sed 命令的使用
sed 命令的使用
sed 介绍
sed,英文全称 stream editor ,是一种非交互式的流编辑器,能够实现对文本非交互式的处理,功能很强大。
sed 是一个 70 后,诞生于 1973 - 1974 年间,具体时间未知。而出生地则是鼎鼎大名的 贝尔实验室。
sed 是 麦克马洪 ( McMahon ) 老爷子在 贝尔实验室 时开发出来的。
sed 的诞生使并不是那么的神秘,它的诞生只不过是 麦克马洪 ( McMahon ) 老爷子想写一个 行编辑器,谁知写着写着就写成了 sed 的样子。
其实,在 sed 之前还有一个更古老的行编辑器,名字叫做 ed 编辑器。大概是 麦克马洪 ( McMahon ) 老爷子觉得 ed 编辑器不好用吧,顺手重新构架和编写。
sed 工作流程
sed 工作流程,说起来很简单。
读取行 -> 执行 -> 显示 -> 读取行 -> 执行 -> 显示 -> .... -> 读取行 -> 执行 -> 显示

-
读取行
sed 从输入流 (文件、管道、标准输入流)中读取 一行 并存储在名叫
pattern space的内部空间中。sed 是行文字处理器。每次只会读取一行。
sed 内部会有一个计数器,记录着当前已经处理多少行,也就是当前行的行号。
-
执行
按照 sed 命令定义的顺序依次应用于刚刚读取的 一行 数据。
默认情况下,sed 一行一行的处理所有的输入数据。但如果我们指定了行号,则只会处理指定的行。
-
显示
把经过 sed 命令处理的数据发送到输出流(文件、管道、标准输出),并同时清空
pattern space空间。 -
上面流程一直循环,直到输入流中的数据全部处理完成。
sed 注意事项
整个流程看似简单,有几个知识点需要注意:
-
pattern space空间是 sed 在内存中开辟的一个私有的存储区域。内存的特性,会导致关闭命令行或关机数据就没了。 -
默认情况下,sed 命令只会处理
pattern space空间中的数据,且并不会将处理后的数据保存到源文件中。也就是说,sed 默认并不会修改源文件。但 GNU SED 提供提供了一种方式用于修改 源文件。方式就是传递
-i选项,在后面的章节中介绍。 -
sed 还在内存上开辟了另一个私有的空间
hold space用于保存处理后的数据以供以后检索。每一个周期执行结束,sed 会清空
pattern space空间的内容,但hold space空间的内容并不会清空。hold space空间用于存储处理后数据,sed 命令并不会对这里的数据处理。这样,当 sed 需要之前处理后的数据时,可以随时从
hold space空间读取。 -
sed 程序执行前,模式
pattern和hold space空间都是空的。 -
如果我们没有传递任何输入文件,sed 默认会从 标准输入 中读取数据。
-
sed 可以指定只处理输入数据中的行范围。默认情况下是全部行,因此会依次处理每一行。
sed 命令语法
sed 帮助
[wsh@test ~ ✔]$ sed --help
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...-n, --quiet, --silentsuppress automatic printing of pattern space-e script, --expression=scriptadd the script to the commands to be executed-f script-file, --file=script-fileadd the contents of script-file to the commands to be executed--follow-symlinksfollow symlinks when processing in place-i[SUFFIX], --in-place[=SUFFIX]edit files in place (makes backup if SUFFIX supplied)-c, --copyuse copy instead of rename when shuffling files in -i mode-b, --binarydoes nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (open files in binary mode (CR+LFs are not treated specially))-l N, --line-length=Nspecify the desired line-wrap length for the `l' command--posixdisable all GNU extensions.-r, --regexp-extendeduse extended regular expressions in the script.-s, --separateconsider files as separate rather than as a single continuouslong stream.-u, --unbufferedload minimal amounts of data from the input files and flushthe output buffers more often-z, --null-dataseparate lines by NUL characters--helpdisplay this help and exit--versionoutput version information and exitIf no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.GNU sed home page: <http://www.gnu.org/software/sed/>.
General help using GNU software: <http://www.gnu.org/gethelp/>.
E-mail bug reports to: <bug-sed@gnu.org>.
Be sure to include the word ``sed'' somewhere in the ``Subject:'' field. -n, --quiet, --silent 取消自动打印模式空间-e 脚本, --expression=脚本 添加“脚本”到程序的运行列表-f 脚本文件, --file=脚本文件 添加“脚本文件”到程序的运行列表--follow-symlinks 直接修改文件时跟随软链接-i[扩展名], --in-place[=扩展名] 直接修改文件(如果指定扩展名就备份文件)-l N, --line-length=N 指定“l”命令的换行期望长度--posix 关闭所有 GNU 扩展-r, --regexp-extended 在脚本中使用扩展正则表达式-s, --separate 将输入文件视为各个独立的文件而不是一个长的连续输入-u, --unspaceed 从输入文件读取最少的数据,更频繁的刷新输出--help 打印帮助并退出--version 输出版本信息并退出-a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~-c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!-d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚;-i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);-p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~-s ∶取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法
sed 命令语法简写格式如下:
sed [option] [sed-command] [input-file]
总的来说 sed 命令主要由四部分构成:
sed命令。[option]命令行选项,用于改变 sed 的工作流程。[sed-command]是具体的 sed 命令。[input-file]输入数据,如果不指定,则默认从标准输入中读取。
示例1:模拟cat命令打印文件内容
[wsh@test ~ ✔]$ cat datd.txt
I am studing sed
I am www.twle.cn
I am a no-work-men
I am so handsome[wsh@test ~ ✔]$ sed '' data.txt
I am studing sed
I am www.twle.cn
I am a no-work-men
I am so handsome
对照着 sed 命令的语法格式:
- 这里未使用
option。 '',对应着[sed-command]为具体的 sed 语句。data.txt,对应着[input-file],用于提供输入数据。
示例2:从标准输入中读取数据
如果我们没有提供输入文件,那么 sed 默认会冲标准输入中读取数据。
[wsh@test ~ ✔]$ sed ''
# 输入hello world,并回车
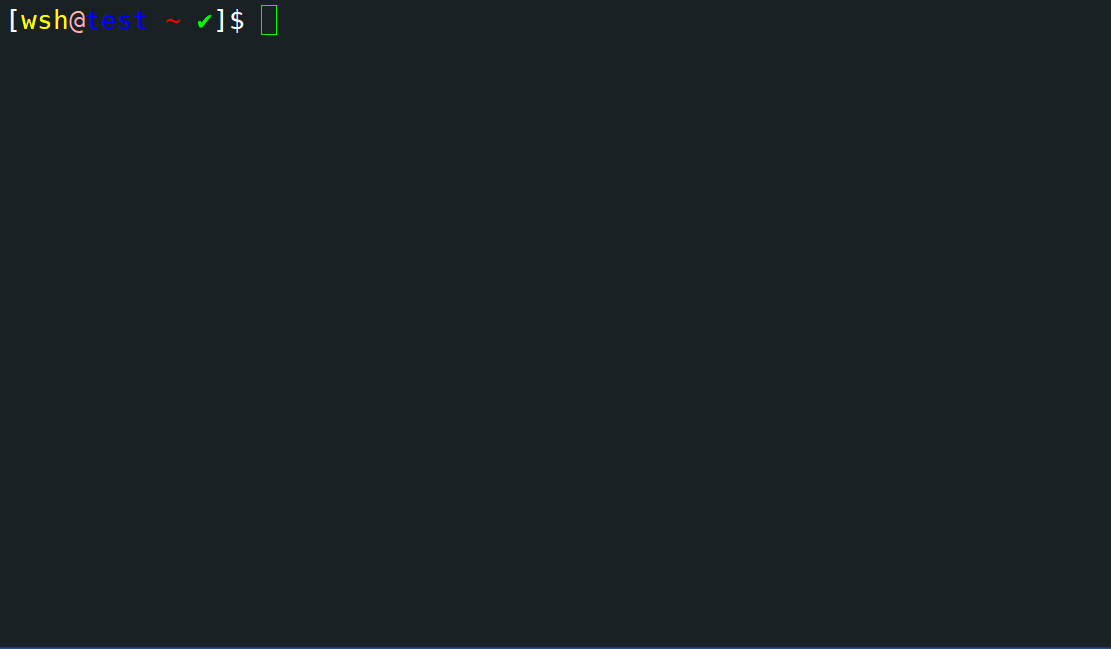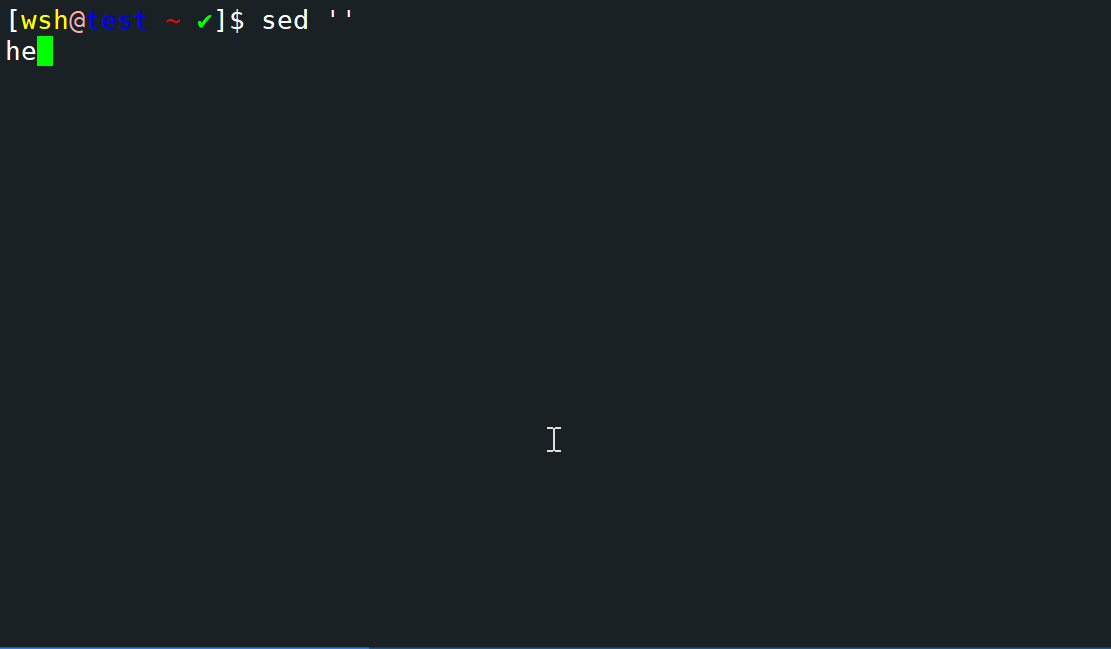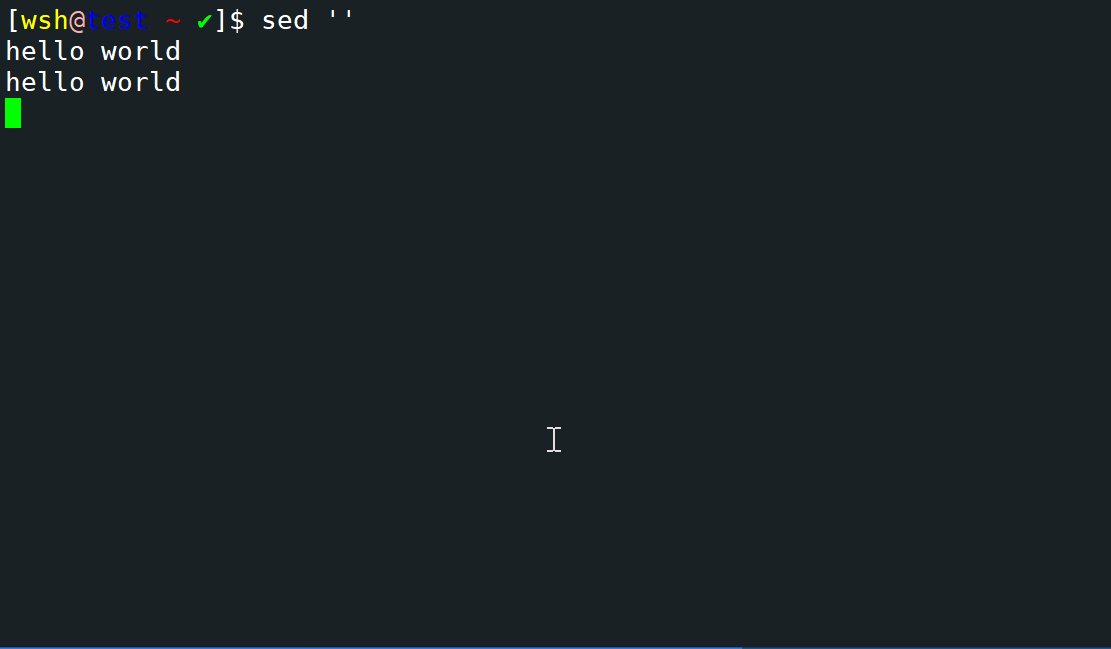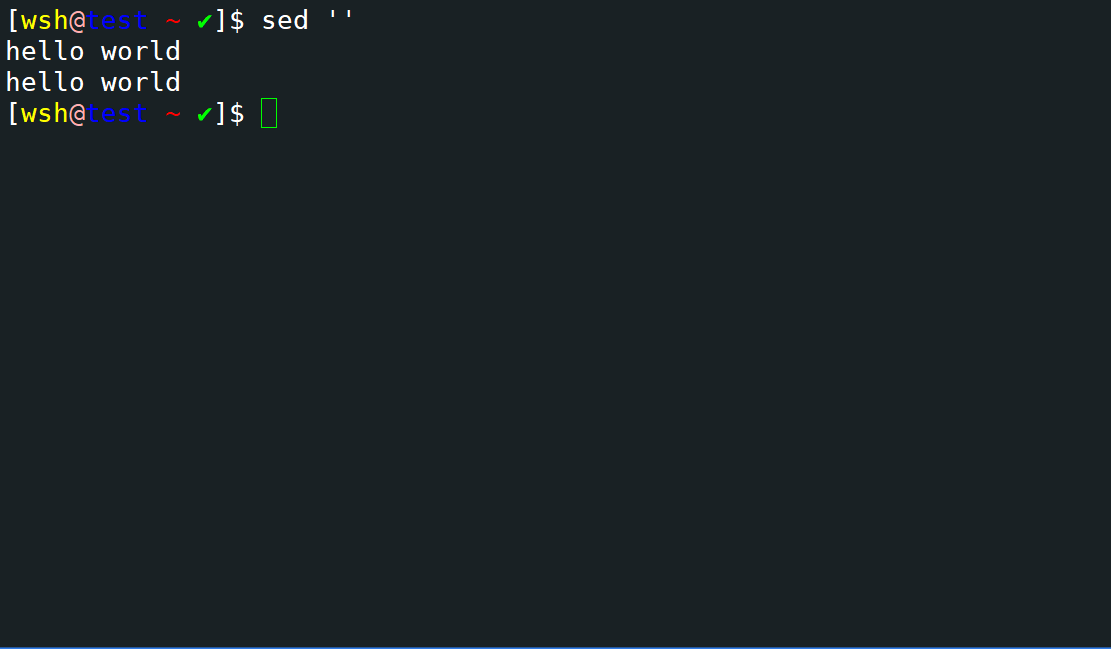
hello world
# 输出hello world
hello world
# 按ctrl+d推出
-e 选项
从命令行读取sed命令,我们需要将 sed 命令使用单引号 ( '' ) 引起来。
# 打印data.txt文件内容
[wsh@test ~ ✔]$ sed -e '' data.txt# 如果只有一个命令,-e选项可以省略
[wsh@test ~ ✔]$ sed '' data.txt# -e 选项可以多次使用,1d是作用是删除第一行
[wsh@test ~ ✔]$ sed -e '1d' -e '2d' -e '5d' data.txt
I am a no-work-men
I am so handsome
# 因为不存在第五行,所以也就没删除的效果# 使用分号(;)分开多个命令
[wsh@test ~ ✔]$ sed -e '1d;2d;5d' data.txt
I am a no-work-men
I am so handsome
-f 选项
sed 还支持把所有 sed 命令保存在一个普通的文本文件里,然后通过 -f 选项来运行这个文件。
当把 sed 存储在文件中时,需要注意 每一个 sed 命令独自成一行。
文件的作用仅仅用于存储命令而已,因此存储 sed 命令的文件并没有任何特殊,可以是一个 .txt 文本文件。
[wsh@test ~ ✔]$ echo -e "1d\n2d\n5d" > scripts
[wsh@test ~ ✔]$ cat scripts
1d
2d
5d
[wsh@test ~ ✔]$ sed -f scripts data.txt
I am a no-work-men
I am so handsome
-n 选项
如果指定了该选项,那么模式空间数据将不会自动打印,需要明确指明打印才会输出记录。
# 以下命令没有任何输出
[wsh@test ~ ✔]$ sed -n '' data.txt# 打印第一行记录
[wsh@test ~ ✔]$ sed -n '1p' data.txt
I am studing sed
sed 行寻址
作用
通过行寻址匹配要处理的输入流。
语法
这里以打印命令p为例。
语法:[address1[,address2]]p
address1和address2分别是 起始地址 和 结束地址,可以是 行号或 模式字符串。address1和address2都是可选参数,可以都不填,这时候就是打印所有行,从文件的开头到文件结束。- 如果存在一个,那么就是打印 单行。也就是只打印
address1指定的那行。 p命令仅从 模式缓冲区 中打印行,也就是该行不会发送到输出流,原始文件保持不变。
示例文件
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5 ' > test
演示
示例1: 打印所有行
# 打印所有行
[wsh@test ~ ✔]$ cat test | sed ''
# 输出结果
This is 1
This is 2
This is 3
This is 4
This is 5 # sed 默认打印模式缓冲区中所有内容。# 等效于
[wsh@test ~ ✔]$ cat test | sed -n 'p'
# -n 关闭sed打印模式缓冲区中所有内容。
# p命令,明确打印输出模式缓冲区中所有内容。
示例2: 打印特定行
# 打印第1行
[wsh@test ~ ✔]$ cat test | sed -n '1p'# 输出结果
This is 1# 打印第最后一行
[wsh@test ~ ✔]$ cat test | sed -n '$p'
# 输出结果
This is 5
示例3: 打印第1行到3行
[wsh@test ~ ✔]$ cat test | sed -n '1,3p'# 输出结果
This is 1
This is 2
This is 3
示例4: 打印第3行到最后一行
[wsh@test ~ ✔]$ cat test | sed -n '3,$p'# 输出结果
This is 3
This is 4
This is 5
示例5: 连续输出,打印第2行以及后续两行
[wsh@test ~ ✔]$ cat test | sed -n '2,+2p'# 输出结果
This is 2
This is 3
This is 4
示例6: 隔行输出,打印第1行以及后续每隔2行输出
[wsh@test ~ ✔]$ cat test | sed -n '1~2p'# 输出结果
This is 1
This is 3
This is 5
sed 模式寻址
sed 除了可以从行号来选择行,s还支持模式查找指定的行。
-
模式 可以是一个普通的字符串或者一个正则表达式。
-
模式 的语法和行寻址的语法类似,只是把行号换成了 模式 匹配。
例如,输出匹配指定模式的行,语法格式如下:
/pattern/
示例文件
[wsh@test ~ ✔]$ cat << 'EOF' > ~/test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
mail:x:8:12:mail:/var/spool/mail:/bin/false
ftp:x:14:11:ftp:/home/ftp:/bin/false
&nobody:$:99:99:nobody:/:/bin/false
zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash
http:x:33:33::/srv/http:/bin/false
dbus:x:81:81:System message bus:/:/bin/false
hal:x:82:82:HAL daemon:/:/bin/false
mysql:x:89:89::/var/lib/mysql:/bin/false
aaa:x:1001:1001::/home/aaa:/bin/bash
ba:x:1002:1002::/home/zhangy:/bin/bash
test:x:1003:1003::/home/test:/bin/bash
@zhangying:*:1004:1004::/home/test:/bin/bash
policykit:x:102:1005:Po
EOF
演示
示例1: 打印含有字符串zhang的行
[wsh@test ~ ✔]$ cat test | sed -n '/zhang/p'
zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash
ba:x:1002:1002::/home/zhangy:/bin/bash
@zhangying:*:1004:1004::/home/test:/bin/bash
示例2: 打印root开头的行到zhang开头的行
[wsh@test ~ ✔]$ cat test | sed -n '/^root/,/^mail/p'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
mail:x:8:12:mail:/var/spool/mail:/bin/false
示例3: 打印root开头的行到第三行
[wsh@test ~ ✔]$ cat test | sed -n '/^root/,3p'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
示例4: 打印root开头的行到最后一行
[wsh@test ~ ✔]$ cat test | sed -n '/^root/,$p'
sed 子命令
打印
作用
- p,打印模式空间所有记录。
- P,打印模式空间第一行记录。
语法
格式:[address1[,address2]]p
address1和address2分别是 起始地址 和 结束地址,可以是 行号或 模式字符串。address1和address2都是可选参数,可以都不填,这时候就是打印所有行,从文件的开头到文件结束。- 如果存在一个,那么就是打印 单行。也就是只打印
address1指定的那行。 p命令仅从 模式缓冲区 中打印行,也就是该行不会发送到输出流,原始文件保持不变。
示例
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3' | sed -n '1{N;p}'
# N是一个命令,表示将下一行读入模式空间并追加到当前行之后# 输出结果
This is 1
This is 2[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3' | sed -n '1{N;P}'# 输出结果
This is 1
读取下一行
- n,提前读取下一行,覆盖模型空间之前读取的行。模型空间之前读取的行并没有删除,依然打印至标准输出,除非使用-n选项指明不打印。
示例1:打印偶数行内容
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5' | sed -n 'n;p'# 输出内容
This is 2
This is 4
说明:
- 读取
This is 1,执行n命令,此时模式空间为This is 2,执行p,打印模式空间内容This is 2。 - 之后读取
This is 3,执行 n 命令,此时模式空间为This is 4,执行p,打印模式空间内容This is 4。 - 之后读取
This is 5,执行 n 命令,因为后续没有内容了,所以退出,并放弃p命令。
因此,最终打印出来的就是偶数行。
- N,简单来说就是追加下一行到模式空间,同时将两行看做一行,但是两行之间依然含有\n换行符。
示例1: 成对合并行
[wsh@test ~ ✔]$ cat test | sed 'N;s/\n/==/'
root:x:0:0:root:/root:/bin/bash==bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false==mail:x:8:12:mail:/var/spool/mail:/bin/false
...
说明:
N,追加下一行到当前行后面,组成一个新行来处理。s/\n/==/,将新行中\n换行符替换成==,末尾的换行符不替换。
示例2: 打印前2行
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5' | sed -n '1{N;p}'
This is 1
This is 2
替换
**示例1:**把test文件中的root替换成tankzhang,只不过只替换一次即终止在这一行的操作,并转到下一行
[wsh@test ~ ✔]$ sed 's/root/tankzhang/' test|grep tankzhang
tankzhang:x:0:0:root:/root:/bin/bash
**示例2:**把test文件中的root全部替换成tankzhang。字母g是global的缩写。
[wsh@test ~ ✔]$ sed 's/root/tankzhang/g' test |grep tankzhang
tankzhang:x:0:0:tankzhang:/tankzhang:/bin/bash
**示例3:**加了-n和p后表示只打印那些发生替换的行(部分替换),下面的例子,不需要使用grep命令
[wsh@test ~ ✔]$ sed -n 's/root/tankzhang/p' test
tankzhang:x:0:0:root:/root:/bin/bash
**示例4:**加了-n和pg后表示只打印那些发生替换的行(全部替换)
[wsh@test ~ ✔]$ sed -n 's/root/tankzhang/gp' test
tankzhang:x:0:0:tankzhang:/tankzhang:/bin/bash
**示例5:**在第二行到第八行之间,替换以zhang开头的行,用ying来替换,并显示替换的行
[wsh@test ~ ✔]$ sed -ne '2,8s/^zhang/ying/gp' test
yingy:x:1000:100:,,,:/home/zhangy:/bin/bash
示例6: 从以zhang开头的行开始,到匹配Po的行结束,在他们之间进行替换
[wsh@test ~ ✔]$ sed -ne '/^zhang/,/Po/ s/zhang/ying/gp' test
yingy:x:1000:100:,,,:/home/yingy:/bin/bash
ba:x:1002:1002::/home/yingy:/bin/bash
@yingying:*:1004:1004::/home/test:/bin/bash
替换中的分隔符可以自定义,默认是/。
示例7: 自定义替换分隔符为 #。
[wsh@test ~ ✔]$ sed -n 's#root#hello#gp' test
hello:x:0:0:hello:/hello:/bin/bash
其他替换
[wsh@test ~ ✔]$ cat test1.txt
my my my my my
my my my my my
my my my my my#替换每行第3个my
[wsh@test ~ ✔]$ sed "s/my/your/3" test1.txt
my my your my my
my my your my my
my my your my my#只替换第3行的第1个my
[wsh@test ~ ✔]$ sed "3s/my/your/1" test1.txt
my my my my my
my my my my my
your my my my my#只替换每行的第3个及以后的my
[wsh@test ~ ✔]$ sed 's/my/your/3g' test1.txt
my my your your your
my my your your your
my my your your your
分隔符;和-e选项
需要执行多个sed处理命令时,用分号分开,或者使用 -e 选项。
示例:
- 在第2行到第8行之间,替换以zhang开头的行,用ying来替换
- 在第5行到第10行之间,用goodbay来替换dbus,并显示替换的行
[wsh@test ~ ✔]$ cat test | sed -n '2,8s/^zhang/ying/gp;5,10s#dbus#goodbay#gp'
yingy:x:1000:100:,,,:/home/zhangy:/bin/bash
goodbay:x:81:81:System message bus:/:/bin/false[wsh@test ~ ✔]$ cat test | sed -ne '2,8s/zhang/ying/gp' -ne '5,10s#dbus#goodbay#gp'
yingy:x:1000:100:,,,:/home/yingy:/bin/bash
goodbay:x:81:81:System message bus:/:/bin/false
插入
a 在匹配行下面插入新行
将要插入的东西,插入到匹配行的下面
[wsh@test ~ ✔]$ sed '/root/a====aaaa====' test
root:x:0:0:root:/root:/bin/bash
====aaaa====
bin:x:1:1:bin:/bin:/bin/false
......
i 在匹配行上面插入新行
将要插入的东西,插入到匹配行的上面
[wsh@test ~ ✔]$ sed '/root/i====iiii====' test
====iiii====
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
......
删除
作用
- d,删除模式空间所有记录。
- D,删除模式空间第一行记录。
语法
d 格式:[address1[,address2]]d
D 格式:[address1[,address2]]D
address1和address2分别是 起始地址 和 结束地址,可以是 行号或 模式字符串。address1和address2都是可选参数,可以都不填,这时候就是删除所有行,从文件的开头到文件结束。- 如果存在一个,那么就是删除 单行。也就是只删除
address1指定的那行。 d命令仅从 模式缓冲区 中删除行,也就是该行不会发送到输出流,原始文件保持不变。
d 删除 示例
示例1: 删除1,14行
[wsh@test ~ ✔]$ sed -e '1,14d' test
@zhangying:*:1004:1004::/home/test:/bin/bash
policykit:x:102:1005:Po
示例2: 删除4以后的行,包括第4行,把$当成最大行数就行了。
[wsh@test ~ ✔]$ sed -e '4,$d' test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
示例3: 删除包括false的行,或者包括bash的行,别忘了加\
[wsh@test ~ ✔]$ sed -e '/\(false\|bash\)/d' test
policykit:x:102:1005:Po
示例4: 删除从匹配root的行,到匹配以test开头的行,中间的行
[wsh@test ~ ✔]$ sed -e '/root/,/^test/d' test
@zhangying:*:1004:1004::/home/test:/bin/bash
policykit:x:102:1005:Po
D 删除 示例
删除当前模式空间开端至\n的内容,放弃之后的命令,对剩余模式空间继续执行sed。
示例1:读取最后一行内容
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5' | sed 'N;D'
# 输出内容
This is 5
说明:
- 读取
This is 1,执行N,得出This is 1\nThis is 2\n,执行D。 - 读取
This is 3,执行N,得出This is 3\nThis is 4\n,执行D。 - 读取
This is 5,执行N,后续无内容,读取失败,放弃后续命令,正常打印This is 5
示例2:删除偶数行
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5' | sed 'n;D'# 输出内容
This is 1
This is 3
This is 5
说明:
- 读取
This is 1,执行n,This is 2\n覆盖This is 1\n,执行D删除This is 2\n,This is 1\n没有删除,正常打印This is 1。 - 读取
This is 3,执行n,This is 4\n覆盖This is 3\n,执行D删除This is 4\n,正常打印This is 3。 - 读取
This is 5,执行n,后续无内容,读取失败,放弃后续命令,正常打印This is 5
打印行号
=
示例1:
[wsh@servera ~]$ sed '=' test
1
root:x:0:0:root:/root:/bin/bash
2
bin:x:1:1:bin:/bin:/bin/false
3
daemon:x:2:2:daemon:/sbin:/bin/false
......
[wsh@servera ~]$ sed '=' test| sed 'N;s/\n/:/'
1:root:x:0:0:root:/root:/bin/bash
2:bin:x:1:1:bin:/bin:/bin/false
3:daemon:x:2:2:daemon:/sbin:/bin/false
......
# 使用N将行号与原本行合为一行以便于用 ':' 替换换行符 '\n'
大小写转换
y 字符
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3
This is 4
This is 5' | sed 'y/si/SI/'# 将小写字母s和i转换成大写字母S和I
ThIS IS 1
ThIS IS 2
ThIS IS 3
ThIS IS 4
ThIS IS 5
读取
示例: 读取test2的内容,并将其写入到匹配行的下面
[wsh@test ~ ✔]$ vim test2
=============
-------------
+++++++++++++[wsh@test ~ ✔]$ sed -e '/^root/r test2' test
root:x:0:0:root:/root:/bin/bash
=============
-------------
+++++++++++++
bin:x:1:1:bin:/bin:/bin/false
......
写入
w 写入
将模式空间中记录写入到文件中。
示例1: 将root开头的行,写入test3中
[wsh@test ~ ✔]$ sed -n '/^root/w test3' test
[wsh@test ~ ✔]$ cat test3
root:x:0:0:root:/root:/bin/bash
W 写入
将模式空间中第一条记录写入到文件中。
示例: 写入记录
# 小写w写入
[wsh@test ~ ✔]$ vim scripts
1{
N
w write.log
}
[wsh@test ~ ✔]$ sed -n -f scripts test# 小写w写入包含模式中所有行
[wsh@test ~ ✔]$ cat write.log
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false# 大写W写入只包含模式中第一行
[wsh@test ~ ✔]$ vim scripts
1{
N
W write.log
}
[wsh@test ~ ✔]$ sed -n -f scripts test
[wsh@test ~ ✔]$ cat write.log
root:x:0:0:root:/root:/bin/bash
更改
整行替换。
示例:root开头行替换出hello
[wsh@test ~ ✔]$ sed '/^root/chello' test
hello
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
......# 等效下面命令
[wsh@test ~ ✔]$ sed 's/^root.*/hello/' test
多命令执行 {} 和-f 选项
对匹配的内容执行多个命令。
示例1: 打印前两行
[wsh@test ~ ✔]$ echo 'This is 1
This is 2
This is 3' | sed -n '1{N;p}'# 输出结果
This is 1
This is 2
示例2: 替换并打印
[wsh@test ~ ✔]$ sed -n '1,5{s/^root/hello/;p}' test
hello:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
mail:x:8:12:mail:/var/spool/mail:/bin/false
ftp:x:14:11:ftp:/home/ftp:/bin/false
示例3: 多个命令写成脚本
# 小写w写入
[wsh@test ~ ✔]$ vim scripts
1{
N
w write.log
}
[wsh@test ~ ✔]$ sed -n -f scripts test# 小写w写入包含模式中所有行
[wsh@test ~ ✔]$ cat write.log
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
退出
示例1:打印前2行
[wsh@test ~ ✔]$ sed '2q' test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
示例2: 3q的意思是到第三行的时候,退出
[wsh@test ~ ✔]$ sed -e 's/bin/tank/g;3q' test
root:x:0:0:root:/root:/tank/bash
tank:x:1:1:tank:/tank:/tank/false
daemon:x:2:2:daemon:/stank:/tank/false# 等效于
[wsh@test ~ ✔]$ sed -ne '1,3s/bin/tank/gp' test
root:x:0:0:root:/root:/tank/bash
tank:x:1:1:tank:/tank:/tank/false
daemon:x:2:2:daemon:/stank:/tank/false
! 匹配取反
表示后面的命令作用于所有没有被选定的行。
示例:打印非root开头的行
[wsh@test ~ ✔]$ sed -n '/^root/!p' test
正则用法
示例1: sed中正则表达式需要转移字符\,例如,用括号要加上 \ ,不然会报错。
[wsh@test ~ ✔]$ sed -ne '2,8s/^\(zhangy\)/zhangying/gp' test
zhangying:x:1000:100:,,,:/home/zhangy:/bin/bash
**示例2:**使用 -r 选项不需要转义字符。
[wsh@test ~ ✔]$ sed -nre '2,8s/^(zhangy)/zhangying/gp' test
zhangying:x:1000:100:,,,:/home/zhangy:/bin/bash
子串使用
- (),用于匹配子串
- \N,N是个数字,代表前面匹配的第N个子串
- &,代表匹配的所有内容
[wsh@test ~ ✔]$ egrep 'ba.*zhang' test
ba:x:1002:1002::/home/zhangy:/bin/bash[wsh@test ~ ✔]$ sed -nre 's/(ba).*(zhangy)/\1/gp' test
ba:/bin/bash[wsh@test ~ ✔]$ sed -nre 's/(ba).*(zhangy)/&,haha/gp' test
ba:x:1002:1002::/home/zhangy,haha:/bin/bash
g G h G
前文我们讨论过:
-
pattern space空间是 sed 在内存中开辟的一个私有的存储区域。 -
sed 还在内存上开辟了另一个私有的空间
hold space用于保存处理后的数据以供以后检索。每一个周期执行结束,sed 会清空pattern space内容,但hold space内容并不会清空。hold space用于存储处理后数据,sed 命令并不会对这里的数据处理。这样,当 sed 需要之前处理后的数据时,可以随时从
hold space读取。
我们可以这样理解:
- pattern space,看成是一个流水线,所有的动作都是在“流水线”上执行的。
- hold space,是一个“仓库”,“流水线”上的东西存存放到这里。
下面我们来解释以下指令:
- g:清除pattern space里的内容,拷贝hold space中的内容到pattern space中
- G:将hold space中的内容append到pattern space\n后
- h:清除hold space里的内容,拷贝pattern space中的内容到hold space中
- H:将pattern space中的内容append到hold space\n后
**示例1:**在每一行后面增加一空行
[wsh@test ~ ✔]$ sed 'G' test
root:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/bin/falsedaemon:x:2:2:daemon:/sbin:/bin/false
......
示例2: h的作用是将找到的行,放到一个缓存区,G 的作用是将缓存区中的内容放到最后一行
[wsh@test ~ ✔]$ sed -e '/root/h' -e '$G' test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
......
policykit:x:102:1005:Po
root:x:0:0:root:/root:/bin/bash
示例3: 行替换,用匹配root的行,来替换匹配zhangy的行
[wsh@test ~ ✔]$ sed -e '/root/h' -e '/zhangy/g' test
root:x:0:0:root:/root:/bin/bash
......
&nobody:$:99:99:nobody:/:/bin/false
root:x:0:0:root:/root:/bin/bash
http:x:33:33::/srv/http:/bin/false
......
aaa:x:1001:1001::/home/aaa:/bin/bash
root:x:0:0:root:/root:/bin/bash
test:x:1003:1003::/home/test:/bin/bash
root:x:0:0:root:/root:/bin/bash
policykit:x:102:1005:Po
列表
l,列表不能打印字符的清单。
sed 命令模式中命令
- #,把注释扩展到下一个换行符以前。