【datawhale组队学习】RAG技术 - TASK01
教程地址:https://github.com/datawhalechina/all-in-rag/tree/main
感谢datawhale的教程和贡献者们
文章目录
- 如何上手RAG
- 基础工具链:
- 四步构建最小可行系统(MVP)【 Minimum Viable Product】
- 嵌入和向量化
- 新手友好方案
- 什么是RAG
- 技术原理
- 技术演进
- 为什么要使用RAG
- 解决LLM的核心局限
- 关键优势
- 使用场景风险分级
如何上手RAG
基础工具链:
开发框架:
- LangChain:提供预置RAG链(如rag_chain),支持快速集成LLM与向量库
- LlamaIndex:专为知识库索引优化,简化文档分块与嵌入流程(索引:将非结构化文档(PDF/Word等)分割为片段,通过嵌入模型转换为向量数据。)
向量数据库:
- Milvus:开源高性能向量数据库
- FAISS:轻量级向量搜索库
- Pinecone:云服务向量数据库
四步构建最小可行系统(MVP)【 Minimum Viable Product】
- 数据准备
格式支持:PDF、Word、网页文本等
分块策略:按语义(如段落)或固定长度切分,避免信息碎片化 - 索引构建
嵌入模型:选取开源模型(如text-embedding-ada-002)或微调领域专用模型
向量化:将文本分块转换为向量存入数据库 - 检索优化
混合检索:结合关键词(BM25)与语义搜索(向量相似度)提升召回率
重排序(Rerank):用小模型筛选Top-K相关片段(如Cohere Reranker) - 生成集成
提示工程:设计模板引导LLM融合检索内容
LLM选型:GPT、Claude、Ollama等(按成本/性能权衡)
嵌入和向量化
嵌入模型(Embedding Model)的核心作用是将文本、图像、音频等非结构化数据转换为计算机可理解的低维稠密向量(Embedding),这些向量能够捕捉原始数据的语义信息或特征,使得机器可以通过向量运算(如余弦相似度、距离计算)来理解数据间的关联。
嵌入模型是向量化的一种高级实现:所有嵌入模型的输出都是向量(即完成了向量化),但并非所有向量化都依赖嵌入模型(如 One-Hot 编码、像素矩阵等简单向量化无需模型)。核心区别在 “语义 / 特征保留”:普通向量化仅解决 “可计算性”,而嵌入模型在此基础上额外解决了 “语义 / 特征关联性”,这也是嵌入模型在 NLP、推荐系统等领域广泛应用的原因。嵌入模型生成包含语义 / 特征关联的向量,使向量运算能反映数据的内在关系。必须通过深度学习模型训练实现(如 Word2Vec、BERT、CLIP 等)。适用于需要语义理解的场景(如检索、推荐、问答、聚类)。专门设计用于捕捉关联(如 “苹果” 和 “水果” 的嵌入向量距离更近)。
- 语义映射
将文本(如单词、句子、文档)转换为向量,使得语义相似的文本对应向量的余弦相似度更高。
例如:“猫” 和 “狗” 的向量距离较近,而 “猫” 和 “汽车” 的向量距离较远。 - 特征提取
从复杂数据中提取关键特征,将高维、稀疏的原始数据(如文本的 one-hot 编码)压缩为低维、稠密的向量,减少数据维度同时保留核心信息。 - 跨模态关联
部分嵌入模型支持跨模态转换(如 CLIP 模型),能将文本和图像映射到同一向量空间,实现 “用文字搜索图片” 或 “用图片搜索文字”。 - 支撑下游任务
生成的向量可直接用于机器学习或深度学习任务,如:- 文本检索(如搜索引擎、问答系统)
- 相似度计算(如重复内容检测)
- 分类与聚类(如文本情感分析、用户分群)
- 推荐系统(如基于内容的商品推荐)
新手友好方案
LangChain4j Easy RAG:仅需上传文档,自动处理索引与检索
FastGPT:开源知识库平台,可视化配置RAG流程
GitHub模板:如"TinyRAG"项目,提供完整代码 tinyrag地址
进阶方向:
检索质量:上下文相关性(Context Relevance)
生成质量:答案忠实度(Faithfulness)、事实准确性
性能优化:
索引分层:对高频数据启用缓存机制
多模态扩展:支持图像/表格检索
什么是RAG
融合信息检索与文本生成的技术范式。其核心逻辑是:在大型语言模型(LLM)生成文本前,先通过检索机制从外部知识库中动态获取相关信息,并将检索结果融入生成过程,从而提升输出的准确性和时效性
在LLM生成文本之前,先从外部知识库中检索相关信息,作为上下文辅助生成更准确的回答。
技术原理
双阶段架构:

关键组件:
-
索引:将非结构化文档(PDF/Word等)分割为片段,通过嵌入模型转换为向量数据。
-
检索:基于查询语义,从向量数据库召回最相关的文档片段(Context)。
-
生成:将检索结果作为上下文输入LLM,生成自然语言响应。
技术演进
-
初级RAG
- 基础“索引-检索-生成”流程
- 简单文档分块
- 基本向量检索机制
-
高级RAG
- 增加数据清洗流程
- 元数据优化
- 多轮检索策略
- 提升准确性和效率
-
模块化RAG
- 灵活集成搜索引擎
- 强化学习优化
- 知识图谱增强
- 支持复杂业务场景
为什么要使用RAG
解决LLM的核心局限
| 问题 | RAG的解决方案 |
|---|---|
| 静态知识局限 | 实时检索外部知识库,支持动态更新 |
| 幻觉(Hallucination) | 基于检索内容生成,错误率降低 |
| 领域专业性不足 | 引入领域特定知识库(如医疗/法律) |
| 数据隐私风险 | 本地化部署知识库,避免敏感数据泄露 |
关键优势
准确性提升
- 知识基础扩展
- 降低幻觉现象
- 可溯源引用
实时性保障
动态知识更新,减少时滞性
成本效益 - 避免频繁微调
- 降低推理成本
- 资源消耗优化
- 快速适应变化
可扩展性 - 多源集成
- 模块化设计
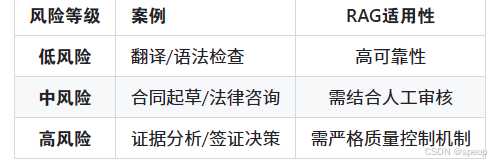
使用场景风险分级