bms_free(id_attrs);return HeapTupleMayBeUpdated;
}
更新丢失
下面我们就重点来说下,PostgreSQL如何应对概述中的三个场景。对于场景3,实际上并不存在更新丢失的问题,在查询阶段依据可见性和查询条件就可以直接过滤掉不满足条件的元组。对于场景1和场景2的处理涉及ExecUpdate与heap_update的联动,流程稍显复杂,所以我们先设计一个用例,然后调试一下整个流程,再对流程中的各个细节做讲解。
场景1
对于场景1,我们首先创建一张表,然后向其中插入一条元组:
drop table if exists test;
create table test (id int, name char(32), age int, score int);
insert into test values(1, '123', 30, 99);
然后,我们在ExecutePlan函数中的ExecProcNode函数调用处打上断点,然后开启事务A,并执行更新:
begin;
update test set score = score+100 where id = 1;
commit;
事务A会执行到断点处:
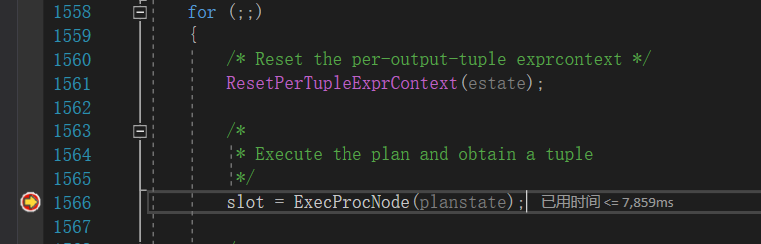
此时事务A已经进行了事务快照,并且即将开始执行更新操作。这个断点的目的是我们需要在A事务进行事务快照之后,执行更新之前,开启、执行并提交事务B。
现在,我们开启事务B,并执行更新操作,然后提交:
begin;
update test set score = score+50 where id = 1;
commit;
由于,此时事务A还没有修改id为1的元组,所以元组上不会有行锁,事务B可以顺利提交。由于事务B是在事务A的执行过程中开启、执行并提交的,所以显然事务B的相关操作对事务A都不可见。

事务B提交之后,数据库中就会存在新老两条元组。我们继续执行事务A,事务A会调用ExecProcNode > ExecModifyTable > ExecProcNode执行更新流程的查询操作。对!你没看错,是这个调用顺序,只是需要注意红色的ExecProcNode是在ExecutePlan函数中调用,而绿色的ExecProcNode是在ExecModifyTable函数中调用。
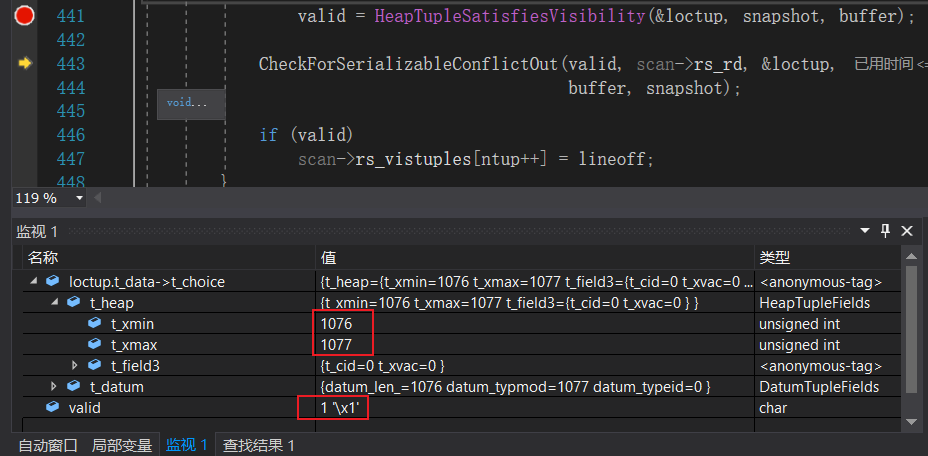
上图显示的元组是old tuple,从t_xmax为1077可以看出,该元组已经被其他事务删除,但依据MVCC该元组对事务A可见,HeapTupSatisfiesVisibility返回的valid为TRUE。
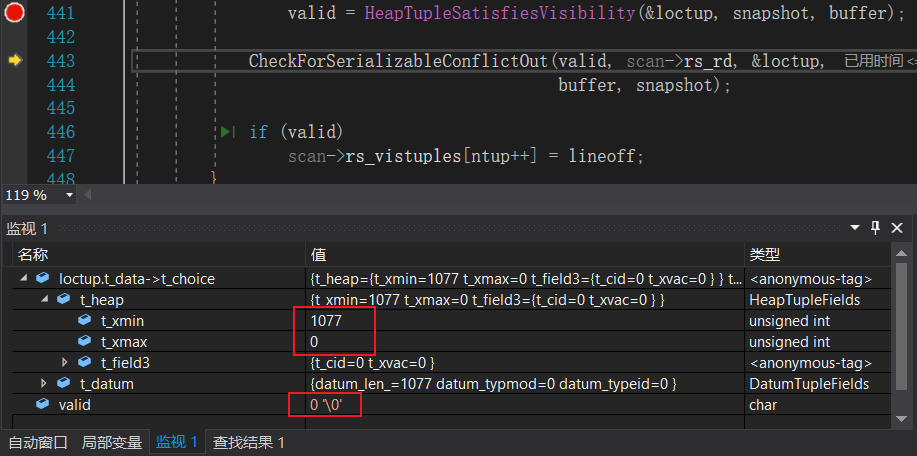
图中元组时new tuple,从t_xmax为0可以看出,该元组是事务B更新后的元组,依据MVCC该元组对事务A不可见,HeapTupSatisfiesVisibility返回的valid为FALSE。
根据可见性ExecProcNode会依据old tuple返回元组中各个字段和更新后的字段值(更新主流程里介绍过ExecProcNode的功能)。
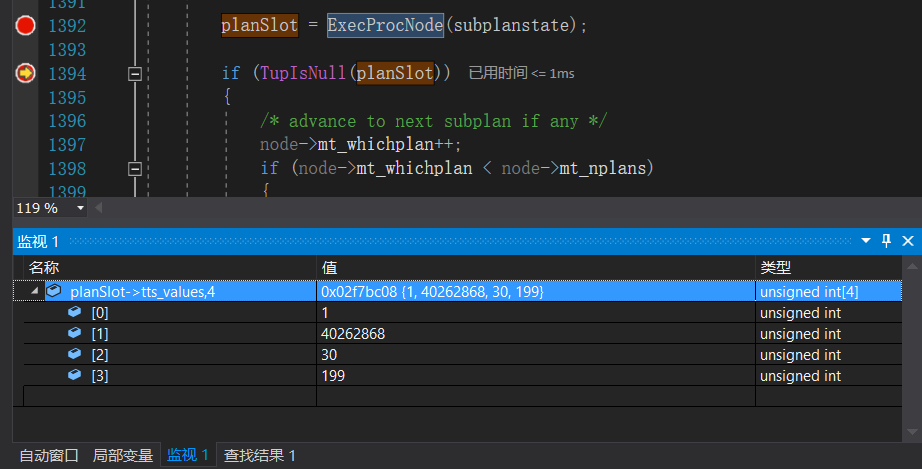
tts_values中包含了4个字段,前三个字段分别为id,name,age的值(name由于是字符所以这里显示成了很大的一个整数)而最后一个字段是score + 100的值。接下来就会调用ExecUpdate函数执行更新操作。

按照更新主流程中介绍的流程,在ExecUpdate中首先调用ExecMaterializeSlot组装一条更新元组。
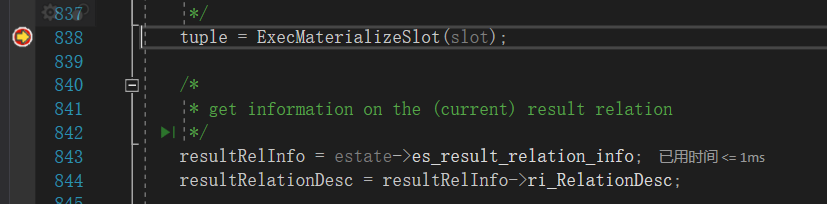
然后调用heap_update执行更新。

这里,我们先不去调试heap_update的具体细节,而是直接看result的返回值:
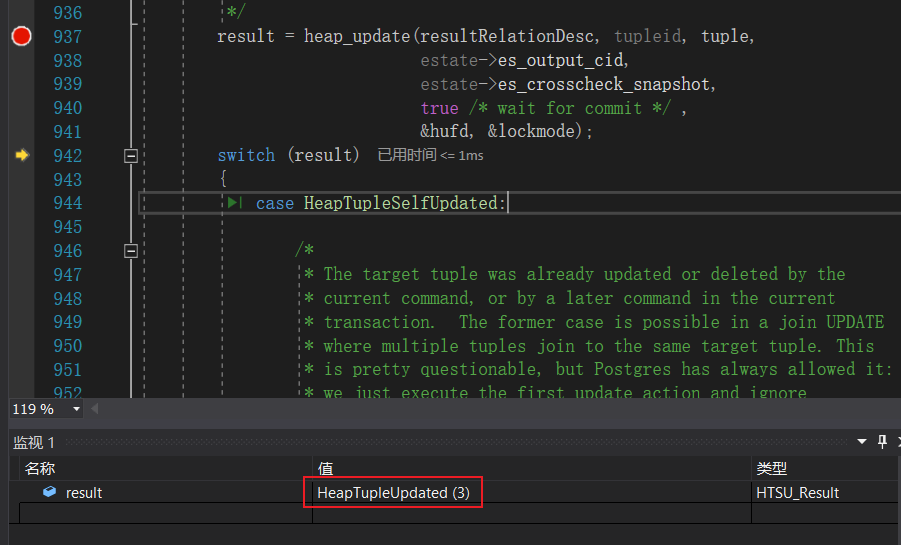
result是一个枚举类型,定义如下:
typedef enum
{HeapTupleMayBeUpdated, /* 0 */HeapTupleInvisible, /* 1 */HeapTupleSelfUpdated, /* 2 */HeapTupleUpdated, /* 3 */HeapTupleBeingUpdated, /* 4 */HeapTupleWouldBlock /* 5 can be returned by heap_tuple_lock */
} HTSU_Result;
此时result的返回值为3,也就是HeapTupleUpdated,这表达式我们在更新当前元组也就是查询出的old tuple时发现old tuple已经被改变了。这里的改变可能是当前元组被更新,也可能是当前元组被删除(如果事务B是一个delete操作就会出现这种情况)。我们来看看如何处理HeapTupleUpdated:
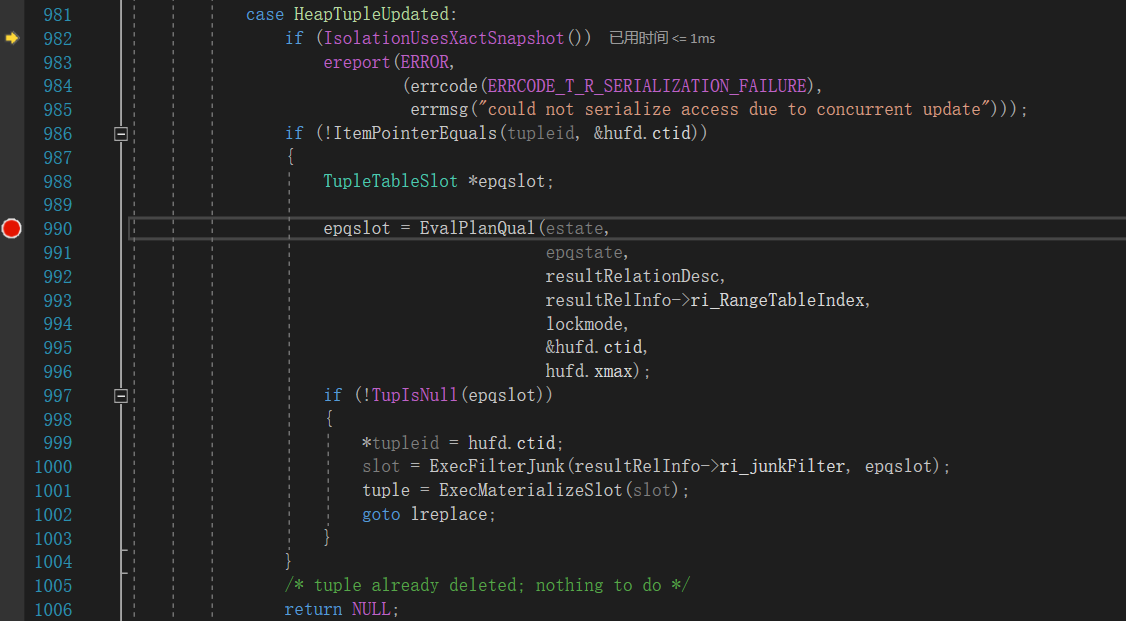
-
调用IsolationUsesXactSnapshot判断当前隔离级别
如果当前隔离级别为 >= RR,则直接报错。
-
调用ItemPointerEquals判断当前元组是被更新还是被删除
如果当前元组被更新,那么元组的ctid会执行new tuple,所以只需要判断当前元组的ctid是否发生变化。
-
如果当前元组被删除则直接return NULL
-
如果当前元组被更新则调用EvalPlanQual
EvalPlanQual函数非常重要,EvalPlanQual首先会获取当前最新版本的元组,然后判断该元组是否符合where条件,如果符合where条件则返回元组,否则返回空。这个步骤非常重要,回顾下场景2,事务B修改了id字段的值,当事务A执行修改时,调用EvalPlanQual时就会发现最新版本的元组已经不满足where条件,所以不做任何操作。
当前我们调试的是场景1,我们来看看EvalPlanQual返回什么?
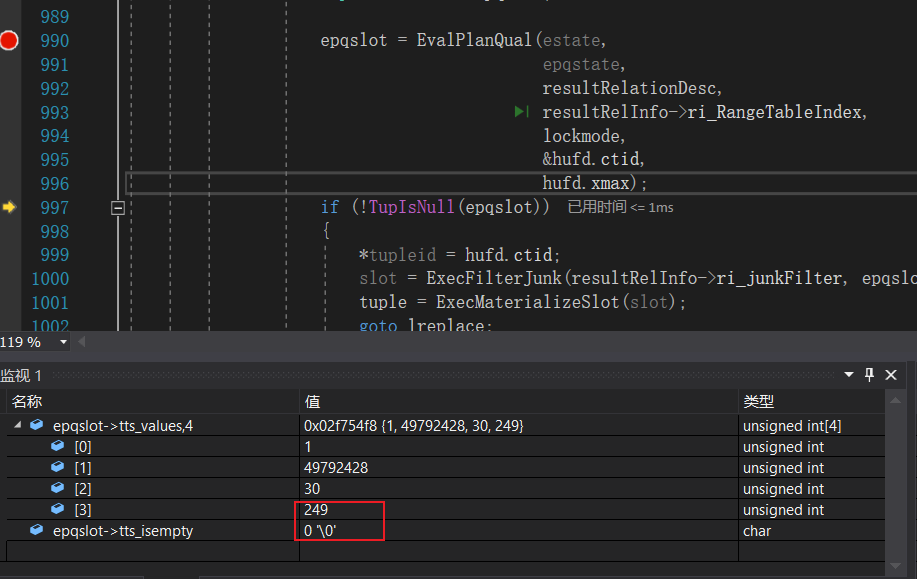
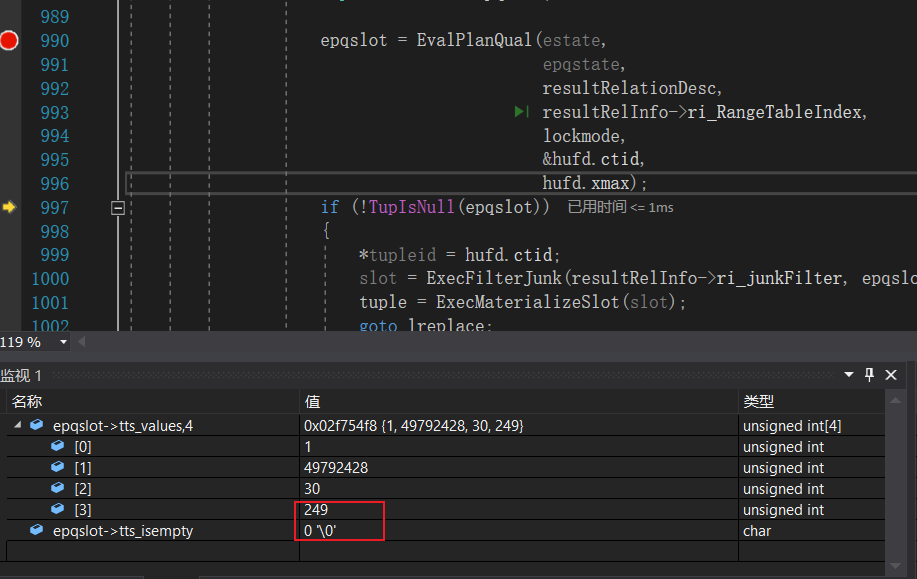
此时,tts_values的第四个字段的值变为了249,这是由于我们使用了事务B更新后的元组来计算score + 100。score的原始值为99,事务B更新后变为了99+50 = 149,再加上100,就是249。
由于场景2中事务B并没有修改id值,所以新元组满足where条件tts_isempty为FALSE,!TupIsNull(epqslot)为TRUE,于是会调用ExecMaterializeSlot使用新的字段重新构建进行更新的元组,然后goto lreplace。
goto到lreplace后会重新执行heap_update。
根据上述流程,其实我们已经解决了场景1和场景2中更新丢失的问题,下面我们来看看EvalPlanQual是如何获取到最新版本的元组,以及heap_update是如何判断当前元组已经被其他事务更改的,即HeapTupleUpdated是如何产生的。
EvalPlanQual
在讲解EvalPlanQual前,我们先来看看EvalPlanQual的调用:

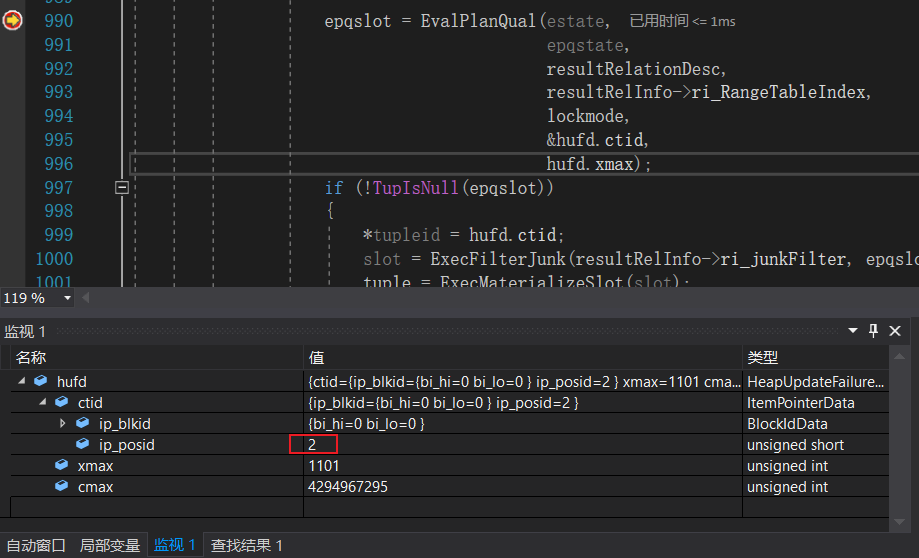
这个hufd是什么东西?hufd是一个HeapUpdateFailureData的结构体,见名知意HeapUpdateFailureData用于标识更新失败的元组。在前面执行heap_update时,由于当前元组已经被其他事务更新,所以返回了HeapTupleUpdated,同时也返回了当前元组的相关信息。

HeapUpdateFailureData的定义如下:
typedef struct HeapUpdateFailureData
{ItemPointerData ctid;TransactionId xmax;CommandId cmax;
} HeapUpdateFailureData;
其中ctid定义了元组的位置信息,这里需要注意的是,由于当前元组发生了更新,所以ctid实际指向的是更新后的元组!PostgreSQL使用ctid来串联元组多次更新产生的多个版本!
EvalPlanQual的实现如下:
TupleTableSlot *
EvalPlanQual(EState *estate, EPQState *epqstate,Relation relation, Index rti, int lockmode,ItemPointer tid, TransactionId priorXmax)
{TupleTableSlot *slot;HeapTuple copyTuple;Assert(rti > 0);/** Get and lock the updated version of the row; if fail, return NULL.*/copyTuple = EvalPlanQualFetch(estate, relation, lockmode, LockWaitBlock,tid, priorXmax);if (copyTuple == NULL)return NULL;/** For UPDATE/DELETE we have to return tid of actual row we're executing* PQ for.*/*tid = copyTuple->t_self;/** Need to run a recheck subquery. Initialize or reinitialize EPQ state.*/EvalPlanQualBegin(epqstate, estate);/** Free old test tuple, if any, and store new tuple where relation's scan* node will see it*/EvalPlanQualSetTuple(epqstate, rti, copyTuple);/** Fetch any non-locked source rows*/EvalPlanQualFetchRowMarks(epqstate);/** Run the EPQ query. We assume it will return at most one tuple.*/slot = EvalPlanQualNext(epqstate);/** If we got a tuple, force the slot to materialize the tuple so that it* is not dependent on any local state in the EPQ query (in particular,* it's highly likely that the slot contains references to any pass-by-ref* datums that may be present in copyTuple). As with the next step, this* is to guard against early re-use of the EPQ query.*/if (!TupIsNull(slot))(void) ExecMaterializeSlot(slot);/** Clear out the test tuple. This is needed in case the EPQ query is* re-used to test a tuple for a different relation. (Not clear that can* really happen, but let's be safe.)*/EvalPlanQualSetTuple(epqstate, rti, NULL);return slot;
}在EvalPlanQual中需要注意两个函数:
-
EvalPlanQualFetch
该函数的注释说的特别明白:Get and lock the updated version of the row;该函数用于获取元组的最新版本。
-
EvalPlanQualNext
该函数会调用ExecProcNode执行一次查询。
EvalPlanQualFetch
EvalPlanQualFetch函数的实现如下:
HeapTuple
EvalPlanQualFetch(EState *estate, Relation relation, int lockmode,LockWaitPolicy wait_policy,ItemPointer tid, TransactionId priorXmax)
{HeapTuple copyTuple = NULL;HeapTupleData tuple;SnapshotData SnapshotDirty;/** fetch target tuple** Loop here to deal with updated or busy tuples* 将可见性判断的方式设置为HeapTupleSatisfiesDirty*/InitDirtySnapshot(SnapshotDirty);tuple.t_self = *tid;for (;;){Buffer buffer;if (heap_fetch(relation, &SnapshotDirty, &tuple, &buffer, true, NULL)){HTSU_Result test;HeapUpdateFailureData hufd;/** If xmin isn't what we're expecting, the slot must have been* recycled and reused for an unrelated tuple. This implies that* the latest version of the row was deleted, so we need do* nothing. (Should be safe to examine xmin without getting* buffer's content lock. We assume reading a TransactionId to be* atomic, and Xmin never changes in an existing tuple, except to* invalid or frozen, and neither of those can match priorXmax.)*/if (!TransactionIdEquals(HeapTupleHeaderGetXmin(tuple.t_data),priorXmax)){ReleaseBuffer(buffer);return NULL;}/* otherwise xmin should not be dirty... */if (TransactionIdIsValid(SnapshotDirty.xmin))elog(ERROR, "t_xmin is uncommitted in tuple to be updated");/** If tuple is being updated by other transaction then we have to* wait for its commit/abort, or die trying.*/if (TransactionIdIsValid(SnapshotDirty.xmax)){ReleaseBuffer(buffer);switch (wait_policy){case LockWaitBlock:XactLockTableWait(SnapshotDirty.xmax,relation, &tuple.t_self,XLTW_FetchUpdated);break;case LockWaitSkip:if (!ConditionalXactLockTableWait(SnapshotDirty.xmax))return NULL; /* skip instead of waiting */break;case LockWaitError:if (!ConditionalXactLockTableWait(SnapshotDirty.xmax))ereport(ERROR,(errcode(ERRCODE_LOCK_NOT_AVAILABLE),errmsg("could not obtain lock on row in relation \"%s\"",RelationGetRelationName(relation))));break;}continue; /* loop back to repeat heap_fetch */}/** If tuple was inserted by our own transaction, we have to check* cmin against es_output_cid: cmin >= current CID means our* command cannot see the tuple, so we should ignore it. Otherwise* heap_lock_tuple() will throw an error, and so would any later* attempt to update or delete the tuple. (We need not check cmax* because HeapTupleSatisfiesDirty will consider a tuple deleted* by our transaction dead, regardless of cmax.) We just checked* that priorXmax == xmin, so we can test that variable instead of* doing HeapTupleHeaderGetXmin again.*/if (TransactionIdIsCurrentTransactionId(priorXmax) &&HeapTupleHeaderGetCmin(tuple.t_data) >= estate->es_output_cid){ReleaseBuffer(buffer);return NULL;}/** This is a live tuple, so now try to lock it.*/test = heap_lock_tuple(relation, &tuple,estate->es_output_cid,lockmode, wait_policy,false, &buffer, &hufd);/* We now have two pins on the buffer, get rid of one */ReleaseBuffer(buffer);switch (test){case HeapTupleSelfUpdated:/** The target tuple was already updated or deleted by the* current command, or by a later command in the current* transaction. We *must* ignore the tuple in the former* case, so as to avoid the "Halloween problem" of* repeated update attempts. In the latter case it might* be sensible to fetch the updated tuple instead, but* doing so would require changing heap_update and* heap_delete to not complain about updating "invisible"* tuples, which seems pretty scary (heap_lock_tuple will* not complain, but few callers expect* HeapTupleInvisible, and we're not one of them). So for* now, treat the tuple as deleted and do not process.*/ReleaseBuffer(buffer);return NULL;case HeapTupleMayBeUpdated:/* successfully locked */break;case HeapTupleUpdated:ReleaseBuffer(buffer);if (IsolationUsesXactSnapshot())ereport(ERROR,(errcode(ERRCODE_T_R_SERIALIZATION_FAILURE),errmsg("could not serialize access due to concurrent update")));/* Should not encounter speculative tuple on recheck */Assert(!HeapTupleHeaderIsSpeculative(tuple.t_data));if (!ItemPointerEquals(&hufd.ctid, &tuple.t_self)){/* it was updated, so look at the updated version */tuple.t_self = hufd.ctid;/* updated row should have xmin matching this xmax */priorXmax = hufd.xmax;continue;}/* tuple was deleted, so give up */return NULL;case HeapTupleWouldBlock:ReleaseBuffer(buffer);return NULL;case HeapTupleInvisible:elog(ERROR, "attempted to lock invisible tuple");default:ReleaseBuffer(buffer);elog(ERROR, "unrecognized heap_lock_tuple status: %u",test);return NULL; /* keep compiler quiet */}/** We got tuple - now copy it for use by recheck query.*/copyTuple = heap_copytuple(&tuple);ReleaseBuffer(buffer);break;}/** If the referenced slot was actually empty, the latest version of* the row must have been deleted, so we need do nothing.*/if (tuple.t_data == NULL){ReleaseBuffer(buffer);return NULL;}/** As above, if xmin isn't what we're expecting, do nothing.*/if (!TransactionIdEquals(HeapTupleHeaderGetXmin(tuple.t_data),priorXmax)){ReleaseBuffer(buffer);return NULL;}/** If we get here, the tuple was found but failed SnapshotDirty.* Assuming the xmin is either a committed xact or our own xact (as it* certainly should be if we're trying to modify the tuple), this must* mean that the row was updated or deleted by either a committed xact* or our own xact. If it was deleted, we can ignore it; if it was* updated then chain up to the next version and repeat the whole* process.** As above, it should be safe to examine xmax and t_ctid without the* buffer content lock, because they can't be changing.*/if (ItemPointerEquals(&tuple.t_self, &tuple.t_data->t_ctid)){/* deleted, so forget about it */ReleaseBuffer(buffer);return NULL;}/* updated, so look at the updated row */tuple.t_self = tuple.t_data->t_ctid;/* updated row should have xmin matching this xmax */priorXmax = HeapTupleHeaderGetUpdateXid(tuple.t_data);ReleaseBuffer(buffer);/* loop back to fetch next in chain */}/** Return the copied tuple*/return copyTuple;
}
在EvalPlanQualFetch中,我们需要重点关注的函数是heap_fetch,用于获取一条元组如果该元组可以用于更新则heap_fetch返回true,否则返回false。为了说清楚heap_fetch的流程,我们修改事务B的执行语句:
begin;
update test set score = score+50 where id = 1;
update test set score = score+50 where id = 1;
commit;
注意:事务B执行了两次update,这样数据库中就有3个版本元组,而只有最新版本的元组才可以执行更新。heap_fetch主要有两个步骤:
- 根据tid获取元组
- 调用HeapTupleSatisfiesVisibility判断元组的可见性
heap_fetch的源代码如下:
bool
heap_fetch(Relation relation,Snapshot snapshot,HeapTuple tuple,Buffer *userbuf,bool keep_buf,Relation stats_relation)
{ItemPointer tid = &(tuple->t_self);ItemId lp;Buffer buffer;Page page;OffsetNumber offnum;bool valid;/** Fetch and pin the appropriate page of the relation.*/buffer = ReadBuffer(relation, ItemPointerGetBlockNumber(tid));/** Need share lock on buffer to examine tuple commit status.*/LockBuffer(buffer, BUFFER_LOCK_SHARE);page = BufferGetPage(buffer);TestForOldSnapshot(snapshot, relation, page);/** We'd better check for out-of-range offnum in case of VACUUM since the* TID was obtained.*/offnum = ItemPointerGetOffsetNumber(tid);if (offnum < FirstOffsetNumber || offnum > PageGetMaxOffsetNumber(page)){LockBuffer(buffer, BUFFER_LOCK_UNLOCK);if (keep_buf)*userbuf = buffer;else{ReleaseBuffer(buffer);*userbuf = InvalidBuffer;}tuple->t_data = NULL;return false;}/** get the item line pointer corresponding to the requested tid* 步骤1:根据tid获取元组*/lp = PageGetItemId(page, offnum);/** Must check for deleted tuple.*/if (!ItemIdIsNormal(lp)){LockBuffer(buffer, BUFFER_LOCK_UNLOCK);if (keep_buf)*userbuf = buffer;else{ReleaseBuffer(buffer);*userbuf = InvalidBuffer;}tuple->t_data = NULL;return false;}/** fill in *tuple fields* 将元组的信息填充到tuple结构体中*/tuple->t_data = (HeapTupleHeader) PageGetItem(page, lp);tuple->t_len = ItemIdGetLength(lp);tuple->t_tableOid = RelationGetRelid(relation);/** check time qualification of tuple, then release lock* 步骤2:调用HeapTupleSatisfiesVisibility判断元组可见性*/valid = HeapTupleSatisfiesVisibility(tuple, snapshot, buffer);if (valid)PredicateLockTuple(relation, tuple, snapshot);CheckForSerializableConflictOut(valid, relation, tuple, buffer, snapshot);LockBuffer(buffer, BUFFER_LOCK_UNLOCK);if (valid){/** All checks passed, so return the tuple as valid. Caller is now* responsible for releasing the buffer.*/*userbuf = buffer;/* Count the successful fetch against appropriate rel, if any */if (stats_relation != NULL)pgstat_count_heap_fetch(stats_relation);return true;}/* Tuple failed time qual, but maybe caller wants to see it anyway. */if (keep_buf)*userbuf = buffer;else{ReleaseBuffer(buffer);*userbuf = InvalidBuffer;}return false;
}
下面我们来调试heap_fetch。
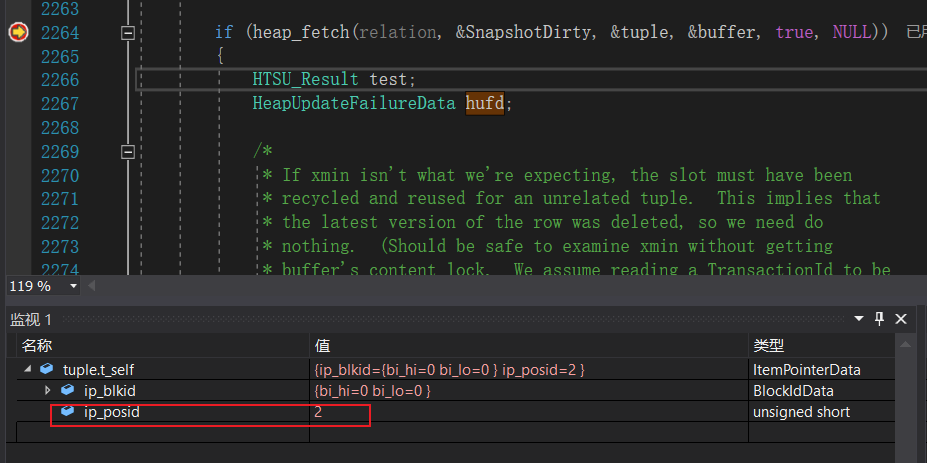
这是我们第一次调用heap_fetch,此时ip_posid的值为2,对应用例中元组的第二个版本,也就是事务B第一次执行完update后的版本,该版本并不是最新的版本,不能用于更新。我们来看看heap_fetch是如果过滤掉这条记录的。
在heap_fetch中,会首先获取ip_posid对应的元组,然后调用HeapTupleSatisfiesVisibility判断元组的可见性,HeapTupleSatisfiesVisibility实际会调用HeapTupleSatisfiesDirty。在全表遍历时我们介绍过HeapTupleSatisfiesMVCC,HeapTupleSatisfiesDirty的判断规则与HeapTupleSatisfiesMVCC非常不一样。HeapTupleSatisfiesDirty用于判断一条元组对当前元组是否是脏数据。对于当前元组来说,由于该元组已经被修改,并且修改已经提交,即该元组t_xmax对应的元组已经提交,所以该元组并不是一条脏的元组。

所以HeapTupleSatisfiesDirty会返回false,于是heap_fetch也会返回false,于是EvalPlanQualFetch会继续循环。注意,在heap_fetch中已经将tuple中的元组更新为了事务B第一更新后的元组,该元组由于被事务B进行了第二次更新,所以元组的t_ctid将指向最新的版本。
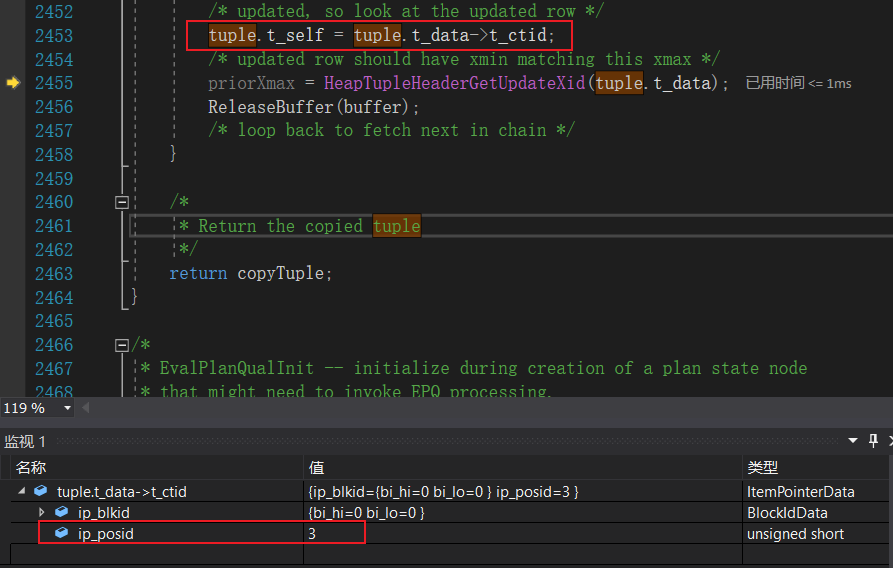
如此,更新t_self后循环将再次执行heap_fetch
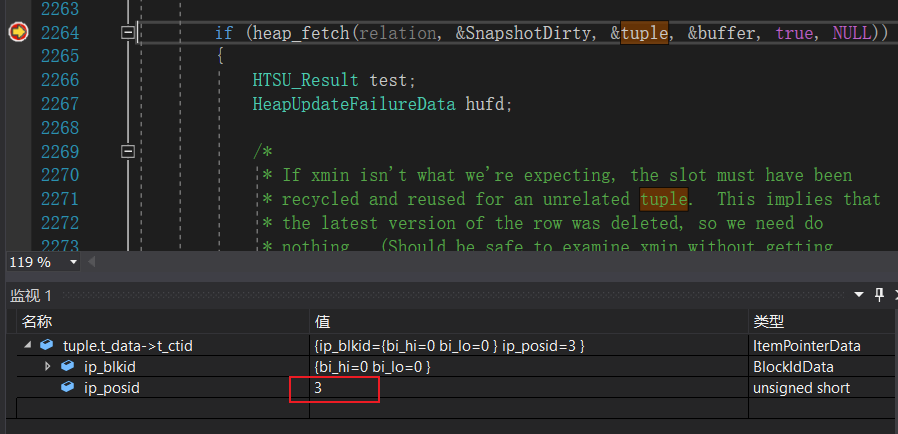
此时,heap_fech将获取最新版本的元组。
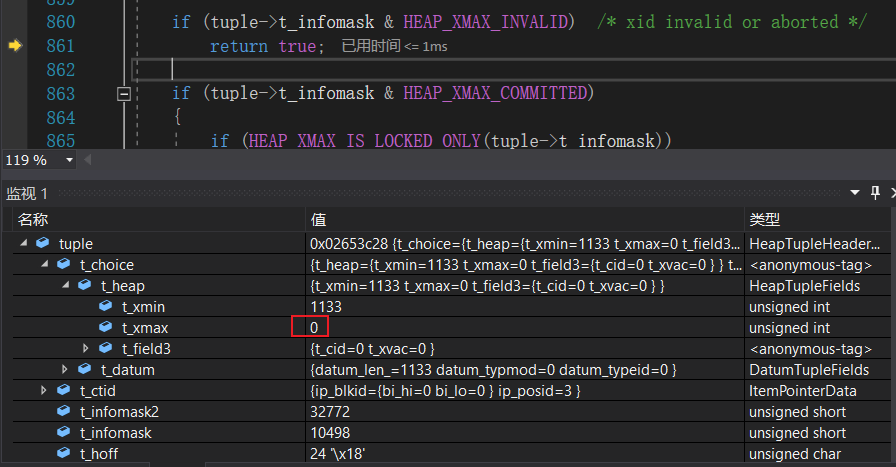
在HeapTupleSatisfiesDirty中由于该元组为最新版本,所以t_xmax为0,自然满足HEAP_XMAX_INVALID,所以是一条脏的记录!如此我们就找到了最版本的元组。
EvalPlanQualNext
在通过EvalPlanQualFetch获取最新版的元组后,接着会调用EvalPlanQualNext,该函数会调用ExecProcNode执行一次查询,实现代码如下:
TupleTableSlot *
EvalPlanQualNext(EPQState *epqstate)
{MemoryContext oldcontext;TupleTableSlot *slot;oldcontext = MemoryContextSwitchTo(epqstate->estate->es_query_cxt);slot = ExecProcNode(epqstate->planstate);MemoryContextSwitchTo(oldcontext);return slot;
}
需要注意,ExecProcNode在执行时并不会真正的去执行查询操作,因为已经获取到了元组,为什么还要执行查询?实际上这里只是借助查询的框架做两件事:
- 依据最新版的本的元组获取我们需要的字段值。
- 判断最新版本的元组是否满足where条件。
EvalPlanQualNext执行过后我们就产生了我们在前面看到过的结果:
HeapTupleSatisfiesUpdate
最后我们来看看heap_update是如何判断一条元组是否可以修改的。其核心的函数就是HeapTupleSatisfiesUpdate,其实现如下:
HTSU_Result
HeapTupleSatisfiesUpdate(HeapTuple htup, CommandId curcid,Buffer buffer)
{HeapTupleHeader tuple = htup->t_data;Assert(ItemPointerIsValid(&htup->t_self));Assert(htup->t_tableOid != InvalidOid);if (!HeapTupleHeaderXminCommitted(tuple)){if (HeapTupleHeaderXminInvalid(tuple))return HeapTupleInvisible;/* Used by pre-9.0 binary upgrades */if (tuple->t_infomask & HEAP_MOVED_OFF){TransactionId xvac = HeapTupleHeaderGetXvac(tuple);if (TransactionIdIsCurrentTransactionId(xvac))return HeapTupleInvisible;if (!TransactionIdIsInProgress(xvac)){if (TransactionIdDidCommit(xvac)){SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,InvalidTransactionId);return HeapTupleInvisible;}SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,InvalidTransactionId);}}/* Used by pre-9.0 binary upgrades */else if (tuple->t_infomask & HEAP_MOVED_IN){TransactionId xvac = HeapTupleHeaderGetXvac(tuple);if (!TransactionIdIsCurrentTransactionId(xvac)){if (TransactionIdIsInProgress(xvac))return HeapTupleInvisible;if (TransactionIdDidCommit(xvac))SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,InvalidTransactionId);else{SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,InvalidTransactionId);return HeapTupleInvisible;}}}else if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmin(tuple))){if (HeapTupleHeaderGetCmin(tuple) >= curcid)return HeapTupleInvisible; /* inserted after scan started */if (tuple->t_infomask & HEAP_XMAX_INVALID) /* xid invalid */return HeapTupleMayBeUpdated;if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask)){TransactionId xmax;xmax = HeapTupleHeaderGetRawXmax(tuple);/** Careful here: even though this tuple was created by our own* transaction, it might be locked by other transactions, if* the original version was key-share locked when we updated* it.*/if (tuple->t_infomask & HEAP_XMAX_IS_MULTI){if (MultiXactIdIsRunning(xmax, true))return HeapTupleBeingUpdated;elsereturn HeapTupleMayBeUpdated;}/** If the locker is gone, then there is nothing of interest* left in this Xmax; otherwise, report the tuple as* locked/updated.*/if (!TransactionIdIsInProgress(xmax))return HeapTupleMayBeUpdated;return HeapTupleBeingUpdated;}if (tuple->t_infomask & HEAP_XMAX_IS_MULTI){TransactionId xmax;xmax = HeapTupleGetUpdateXid(tuple);/* not LOCKED_ONLY, so it has to have an xmax */Assert(TransactionIdIsValid(xmax));/* deleting subtransaction must have aborted */if (!TransactionIdIsCurrentTransactionId(xmax)){if (MultiXactIdIsRunning(HeapTupleHeaderGetRawXmax(tuple),false))return HeapTupleBeingUpdated;return HeapTupleMayBeUpdated;}else{if (HeapTupleHeaderGetCmax(tuple) >= curcid)return HeapTupleSelfUpdated; /* updated after scan* started */elsereturn HeapTupleInvisible; /* updated before scan* started */}}if (!TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple))){/* deleting subtransaction must have aborted */SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,InvalidTransactionId);return HeapTupleMayBeUpdated;}if (HeapTupleHeaderGetCmax(tuple) >= curcid)return HeapTupleSelfUpdated; /* updated after scan started */elsereturn HeapTupleInvisible; /* updated before scan started */}else if (TransactionIdIsInProgress(HeapTupleHeaderGetRawXmin(tuple)))return HeapTupleInvisible;else if (TransactionIdDidCommit(HeapTupleHeaderGetRawXmin(tuple)))SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,HeapTupleHeaderGetRawXmin(tuple));else{/* it must have aborted or crashed */SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,InvalidTransactionId);return HeapTupleInvisible;}}/* by here, the inserting transaction has committed *//* t_xmax非法,即t_xmax不可见,说明元组没被修改,或被修改未生效(例如:被回滚) */if (tuple->t_infomask & HEAP_XMAX_INVALID) /* xid invalid or aborted */return HeapTupleMayBeUpdated;/* t_xmax提交,即t_xmax可见,说明元组被修改 */if (tuple->t_infomask & HEAP_XMAX_COMMITTED){if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask))return HeapTupleMayBeUpdated;return HeapTupleUpdated; /* updated by other */}if (tuple->t_infomask & HEAP_XMAX_IS_MULTI){TransactionId xmax;if (HEAP_LOCKED_UPGRADED(tuple->t_infomask))return HeapTupleMayBeUpdated;if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask)){if (MultiXactIdIsRunning(HeapTupleHeaderGetRawXmax(tuple), true))return HeapTupleBeingUpdated;SetHintBits(tuple, buffer, HEAP_XMAX_INVALID, InvalidTransactionId);return HeapTupleMayBeUpdated;}xmax = HeapTupleGetUpdateXid(tuple);if (!TransactionIdIsValid(xmax)){if (MultiXactIdIsRunning(HeapTupleHeaderGetRawXmax(tuple), false))return HeapTupleBeingUpdated;}/* not LOCKED_ONLY, so it has to have an xmax */Assert(TransactionIdIsValid(xmax));if (TransactionIdIsCurrentTransactionId(xmax)){if (HeapTupleHeaderGetCmax(tuple) >= curcid)return HeapTupleSelfUpdated; /* updated after scan started */elsereturn HeapTupleInvisible; /* updated before scan started */}if (MultiXactIdIsRunning(HeapTupleHeaderGetRawXmax(tuple), false))return HeapTupleBeingUpdated;if (TransactionIdDidCommit(xmax))return HeapTupleUpdated;/** By here, the update in the Xmax is either aborted or crashed, but* what about the other members?*/if (!MultiXactIdIsRunning(HeapTupleHeaderGetRawXmax(tuple), false)){/** There's no member, even just a locker, alive anymore, so we can* mark the Xmax as invalid.*/SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,InvalidTransactionId);return HeapTupleMayBeUpdated;}else{/* There are lockers running */return HeapTupleBeingUpdated;}}if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple))){if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask))return HeapTupleBeingUpdated;if (HeapTupleHeaderGetCmax(tuple) >= curcid)return HeapTupleSelfUpdated; /* updated after scan started */elsereturn HeapTupleInvisible; /* updated before scan started */}/* t_xmax为活动事务,说明元组正在被更新 */if (TransactionIdIsInProgress(HeapTupleHeaderGetRawXmax(tuple)))return HeapTupleBeingUpdated;/* t_xmax未提交,说明元组更新失效 */if (!TransactionIdDidCommit(HeapTupleHeaderGetRawXmax(tuple))){/* it must have aborted or crashed */SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,InvalidTransactionId);return HeapTupleMayBeUpdated;}/* xmax transaction committed */if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask)){SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,InvalidTransactionId);return HeapTupleMayBeUpdated;}SetHintBits(tuple, buffer, HEAP_XMAX_COMMITTED,HeapTupleHeaderGetRawXmax(tuple));return HeapTupleUpdated; /* updated by other */
}
这里我们主要关注三类返回值:
-
HeapTupleBeingUpdated
表示当前元组正在被其他事务更新,需要等待。
-
HeapTupleMayBeUpdated
表示当前元组可能被更新,这种状态是为可以更新当前元组。
-
HeapTupleUpdated
表示当前元组已经被其他事务更新,无法更新当前元组。
对于这三种状态的判断,主要依靠TransactionIdIsInProgress函数和t_xmax是否可见。TransactionIdIsInProgress返回TRUE说明,有事务正在更新元组,返回HeapTupleBeingUpdated。如果t_xmax不可见则说明该元组没有被其他事务更新返回HeapTupleMayBeUpdated,否则说明该元组已经被其他事务更新返回HeapTupleUpdated。