Week 1
1.1 K-means
Cluster centroid
- K-means 是无监督学习中聚类算法的一种,核心在于更新聚类质心;
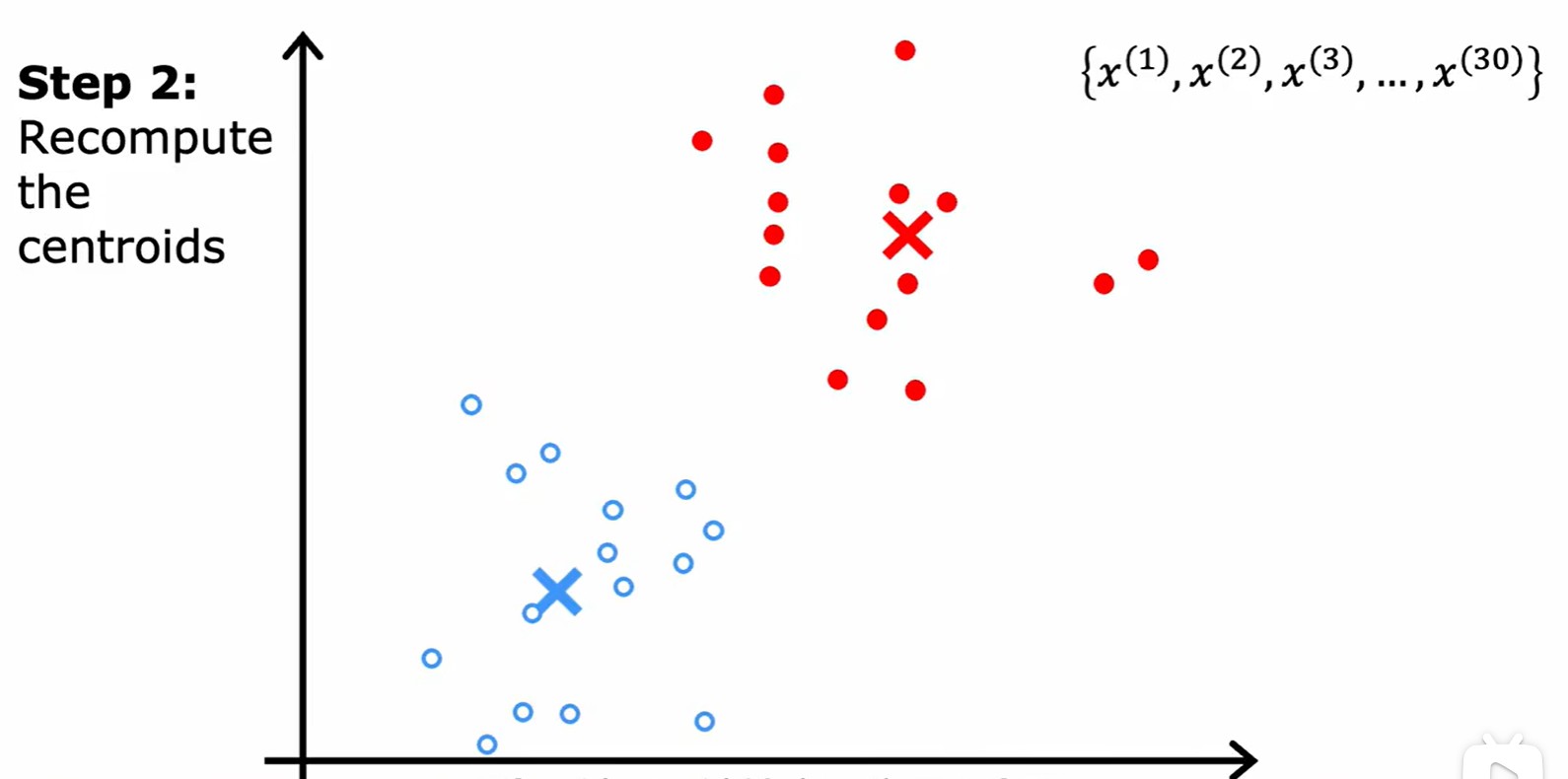
- 首先将每个点分配给几个聚类质心,取决于那些点离哪个质心更近;然后将几个聚类质心移动到分配给他的所有点的平均值,不断重复,直到没有点更改类别;
K-means algorithm
- 如果一个簇里面没有点分配给他,最常见的方法就是消除一个簇;
- 总的来说,减少 cost 的两步:就近分配中心点,中心点移动到平均点;
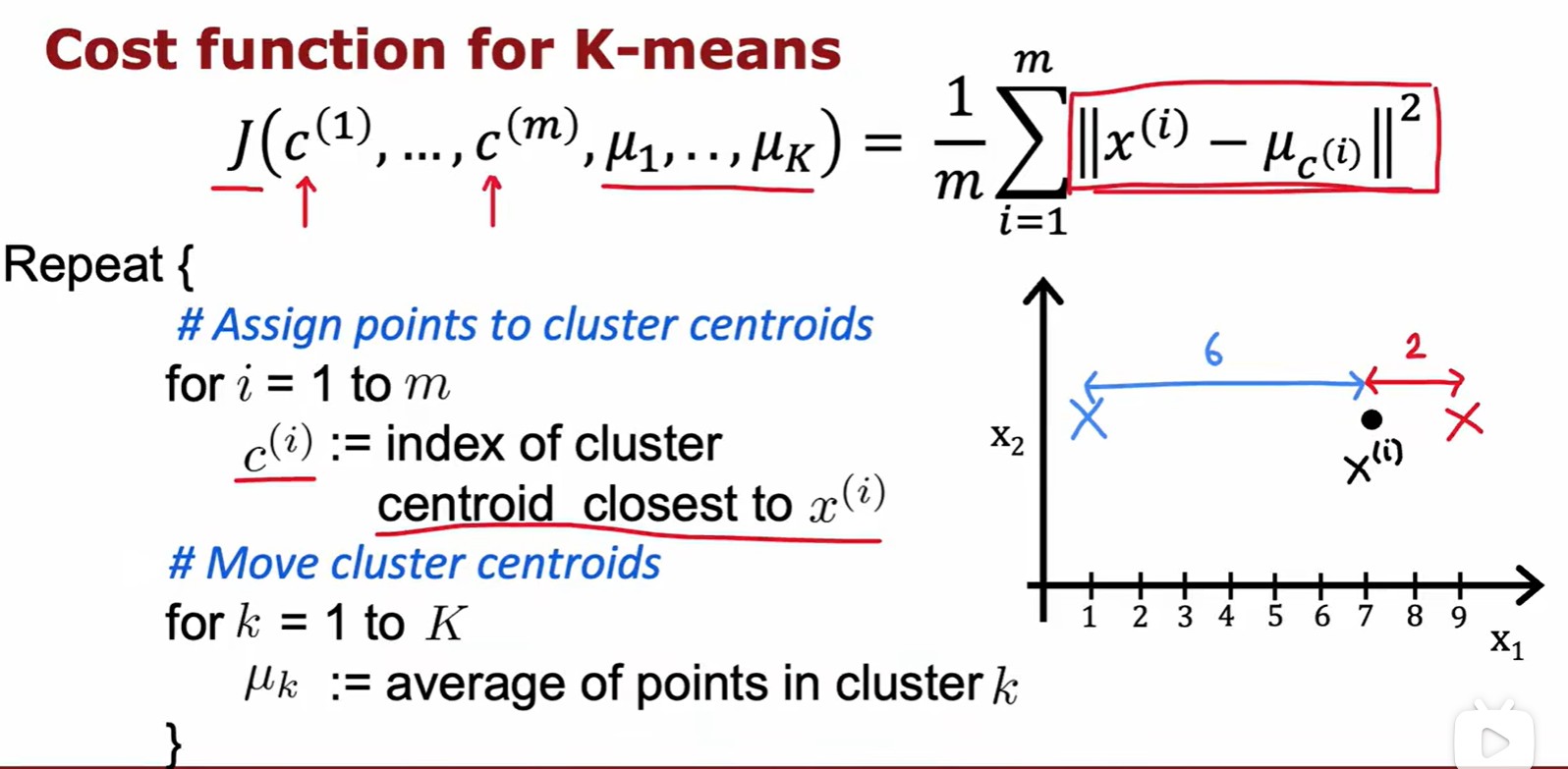
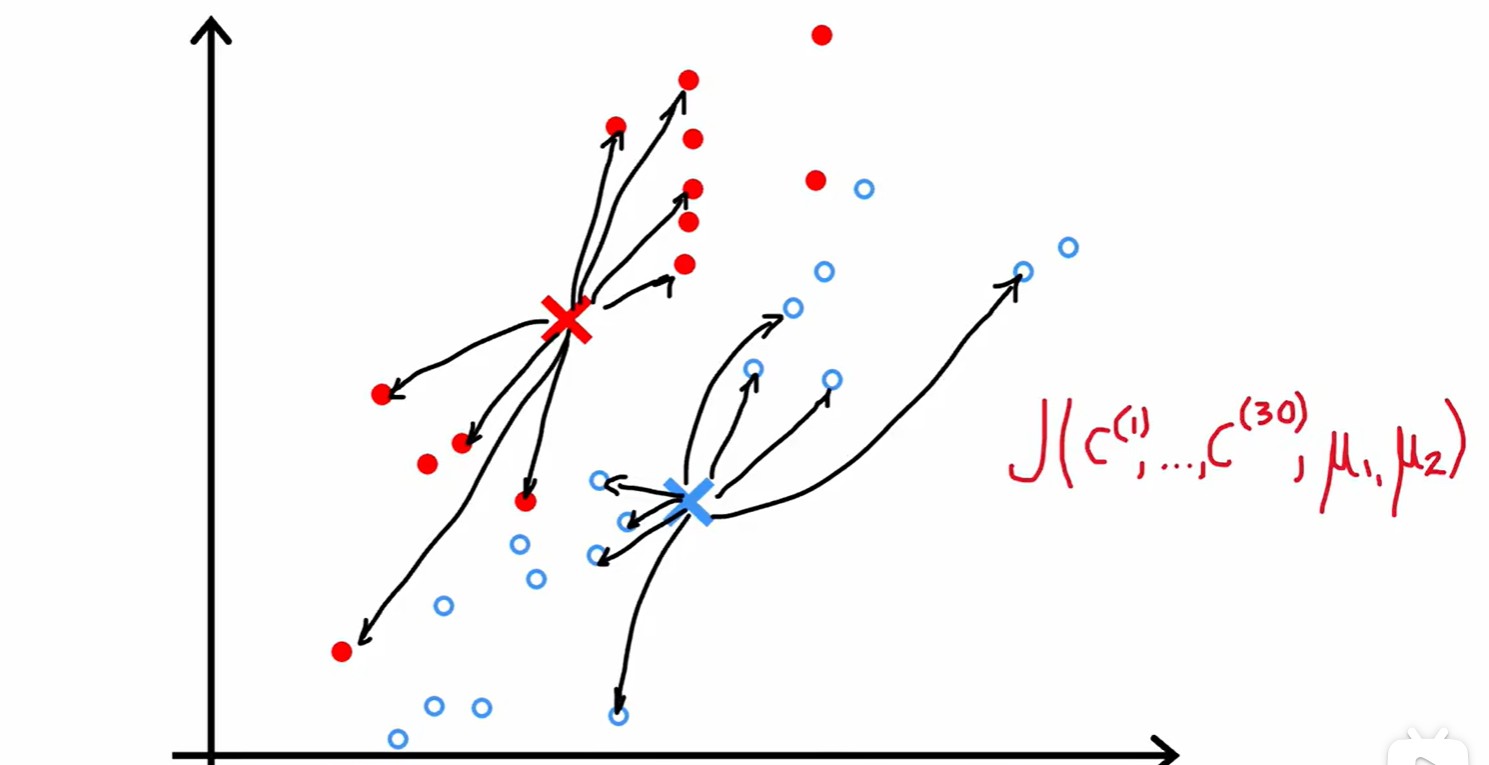
Optimization objective
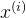 指的每个点,
指的每个点, 指的每个点被分配给的簇,
指的每个点被分配给的簇,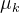 是簇质心位置,
是簇质心位置, 指 所属簇的质心位置;
指 所属簇的质心位置;- 损失 J = 每个数据到其最近质心的距离平方的平均值;

- 这个损失函数还有一个别名:失真函数(distortion funtion);
Initializing K-means
- 更常见的初始化质心位置的方法:将质心分配到几个训练数据的位置上;
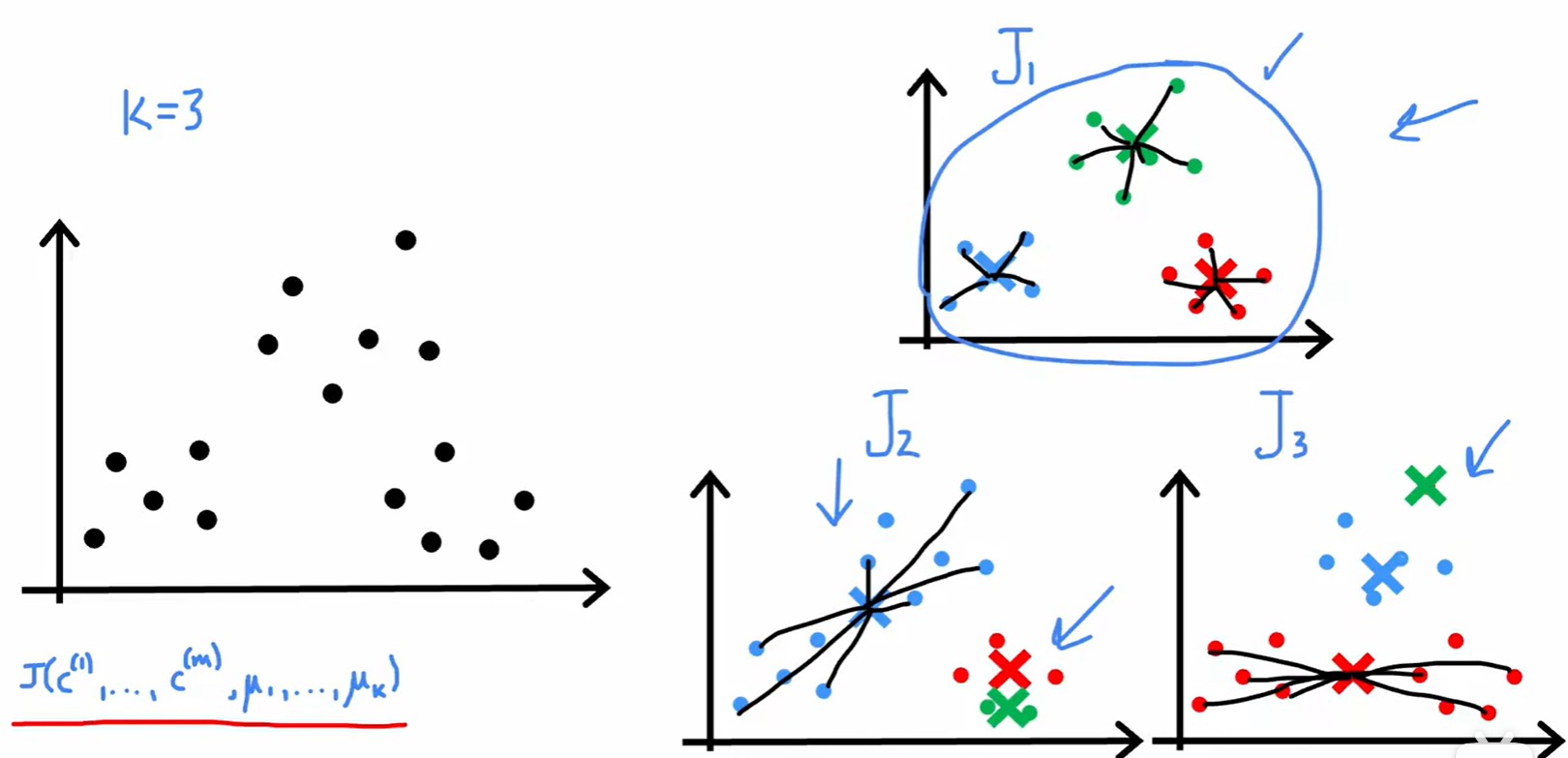
- 在经过多次的随机初始化后,选取 J 最低的初始化方式;

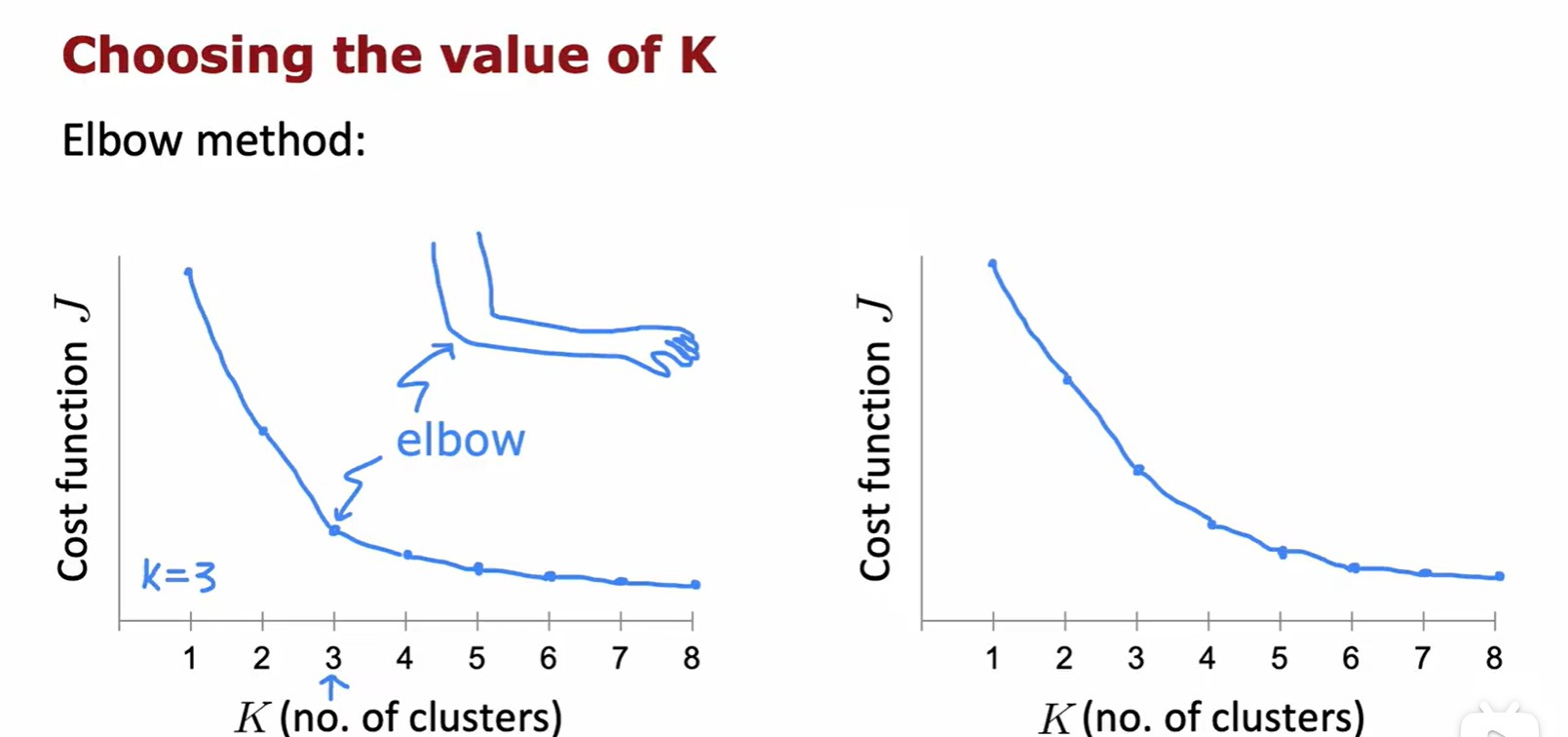
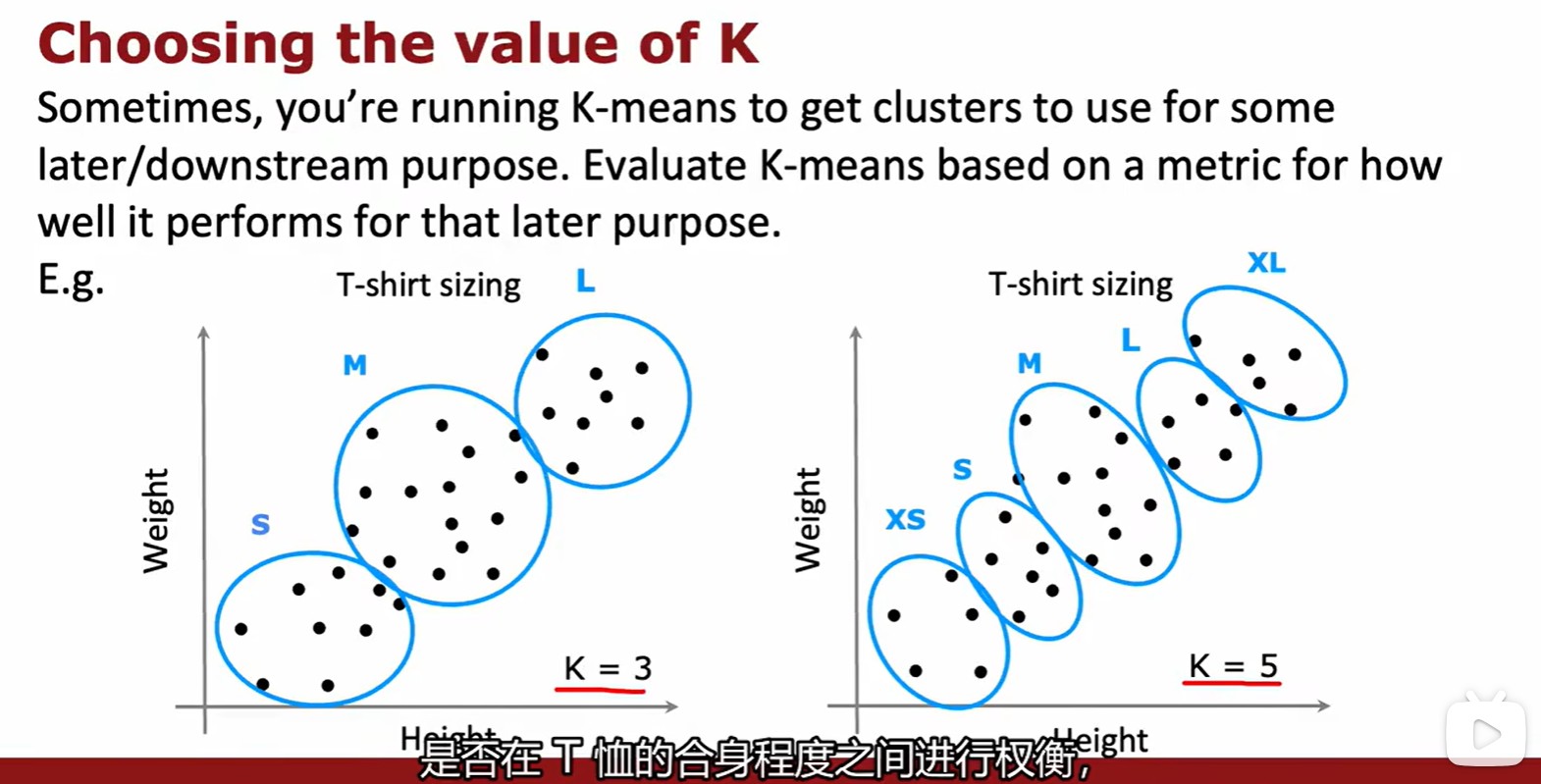
Choosing the value of K
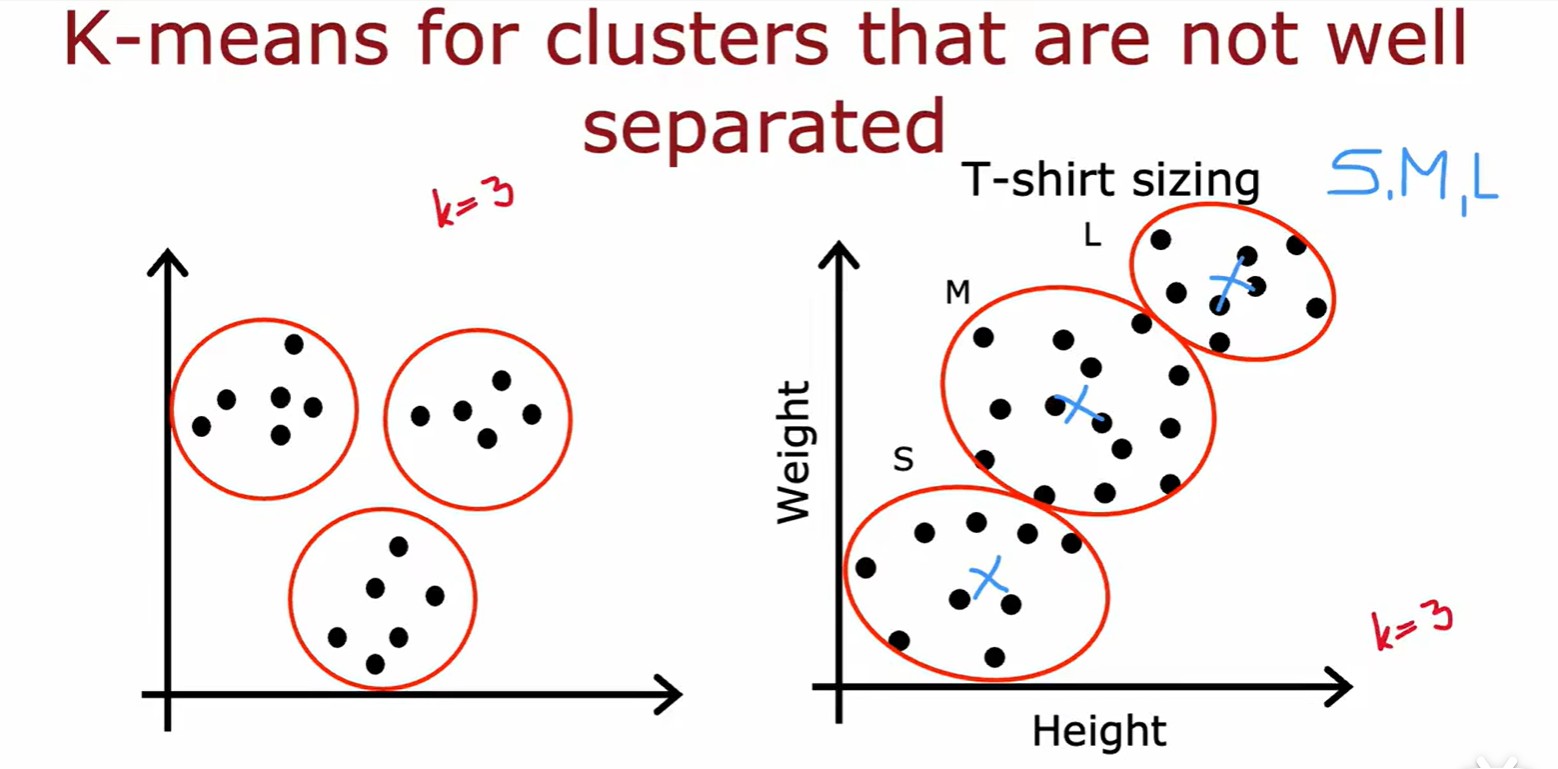
- 如何选择聚类的数量 K,需要平衡 K 与 J 的关系,但是一般不会为了降低 J 而增加 K;
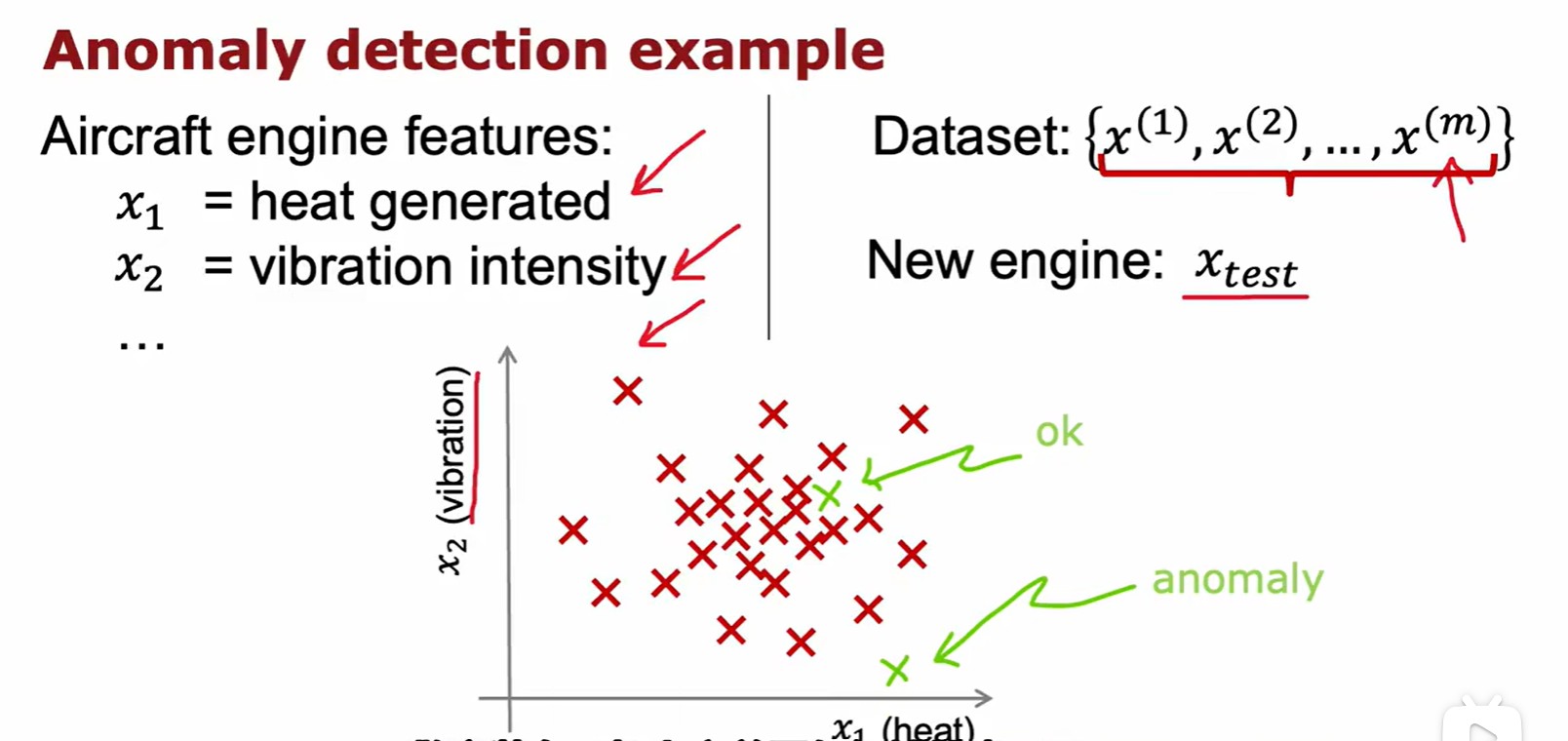
1.2 Anomaly Detection
Example and Solution
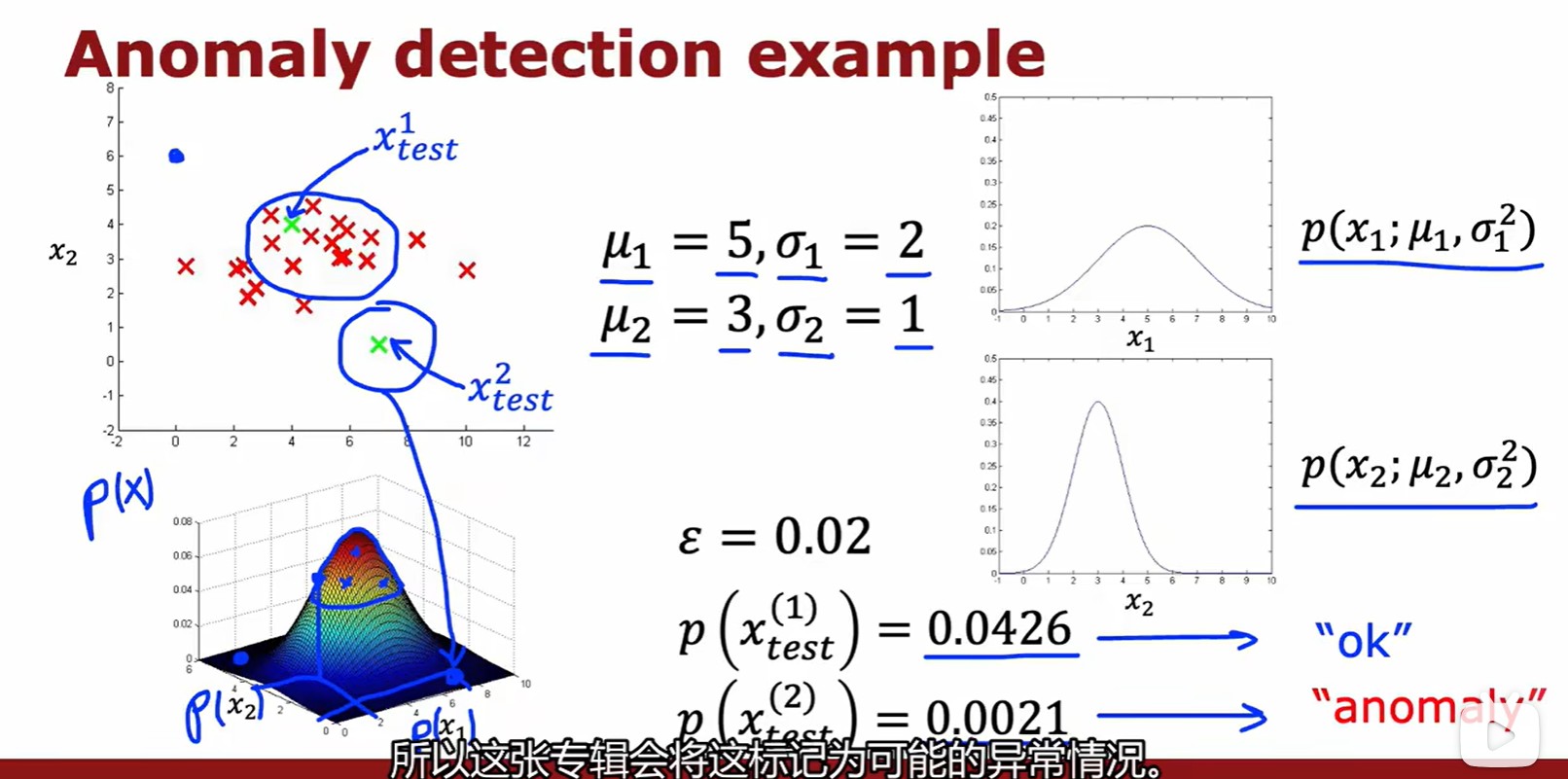
- 这里记录的数据为飞机引擎温度与振动强度,越接近密集区的数据越正常,越偏离越异常;
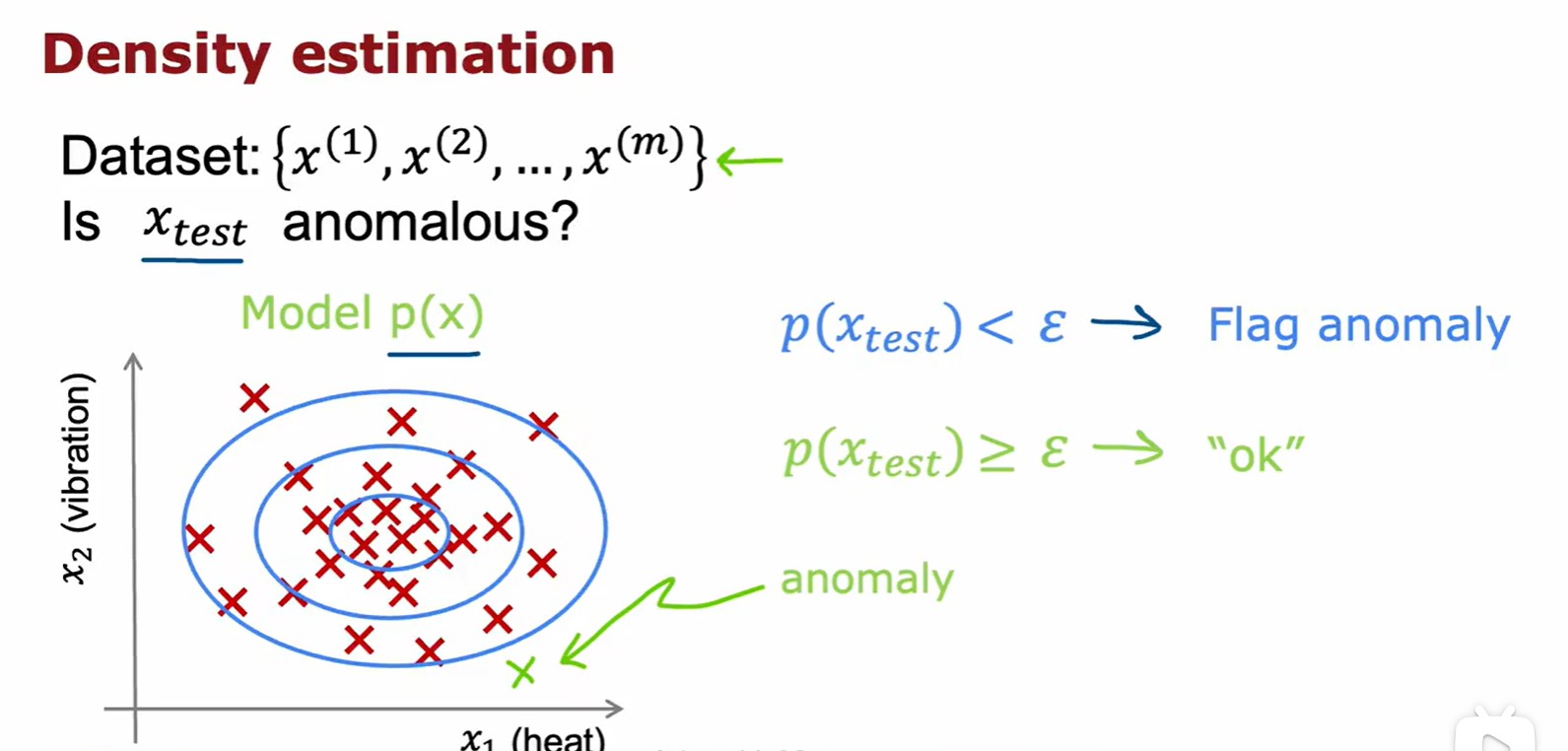
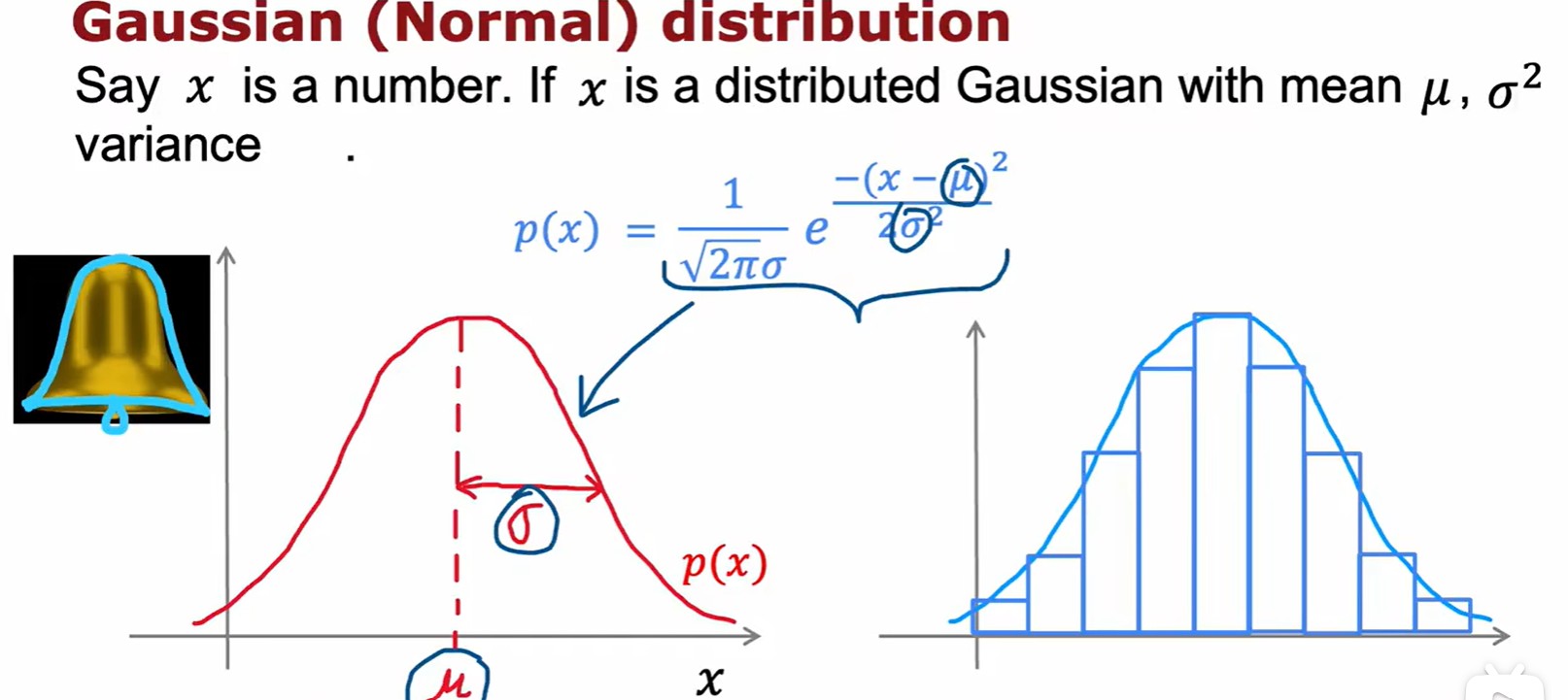
Gaussion/Normal Distribution
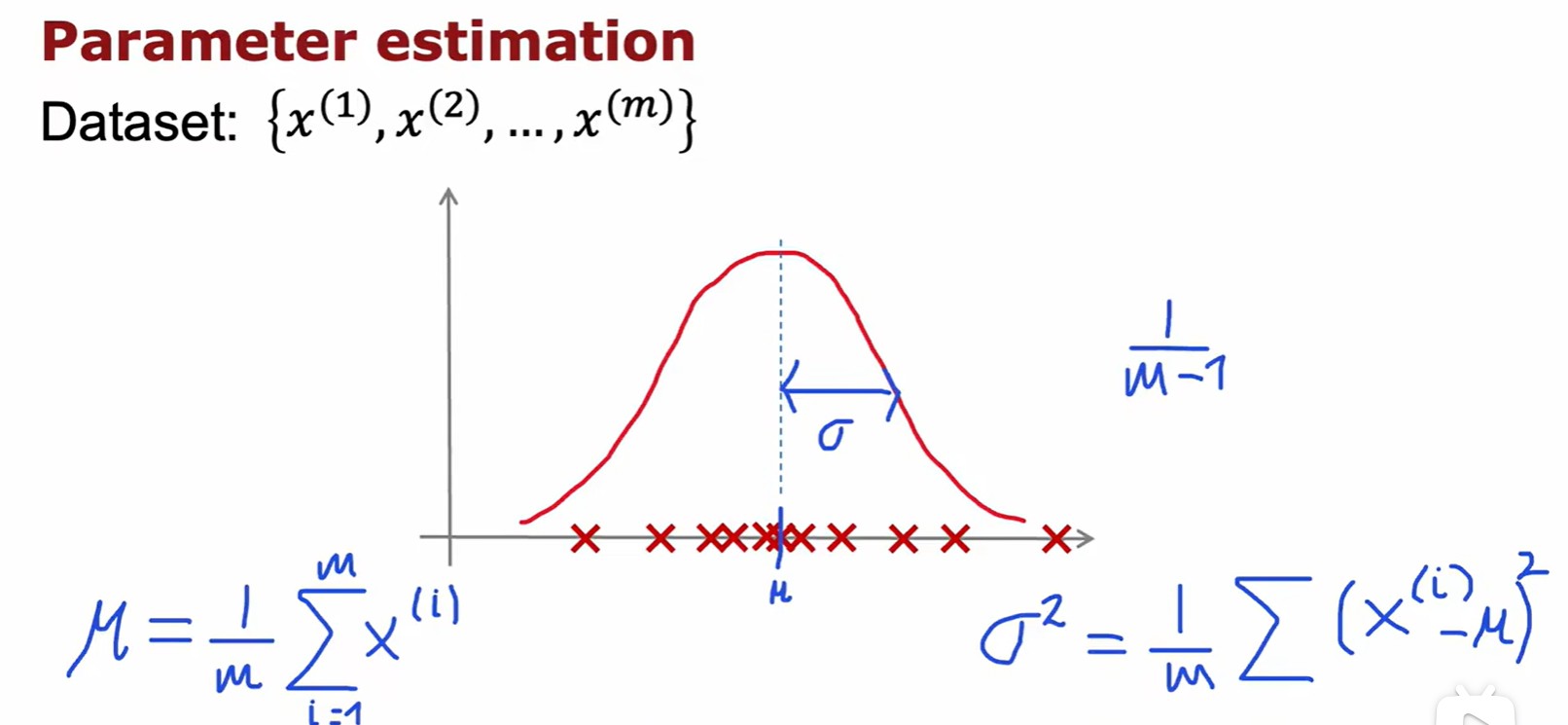
Algorithm
- 概率密度函数不表示概率,但是概率密度函数的值可以表示取这个值附近的点的概率;
- 计算每个特征的概率密度,然后累乘,最后比较;

- 二维的正态分布如果是独立的,那么联合概率分布就等于两个相乘;
- 将计算出的概率密度与预先设定好的
 相比较,如果小于它,则为异常;
相比较,如果小于它,则为异常;
Evaluating system
- 评估系统:设立交叉验证集和测试集,或者只保留交叉验证集,训练集不包含异常数据;
- 相当于用无标注的训练集训练出一个特定均值和方差的正态分布,并默认两端的极值是不正常的。再通过测试集来调整阈值,使得阈值之上的都是正常的,阈值之外的都是不正常的。

- 利用交叉验证集和倾斜数据集里的F1 score计算出最合适的 ;

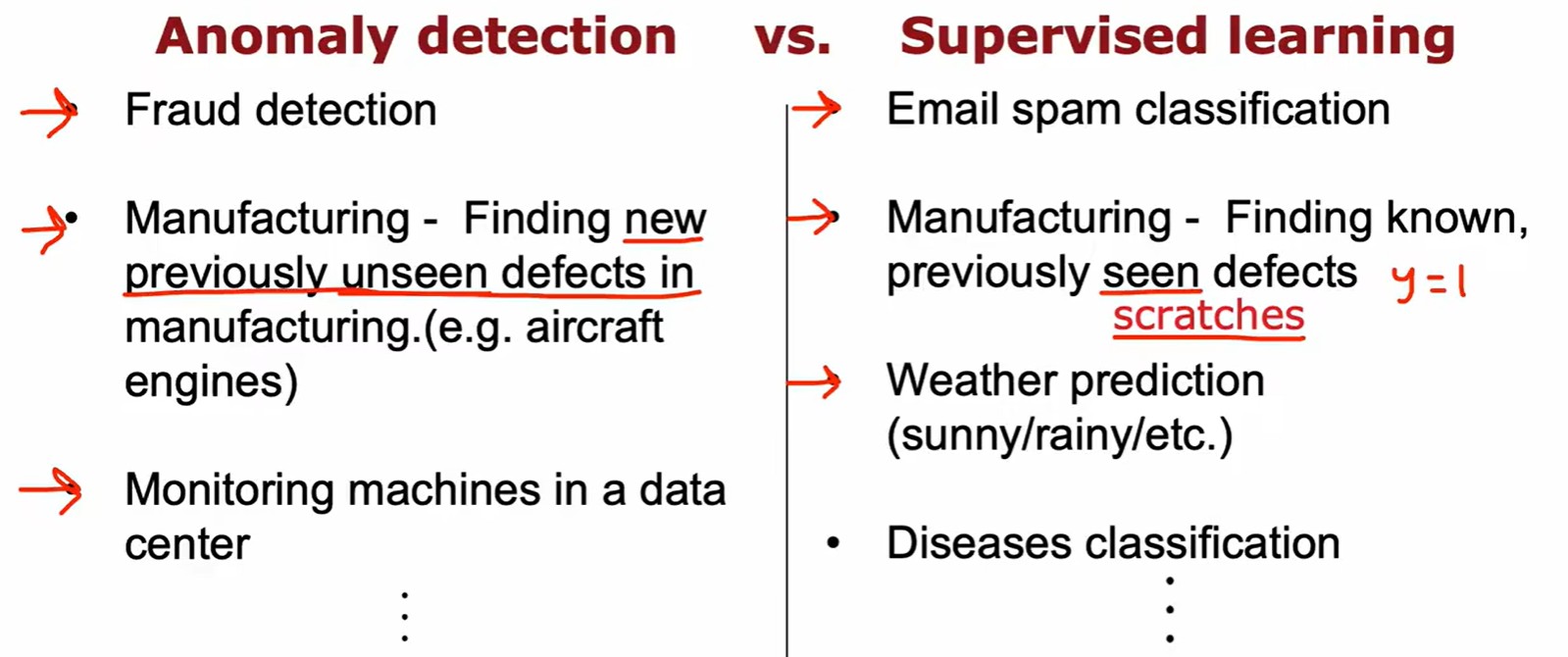
Compared with supervised learning
- 异常检测面对未知异常情况,监督学习面对已知异常的所有可能;
- 本质区别:一个反向排除,一个正向学习;
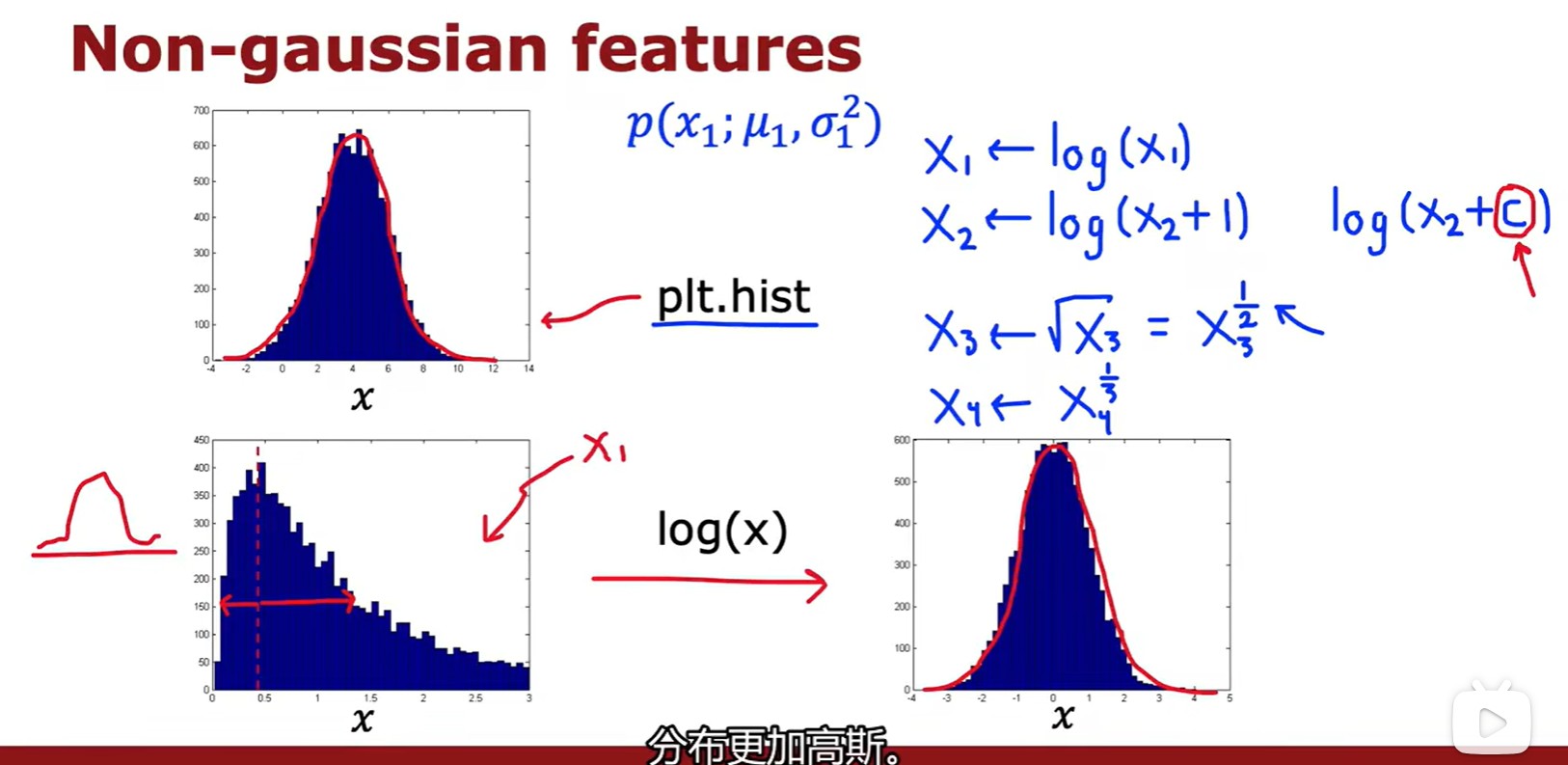
Choosing featrues
- 选择更接近高斯分布的特征集,或者将其转化为类似高斯分布的特征集;
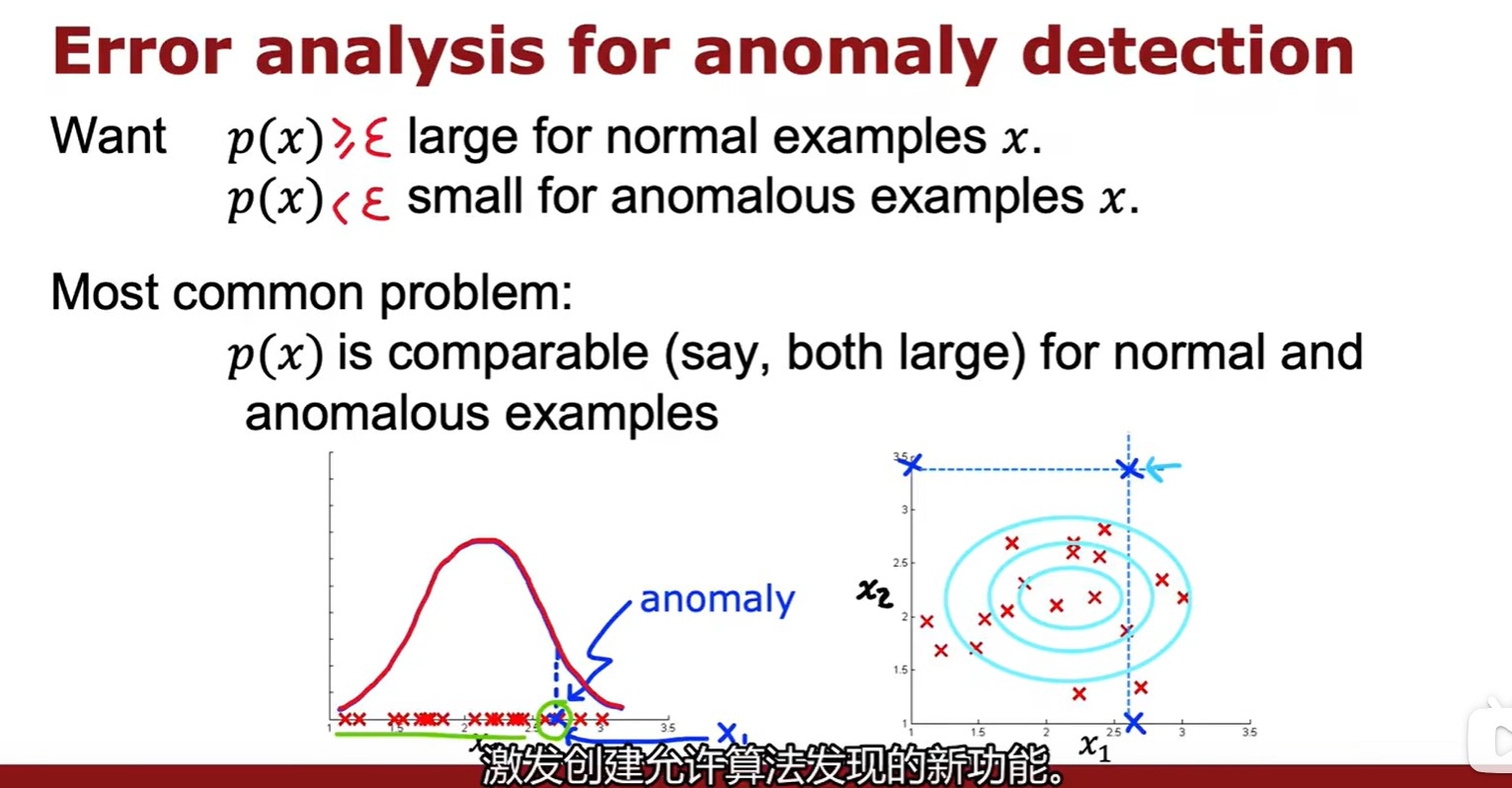
- 如果已有特征无法分辨该数据是否异常(计算得出是异常,但与其他示例又十分接近),则试图找出是什么让我认为是一个异常,由此识别出新特征;

Week 2
2.1 Recommender System
Making recommendations
- 电影评分:r(i, j) 表示用户 j 是否对电影 i 进行评分,y(i, j) 表示用户 j 对电影 i 的评分;
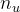 为用户数,
为用户数, 为电影数;
为电影数;
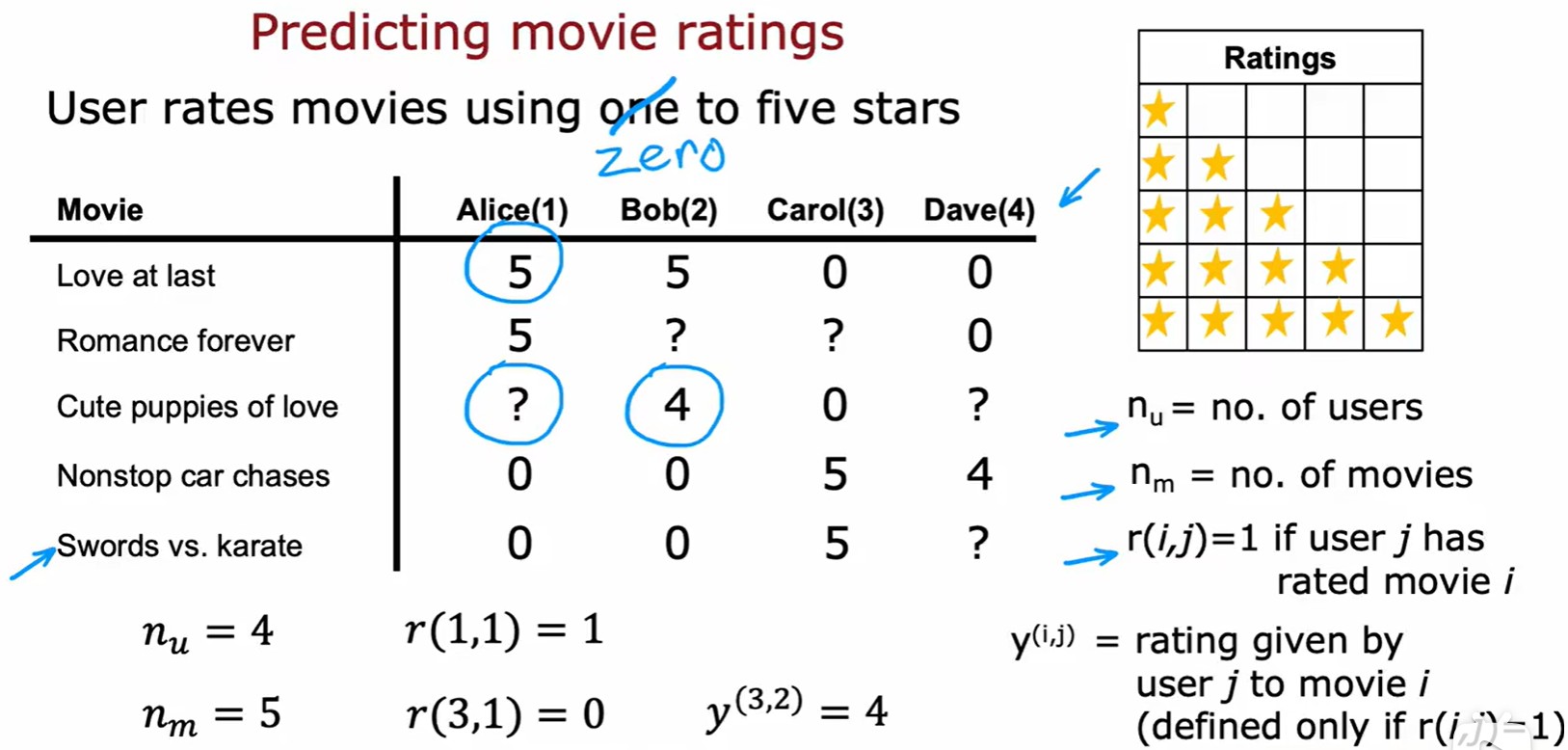
Using featrues
 表示用户 j 有评分的电影数量,注意这里求和的是 r = 1 的用户,就是有评分的数据;;
表示用户 j 有评分的电影数量,注意这里求和的是 r = 1 的用户,就是有评分的数据;;- 计算损失:

Collaborative filtering algorithm
- 协同过滤算法:特征向量未知,但是参数 w, b 已知;
- 也就是说我们可以通过用户对电影的评分然后计算出参数 w 和 b。然后计算出 w 和 b 后,就可以通过数据来预测对未知电影特征进行评分;
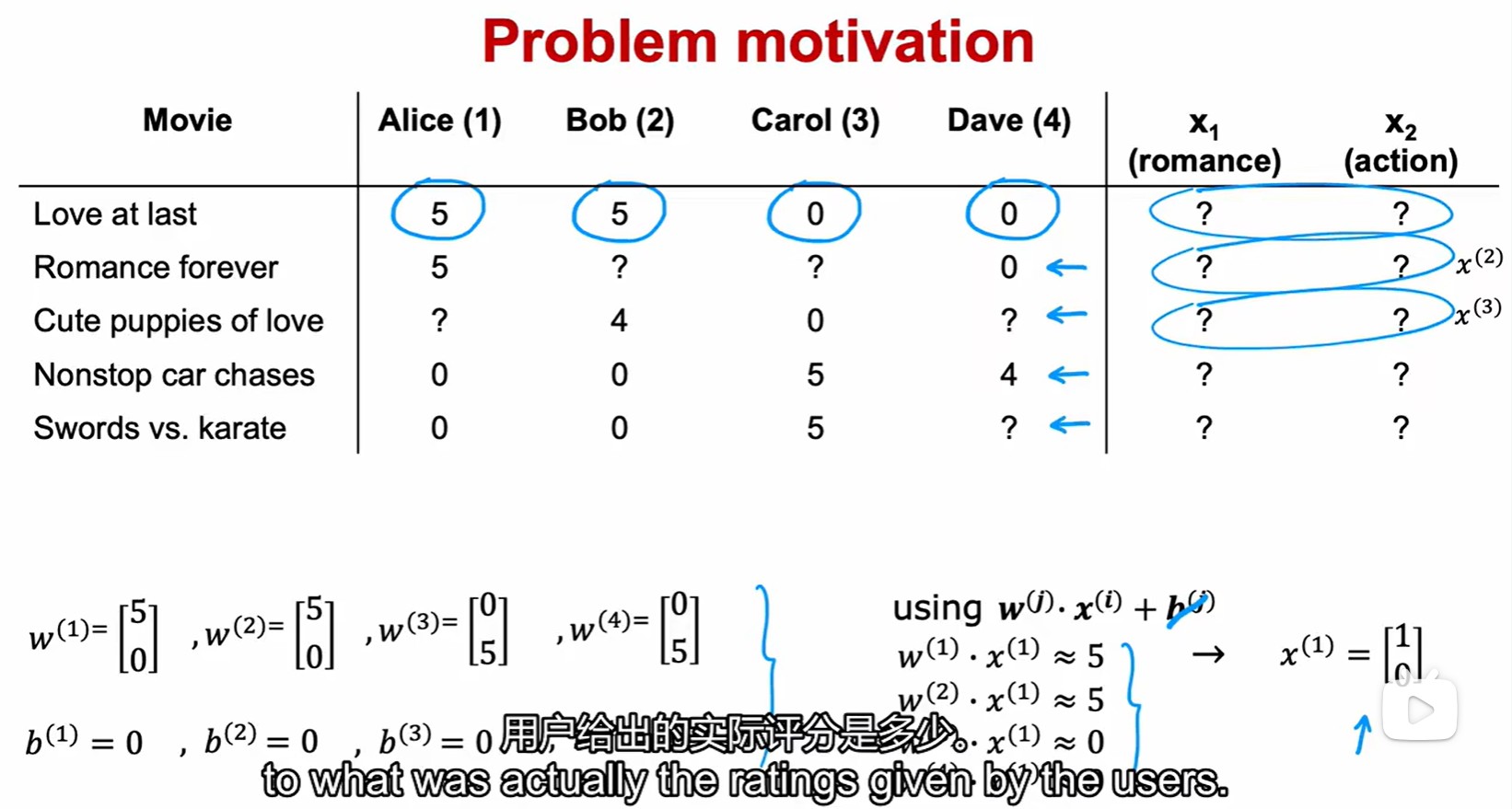
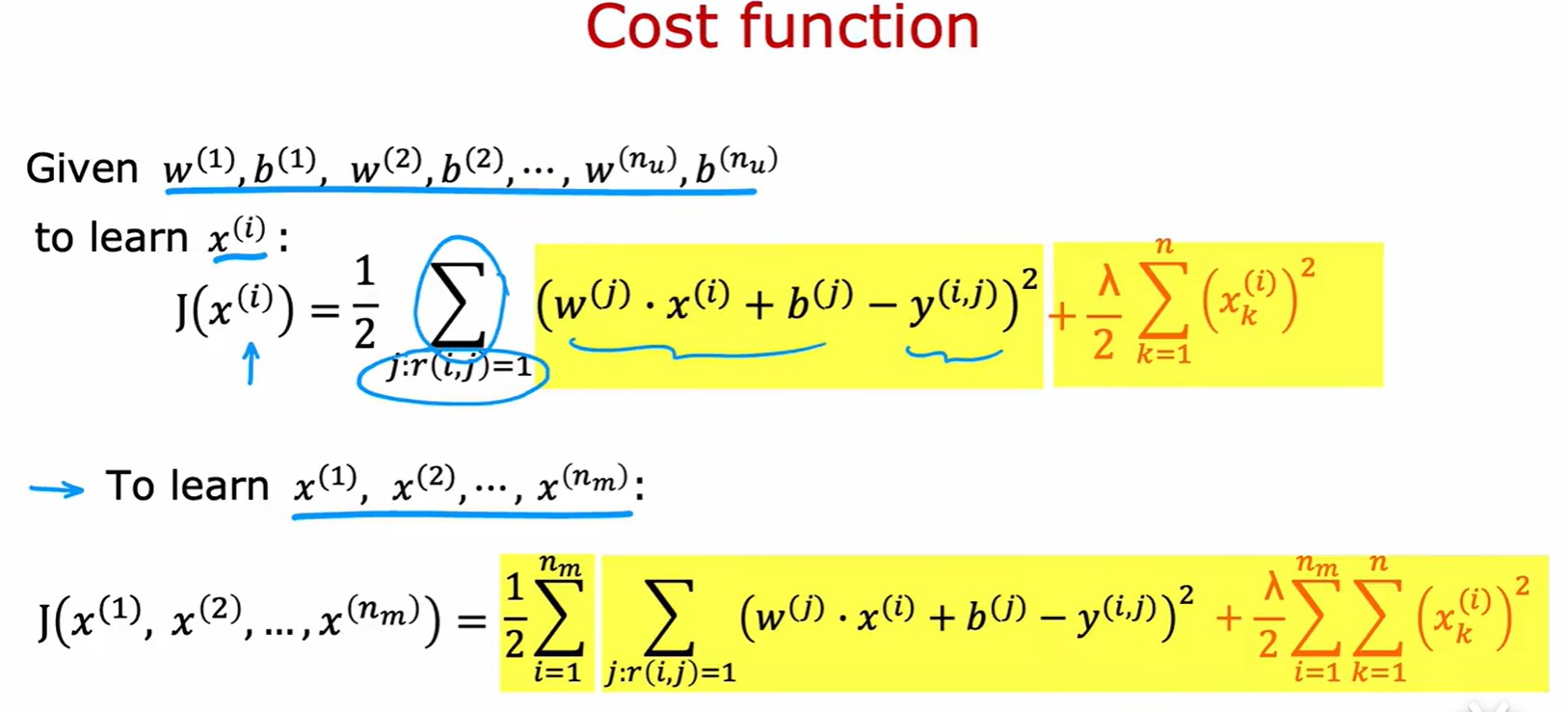
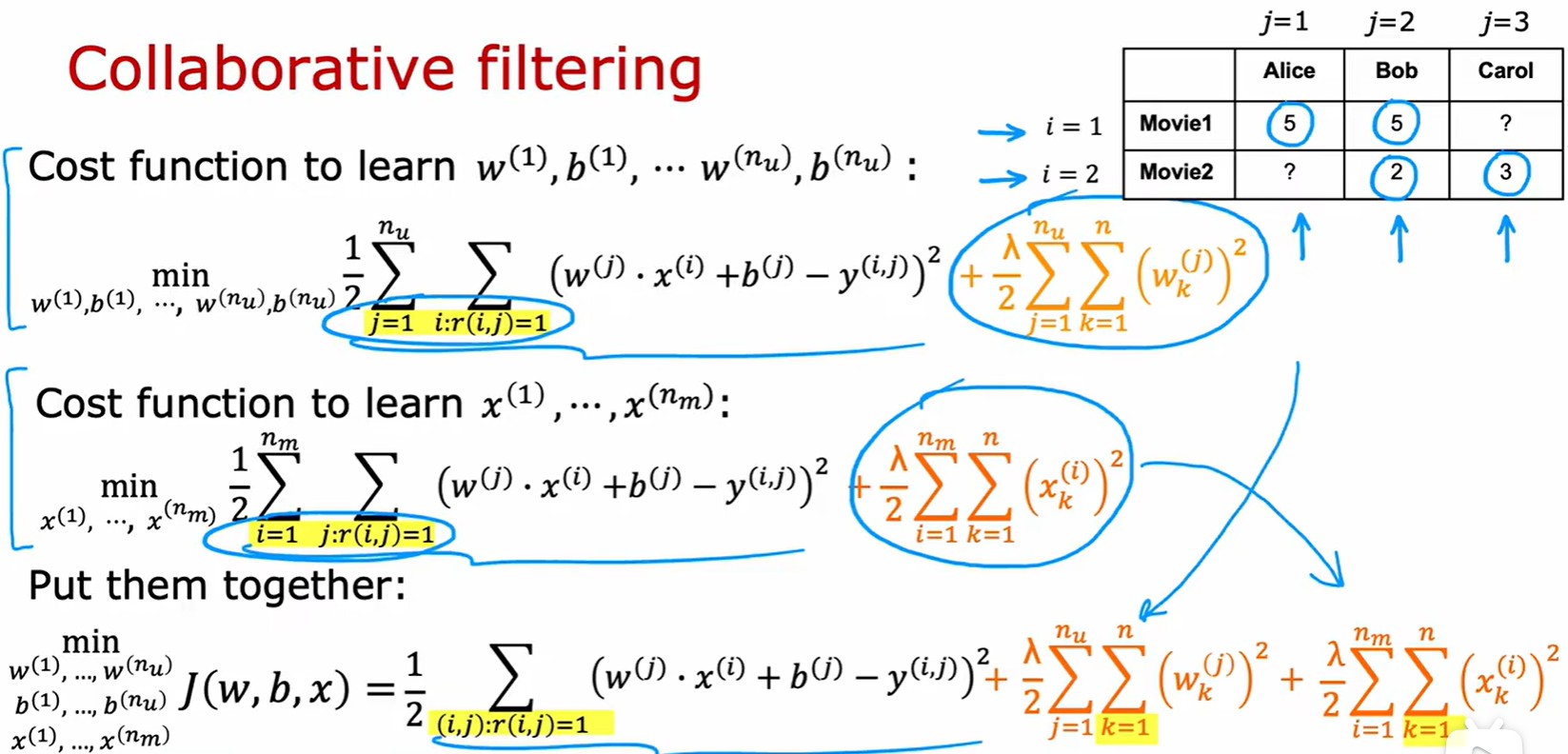
- 结合两个损失公式,得到总体成本函数(类似线性回归,但是包含三个变量):
- 这里的求和项只是变了一种形式而已。第一个表示先对列求和,在对行求和。第二个则表示先对行求和,再对列求和。最后这个再形式上化简了,没有行和列的概念。直接对每个(i,j)对求和;
Binary labels
- 二进制标签应用:1代表看到了且参与,0代表看到了但是未参与,?代表没有看到;

- 计算损失(类似 logistic 回归,只是包含三个参数):

2.2 Mean Normalization
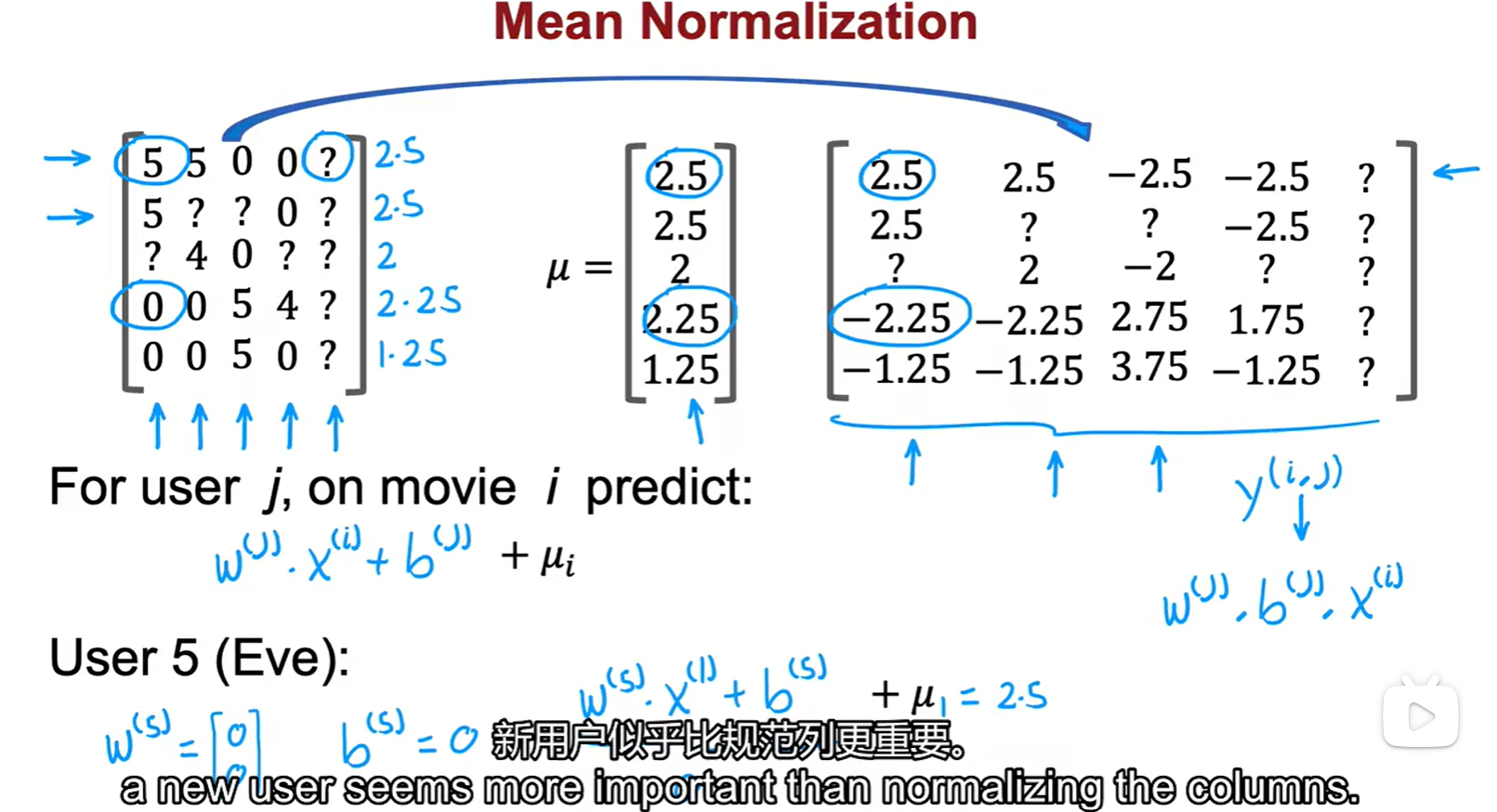
- 均值归一化:一个新用户,没有任何信息,但是我们不能不给TA推东西,所以要靠取均值来进行冷启动;这里做的是行归一化,参数初始化为 0;
- 行归一是对于新用户的预测更加合理,列归一是对于新电影的预测更加合理;
2.3 Finding related terms
- 通过计算两个特征向量间的差平方和,从而判断两者是否相似:

Cold start
- 协同过滤的限制:1.冷启动问题(初始数据不足)2.难以利用其他信息;

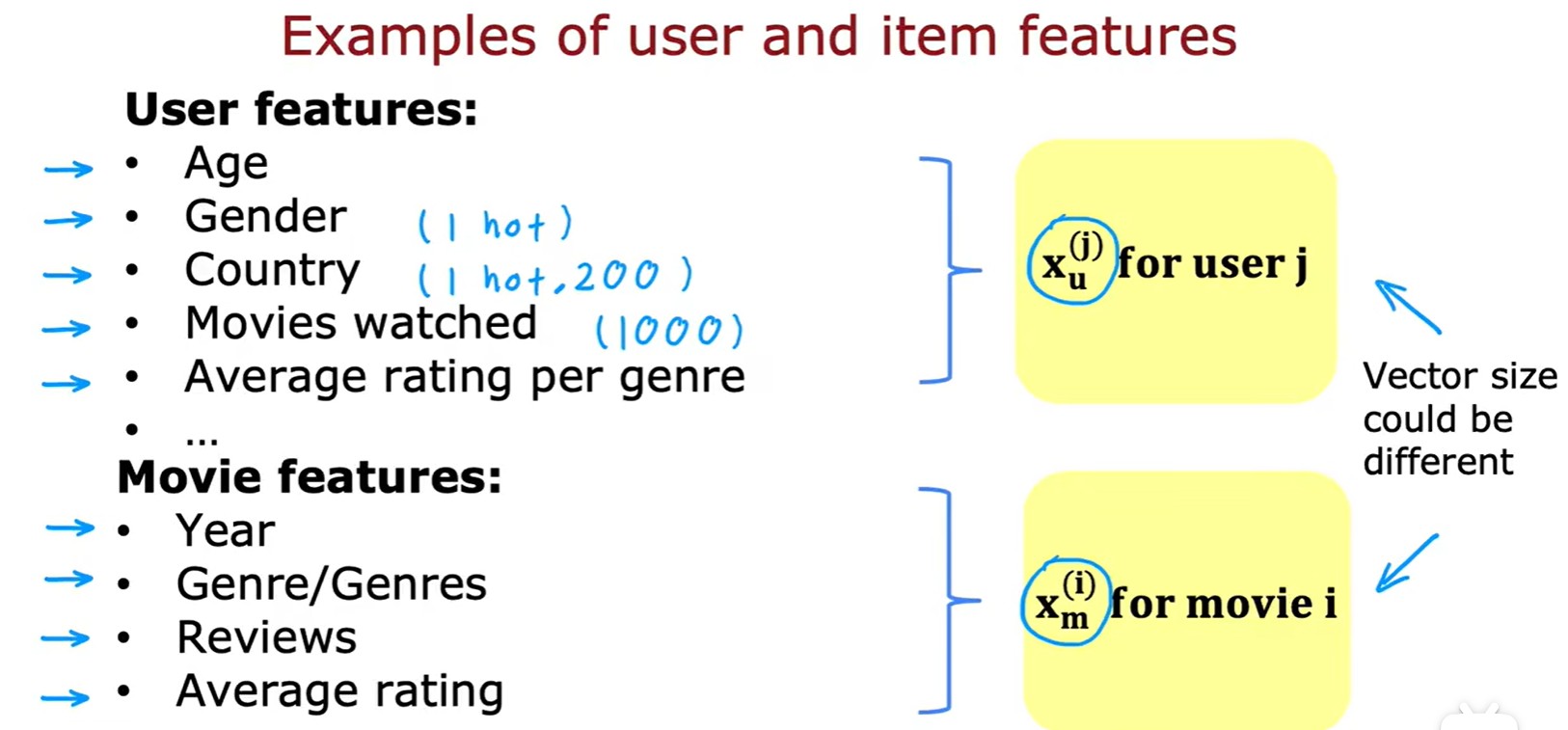
2.4 Content-based filtering
Compared with Collborative filtering
- 基于内容过滤:通过用户和电影的特征,计算两者间的匹配度;

 和
和 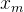 分别代表用户,电影的特征向量:
分别代表用户,电影的特征向量:
Learning to match
- 通过 和 计算出
 和
和 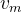 ,并且两者大小需要相同,然后进行点积计算得到用户对某电影的预估分数:
,并且两者大小需要相同,然后进行点积计算得到用户对某电影的预估分数:

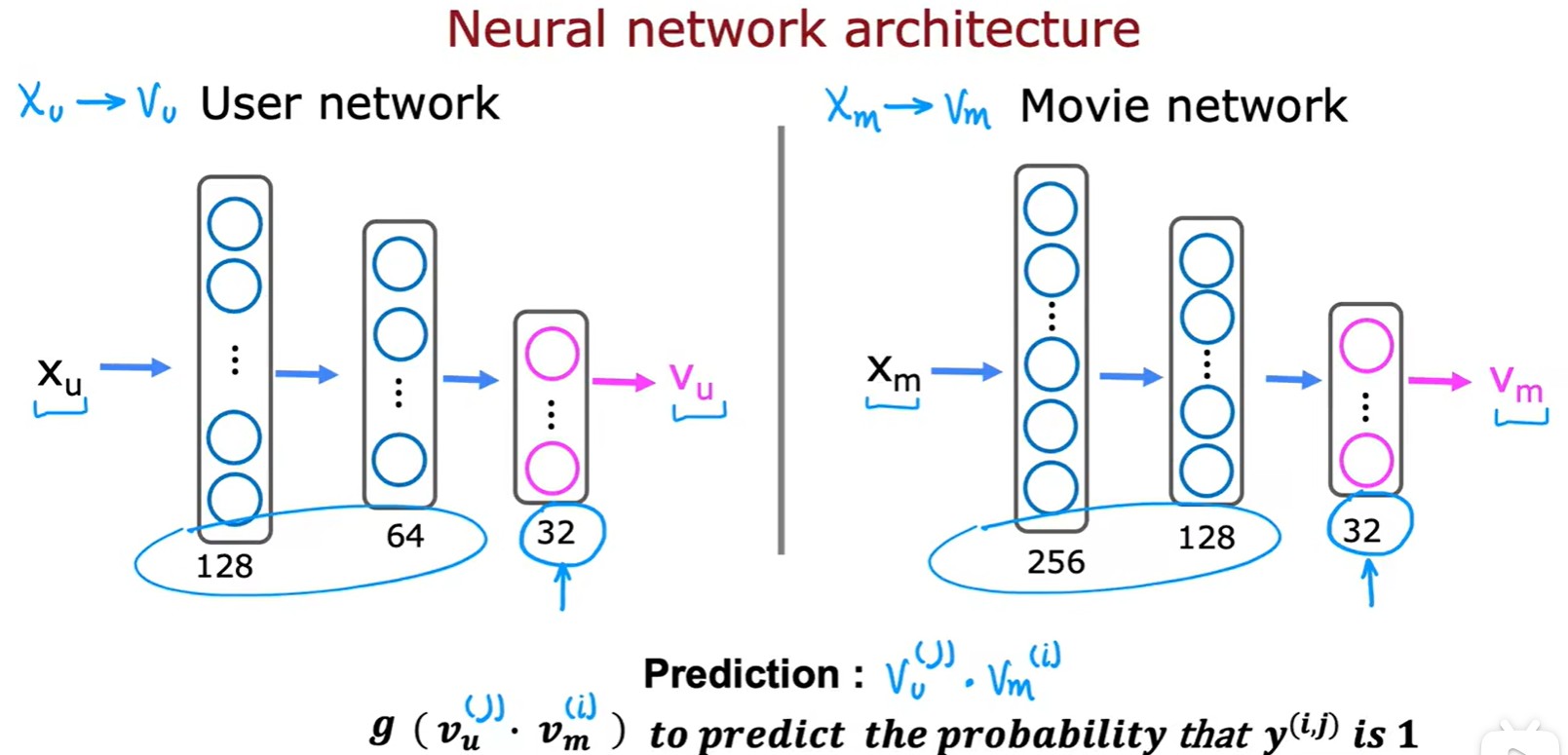
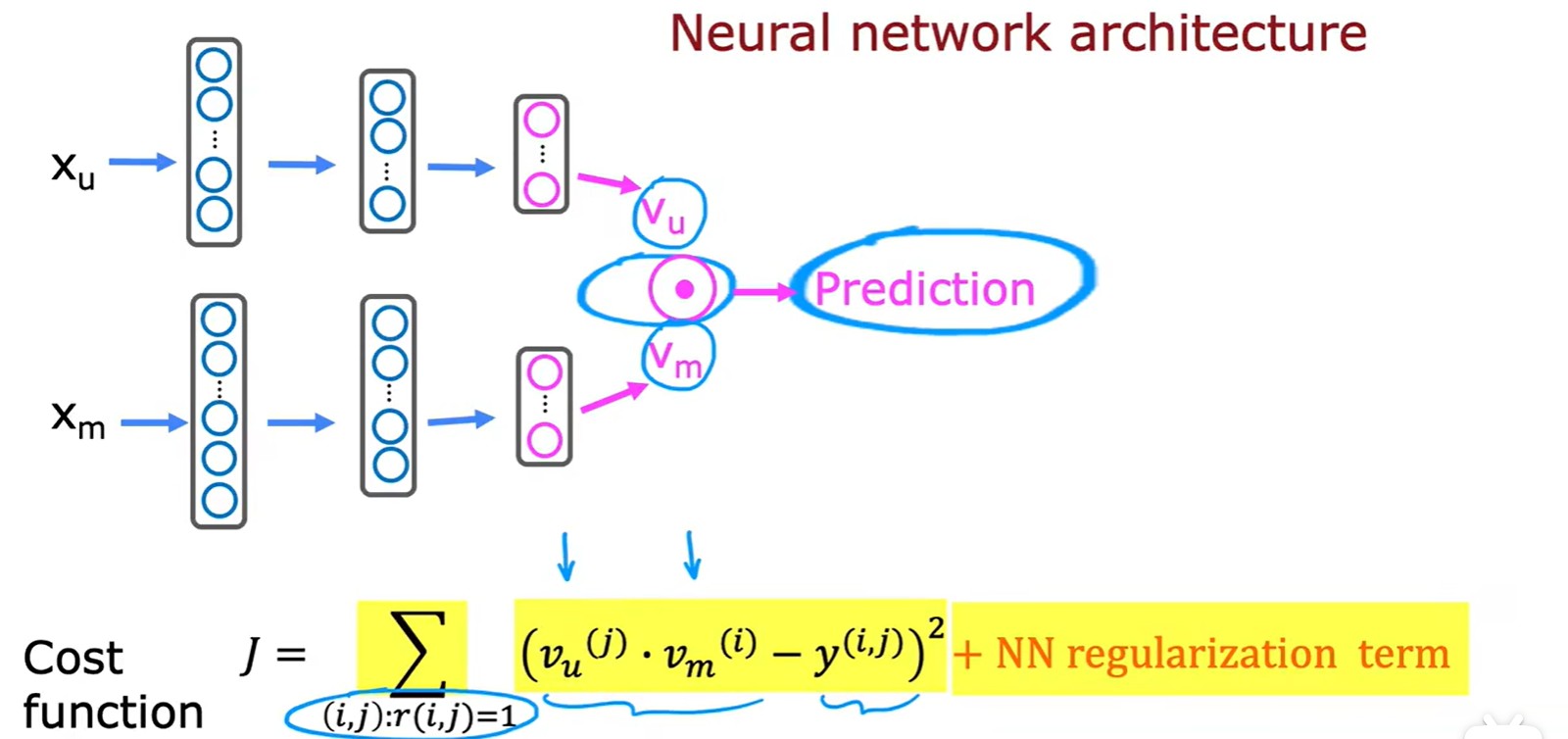
Neural network
- 利用神经网络将特征向量变换为 和 ,可以做点积得到电影预估分数,也可以再利用一次 logistic 回归计算喜欢概率:

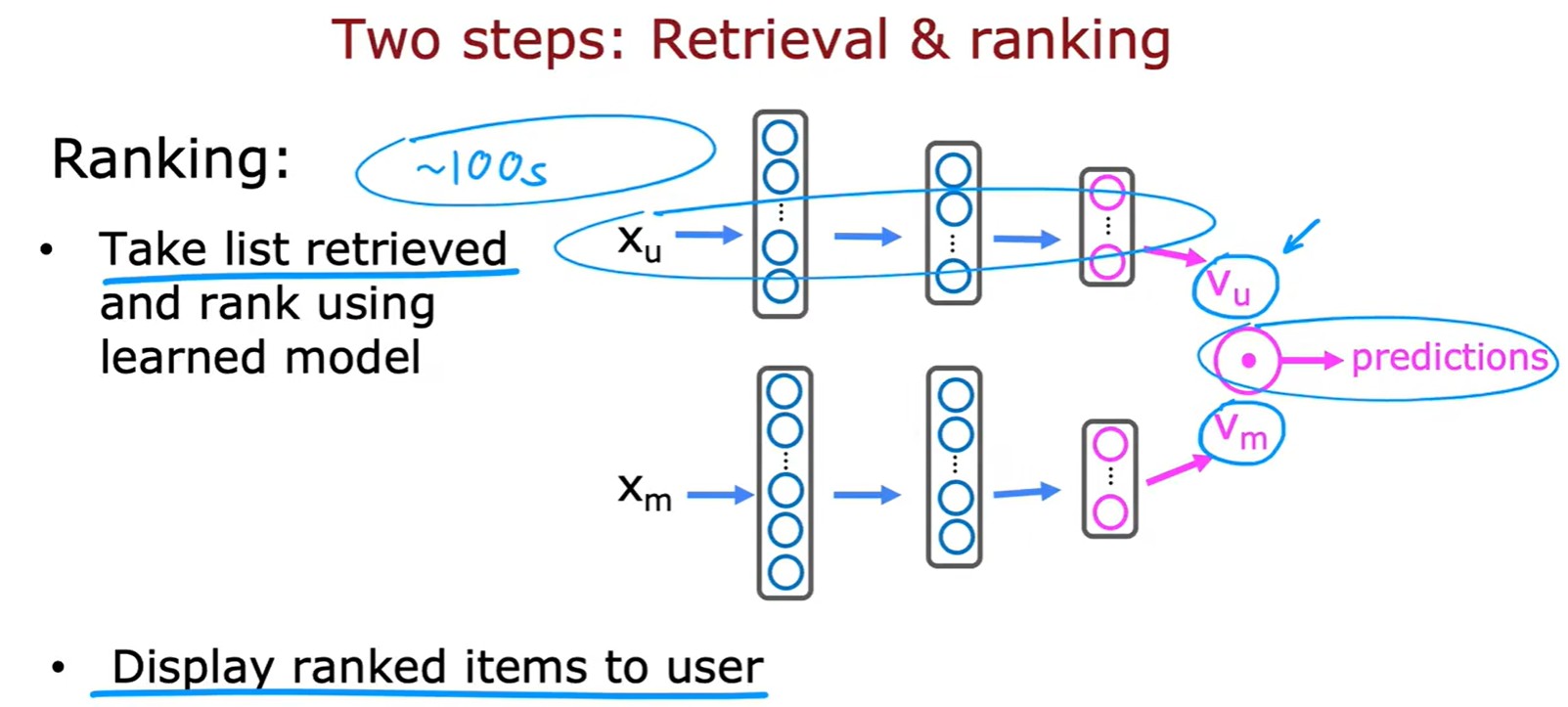
2.5 Large catalogue
Retrieval
- 第一步是检索:按照计算出的最相似的电影、常看题材的Top10、总榜单Top20,并且删除已经看过的,可以先得到一个粗略的较大列表;

Ranking
- 第二步:将检索的电影带入模型计算预测分数,按照分数进行排名推荐;
Week 3
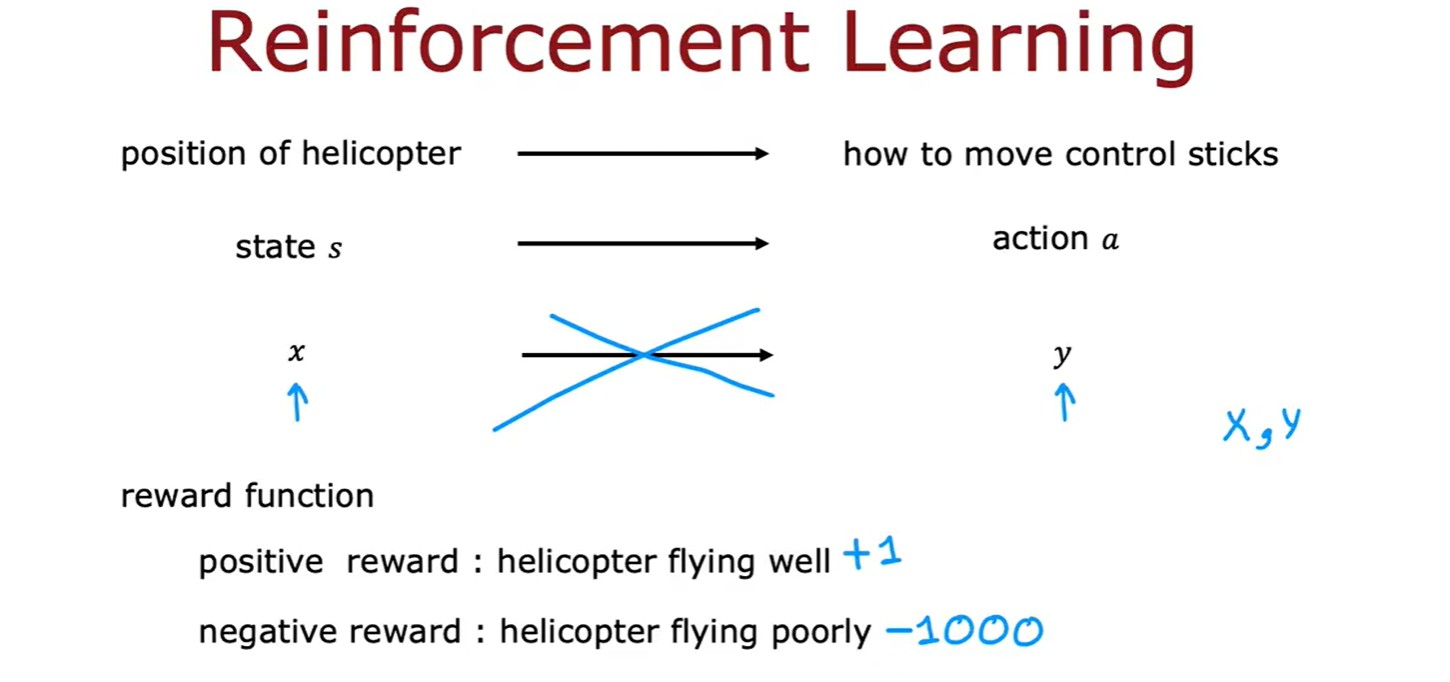
3.1 Reinforcement Learning
- 强化学习:核心在于指定一个奖励函数,告诉它什么时候做得好,什么时候做的不好,算法的工作是自动找出如何选择好的动作;
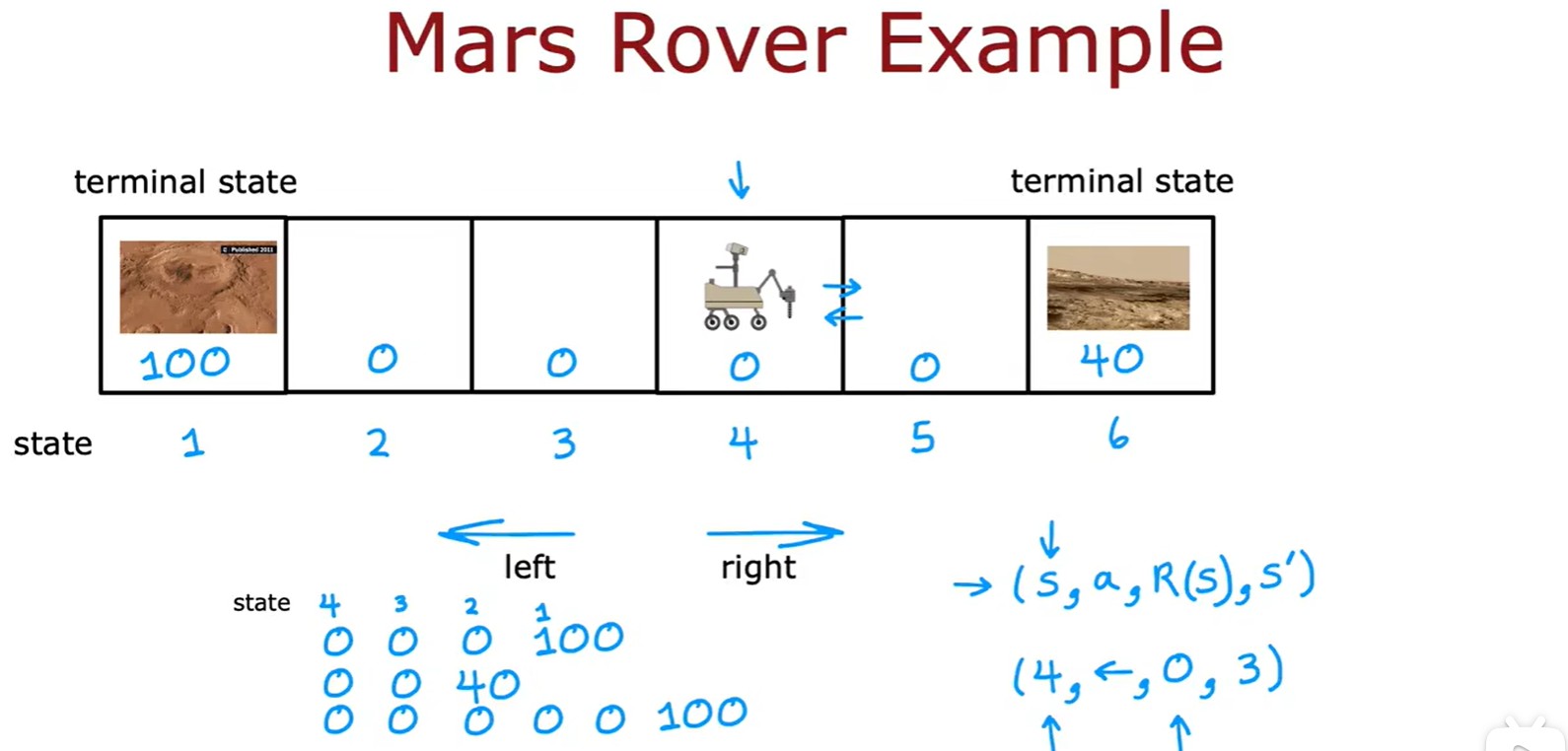
Mars Rover Example
- 火星探测器:这里的(s,a,R(s),s')表示(状态,动作,当前状态的奖励,下一个状态);
Return
- 强化学习的回报:每走一步都要乘以一个折扣因子,由此计算回报;
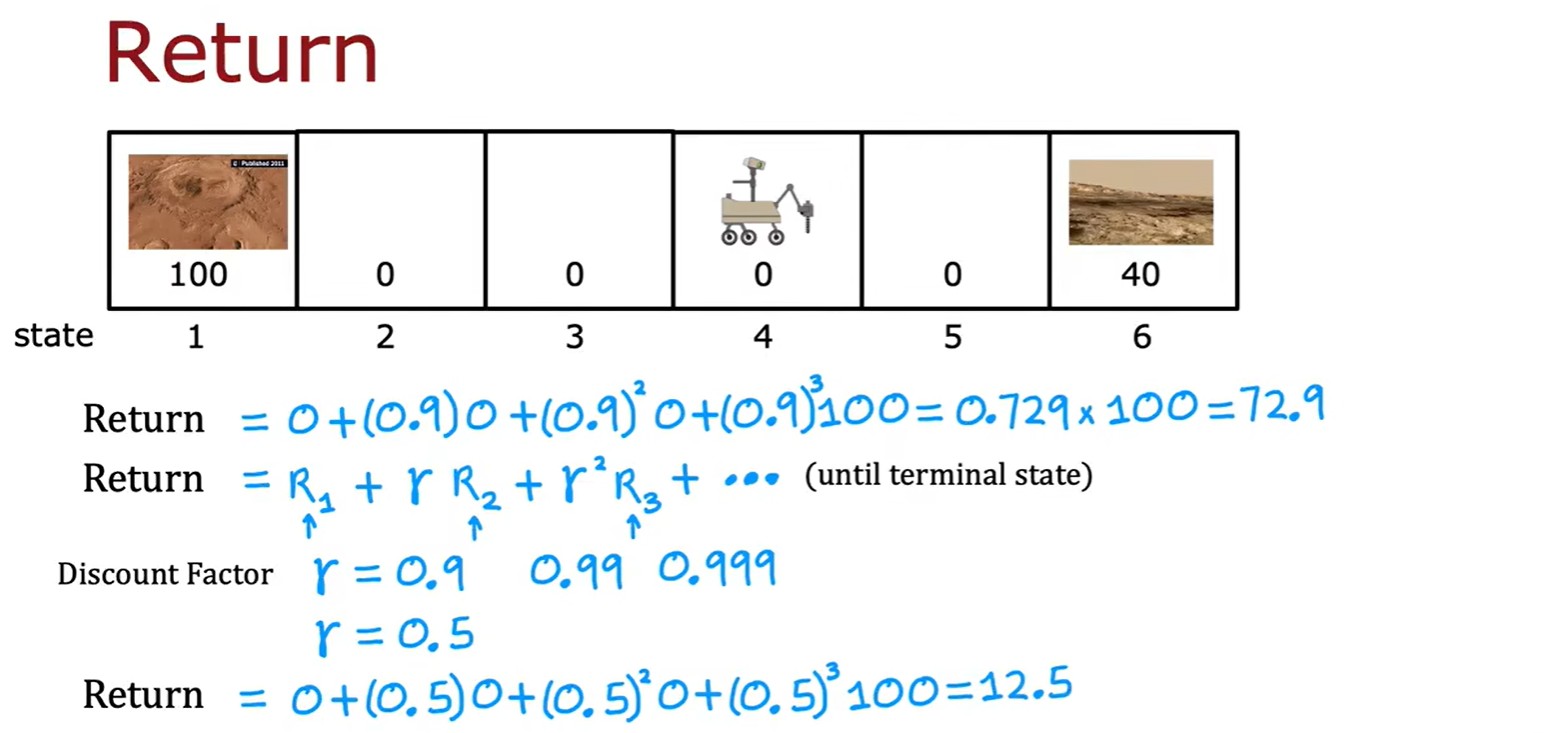
- 这里是几种不同的选择:一直向左、右,还有根据计算结果选择方向;

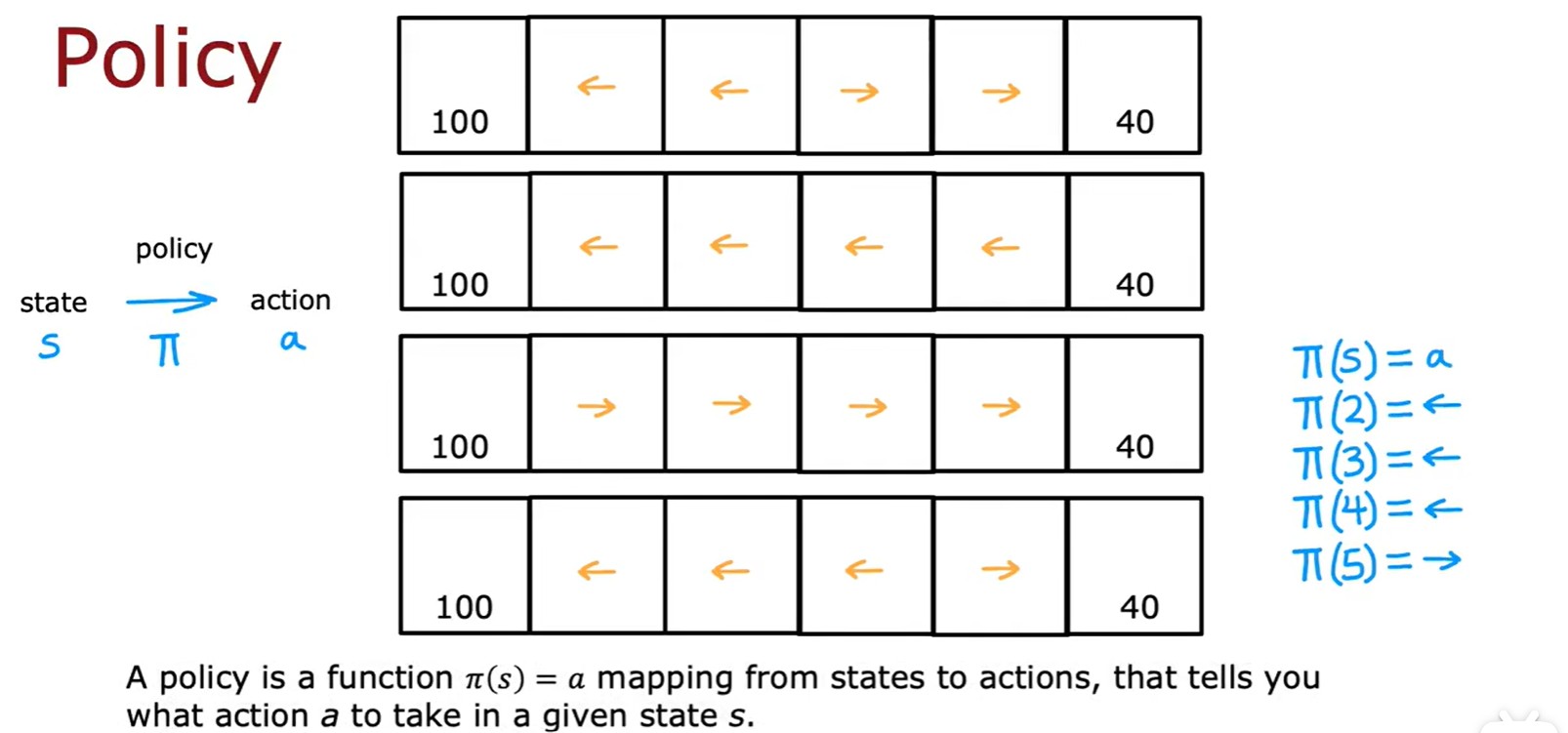
Policy
- 强化学习中的策略:
 表示在 s 处的行动是 a;
表示在 s 处的行动是 a;
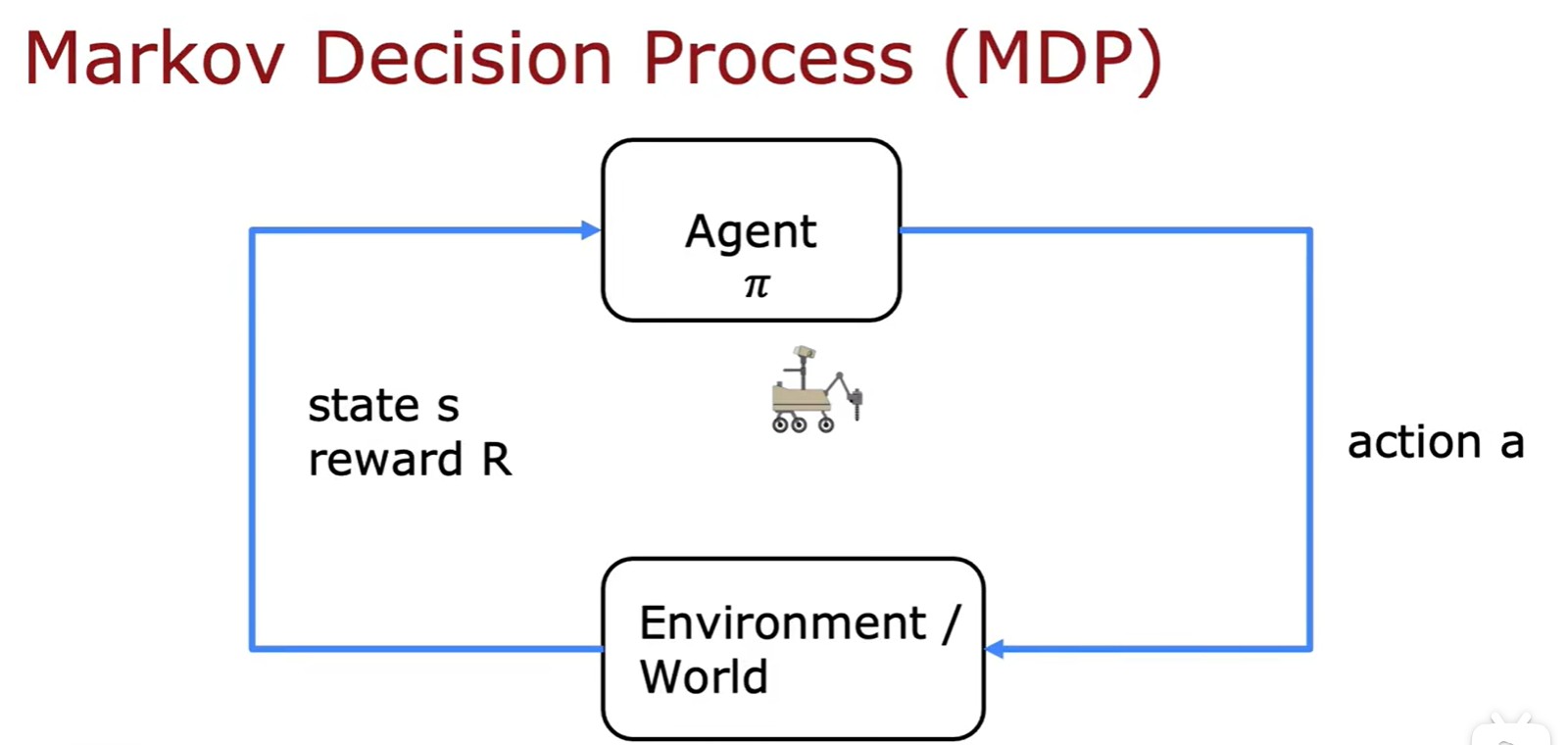
Markov Decision Process
- 马尔科夫决策过程:未来只取决于你现在在哪里,而不管你是怎么到这里的;
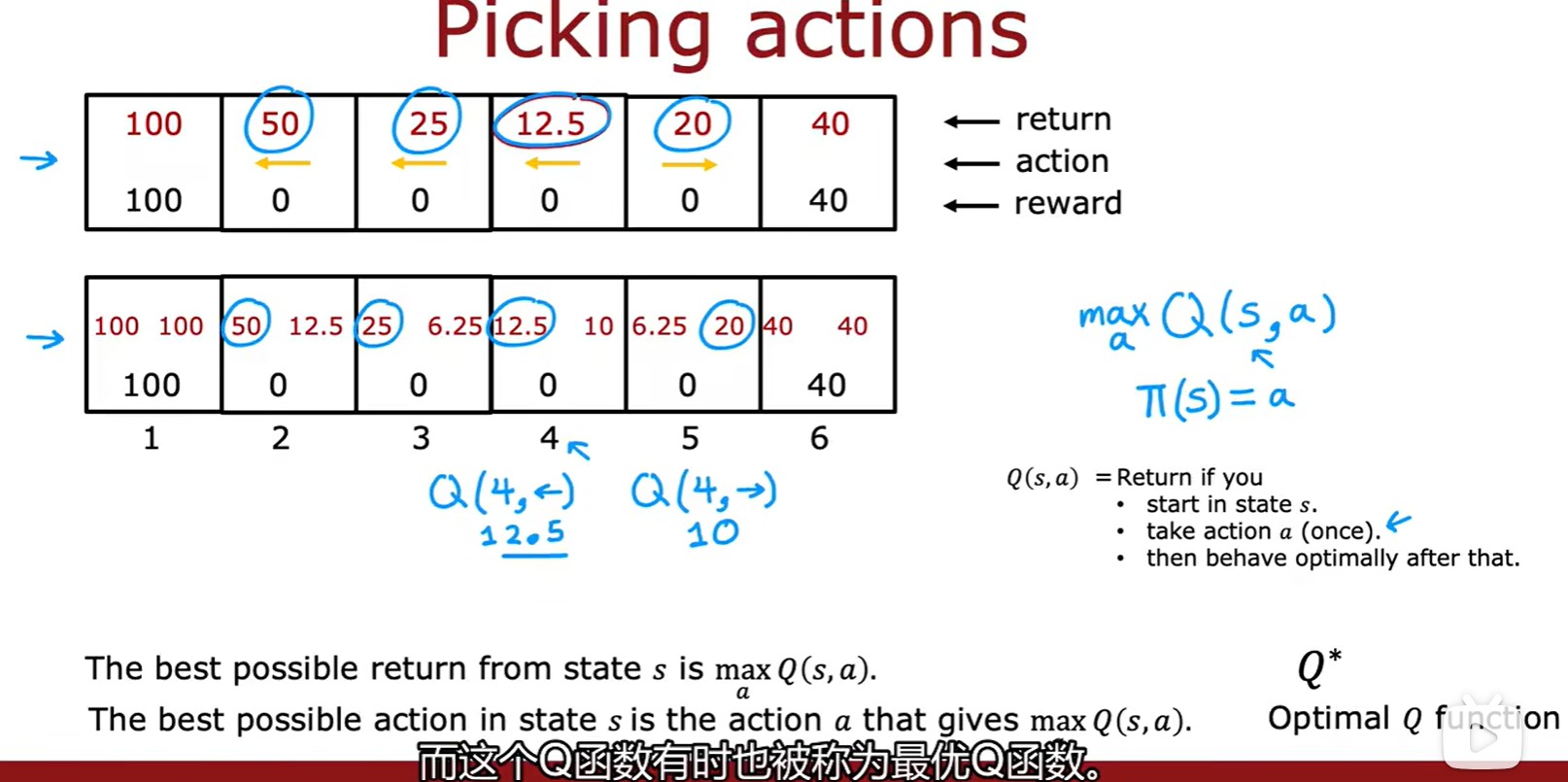
3.2 State-action value function
- 状态 - 动作价值函数:Q(s,a)表示在 s 处做出动作 a 得到的回报;
- 注意这里第一个计算的是先向右一步,再掉头的策略;

Picking actions
Bellman Equation
- 贝尔曼方程:原理就是递归方程,注意终端状态下计算没有第二项;

3.3 Continuous State

Lunar Lander Problem
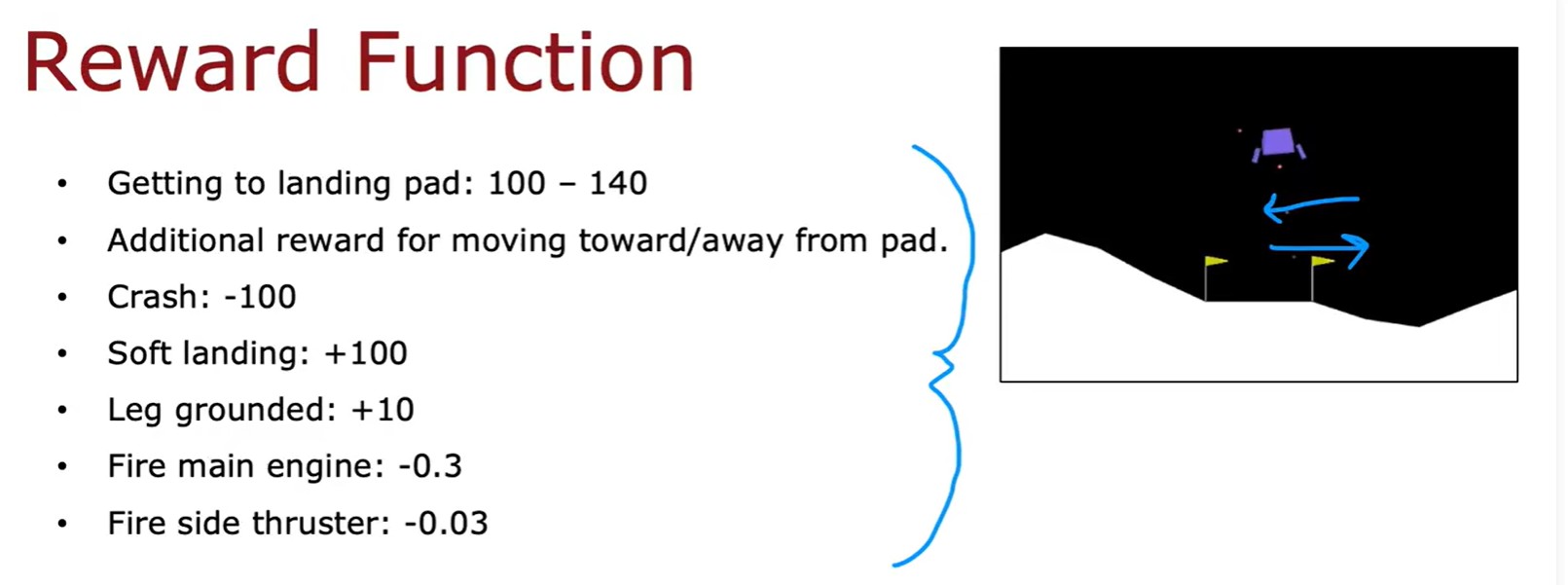
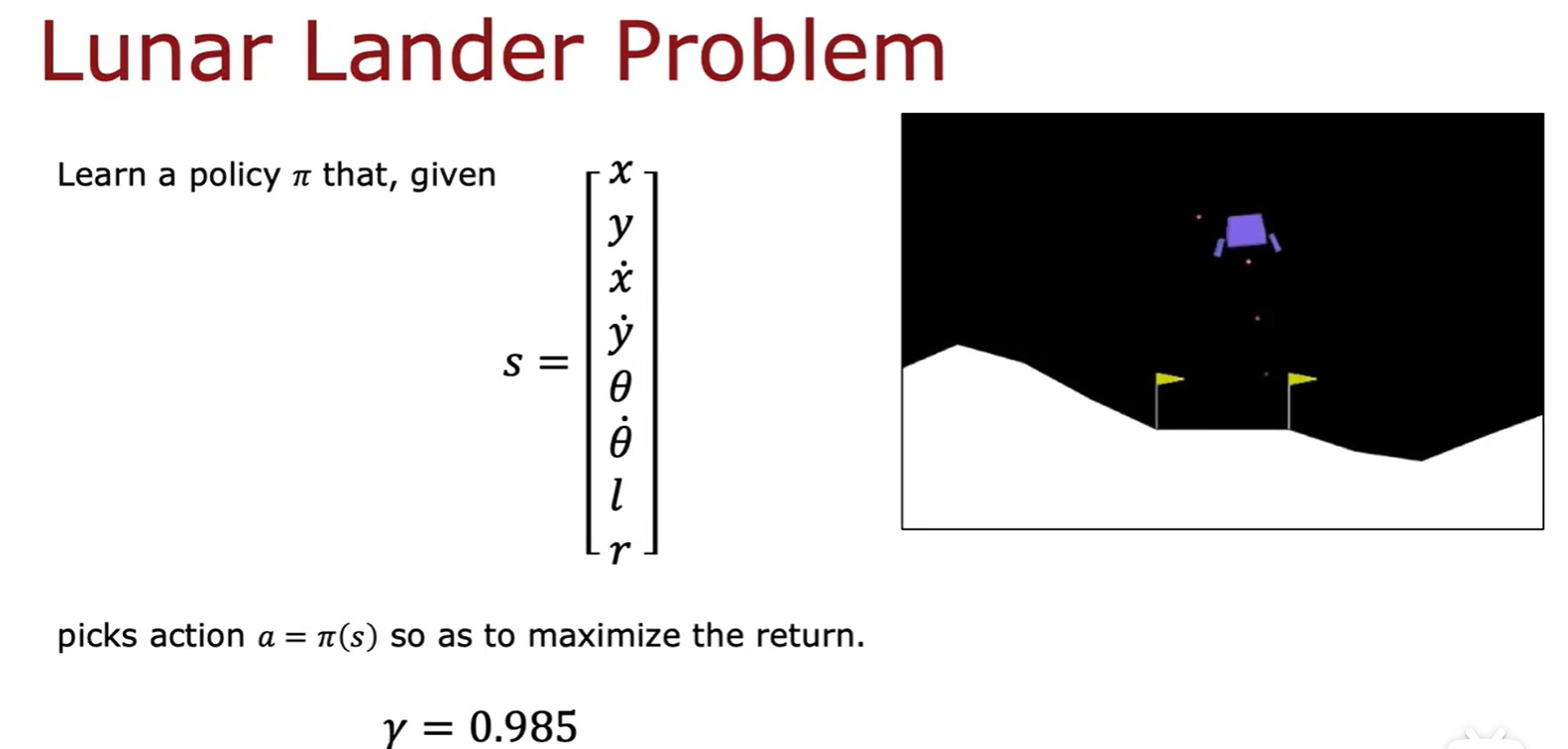
Algorithm

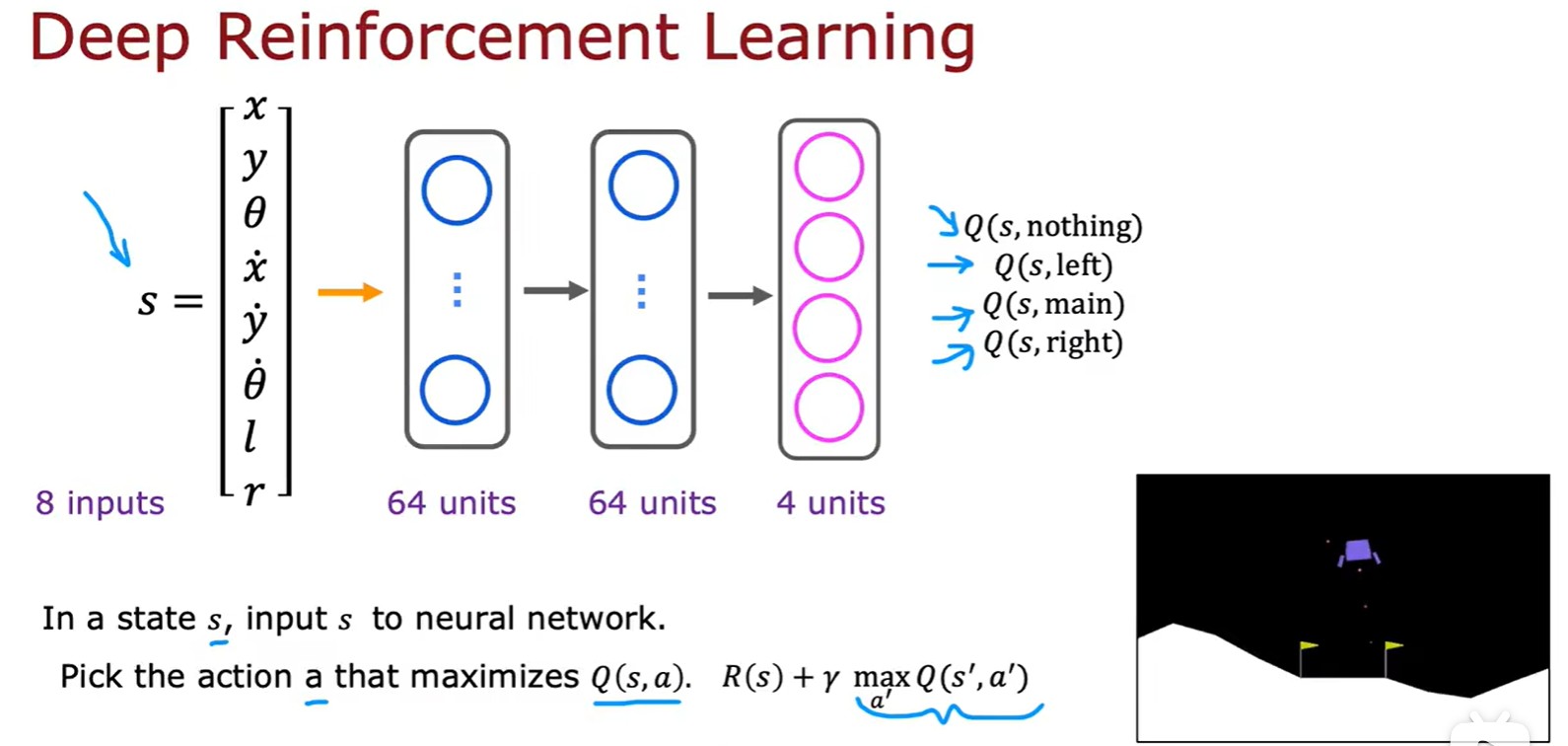
Epsilon - greedy policy
