RAGFlow入门
一、RAG检索增强生成
官方定义:
"RAG是一种将参数化记忆(预训练语言模型)与非参数化记忆(外部知识检索系统)相结合的混合架构,通过实时检索相关文档片段作为上下文依据,显著增强生成模型的 factual grounding 和知识时效性。"
简单理解:
一般我们问大模型一个关于企业内部的问题或者是特定领域的专业问题,因为大模型训练的时候没有接触这些专有数据,所以这个时候大模型会出现幻觉,会凭空捏造答案。
RAG就是为了解决这个问题,做法是将从知识库检索出来的文档作为提示词的上下文,一并提交给大模型,让他生成更可靠的答案,比如用户发起一个提问,首先会把这个问题向量化,然后查找相关的知识库中相关片段,根据片段和用户的问题,生成一个带有上下文的prompt,提交给大模型进行回答,获得一个相对更准确的回答。
如果只是没有查找到相关数据,依然会出现幻觉,可以设计兜底策略,实际应用中,通常会在检索阶段设置阈值(如相似度分数),如果没有检索到足够相关的内容,可以让系统直接回复‘未找到相关信息’或‘知识库暂无此内容’,而不是让大模型随意发挥,这样可以降低幻觉风险。
二、LLM大语言模型
大语言模型(英语:Large Language Model,简称LLM)是指使用大量文本数据训练的深度学习模型,使得该模型可以生成自然语言文本或理解语言文本的含义。这些模型可以通过在庞大的数据集上进行训练来提供有关各种主题的深入知识和语言生产 。其核心思想是通过大规模的无监督训练学习自然语言的模式和结构,在一定程度上模拟人类的语言认知和生成过程,可以执行各种语言任务,如问答、翻译、写作、代码生成等。
常见的LLM大语言模型有这些:
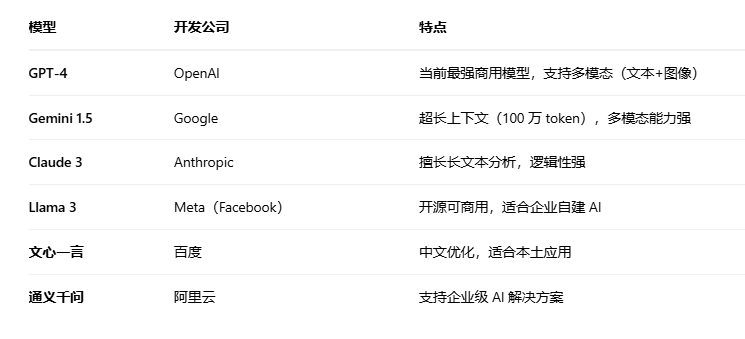
三、RAGFlow定义
RAGFlow 是一款基于深度文档理解的开源 RAG(Retrieval-Augmented Generation,检索增强生成)引擎。它与大语言模型(LLM)结合,能够为各种格式复杂的数据提供可靠的问答能力,并提供充分的引用依据。
- 普通LLM:只靠死记硬背(训练数据,可能会有数据比较旧的情况,因为新数据并没有加入训练)
- RAG+LLM:可以开卷考试(实时检索最新数据)
四、为什么要选择RAGFlow(对比Excel和网盘)

五、RAGFlow与传统LLM的对比
