脑电分析——ICA原理、ICALabel成分与伪迹之间一对多的关系
ICA原理、ICALabel成分与伪迹之间一对多的关系
- 一、ICA原理
- 1. ICA的基本概念
- 2. ICA的数学原理
- 二、ICA与ICALabel分别在做什么
- 1. ICA: 统计分解层(“把混合信号拆开”)
- 2. ICALabel:语义标注层(“给每个IC贴标签”)
- 三、为什么会出现“一对多”:同一类伪迹会对应多个IC
- 1. 主要原因:
- 2. 总结
- 四、同理也可能出现“多对一”:一个IC混合多类特征
- 五、论文复现
- 1. 论文核心内容
- 2. 实现内容
- 六、感受
一、ICA原理
1. ICA的基本概念
基本概念
独立成分分析(ICA)是一种盲源分离技术,旨在从观测数据中提取相互独立的信号源。ICA主要用于信号处理、语音分离、图像分析等领域。
ICA的理想假设
① 各源信号统计独立(有效地分离)
② 至少有一个(通常大多数)源呈非高斯分布(中心极限定理)
③ 通道数 ≥ 主要源数(满足线性方程求逆的基本可解性)
ICA与PCA的区别
- PCA关注方差最大化,假设不同主成分之间是正交的、不相关的
- ICA关注信号的统计独立性,假设信号是非高斯的
ICA试图找到一个变换,使得投影后的数据尽可能独立,而不是仅仅去除相关性。
什么是非高斯信号?
- 非高斯信号是指其统计特性偏离高斯分布。
为什么要研究高斯信号
- 中心极限定理:多个独立信号的线性混合会趋向高斯分布(混合信号比单一源信号更“高斯”)。
- 推论:若分离后的信号越非高斯,越接近真实的源信号。
- ICA的策略:通过最大化分离信号的非高斯性来逼近源信号。
2. ICA的数学原理
假设现有 nnn 个源信号 S=(s1,s2,⋯,sn)TS = \left ( s_{1} ,s_{2} , \cdots , s_{n} \right )^{T}S=(s1,s2,⋯,sn)T,它们通过一个未知的混合矩阵 AAA 线性混合后,形成观测信号 XXX :
X=ASX=AS X=AS
其中:
- X=(x1,x2,⋯,xn)TX = \left ( x_{1} ,x_{2} , \cdots , x_{n} \right )^{T}X=(x1,x2,⋯,xn)T 是观测到的数据
- s=(s1,s2,⋯,sn)Ts = \left ( s_{1} ,s_{2} , \cdots , s_{n} \right )^{T}s=(s1,s2,⋯,sn)T 是源信号,它们是相互独立的
- AAA 是未知的混合矩阵
ICA的目标 是找到了一个逆矩阵 WWW ,使得:S=WXS=WXS=WX
- 其中 WWW 是分离矩阵,使得 SSS 尽可能独立。
二、ICA与ICALabel分别在做什么
1. ICA: 统计分解层(“把混合信号拆开”)
-
模型:观测 EEG X(t)X(t)X(t) 是若干潜在源 S(t)S(t)S(t) 的 线性混合。
X(t)=AS(t)X(t)=AS(t) X(t)=AS(t) -
目标: 求解解混矩阵 WWW ,得到 IC (独立成分)。
-
关键假设:源之间统计独立、至少一部分源 非高斯。
-
输出含义:每个IC是一个 统计上 尽量独立的时序分量及其空间投影(拓扑/头皮图)。
注意:ICA的“独立”是统计独立的,通常通过非高斯最大化来实现。(也就是说,得到的 IC 之间在统计特征上 [ 分布、联合概率 ] 没有依赖关系 )
2. ICALabel:语义标注层(“给每个IC贴标签”)
- 输入:ICA 得到的每个 IC(其波形、功率谱、头皮拓扑等特征)
- 本质:一个监督学习分类器,输出7类概率分布。(Brain/Eye/Muscle/Heart/Line/Channel/Other)
- 输出解释:对每个IC 给出 “属于各类别的概率” 而不是单一确定标签。(例如:Eye=0.86, Muscle=0.07……)
- 作用:把 统计分解出的IC 映射到人可理解的 伪迹/脑源类别。
ICA负责“拆”,ICALabel负责“认”。即先用ICA的独立成分,再用ICALabel给每个成分判别语义类别。
三、为什么会出现“一对多”:同一类伪迹会对应多个IC
“独立(统计)” 与 “类别(语义)”不是一一对应的。
1. 主要原因:
(1)生理源本身是多维的
- 眼动:垂直 EOG(眨眼/眼动)VS 水平 EOG(扫视),它们在头皮上的投影不同,ICA 会分别抓住它们。
- 肌电:不同肌群(额肌、颞肌、颊肌等)→ 各有独立的电活动模式,可能分成多个 IC。
(2)信号具有时变/非平稳性
- 眨眼:短时、低频成分;
- 眼位偏移(眼睛保持在某个偏移方向):更慢的漂移;
- 扫视:快速瞬态。
ICA 倾向于把不同时间/频率特征的活动拆分到不同的 IC 。
(3)噪声与通道数限制
- 电极少 → 无法完整分离全部源 → 伪迹可能被拆到多个方向
ICA 的前提之一是:通道数 ≥ 源信号数
如果电极数量太少(比如只用 8 通道EEG),但脑电源+伪迹源(眼动、肌电、心电等)数量比通道数多,那么ICA 无法完全一一分离。
结果就是:
- 一个伪迹信号(比如眼动)可能 “溢出” 到多个 IC ;
- ICA 会尽量在有限的维度里找到近似独立的方向 → 可能把同一个伪迹拆散。
- 信噪比低 → ICA 会把“伪迹主轴”分裂成多个独立成分,以适应数据的波动
如果 EEG 信号被噪声淹没(比如电极接触不好、肌电干扰很强),ICA 在分离时就会收到影响:
- 它会把原本应该属于 “一个独立成分” 的信号分裂开;
- 这样得到的 IC 可能不是一个干净的伪迹,而是几个波动不完全独立的小块。
等于说:ICA 为了满足 “统计独立”,不得不把同一个伪迹分配到多个成分上。
(4)理论层面
- ICA 只要求 IC 之间统计独立
- 类别是人为语义,可以重复。独立≠唯一
例子:
- 你可能得到 Eye-IC_V(垂直眼动,前额对称、大振幅、低频、眨眼主轴)和 Eye-IC_H(水平眼动,左右偏置,水平扫视主轴);
- 二者都被 ICALabel 标为 Eye,这是同一类伪迹的一对多。
2. 总结
一个生理伪迹(如眼动/肌电)在空间、时间、频率上可能有多个独立成分,所以 ICA 会给出多个 IC ,它们在标注时被归为同一类伪迹,这就是 “一对多” 。
四、同理也可能出现“多对一”:一个IC混合多类特征
- 因为真实数据不完全满足 ICA 的理想假设(源之间统计独立),或某些源本身就有耦合
- ICALabel 会给出混合概率(如 Brain 0.55、 Muscle 0.35…)
五、论文复现
我这周主要是粗略地了解了 EEGANet_Removal_of_Ocular_Artifacts_From_the_EEG_Signal_Using_Generative_Adversarial_Networks(EEGANet:使用生成对抗网络从脑电图信号中去除眼部伪影)这篇论文,然后根据它的开源代码地址https://github.com/IoBTVISTEC/EEGANet进行复现。
1. 论文核心内容
EEGANet 是一种基于 生成对抗网络(GAN)的脑电信号眼动伪迹去除方法。主要的贡献和特点:
(1)问题背景:
- EEG 数据中,眼动伪迹严重影响信号分析,尤其是用于脑机接口应用时。
- 传统的方法需要 EOG 信号 或 眼动检测算法 ,增加实现复杂性。
(2)方法创新
- EEGANet 使用 GAN 来学习去除眼动伪迹的映射,无需依赖 EOG 或眼动检测。
(3)模型能力
- 能生成多通道 EEG 信号。
- 在眼动伪迹去除上,与依赖 EOG 的传统方法性能接近。
- EEGANet 处理后的信号分类性能与传统方法相当,即使没有 EOG 信号。
2. 实现内容
复现的流程是:
① 将我们自己的数据集从 .edf 转化为 .npy(符合模型的输入格式)
② 使用训练好的 EEGANet 模型,将自己的训练集进行去伪迹
输出前10个样本(从自己的EEG数据集中选取了前10段EEG信号样本),将原始信号和模型输出信号进行绘图对比,每个样本里包含多个通道(绿色:原始EEG,红色:去伪迹EEG)
下图为输出结果的一部分内容:
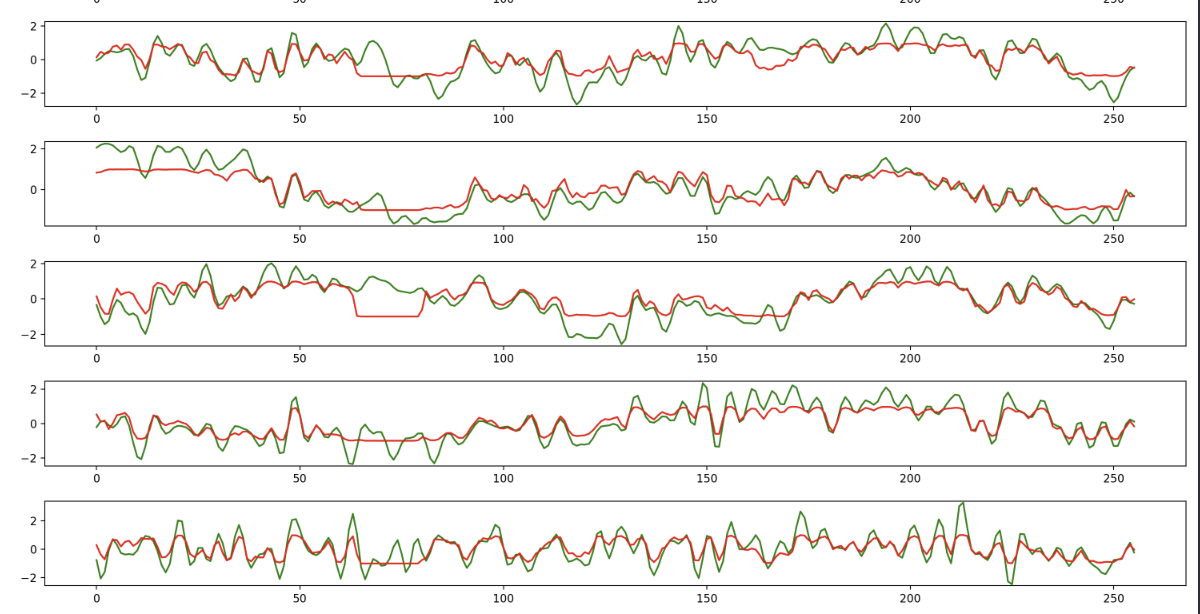
每个子图代表一个 EEG 通道
(1)横坐标是时间点(0~256,对应256个采样点),纵坐标是幅值(经过标准化)
(2)绿色曲线:原始 EEG 信号(含眼动伪迹)
(3)红色曲线:EEGANet 输出信号(模型去伪迹后的结果)
六、感受
这周我主要学习了 ICA 与 ICALabel 的原理和区别,理解了 ICA 负责 “分解信号” 、ICALabel 负责 “给成分贴标签” ,以及为什么会出现 “一对多” 或 “多对一” 的情况;同时,我粗略阅读并复现了 EEGANet 去除眼动伪迹的论文与代码,把自己的 EEG 数据集转化为模型可用格式并进行了实验,输出前 10 个样本的多通道对比图,直观看到模型在抑制伪迹和保留脑电趋势方面的效果。