大数据计算引擎(三)——Elasticsearch入门
介绍
它是一个建立在全文搜索引擎 Apache Lucene 基础上的,实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。
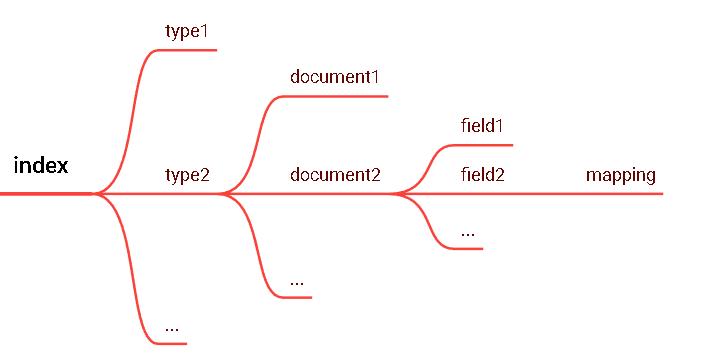
1 索引 index一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。2 类型 type在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。高版本ES中逐渐抛弃了type的概念,会有一个默认的type:_doc3 字段Field相当于是数据表的字段,对文档数据根据不同属性进行的分类标识4 映射 mappingmapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。5 文档 document一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。6 接近实时 NRTElasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)7 cluster集群(Cluster) 一个Elasticsearch集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识节点(Node)一个Elasticsearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例都应该会部署在不同的机器上。Elasticsearch的配置文件中可以通过node.master、node.data来设置节点类型。
- node.master:表示节点是否具有成为主节点的资格
- true代表的是有资格竞选主节点
- false代表的是没有资格竞选主节点
- node.data:表示节点是否存储数据
Node节点组合主节点+数据节点(master+data) 默认节点既有成为主节点的资格,又存储数据node.master: truenode.data: true数据节点(data)节点没有成为主节点的资格,不参与选举,只会存储数据node.master: falsenode.data: true客户端节点(client)不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡node.master: falsenode.data: false分片每个索引有1个或多个分片,每个分片存储不同的数据。分片可分为主分片(primary shard)和复制分片(replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复制分片,每个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个节点上副本这里指主分片的副本分片(主分片的拷贝)提高恢复能力:当主分片挂掉时,某个复制分片可以变成主分片;提高性能:get 和 search 请求既可以由主分片又可以由复制分片处理;分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
搭建配置
systemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动firewall-cmd --state # 查看防火墙下载Elasticsearch 地址: https://www.elastic.co/cn/downloads/elasticsearch 最新版本cd /opt/lxq/softwaretar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz -C ../serverscd ../servers/mv elasticsearch-7.3.0/ elasticsearch/vim /opt/lxq/servers/elasticsearch/config/elasticsearch.ymlnode.name: node-1 network.host: linux121 # # Set a custom port for HTTP: # http.port: 9200 cluster.initial_master_nodes: ["node-1"]vim /opt/lxq/servers/elasticsearch/config/jvm.options-Xms2g-Xmx2g要新增个用户 root用户无法启动ESuseradd estest#修改密码passwd estestchown -R estest /opt/lxq/servers/elasticsearch/ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错vim /etc/sysctl.conf 末尾添加:vm.max_map_count=655360sysctl -p修改linux系统对文件描述符的限制级别vim /etc/security/limits.conf末尾添加:* soft nofile 65536* hard nofile 65536* soft nproc 4096* hard nproc 4096启动ESsu estest/opt/lxq/servers/elasticsearch/bin/elasticsearch访问一下:http://linux121:9200
集群配置

第一步:先更改上面已经安装的那台ES的配置
cd /opt/lxq/servers/es/elasticsearch/configvim elasticsearch.yml内容如下:# 集群名字 cluster.name: myes ## 集群中当前的节点 node.name: linux121 ## 数据目录 path.data: /opt/lxq/servers/data/es # # 日志目录 path.logs: /opt/lxq/servers/logs/es # 当前主机的ip地址 network.host: linux121 http.port: 9200 #初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["linux121","linux122","linux123"] #写入候选主节点的设备地址 discovery.seed_hosts: ["linux121", "linux122","linux123"] http.cors.enabled: true http.cors.allow-origin: "*"第二步:其它机子也要弄好防火墙,创好用户,root不能启动
第三步:分发/opt/lxq/servers/es/elasticsearch到其它两台机子
第四步:其它机子要改elasticsearch.yml文件,只要改node.name,network.host就行了,改成自己当前机子
所有机子启动,这里是后台启动,要发现错误的话,去/opt/lxq/servers/logs/es目录下查看。nohup /opt/lxq/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &访问一下:http://linux12[1,2,3]:9200/?pretty pretty是美化输出格式
操作命令
# 创建索引
PUT /索引名称
{
"settings": {
"属性名": "属性值"
}
}# 判断索引是否存在 200 - OK 就是存在的
HEAD /索引名称
# 获取索引详情
GET /索引名称1,索引2,索引3....# 查看所有索引详情,下面两种都行GET _allGET /_cat/indices?v# 打开索引POST /索引名称/_open# 关闭索引POST /索引名称/_close# 删除索引DELETE /索引名称1,索引名称2,索引名称3...# 配置索引映射PUT /索引库名/_mapping{"properties": {"字段名": {"type": "数据类型","index": true, //是否索引,不索引就无法针对这个字段查询"store": false, //存储,默认不存储,_source:存储了文档的所有字段内容;从_source字段中可以获取所有字段,但是需要自己解析,如果对某个字段指定了存储,在查询时直接指定返回的字段会增加io开销。"analyzer": "分词器","format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"}}}示例:PUT /lxq-company-index PUT /lxq-company-index/_mapping/ { "properties": { "name": { "type": "text", "analyzer": "ik_max_word" }, "job": { "type": "text", "analyzer": "ik_max_word" }, "logo": { "type": "keyword", "index": "false" }, "payment": { "type": "float" } } }# 获取索引映射详情GET /索引名称/_mapping# 查看所有映射GET _mapping GET _all/_mapping# 修改索引映射PUT /索引库名/_mapping{"properties": {"字段名": {"type": "类型","index": true,"store": true,"analyzer": "分词器"}}}# 一次性创建索引和映射put /索引库名称{"settings":{"索引库属性名":"索引库属性值"},"mappings":{"properties":{"字段名":{"映射属性名":"映射属性值"}}}}# 创建文档 —— 手动指定idPOST /索引名称/_doc/{id}# 创建文档 —— 自动生成idPOST /索引名称/_doc{"field":"value"}# 获取文档详情 重要的是:_source存着文档的全部内容GET /索引名称/_doc/{id}# 查询所有文档
POST /索引名称/_search{"query":{"match_all": {}}}# 某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使用逗号分隔GET /lxq-company-index/_doc/1?_source=name,job# 全局更新文档 下面的5代表id,id存在则更新文档内容,id不存在则新增文档内容PUT /lxq-company-index/_doc/5{"name" : "百度","job" : "大数据工程师","payment" : "300000","logo" :"http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png"}注意:Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者POST) 局部更新,只是修改某个字段(使用POST)# 局部更新文档
POST /索引名/_update/{id}{"doc":{"field":"value"}}# 删除文档DELETE /索引名/_doc/{id}POST /索引库名/_delete_by_query{"query": {"match": {"字段名": "搜索关键字"}}}POST /索引名/_delete_by_query{"query": {"match_all": {}}}
查询DSL(Domain Specific Language 特定域的语言)AST(抽象语法树)
Elasticsearch提供了基于JSON的完整查询DSL(Domain Specific Language 特定域的语言)来定义查询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句 叶子查询子句 在特定域中寻找特定的值,如 match,term或 range查询。
- 复合查询子句 复合查询子句包装其他叶子查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(例如 constant_score查询)。
我们在使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会SQL语法一样。基本语法POST /索引库名/_search{"query":{"查询类型 例如: match_all , match , term , range 等等":{"查询条件":"查询条件值"}}}match 类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系POST /lxq-property/_search{"query":{"match":{"title":"小米电视4A"}}}这个结果不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是 or 的关系。"title": {"query": "小米电视4A","operator": "and"}只有同时包含 小米 和 电视 的词条才会被搜索到。match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含,而且顺序必须相同,而且必须都是连续的GET /lxq-property/_search{"query": {"match_phrase": {"title": "小米电视"}}}Query String Query提供了无需指定某字段而对文档全文进行匹配查询的一个高级查询,同时可以指定在哪些字段上进行匹配。该查询与match类似,但是match需要指定字段名query_string是在所有字段中搜索,范围更广泛。# 默认 和 指定字段GET /lxq-property/_search{"query": {"query_string" : {"query" : "2699"}}}GET /lxq-property/_search{"query": {"query_string" : {"query" : "2699","default_field" : "title"}}}# 逻辑查询GET /lxq-property/_search{"query": {"query_string" : {"query" : "手机 OR 小米","default_field" : "title"}}}GET /lxq-property/_search{"query": {"query_string" : {"query" : "手机 AND 小米","default_field" : "title"}}}# 模糊查询GET /lxq-property/_search{"query": {"query_string" : {"query" : "大米~1","default_field" : "title"}}}# 多字段支持GET /lxq-property/_search{"query": {"query_string" : {"query":"2699","fields": [ "title","price"]}}}如果你需要在多个字段上进行文本搜索,可用multi_match。multi_match在match的基础上支持对多个字段进行文本查询。GET /lxq-property/_search{"query": {"multi_match" : {"query":"小米4A","fields": [ "title","images"]}}}可以使用term-level queries根据结构化数据中的精确值查找文档。结构化数据的值包括日期范围、IP地址、价格或产品ID。与全文查询不同,term-level queries不分析搜索词。相反,词条与存储在字段级别中的术语完全匹配。term 查询用于查询指定字段包含某个词项的文档POST /book/_search{"query": {"term" : { "name" : "solr" }}}terms 查询用于查询指定字段包含某些词项的文档GET /book/_search{"query": {"terms" : { "name" : ["solr", "elasticsearch"]}}}gte:大于等于gt:大于lte:小于等于lt:小于boost:查询权重:在多条件组合查询时,可以手动控制每个条件的比重GET /book/_search{"query": {"range" : {"price" : {"gte" : 10,"lte" : 200,"boost" : 2.0}}}}GET book/_search{"query": {"range" : {"timestamp" : {"gte": "18/08/2020","lte": "2021","format": "dd/MM/yyyy||yyyy"}}}}查询指定字段值不为空的文档。相当 SQL 中的 column is not nullGET /book/_search{"query": {"exists" : { "field" : "price" }}}词项前缀搜索(prefix query)GET /book/_search{ "query": {"prefix" : { "name" : "so" }}}regexp允许使用正则表达式进行term查询.注意regexp如果使用不正确,会给服务器带来很严重的性能压力。比如.*开头的查询,将会匹配所有的倒排索引中的关键字,这几乎相当于全表扫描,会很慢。因此如果可以的话,最好在使用正则前,加上匹配的前缀。GET /book/_search{"query": {"regexp":{"name": "s.*"}}}GET /book/_search{"query": {"regexp":{"name":{"value":"s.*","boost":1.2}}}}模糊搜索(fuzzy query)GET /book/_search{"query": {"fuzzy" : { "name" : "sol" }}}GET /book/_search{"query": {"fuzzy" : { "name" : "so" }}}GET /book/_search{"query": {"fuzzy" : {"name" : {"value": "so""fuzziness": 2}}}}GET /book/_search{"query": {"fuzzy" : {"name" : {"value": "sorl"}}}}POST /book/_search{"query": {"fuzzy": {"name": {"value": "osrl","fuzziness":2}}}}ids搜索(id集合查询)GET /book/_search{"query": {"ids" : {"values" : ["1", "3"]}}}bool 查询用bool操作来组合多个查询子句为一个查询。 可用的关键字:must:必须满足filter:必须满足,对集合包含/排除的简单检查,计算速度非常快,不参与、不影响评分should:或must_not:必须不满足,在filter上下文中执行,不参与、不影响评分示例:description中必须包含java,price必须满足大于100小于1000,name字段可以是lucene或者是solr中的一种即可,时间满足。。。。POST /book/_search{"query": {"bool" : {"filter" : {"match" : { "description" : "java" }},"must": [{"range" : {"price" : { "gte" : 100, "lte" : 1000 }}},{"bool": {"should": [{"term":{"name":"lucene"}},{"term":{"name":"solr"}}]}}],"must_not": [{"range": {"timestamp": {"gte": "18/08/2020","lte": "2021","format": "dd/MM/yyyy||yyyy"}}}]}}}Elasticsearch中的所有的查询都会触发相关度得分的计算。对于那些不需要相关度得分的场景下,Elasticsearch以过滤器的形式提供了另一种查询功能,过滤器在概念上类似于查询,但是它们有非常快的执行速度,执行速度快主要有以下两个原因:
- 过滤器不会计算相关度的得分,所以它们在计算上更快一些。
- 过滤器可以被缓存到内存中,这使得在重复的搜索查询上,其要比相应的查询快出许多。
为了理解过滤器,可以将一个查询(像是match_all,match,bool等)和一个过滤器结合起来。我们以范围过滤器为例,它允许我们通过一个区间的值来过滤文档。这通常被用在数字和日期的过滤上。 下面这个例子使用一个被过滤的查询,其返回price值是在200到1000之间(闭区间)的书。示例:POST /book/_search{"query": {"bool": {"must": {"match_all": {}},"filter": {"range": {"price": {"gte": 200,"lte": 1000}}}}}}通常情况下,要决定是使用过滤器还是使用查询,你就需要问自己是否需要相关度得分。如果相关度是不重要的,使用过滤器,否则使用查询。查询和过滤器在概念上类似于SELECT WHERE语句。排序 并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序,按照相关性评分升序排序如下POST /book/_search{"query": {"match": {"description":"solr"}},"sort": [{"_score": {"order": "asc"}} // _score可以换成自己的字段]"sort": [{ "price": { "order": "desc" }},{ "timestamp": { "order": "desc" }}],"size": 2,"from": 2,"highlight": {"pre_tags": "<font color='pink'>","post_tags": "</font>","fields": [{"name":{}}]}}size:每页显示多少条from:当前页起始索引, int start = (pageNum - 1) * size高亮POST /book/_search{"query": {"query_string" : {"query" : "elasticsearch"}},"highlight": {"pre_tags": "<font color='pink'>","post_tags": "</font>","fields": [{"name":{}},{"description":{}}]}}⭐⭐⭐ 以下操作面向文档 ⭐⭐⭐mget 批量查询多个文档GET /_mget{"docs" : [{"_index" : "book","_id" : 1},{"_index" : "book","_id" : 2}]}GET /book/_mget{"docs" : [{"_id" : 2},{"_id" : 3}]}搜索简化写法POST /book/_search{"query": {"ids" : {"values" : ["1", "4"]}}}Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。如下操作,删除1,新增5,修改2。POST /_bulk{ "delete": { "_index": "book", "_id": "1" }}{ "create": { "_index": "book", "_id": "5" }}{ "name": "test14","price":100.99 }{ "update": { "_index": "book", "_id": "2"} }{ "doc" : {"name" : "test"} }实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操作、大小在几M正好。 bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据两不是一个确定的数据,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。 一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(ES的config下的elasticsearch.yml)中配置。http.max_content_length: 10mb聚合介绍POST /book/_search{"size": 0,"aggs": {"max_price": {"max": {"field": "price"}}}}### countPOST /book/_count{"query": {"range": {"price" : {"gt":100}}}}#统计条数(value_count统计某个字段有值的数量)POST /book/_search{"size": 0,"aggs": {"book_nums": {"value_count": {"field": "_id"}}}}stats 统计 count max min avg sum 5个值POST /book/_search?size=0{"aggs": {"price_stats": {"stats": {"field": "price"}}}}高级统计,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间group by havingPOST /book/_search{"size": 0,"aggs": {"group_by_price": {"range": {"field": "price","ranges": [{"from": 0,"to": 200},{"from": 200,"to": 400},{"from": 400,"to": 1000}]},"aggs": {"average_price": {"avg": {"field": "price"}},"having": {"bucket_selector": {"buckets_path": {"avg_price": "average_price"},"script": {"source": "params.avg_price >= 200 "}}}}}}}
每台机器都要配置IK分词器。配置完成之后,需要重启ES服务
安装配置
!!!在elasticsearch安装目录的plugins目录下新建 analysis-ik 目录# 新建analysis-ik文件夹mkdir analysis-ik# 切换至 analysis-ik文件夹下cd analysis-ik# 上传下载的 elasticsearch-analysis-ik-7.3.0.zip# 解压unzip elasticsearch-analysis-ik-7.3.3.zip如果解压出现:-bash: unzip: command not found需要安装:yum install -y unzip# 解压完成后删除ziprm -rf elasticsearch-analysis-ik-7.3.0.zip# 分发到其它节点cd ..scp -r analysis-ik/ linux122:$PWDscp -r analysis-ik/ linux123:$PWD# 杀死esps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9# 启动nohup /opt/lxq/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &# 重启kibanacd /opt/lxq/servers/kibana//bin/kibana
用法讲解
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of 等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。扩展词与停用词集中存储到linux123服务器上,使用web服务器集中管理,避免每个节点维护一份自己的词典Linux123使用es用户部署Tomcat,可参考我这边文章:Linux——CentOS7安装到Tomcat安装完成_linux c7 crontab.tar.gz安装包下载-CSDN博客《《《《《 简单嘞😀 》》》》》》
tomcat装完之后,配置需要的停用词,拓展词
cd /opt/lxq/servers/es/tomcat/webapps/ROOTvim ext_dict.dic内容如下:的 了 啊启动tomcat:/opt/lxq/servers/es/tomcat/bin/startup.sh访问:http://linux123:8080/ext_dict.dic 词就配置好了,接下来要es能获取到我们配置的词# 三个节点都需修改 建议用root用户改cd /opt/lxq/servers/es/elasticsearch/plugins/analysis-ik/configvim IKAnalyzer.cfg.xml内容如下:<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">http://linux123:8080/ext_dict.dic</entry><!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">http://linux123:8080/stop_dict.dic</entry></properties># 杀死esps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9# 启动nohup /opt/lxq/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &# 重启kibanacd /opt/lxq/servers/kibana//bin/kibana# 验证分词器POST _analyze{"analyzer": "ik_smart","text": "南京市长江大桥"}
界面(不用es head 用Kibana)
操作系统能装的版本
tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz -C ../servers/cd ../servers/mv kibana-7.3.0-linux-x86_64/ kibana/chown -R es /opt/lxq/servers/kibanachmod -R 777 /opt/lxq/servers/kibanavim /opt/lxq/servers/kibana/config/kibana.yml内容如下:server.port: 5601 server.host: "linux121" # The URLs of the Elasticsearch instances to use for all your queries. elasticsearch.hosts: ["http://linux121:9200","http://linux122:9200","http://linux123:9200"]切换用户su escd /opt/lxq/servers/kibana//bin/kibana访问linux121:5601,即可看到安装成功,《《《《《《《简单嘞 😀》》》》》》
拓展
扩展kibana dev tools快捷键:
ctrl+enter 提交请求
ctrl+i 自动缩进倒排索引
Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。例如,假设我们有两个文档,每个文档是如下内容:1. The quick brown fox jumped over the lazy dog2. Quick brown foxes leap over lazy dogs in summer要创建倒排索引,首先要将每个文档内容拆分成单独的词,创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档
感谢阅读!!!