Transformer架构的编码器和解码器介绍
Transformer 架构是一种基于自注意力机制(Self-Attention)的深度学习模型,由 Google 团队在 2017 年的论文《Attention Is All You Need》中首次提出。
Transformer 彻底改变了自然语言处理(NLP)领域,并成为现代大语言模型(如GPT、BERT等)的核心基础。
Transformer 与循环神经网络(RNN)类似,旨在处理自然语言等顺序输入数据,适用于机器翻译、文本摘要等任务。然而,与 RNN 不同,Transformer 无需逐步处理序列,而是可以一次性并行处理整个输入。
1.1 整体架构
Transformer是由编码器和解码器组成的。 Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。
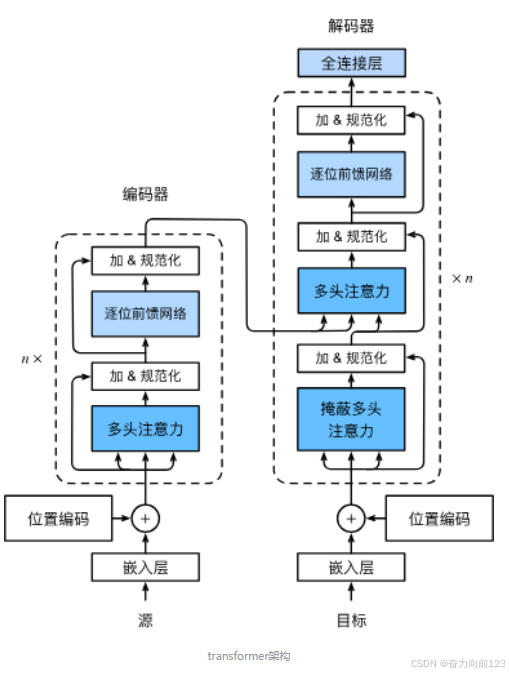
1.2 编码器架构
从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。每个子层都采用了残差连接(residual connection)。在Transformer中,对于序列中任何位置的任何输入 �∈�� ,都要求满足 ��������(�)∈�� ,以便残差连接满足�+��������(�)∈��。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量。
1.3 解码器架构
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
1. 输入处理(底部)
- Embeddings/Projections(嵌入/投影层)
- 作用:将输入的单词(或 token)转换成数字向量(比如 "猫" → [0.2, -0.5, 0.7…])。
- 类比:就像给每个单词分配一个独特的"身份证号码",但更智能(包含语义信息)。
2. 编码器(左侧)
-
Multi-Headed Self-Attention(多头自注意力)
- 作用:让模型同时关注输入中的所有单词,并计算它们之间的关系。
- 举例:在句子"猫追老鼠"中,模型会学习"猫"和"老鼠"的关联比"猫"和"追"更强。
- 关键:并行处理所有单词,不像RNN需要逐个计算。
-
Norm(层归一化)
- 作用:稳定训练过程,防止数值过大或过小(类似"调音量"到合适范围)。
-
Feed-Forward Network(前馈神经网络)
- 作用:对每个单词的表示进行进一步加工(比如提取更复杂的特征)。
- 类比:像对"猫"的向量做一次深度解读,补充细节(比如"猫是哺乳动物")。
3. 解码器(右侧)
-
Masked Multi-Headed Self-Attention(掩码多头自注意力)
- 作用:训练时防止模型"作弊"(只能看到当前和之前的单词,不能看未来的)。
- 举例:生成"我爱__"时,模型只能基于"我""爱"预测下一个词,不能提前知道答案是"你"。
-
Multi-Headed Cross-Attention(多头交叉注意力)
- 作用:让解码器询问编码器:"关于输入,我应该重点关注什么?"
- 场景:翻译任务中,解码器生成英文时,会参考编码器处理的中文输入。
-
Norm 和 Feed-Forward Network
- 与编码器类似,对解码器的表示进行归一化和深度处理。
4. 输出(顶部)
- Linear(线性层)
- 作用:将解码器的输出映射到词表(比如预测下一个词是"你"的概率最高)。
- 举例:输入"我爱",模型输出"你"的概率可能是80%,"吃饭"的概率是10%…