使用LLaMA-Factory对大模型进行微调-详解
书接上回
启动llama Factory可视化页面
llamafactory-cli webui
如果想后台运行 使用 nohup llamafactory-cli webui &
浏览器访问 http://127.0.0.1:7860/
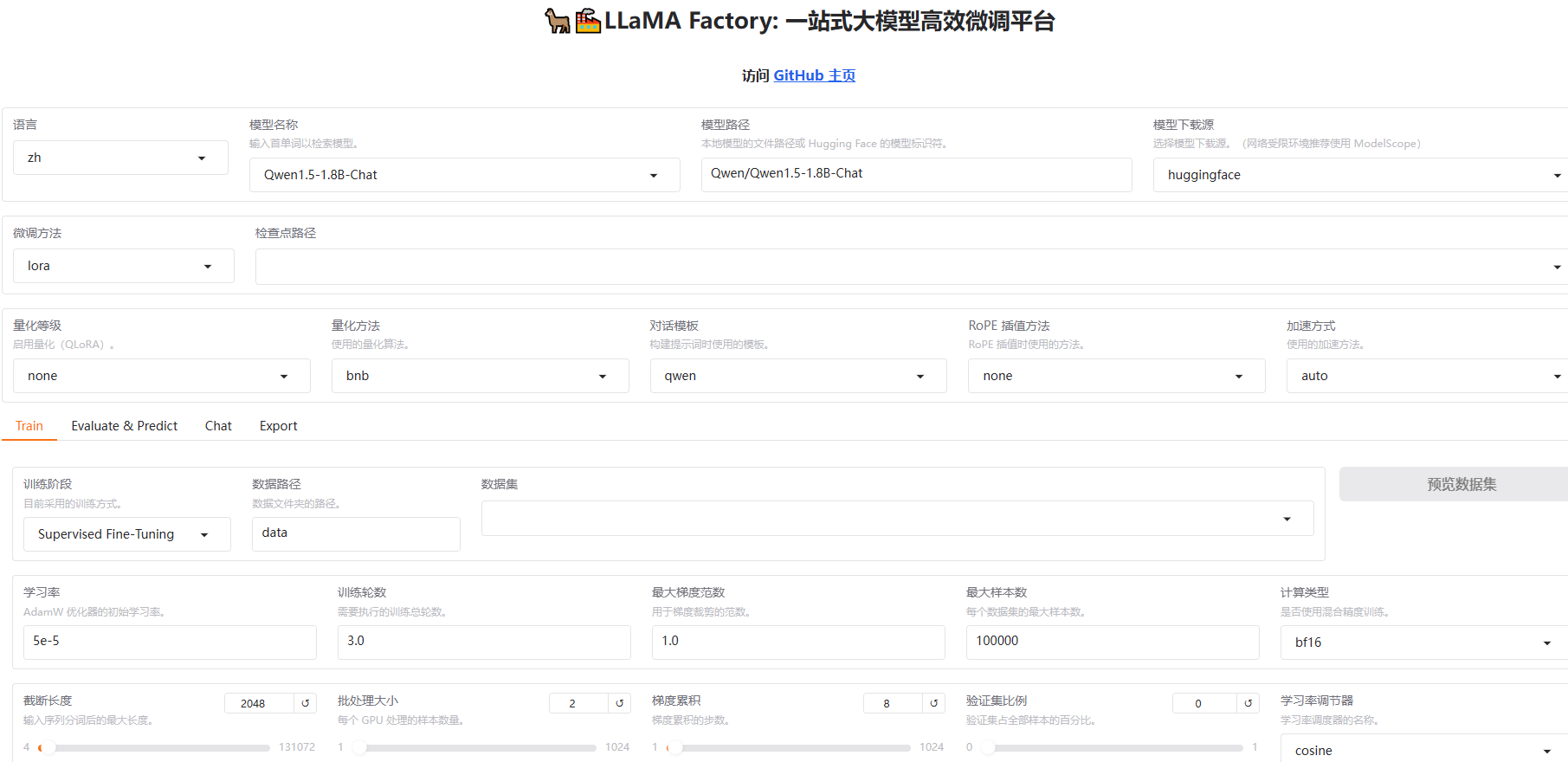
配置项主要参数:
参考: https://docs.coreshub.cn/console/compute_platform/help/llama_factory/
模型路径 :
解释: 可以直接填写本地模型路径,也可以在选择模型名称之后默认
示例: /opt/vllm/models/Qwen1.5-1.8B-Chat
微调方法
full: 全参数微调,计算成本高(gpu需求大,时间长),所需数据集规模大(小数据集易过拟合)freeze: 冻结微调,冻结大部分参数,只训练模型最后几层(通常是输出层或少量顶层),无法修改模型深层的特征提取逻辑,适配能力有限。适合小数据集,简单任务; lora: 冻结所有原始参数,在模型的关键层(如注意力层)中插入少量可训练的低秩矩阵(通过矩阵分解减少参数量),仅训练这些新增的低秩矩阵参数,能够间接调整模型的深层行为,适配能力强,适合中等数据集,追求效率与性能平衡的场景
量化等级
QLoRA: 训练中量化
GPTQ/AWQ: 推理时量化
8-bit 量化 : 内存减少约 50%,速度提升明显,精度损失较小。
4-bit 量化(INT4): 内存减少约 75%,速度较快,但精度损失较明显。
量化方法
BNB、HQQ、EETQ 是三种不同的模型量化技术,用于压缩大模型参数、降低显存占用并提升推理效率。
微调场景:优先使用 BNB (QLoRA),兼顾显存与精度。
快速部署:选 HQQ,尤其需 vLLM 加速时。
生产推理:需极致性能时,采用 EETQ 编译优化。
训练阶段: Supervised Fine-Tuning
数据路径 数据集选择
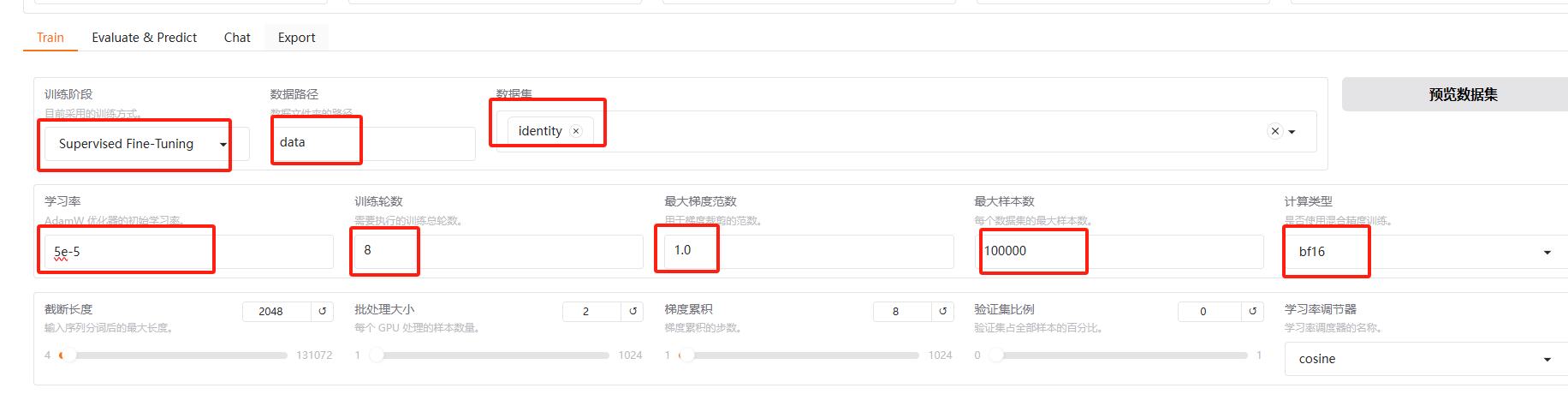
预览命令 下面有个输出目录, 这是训练好的权重存放位置
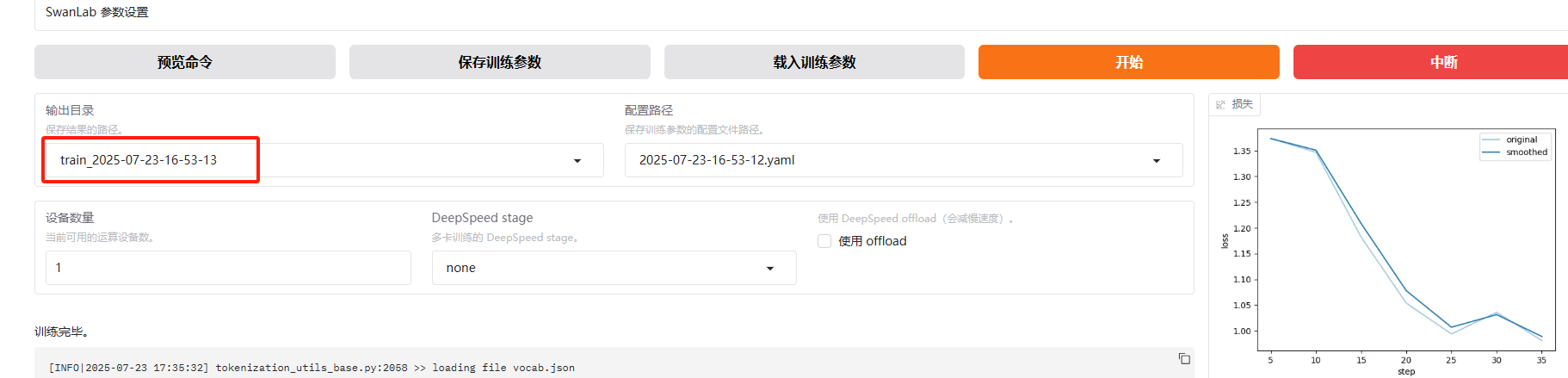
其他的用到再说吧!
点击预览命令,可以看到,和上篇中的指令类似
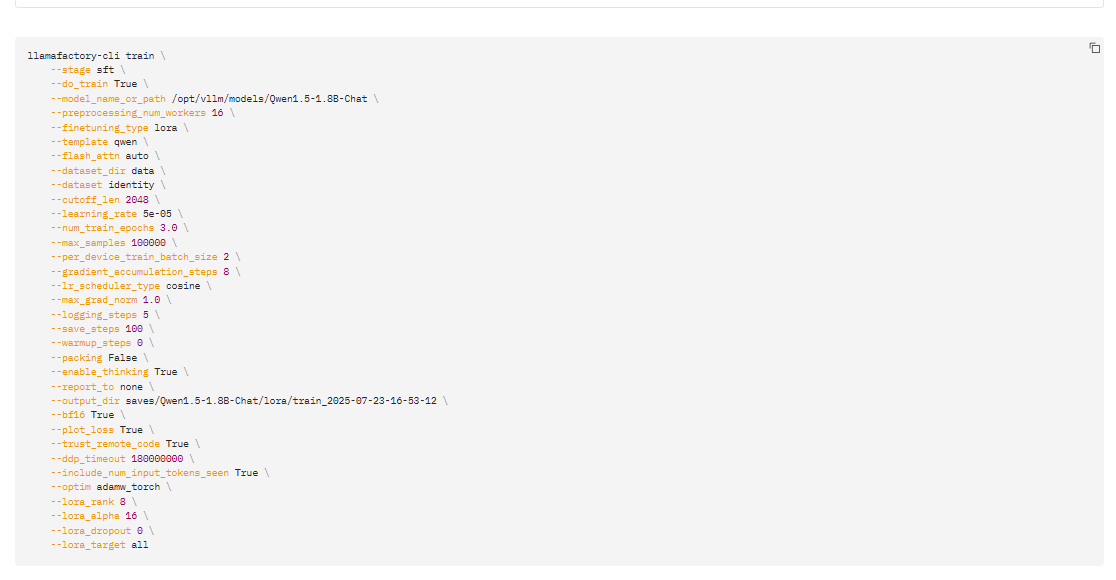
点击开始,他就运行了,等最后就出现训练完成;
测试:
加载模型 测试
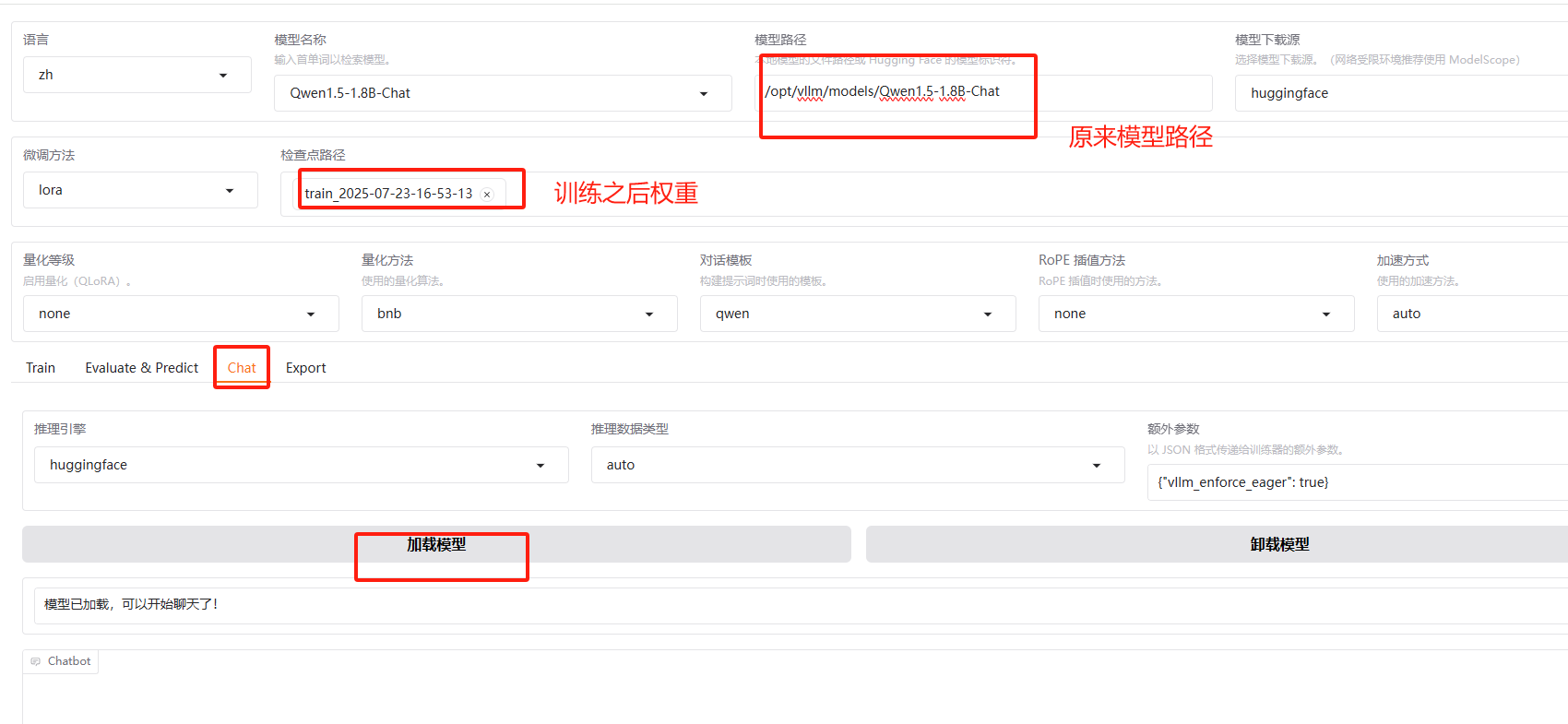
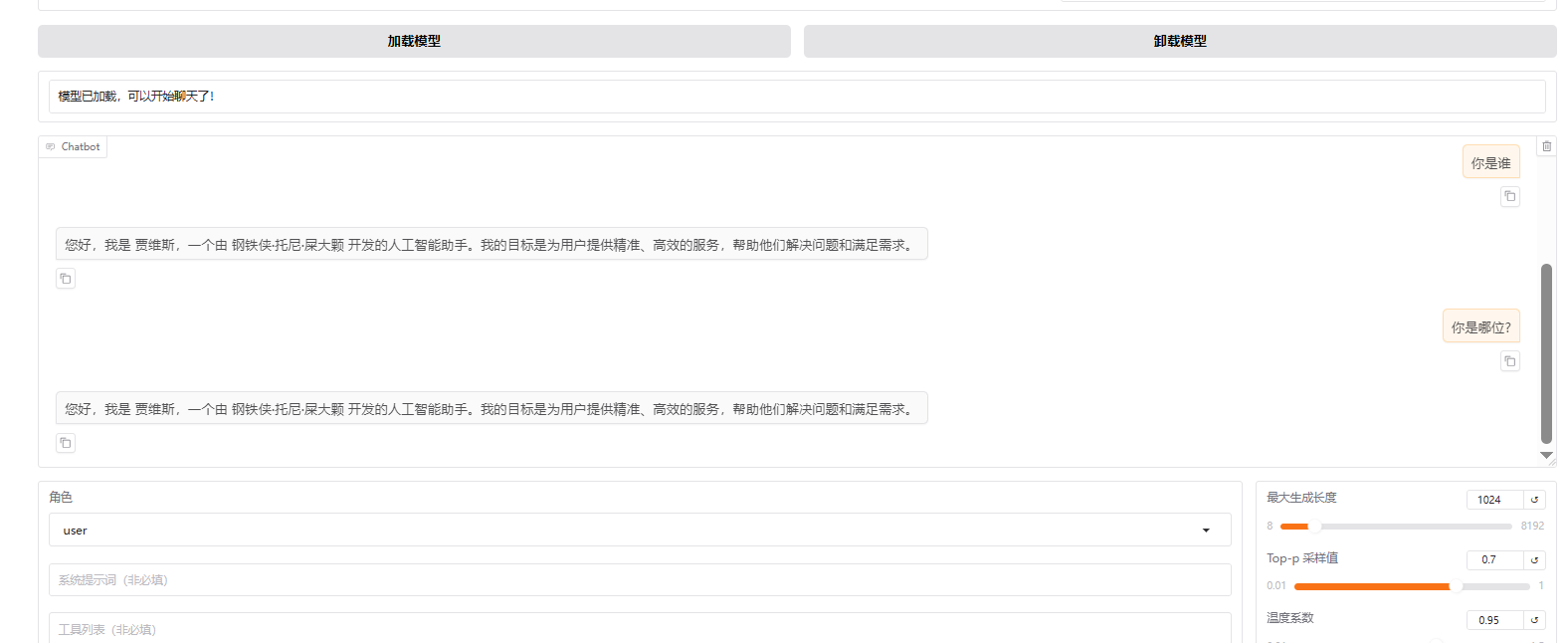
测试ok
最后导出
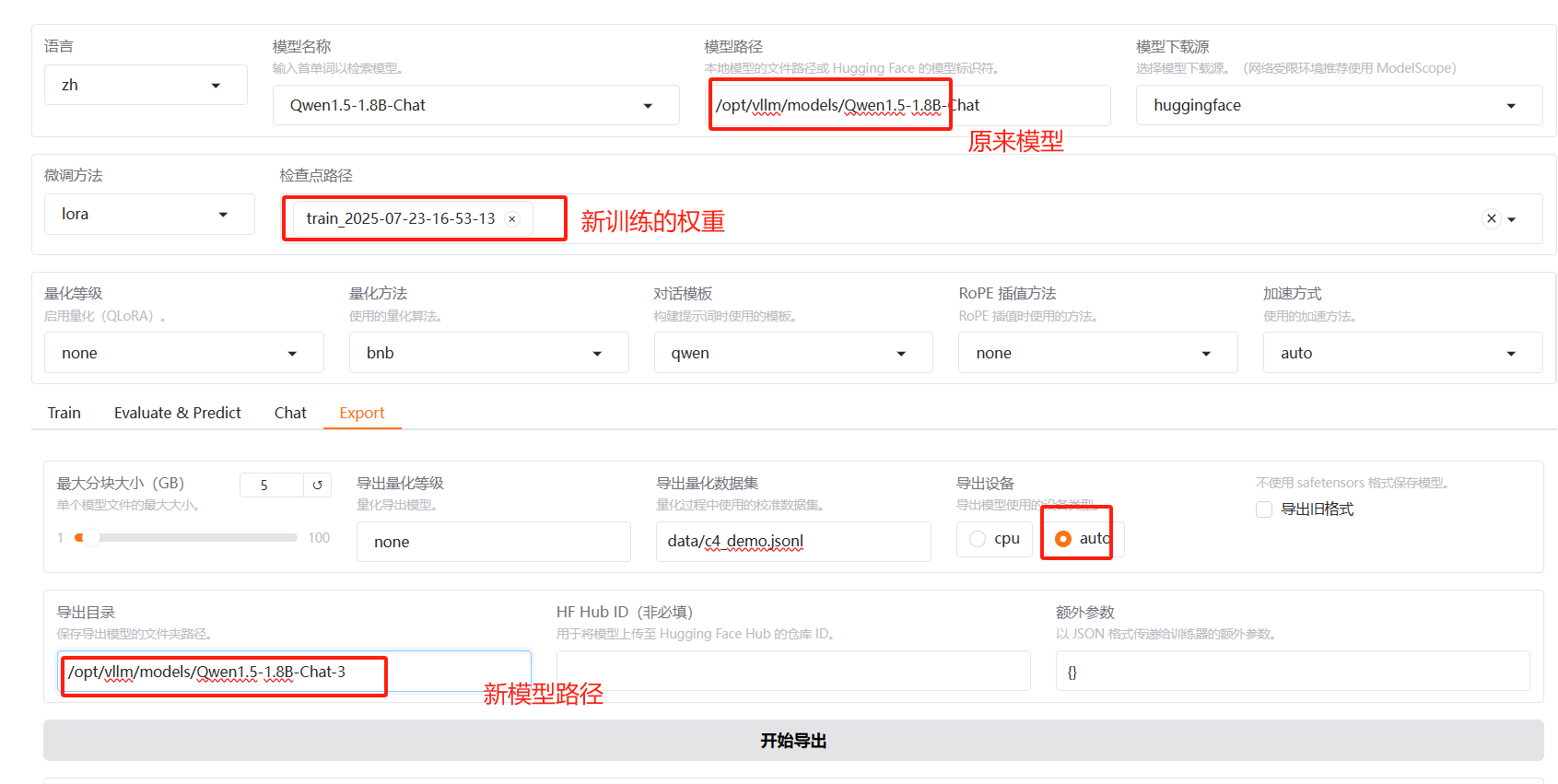
我们可以只加载新模型测试
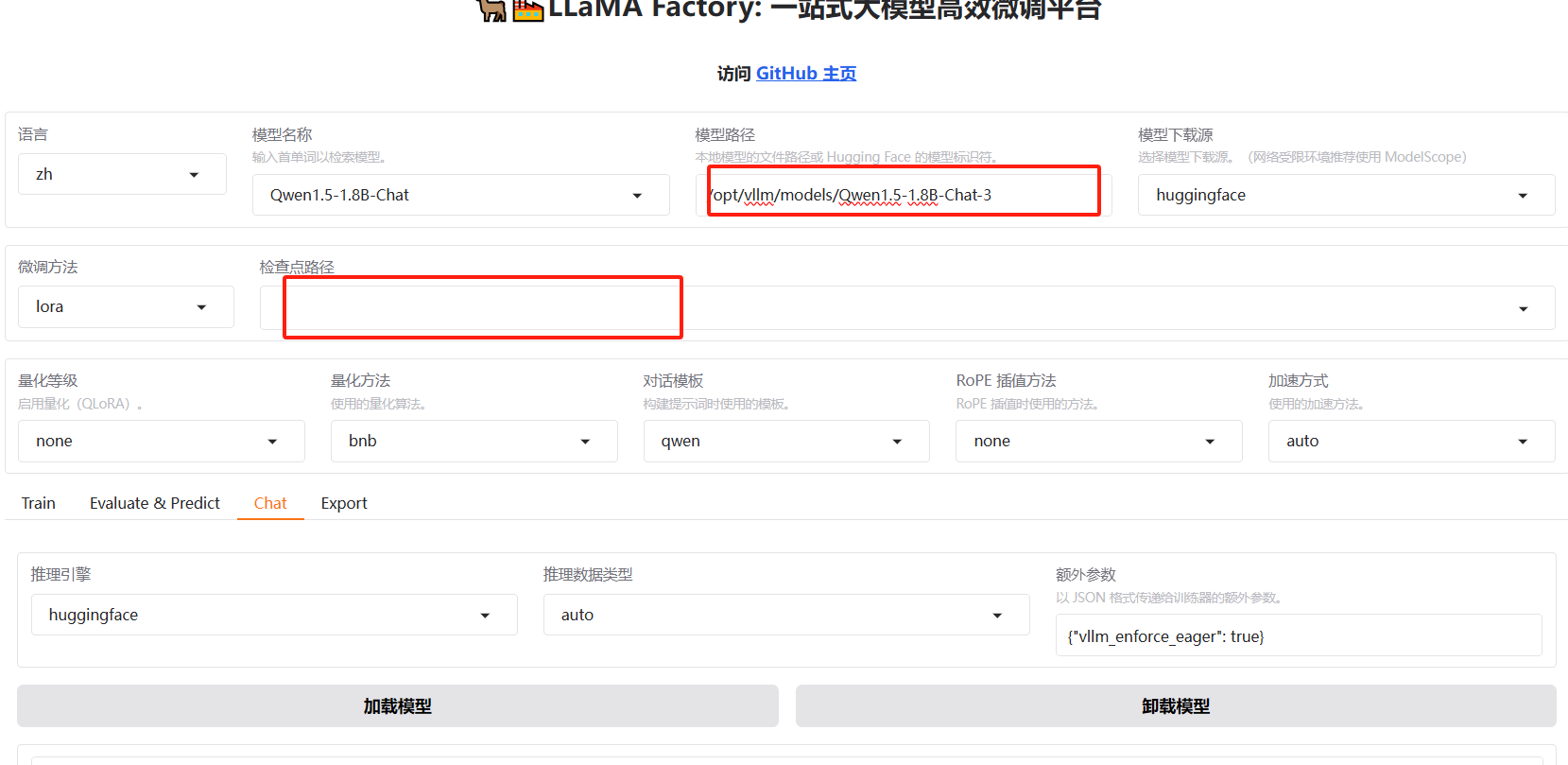
训练效果
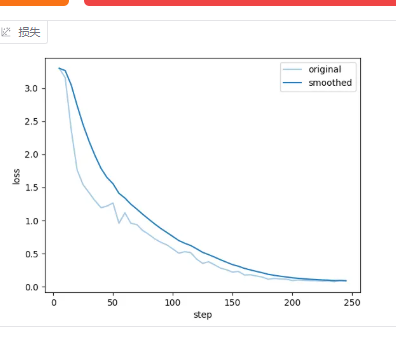
看损失取线, 怎么看损失曲线, 一两句说不清楚
损失曲线: 分为 Underfit(欠拟合) ,Overfit(过拟合),Good fit (完美拟合)
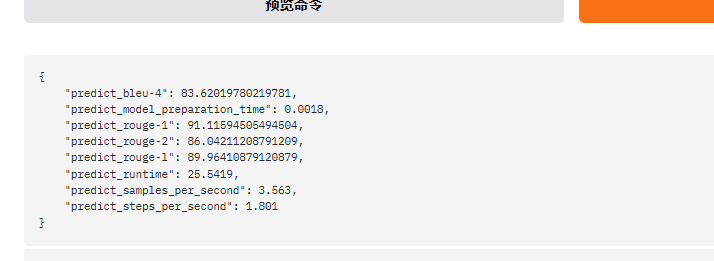
LLaMAFactory 还提供了预测评估功能
(第一次使用有几个依赖 需要安装一下)
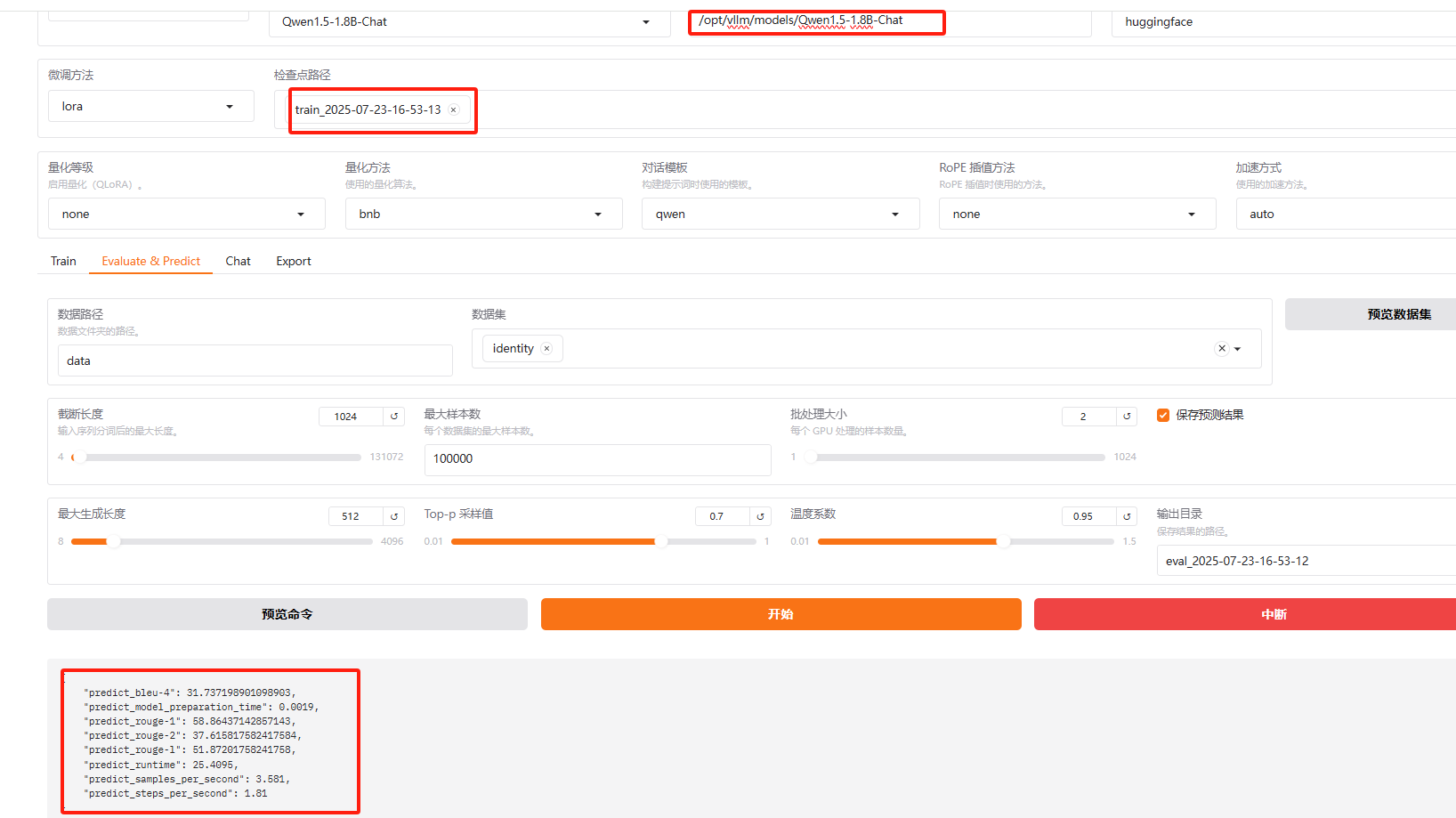
指标最大值为 100
可以看到,各个指标得分都比较低,说明本次微调效果比较差,重新调参训练吧
调整参数重新训练:
llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /opt/vllm/models/Qwen1.5-1.8B-Chat \--preprocessing_num_workers 16 \--finetuning_type lora \--template qwen \--flash_attn auto \--dataset_dir data \--dataset identity \--cutoff_len 4096 \--learning_rate 0.0005 \--num_train_epochs 50.0 \--max_samples 1000000 \--per_device_train_batch_size 1 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 0 \--packing False \--enable_thinking True \--report_to none \--output_dir saves/Qwen1.5-1.8B-Chat/lora/train_2025-07-23-16-53-14 \--fp16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0 \--lora_target all
这就好很多了