深度学习图解:神经网络如何学习?
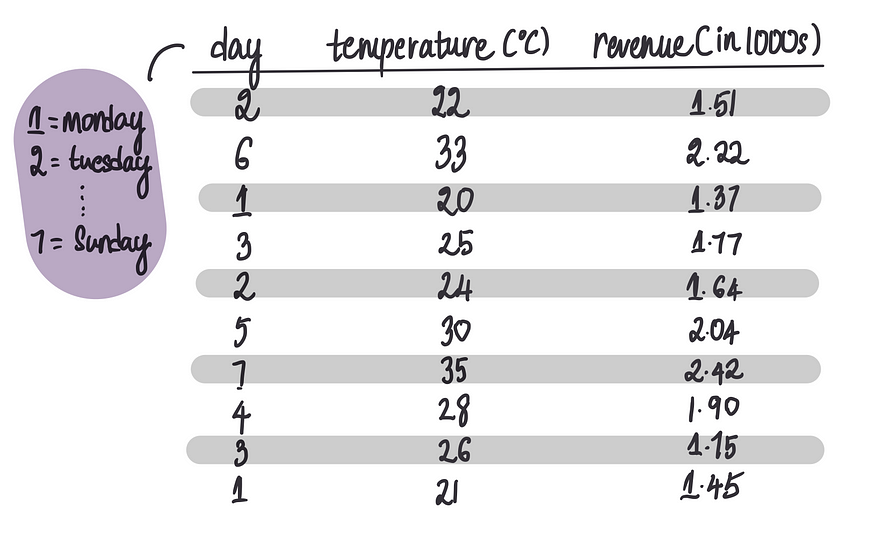
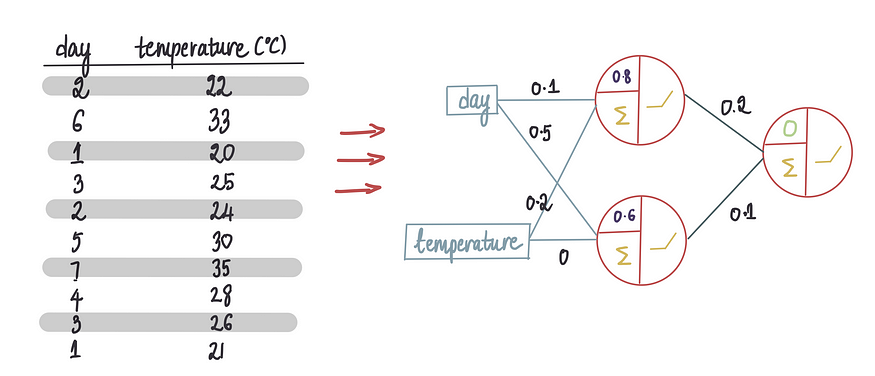
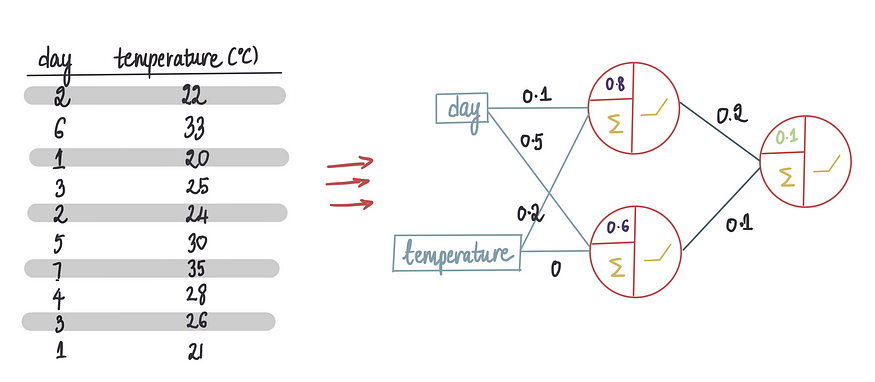
假设我们要创建一个神经网络,使用温度和星期几等特征来预测冰淇淋销售的每日收入。下面是训练数据集:
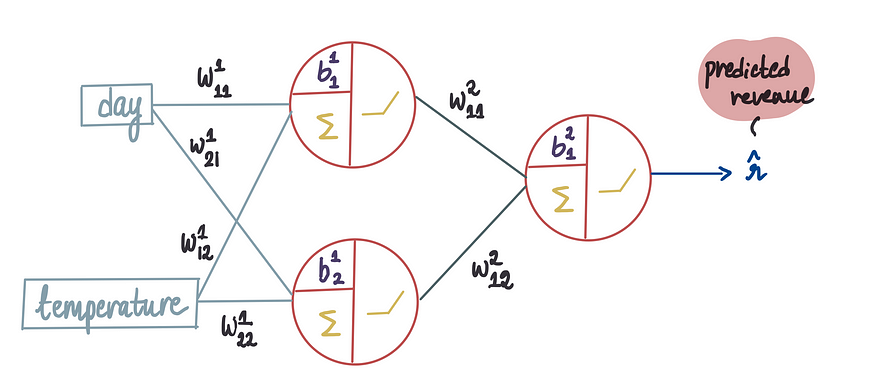
正如我们在上一篇文章中了解到的,要构建神经网络,我们首先需要确定其架构。这包括确定隐藏层的数量、每层的神经元数量以及每个神经元的激活函数。
假设我们确定的架构是:
1个隐藏层,有2个神经元,1格输出神经元,全部使用整流器激活函数。
tips:
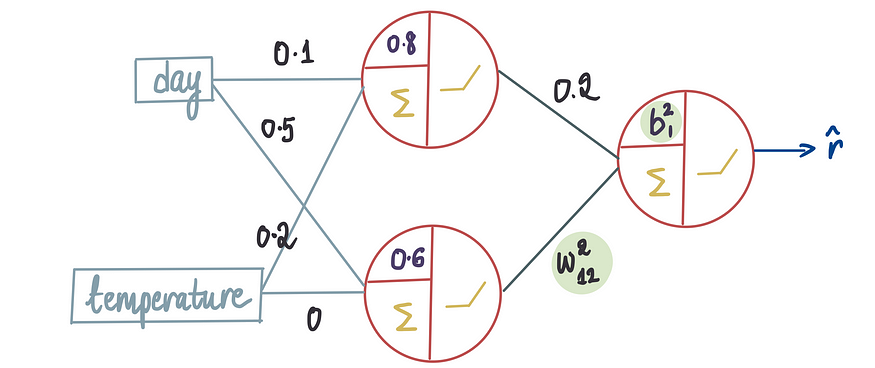
前面模型基础文章中,使用下标来区分不同的权重。本文将沿用相同的惯例,此外,我们还将使用上标来指示偏差和权重所属的层。因此,在上文中,我们可以看到,进入第一层神经元的权重以及该层中的偏差项都带有上标1。同时预测输出被表示为 r_hat,符号表示它是预测值,由于预测的是收入,使用r表示。
一旦我们确定了架构,就该通过输入一些数据来训练模型了。在此训练过程中,神经网络将学习权重和偏差项的最优值。假设在使用上述训练数据训练模型后,它产生了以下最优值:
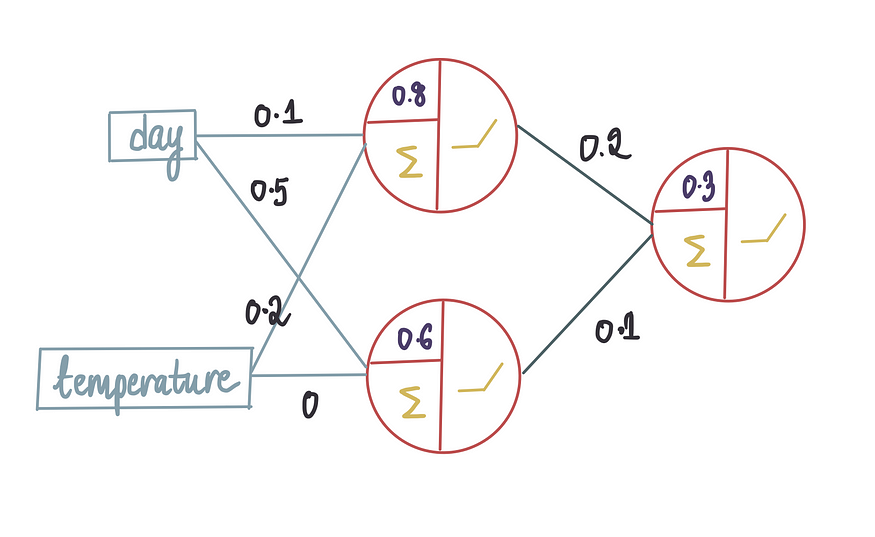
本文将重点介绍我们如何得出这些最佳值。假设已经获得了除了外层神经元的偏置项之外的所有最优值:
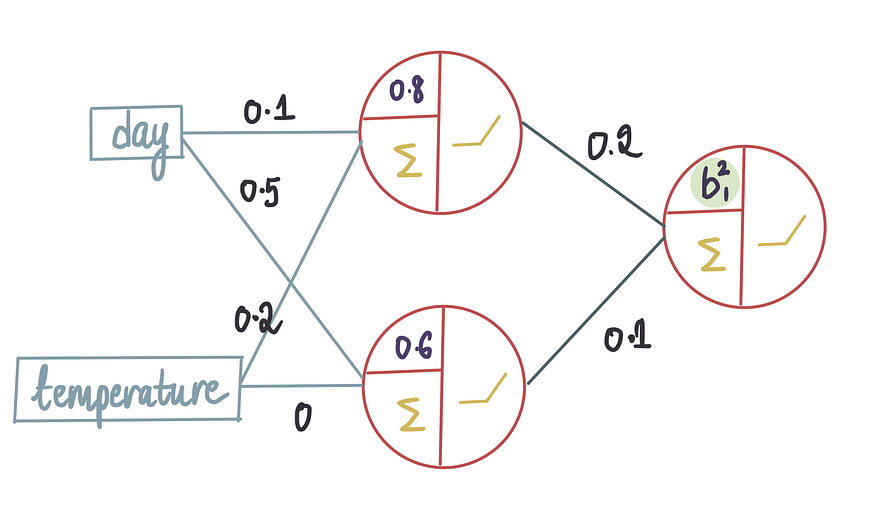
由于不知道偏差的确切值,首先进行初始猜测并将该值设置为0,通常,偏差值在开始时初始化为 0:
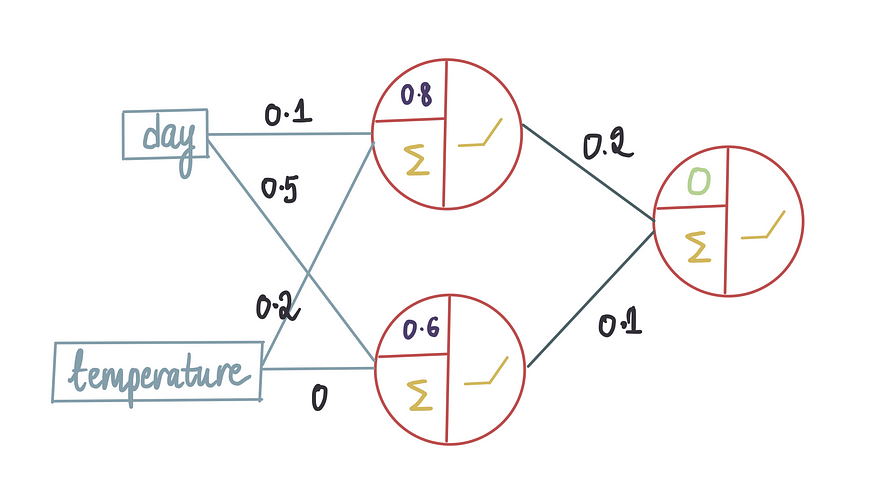
现在需要输入所有冰淇淋店的特征来进行收入预测(也就是前向传播),假设最后一个偏差项为 0。接着将 10 行训练数据传递到神经网络中:
预测结果如下:
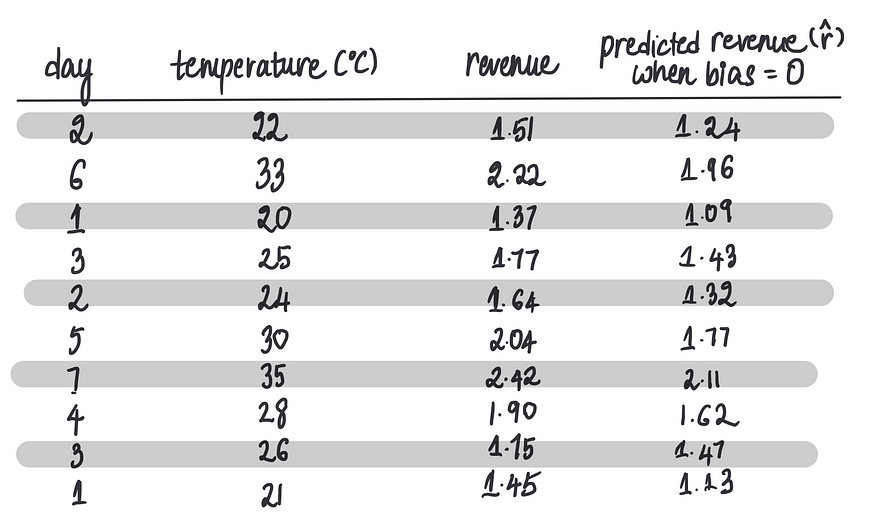
现在,当最后一个偏差项等 0时,我们得到了预测结果,可以将其与实际收入进行比较。前面文章中提到过,可以使用成本函数来衡量预测的准确性,特别是对于我们的用例,可以使用均方误差 (MSE):
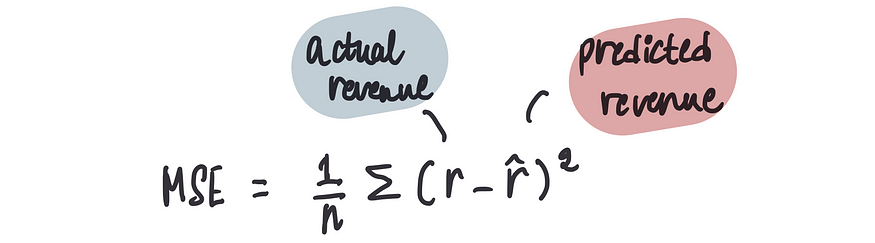
计算偏差为 0 的该模型的 MSE:
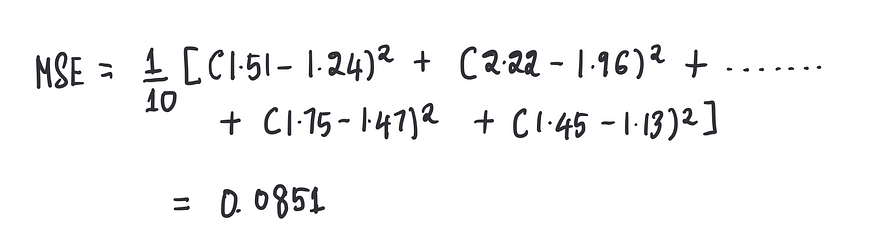
另外,任何模型的最终目标都是降低MSE。因此,现在的目标是找到一个最小化MSE的最优偏差值。
比较不同偏差值下的MSE值的一种方法是强制执行,并尝试对最后一个偏差项使用不同的值。例如,让我们对偏差项进行第二次猜测,使其略高于最后一个0的值。接下来,让我们尝试偏差=0.1。
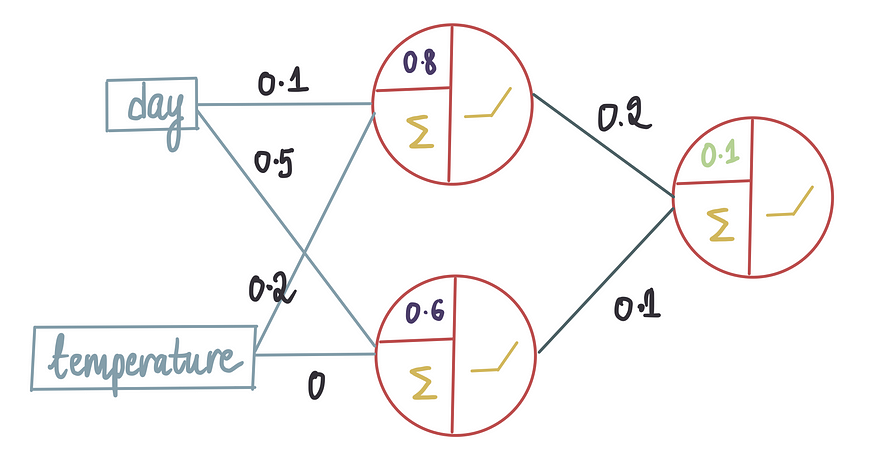
我们将训练数据传递给偏差 = 0.1 的新模型:
基于此产生的预测结果如下:
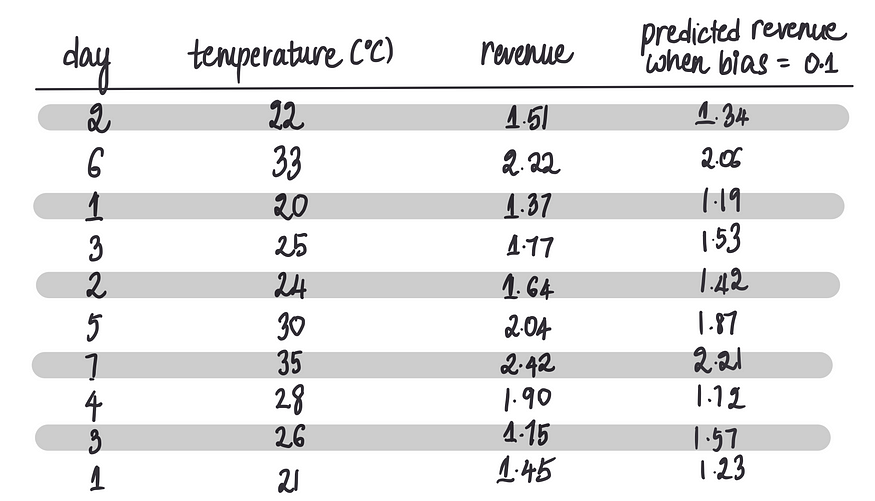
计算 MSE:
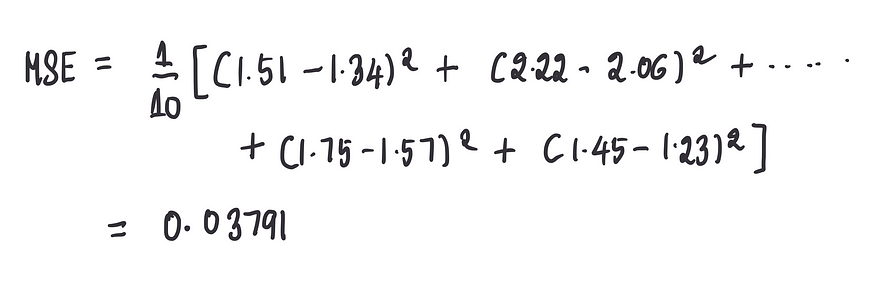
我们可以看到,当偏差设置为0时,该模型的MSE(0.03791)略优于之前的MSE(0.08651)。为了更清楚地显示这一点,通过图形化展示如下值:
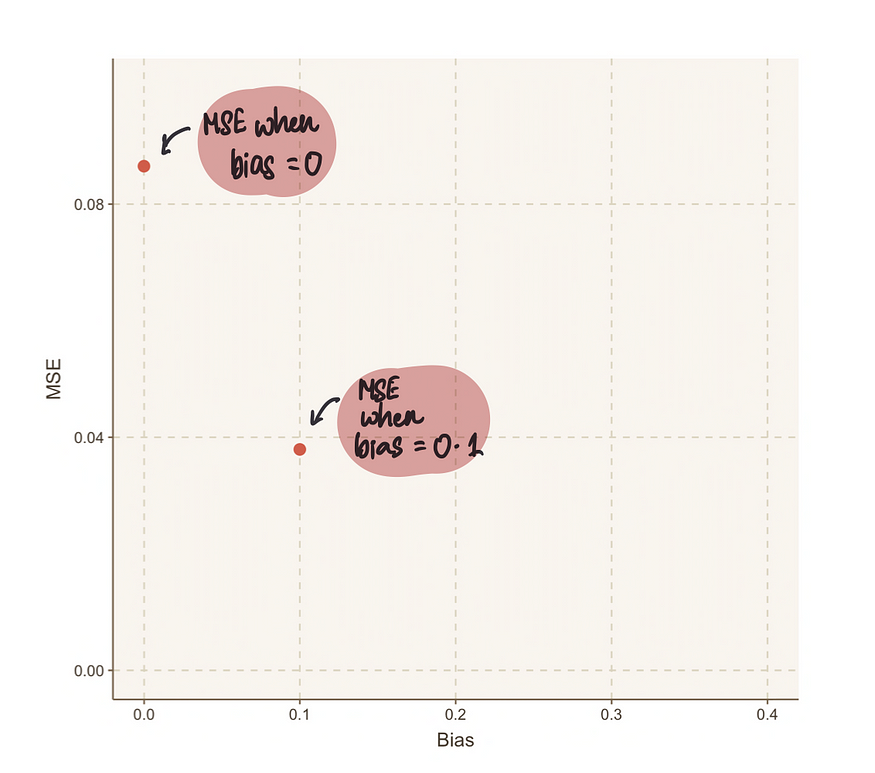
我们可以继续使用这种暴力破解方法,猜测数值。
假设我们又猜测了 4 个值:bias = 0.2、0.3、0.4 和 0.5。
重复上述过程,生成如下所示的 MSE 图表:
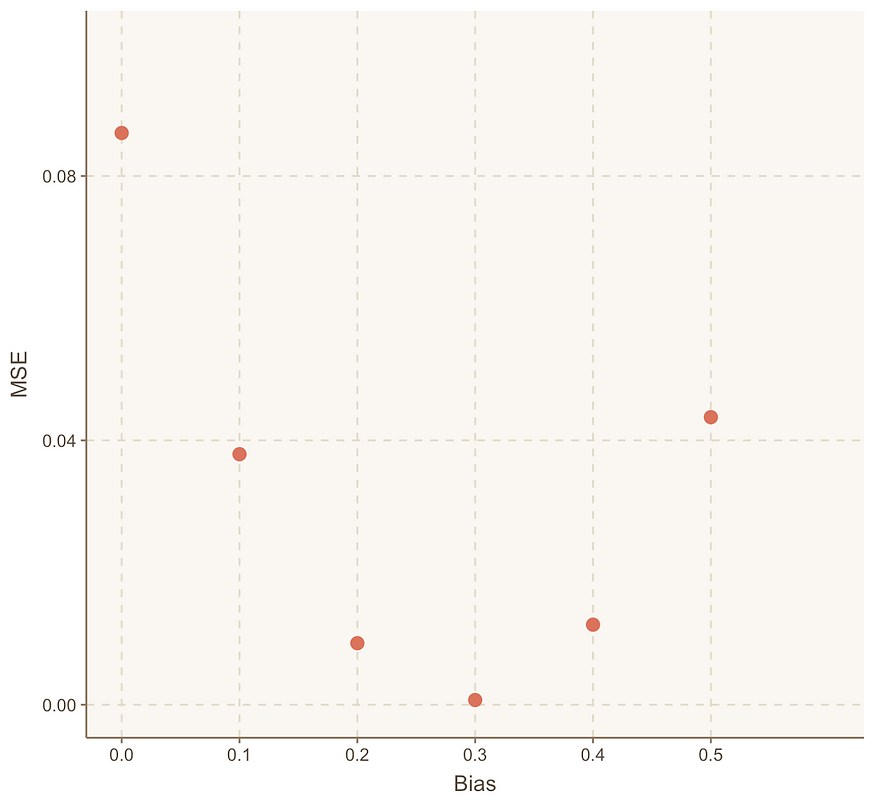
但需要注意:当bias = 0.3时,MSE最低。而当bias = 0.4时,MSE又开始增加。
这表明模型在bias = 0.3时最小化了MSE。
幸运的是能够通过几次合理的猜测来确定这一点,并通过额外的尝试来确认。
但是,如果最优 MSE 值为 100 呢?在这种情况下,需要进行 1000(100 x 10)次猜测才能达到这个值。
因此,这种方法对于寻找最优偏差值来说效率不高。此外如何确定 MSE 值最低的偏差恰好是 0.3?如果它是 0.2998 或 0.301 呢?使用这种暴力破解技术很难做出这样的精确猜测。
引入梯度下降。
通过使用梯度下降并利用导数,可以高效地到达任何凸曲线(本质上是 U 形曲线)的最低点。这在当前情况下非常理想,因为上面的MSE图类似于U形曲线,需要找到MSE最小的谷底。梯度下降通过指示每一步所需的大小和方向来指导我们,以便尽快到达曲线的底部。现在让我们重新开始使用梯度下降法的步骤寻找最佳偏差的过程。
步骤 1:从偏差的随机初始值开始
比如先从从偏差 = 0 开始:
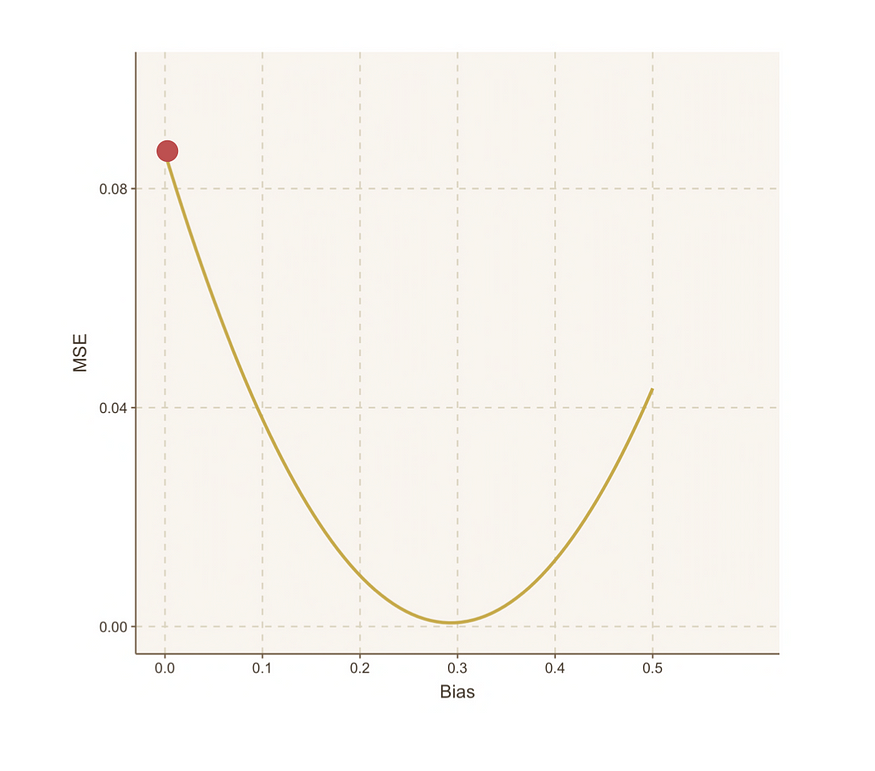
步骤 1:计算步长的步长
接下来,我们需要确定迭代的方向和步长。这可以通过计算步长来实现,步长是将学习率乘以偏差值处 MSE 的梯度所得的结果。在本例中,本次迭代的偏差值为 0。

其中学习率是一个用于控制步长的常数。通常,它介于 0 到 1 之间。
在这里更仔细地检查一下导数值。MSE 是r_hat的函数,如公式所示:
且r_hat由最后一个神经元中的 relu 函数决定,因为我们只能利用激活函数来获得 r_hat:
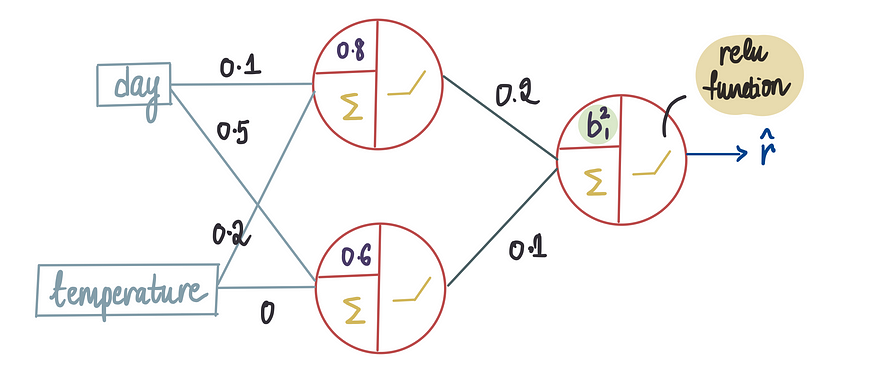
最后一个神经元中的relu函数包含偏置项。
现在,如果想要计算MSE对偏差的导数,将使用链式法则,这是微积分的一个超级组成部分,它利用了上述3个关键信息:
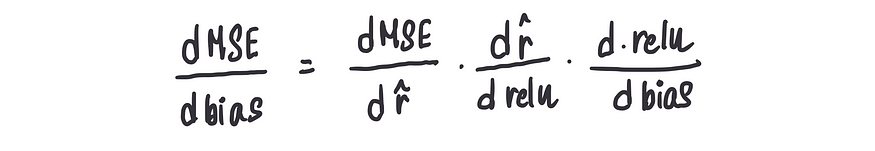
我们需要使用链式法则,因为这些项彼此依赖,但并非直接相关。之所以称之为链式法则,是因为它们都以链状结构连接在一起。我们几乎可以想象分子和分母互相抵消。
这就是我们计算 MSE 对偏差的导数的方法。我们在当前偏差值 (0) 处计算该导数。
步骤3:使用上述步长更新偏差值

这将提供一个新的偏差值,希望使结果更接近最佳偏差值:
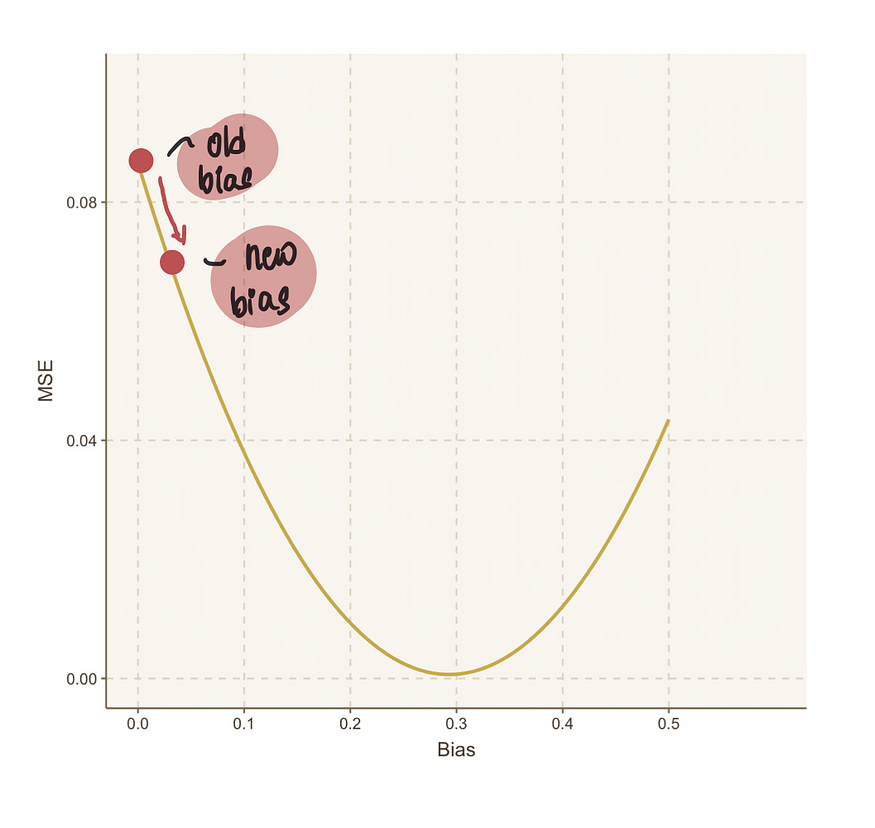
步骤 4:重复步骤 2-3,直到达到最优值
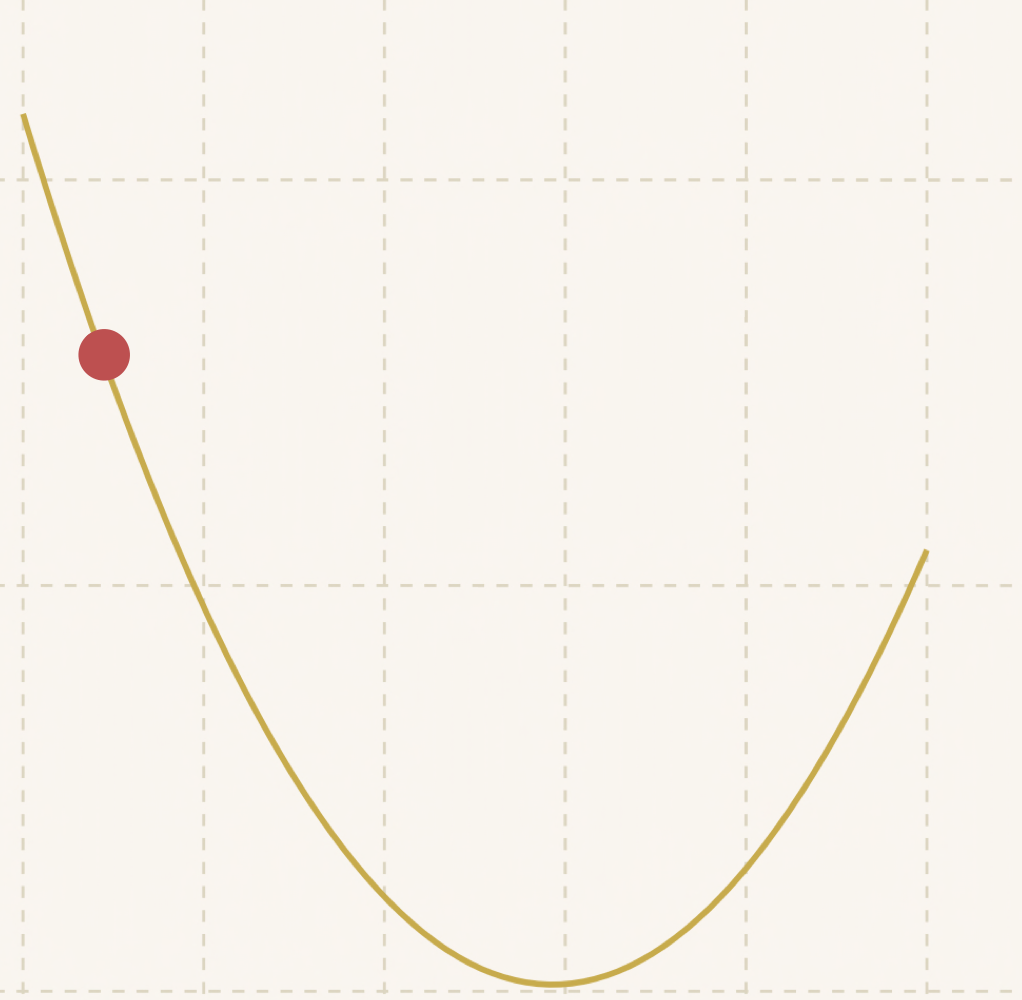
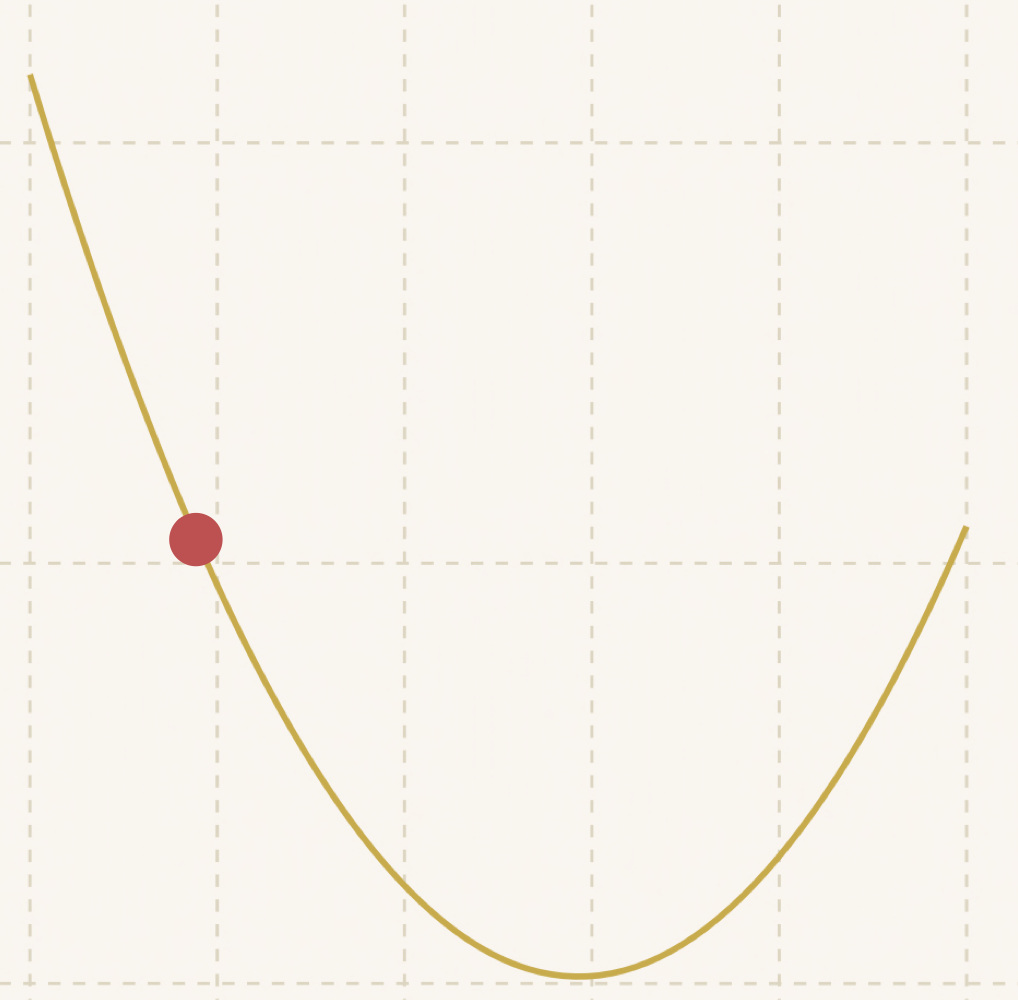
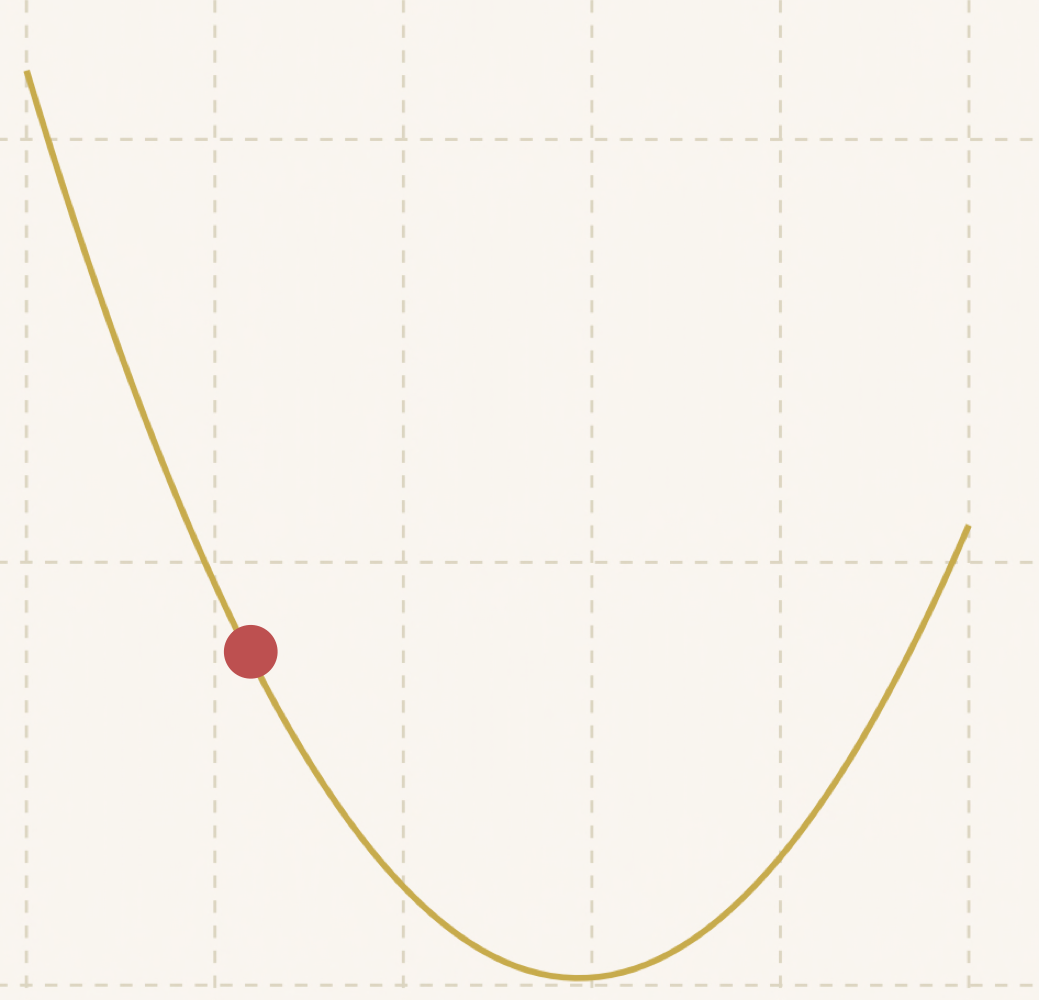
可以看到随着距离底部越来越近,步子也越来越小:
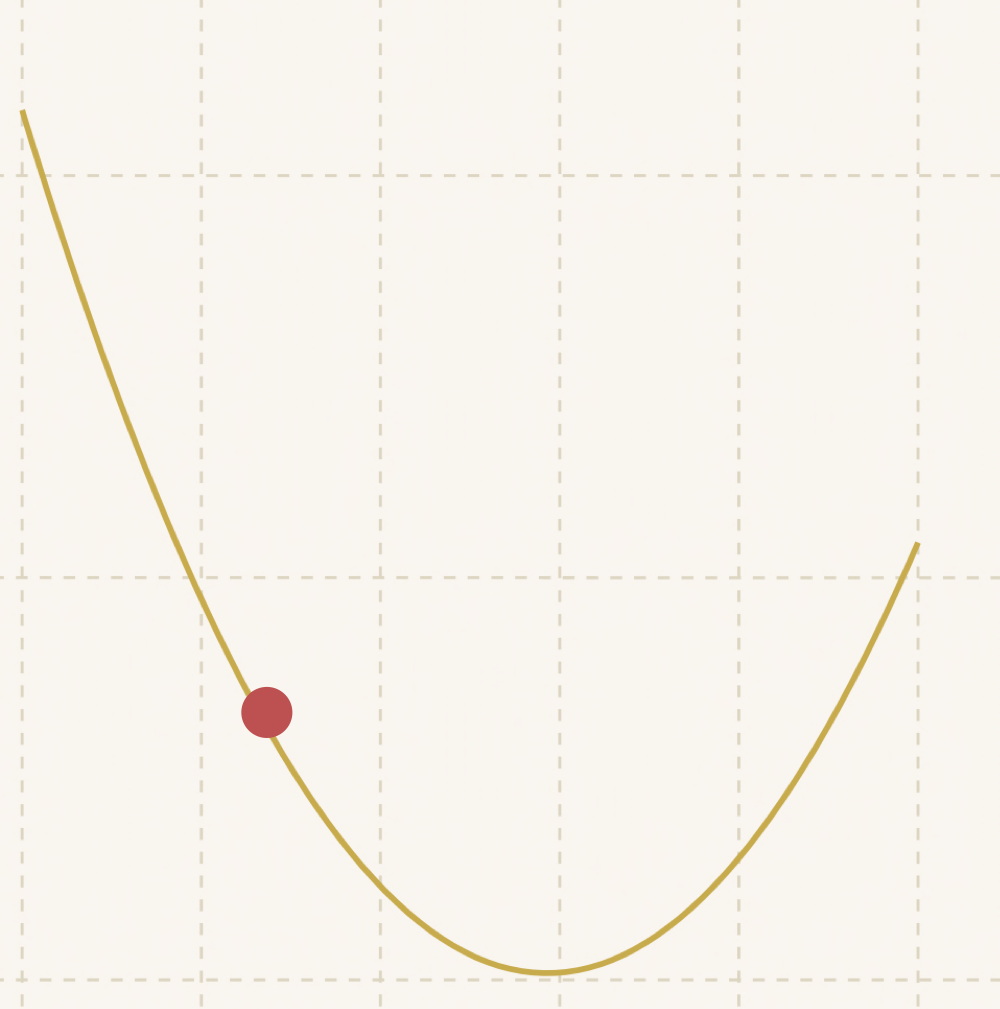
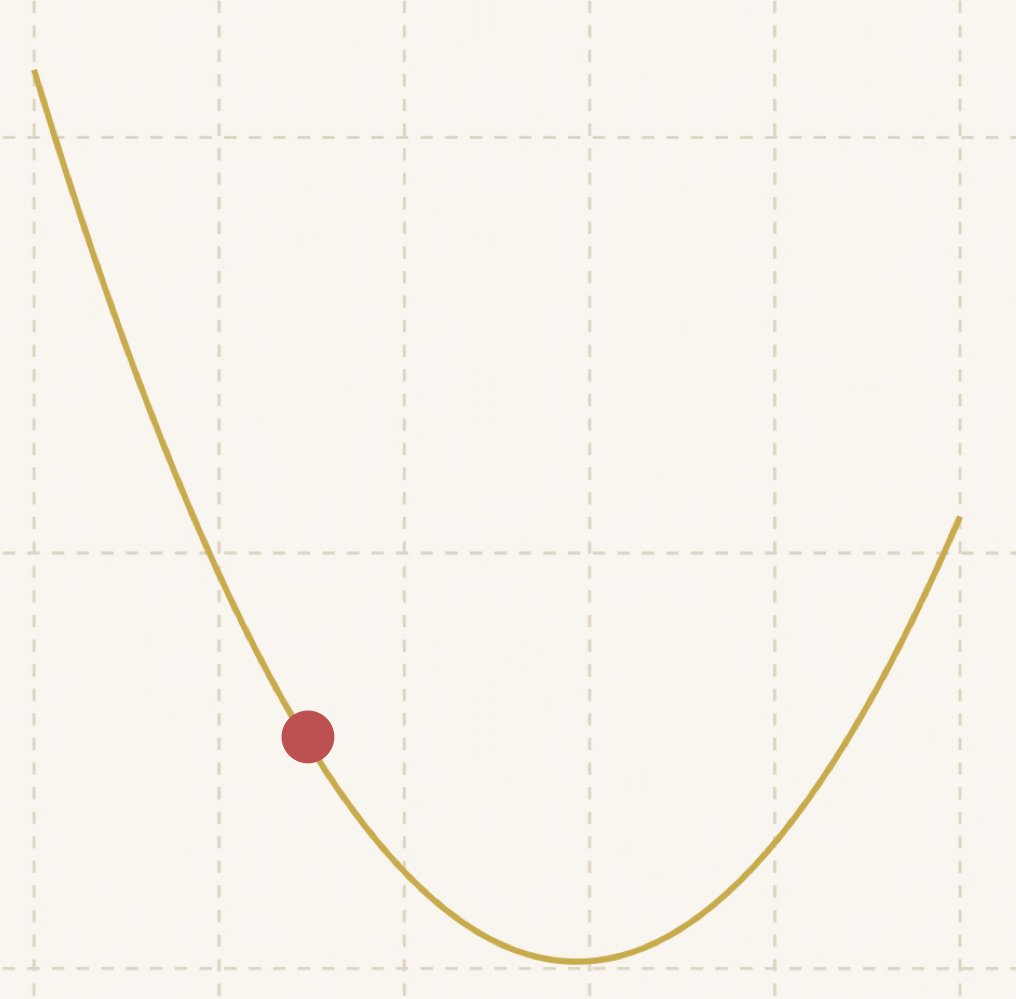
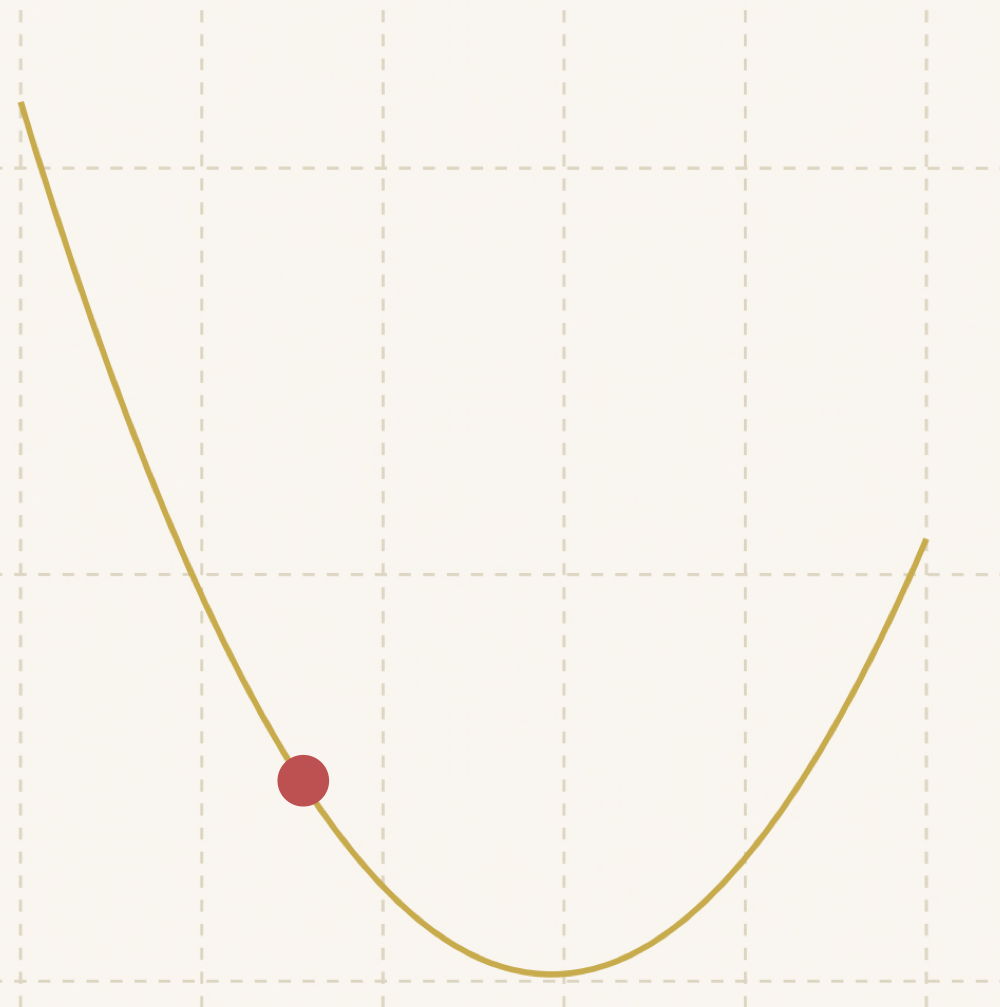
最后:
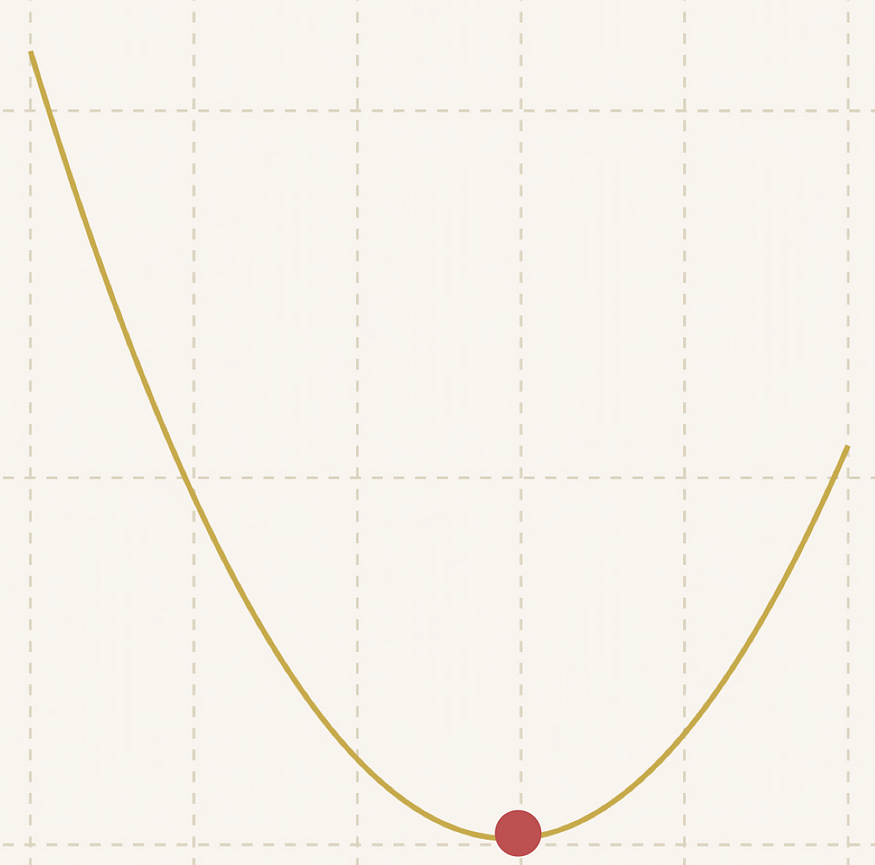
达到了最优值!
注意:当步长接近 0 或达到我们在算法中设置的最大步数时,我们就达到了最佳值。
完美。假设其他变量的最优值已知,我们就能这样找到偏差项了。
术语:确定偏差项值的过程称为反向传播。前面文章重点介绍了前向传播,即传递输入以获得输出。之所以称为前向传播,是因为我们实际上是将输入向前传播。而这个过程之所以称为反向传播,是因为我们向后移动以更新偏差值。
现在,让我们更进一步,考虑这样一种情况,我们知道除了偏差项和进入最后一个神经元的第二个输入的权重之外的所有最优值。
再次,我们需要找到这两个项的最优值,以使 MSE 最小化。针对不同的权重和偏差值,我们绘制一个 MSE 图。该图与上面显示的类似,但是是三维的。
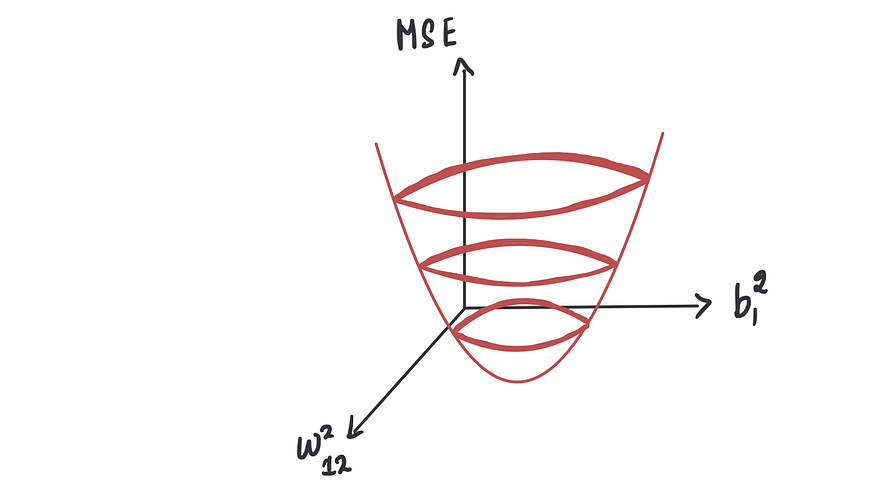
与之前的 MSE 曲线类似,我们需要找到使 MSE 最小化的点。这个点被称为谷点,它将为我们提供偏差和权重项的最优值。同样,我们可以利用梯度下降来达到这个最小值点。这个过程本质上也是一样的。
步骤 1:随机初始化权重和偏差的值
步骤 2:使用偏导数计算步长

这里出现了一个轻微的偏差。我们不再计算 MSE 的导数,而是计算偏导数,并同时更新步长。“同时”的意思是,需要在当前权重和偏差值下计算部分梯度的值,我们再次使用链式法则:
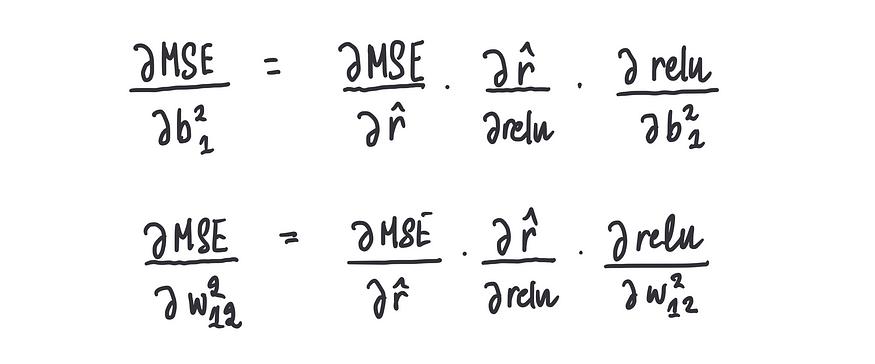
步骤 3:同时更新权重和偏差项
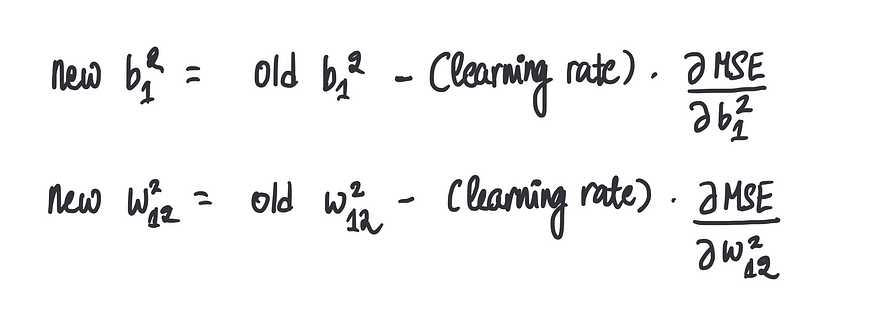
步骤 4:重复步骤 2-3,直到收敛到最优值
我们可以对此进行疯狂的操作。现在,如果我们想优化神经网络中的所有 9 个值,该怎么办?
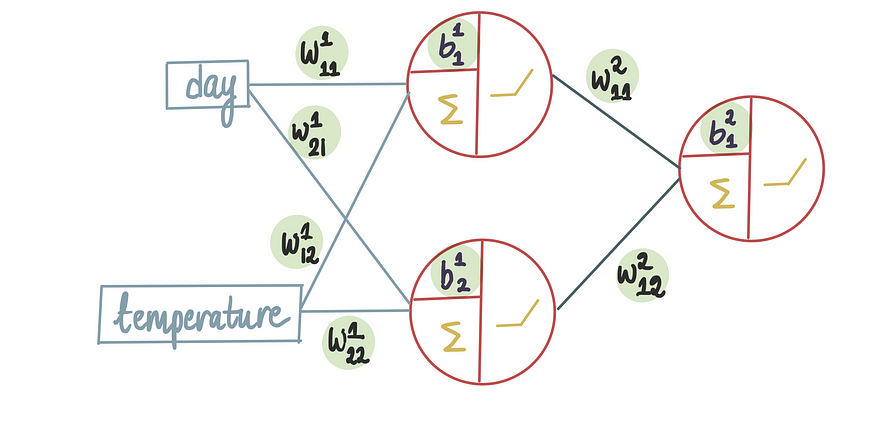
然后,我们将有 9 个联立方程需要更新才能达到最小值。(甚至无法尝试绘制这个 MSE 函数,因为正如你所想象的,或者更确切地说,无法想象的,这将是一个看起来很疯狂的图表)
尽管随着联立方程数量的增加,手工计算变得越来越复杂,但概念依然不变。我们试图逐渐向谷底移动,依靠梯度下降来指引我们。
通过应用上面讨论的方程和优化程序,数据的隐藏模式自然显现出来。这使我们能够在无需任何人工干预的情况下找到这些深层模式。
好的,总结一下,我们现在明白了,我们总是希望最小化成本函数(在上述情况下为 MSE),以及如何使用梯度下降获得最小化 MSE 的权重和偏差项的最优值。
我们了解到,利用梯度下降,我们可以轻松地遍历凸形曲线到达底部。幸运的是,在我们的案例研究中,我们得到了一条漂亮的凸曲线。然而,有时我们可能会遇到一个成本函数,它并不能产生完美的凸曲线,而是产生类似这样的曲线。
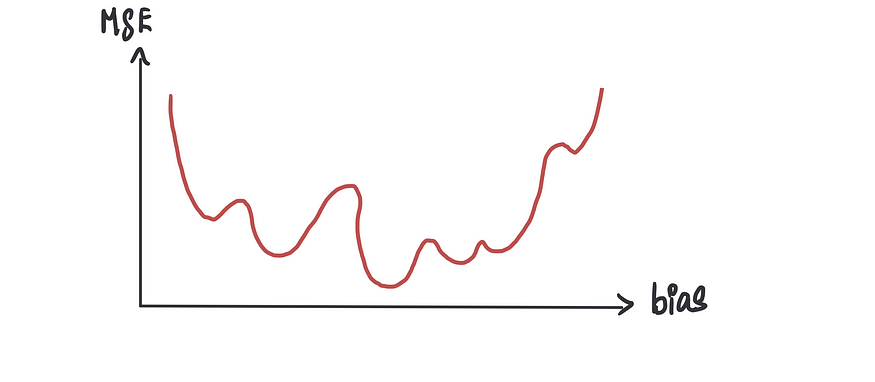
如果我们使用梯度下降,有时我们可能会错误地将众多局部最小值(看起来是最小值点但实际上不是的点)中的一个识别为最小值点,而不是全局最小值(实际的最小值点)。
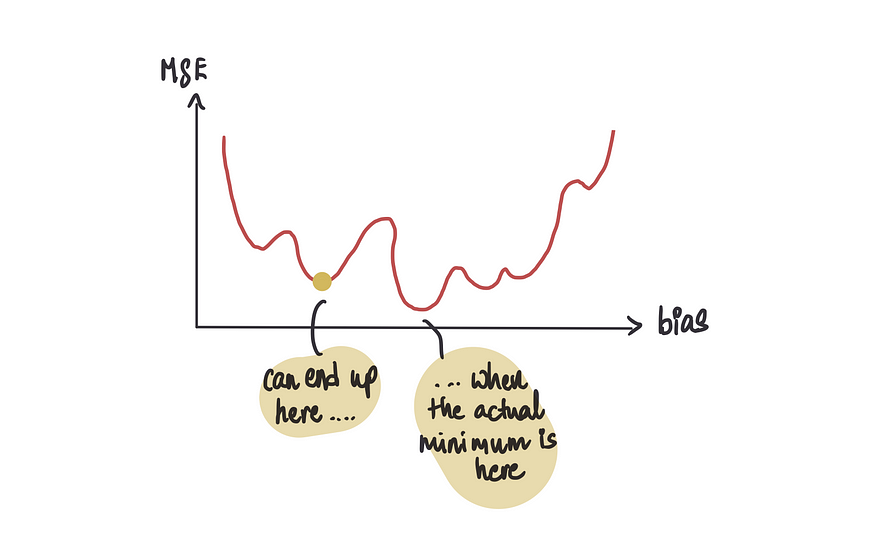
梯度下降的另一个问题是,随着数据集中数据点的数量或项的数量的增加,执行梯度下降所需的时间也会增加。这是因为所涉及的数学变得更加复杂。
在我们的小示例中,我们有 10 个数据点(这非常不切实际;通常我们有数十万个数据点),并且我们试图优化 9 个参数(根据架构的复杂程度,这个数字也可能非常高)。目前,对于梯度下降的每次迭代,我们使用 10 个数据点来计算偏导数并更新 9 个参数值。
这本质上就是梯度下降所做的事情:
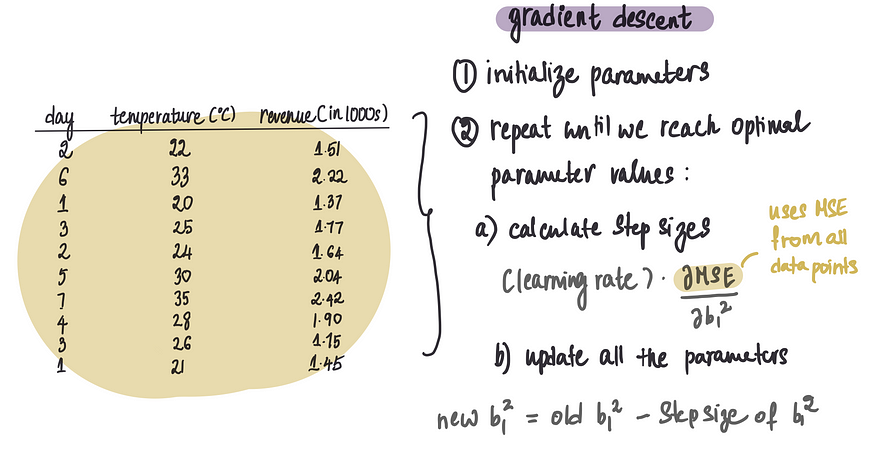
在每次迭代中,我们执行大约 90 (9*10) 次小计算来计算每个数据点的 MSE 导数。通常,我们会像这样执行 1000 次迭代,总共进行 90,000 (90*1000) 次计算。
但是,如果我们有 10 万个数据点,而不是 10 个呢?在这种情况下,我们需要计算所有 10 万个数据点的均方误差 (MSE),并对 90 万(= 9*10 万)项求导。通常,我们需要执行大约 1000 步梯度下降才能达到最优值,这会导致惊人的 9 亿(90 万*1000)次计算。此外,我们的数据可能会变得更加复杂,包含数百万个数据点和大量需要优化的参数。这很快就会变得非常具有挑战性。
为了避免这个问题,我们可以利用更快、更强大的替代优化算法。
随机梯度下降
随机梯度下降 (SGD) 与梯度下降类似,但有细微的差别。在梯度下降中,我们在计算包含所有 10 个值的整个训练数据集的 MSE 后更新我们的值。然而,在 SGD 中,我们仅使用数据集中的一个数据点来计算 MSE。
该算法随机选择单个数据点并使用它来更新参数值,而不是使用整个数据集。

这是一个更轻量的算法,比包罗万象的算法更快。
小批量梯度下降
这种方法结合了原始梯度下降法和随机梯度下降法。我们不是仅基于一个数据点或整个数据集来更新值,而是每次迭代处理一批数据点。我们可以将批次大小设置为 5、10、100、256 等。
例如,如果我们的批量大小为 4,我们将根据 4 行数据计算偏导数的 MSE。

在处理梯度下降时,除了大数据问题和局部最小值问题之外,还有学习率,学习率是在模型构建过程开始时设定的一个常数项。学习率的选择极大地影响了梯度下降的性能。如果我们将学习率设置得太低,我们可能永远无法收敛到最优值;如果我们将其设置得太高,我们可能会超出我们的步长并偏离最优值。实际上,存在一个折衷方案。
现在的问题是,我们如何找到这个学习率?有两个思路:
尝试多种不同的学习率,看看哪种效果最好
设计一个自适应学习率,以“适应”我们的神经网络并适应我们的 MSE 环境。
我也准备了三个月从零入门深度学习的籽料包,可以让你很好系统的入门到AI这个行业来:
【1.超详细的人工智能学习大纲】:一个月精心整理,快速理清学习思路!
【2.基础知识】:Python基础+高数基础
【3.机器学习入门】:机器学习经典算法详解
【4.深度学习入门】:神经网络基础(CNN+RNN+GAN)
【5.项目实战合集】:34个机器学习+36深度学习项目实战

这正是其他优化算法的目标。然而,详细讨论它们需要另写一篇文章。如果您感兴趣,可以参考这篇文章,其中深入探讨了一些流行的算法。