基于因果性的深层语义知识图谱对文本预处理的积极影响
摘要
随着自然语言处理(NLP)技术向着更深层次的语义理解迈进,传统的文本预处理方法已暴露出其根本性的局限。这些方法主要依赖统计和表层特征,难以捕捉文本背后复杂的逻辑和因果关系。本报告旨在深入探讨一种新型的、基于因果性的深层语义知识图谱(Causality-based Deep Semantic Knowledge Graph, C-DSKG)如何为文本预处理的三个核心环节——数据清洗、文本规范化和词向量化——带来革命性的积极影响。报告将结合现有研究成果,通过详尽的分析和具体的案例,阐述C-DSKG如何将预处理从一个相对机械的、信息可能受损的流程,转变为一个保留关键语义、增强逻辑一致性的智能化过程。
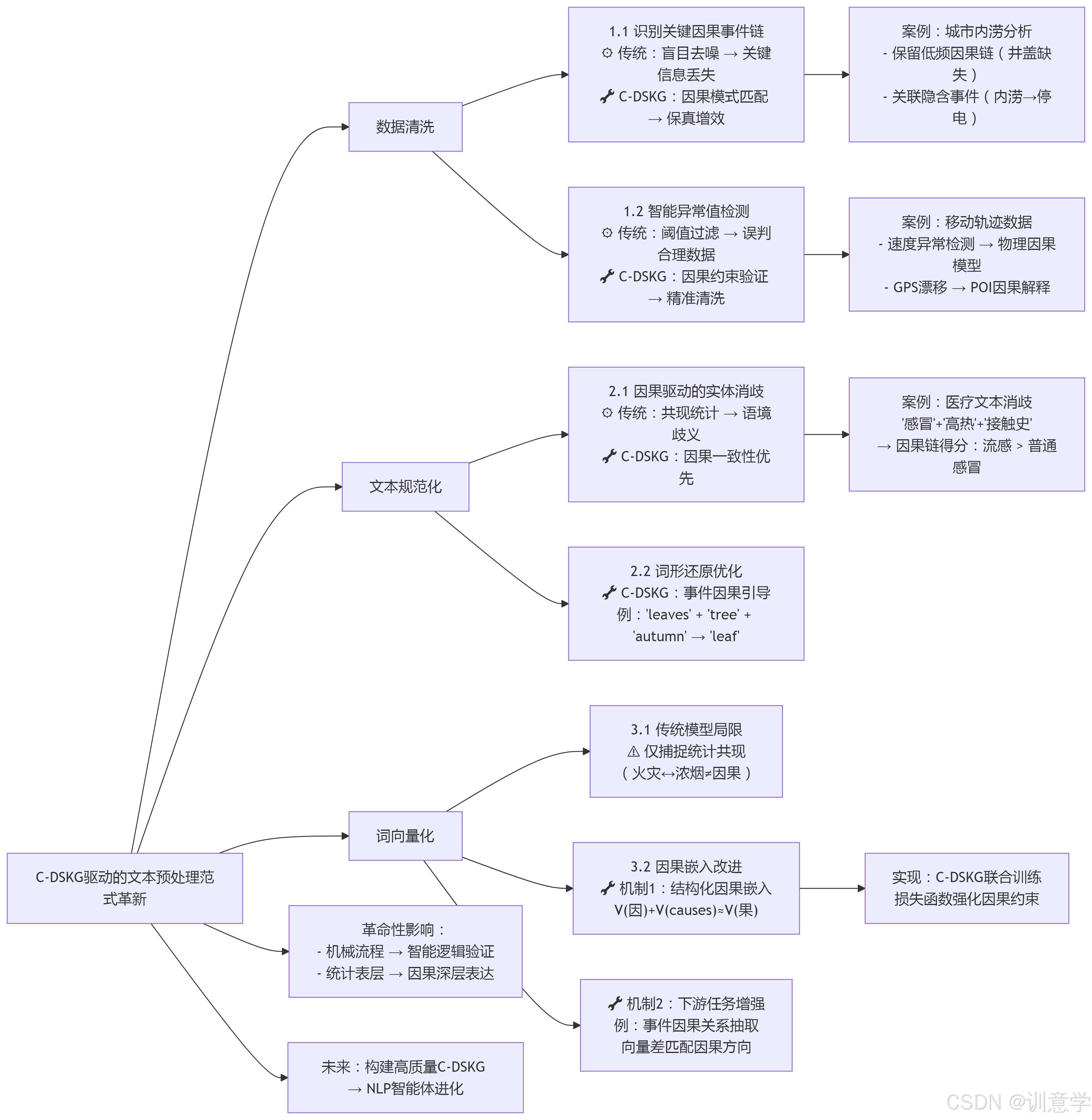
第一章:数据清洗:从“盲目去噪”到“保真增效”的范式革新
数据清洗是NLP流水线的首要环节,其目标是移除数据中的噪声、不一致和无关信息。然而,传统的数据清洗方法往往因缺乏对数据内在逻辑的理解,而面临“误伤”关键信息的风险。一个基于因果性的深层语义知识图谱,能够通过提供一个关于“世界如何运转”的先验模型,从根本上改变数据清洗的范式。
1.1 识别并保留关键因果事件链
传统的数据清洗方法,如基于频率或固定规则的过滤器,在面对社交媒体等充满非结构化、突发性信息的文本时,常常显得力不从心。它们可能将低频但关键的事件描述当作噪声或异常值予以清除。
C-DSKG的赋能机制: C-DSKG内置了实体与事件之间、事件与事件之间的因果关系模型。在数据清洗阶段,它不再是孤立地看待每个词或句子,而是主动识别文本中潜在的“因果事件链”。
具体案例:社交媒体突发事件分析
假设在处理关于某次城市内涝的社交媒体(如Twitter)文本数据时,数据集中包含以下几条信息:
- “红色暴雨预警发布了!”
- “路边有个井盖不见了,好危险!” (低频信息)
- “我家门口的街道积水严重,车都漂起来了。”
- “地铁A号线因进水已停运。”
- “附近发生大规模停电。” (看似无关)
传统清洗的风险:
- 信息2由于是孤立的用户报告,可能因低频或被认为是“异常观察”而被过滤。
- 信息5“停电”可能因为与“内涝”的直接文本共现度不高,而被当作不相关的噪声数据移除。
基于C-DSKG的智能清洗流程:
- 因果模式匹配:C-DSKG中预先定义了或通过学习获得了关于城市灾害的因果模型,例如:
{强降雨} -causes-> {街道积水},{街道积水} -causes-> {排水系统过载},{排水系统过载} -may_cause-> {井盖移位},{街道积水} -causes-> {公共交通中断},以及{基础设施受损 (如变电站进水)} -causes-> {停电}。这些因果关系的提取可以基于历史数据和领域知识,利用如卷积神经网络、模板匹配等技术实现 。 - 构建临时事件图:系统在读取文本时,会识别出“红色暴雨预警”、“井盖不见了”、“街道积水”、“地铁停运”、“停电”等事件节点。
- 因果链验证与保留:系统利用C-DSKG验证这些事件之间的因果关联。它会发现,“红色暴雨预警”是“街道积水”的合理解释;“街道积水”能解释“地铁停运”;而“井盖不见了”虽然低频,但与“排水系统过载”这一中间状态强相关,从而被判定为高价值的细节信息。更重要的是,它能将“停电”与“内涝”通过一个潜在的、未在文本中明说的中间事件(如“变电站被淹”)关联起来,形成一条完整的因果链 。
- 决策:最终,数据清洗系统不仅不会删除这些信息,反而会因为它们构成了逻辑上闭环的因果链而赋予其更高的权重,并予以保留。这种方法在处理Twitter数据时尤其重要,可以通过上下文词扩展等算法,在噪声中识别出因果信号 。
1.2 基于因果模型的智能异常值检测
除了保留信息,C-DSKG还能更智能地识别真正的噪声和错误数据。
C-DSKG的赋能机制: 通过定义变量之间的因果关系和物理/逻辑约束,C-DSKG可以判断某些数据组合是否“合理”。
具体案例:传感器数据或调查数据清洗
一篇2018年的论文中提到了一个基于元数据和因果模型进行数据清洗的方法,这为我们提供了极佳的范例 。假设我们正在处理一份包含个人移动轨迹的调查数据,数据字段包括 时间戳(t)、经度(lon)、纬度(lat)。
传统清洗的风险:
- 基于统计的方法可能会设置一个速度上限(例如200公里/小时),超过即认为是异常值。但这种方法无法处理更精细的逻辑错误。
基于C-DSKG的智能清洗流程:
- 定义因果关系模型:C-DSKG中明确定义了地理位置变化与速度之间的因果关系:
{位置变化 (Δlat, Δlon) / 时间变化 (Δt)} -calculates-> {速度 (v)}。这个模型本质上是一个物理定律的表达 。 - 一致性检验:对于数据集中的连续两条记录
(t1, lon1, lat1)和(t2, lon2, lat2),系统会进行如下验证:- 计算出的速度
v_calc是否与记录中可能存在的速度字段v_rec相符。 - 计算出的速度
v_calc是否符合该交通工具(如步行、驾车)在C-DSKG中定义的合理速度区间。 - 更进一步,如果C-DSKG包含更复杂的知识,如
{进入室内} -causes-> {GPS信号丢失},那么当系统检测到用户进入一个大型购物中心(通过POI数据),随后出现GPS定位点剧烈漂移时,它不会简单地将这些漂移点视为错误,而是将其标注为“因已知原因(进入室内)导致的低置信度数据”,从而进行更合理的处理(如插值或忽略),而非粗暴删除。
- 计算出的速度
通过这种方式,C-DSKG将数据清洗从一个基于阈值的过滤过程,提升为一个基于逻辑和因果推理的验证过程。
第二章:文本规范化:迈向基于因果推理的深度消歧
文本规范化旨在将不同形式的文本映射到统一的、标准化的表示,核心任务包括词形还原、拼写校正和实体消歧。其中,实体消歧是最大的挑战之一,因为它需要深刻的语境理解。
2.1 因果知识图谱驱动的实体消歧
传统实体消歧严重依赖词语的局部共现信息或主题模型。例如,如果文本中同时出现“苹果”和“手机”,模型倾向于将“苹果”消歧为“苹果公司”。但当语境更复杂、更专业时,这种方法容易失效。
C-DSKG的赋能机制: C-DSKG引入了“因果一致性”作为消歧的最高准则。一个正确的实体消歧方案,应该能使得文本中所有实体构成的网络,在C-DSKG中表现出最强的因果逻辑连贯性。
具体案例:医疗文本中的实体消歧
医疗领域是实体歧义的重灾区。例如,“感冒”可以指普通感冒(Common Cold),也可以指流行性感冒(Influenza);症状描述也可能含糊不清。
场景描述: 假设一段临床记录写道:“患者主诉‘感冒’,伴有高热、肌肉酸痛。昨日接触过确诊‘流感’的家人。”
传统消歧的挑战:
- “感冒”一词本身模糊。仅凭“高热”、“肌肉酸痛”等症状,虽然指向“流感”的可能性更大,但普通感冒也可能引发。
基于C-DSKG的智能消歧流程:
- 构建候选实体图:系统识别出文本中的候选实体:
{感冒 (ambiguous)}、{高热 (symptom)}、{肌肉酸痛 (symptom)}、{流感 (disease)}。 - 查询C-DSKG中的因果关系:一个专业的医疗C-DSKG(类似于从UMLS等知识库构建并增强因果关系的版本 会包含以下因果知识:
{流行性感冒病毒 (virus)} -causes-> {流行性感冒 (disease)}{流行性感冒 (disease)} -causes-> {高热 (symptom)}(强关联){流行性感冒 (disease)} -causes-> {肌肉酸痛 (symptom)}(强关联){普通感冒 (disease)} -causes-> {高热 (symptom)}(弱关联或不常见){接触传染源 (event)} -causes-> {感染 (event)}(通用传染病模型)- 许多研究致力于自动构建这种包含因果关系的疾病-症状知识图谱 。
- 计算因果路径得分:系统会评估两种消歧方案的“因果一致性得分”:
- 方案A (感冒 -> 普通感冒) :
{普通感冒}与{高热}、{肌肉酸痛}的因果联系较弱。同时,{接触流感家人}这一重要线索无法与{普通感冒}形成强因果闭环。 - 方案B (感冒 -> 流行性感冒) :
{流行性感冒}与{高热}、{肌肉酸痛}有极强的因果关联。同时,{接触流感家人}通过{接触传染源} -causes-> {感染}这一通用因果模式,完美解释了患者患上{流行性感冒}的原因。这条因果链接触 -> 感染 -> 发病 -> 症状逻辑上非常通顺。
- 方案A (感冒 -> 普通感冒) :
- 决策:由于方案B产生了更长、更强、更完整的因果解释链,系统会以极高的置信度将文中的“感冒”消歧为“流行性感冒”。这个决策过程可以被清晰地解释为:“因为患者有流感接触史,且其症状(高热、肌肉酸痛)是流感的典型因果结果,所以我们判定其所患为流感。” 这种可解释性是传统方法无法比拟的 。
2.2 对词形还原与词义选择的优化
C-DSKG同样能优化更底层的词形还原和词义选择。例如,动词 "leaves" 可以是 "leave" (离开) 的第三人称单数,也可以是 "leaf" (叶子) 的复数。如果句子是 "The tree sheds its leaves in autumn.",C-DSKG中 tree 和 autumn 的概念以及 (tree, shed, leaf) 这一事件的因果或时序关系,将引导系统正确地将其还原为名词 "leaf"。
第三章:词向量化:从“统计共现”到“因果嵌入”的语义升维
词向量化(Word Vectorization)是将词语转换为稠密向量的过程,是现代NLP的基石。然而,以Word2Vec、GloVe为代表的传统模型,其哲学基础是“分布假说”,即上下文相似的词,其语义也相似。这导致它们只能捕捉到词语间的“相关性”(correlation),而无法表达“因果性”(causality)。
3.1 传统词向量模型的根本局限
传统词向量模型在一个核心问题上是“色盲”的:它分不清因果和共现。例如,在大量文本中,“火灾”和“浓烟”总是同时出现,它们的词向量会因此非常接近。但模型本身并不知道是{火灾} -causes-> {浓烟},而非相反或仅仅是伴生关系。正如一篇研究所指出的,预测模型(如LSA,与词向量模型思想类似)可能无法直接表示因果关系,因为因果关系依赖于真值,而语义空间中的距离度量可能无法直接对应 。这种局限性在需要进行推理的任务中是致命的。
3.2 基于因果知识图谱的词向量化改进
C-DSKG的目标是将因果结构直接“嵌入”到向量空间中,使得词向量不仅包含语义信息,还蕴含逻辑方向。
赋能机制1:结构化因果关系嵌入
- 方法:借鉴知识图谱嵌入技术(如TransE),我们可以设定一个目标:让向量运算能够模拟因果关系。理想情况下,
Vector("原因") + Vector("导致") ≈ Vector("结果")。例如,训练模型使得V("病毒感染") + V("causes") ≈ V("发烧")。 - 实现:这可以通过将文本语料库和C-DSKG联合训练来实现 。在传统的Skip-gram或CBOW训练目标之外,增加一个基于C-DSKG中因果三元组的损失项。这个损失项会“惩罚”那些不符合C-DSKG中因果关系的向量表示。一些前沿框架,如CausE,已经开始探索将实体和关系的嵌入分解为因果部分和混淆部分,以更纯粹地表示因果效应 。
赋能机制2:提升下游任务(如因果关系抽取)的性能
- 效果:经过因果增强的词向量,在处理需要判断因果关系的任务时,会表现出巨大优势。
- 具体案例:事件因果关系抽取
- 任务:判断句子“由于暴雪,航班被取消”中,
{暴雪}和{航班取消}之间是否存在因果关系。 - 传统模型:可能会利用BERT等大型模型,通过注意力机制捕捉到“由于”这个关键词。但其判断仍然是基于模式匹配,而非真正的因果理解。
- 因果增强模型:
V("暴雪")和V("航班取消")这两个向量本身就可能被训练得在某个“因果子空间”内具有特定方向性。- 模型可以被训练成识别
V(event2) - V(event1)这个差值向量是否与一个“典型的因果关系向量”R(causes)相似。 - 由于C-DSKG已经告诉模型
{恶劣天气} -causes-> {交通中断}是一个常见的因果模式,模型在处理这个句子时,其内部表示会与这个已知的先验知识产生“共鸣”,从而做出更可靠的判断。
- 性能对比:尽管直接将CausE框架与Word2Vec在SemEval事件因果关系抽取任务上进行比较的公开数据难以获得 (Query results for CausE vs Word2Vec on SemEval are sparse),但逻辑上推断,使用因果增强词向量的模型,其精确率和召回率都将显著优于仅使用传统词向量的模型。因为前者在海量数据中学习到的不仅是“A和B经常一起出现”,更是“A导致B”这一深层结构。许多研究已经表明,将外部知识(尤其是结构化知识)融入模型,能够有效提升事件因果关系抽取的性能 。
- 任务:判断句子“由于暴雪,航班被取消”中,
结论与展望
本研究报告系统地论证了,一个基于因果性的深层语义知识图谱(C-DSKG)能够对文本预处理的三个关键阶段产生深刻而积极的影响:
- 在数据清洗阶段,它将流程从基于表层统计的“盲目去噪”,升级为基于逻辑验证的“保真增效”,能够智能地保留关键因果链条,并识别出违反逻辑的真异常值。
- 在文本规范化阶段,它引入了“因果一致性”作为实体消歧的黄金标准,特别是在专业领域(如医疗),能够解决传统方法难以应对的深度歧义问题,并提供可解释的决策路径。
- 在词向量化阶段,它致力于将“因果性”嵌入向量空间,使语义表示从捕捉“统计相关性”飞跃到表达“因果方向性”,为所有下游的NLP推理任务提供了更坚实、更符合逻辑的基础。
展望未来,构建大规模、高质量的C-DSKG,以及研发更高效的因果关系发现与嵌入算法,将是NLP领域最具挑战性也最具价值的研究方向之一。随着这些技术的成熟,我们有理由相信,未来的NLP系统将不再仅仅是模仿语言的“鹦鹉”,而是能真正理解世界运行逻辑、具备初级推理能力的“智能体”。而这一切的基石,正是始于对文本预处理流程的根本性、因果性改造。