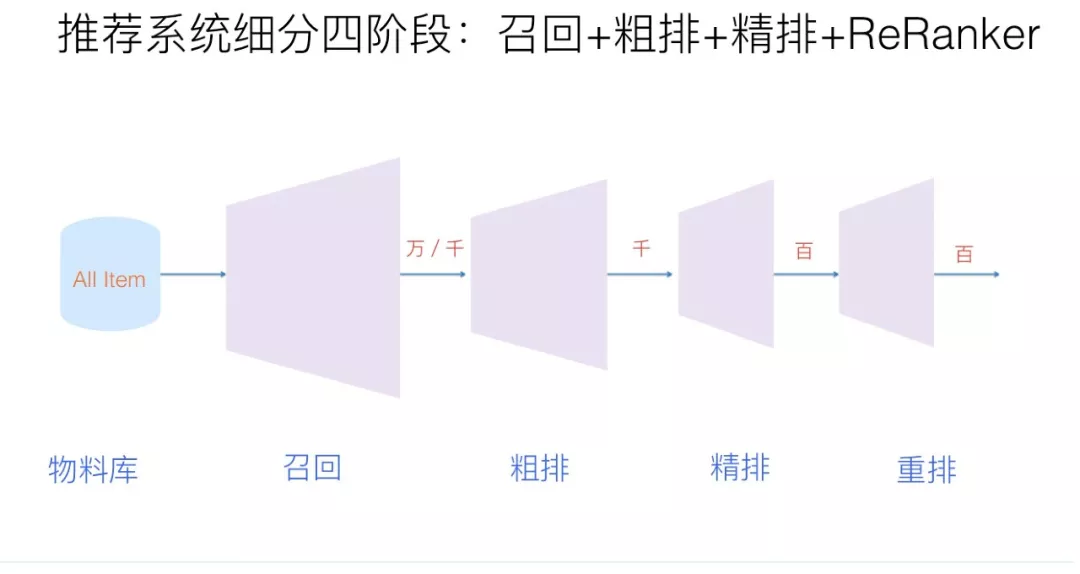
初始推荐系统
最重要的还是梳理清楚整个推荐系统的架构,知道每一个部分需要完成哪些任务,是如何做的,主要的技术栈是什么,有哪些局限和可以研究的问题
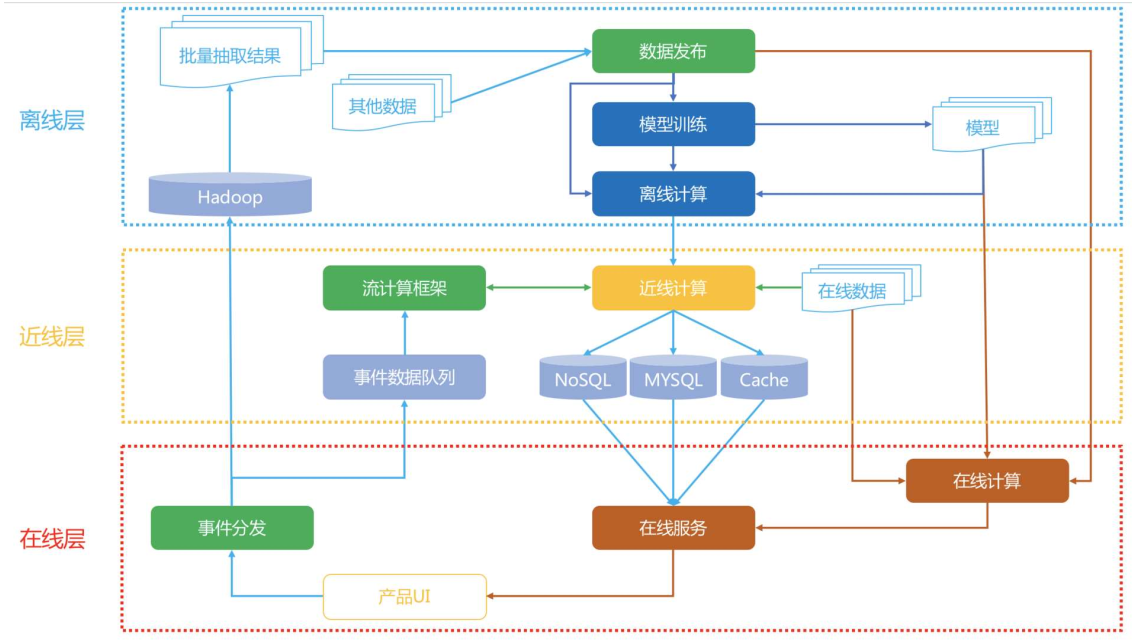
1.
首先是客户端和服务端的实时数据处理。做埋点,将用户在平台上真实的行为记录下来,因为数据这种东西需要工程师去主动记录,既然做推荐系统,要分析用户行为,还要训练模型,显然需要数据。需要数据,就需要记录。
2.
流处理平台准实时数据处理,记录一些准实时的数据,可能存在几分钟的误差。那什么样的准实时数据需要记录呢?在推荐领域基本上只有一个类别,就是用户行为数据。也就是用户在观看这个内容之前还看过哪些内容,和哪些内容发生过交互。由于这部分数据量比较大,并且逻辑也相对复杂,所以很难做到非常实时,一般都是通过消息队列加在线缓存的方式做成准实时。
3.
离线数据处理,基本上就没有时限的要求了。一般来说,离线处理才是数据处理的大头。所有“脏活累活”复杂的操作都是在离线完成的,比如说一些join操作。后端只是记录了用户交互的商品id,我们需要商品的详细信息怎么办?需要去和商品表关联查表。显然数据关联是一个非常耗时的操作,所以只能放到离线来做。
这三个层面:
1.在线层
在线层,就是直接面向用户的的那一层了。最大的特点是对响应延时有要求,需要快速返回结果
它主要承担的工作有:
- 模型在线服务;包括了快速召回和排序;
- 在线特征快速处理拼接::根据传入的用户ID和场景,快速读取特征和处理;
- AB实验或者分流:根据不同用户采用不一样的模型,比如冷启动用户和正常服务模型;
- 运筹优化和业务干预:比如要对特殊商家流量扶持、对某些内容限流;
典型的在线服务是用过RESTful/RPC等提供服务,一般是公司后台服务部门调用我们的这个服务,返回给前端。在线服务的数据源就是我们在离线层计算好的每个用户和商品特征,我们事先存放在数据库中,在线层只需要实时拼接,不进行复杂的特征运算,然后输入近线层或者离线层已经训练好的模型,根据推理结果进行排序,最后返回给后台服务
在线层最大的问题就是对实时性要求特别高,一般来说是几十毫秒,这就限制了我们能做的工作,很多任务往往无法及时完成,需要近线层协助我们做
2.近线层
近线层的主要特点是准实时,它可以获得实时数据,然后快速计算提供服务,但是并不要求它和在线层一样达到几十毫秒这种延时要求。近线层的产生是同时想要弥补离线层和在线层的不足,折中的产物。
它适合处理一些对延时比较敏感的任务,比如:
- 特征的事实更新计算:例如统计用户对不同type的ctr,推荐系统一个老生常谈的问题就是特征分布不一致怎么办,如果使用离线算好的特征就容易出现这个问题。近线层能够获取实时数据,按照用户的实时兴趣计算就能很好避免这个问题。
- 实时训练数据的获取:比如在使用DIN、DSIN这行网络会依赖于用户的实时兴趣变化,用户几分钟前的点击就可以通过近线层获取特征输入模型。
- 模型实时训练:可以通过在线学习的方法更新模型,实时推送到线上;
近线层的发展得益于最近几年大数据技术的发展,很多流处理框架的提出大大促进了近线层的进步。如今Flink、Storm等工具一统天下
3.离线层
离线层是计算量最大的一个部分,需要实现的主要功能模块是:
- 数据处理、数据存储;
- 特征工程、离线特征计算;
- 离线模型的训练;
离线任务一般会按照天或者更久运行,比如每天晚上定期更新这一天的数据,然后重新训练模型,第二天上线新模型。
离线层优势和不足
离线层面临的数据量级是最大的,面临主要的问题是海量数据存储、大规模特征工程、多机分布式机器学习模型训练。目前主流的做法是HDFS,收集到我们所有的业务数据,通过HIVE等工具,从全量数据中抽取出我们需要的数据,进行相应的加工,离线阶段主流使用的分布式框架一般是Spark。所以离线层有如下的优势:
- 可以处理大量的数据,进行大规模特征工程;
- 可以进行批量处理和计算;
- 不用有响应时间要求;