YOLO多模态改进系列 | YOLOFuse:多模态融合的 Slim-Neck 改进
本教程详细讲解如何将
YOLOFuse的 多模态融合结构 与Slim-Neck架构相结合,实现目标检测模型的性能优化。
相关代码可在GitHub获取:YOLOFuse开源项目地址:https://github.com/WangQvQ/YOLOFuse

目标检测是计算机视觉中一个重要的下游任务。对于车载边缘计算平台来说,很难实现实时检测的要求,因为庞大的模型会带来困难。而由大量深度可分离卷积层构建的轻量级模型不能达到足够的准确性。我们引入了一种新的轻量级卷积技术 GSConv,以减轻模型负担但保持准确性。GSConv 在模型准确性和速度之间实现了出色的平衡。此外,我们提供了一种设计范式 slim-neck,以实现更高的检测器计算成本效益。我们的方法在二十多组比较实验中表现出了鲁棒的有效性。特别地,我们改进后的检测器相比原始版本实现了最先进的结果(例如,在 Tesla T4 GPU 上以约 100FPS 的速度在 SODA10M 数据集上获得了 70.9% 的 mAP0.5)。
论文地址:https://arxiv.org/abs/2206.02424
模型结构
为什么要在Neck中使用GSConv?
为了加快预测的计算速度,CNN 中的馈送图像几乎必须在 Backbone 中经历类似的转换过程:空间信息逐步向通道传输。并且每次特征图的空间(宽度和高度)压缩和通道扩展都会导致部分语义信息的丢失。密集卷积计算最大限度地保留了每个通道之间的隐藏连接,而稀疏卷积则完全切断了这些连接。
GSConv 尽可能地保留这些连接。但是如果在模型的所有阶段都使用它,模型的网络层会更深,深层会加剧对数据流的阻力,显著增加推理时间。当这些特征图走到 Neck 时,它们已经变得细长(通道维度达到最大,宽高维度达到最小),不再需要进行变换。因此,更好的选择是仅在 Neck 使用 GSConv(Slim-Neck + 标准Backbone)。在这个阶段,使用 GSConv 处理拼接的特征图恰到好处:冗余重复信息少,不需要压缩,注意力模块效果更好,例如 SPP 和 CA。
Slim-Neck中的模块

首先,我们使用轻量级卷积方法 GSConv 来代替标准卷积。其计算成本约为标准卷积的60%~70%,但其对模型学习能力的贡献与后者不相上下。然后,我们在GSConv的基础上继续引入GSbottleneck,图(a)展示了GSbottleneck模块的结构。我们使用one-shot aggregation的方法来设计跨级部分网络(GSCSP)模块,VoV-GSCSP。 VoV-GSCSP 模块降低了计算和网络结构的复杂性,但保持了足够的精度。图 (b) 显示了 VoV-GSCSP 的结构。值得注意的是,如果我们使用 VoV-GSCSP 代替Neck的 CSP,其中 CSP 层由标准卷积组成,FLOPs 将平均比后者减少 15.72%。最后,我们需要灵活地使用3个模块、GSConv、GSbottleneck 和 VoV-GSCSP。我们可以像拼乐高积木一样构建Slim-Neck层。
源代码
import math
import torch
import torch.nn as nndef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.Mish() if act else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class GSConv(nn.Module):# GSConv https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=1, s=1, g=1, act=True):super().__init__()c_ = c2 // 2self.cv1 = Conv(c1, c_, k, s, None, g, act)self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)def forward(self, x):x1 = self.cv1(x)x2 = torch.cat((x1, self.cv2(x1)), 1)# shuffle# y = x2.reshape(x2.shape[0], 2, x2.shape[1] // 2, x2.shape[2], x2.shape[3])# y = y.permute(0, 2, 1, 3, 4)# return y.reshape(y.shape[0], -1, y.shape[3], y.shape[4])b, n, h, w = x2.data.size()b_n = b * n // 2y = x2.reshape(b_n, 2, h * w)y = y.permute(1, 0, 2)y = y.reshape(2, -1, n // 2, h, w)return torch.cat((y[0], y[1]), 1)class GSConvns(GSConv):# GSConv with a normative-shuffle https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=1, s=1, g=1, act=True):super().__init__(c1, c2, k=1, s=1, g=1, act=True)c_ = c2 // 2self.shuf = nn.Conv2d(c_ * 2, c2, 1, 1, 0, bias=False)def forward(self, x):x1 = self.cv1(x)x2 = torch.cat((x1, self.cv2(x1)), 1)# normative-shuffle, TRT supportedreturn nn.ReLU(self.shuf(x2))class GSBottleneck(nn.Module):# GS Bottleneck https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=3, s=1, e=0.5):super().__init__()c_ = int(c2*e)# for lightingself.conv_lighting = nn.Sequential(GSConv(c1, c_, 1, 1),GSConv(c_, c2, 3, 1, act=False))self.shortcut = Conv(c1, c2, 1, 1, act=False)def forward(self, x):return self.conv_lighting(x) + self.shortcut(x)class DWConv(Conv):# Depth-wise convolution classdef __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)class GSBottleneckC(GSBottleneck):# cheap GS Bottleneck https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=3, s=1):super().__init__(c1, c2, k, s)self.shortcut = DWConv(c1, c2, k, s, act=False)class VoVGSCSP(nn.Module):# VoVGSCSP module with GSBottleneckdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)# self.gc1 = GSConv(c_, c_, 1, 1)# self.gc2 = GSConv(c_, c_, 1, 1)# self.gsb = GSBottleneck(c_, c_, 1, 1)self.gsb = nn.Sequential(*(GSBottleneck(c_, c_, e=1.0) for _ in range(n)))self.res = Conv(c_, c_, 3, 1, act=False)self.cv3 = Conv(2 * c_, c2, 1) #def forward(self, x):x1 = self.gsb(self.cv1(x))y = self.cv2(x)return self.cv3(torch.cat((y, x1), dim=1))class VoVGSCSPC(VoVGSCSP):# cheap VoVGSCSP module with GSBottleneckdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2)c_ = int(c2 * 0.5) # hidden channelsself.gsb = GSBottleneckC(c_, c_, 1, 1)
# ---------------------------GSConv End---------------------------
YOLOFuse 添加方式
- 在
ultralytics/nn/modules/layers下新建一个GSConv.py, 将源代码加进去。 - 在
ultralytics/nn/tasks.py上方导包;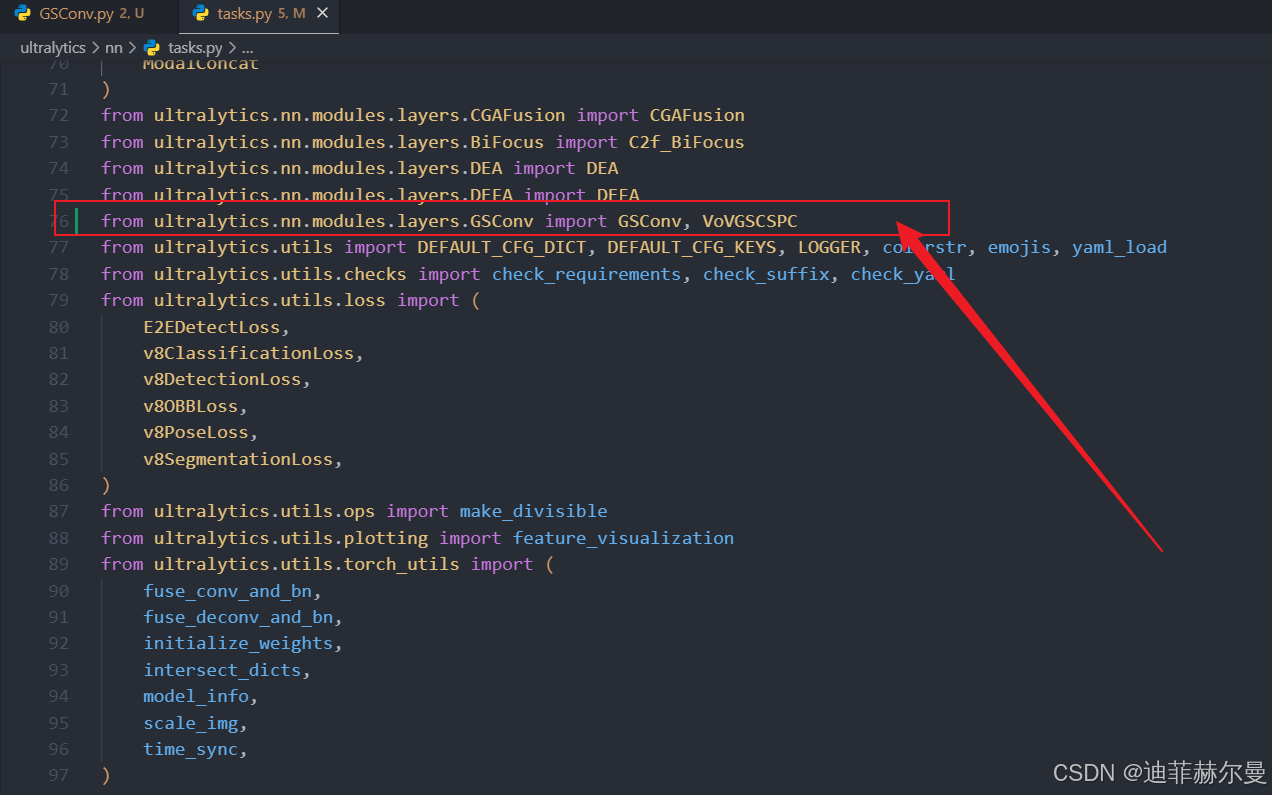
from ultralytics.nn.modules.layers.GSConv import GSConv, VoVGSCSPC
- 在
ultralytics/nn/tasks.py文件注册模块名。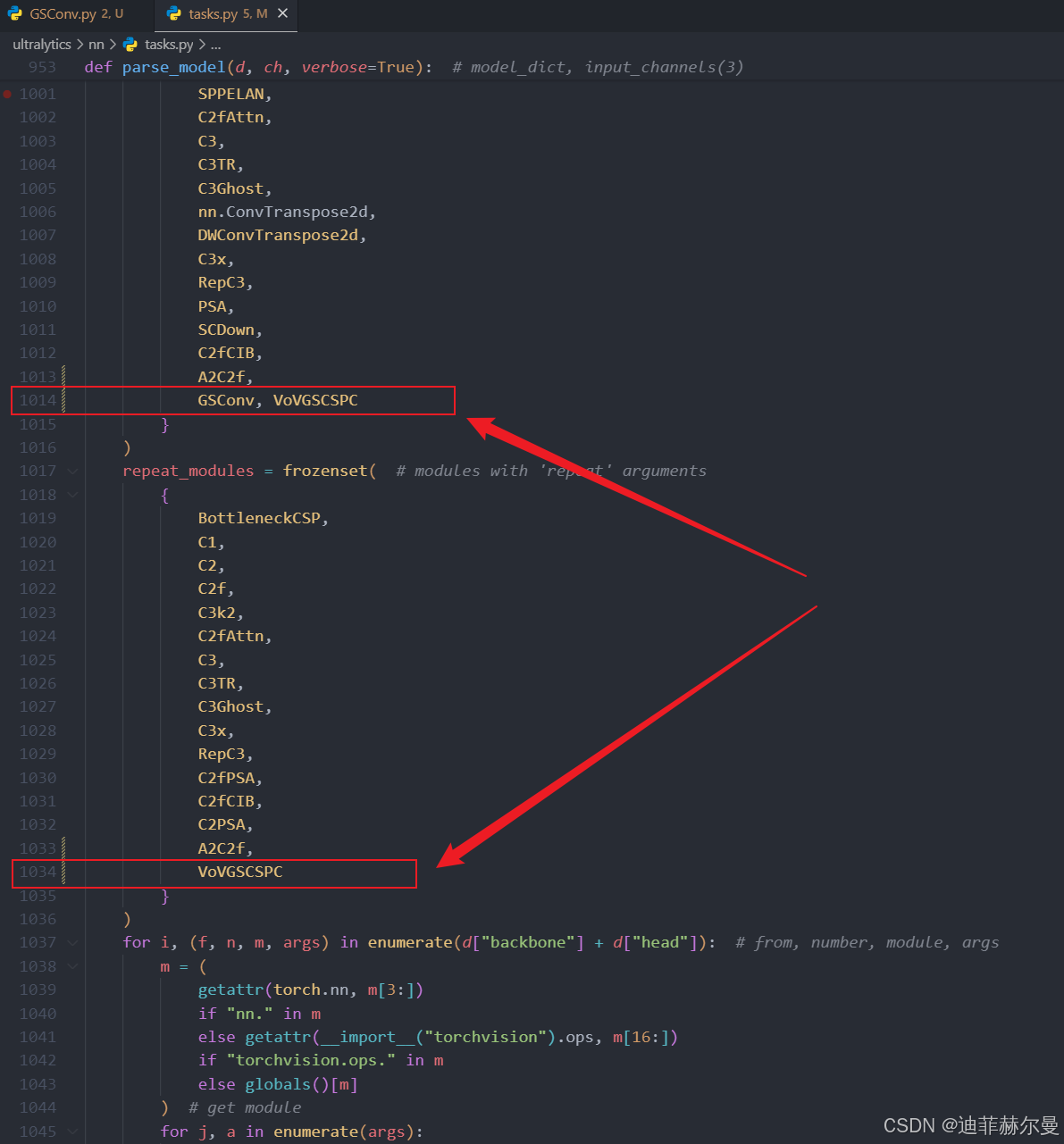
GSConv, VoVGSCSPC
4. 修改模型结构的 yaml 文件并启动训练
在 Slim-Neck 中包含两个核心模块:GSConv 与 VoVGSCSPC。这两个模块可灵活应用于自定义网络结构中,既可以单独加入其中一个,也可以同时引入两者。
-
GSConv 模块
建议在网络中直接用 GSConv 替换常规 Conv,并保持args参数一致。这种替换方式不仅适用于 Neck,同样也适用于 Backbone,能够在保持计算效率的同时提升特征融合能力。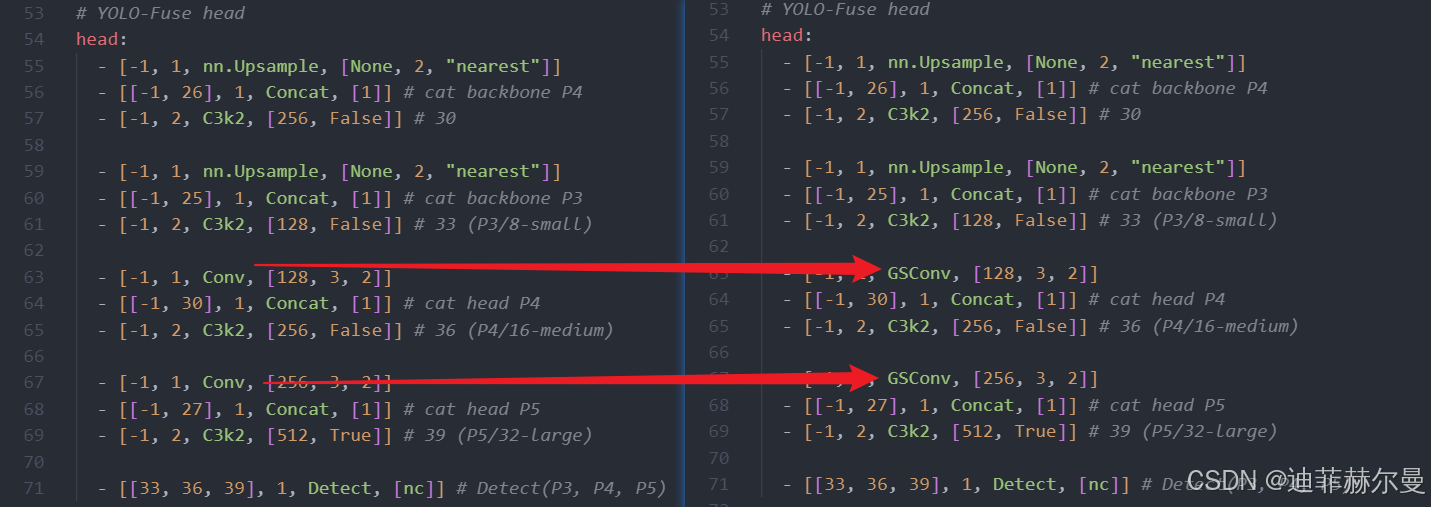
-
VoVGSCSPC 模块
建议用 VoVGSCSPC 模块替换 C3k2,同样保持args参数一致。这种替换能够增强中期特征的表达能力,提高网络的整体性能。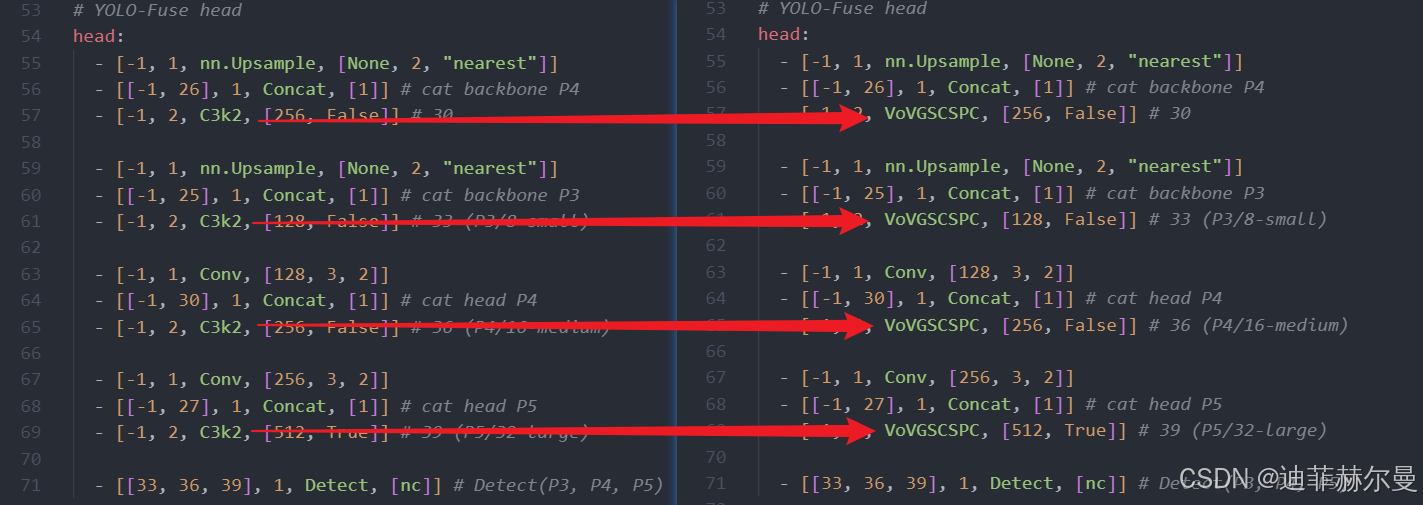
下面是一个融合了两个模块,且和原论文思想一致的案例,供大家参考:
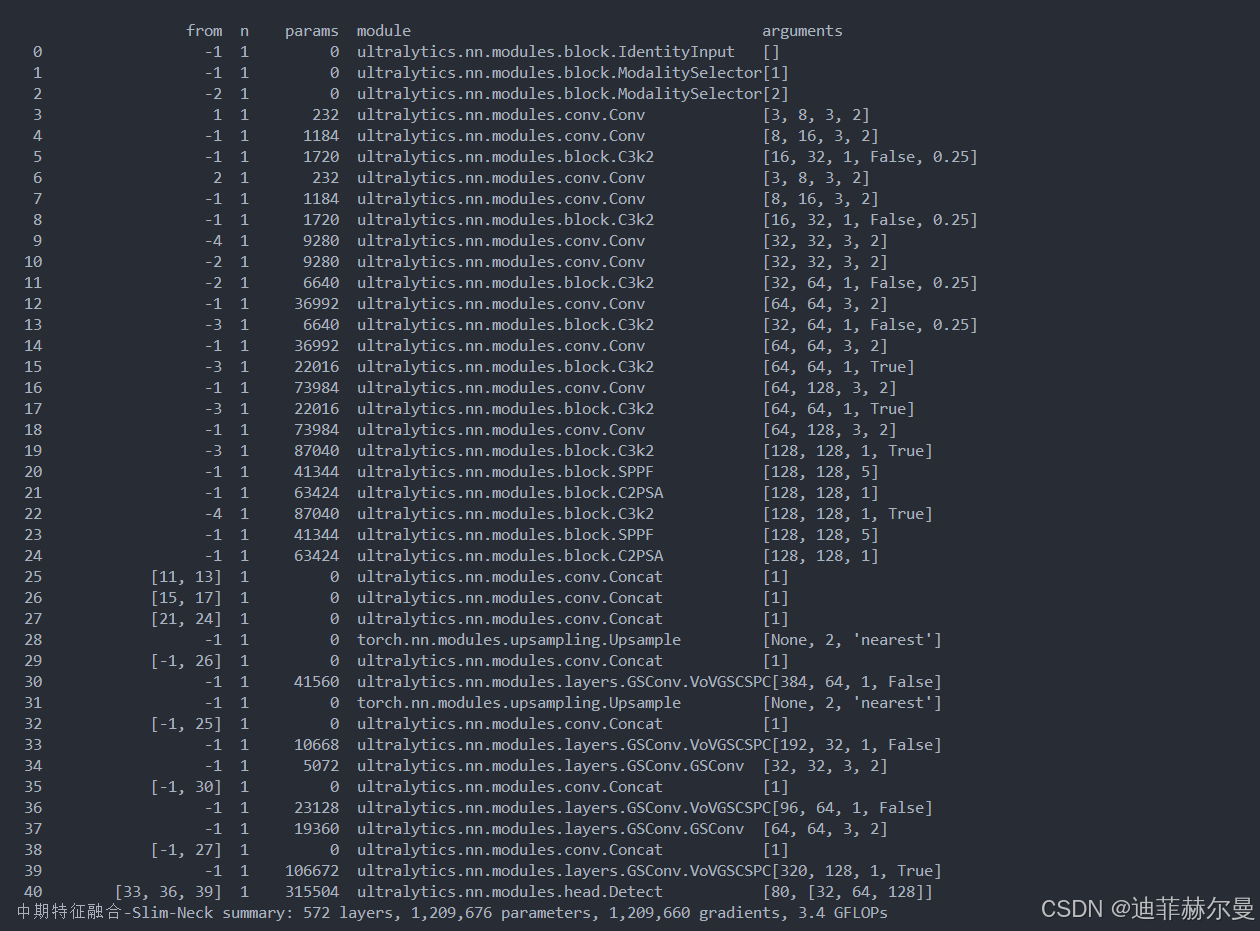
中期特征融合-Slim-Neck.yaml
# Parameters
ch: 6
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024]s: [0.50, 0.50, 1024]m: [0.50, 1.00, 512]l: [1.00, 1.00, 512]x: [1.00, 1.50, 512]backbone:# [from, repeats, module, args]- [-1, 1, IdentityInput, []] # 0- [-1, 1, ModalitySelector, [1]] # 1 RGB- [-2, 1, ModalitySelector, [2]] # 2 IR# YOLO-Fuse backbone# Visible branch- [1, 1, Conv, [32, 3, 2]] # 3-P1/2- [-1, 1, Conv, [64, 3, 2]] # 4-P2/4- [-1, 2, C3k2, [128, False, 0.25]]# Infrared branch- [2, 1, Conv, [32, 3, 2]] # 6-P1/2- [-1, 1, Conv, [64, 3, 2]] # 7-P2/4- [-1, 2, C3k2, [128, False, 0.25]]- [-4, 1, Conv, [128, 3, 2]] # 9-P3/8- [-2, 1, Conv, [128, 3, 2]] # 10-P3/8 # infrared- [-2, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 12-P4/16- [-3, 2, C3k2, [256, False, 0.25]] # infrared- [-1, 1, Conv, [256, 3, 2]] # 14-P4/16- [-3, 2, C3k2, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 16-P5/32- [-3, 2, C3k2, [256, True]] # infrared- [-1, 1, Conv, [512, 3, 2]] # 18-P5/32- [-3, 2, C3k2, [512, True]]- [-1, 1, SPPF, [512, 5]] # 20- [-1, 2, C2PSA, [512]] # 21- [-4, 2, C3k2, [512, True]] # infrared- [-1, 1, SPPF, [512, 5]] # 23- [-1, 2, C2PSA, [512]] # 24- [[11, 13], 1, Concat, [1]] # 25- [[15, 17], 1, Concat, [1]] # 26- [[21, 24], 1, Concat, [1]] # 27# YOLO-Fuse head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 26], 1, Concat, [1]] # cat backbone P4- [-1, 2, VoVGSCSPC, [256, False]] # 30- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 25], 1, Concat, [1]] # cat backbone P3- [-1, 2, VoVGSCSPC, [128, False]] # 33 (P3/8-small)- [-1, 1, GSConv, [128, 3, 2]]- [[-1, 30], 1, Concat, [1]] # cat head P4- [-1, 2, VoVGSCSPC, [256, False]] # 36 (P4/16-medium)- [-1, 1, GSConv, [256, 3, 2]]- [[-1, 27], 1, Concat, [1]] # cat head P5- [-1, 2, VoVGSCSPC, [512, True]] # 39 (P5/32-large)- [[33, 36, 39], 1, Detect, [nc]] # Detect(P3, P4, P5)