医疗领域名词标准化工具
1.项目整体目标
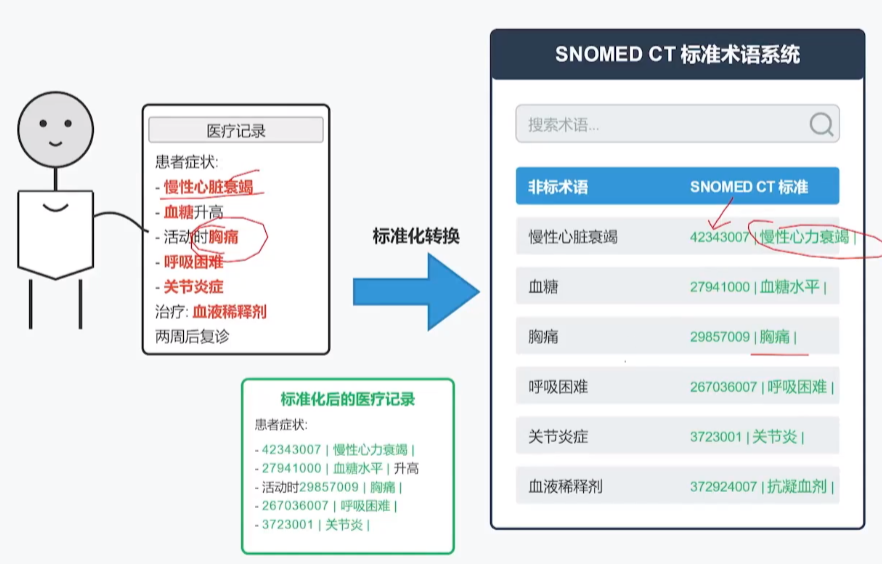
医疗系统记录的专有名词标准化,医生记录的非标准术语转化为标准的术语和id
词汇表:https://www.snomed.org/what-is-snomed-ct
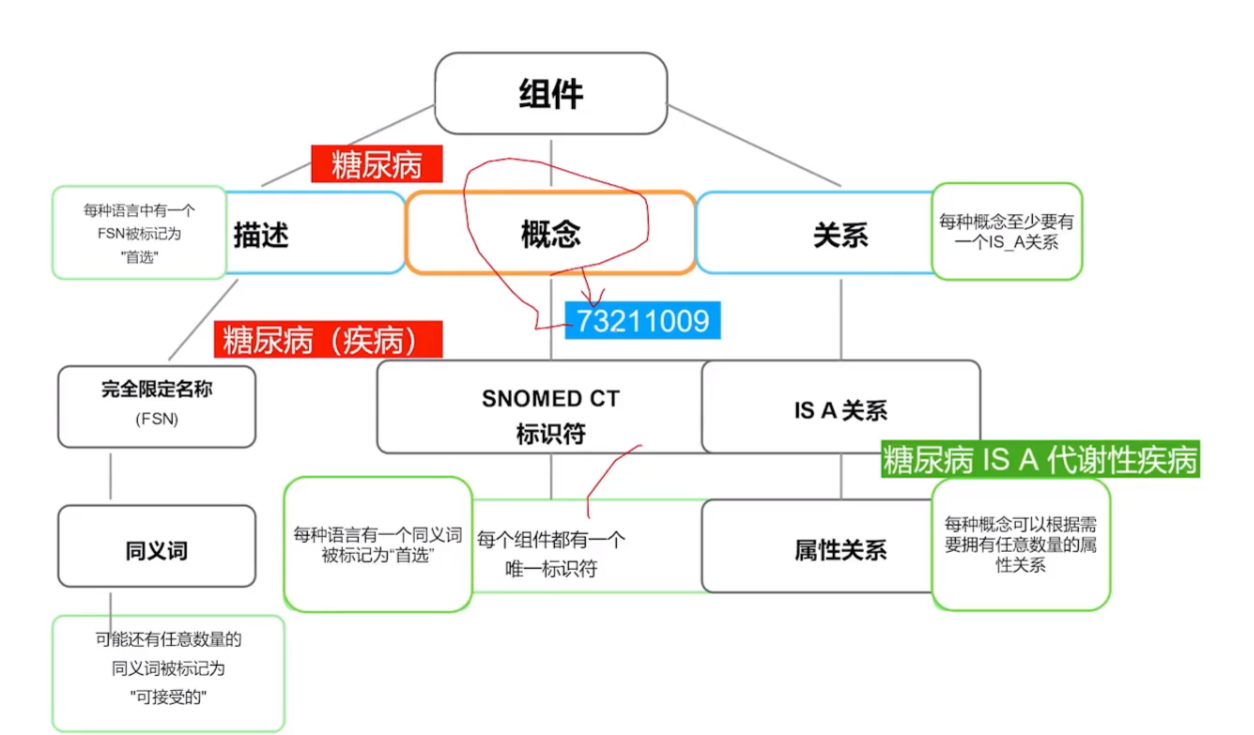
SNOMED CT 术语结构:
SNOMED CT 术语查询网址:NHSDigital SNOMED CT Browser
FSN - Fully Specified Name(完全限定名称)
FSN 是对一个 SNOMED 概念最完整、最明确、不含歧义的命名方式。它包括了该概念的核心术语和它的上下文,以确保它在任何地方都可以被唯一识别
特点
• 每个 SNOMED 概念 只有一个 FSN
• 通常以括号中的词(如 (disorder)、(procedure) 等)表示 语义类别
• 用于程序内部的 唯一识别与精确区分,处理术语映射或知识抽取,FSN 是可靠的概念“标签”
• 不适合作为界面友好显示,通常界面上会使用 Preferred Term(首选术语)
概念(Concept)例子
SNOMED CT 标识符示例:
• 22298006:表示"心肌梗死"这一概念
• 73211009:表示"糖尿病"这一概念
• 39156-5:表示"体温"这一概念
每个概念都有一个唯一的数字标识符,不论使用何种语言表达,这个概念的核心含义都不变。
描述(Description)例子
完全限定名称(FSN)示例:
• 22298006 |心肌梗死(疾病)|
• 73211009 |糖尿病(疾病)|
• 386661006 |发热(临床发现)|
同义词示例:
1. 心肌梗死(22298006)的同义词:
1. 首选同义词:心肌梗死
2. 可接受的同义词:心梗、急性心肌梗死、冠脉堵塞
2. 糖尿病(73211009)的同义词:
1. 首选同义词:糖尿病2. 可接受的同义词:高血糖症、血糖异常
关系(Relationship)例子
IS A关系示例:
• 心肌梗死 IS A 心脏疾病
• 2型糖尿病 IS A 糖尿病
• 阿司匹林 IS A 非甾体抗炎药
属性关系示例:
- 肺炎的属性关系:
- 有发病部位:肺组织
- 有病因:肺炎链球菌(细菌性肺炎的情况)
- 有临床表现:发热、咳嗽、呼吸困难
- 阿司匹林的属性关系:
- 有活性成分:乙酰水杨酸
- 有药理作用:抗血小板聚集
- 有适应症:预防心肌梗死、缓解疼痛
场景1:医疗记录标准化
医生在病历中写道:"患者出现胸痛,诊断为急性心肌梗死"。
系统会将“急性心肌梗死”映射到SNOMED CT概念22298006。
使其在所有相关系统中被一致识别,无论当地医生习惯使用何种表达方式。
场景2:多语言环境
不同语种
- 中文系统中显示:"心肌梗死"
- 英文系统中显示:"Myocardial infarction"
- 西班牙语系统中显示:"Infarto de miocardio“
但三者背后都是同一个概念ID:22298006,这使得不同语言的医疗系统可以无缝交换信息。
场景3:药物相互作用检测
当医生为一位已在服用华法林(抗凝药)的患者开具阿司匹林时,系统通过属性关系识别到两种药物都有"抗凝"作用,自动发出药物相互作用警告,可能增加出血风险。
场景4:医疗数据分析
研究人员想分析所有心脏疾病患者的数据,系统可以通过IS A关系自动包含心肌梗死、心绞痛、心律失常等所有心脏疾病的子类,确保分析的全面性。
场景5:临床决策支持
医生记录患者有"发热、咳嗽、血常规示白细胞升高"等症状,决策支持系统通过SNOMED CT的关系网络,可以提示可能的诊断包括肺炎、支气管炎等,并根据属性关系推荐相应的检查和治疗方案。
2.项目技术实现
代码下载和功能演示
https://github.com/huangjia2019/rag-project02-medical-nlp-box
构建医学专有名词知识库
1. 选择一个好的Embedding模型
MTEB Leaderboard排名提供了关于各种任务的最佳文本嵌入模型的整体视图:https://huggingface.co/blog/mteb
2. 用SentenceTransformer(Hugging Face) 下载这个模型
embedding_function = model.dense.SentenceTransformerEmbeddingFunction(# model_name='nvidia/NV-Embed-v2', # model_name='dunzhang/stella_en_1.5B_v5',# model_name='all-mpnet-base-v2',# model_name='intfloat/multilingual-e5-large-instruct',model_name='Alibaba-NLP/gte-Qwen2-1.5B-instruct',# model_name='BAAI/bge-m3',# model_name='jinaai/jina-embeddings-v3',device='cuda:0' if torch.cuda.is_available() else 'cpu',trust_remote_code=True)3. 创建向量数据库(Milvus)
windows系统不支持Milvus数据库,替换为chroma
专有名词标准化系统设计
系统通过向量数据库处理文本输入,识别医疗相关的术语,并使用NER技术找到相关的医疗关键词。前端需传递特定的文本和向量数据库设定至后端,后端则通过API实现逻辑处理,最终返回最相关的专有名词。系统还能根据设定返回多个最相关的名词,例如top 5或top 10。
医疗NER功能实现
使用一个医疗名词抽取(Medical NER)模型来识别和分类医疗术语,特别是疾病和症状。通过分析模型返回的数据类型和种类,将这些信息与项目中的domain ID相链接,从而进行更精准的医疗信息检索和过滤。
通过调用Hugging Face库中的pipeline,可以实现命名实体识别任务。进一步的,通过对模型返回的实体类别进行了解和分析,可以进行类别合并或剔除等定制化操作以满足特定项目需求。例如,可以将特定的身体部位和症状合并成一个实体,或者移除不需要的实体类别如年龄、性别或地理位置。通过这些策略,可以对命名实体识别的结果进行调整和优化,以提高处理的准确性和效率。
医疗名词扩展和纠错功能实现
把名词缩写扩展为完整名词,使用ollama模型
3.利用图数据库提升RAG质量
利用知识图谱,系统不仅能直接匹配相近术语,还能通过概念节点关联,实现复杂语义的检索,如从简称SOB定位到dspnea,从而提高检索质量和信息饱满度。
此方法通过抓取描述信息和相关关系,将其与原有概念结合进行embedding,从而在检索时提供更丰富的语义信息。