Rust学习笔记(七)|错误处理
本篇文章包含的内容
- 1 程序错误分类
- 2 Panic 与不可恢复的错误
- 2.1 开发者调用`panic!`宏
- 2.2 程序自动panic
- 2.3 为验证创建自定义类型
- 3 Result 与可恢复的错误
- 3.1 Result 枚举
- 3.2 匹配不同的错误类型
- 3.3 `unwrap` 和 `expect` 方法
- 3.4 传播错误和`?`运算符
Rust是一门安全性很高的语言,所以它迫使开发者在写代码的时候就考虑到运行时可能发生的错误,并在编译时提示可能出现的错误,并进行处理。
1 程序错误分类
在Rust中,程序运行时可能发生的错误分为如下两类:
- 不可恢复的错误:相当于bug,例如数组访问越界,此时为了内存安全必须终止程序运行;
- 可恢复的错误:例如未找到文件,此时就可以选择创建一个新文件
2 Panic 与不可恢复的错误
2.1 开发者调用panic!宏
可以使用panic!宏手动使得程序panic(恐慌),当程序panic时,程序会打印错误信息(有时候错误信息是开发者自定义的),之后展开(unwind)和清理调用栈(Stack),最后会退出程序。
panic!("crash and burn!");
这里的展开调用栈,指的是Rust会沿着调用栈往回走,清理每一个遇到的函数中的数据,这样的工作量是最大的(默认);如果想要见效二进制文件更小,可以将工程配置为panic时中止(abort)调用栈,此时不进行内存清理,立即中止程序,而使用的内存稍后由操作系统清理。如果要将panic的默认行为从展开改为中止,需要在Cargo.toml文件中更改[profile.release]的设置:
[package]
name = "error_handle"
version = "0.1.0"
edition = "2024"[dependencies][profile.release]
panic = 'abort'
2.2 程序自动panic
当发生数组索引越界时,程序会自动panic,此时会打印错误信息。RustRover还可以自动显示调用栈的信息。调用栈可以让我们方便地找到程序发生panic的位置。例如下面的代码一定会panic:
fn main() {let v = vec![1, 2, 3];let item = &v[99];
}
RustRover输出的错误信息:
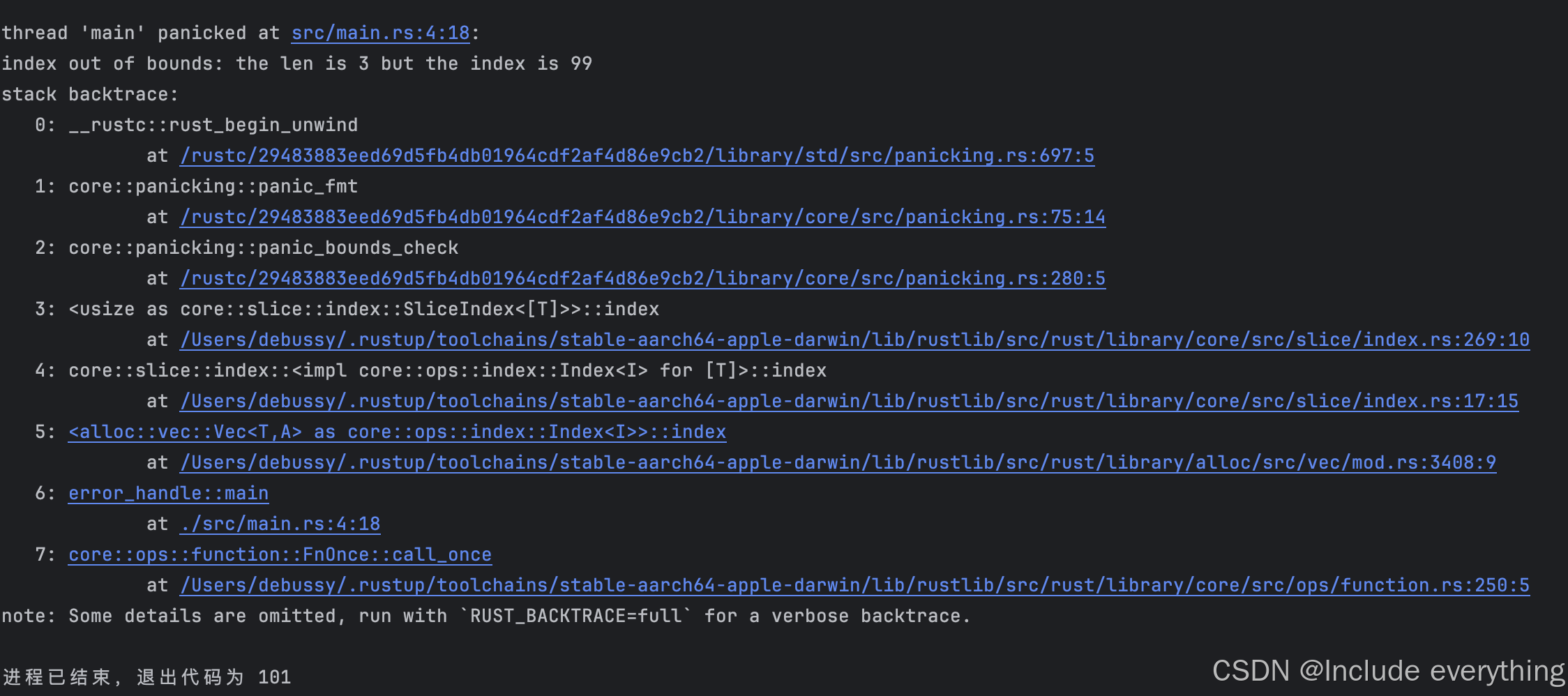
注意,这里的stack backtrace属于调试信息,此时执行cargo run或者cargo build时不可以加--release参数,否则就没有调试信息了。
当你认为你的代码可能会出现问题,比如定义一个可能失败的函数,应该优先考虑Result枚举,使函数可以恢复(也可以手动panic),如果确定代码的错误一定不可恢复,则此时就需要panic。
在下面三种情况下优先考虑使用panic!宏使得程序恐慌:
- 编写代码实例,演示某些概念(可以调用会引起panic的函数,例如
unwrap、expect) - 编写原型代码
- 编写测试
- 当代码出现的问题不在预期内,使用panic;如果代码出现的错误是可预见的,优先使用Result
2.3 为验证创建自定义类型
对于一开始做的猜数游戏,我们并没有检查数字的范围,这时候就可以借鉴标准库对某些数据结构的设计,创建一个自定义的类型对数据进行包装。我么可以在构造函数(关联函数)中对数据进行检查,只有当这个新的自定义类型的实例被正确创建时,数据就是有效的,否则就panic。
pub struct Guess {value: i32, // private
}impl Guess {pub fn new(value: i32) -> Guess {if value < 1 || value > 100 {panic!("Guess value must be between 1 and 100, got {}", value);}Guess { value }}pub fn value(&self) -> i32 {self.value}
}
3 Result 与可恢复的错误
3.1 Result 枚举
Result枚举拥有两个变体,一个是Ok(T),另一个是Err(E)。如果操作成功,就返回Ok(T),T就是返回数据的类型;如果操作失败,返回Err(E),E就是返回错误的类型。和Option枚举类似,Result<T, E>枚举及其变体也是预导入的。可以使用match表达式方便地获取返回值或者处理错误。
use std::fs::File;fn main() {let f = File::open("text.txt");let f = match f {Ok(file) => { file }Err(e) => {panic!("Error in opening file: {:?}", e);}};
}
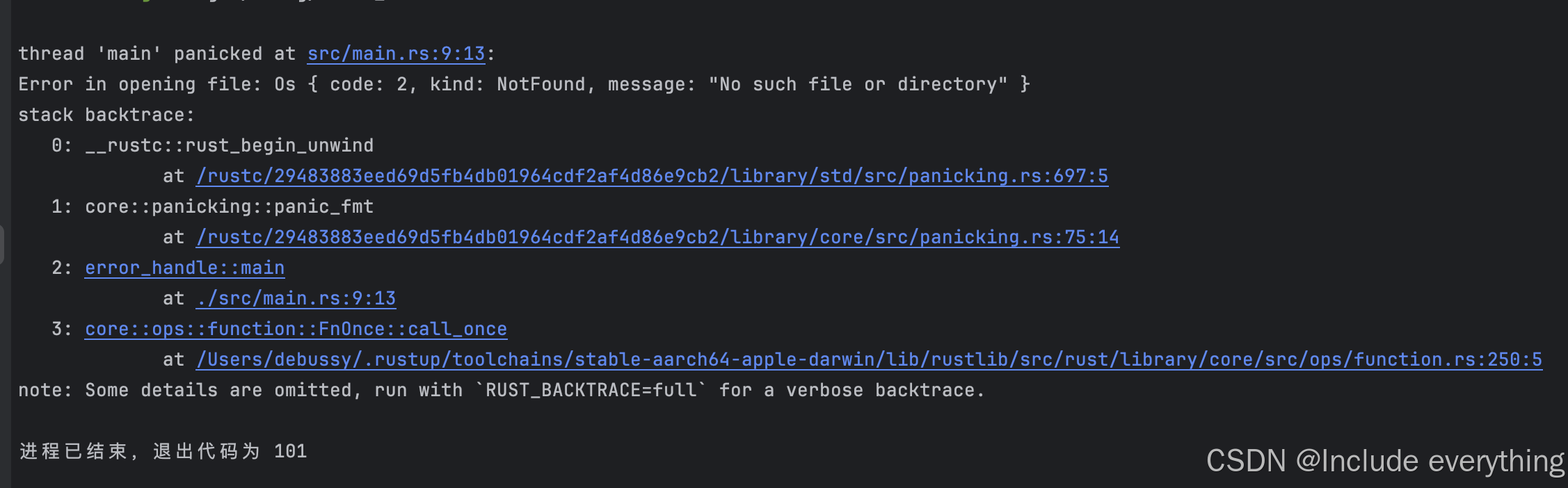
3.2 匹配不同的错误类型
对于不同的错误类型,可以在match表达式内部进行嵌套。例如下面的例子,就使用了三个match表达式。
use std::fs::File;
use std::io::ErrorKind;fn main() {let f = File::open("text.txt");let f = match f {Ok(file) => { file }Err(e) => match e.kind() {ErrorKind::NotFound => match File::create("text.txt") {Ok(file) => { file }Err(e) => {panic!("Error in creating file: {:?}", e);}}other_error => { // 相当于通配符 _panic!("Error in creating file: {:?}", other_error);}}};
}
使用多个match表达式虽然有用,但是较为原始。Result可以接受闭包作为参数,代码可以更加简洁(后续再了解)。
3.3 unwrap 和 expect 方法
unwrap 和 expect方法是match表达式的一个简单实现,如果操作成功,就返回Ok变体里的值,如果操作失败,就调用panic!宏。两个方法的区别是unwrap不能定义提示信息,expect可以自定义提示信息:
use std::fs::File;fn main() {// let f = File::open("text.txt").unwrap();let f = File::open("text.txt").expect("无法打开文件 text.txt");
}
3.4 传播错误和?运算符
在上面的例子中,错误是由开发者处理的,但是有时候我们需要将错误的处理权交给函数的调用者,即自己构建一个Result枚举,使得错误的处理者发生转移(传播),这样的做法称为传播错误。
首先,我么可以使用上面学习过的知识完成一个传播错误的例子:
use std::fs::File;
use std::io;
use std::io::Read;fn read_string_from_file() -> Result<String, io::Error> {let f = File::open("hello.txt");let mut f = match f {Ok(file) => {file} // 如果打开成功,程序继续运行Err(e) => {return Err(e)}};let mut s = String::new();match f.read_to_string(&mut s) {Ok(_) => {Ok(s)}Err(e) => {Err(e)}}
}fn main() {let result = read_string_from_file();
}
上面的例子中,我们并没有直接处理错误,而是将错误和可能的结果包装成一个Result枚举,将其返回给函数的调用者(main函数)。为了简化写法,我们可以使用?表达式:
use std::fs::File;
use std::io;
use std::io::Read;fn read_string_from_file() -> Result<String, io::Error> {let mut f = File::open("hello.txt")?;let mut s = String::new();f.read_to_string(&mut s)?;Ok(s)
}fn main() {let result = read_string_from_file();
}
?表达式的作用是:当函数正常运行,那么就将Ok(T)变体中的数据作为返回值返回给一个变量;如果运行失败,就将Err(E)作为整个函数的返回值返回。
使用
?表达式还有一个好处,即使用?表达式时会隐式地调用from函数。这个from函数负责错误之间的转换,即对于不同的错误,都将其转换为函数所定义的错误类型。在上面的例子中,有时候我们并不能保证函数的错误类型都是io::Error,但是from函数会将某个具体的错误类型转化为io::Error。但是转换存在一个前提条件:只有当这个错误实现了转换为目标错误的from函数时才可以成功转换。
上面的例子还可以继续优化,即使用链式调用更加简化代码(仔细理解?运算符的作用,相信你可以理解):
use std::fs::File;
use std::io;
use std::io::Read;fn read_string_from_file() -> Result<String, io::Error> {let mut s = String::new();File::open("hello.txt")?.read_to_string(&mut s)?;Ok(s)
}fn main() {let result = read_string_from_file();
}
?运算符只能用于返回值只能是返回类型是Result枚举的类型。我们甚至可以修改main函数的返回类型,使其中的函数可以使用?运算符,这可以减少我们的代码量:
use std::error::Error;
use std::fs::File;fn main() -> Result<(), Box<dyn Error>>{ // Box<dyn Error>是一个trait对象,可以理解为任意错误类型let f = File::open("hello.txt")?;Ok(()) // 成功时返回一个单元类型,相当于什么都不返回
}

原创笔记,码字不易,欢迎点赞,收藏~ 如有谬误敬请在评论区不吝告知,感激不尽!博主将持续更新有关嵌入式开发、FPGA方面的学习笔记。