【CUDA教程--3】通过简单的矩阵运算入门CUDA
本文将通过一个简单的运算,来说明一个cuda程序的基本框架,读者读完后应能写一些简单的cuda代码。
本文的代码将实现这样的一个功能:读取一张灰度图片,图片像素值将会存储在一个矩阵内。通过cuda代码将图片中的灰度值全部设置为原来的1/2。
本文将会用到OpenCV库。OpenCV的安装和配置也十分简单。这里不做赘述,参考我的这篇文章:https://blog.csdn.net/ahhxxttxs/article/details/150452627?spm=1011.2415.3001.5331
相信看过这篇文章以及Windows下cuda的安装和配置的同学已经会用CMake构建工程了。
先直接上代码:
代码及程序运行结果
CMakeListx.txt:
##要求最低cmake程序版本
cmake_minimum_required(VERSION 3.20)#本工程的名字
project(CUDAARTICLEPROJECT CUDA CXX)# 设置 CUDA 架构
set(CMAKE_CUDA_ARCHITECTURES 89)
# 设置 C++ 标准
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 设置 CUDA 标准
set(CMAKE_CUDA_STANDARD 14)
set(CMAKE_CUDA_STANDARD_REQUIRED ON)set(OpenCV_DIR "C:/opencv/build") # 替换为你的路径
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})file(GLOB SRC_CPP ${CMAKE_CURRENT_SOURCE_DIR}/*.cpp)
file(GLOB SRC_CUDA ${CMAKE_CURRENT_SOURCE_DIR}/*.cu)
file(GLOB SRC_H ${CMAKE_CURRENT_SOURCE_DIR}/*.h)
# 添加可执行文件
add_executable(${PROJECT_NAME} ${SRC_CPP} ${SRC_CUDA} ${SRC_H})
target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS})
# Windows需额外设置库目录
if(WIN32)link_directories("${OpenCV_DIR}/x64/vc16/lib")
endif()
# 添加 CUDA 头文件路径
target_include_directories(${PROJECT_NAME} PRIVATE"C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.9/include"
)
target_include_directories(${PROJECT_NAME} PRIVATE "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.9/lib/x64"
)
# 设置 CUDA 分离编译
set_target_properties(${PROJECT_NAME} PROPERTIES CUDA_SEPARABLE_COMPILATION ON
)
kernal.h
void test(float *img, int cols, int rows);
kernal.cu
#include <cuda_runtime.h>
#include <stdio.h>
#include <device_launch_parameters.h>
#include "kernal.h"#ifdef _DEBUG
#define CUDA_CHECK(call) \do \{ \cudaError_t err = (call); \if (err != cudaSuccess) \{ \fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err)); \fprintf(stderr, "pos: file %s, line %d\n", __FILE__, __LINE__); \fprintf(stderr, "code: %d\n", err); \cudaDeviceReset(); \return; \} \} while (0)
#else
#define CHECK_CUDA(call) (call)
#endif__global__ void imgProcess(float* img, int cols, int rows)
{ int idx_x = blockDim.x * blockIdx.x + threadIdx.x;int idx_y = blockDim.y * blockIdx.y + threadIdx.y;if (idx_x < cols && idx_y < rows){int idx = idx_y * cols + idx_x;img[idx] /= 2;}
}void test(float* img, int cols, int rows)
{dim3 block(32, 32);dim3 grid((cols + block.x - 1) / block.x, (rows+block.y-1)/block.y);float* img_dev = NULL;CUDA_CHECK(cudaMalloc((void **)&img_dev, cols * rows * sizeof(float)));CUDA_CHECK(cudaMemcpy(img_dev, img, cols * rows * sizeof(float), cudaMemcpyHostToDevice));imgProcess<<<grid, block>>>(img_dev, cols, rows);CUDA_CHECK(cudaGetLastError());CUDA_CHECK(cudaMemcpy(img, img_dev, cols * rows * sizeof(float), cudaMemcpyDeviceToHost));cudaFree(img_dev);cudaDeviceReset();return ;
}
main.cpp
#include <opencv2/opencv.hpp>
#include "kernal.h"
int main()
{cv::Mat img = cv::imread("C:\\Users\\libai\\Desktop\\test.jpg", cv::IMREAD_GRAYSCALE);//以单通道灰度的方式读取图片到一个矩阵中cv::Mat imgClone = img.clone(); //必须用clone方法,赋值运算符对cv::Mat来说是浅拷贝img.convertTo(img, CV_32FC1); //灰度值转换成32位浮点数float *img_data = (float *)malloc(img.cols * img.rows * sizeof(float));memcpy(img_data, img.data, img.cols * img.rows * sizeof(float));test(img_data, img.cols, img.rows); // 调用kernal.cu中的函数memcpy(img.data, img_data, img.cols * img.rows * sizeof(float));img.convertTo(img, CV_8UC1);//灰度值转换回8位无符号整型,防止无法显示图片cv::namedWindow("原图", cv::WINDOW_AUTOSIZE); // 用一个窗口显示图片cv::imshow("原图", imgClone);cv::namedWindow("处理后的图", cv::WINDOW_AUTOSIZE);cv::imshow("处理后的图", img);cv::waitKey(0);cv::destroyAllWindows();
}
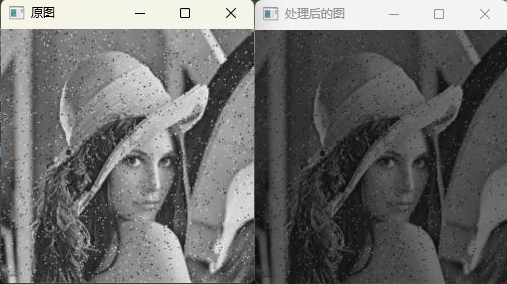
运行代码后OpenCV会弹出如下窗口显示图片,可以看到,处理后的图像变暗了,这正是我们预期的结果。
CUDA代码分析
main.cpp中大部分是OpenCV的代码,直接看注释即可,这里主要分析kernal.cu中的代码。本文中,设备 == GPU,主机 == CPU;
头文件
头文件中包含了cuda_runtime.h, 大部分cuda的API都出自这个头文件。包含device_launch_parameters.h是为了消除visual studio编辑器的某些误判,kernal.h中声明了我们要调用的函数原型。
错误检查宏
然后是代码段:
#ifdef _DEBUG
#define CUDA_CHECK(call) \do \{ \cudaError_t err = (call); \if (err != cudaSuccess) \{ \fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err)); \fprintf(stderr, "pos: file %s, line %d\n", __FILE__, __LINE__); \fprintf(stderr, "code: %d\n", err); \cudaDeviceReset(); \return; \} \} while (0)
#else
#define CHECK_CUDA(call) (call)
#endif
这是一个错误检查宏,由于cuda代码是并行程序,很难调试,因此可以定义一个宏来定位错误。不同的工程都可以用这个代码。用法如test中所示。
test函数
接下来分析test函数。
void test(float *img, int cols, int rows)
{dim3 block(32, 32);dim3 grid((cols + block.x - 1) / block.x, (rows + block.y - 1) / block.y);float *img_dev = NULL;CUDA_CHECK(cudaMalloc((void **)&img_dev, cols * rows * sizeof(float)));CUDA_CHECK(cudaMemcpy(img_dev, img, cols * rows * sizeof(float), cudaMemcpyHostToDevice));imgProcess<<<grid, block>>>(img_dev, cols, rows);CUDA_CHECK(cudaDeviceSynchronize());CUDA_CHECK(cudaGetLastError());CUDA_CHECK(cudaMemcpy(img, img_dev, cols * rows * sizeof(float), cudaMemcpyDeviceToHost));cudaFree(img_dev);cudaDeviceReset();return;
}
其中,
dim3 block(32, 32);
dim3 grid((cols + block.x - 1) / block.x, (rows + block.y - 1) / block.y);
指定了线程块的维度和线程网格的维度。
线程块和线程网格
在上一篇文章中我们知道,一个gpu上可以有成千上万个线程,cuda编程框架通过线程块和线程网格将这些线程组织起来。一个cuda核函数只能设置一个grid,一个grid中可以有多个block, block中有多个线程。grid可以将多个block组织成一维二维或三维的,一个block可以将其中多个线程组织成一维二维或三维的。
dim3是基于uint3定义的cuda内置的向量类型,包含三个无符号整数。对于block, 可以用blockIdx.x,blockIdx.y, blockIdx.z三个字段来指定,对于grid,可以用girdIdx.x, gridIdx.y, gridIdx.z来指定。block(32, 32);指定了blockIdx.x =32, blockIdx.y =32, blockIdx.z = 1(没有显式指定的默认为1,且可以忽略)。
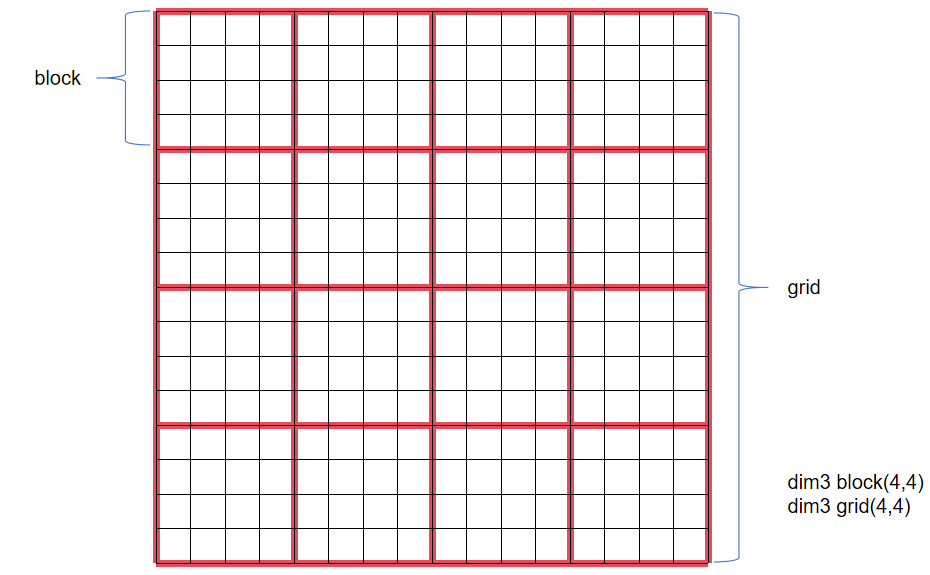
为了更加直观地理解,这里展示几种block和grid的组织方式。
- 二维block和二维grid
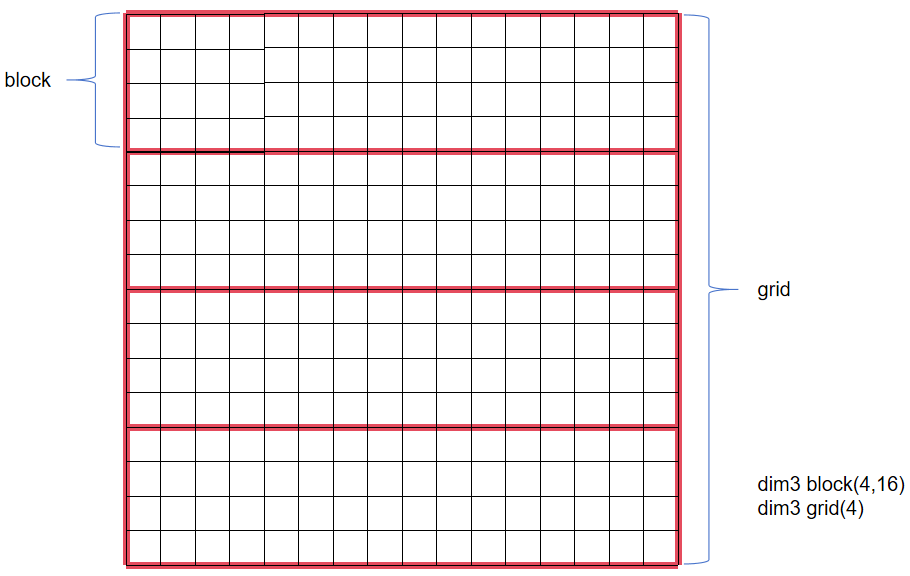
- 二维block和一维grid
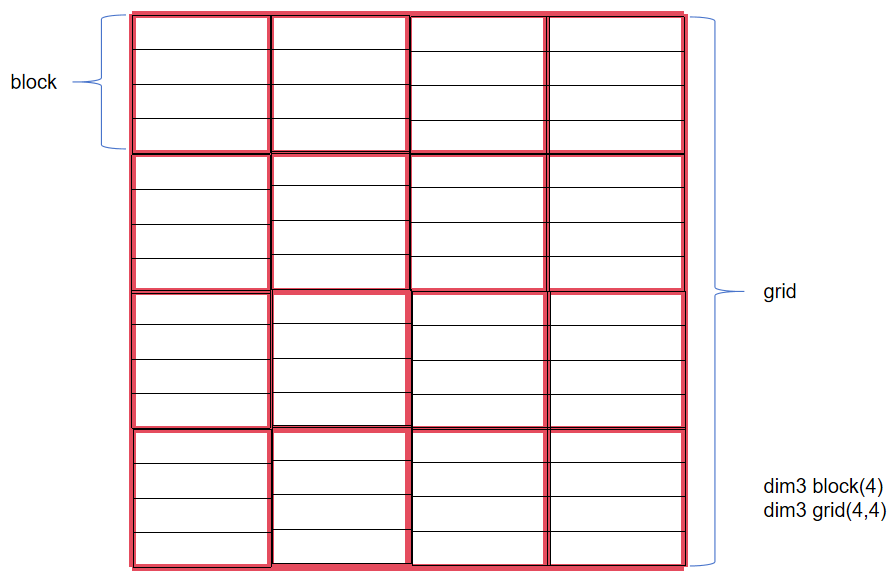
- 一维block和二维grid
实际编程中最常用的是二维gird和二维block.这里要注意一点,一个block中最多有1024个线程,grid的第二个和第三个维度最大为65535.
分配设备(GPU)内存并将数据传输到设备上
在异构架构中,GPU不能直接访问CPU上的数据,CPU也不能直接访问GPU上的数据,因此需要先分配GPU内存并将数据传输到GPU上。
- cudaMalloc: 分配一定字节的内存给一个指针。
(void **)&img_dev是固定写法,每个指针都要这样写。cols * rows * sizeof(float)是分配的字节数。 - cudaMemcpy: 进行GPU和CPU之间的数据传输。四个参数分别为:接受数据的指针,源数据指针,传输的数据字节数,传输的方向。其中传输方向分为四种:
cudaMemcpyDeviceToHost(GPU到CPU),cudaMemcpyHostToDevice(CPU到GPU),cudaMemcpyHostToHost(CPU到CPU),cudaMemcpyDeviceToDevice(GPU到GPU).
核函数分析
imgProcess<<<grid, block>>>(img_dev, cols, rows);这句用来调用核函数。和普通函数不同的是,需要用<<<grid, block>>>来指定线程的配置。核函数的定义中,__global__修饰符表示这个函数在CPU上调用,在GPU上运行。还有__host__以及__device__这两种修饰符,比较少用。
每个线程都会执行一次核函数。由于有很多个线程,可以用线程的索引当作矩阵的索引,这样每个线程只处理矩阵的一个位置的元素,由此可知,每个核函数也是只处理一个位置的元素。
分析核函数内部,首先通过
int idx_x = blockDim.x * blockIdx.x + threadIdx.x;
int idx_y = blockDim.y * blockIdx.y + threadIdx.y;
计算线程的全局索引,即线程在grid中位于第几行第几列。接下来判断线程的索引是否超出了矩阵的维度,即if (idx_x < cols && idx_y < rows)。之所以要进行这样的判断,是因为分配的grid的每行线程数目(gridDim.y * blockDim.x)未必等于矩阵的列数,同样,grid每列线程数目(gridDim.x * blockDim.y)未必等于矩阵的行数,如下图所示:
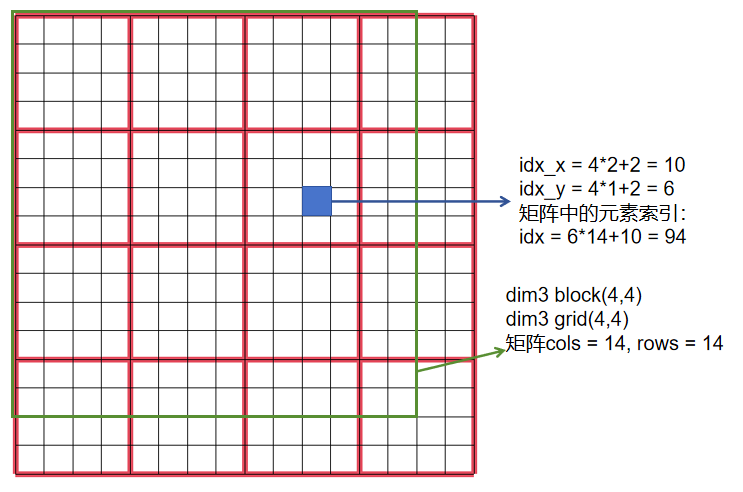
这就导致了线程的索引有可能超出矩阵的索引,发生非法内存访问错误。
另外注意到,在计算grid的x维度时,使用公式(cols + block.x - 1) / block.x,cols加上block.x - 1,和ceil(cols/block.x)效果一样,即保证grid每行的线程数一定要能覆盖矩阵的列数。
线程索引和矩阵元素索引的分析就到这,最后注意:
- 核函数不能有返回值
- 核函数不支持可变数量的参数
- 核函数不支持静态变量
全局同步
test函数是运行在主机上的,其调用的核函数是运行在设备上的。如果需要得到设备的计算结果主机才能进行下面的代码的话,需要添加cudaDeviceSynchronize()来阻塞主机端线程,当核函数运行完后,再运行后面的代码。
核函数错误检查
核函数是由成千上万个线程同时运行的,调试非常困难。这里用cudaGetLastError()来捕获上一个错误,这里就是核函数中的错误。捕获错误后,经过CUDA_CHECK宏将这个错误转换成可读的形式,并打印在终端中(不报错就不会打印)。
数据传回及资源释放
设备的计算结果需要手动传回主机(主机不能直接访问设备数据)。cudaMemcpy上文已经讲过,这里需要改变传输方向。
cudaFree释放在设备端开辟的内存,cudaDeviceReset释放所有全局内存分配(包括通过 cudaMalloc 分配的内存),销毁所有创建的 CUDA 上下文(context),终止所有正在执行的 kernel 函数和异步操作,将设备恢复到初始状态,总是是个更大的重置操作。
结语
分析完test函数后,cuda编程的框架基本上就搭起来了,后续学习会更容易!!!