自由职业数据科学:从细分定位到规模化的实战路线
交付在正确时间点的正确数据,是数据驱动社会中任何组织的首要需求。但坦率地说:构建一个可靠、可扩展、可维护的数据管道并不容易。它需要周密的规划、有意图的设计,以及商业认知与技术专长的结合。无论是整合多数据源、管理数据传输,还是确保报表的及时性,每个环节都有各自的挑战。
这就是为什么今天我想重点介绍什么是数据管道,并讨论构建数据管道时最关键的组成部分。
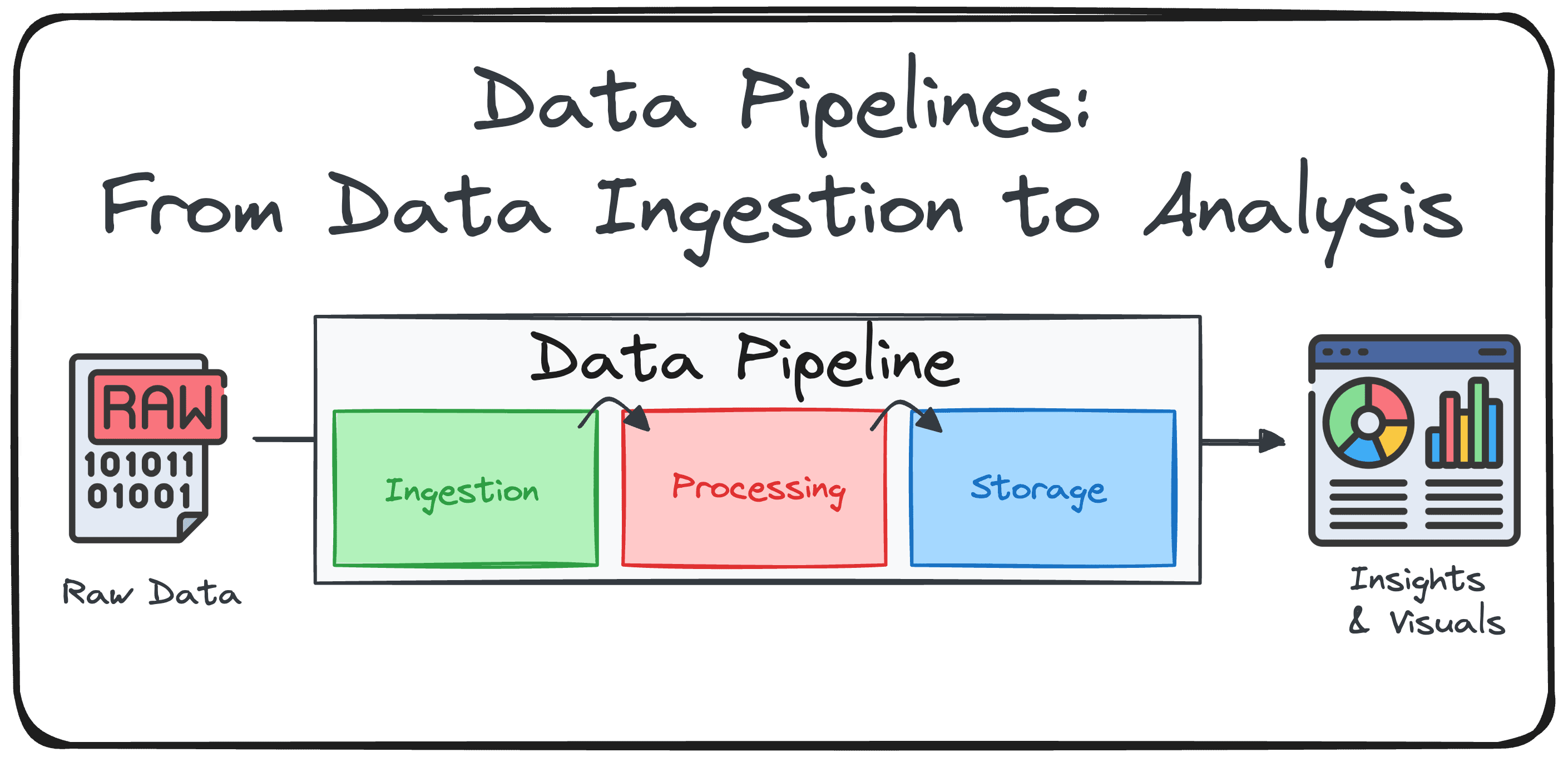
什么是数据管道?
在尝试理解如何部署数据管道之前,你必须先弄清它是什么、为什么需要它。
数据管道是一系列结构化的处理步骤,旨在将原始数据转化为可用于商业智能与决策的可分析格式。简单来说,它是一个系统:从多种来源采集数据,对其进行转换、丰富与优化,然后将其交付至一个或多个目标目的地。
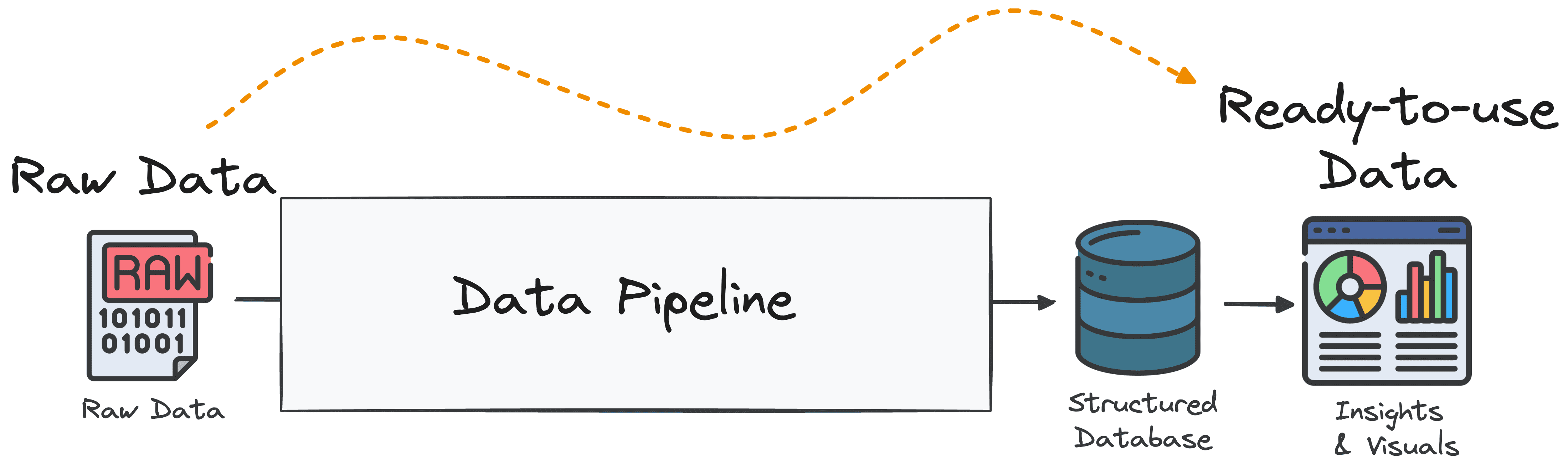
一个常见的误区是将数据管道等同于任何形式的数据移动。仅仅把原始数据从A点移动到B点(例如用于复制或备份)并不构成数据管道。
为什么要定义数据管道?
在处理数据时,定义数据管道有多重理由:
- 模块化:由可复用的阶段组成,便于维护与扩展
- 容错性:通过日志、监控与重试机制从错误中恢复
- 数据质量保障:校验数据的完整性、准确性与一致性
- 自动化:基于调度或触发运行,最大限度减少人工干预
- 安全性:通过访问控制与加密保护敏感数据
数据管道的三大核心组件
大多数管道围绕 ETL(Extract-Transform-Load,抽取-转换-加载)或 ELT(Extract-Load-Transform,抽取-加载-转换)框架构建。两者遵循相同原则:高效处理海量数据,并确保其干净、一致、可用。

下面分解每个步骤:
组件一:数据摄取(或 Extract) 管道从收集来自多种数据源的原始数据开始,如数据库、API、云存储、物联网设备、CRM、平面文件等。数据可以批量到达(按小时的报表),也可以以实时流的形式到达(实时网站流量)。其核心目标是安全可靠地连接到多样的数据源,并在“数据在途(实时)”和“数据静止(批量)”两种方式下进行采集。
两种常见方式:
- 批量:按计划周期性拉取(每天、每小时)。
- 流式:使用 Kafka 或事件驱动 API 持续摄取数据。
常用工具:
- 批量工具:Airbyte、Fivetran、Apache NiFi、自定义 Python/SQL 脚本
- API:获取服务的结构化数据(Twitter、Eurostat、TripAdvisor)
- 网页抓取:BeautifulSoup、Scrapy 或无代码爬虫工具
- 平面文件:来自官方网站或内部服务器的 CSV/Excel
组件二:数据处理与转换(或 Transform) 数据摄取后,需对原始数据进行精炼与分析准备。这包括清洗、标准化、合并数据集以及应用业务逻辑。其核心目标是确保数据质量、一致性与可用性,并让数据与分析模型或报告需求对齐。
此阶段通常包含多步:
- 清洗:处理缺失值、去重、统一格式
- 转换:应用筛选、聚合、编码或重塑逻辑
- 校验:执行完整性检查以保证正确性
- 合并:整合来自多个系统或来源的数据集
常用工具:
- dbt(data build tool)
- Apache Spark
- Python(pandas)
- 基于 SQL 的管道
组件三:数据交付(或 Load) 转换后的数据被交付至最终目的地,通常是数据仓库(结构化数据)或数据湖(半结构化或非结构化数据)。也可能直接交付到仪表盘、API 或机器学习模型。其核心目标是以支持快速查询与可扩展性的格式存储数据,并为决策提供实时或准实时访问。
常用工具:
- 云存储:Amazon S3、Google Cloud Storage
- 数据仓库:BigQuery、Snowflake、Databricks
- 面向 BI 的输出:仪表盘、报表、实时 API
构建端到端数据管道的六个步骤
构建一条优秀的数据管道通常涉及六个关键步骤。
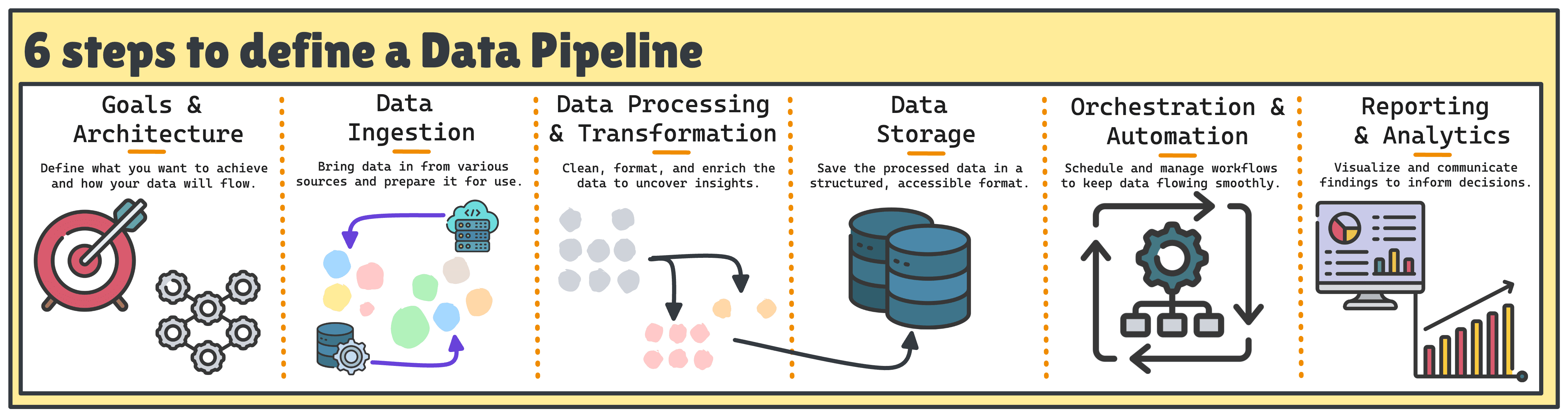
- 明确目标与架构 成功的管道始于对其目的及支撑所需架构的清晰理解。
关键问题:
- 这条管道的首要目标是什么?
- 谁是数据的最终使用者?
- 数据需要多新的时效性(实时/准实时/日级)?
- 哪些工具与数据模型最适合我们的需求?
推荐行动:
- 澄清这条管道将帮助回答的业务问题
- 绘制高层架构图,以对齐技术与业务相关方
- 相应选择工具并设计数据模型(例如为报表采用星型模型)
- 数据摄取 目标明确后,下一步是识别数据源并确定如何可靠地摄取数据。
关键问题:
- 数据源有哪些?以何种格式提供?
- 摄取应为实时、批量,还是两者兼有?
- 如何保证数据的完整性与一致性?
推荐行动:
- 与 API、数据库或第三方工具建立安全、可扩展的连接
- 使用 Airbyte、Fivetran、Kafka 或自定义连接器等摄取工具
- 在摄取阶段实施基础校验规则,尽早发现错误
- 数据处理与转换 当原始数据流入后,是时候让数据变得有用。
关键问题:
- 为了分析,需要哪些转换?
- 是否应使用外部输入对数据进行丰富?
- 如何处理重复或无效记录?
推荐行动:
- 应用筛选、聚合、标准化与数据集关联等转换
- 落地业务逻辑,确保各表的模式一致性
- 使用 dbt、Spark 或 SQL 管理并记录这些步骤
- 数据存储 接下来,选择如何、在哪里存放处理后的数据以用于分析与报表。
关键问题:
- 使用数据仓库、数据湖,还是湖仓一体(lakehouse)?
- 在成本、可扩展性与访问控制方面的要求是什么?
- 如何为高效查询来组织数据结构?
推荐行动:
- 选择与分析需求匹配的存储系统(如 BigQuery、Snowflake、S3 + Athena)
- 设计面向报表场景优化的模式
- 规划数据生命周期管理,包括归档与清理
- 编排与自动化 将所有组件串联需要工作流编排与监控。
关键问题:
- 哪些步骤相互依赖?
- 某一步失败时应发生什么?
- 将如何监控、调试与维护管道?
推荐行动:
- 使用 Airflow、Prefect 或 Dagster 等编排工具进行调度与自动化
- 设置重试策略与失败告警
- 对管道代码进行版本化,并模块化以便复用
- 报告与分析 最后,通过向相关方交付洞见来实现价值。
关键问题:
- 分析师与业务用户将使用哪些工具访问数据?
- 仪表盘应多长时间刷新一次?
- 需要哪些权限或治理策略?
推荐行动:
- 将数据仓库或数据湖连接到 Looker、Power BI 或 Tableau 等 BI 工具
- 建立语义层或视图以简化数据访问
- 监控仪表盘使用与刷新性能,确保持续价值
结论
构建完整的数据管道不仅仅是传输数据,更是赋能需要数据的人做出决策并采取行动。这个有组织的六步流程将帮助你打造既高效又具备韧性与可扩展性的管道。
管道的每个阶段——摄取、转换与交付——都至关重要。它们共同构建出支撑数据驱动决策、提升运营效率并开辟创新路径的数据基础设施。
标签:数据管道, ETL, 数据工程, 数据仓库, 数据湖, 实时流处理, 数据编排, 数据治理
摘要:系统介绍数据管道的定义、价值与三大组件,并给出端到端六步法,从摄取、转换到交付与编排,助力高效、可扩展的数据驱动决策。