多序列时间序列预测案例:scalecast库的使用
文章的重点是演示如何使用 scalecast 库将 VAR 的概念扩展到机器学习方法进行多元预测。
文章目录
- 1 向量自回归 (VAR)模型
- 1.1 引言
- 1.2 将 VAR 概念扩展到机器学习
- 2. 探索性数据分析
- 3. 单变量预测
- 4. 多变量预测
- 5. 模型堆叠
- 6. 结论

1 向量自回归 (VAR)模型
1.1 引言
一种流行的经典时间序列预测技术是 向量自回归 (VAR)。该方法的核心思想是,多个序列的过去值(滞后项)可以线性地用于预测其他序列的未来值。它通过这种方式同时预测多个时间序列。
你会在什么时候使用这种方法呢?当你怀疑两个或更多序列之间相互影响时,例如利率和通货膨胀,这是一种有效的方法。在运行 VAR 时,所有序列都必须是平稳的,这一点非常重要。一旦你确定了要预测的序列并确保了它们的平稳性(通过对非平稳序列进行差分或进行其他变换),唯一需要考虑的参数就是用作预测变量的滞后项数量。这可以通过对不同滞后项数量进行 信息准则搜索 来完成。VAR 方法的扩展包括带误差项的估计 (VARMA)、应用误差修正项 (VECM)、添加外生变量 (VARMAX) 以及带季节性的估计 (SVAR)。
1.2 将 VAR 概念扩展到机器学习
一个合理的问题是,如果你改变这个过程中底层的线性函数会怎样?或者,如果你混合并匹配上述几个概念会怎样?有一些方法可以使用这种通用方法,但采用更基于机器学习的程序,例如使用 Scikit-Learn 库 中可用的模型。考虑到时间序列数据应如何准备以及更新预测和模型输入的困难,从头开始编写这样的程序将非常耗时。幸运的是,一些 Python 包,如 darts、scalecast 等,为你省去了很多麻烦。
今天,我将演示如何使用 scalecast 将这种方法应用于预测。设置过程和提取最终结果都很容易。该包以多步过程动态预测你输入的所有序列。一个缺点是,据我所知,目前关于以这种方式应用机器学习模型进行多变量预测的研究不多。但这仍然很有趣。你可以在 此处 查看完整的 Jupyter Notebook。数据可在 Kaggle 上获得,并带有开放数据库许可证。
2. 探索性数据分析
我们将研究如何预测以下两个序列:
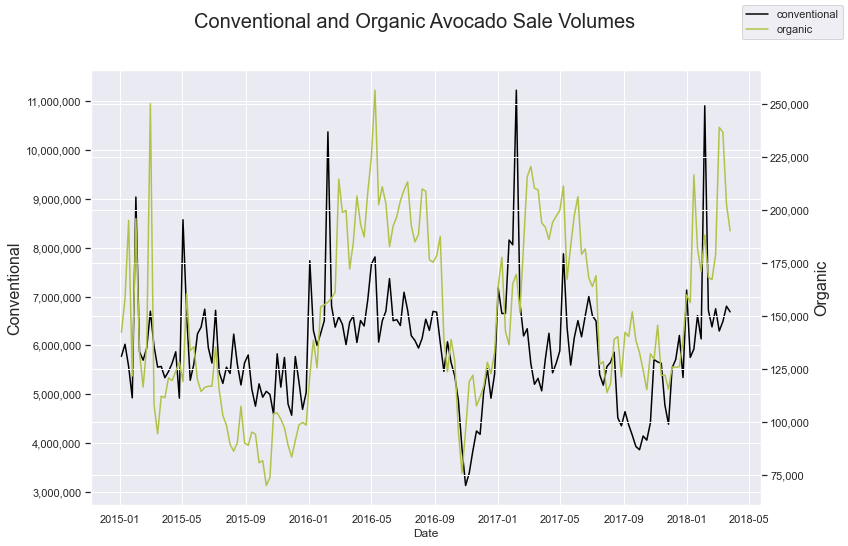
这些数据衡量了 2015 年 1 月至 2018 年 3 月底加利福尼亚州每周传统牛油果和有机牛油果的销量。由于传统牛油果的销量远高于有机牛油果,因此图表需要双轴。对它们进行皮尔逊相关性计算,我们发现它们的系数为 0.48。这两个序列确实同步变化并表现出相似的趋势,尽管规模不同。
接下来,我们检查两个序列的平稳性。使用一种常见的确定平稳性的测试,即增广迪基-富勒检验 (Augmented Dickey-Fuller test),我们发现这两个序列在 95% 的置信度下都可以被认为是平稳的。这意味着我们可以尝试在它们的原始水平上进行建模。
然而,两者看起来都遵循趋势(因此不平稳),并且两个测试都没有在 99% 的显著性水平上证实平稳性。我们现在可以假设它们是平稳的,但对这项分析的一个有趣扩展是,对每个序列进行一次差分,scalecast 允许你轻松做到这一点。

让我们使用自相关和偏自相关函数来查看每个序列有多少滞后项具有统计显著性:
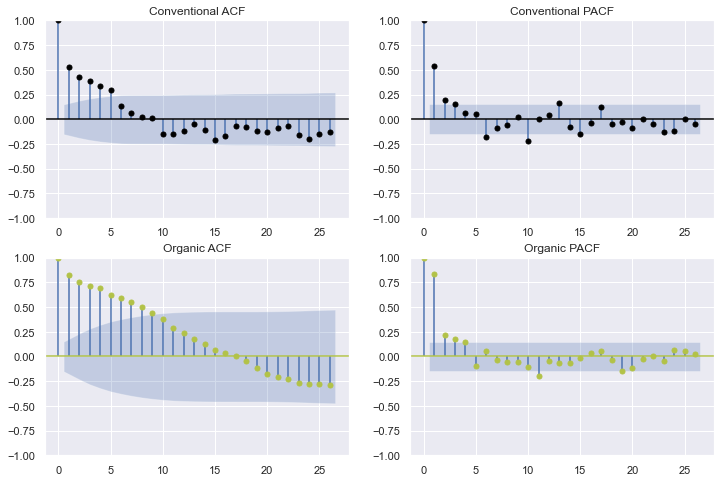
从这些图中,很难确切地判断多少滞后项是理想的预测值。它似乎至少有三个,但可能多达 20 个,中间有一些间隔。我们宁愿选择较少的滞后项——3 个。稍后,我们将展示如何在代码中纳入这个决定。
另一个需要考虑的重要组成部分是每个序列的季节性。我们可以通过使用季节性分解方法来直观地看到季节性:
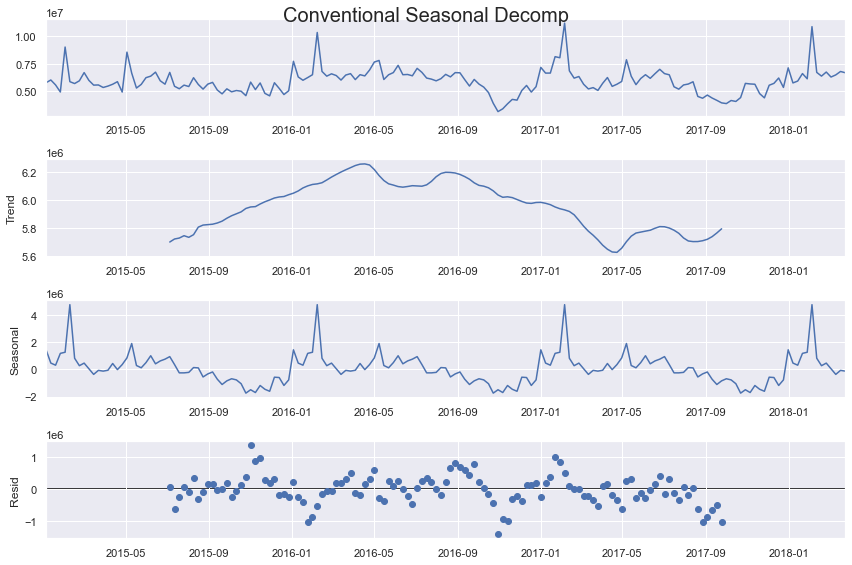
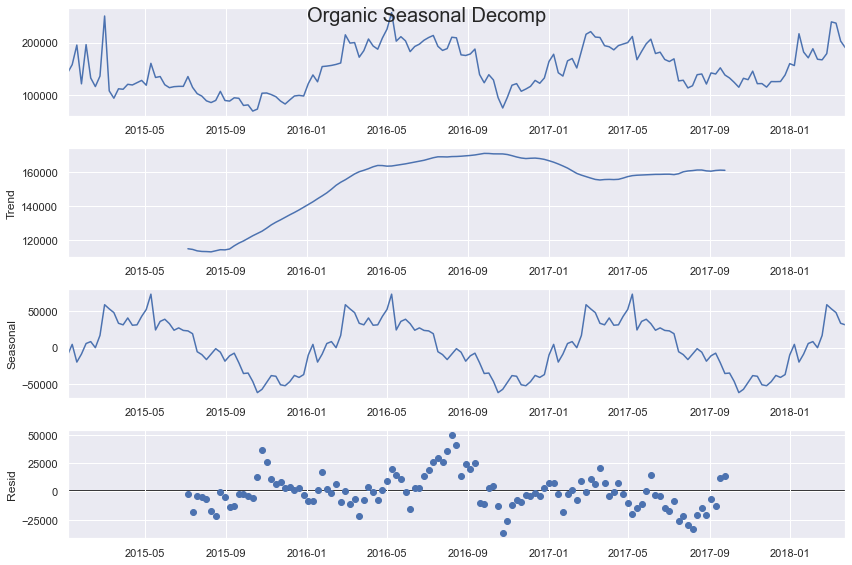
从这个输出中可以看出,尽管增广迪基-富勒检验表明平稳性,但至少有机序列确实存在上升趋势。季节性也很强,看起来有年度(52 周期)和半年度(26 周期)循环。上述是数据的线性分解,但残差看起来仍然遵循某种模式,这表明线性模型可能不是最适合的。我们可以尝试使用线性和非线性方法,并添加不同类型的季节性。
最后,让我们利用我们对这些序列所学到的一切来做出建模决策。首先,我们将应用的模型:
models = ('mlr','elasticnet','knn','rf','gbt','xgboost','mlp')
MLR 和 ElasticNet 模型都是线性应用,其中 ElasticNet 是一个带有 L1 和 L2 正则化参数混合的线性模型。其他模型都是非线性的,包括 k-近邻、随机森林、两种梯度提升树和多层感知器神经网络。
使用 scalecast 过程,我们现在可以创建 Forecaster 对象来存储关于每个序列以及我们想要尝试预测它们的方式的信息:
# load the conventional series
fcon = Forecaster(y=data_cali_con['Total Volume'], current_dates = data_cali_con['Date'])
# load the organic series
forg = Forecaster(y=data_cali_org['Total Volume'], current_dates = data_cali_org['Date'])
for f in (fcon,forg): # set forecast horizon of 1 year f.generate_future_dates(52) # set 20% testing length f.set_test_length(.2) # set aside 4 weeks for validation f.set_validation_length(4) # add seasonality in the form of wave functions f.add_seasonal_regressors( 'week', 'month', 'quarter', raw=False, sincos=True, ) # add the year as a regressor f.add_seasonal_regressors('year') # add a time trend f.add_time_trend() # add an irregular seasonal cycle of 26 periods f.add_cycle(26) # add three dep variable lags f.add_ar_terms(3)
3. 单变量预测
在我们把分析扩展到多序列预测之前,让我们通过应用单变量过程来衡量性能。通过从 scalecast 导入验证网格,这些网格保存到工作目录中的 Grids.py(用于单变量过程)和 MVGrids.py(用于多变量过程),我们可以使用回归量(包括我们已经添加的滞后项、季节性回归量和时间趋势)自动调整、验证和预测我们选择的模型:
GridGenerator.get_example_grids(overwrite=False)
GridGenerator.get_mv_grids(overwrite=False)
然后我们可以调用预测过程:
fcon.tune_test_forecast(models,feature_importance=True)
forg.tune_test_forecast(models,feature_importance=True)
我们还可以为每个对象添加一个加权平均集成模型:
fcon.set_estimator('combo')
fcon.manual_forecast(how='weighted')
forg.set_estimator('combo')
forg.manual_forecast(how='weighted')
并绘制结果:
fcon.plot_test_set(ci=True,order_by='LevelTestSetMAPE')
plt.title('Conventional Univariate Test-set Results',size=16)
plt.show()
forg.plot_test_set(ci=True,order_by='LevelTestSetMAPE')
plt.title('Organic Univariate Test-set Results',size=16)
plt.show()
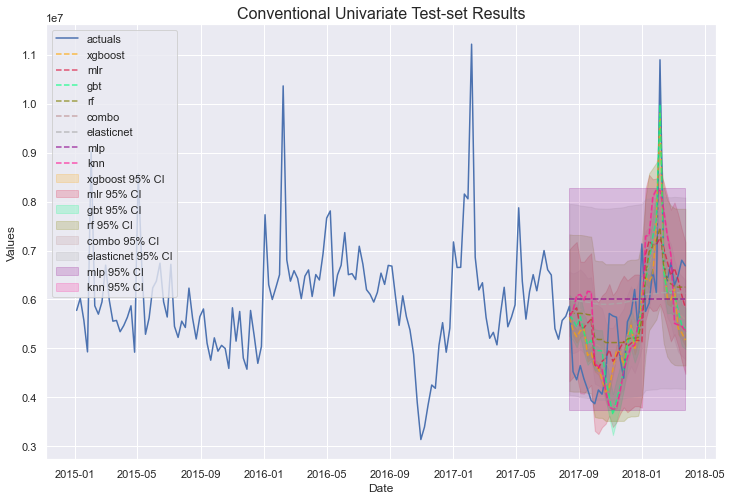
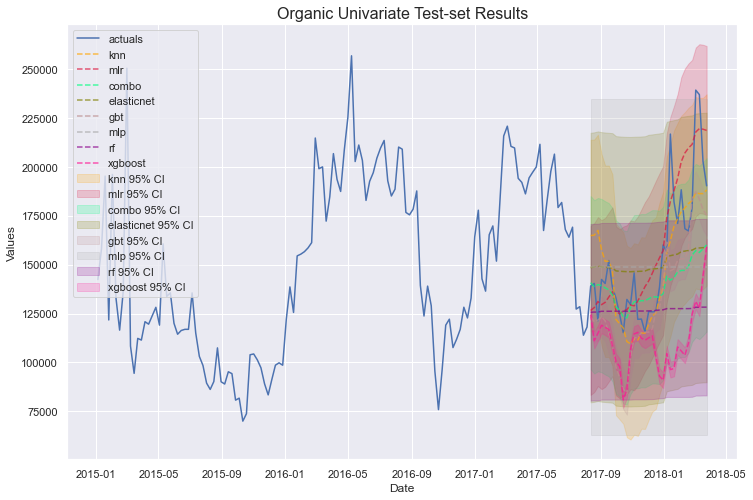
有趣的模式和预测出现了。我们还导出一些模型摘要,以数值方式了解每个模型的表现:
pd.set_option('display.float_format', '{:.4f}'.format)
ms = export_model_summaries({'Conventional':fcon,'Organic':forg}, determine_best_by='LevelTestSetMAPE')
ms[ [ 'ModelNickname', 'Series', 'Integration', 'LevelTestSetMAPE', 'LevelTestSetR2', 'InSampleMAPE', 'InSampleR2', 'best_model' ]
]
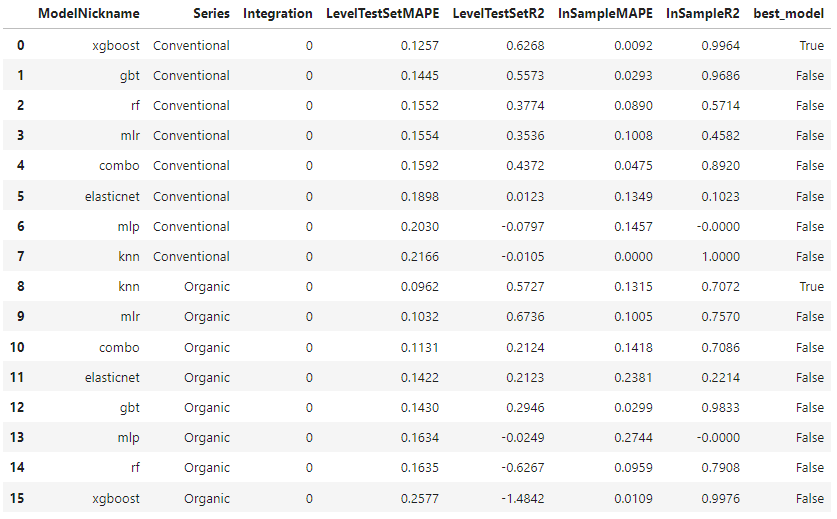
仅从测试集 MAPE 来看,XGBoost 在传统序列上表现最佳,KNN 在有机序列上表现最佳,两者都是非线性模型。然而,XGBoost 似乎严重过拟合。让我们转向多变量建模,看看是否能改善结果。
4. 多变量预测
为了将上述单变量建模扩展到多变量概念,我们需要将从 scalecast 创建的 Forecaster 对象传递给一个 MVForecaster 对象。操作如下:
mvf = MVForecaster(fcon,forg,names=['Conventional','Organic'])
有关此行代码功能的更多详细信息,请参阅 此处。基本上,任意数量的 Forecaster 对象都可以传递给这个新对象。在构建此新对象之前,你应该已经设置了预测范围并添加了任何要使用的 X 变量,否则,你将只能使用每个序列的滞后项进行预测,并且添加季节性和外生回归量的机会将丢失。
有了这个新的 MVForecaster 对象,它能够从我们提供给它的两个 Forecaster 对象中获取其他参数,但我们确实需要重新设置测试和验证长度:
mvf.set_test_length(.2)
mvf.set_validation_length(4)
我们有多个序列要预测,但我们仍然可以使用类似于单变量部分中使用的自动化方法。然而,现在我们的模型将尝试优化两件事,不仅仅是选定的误差指标(默认情况下在模型调优时是 RMSE),而是多个序列上误差指标的聚合。例如,如果出于某种原因,准确预测传统序列比正确预测其他序列更重要,我们可以告诉对象只优化该序列上的选定误差指标:
mvf.set_optimize_on('Conventional')
要将其更改为优化跨序列的平均指标(这也是默认行为),我们可以使用:
mvf.set_optimize_on('mean')
现在,我们运行自动化预测过程:
mvf.tune_test_forecast(models)
完成后,我们告诉对象根据我们选择的指标设置最佳模型。我选择测试集 MAPE。这将选择在两个序列上平均测试集 MAPE 最佳的模型:
mvf.set_best_model(determine_best_by='LevelTestSetMAPE')
现在,让我们看看结果。我们可以将所有模型在所有序列上一起绘制,但由于传统和有机销量的规模差异巨大,我们仍然希望像在单变量部分中那样逐一绘制它们:
mvf.plot_test_set(series='Conventional', put_best_on_top=True, ci=True)
plt.title('Conventional Multivariate Test-set Results',size=16)
plt.show()
mvf.plot_test_set(series='Organic', put_best_on_top=True, ci=True)
plt.title('Organice Multivariate Test-set Results',size=16)
plt.show()
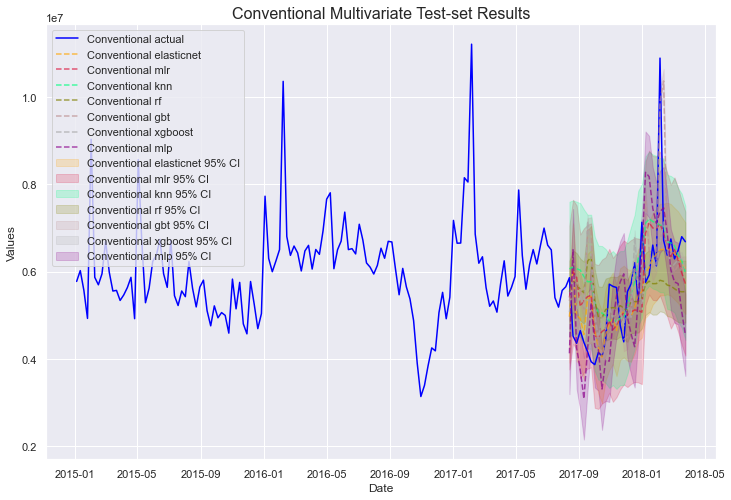
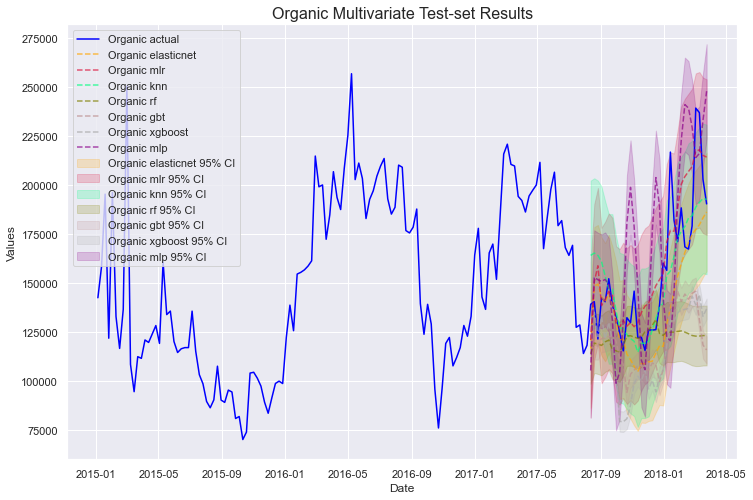
非常好!在进一步研究这些之前,让我们探索另一种可以在 scalecast 中进行多变量预测的集成模型。
5. 模型堆叠
在单变量部分,我们应用了一种 scalecast 原生的集成模型——加权平均模型。多变量预测只允许应用 Scikit-learn 模型,所以我们没有相同的组合模型可用,但有一种不同的集成模型可以使用:StackingRegressor。
from sklearn.ensemble import StackingRegressor
mvf.add_sklearn_estimator(StackingRegressor,'stacking')
现在,我们使用我们之前应用和调整过的其他模型来构建模型,如下所示:
这可能看起来很复杂,但它将我们之前定义的 MLR、ElasticNet 和 MLP 模型组合成一个,其中每个模型的预测成为最终模型(KNN 回归器)的输入。我选择这些模型是因为它们表现出最少的过拟合迹象,并且具有可靠的测试集误差指标。现在让我们在 scalecast 中调用该模型。我们可以使用 13 个滞后项来训练这个模型,因为正如我们很快将看到的,13 个滞后项在模型调优过程中最常被选中,尽管如果我们愿意,我们可以通过网格搜索来调优该参数。
mvf.set_estimator('stacking')
mvf.manual_forecast(estimators=estimators,final_estimator=final_estimator,lags=13)
现在,我们可以看到所有模型的模型性能:
mvf.set_best_model(determine_best_by='LevelTestSetMAPE')
results2 = mvf.export_model_summaries()
results2[ [ 'ModelNickname', 'Series', 'HyperParams', 'LevelTestSetMAPE', 'LevelTestSetR2', 'InSampleMAPE', 'InSampleR2', 'Lags', 'best_model' ]
]
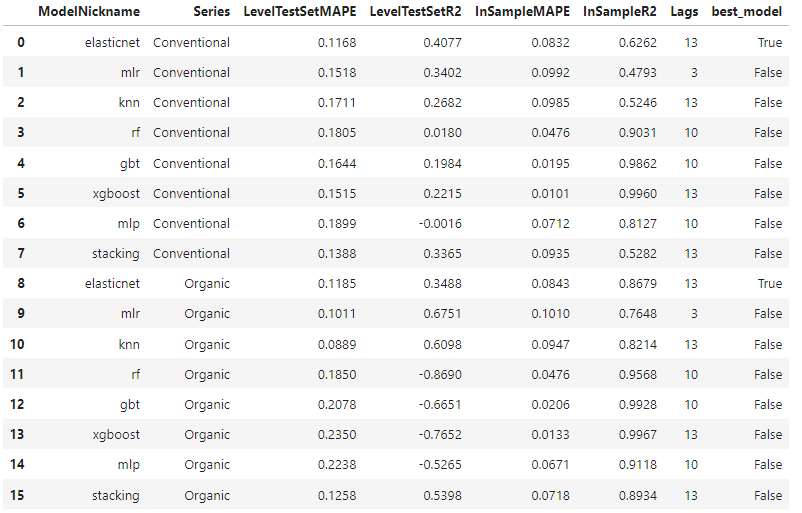
ElasticNet 在两个序列之间的平均误差表现最佳,这就是为什么它在上面的输出中被标记为两个序列的最佳模型,但 KNN 在有机序列上比 ElasticNet 表现更好。我们可以选择 ElasticNet 作为传统序列的最终实现模型,KNN 作为有机序列的最终实现模型。这两个最佳模型的 MAPE 指标都低于单变量方法中的最佳模型,表明整体性能更好。让我们看看它们在 52 周期预测范围内的绘制情况:
mvf.plot(series='Conventional',models='elasticnet',ci=True)
plt.title('Elasticnet Forecast - Conventional - MAPE 0.1168', size=16)
plt.show()
mvf.plot(series='Organic',models='knn',ci=True)
plt.title('KNN Forecast - Organic - MAPE 0.0889', size=16)
plt.show()
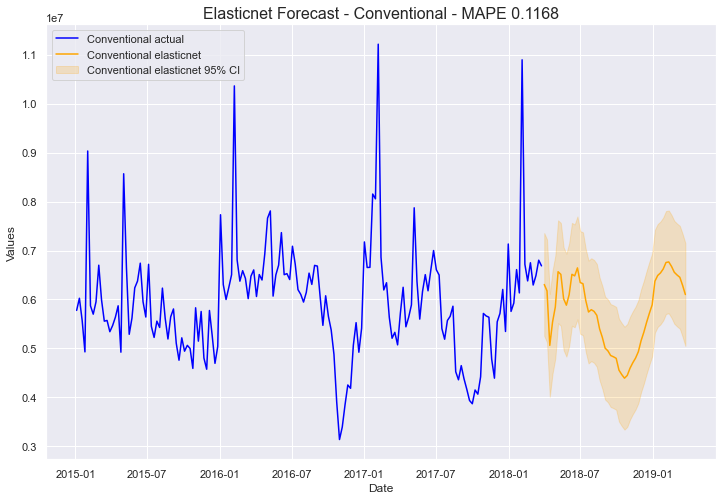
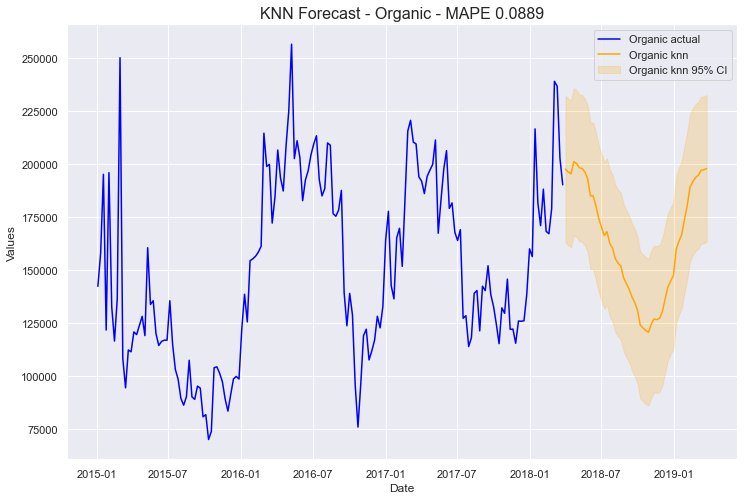
这些图的关键在于考虑它们是否看起来可信。 对我来说,如果一个预测通过了“眼看”测试,那就是它在现实世界中可用的最佳指标。据我所知,这两个模型看起来都还不错,尽管它们都不能很好地预测序列的整体尖峰。也许有更多的数据或更复杂的建模过程,这种不规则趋势可以更好地建模,但目前,我们将坚持这一点。
6. 结论
这是使用 scalecast 在 Python 中进行多变量预测的概述。建模过程非常简单和自动化,这有利于快速获取结果,但这种方法也有其局限性。通过应用许多模型,有可能通过某些技术获得侥幸成功,并实质上在验证数据上过拟合。我赞同 darts 包开发者的 警告:
“那么 [哪种应用模型是最好的]?嗯,在这一点上,很难确切地说哪种是最好的。我们的时间序列很小,我们的验证集甚至更小。在这种情况下,很容易将整个预测练习过拟合到如此小的验证集上。如果可用模型的数量和它们的自由度很高(例如深度学习模型),或者如果我们在单个测试集上使用了许多模型(如本笔记本中所做),则尤其如此。”
鉴于这种观点,查看每种技术的平均误差并记住我们的一些模型显示出过拟合迹象也可能是有益的。

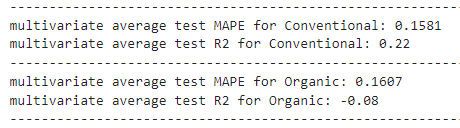
从这个分析角度来看,两种技术都没有明显优于另一种,因为一些模型的误差指标有所下降,而另一些则有所上升。我们做出的任何决定都需要以常识为基础。一个人在这样的分析中做出的决定可能与另一个人不同,而且两者都可能是有效的。归根结底,预测是预测未来的科学,没有人能 100% 正确地预测未来。为了结束 darts 开发者的话:
“作为数据科学家,我们有责任了解我们的模型在多大程度上值得信赖。因此,总是要对结果持保留态度,尤其是在小数据集上,并在进行任何预测之前应用科学方法 😃 祝建模愉快!”