UTF-8 编解码可视化分析
🌟 UTF-8 编解码可视化分析
引用:
- openppp2/ppp/text/Encoding.cpp
- C# UTF-8字符集长度获取及判断二进制块是否UTF-8编码字符集算法的实现
- 严格的C风格字符串 Unicode To UTF-8 的实现(C#、JavaScript)
- nsjsdotnet/NSJSString.cs
📐 1. UTF-8 字节对齐原理 (GetUtf8Alignment)
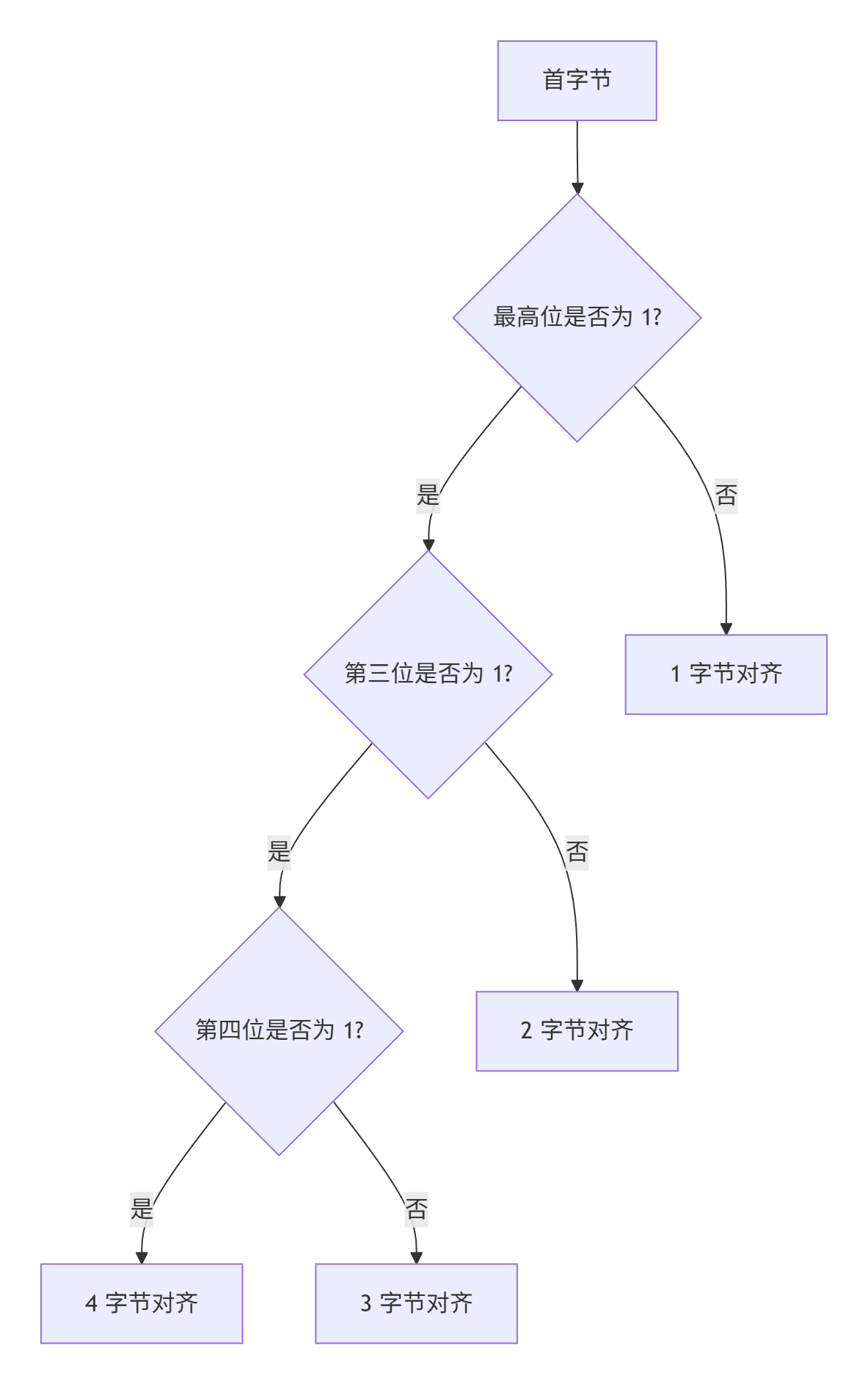
📊 UTF-8 字符编码结构
| 字节数 | 首字节范围 | 编码模板 |
|---|---|---|
1 | 0x00-0x7F | 0xxxxxxx |
2 | 0xC0-0xDF | 110xxxxx 10xxxxxx |
3 | 0xE0-0xEF | 1110xxxx 10xxxxxx 10xxxxxx |
4 | 0xF0-0xF7 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
🔢 2. 字符计数流程 (GetUtf8BufferCount)
✅ 3. UTF-8 验证流程 (IsUTF8Buffer)
⚙️ C++ 实现代码 (带详细注释)
#pragma execution_character_set("utf-8") // 指示编译器使用UTF-8编码执行字符集#include <Windows.h> // 包含Windows API头文件#include <string> // 包含C++字符串库
#include <cstring> // 包含C风格字符串操作函数
#include <iostream> // 包含输入输出流对象
#include <codecvt> // 包含字符编码转换工具// 定义位掩码常量用于UTF-8编码检测
constexpr BYTE kFirstBitMask = 0x80; // 10000000b - 检测首字节最高位
constexpr BYTE kSecondBitMask = 0x40; // 01000000b - 检测首字节次高位
constexpr BYTE kThirdBitMask = 0x20; // 00100000b - 检测首字节第三位
constexpr BYTE kFourthBitMask = 0x10; // 00010000b - 检测首字节第四位// 计算UTF-8字符的字节长度
int GetUtf8Alignment(BYTE character) {int alignment = 1; // 默认ASCII字符占1字节// 检查首字节最高位是否为1(表示多字节字符)if ((character & kFirstBitMask) > 0) {// 检查首字节第三位是否为1(可能为3字节字符)if ((character & kThirdBitMask) > 0) {// 检查首字节第四位是否为1(可能为4字节字符)if ((character & kFourthBitMask) > 0) {alignment = 4; // 确定为4字节字符}else {alignment = 3; // 确定为3字节字符}}else {alignment = 2; // 确定为2字节字符}}return alignment; // 返回字符占用的字节数
}// 计算UTF-8字符串的字节长度(包含空终止符)
int GetUtf8BufferCount(BYTE* s) {if (NULL == s) { // 空指针检查return 0;}BYTE* i = s; // 创建指针用于遍历字符串// 遍历直到遇到空终止符while (*i != '\x0') {int alignment = GetUtf8Alignment(*i); // 获取当前字符的字节长度int character = 0; // 存储字符值(实际未使用)// 根据字符长度处理不同情况if (alignment == 1) {character = *i++; // 单字节字符直接读取}else if (alignment == 2) {character = *(short*)i; // 双字节字符(存在字节序问题)i += 2; // 指针前进2字节}else if (alignment == 3) {// 拼接三字节字符(小端序处理)character = (*i++ | *i++ << 8 | *i++ << 16);}else if (alignment == 4) {character = *(int*)i; // 四字节字符(存在字节序问题)i += 4; // 指针前进4字节}else {return 0; // 无效字符长度处理}}int len = (int)(i - s); // 计算从开始到结束的字节数(含空终止符)return len < 0 ? 0 : len; // 处理长度小于0的情况
}// 验证缓冲区是否为有效的UTF-8编码
bool IsUTF8Buffer(BYTE* buffer, int count) {// 空指针或无效长度检查if (NULL == buffer || count <= 0) {return false;}int counter = 1; // 当前字符的剩余字节数(初始为1)BYTE key = 0; // 当前处理的字节for (int i = 0; i < count; i++) {key = buffer[i]; // 获取当前字节if (counter == 1) { // 处理新字符的首字节if (key >= 0x80) { // 检查是否多字节字符// 计算后续字节数(通过左移检测连续高位1)while (((key <<= 1) & 0x80) != 0) {counter++; // 每多一个高位1则增加计数}// 验证字节数在有效范围(2-4字节)if (counter == 1 || counter > 4) {return false; // 无效的首字节格式}}}else { // 处理连续字节// 检查是否为有效的连续字节(格式应为10xxxxxx)if ((key & 0xC0) != 0x80) {return false; // 无效的连续字节格式}counter--; // 减少剩余字节计数}}return !(counter > 1); // 检查是否完整读取最后一个字符
}// 将宽字符串转换为UTF-8编码的字符串
std::string wstring_to_utf8(const std::wstring& s) noexcept {// 创建宽字符到UTF-8的转换器std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;// 执行转换并返回结果return converter.to_bytes(s);
}// 程序主入口
int main(int argc, const char** argv) noexcept {const char str[] = "中国"; // UTF-8编码的中文字符串// 验证字符串是否为有效UTF-8编码std::cout << "Is utf8 string: "<< IsUTF8Buffer((BYTE*)str, sizeof(str))<< std::endl;// 计算字符串的字节长度(包含空终止符)std::cout << "Utf8 string length: "<< GetUtf8BufferCount((BYTE*)str)<< std::endl;return 0; // 程序正常退出
}
⚡ C# 实现说明 (优化版)
// 导入kernel32.dll中的IsBadReadPtr函数,用于检测内存指针是否可读
[DllImport("kernel32.dll", CallingConvention = CallingConvention.StdCall)]
private extern static bool IsBadReadPtr(void* lp, uint ucb);// 定义UTF-8编码检测用的位掩码常量
private const byte kFirstBitMask = 0x80; // 10000000b - 检测首字节最高位
private const byte kSecondBitMask = 0x40; // 01000000b - 检测首字节次高位
private const byte kThirdBitMask = 0x20; // 00100000b - 检测首字节第三位
private const byte kFourthBitMask = 0x10; // 00010000b - 检测首字节第四位
private const byte kFifthBitMask = 0x08; // 00001000b - 检测首字节第五位// 计算UTF-8字符的字节长度
public static int GetUtf8Alignment(byte character)
{int alignment = 1; // 默认ASCII字符占1字节// 检查首字节最高位是否为1(表示多字节字符)if ((character & kFirstBitMask) > 0) {// 检查首字节第三位是否为1(可能为3字节字符)if ((character & kThirdBitMask) > 0) {// 检查首字节第四位是否为1(可能为4字节字符)if ((character & kFourthBitMask) > 0) {alignment = 4; // 确定为4字节字符}else{alignment = 3; // 确定为3字节字符}}else{alignment = 2; // 确定为2字节字符}}return alignment; // 返回字符占用的字节数
}// 计算UTF-8字符串的字节长度(不安全代码)
public static unsafe int GetUtf8BufferCount(byte* s)
{if (s == null) // 空指针检查{return 0;}byte* i = s; // 创建指针用于遍历字符串// 循环直到遇到无效内存或空字符while (!IsBadReadPtr(i, 1)) // 检查当前指针是否可读{int alignment = GetUtf8Alignment(*i); // 获取当前字符的字节长度int character = 0; // 存储字符值(实际未使用)// 根据字符长度处理不同情况if (alignment == 1){character = *i++; // 单字节字符直接读取}if (alignment == 2) // 注意:此处应为else if,否则逻辑错误{character = *(short*)i; // 双字节字符(存在字节序问题)i += 2; // 指针前进2字节}else if (alignment == 3){// 拼接三字节字符(小端序处理)character = (*i++ | *i++ << 8 | *i++ << 16);}else if (alignment == 4){character = *(int*)i; // 四字节字符(存在字节序问题)i += 4; // 指针前进4字节}// 检测到空终止符时结束遍历if (character == 0){// 计算从开始到结束的字节数(含空终止符)int len = unchecked((int)(i - (s + 1)));return len < 0 ? 0 : len; // 处理长度小于0的情况}}return 0; // 遇到无效内存时返回0
}// UTF-8验证方法(字节数组重载)
public static unsafe bool IsUTF8Buffer(byte[] buffer)
{if (buffer == null) // 空数组检查{return false;}// 固定字节数组内存地址fixed(byte * pinned = buffer){// 调用指针版本验证方法return IsUTF8Buffer(pinned, buffer.Length);}
}// UTF-8验证方法(指针版本)
public static unsafe bool IsUTF8Buffer(byte* buffer, int count)
{// 空指针或无效长度检查if (buffer == null || count <= 0){return false;}int counter = 1; // 当前字符的剩余字节数(初始为1)byte key = 0; // 当前处理的字节for (int i = 0; i < count; i++){key = buffer[i]; // 获取当前字节if (counter == 1) // 处理新字符的首字节{if (key >= 0x80) // 检查是否多字节字符{// 计算后续字节数(通过左移检测连续高位1)while (((key <<= 1) & 0x80) != 0){counter++; // 每多一个高位1则增加计数}// 验证字节数在有效范围(2-4字节)if (counter == 1 || counter > 4){return false; // 无效的首字节格式}}}else // 处理连续字节{// 检查是否为有效的连续字节(格式应为10xxxxxx)if ((key & 0xC0) != 0x80){return false; // 无效的连续字节格式}counter--; // 减少剩余字节计数}}return !(counter > 1); // 检查是否完整读取最后一个字符
}
📌 关键原理总结
- 变长编码:UTF-8 使用 1-4 字节动态编码 Unicode
- 首字节标识:高位 1 的数量表示总字节数
- 续字节格式:后续字节必须以
10开头 - 内存安全:通过
IsBadReadPtr防止非法内存访问 - 边界校验:严格验证多字节序列完整性
流程图使用 Mermaid 语法绘制,可在支持 Mermaid 的环境(如Obsidian、VSCode插件)中查看动态效果。