基于强化学习的柔性机器人控制研究
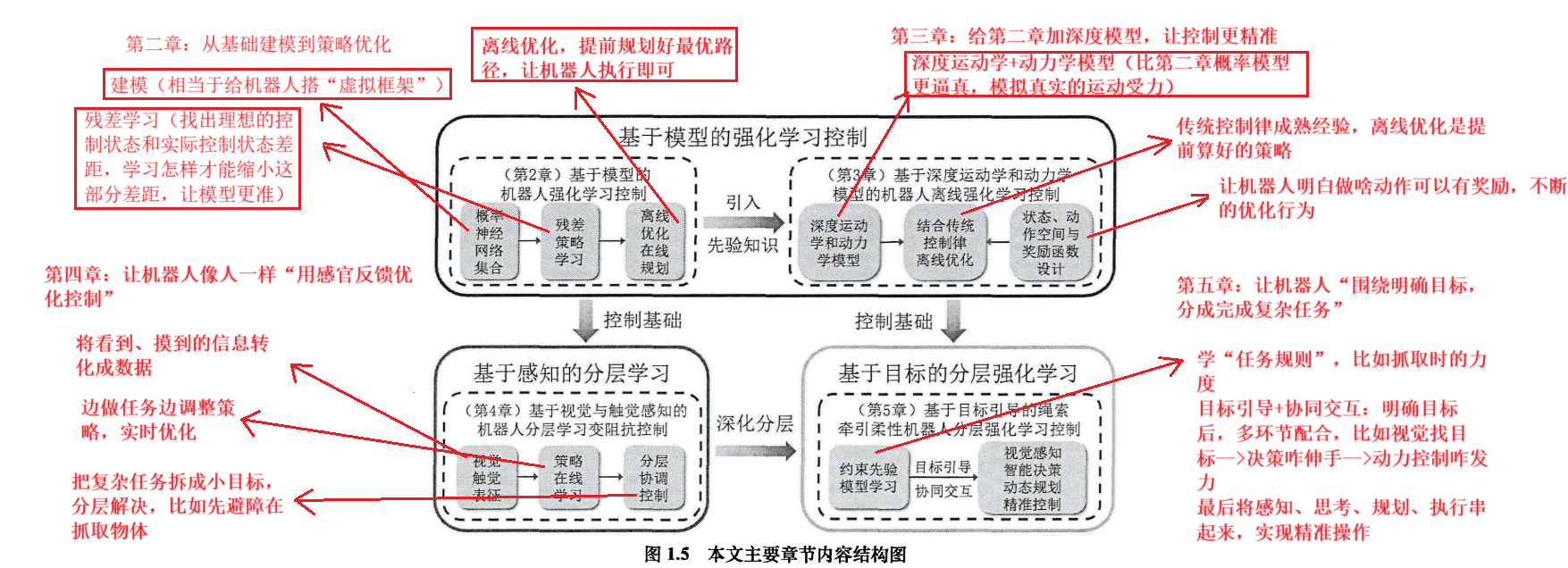
第二、三章是“基础控制方法”,先学会用模型+强化学习控制机器人,第四、五章是“分层应用”(给控制加感知力、目标感,解决更复杂的问题)
---------------------------------------------------------------------------------------------------------------------------
1.马尔可夫决策过程(MDP)给机械臂轨迹跟踪任务建模----将机械臂轨迹跟踪这事,套进一个叫“马尔可夫决策过程(MDP)”的框架里分析,用公式![]()
其中状态空间S:机械臂所有可能的状态,比如位置、角度等,用![]() 表示当前时刻状态
表示当前时刻状态
动作空间A:机械臂能做的动作,像移动、旋转,选动作![]() 去执行
去执行
状态转移![]() :执行动作
:执行动作![]() 后从当前状态
后从当前状态![]() ,转移到下一状态的概率
,转移到下一状态的概率![]()
奖励函数![]() :做动作
:做动作![]() 后给个奖励分,衡量任务做的怎么样
后给个奖励分,衡量任务做的怎么样
折扣因子![]() :平衡眼前奖励和未来奖励,比如
:平衡眼前奖励和未来奖励,比如![]() 越接近1,就看重长远奖励
越接近1,就看重长远奖励
强化学习的目标就是找策略![]() (根据当前状态选动作规则),让累积折扣奖励的期望最大
(根据当前状态选动作规则),让累积折扣奖励的期望最大
公式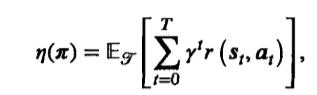 ,就是把每次动作奖励,按折扣算总和,希望这个折扣总和的期望最大,T是轨迹长度
,就是把每次动作奖励,按折扣算总和,希望这个折扣总和的期望最大,T是轨迹长度
基于模型的强化学习(MBRL)部分----核心是“先建环境和状态变化的预测模型,在用模型优化策略”
收集样本、训练模型:在实际环境里,记录状态咋转移的(执行完某一动作后咋变),拿这些数据训练模型,文中用“概率神经网络集合模型”,去拟合状态转移概率![]()
离线优化策略:用训练好的模型,在虚拟环境里模拟互动,试用不同的策略好不好使,选最优的,这样效率高,还不影响真实环境
在线调整+更新模型:把优化好的策略用在实际中,边用边优化
------------------------------------------------------------------------------------------------------------------------------
状态转移概率模型的学习
机械臂动起来得遵循物理规律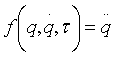 ,其中q表示关节角度,
,其中q表示关节角度,![]() 表示关节的速度,
表示关节的速度,![]() 表示施加的力,这个规则由函数f描述,可以计算出加速度
表示施加的力,这个规则由函数f描述,可以计算出加速度![]()
状态空间:研究机械臂轨迹跟踪时,重点关注它自身咋动的,不用管周围环境,专门搞了个状态空间,把关节角度q和关节速度![]() ,打包成一个状态
,打包成一个状态![]() ,用这样的一组数据,代表机械臂的一个状态
,用这样的一组数据,代表机械臂的一个状态
离散时间的状态转移:机械臂的运动是连续的,但计算机处理得拆成一步一步(离散化),所以有了![]() ,意思是知道当前状态
,意思是知道当前状态![]() ,在加上控制指令
,在加上控制指令![]() ,就能算出下一步状态
,就能算出下一步状态![]() ,不过机械臂运动有不确定性(比如摩擦力变化,测量误差)所以得用概率模型
,不过机械臂运动有不确定性(比如摩擦力变化,测量误差)所以得用概率模型![]() ,表示 执行动作
,表示 执行动作![]() 后从当前状态
后从当前状态![]() ,转移到下一状态的概率
,转移到下一状态的概率![]()
用神经网络来学这个模型:机械臂运动规律复杂普通方法不好模拟,所以用“深度神经网络”,它能从大量的数据里学出状态咋转移的
EPNNs模型:EPNNs模型可以想象成一群“小预测师”(概率神经网络模型),它的最终预测结果,是把这一群“小预测师”各自预测的结果,平均一下。而且EPNNs模型不是去猜下一个状态是啥,而是猜状态的变化,比如不是直接说下一刻温度是25度,而是说和现在比,温度变化了+2摄氏度,这样是未来让模型真正学清楚状态是咋变的,不单单记住执行完动作后,下一个状态是啥,而是状态是怎么变化的。
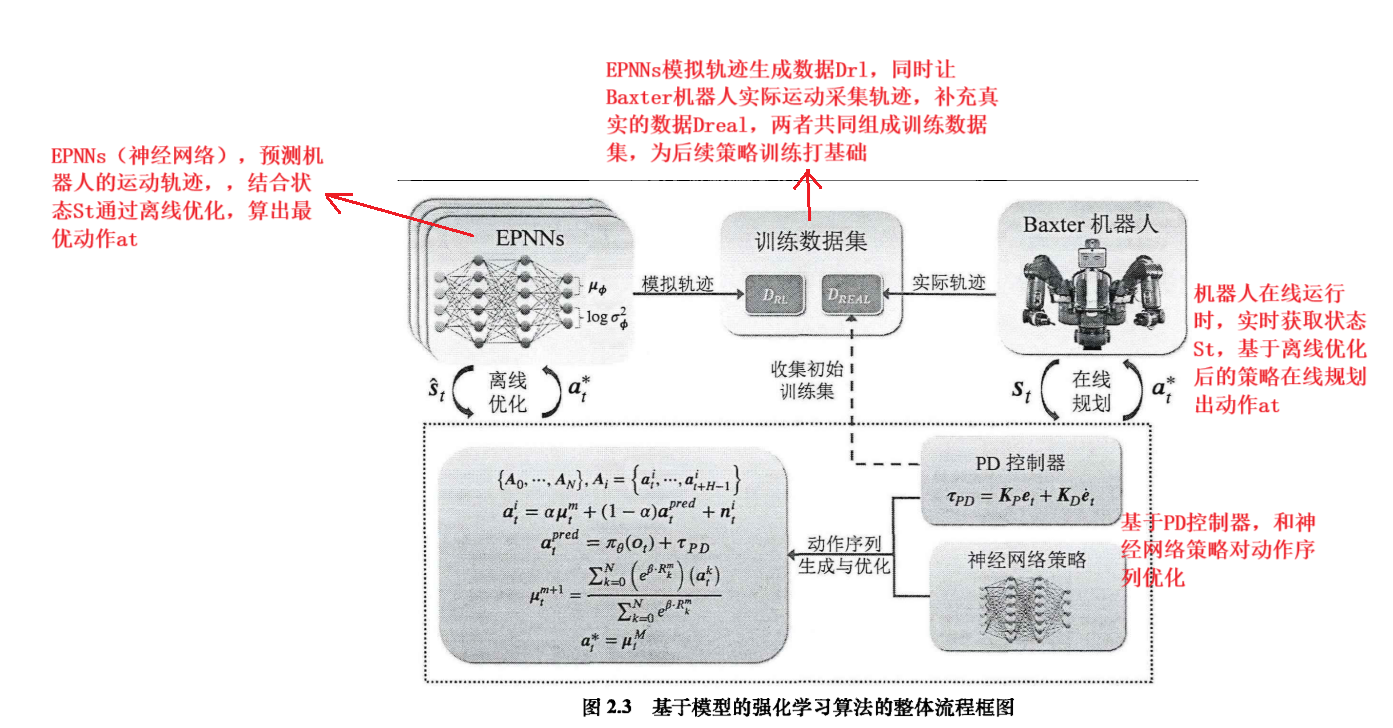
策略的基本逻辑:
“模拟预测”:机器人每时每刻,会从当前状态出发,用已经学过的“状态转移模型”,模拟各种可能的动作序列(比如先动胳膊再动腿,或者反过来)
“评估筛选”:模拟时,用“奖励函数”(动作让机器人越接近目标,奖励就高,撞墙了奖励就低),评估不同动作序列好坏,然后策略优化算法会综合考虑“动作对未来影响”和累计奖励,选出当前看来最优的动作序列
“只做第一步”:虽然模拟了一串动作,但实际只执行了第一个动作(参考模型预测MPC的思路),执行后状态更新,下次循环在重新规划,这样能避免模型预测不准带来的长期误差
动作序列怎么生成和优化:
“混合生成”:候选动作序列不是瞎猜的,是把“PD控制器的基础动作”“神经网络预测的动作”“随机探索噪声(防止只走老路,偶尔试试新路子)”,混在一起生成
![]() 就是控制这几部分对候选动作序列的权重
就是控制这几部分对候选动作序列的权重
迭代更新:每次生成一堆候选动作序列后,用奖励加权方式更新“动作平均值”,简单来说,奖励高的动作序列,权重就大,下次生成序列动作时,更倾向于参考它们,逐步优化

奖励咋算的:就是把未来一段时间的奖励加起来考虑折扣(未来的奖励没有当下值钱,毕竟变数多),评估动作序列的好坏
在线规划的短板:在线规划(实时循环里的模拟-执行-再规划)因为要实时算,没法深入分析所有可能性,容易收敛慢或者性能不够
离线优化补短板:离线的时候用大量计算资源,把各种可能的动作序列狠狠模拟,评估一遍,把策略优化的完善,这样在线规划时,直接用离线优化好的”半成品“
基于视觉与触觉感知的机器人分层学习变阻抗控制
上层规划系统的作用:想让机械臂做复杂任务时,能更好的理解周围环境,就得先处理摄像头等传感器的数据,把这部分数据变成有用的信息
变分自编码模型(VAE):机械臂摄像拍的图像数据(高维,冗余信息多),传统的AE模型难以应付,VAE能更好的处理
VAE不只是原样复制原图,还会学图像当中的隐藏规律(概率分布),将图像压缩成一个有意义的“特征向量”,方便后续分析,遇到模糊,有噪声的图像(光线不好的),也能提取出靠谱的特征
VAE用机械臂摄像头存的大量图像训练,构建一个“潜在空间”,模型分为俩部分,编码器把图像变成“特征向量”,解码器,再把特征向量变回原图像,假设“特征向量”符合高斯分布,通过调整参数,让模型输出的图像尽量和输入图像像,同时让特征向量的分布更合理
VAE当中用到的技术-------残差网络(ResNet)
选用ResNet卷积神经网络作为VAE的骨干网络,因为它擅长从图像里挖深层次的特征,能更敏锐捕捉图像细节,深度神经网络训练时,容易出现“梯度消失”(学着学着,前面层的参数更新不动,模型学不到东西),和模型退化(网络变深后,反而效果越学越差)问题,ResNet搞了个残差块的结构,就是直接把输入和卷积层处理完后的输出加在一起
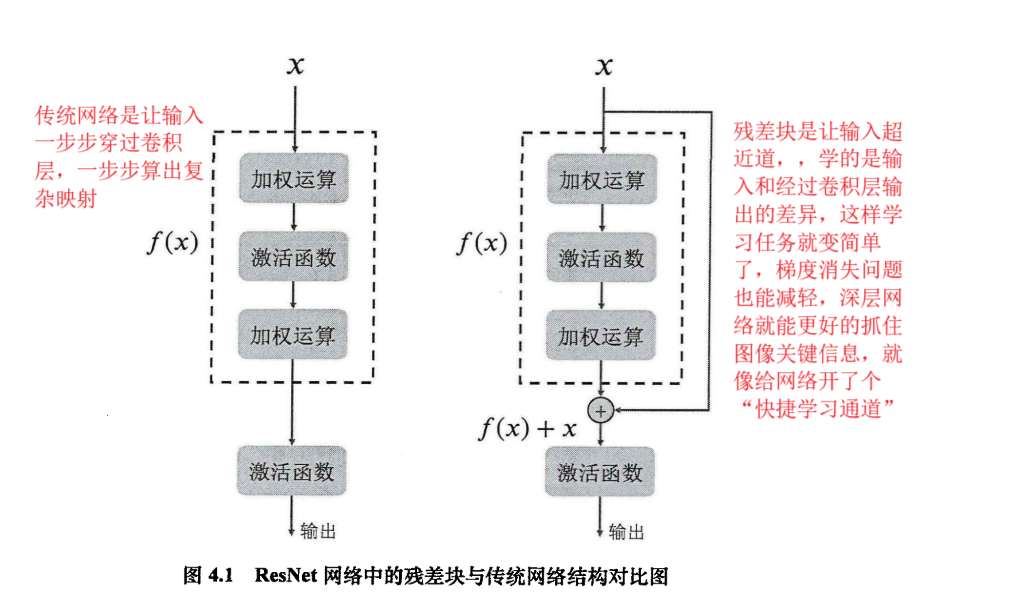
卷积注意力模块(CBAM):为了让模型更厉害,在编码器和解码器的残差块里又加了CBAM这个“注意力小助手”,能嵌入到卷积神经网络里,帮模型更专注抓重要特征
CBAM工作原理:它有两个子模块,“通道注意力模块”和“空间注意力模块”,对输入的特征图,先通过卷积层特征提取,再进行CBAM
“通道注意力”:评估不同通道特征图重要性,比如有的通道专抓图像轮廓,有的抓颜色,它通过全局最大池化和平均池化,从每个通道提取特征统计量,再用共享的MLP算权重系数,最后用Sigmoid函数把权重归0-1之间,得到通道注意力图,这样模型就知道关注哪些信息丰富、对任务有用的通道,像找人脸时,重点关注面部特征的通道
空间注意力:接着处理,强化关键区域特征,经过通道注意力调整后,再用空间注意力模块算空间权重,突出图像里的关键位置(人脸的眼睛,嘴巴区域),最后,调整特征图和原始输入特征图再“残差连接”,输出结果,让模型对图像特征捕捉更精准
整体逻辑:把VAE、ResNet、CBAM结合起来,先用ResNet提取图像特征,CBAM让模型聚焦关键特征,再用VAE把这些特征编码成“特征向量”,方便后续让机械臂理解处理。