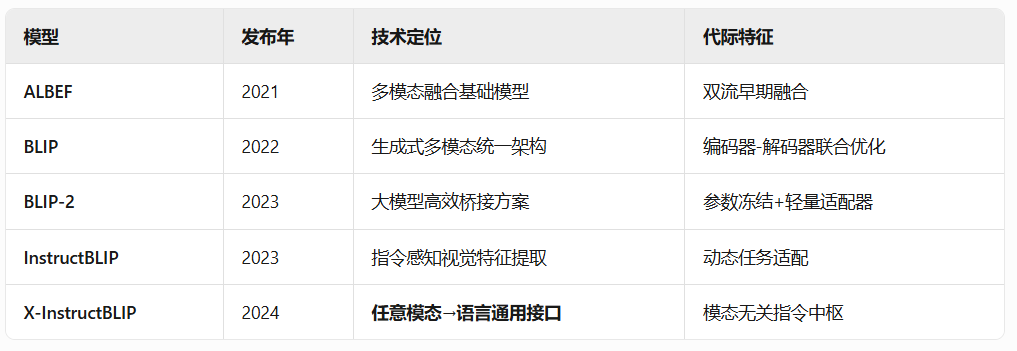
ALBEF/BLIP/BLIP2/Instruct BLIP/X Instruct BLIP
ALBEF
研究动机
ALBEF之前的一些方式, 视觉分支基本都是基于 dector的方式(检出目标框),如下图所示,由于大量的数据没有标框,因此视觉预训练的受限于dector的检测方式。
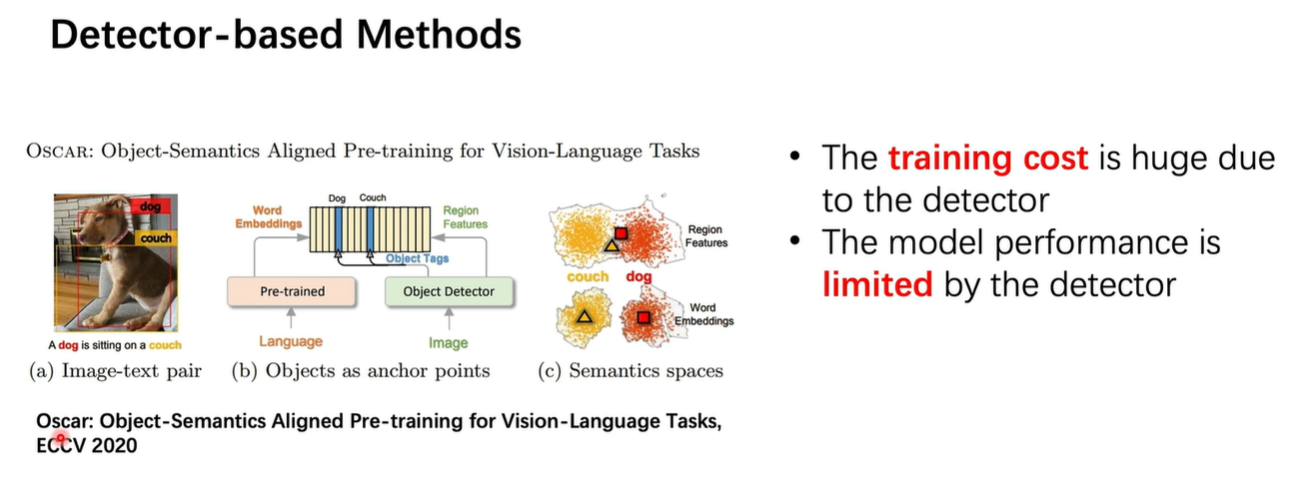
创新点
能不能不再采用dector的方式训练视觉分支模型,ALBEF采用了一种新的方式,能够在信息融合之前就对齐图文的特征,即Align Before Fuse
网络结构
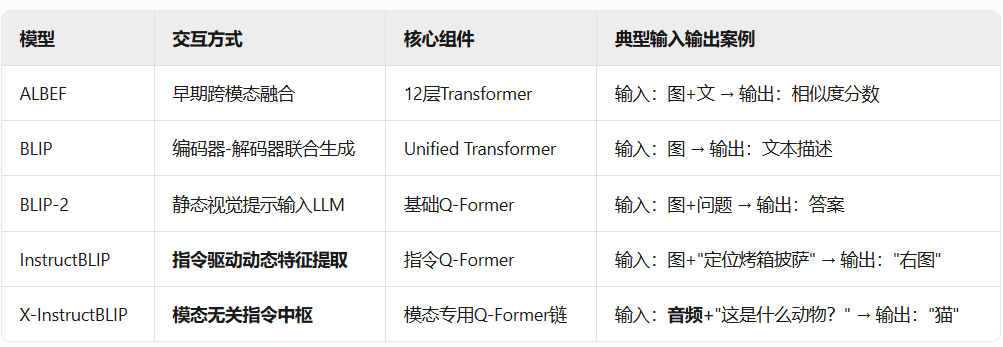
- image encoder : ViT
- text encoder: BERT
- multimodal encoder : 通过 CrossAttention进行模态之间的融合
- Momentum Encoder : 输出软分布,有助于过滤图文不太匹配的噪声数据 .(不理解的可以看下何凯明的MoCo系列)
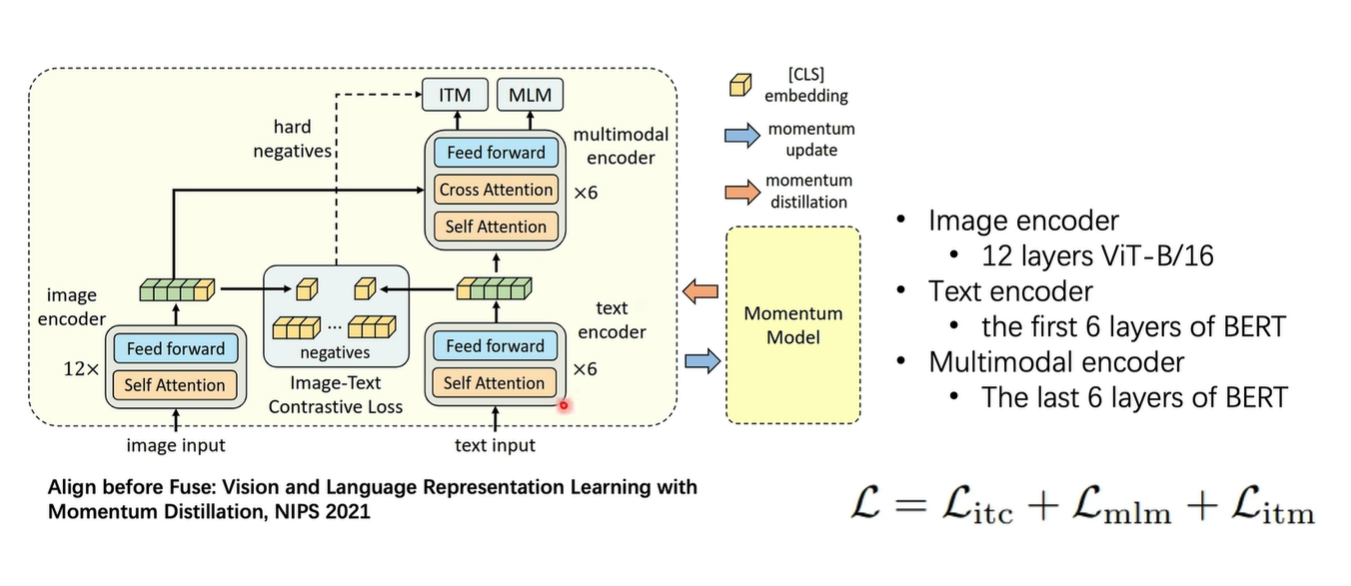
损失函数
通过设计ITC(Image-Text Contrastive) Loss,强制在融合之前对齐特征。 通过设计两个下游任务,图文匹配(Image Text Match,ITM)和 完形填空(Masked Language Modeling, MLM)进行多模态模型的融合。
关键设计:在融合前加入图像-文本对比损失(ITC),强制单模态编码器生成的表示在语义空间对齐(类似CLIP)
BLIP
研究动机
- 对于只有encoder结构的模型,无法做生成(因为没有生成任务)
- 对于 encoder-decoder结构的模型,可以做生成但是不能做检索这种理解式的任务。
- 网络上的图文对包含很多噪声,可能并不是真正的匹配图文对。
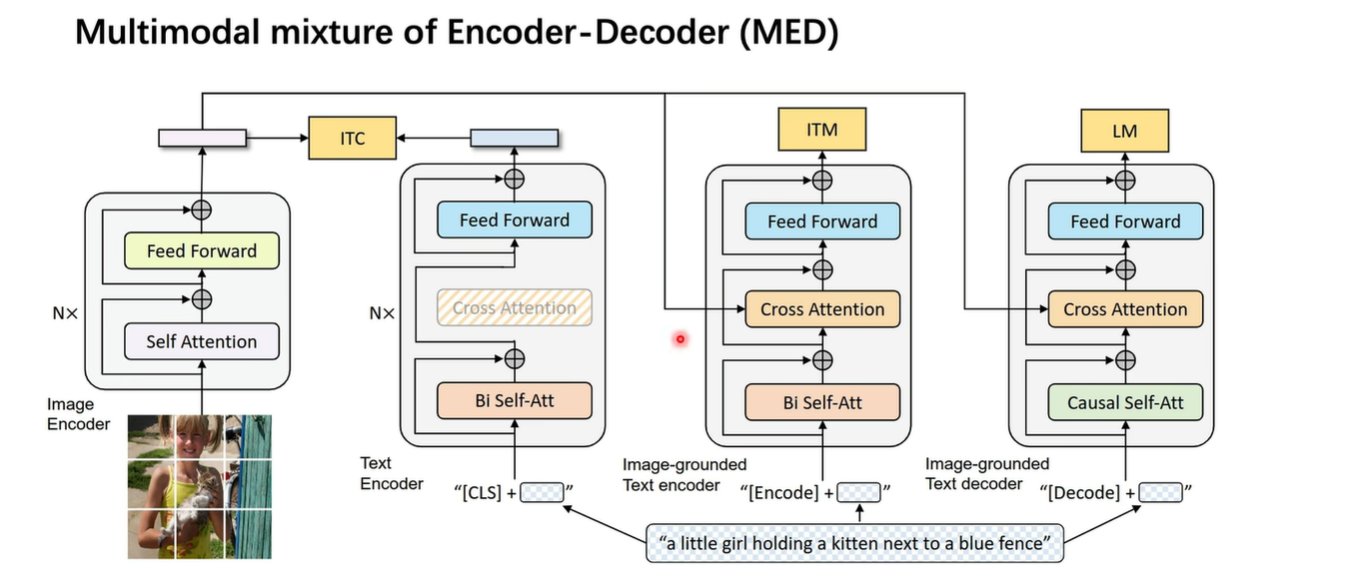
网络结构
如图所示,相对于 ALBEF结构,增加了一个decoder的模块,并且把完形填空任务换成了句子生成的任务(Language Model,LM), 并且把Cross Attention换成了Causal Attention,即从Bert形式换成了GPT的形式, 这样就可以进行生成了。 所以现在整个网络结构既有理解又有生成任务,做到了理解和生成的架构统一。
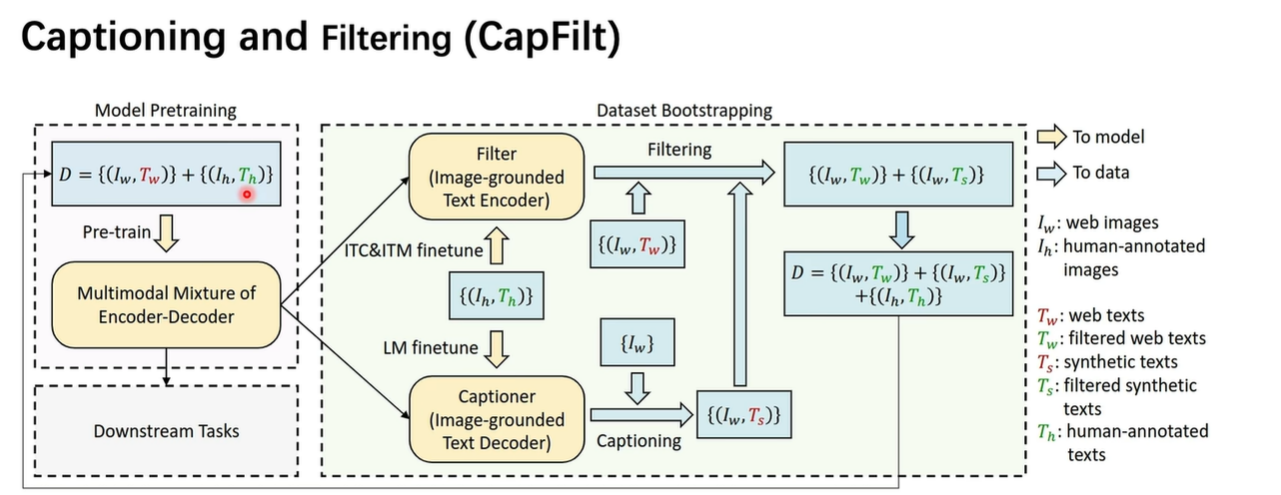
数据策略
BLIP2
研究动机
当前的大模型都是基于 大量数据和大模型参数量下进行训练的, 训练的很慢,能不能改善一下提高训练效率呢?
如果把 image encoder 和 text encoder都冻住不进行更新的话,这俩时间的gap可能会比较大,BLIP2在这两者之间加了一个 小的transformer的结构,即Q-Former,达到了四两拨千斤的效果。
网络结构
如图所示, 这两个框分别表示理解任务和生成任务
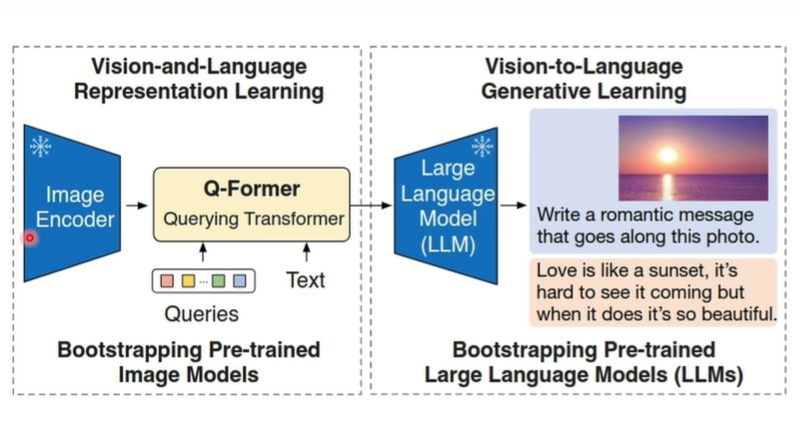
第一阶段:Representation Learning
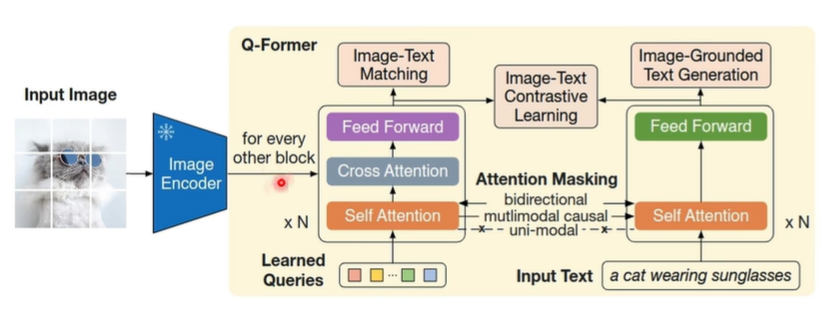
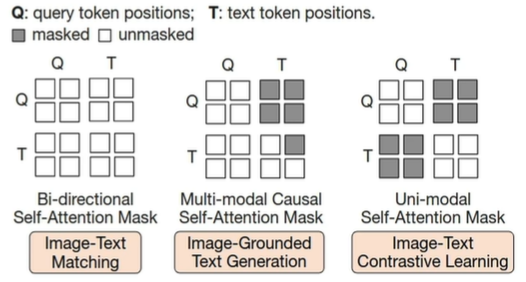
扮演了理解任务,即表征学习阶段, 通过一个 可学习Query和txt作为输入,通过设计 ITC,ITM ,ITGT(基于图像的文本生成)任务,把视觉特征和语言特征对齐,得到学习好的Query (学好后包含了对齐到语言空间的视觉信息)
第二阶段:Generation Learning
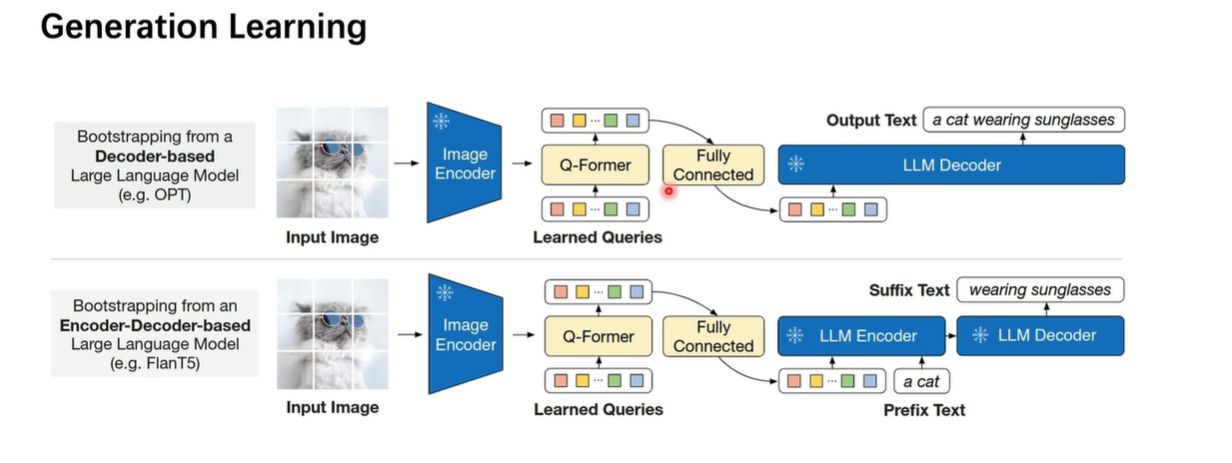
把学习好的Query输入到 Decoder中,做生成任务。
Instruct BLIP
参考链接:
https://www.bilibili.com/video/BV15vsueME7J?spm_id_from=333.788.videopod.sections&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245
研究动机
核心问题:传统视觉-语言模型(如BLIP-2)在响应复杂指令时表现局限
(例如:“which picture shows the pizza inside the oven?” 需同时理解空间关系与对象状态)
关键痛点:
视觉特征与语言指令语义割裂:冻结的Image Encoder无法感知任务需求
静态提示输入:LLM接收的视觉特征与当前指令无关
网络结构
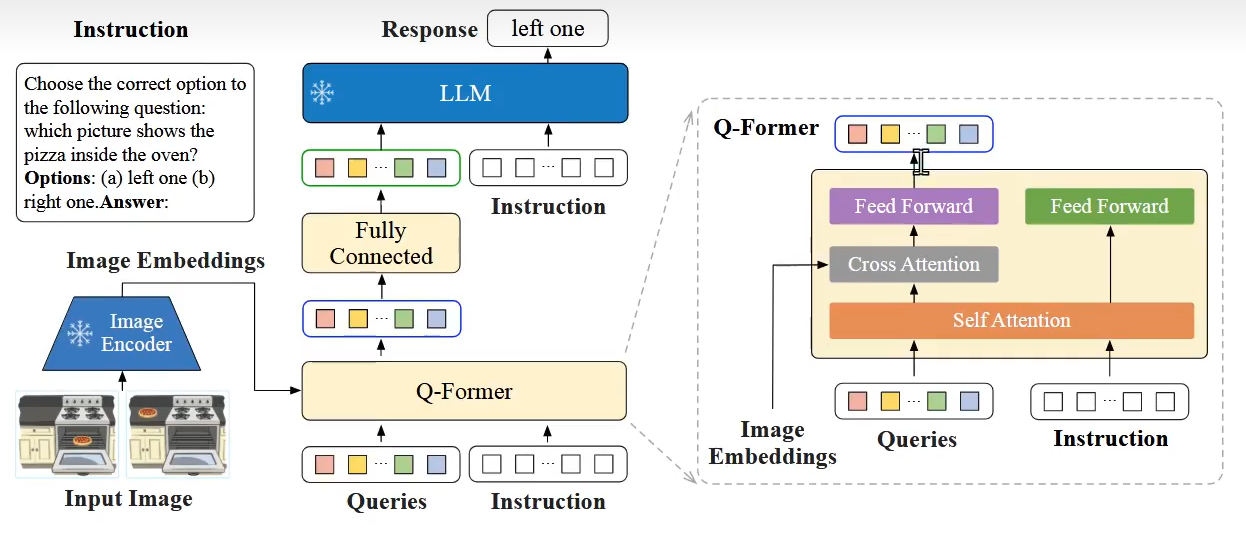
视觉特征提取
图像输入预训练且冻结的ViT(例如CLIP-ViT),输出特征向量
基于指令的Q-Former(创新核心)
任务指令(如披萨定位问题)与视觉特征共同输入Q-Former
通过三层交互:
▪ Self-Attention:融合指令语义(理解"inside"的空间关系)
▪ Cross-Attention:筛选与指令相关的视觉特征(聚焦烤箱区域)
▪ Feed Forward:强化任务适配特征表示
LLM交互机制
Q-Former输出的32个动态Token(即软提示)经线性投影后
与指令文本拼接成完整输入:
[任务指令] + [指令感知视觉特征] → LLM
响应生成
冻结的LLM(如FlanT5、Vicuna)基于融合输入生成自然语言响应
(示例输出:“left one” 指向左图中的烤箱披萨)
架构图实例解析(图中披萨定位示例)
当输入指令:
“which picture shows the pizza inside the oven?”
Q-Former的运作流程:
解析指令关键词 → inside(空间关系), oven(目标容器)
通过Cross-Attention聚焦图像中的烤箱内部区域
输出对比特征:左图(披萨在烤箱内) vs 右图(披萨在台面上)
LLM基于特征对比生成响应 → left one
对比BLIP2
# BLIP-2的静态输入:
visual_prompt = [固定向量] # 与"oven inside"无关# InstructBLIP的动态生成:
if 指令 == "which shows pizza inside oven?":visual_prompt = focus(烤箱区域, 披萨位置) # 输出32个位置敏感Token
BLIP-2典型问题(对比图中披萨定位任务)
问题:“which picture shows the pizza inside the oven?”
可能响应:“left: pizza on counter, right: pizza in oven”(需用户自行判断位置)
InstructBLIP优化响应
指令感知处理: Q-Former过滤"inside oven"相关特征
动态Token突出左图错误/右图正确区域
LLM直接生成:*"right one"*
总结:InstructBLIP的核心突破
将指令语义深度融入视觉特征提取阶段,通过动态软提示实现: “让模型学会根据问题主动寻找视觉证据”
而BLIP-2仅是简单拼接静态图像特征与问题文本。
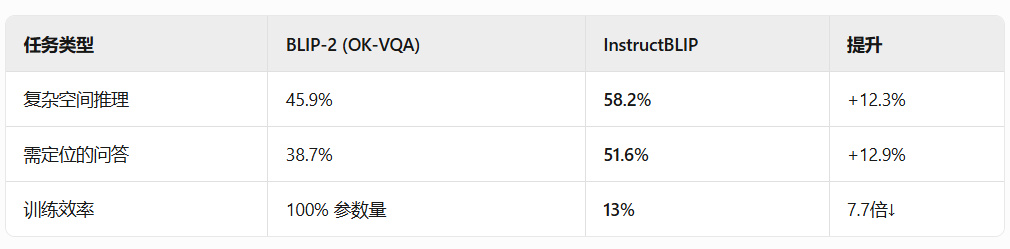
指标对比
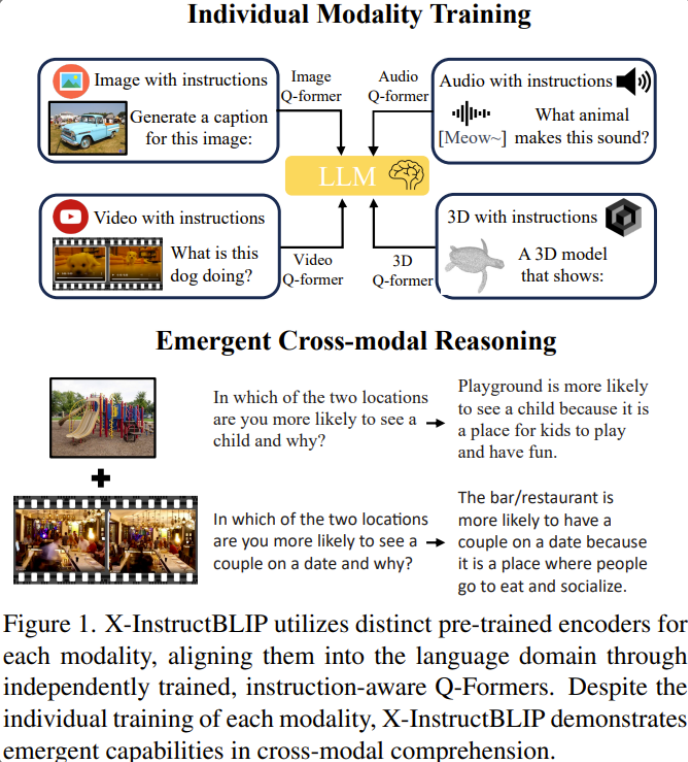
X InstructBLIP
核心动机
解决多模态割裂问题:传统多模态模型需对不同模态数据联合训练(如CLIP),计算成本高且模态扩展性差。
打破模态壁垒:实现图像、音频、视频、3D等异构模态的统一理解和推理,仅通过单模态独立训练即可涌现跨模态能力
网络结构
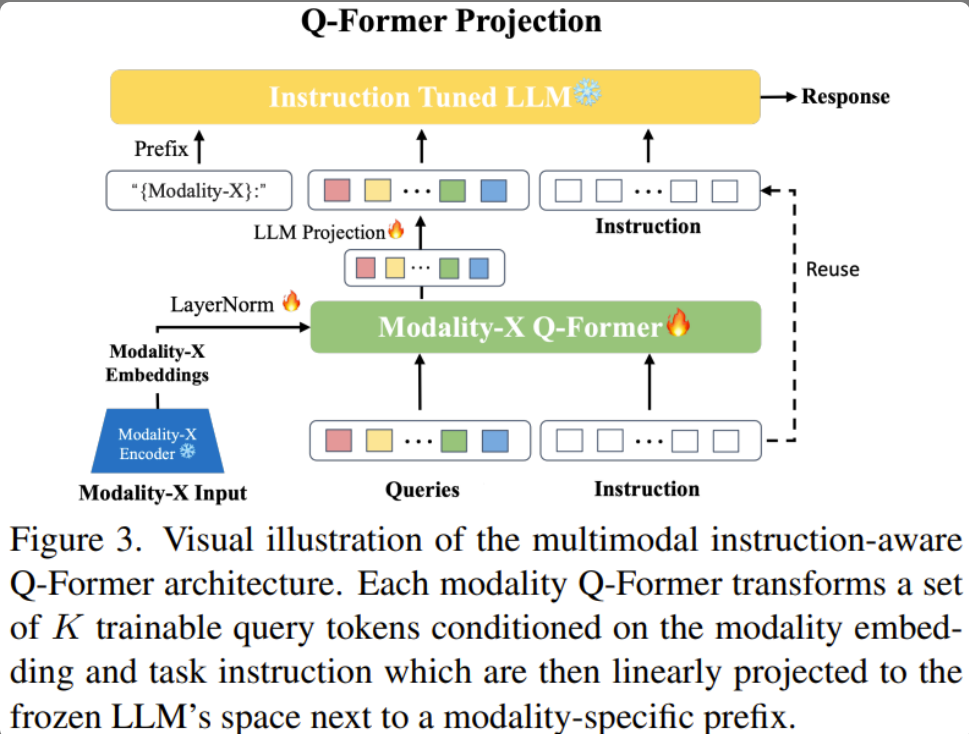
五种网络对比

参考
-
https://www.bilibili.com/video/BV1uT411q7ef/?spm_id_from=333.337.search-card.all.click&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245
-
https://www.bilibili.com/video/BV15vsueME7J?spm_id_from=333.788.videopod.sections&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245