从 “视频孪生” 到 “视频动态目标三维重构”:技术演进与核心突破
黎阳之 光的技术从数字孪生开发,到视频孪生的开发与应用,走了很长一段时间,视频孪生技术通过将物理场景的实时视频流与数字孪生模型绑定,实现了物理世界与数字空间的 “实时映射”,但其核心仍依赖于二维视频的平面化呈现,难以突破 “看得到” 却 “测不准” 的局限 —— 即无法精准获取目标的三维坐标、运动轨迹、空间关系等深层信息。黎阳之光目前研发的最新技术--视频动态目标实时三维重构则是在此基础上的进阶:它不再满足于 “数字复刻”,而是聚焦于从视频中 “解析空间”,通过技术手段将动态目标(人、车等)的二维影像转化为三维空间中的精确坐标与形态,最终打通 “三维坐标感知 — 空间关系分析 — 场景智能决策” 的完整通路。
核心逻辑:将每一帧视频转化为空间控制点
“空间控制点” 是三维重构的核心载体 —— 它指从视频帧中提取的、能唯一对应物理空间位置的特征点(如目标的边缘、角点、纹理等)。通过对这些控制点的时空关联与坐标计算,可实现三大突破:
突破二维平面限制,实现纵深感知
传统视频仅能提供 “长度 × 宽度” 的平面信息,而空间控制点通过多帧 / 多视角的视差计算,可推导 “深度” 维度(即目标与摄像头的距离、目标自身的高度 / 厚度)。例如,从单摄像头视频中,通过人车的运动轨迹变化与尺度一致性,可反推其在三维空间中的 “纵深位置”;多摄像头协同时,不同视角的控制点匹配能直接计算目标的三维坐标(如 “某辆车在 t 时刻位于 X=10m,Y=5m,Z=0.5m 处”)。

构建全局坐标系统,支撑坐标推演
即使摄像头安装时未记录高度、角度、内外参数(焦距、畸变等),技术可通过 “自标定” 从视频序列中反推摄像头参数,并基于空间控制点的关联,将分散的摄像头视角统一到 “世界坐标系” 中。例如,街角多个无标定的摄像头,通过共同拍摄的行人轨迹,可自动计算各摄像头的相对位置,进而将每个摄像头的视频控制点映射到同一全局坐标,实现 “跨摄像头目标追踪” 与 “全域坐标推演”(如 “行人从摄像头 A 的视野进入摄像头 B 的视野,其三维轨迹连续无断裂”)。动态目标的实时三维还原
对于运动中的人、车,通过连续帧的控制点追踪,可还原其 “形态 + 运动” 的三维特征:- 形态还原:如车辆的长度、宽度、高度,行人的身高、肢体姿态;
- 运动还原:如车辆的三维速度(不仅是平面移动,还包括上下坡的垂直速度)、行人的步幅与转向角度。
关键技术路径:从 “视频输入” 到 “决策输出” 的全链路
要实现 “三维坐标 — 场景决策” 的打通,需串联四大技术模块:
1. 动态目标精准检测与特征提取
从视频帧中分离出 “动态目标”(人、车等)与 “静态背景”,并提取目标的稳定特征点(作为空间控制点)。
- 技术手段:结合深度学习(如 YOLO、Transformer)实现复杂场景下的目标检测(抗遮挡、抗光照变化);通过 SIFT、ORB 等传统特征算法或 CNN 特征提取器,获取目标表面的 “不变特征点”(即使目标运动或视角变化,特征仍可匹配)。
2. 多源视频的三维坐标推演
基于单摄像头视频序列或多摄像头同步视频,计算目标的三维坐标:
- 单摄像头:利用 “运动恢复结构(SfM)”,通过目标在多帧中的运动视差,反推其三维位置(类似人眼通过左右眼视差感知深度);
- 多摄像头:通过 “多视图立体匹配(MVS)”,对同一时刻不同视角的目标特征点进行三角化计算,直接获取三维坐标(精度更高,适用于全域场景)。
- 关键突破:针对 “无标定摄像头”,通过 “光束平差法(Bundle Adjustment)” 从视频中自动估计相机内外参数,摆脱对安装参数的依赖。

3. 全域三维场景的时空融合
当多摄像头覆盖全域场景时,需将各摄像头的三维坐标统一到 “世界坐标系”,形成全局空间模型:
- 时空校准:通过时间戳同步多摄像头视频(解决拍摄时差),通过空间控制点匹配计算摄像头间的相对位置(解决视角差异);
- 动态更新:实时融合新帧的空间控制点,更新目标的三维轨迹(如车辆行驶路径、行人移动路线),确保模型与物理世界的动态一致性。
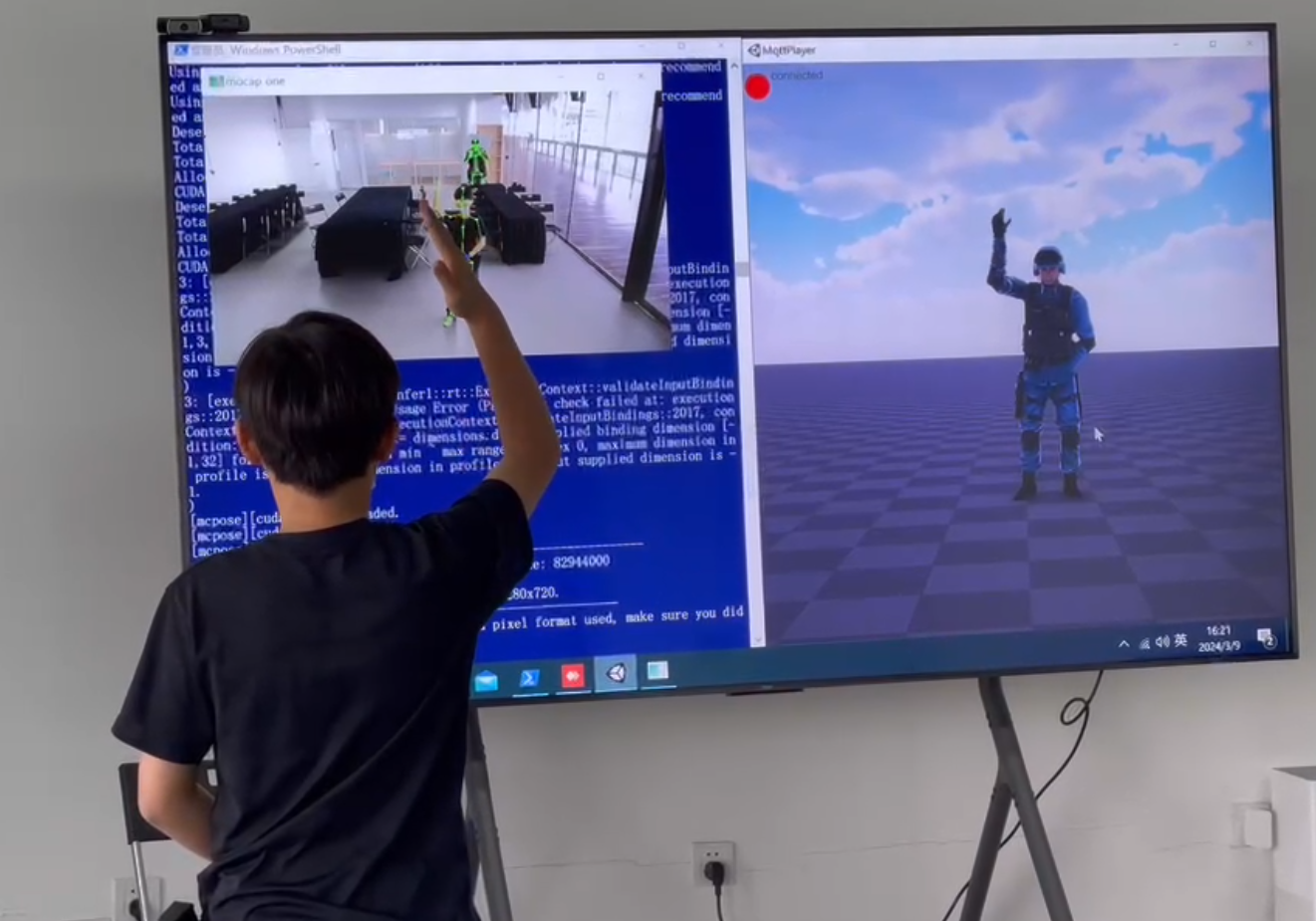
4. 基于三维坐标的场景决策引擎
利用三维坐标提供的 “深度 + 空间关系” 信息,支撑更精准的决策:
- 纵深控制:如在智慧停车场中,通过车辆的三维坐标判断其与障碍物的真实距离(而非二维图像中的像素距离),实现自动泊车避障;
- 行为分析:在安防场景中,通过行人的三维运动轨迹(如突然加速、偏离正常路径)识别异常行为;
- 资源调度:在交通管理中,基于车辆的三维密度分布(如某路段三维空间内的车流量)动态调整信号灯时长。
应用价值:打破摄像头 “视角壁垒”,释放全域智能
无论摄像头安装在天花板、街角、高空还是移动设备(如无人机),只要能捕捉动态目标,该技术即可:
- 消除 “二维误判”:例如,二维视频中 “两个物体重叠” 可能是视角导致的假象,而三维坐标可明确其实际空间位置(是否真的接近);
- 提升决策精度:如消防救援中,通过三维重构可精准定位被困人员的楼层高度(纵深信息),而非仅知道 “在某区域”;
- 降低部署门槛:无需专业标定设备,普通摄像头即可组成三维感知网络,适用于社区、工厂、园区等各类场景。

从 “视频孪生” 的 “数字映射” 到 “动态目标三维重构” 的 “空间解析”,本质是让视频从 “被动观看工具” 升级为 “主动感知器官”—— 通过三维坐标的打通,物理世界的动态信息得以转化为可计算、可决策的数据,最终支撑更精细、更智能的场景管理。