(论文速读)低光照图像增强综述(一)
论文题目:(Advancing low-light image enhancement through deep learning: A comprehensive experimental study)通过深度学习推进弱光图像增强:一项综合实验研究
期刊:Knowledge-Based Systems
摘要:低光摄影严重降低了图像的感知质量,这对计算机视觉算法的性能产生了不利影响。基于深度学习的低光照图像增强(LLIE)方法在改善非最佳光照条件下拍摄的退化和损坏图像的质量方面占主导地位。设计的方法要么在有限的测试数据集上进行评估,要么没有对机器视觉应用进行评估。需要详细检查最近的发展,它们的概括,以及它们在计算机视觉任务中的应用。本实验综述通过统计分析强调了最近基于学习的LLIE方法的未来趋势,实验分析了它们在广泛的测试数据集上的泛化能力,检验了LLIE在计算机视觉应用中的有效性,并讨论了它们之间的相关性。用于这些方法通用性的测试数据涵盖了多样化的场景/内容以及真实场景中的复杂退化。采用了丰富的全参考和无参考指标来比较相对性能。此外,还验证了增强方法在弱光人脸检测中的应用,以检验这些LLIE方法作为机器视觉任务预处理步骤的有效性。后续部分从人视觉和机器视觉两个角度对实验结果的相关性进行了讨论,为该领域提供了更广阔的视野。这篇系统的综述总结了增强方法的局限性和未解决的问题。
深度学习驱动的低光照图像增强:现状、挑战与未来
在这个人人都是摄影师的时代,我们经常会遇到这样的困扰:夜晚拍摄的照片暗淡模糊,细节丢失,噪点满满。更重要的是,这些质量不佳的图像不仅影响我们的视觉体验,也会严重影响人工智能系统的性能——比如夜间的自动驾驶、安防监控中的人脸识别等。
🌙 为什么低光照图像增强如此重要?
现实应用场景的迫切需求
想象一下这些我们日常遇到的场景:
📱 智能手机摄影
- 在昏暗的餐厅想要拍摄美食,但照片总是灰蒙蒙的
- 夜景拍摄时,要么一片漆黑,要么噪点满满
- 据统计,仅2017年智能手机就拍摄了超过1.2万亿张照片,其中相当比例是在非理想光照条件下拍摄的
🚗 自动驾驶技术
- 夜间行驶时,车载摄像头需要准确识别行人、车辆和交通标志
- 隧道、地下车库等低光环境下的物体检测
- 研究表明,传统计算机视觉算法在低光条件下性能会显著下降
🛡️ 安防监控系统
- 夜间或光线不足环境下的人脸识别
- 异常行为检测和入侵检测
- 野生动物监控中的防偷猎应用
🏥 医疗成像
- 低剂量X射线成像,既要保护患者又要保证诊断质量
- 内窥镜检查中的暗部组织成像
低光照图像的典型问题

论文中详细分析了低光照图像的几种典型退化现象:
- 可见度降低:整体图像偏暗,细节难以辨认
- 严重噪声:ISO高时产生的颗粒感和彩色噪点
- 模糊不清:为了获得足够曝光时间导致的运动模糊
- 色彩失真:在不同光源下出现偏色问题
- 对比度降低:缺乏层次感,显得平淡
- 纹理细节丢失:精细结构被噪声掩盖
🧠 深度学习的四大解决方案
传统方法如直方图均衡化、伽马校正等往往效果有限,容易产生不自然的结果。深度学习为这个问题带来了革命性的解决方案。

1. 监督学习方法:有"老师"指导的学习 📚
工作原理:就像学生有标准答案一样,这类方法需要大量的低光照图像和对应的正常光照图像作为训练对照。
代表性方法详解:
🌟 Retinexformer (2023)
- 创新点:首次将Transformer架构应用到Retinex理论中
- 核心思想:将图像分解为反射分量和光照分量,分别进行优化
- 实验表现:在NIQE指标上排名第一,平均得分3.673
- 适用场景:需要保持色彩自然度的专业摄影应用
🌟 DLL (Deep Learning-based Low-light enhancement)
- 技术特点:基于小波变换的扩散模型
- 突出优势:在PSNR指标上表现最佳,达到25.67 dB
- 计算成本:参数量24.549M,处理600×400图像需要0.22秒
- 应用限制:计算复杂度较高,不适合实时应用
🌟 LLFormer (Ultra-high-definition Low-light Transformer)
- 独特优势:专门针对超高分辨率图像设计
- 技术难点:解决了传统方法无法处理4K+图像的问题
- 性能表现:SSIM得分0.756,在结构保持方面表现优异
训练数据集挑战:
- LOLv1数据集:仅500对图像,分辨率600×400
- LOLv2数据集:789张真实图像 + 1000张合成图像
- SID数据集:424张RAW格式的极暗图像
2. 无监督学习方法:自主探索的学习 🎯
工作原理:不需要配对的"标准答案",通过设计巧妙的损失函数让网络自己学会增强规律。
代表性方法详解:
🌟 EnlightenGAN (2021)
- 开创意义:首个基于GAN的无监督低光照增强方法
- 技术创新:双判别器设计(全局+局部)+ 自正则化感知损失
- 实际问题:在某些情况下会出现严重的颜色偏差和视觉伪影
- 改进方向:后续的LE-GAN通过循环架构解决了部分问题
🌟 Zero-DCE系列
- Zero-DCE (2020):
- 核心思想:估计高阶曲线参数进行像素级调整
- 网络轻量:仅0.079M参数
- 主要问题:噪声处理能力不足
- Zero-DCE++ (2021):
- 改进:提升了曲线估计的准确性
- 实际表现:在人脸检测任务中提升最显著
- 运行效率:处理600×400图像仅需0.00173秒
🌟 SCI (Self-Calibrated Illumination)
- 设计理念:级联模块设计,权重共享
- 计算优势:参数量仅0.0003M,FLOPs只有0.0619G
- 实时性能:处理600×400图像仅需0.00073秒
- 应用价值:非常适合移动设备和边缘计算
3. 半监督学习方法:平衡的艺术 ⚖️
典型案例:DRBN (Deep Recursive Band Network)
- 两阶段设计:
- 第一阶段:使用少量配对数据学习信号保真度先验
- 第二阶段:使用大量无标签高质量数据学习感知质量先验
- 实际效果:在保证技术指标的同时提升视觉感知质量
4. 零样本学习方法:因材施教的智能 🎪
工作原理:每张图像都是独特的,算法为每张图像量身定制优化策略。
代表方法:RetinexDIP
- 技术基础:深度图像先验 + Retinex分解
- 优化过程:需要约300次迭代才能收敛
- 时间成本:处理单张图像需要13-15秒
- 效果权衡:质量不错但实时性差
📊 史上最全面的实验对比:30+方法大比拼
这篇综述进行了迄今为止最全面的实验评估,让我们看看具体的比较结果:
实验设置
测试数据集的多样性:
- DICM:69张高对比度图像,测试算法对明暗区域的处理能力
- MEF:17张多曝光融合图像,考验算法的动态范围处理
- BDD100K:自动驾驶场景,包含眩光和复杂光照
- DARK FACE:100张极暗人脸图像,专门测试人脸检测效果
- LOLv1/v2:经典的配对测试集
评估指标的含义:
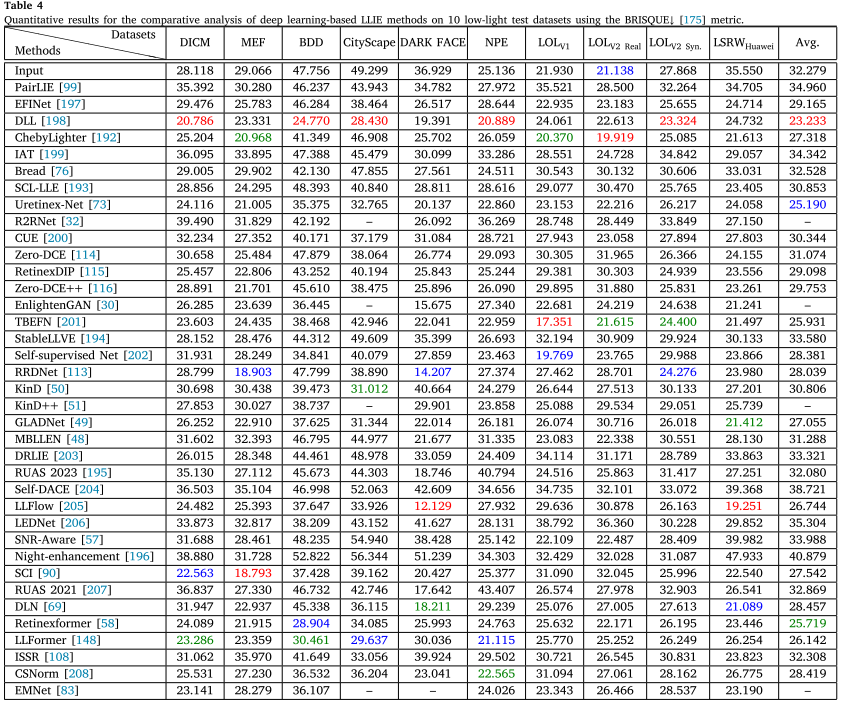
- NIQE:越低越好,衡量图像的自然度
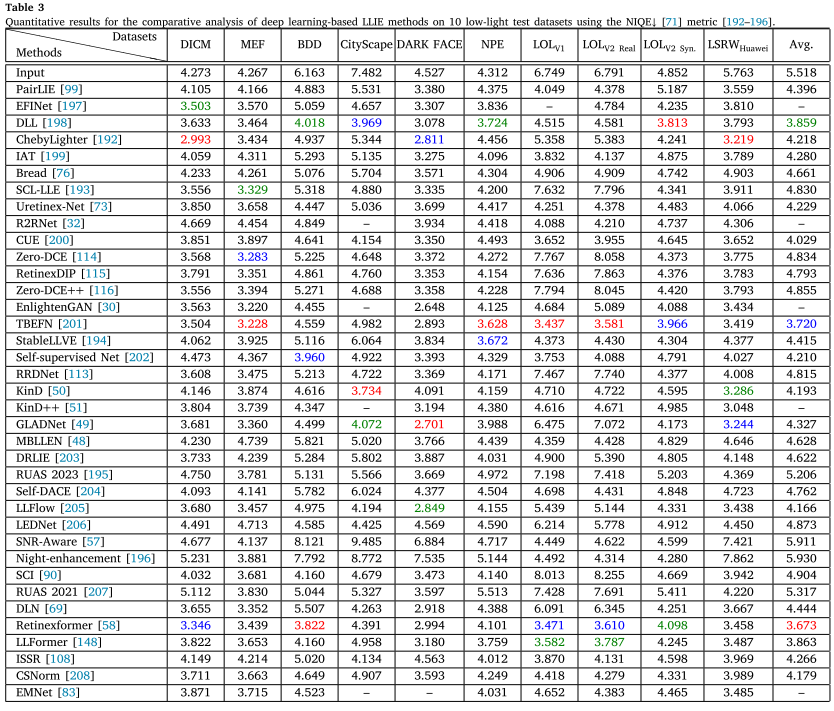
- BRISQUE:越低越好,评估图像失真程度
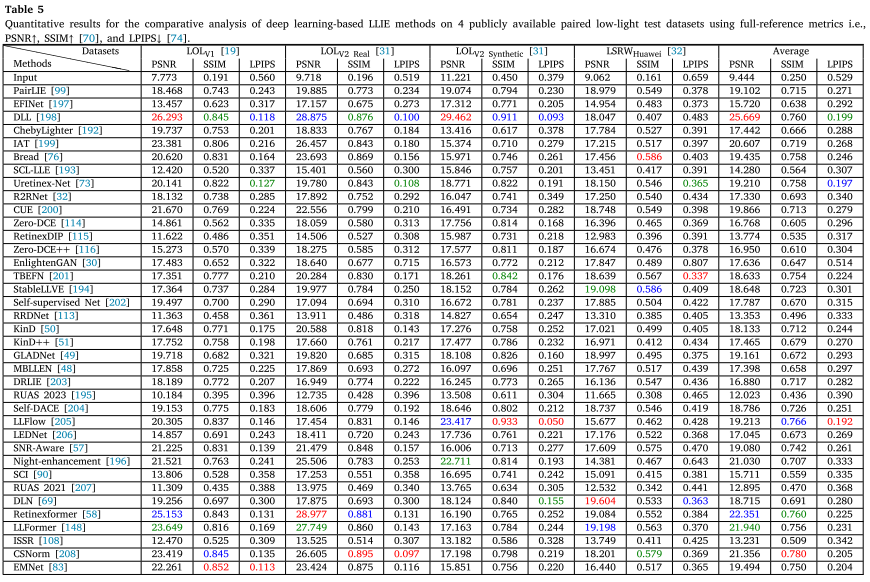
- PSNR:越高越好,衡量重建质量
- SSIM:越高越好,评估结构相似度
令人意外的实验结果
1. 没有绝对的王者 🏆
以NIQE指标为例的排名变化:
- 第1名:Retinexformer (3.673) - 在自然度方面最佳
- 第2名:TBEFN (3.720) - 双分支曝光融合网络
- 第3名:DLL (3.859) - 扩散模型方法
但在BRISQUE指标上:
- 第1名:DLL (23.233) - 在失真控制方面最佳
- 第2名:Uretinex-Net (25.190) - 基于深度展开的方法
- 第3名:Retinexformer (25.719) - 排名掉到第三
2. 监督学习的明显优势
在Top 10方法中:
- LPIPS和SSIM指标:前10名全部是监督学习方法
- PSNR指标:前10名中9个是监督学习方法,1个无监督方法
- 无监督方法最佳表现:RetinexDIP的SSIM为0.535,而最佳监督方法CSNorm达到0.780
3. 计算效率的巨大差异 ⚡
最轻量级方法:
- SCI:0.0003M参数,0.0619G FLOPs,0.00073秒
- Zero-DCE++:0.010M参数,2.418G FLOPs,0.00173秒
最重量级方法:
- KinD++:8.275M参数,2532G FLOPs,0.31秒
- RRDNet:0.128M参数,但需要59秒(迭代优化)
- RetinexDIP:0.707M参数,需要13秒(300次迭代)
视觉效果的具体分析

LOLv1测试集表现:
- 最佳方法:LLFlow、CSNorm、EMNet、CUE、LLformer
- 问题方法:
- MBLLEN:过度平滑,丢失纹理细节
- Self-supervised Net:颜色恢复不正确
- KinD++:结果看起来不自然
DARK FACE测试集表现:
- 成功案例:Bread、Uretinex-Net、PairLIE不仅增强暗部还保持纹理细节
- 失败案例:
- R2RNet和ChebyLighter:自然度不足
- DLL:引入黄色偏差
- EMNet:光源周围过度增强
BDD测试集的极端挑战:
- 普遍困难:几乎所有方法都无法很好处理这个数据集
- 常见问题:低动态范围、噪声、色彩不准确、伪影、眩光过度增强
- 相对较好:ISSR方法产生了相对更好的结果
🎯 计算机视觉应用的实际验证
人脸检测实验设计
实验设置:
- 数据集:DARK FACE的500张随机选择图像
- 检测器:Retinaface和EResFD两种预训练模型
- 评估指标:mAP(平均精度均值)和Precision(精确率)
令人振奋的应用结果
显著提升的方法:
使用Retinaface检测器:
- 输入图像:mAP仅13.23%,Precision为0.839
- Zero-DCE++:mAP提升到25.40%(+12.17%),Precision为0.881
- Zero-DCE:mAP达到25.28%(+12.05%),Precision为0.895
- GLADNet:mAP为25.39%(+12.16%),Precision为0.907
使用EResFD检测器:
- 输入图像:mAP仅11.75%,Precision为0.625
- Zero-DCE++:mAP提升到26.29%(+14.54%),Precision为0.683
- DLN:mAP达到26.14%(+14.39%),Precision为0.678
- IAT:mAP为25.25%(+13.50%),Precision为0.681
有趣的发现
1. 视觉效果≠检测性能
- MBLLEN:视觉效果相对不错,但过度平滑影响了检测性能
- ISSR:图像看起来较暗,导致检测性能下降
2. 不同检测器的偏好不同
- 某些增强方法对特定检测器更友好
- 这提示我们需要针对具体应用场景选择合适的增强方法
🤔 人类感知 vs 机器视觉:意外的发现
相关性分析
研究通过散点图分析了人类感知指标与机器视觉性能的相关性:
强相关性:
- NIQE vs mAP:显示出较强的相关性
- 说明自然度指标与检测性能有一定关联
弱相关性:
- Information Entropy vs mAP:相关性很弱
- 说明简单的统计指标难以预测实际应用效果
实际启示
这个发现告诉我们:
- 不能仅凭人类视觉评判算法好坏
- 需要针对具体应用设计评估标准
- 多指标综合评估的必要性
🚧 当前面临的核心挑战
1. 技术层面的挑战
泛化能力问题:
- LOLv1训练的模型:在其他数据集上性能下降明显
- 合成数据的局限:与真实低光环境存在domain gap
- 场景特化:室内效果好但户外效果差,或相反
极端条件下的失效:
- 强光源处理:如路灯、车灯造成的眩光
- 极暗环境:信息严重缺失的情况
- 混合光源:不同色温光源并存的复杂情况
计算复杂度与效果的权衡:
- 实时性要求:移动端、车载系统需要毫秒级响应
- 质量要求:专业摄影需要最佳效果,可以接受较长处理时间
- 内存限制:大多数方法无法处理4K+分辨率图像
2. 数据层面的挑战
配对数据获取困难:
- 技术难度:同一场景的低光/正常光图像很难同时获得
- 成本问题:需要专业设备和大量人工
- 动态场景:移动物体使得配对变得不可能
现有数据集的局限性:
- 分辨率低:LOLv1/v2仅600×400,远低于现代相机标准
- 场景单一:主要是静态室内场景,缺乏复杂户外环境
- 数量有限:总计不到2000对图像,相比ImageNet的14M图像差距巨大
3. 评估标准的混乱
指标间的矛盾: 以Retinexformer为例:
- NIQE排名:第1位
- BRISQUE排名:第3位
- NIQMC排名:第9位
- Information Entropy排名:第14位
人类感知vs客观指标:
- 有些方法客观指标很好,但人眼看起来不自然
- 有些方法视觉效果不错,但对下游任务帮助有限
🔮 未来发展的五大方向
1. 更智能的算法架构
自适应增强策略:
- 场景感知:根据图像内容(室内/户外、静态/动态)自动选择增强策略
- 区域分别处理:对图像的不同区域应用不同的增强强度
- 多尺度融合:结合全局调整和局部优化
多任务协同优化:
- 联合训练:同时优化增强效果和下游任务性能
- 端到端系统:增强+检测一体化训练
- 自监督学习:减少对标注数据的依赖
2. 突破性的技术方向
基于物理模型的深度学习:
- 光照建模:更精确的光传播和反射模型
- 噪声建模:基于相机传感器特性的噪声模拟
- 色彩科学:结合人眼视觉机制的色彩恢复
扩散模型的应用:
- Diff-Retinex:已展示出生成高质量图像的潜力
- 可控生成:用户可指定增强程度和风格
- 细节重建:能够"想象"并恢复缺失的细节
Vision-Language模型:
- DA-CLIP:结合文本描述指导图像增强
- 语义理解:基于图像内容智能调整增强策略
3. 计算效率的革命性提升
模型压缩技术:
- 知识蒸馏:大模型指导小模型学习
- 网络剪枝:去除冗余参数和连接
- 量化加速:INT8/INT4精度推理
硬件协同设计:
- 神经网络处理器:专用的AI芯片
- 边缘计算:在设备端直接处理
- 流水线优化:预处理、增强、后处理的并行执行
算法创新:
- 渐进式处理:先快速预览,再精细优化
- 注意力机制:只对关键区域进行复杂处理
- 分层处理:不同层次采用不同复杂度的算法
4. 全新的评估体系
面向应用的评估:
- 任务特定指标:针对人脸识别、目标检测等设计专门指标
- 用户体验评估:结合心理学和认知科学的主观评估
- 时间效率评估:处理速度、能耗等实用性指标
大规模数据驱动评估:
- 众包评估:利用大众力量进行主观质量评估
- A/B测试:在真实应用中比较不同方法的效果
- 长期跟踪:评估算法在不同时间、场景下的稳定性
5. 数据生态的重构
高质量数据集建设:
- 高分辨率:4K、8K分辨率的配对数据
- 多样化场景:涵盖各种真实应用场景
- 动态数据:视频序列的低光照增强
合成数据技术:
- 物理渲染:基于真实光照物理的图像合成
- 域适应:缩小合成数据与真实数据的差距
- 数据增广:通过变换生成更多样的训练数据
开放数据平台:
- 标准化格式:统一的数据格式和评估协议
- 版本控制:数据集的版本管理和更新机制
- 社区贡献:鼓励研究者贡献数据和算法
🎯 实际应用的选择指南
基于论文的实验结果,这里给出针对不同应用场景的具体建议:
移动摄影应用 📱
推荐方法:
- 首选:SCI - 0.00073秒处理时间,效果不错
- 备选:Zero-DCE++ - 0.00173秒,视觉效果更佳
- 避免:DLL、RRDNet - 处理时间过长
选择理由:移动设备对实时性要求极高,用户无法接受数秒的等待时间。
安防监控系统 🛡️
推荐方法:
- 首选:Zero-DCE系列 - 在人脸检测任务中表现最佳
- 备选:GLADNet - 检测性能和视觉效果平衡好
- 考虑:TBEFN - 专门针对增强和检测设计
选择理由:安防应用更关心识别准确率而非视觉美观度。
自动驾驶系统 🚗
推荐方法:
- 首选:Retinexformer - 综合性能优秀,自然度高
- 备选:LLFormer - 能处理高分辨率图像
- 避免:计算复杂度过高的方法
选择理由:需要在保证安全的前提下平衡处理速度和效果。
专业摄影后期 📸
推荐方法:
- 首选:DLL - PSNR最高,重建质量最佳
- 备选:LLFlow - LPIPS表现优秀,感知质量好
- 考虑:Retinexformer - 色彩自然度最佳
选择理由:专业应用可以接受较长处理时间,追求最佳效果。
医疗成像应用 🏥
推荐方法:
- 首选:Uretinex-Net - 基于展开网络,可解释性较强
- 备选:TBEFN - 双分支设计,细节保持好
- 避免:生成式方法 - 可能产生虚假细节
选择理由:医疗应用对准确性和可靠性要求极高,不能有虚假信息。
🌟 技术发展的时间线展望
短期目标(1-2年)
- 效率优化:现有算法的轻量化改进
- 评估标准化:建立统一的评估基准
- 数据集扩充:更多高质量配对数据
中期目标(3-5年)
- 算法突破:自适应增强、多任务学习的成熟应用
- 硬件协同:专用芯片的普及应用
- 应用落地:在主流消费电子产品中的广泛部署
长期愿景(5-10年)
- 通用智能:能够处理任意光照条件的通用增强系统
- 实时4K+:高分辨率视频的实时增强
- 无缝集成:增强功能成为成像系统的标准组件
🔬 给研究者的建议
对算法研究者
- 关注实用性:不只追求paper指标,更要考虑实际应用价值
- 注重效率:在保证效果的同时优化计算复杂度
- 多元评估:使用多种指标和多个数据集进行全面评估
- 开源共享:推动社区发展,避免重复造轮子
对工程开发者
- 场景定制:根据具体应用场景选择合适的算法
- 性能优化:利用模型压缩、硬件加速等技术提升效率
- 用户体验:关注处理时间、功耗等用户实际感受
- 持续集成:建立算法性能的持续监控和更新机制
对产品经理
- 需求分析:明确产品的核心需求(效果vs效率)
- 技术跟踪:持续关注领域最新进展
- 用户反馈:收集真实用户的使用体验和改进建议
- 竞品分析:了解市场上其他产品的技术方案
🌈 结语:技术改变生活的美好愿景
低光照图像增强技术正处在一个激动人心的发展阶段。从最初简单的直方图均衡化,到现在复杂的深度学习网络,再到未来可能的通用智能增强系统,这项技术正在以前所未有的速度改变着我们的生活。