语音活动检测VAD技术简介
Introduction
最近工作上要做一些语音相关的工作,语音上又有很多相关步骤,降噪啦,增强啦,VAD啦,ASR啦,最近主要是在了解调研一些VAD的相关内容,做个记录。
VAD(Voice Activity Detection,语音活动检测)用于识别音频流中“语音段”(含人声)和“非语音段”(静音、背景噪音、音乐等)的时间边界,输出语音段的起止时间戳。
VAD通常在ASR(Automatic Speech Recognition,自动语音识别,用于将人类语音转化为文本)之前进行,用以划分出有效的语音段,从而降低后续处理的算力成本,并且也能够通过截断无效音频来提高实时性。
VAD本质上是一个二分类方法,因为音频中一般只有语音和噪声(语音以外的内容均认为是噪声)两种内容,VAD方法就只需在一段音频流中划分出这两部分的内容。一般来说,给定一段音频,划分为若干帧(若干毫秒的采样数据为一帧,比如16kHz采样率的双通道音频,每毫秒每个通道要采集16个数据点,以16ms为一帧,每帧每个通道的数据点应该为16x16=256),这些帧输入到vad模型中,vad输出一个概率值表示当前帧有多大可能有人声,设定了阈值之后会判断这个概率值是否大于这个阈值,大于的话输出1,否则0,表示有无人声。(当然有的模型可能反过来的,比如我看到有个ten-vad模型onnx格式的优化版本就是有人声输出0否则输出1,据作者说可以“大大优化性能开销”)
有两个图能够很好地描述如VAD等语音处理步骤在整个语音交互系统中是如何作用以及处于如何地位的:

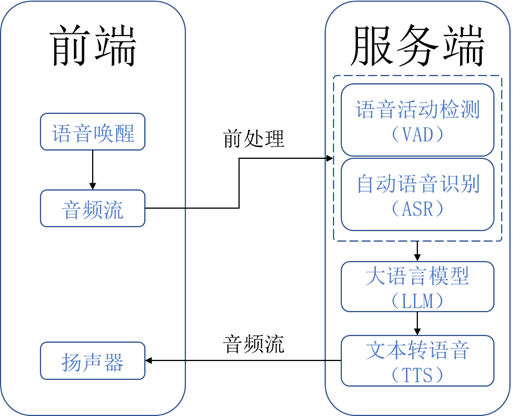
实现vad一般两种方法:传统方法和现代的深度学习方法。传统方法一般基于声音之中的某些特征,比如能量、频域、倒谱、谐波、长时等等等等,一大票指标,WebRTC是这之中的代表作品,但都什么年代了,还在搞传统vad?深度学习方法的性能又好鲁棒性又强,还能猛猛水文章,没理由不用它啊!唯一的缺点就是成本较高,但在现代硬件性能不断提高的背景下,再加上有意识的模型优化,这点开销已经并非不能承担。
接下来介绍三个主流的vad模型(也许不是主流,但是是博主这几天跑代码亲手试验过的,要不然不敢拿出来讲)。
以下所有代码都跑在Python3.8.20的环境下,使用的测试音频是博主自己拿手机录的一段6秒左右的音频,在安静环境下录的,因此几乎没有噪声,音频内容念了一句诗(我知道你在想什么,但确实不是那句):柴门闻犬吠,风雪夜归人。其中在中间有停顿,因此最后vad应该输出四个时间戳,分别代表前半句的开始和结束与后半句的开始和结束。音频的采样率为16kHz,双通道,比特率为512 kb/s。
silero-vad
GitHub地址:snakers4/silero-vad: Silero VAD: pre-trained enterprise-grade Voice Activity Detector
silero-vad是一个轻量级的深度学习模型,模型大小在1MB左右,支持多种语言,推理速度较快,支持8kHz/16kHz的输入。
安装方法:pip install silero-vad
但是silero-vad需要一个音频后端对音频做处理,ffmpeg or soundfile,为了方便,我们安装soundfile,安装方法:pip install soundfile。
此外,为了保险,把pytorch及其相关的库也安装上:pip install torch torchaudio torchvision。
然后是代码:
from silero_vad import load_silero_vad, read_audio, get_speech_timestampsif __name__ == '__main__':model = load_silero_vad()wav = read_audio('a.wav') # 我们的音频文件speech_timestamps = get_speech_timestamps(wav,model,return_seconds=True, # Return speech timestamps in seconds (default is samples))for di in speech_timestamps:start = di['start'] # 开始处的秒数end = di['end'] # 结束处的秒数print(f"start: {start}s, end: {end}s")
输出结果:
start: 0.8s, end: 2.6s
start: 3.7s, end: 5.3s
然后听听对应部分的音频,嗯,不错,确实基本只有人声。
fsmn-vad
fsmn-vad是基于FSMN(Feedforward Sequential Memory Network,前馈序列记忆网络)架构设计的语音活动检测模型。FSMN由百度团队提出,核心特点是在保持前馈网络高效计算特性的同时,通过引入“记忆模块”捕捉长时序列依赖,非常适合处理语音这类时序信号。FSMN VAD结合了FSMN的时序建模能力与VAD的二分类任务需求,在实时性和检测精度上取得了较好平衡。得益于全并行计算,其推理速度较快,参数量在1M-5M左右。
一开始博主还傻乎乎的去网上找对应的GitHub网址,结果真让博主找到一个,但是下载下来按照教程跑了一下,输出的时间戳怎么都不对,后来看到网上有在funasr框架下用fsmn的,于是去试了一下,果然就没问题了,现在想起来,大概是野鸡仓库被博主当成官方仓库了,内部实现有问题,博主还傻乎乎的找了一下午bug(泪目)。
这里再简单介绍下funasr:FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。FunASR希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
上述是在GitHub上的介绍(https://github.com/modelscope/FunASR)。可以看到,这是一个语音方面综合性的框架,兼顾学术研究和工业应用(偏向端侧部署),虽然说可能以asr为大头主流,但还是有vad相关的内容的,比如说fsmn-vad就在其中内置了。
安装funasr之前,确保已经安装了下面依赖环境:
python>=3.8
torch>=1.13
torchaudio
安装:
pip3 install -U funasr modelscope huggingface huggingface_hub
代码:
'''采用funasr框架调用fsmn-vad进行vad'''from funasr import AutoModelif __name__ == '__main__':model = AutoModel(model="fsmn-vad",disable_update=True,device='cpu',)res = model.generate(input='a.wav')segments = res[0]['value']segments = list(map(lambda x: [x[0] / 1000.0, x[1] / 1000.0], segments)) # 将毫秒转换为秒for a, b in segments:print(f"start: {a}s, end: {b}s")
这里注意,因为fsmn-vad最后输出的单位是毫秒,因此我们要除以1000来转换为秒的单位。
输出结果:
start: 0.51s, end: 2.76s
start: 3.38s, end: 5.5s
嗯,跟之前silero-vad的差不多,听一听,确实如此,这下终于没把时间戳划到人声上面去了。
ten-vad
GitHub地址:TEN-framework/ten-vad: Voice Activity Detector(VAD) from TEN: low-latency, high-performance and lightweight
一个基于深度学习的轻量级流式语音活动检测模型,具备低延迟、低功耗、高准确率等优势,相较于一些常用的模型有更好的性能和更低的计算成本。
这好像还是一个比较新的模型,似乎是去年还是啥时候发布的,看它主页上面的介绍,好像还是目前最先进的vad模型,性能、开销、延迟等都要走在第一梯队。
安装:
pip install -U --force-reinstall -v git+https://github.com/TEN-framework/ten-vad.git
代码:
from ten_vad import TenVad
import scipy.io.wavfile as Wavfile
import numpy as npif __name__ == "__main__":sr, data = Wavfile.read('a.wav') # data - N x 2 双通道数据,N为采样点数if len(data.shape) >= 2:data = data.mean(1, dtype=np.int16) # 多通道平均# data = data[:, 0] # 只取第一个声道hop_size = 256 # 16 ms per framethreshold = 0.5ten_vad_instance = TenVad(hop_size, threshold) # Create a TenVad instancenum_frames = data.shape[0] // hop_size# Streaming inferenceli = []for i in range(num_frames):audio_data = data[i * hop_size:(i + 1) * hop_size]# Out_flag is speech indicator (0 for non-speech signal, 1 for speech signal)out_probability, out_flag = ten_vad_instance.process(audio_data)# print("[%d] %0.6f, %d" % (i, out_probability, out_flag))li.append(out_flag)# smoothli_new = [0 for _ in range(len(li))]li_new[0] = li[0]for i in range(1, len(li) - 1):zero, one = 0, 0for j in range(i - 1, i + 2):if li[j] == 0: zero += 1else: one += 1if zero > one: li_new[i] = 0else: li_new[i] = 1li_new[-1] = li[-1]# 计算时间戳one = Falseres = []start, end = 0, 0for i, v in enumerate(li_new):if v == 1 and not one:start = i * hop_size / 16one = Trueelif v == 0 and one:end = i * hop_size / 16res.append([start, end])one = Falseif one:end = len(li) * hop_size / 16res.append([start, end])# 过滤掉过短的时间段res = [[start, end] for (start, end) in res if end - start > 300]# 将毫秒转换为秒res = list(map(lambda x: [x[0] / 1000.0, x[1] / 1000.0], res))for a, b in res: # 输出结果print(f"start: {a}s, end: {b}s")
这里注意了,不像是silero-vad或者funasr下的fsmn-vad,这些模型都是输入音频直接输出给你时间戳了,但ten-vad比较底层,需要你手动划分音频数据,一帧一帧的送到模型里,并且给定阈值由模型输出0和1,然后得到了一系列的0和1,每个0或1对应那一帧里是否会有人声,这里会出现一种情况,那就是一连串的0里掺杂了几个1,或者一连串的1里掺杂了几个0,因此这串数据不能够直接使用,先做一个平滑,博主这里是选定当前帧以及前后各一帧一共3帧的数据,1多当前帧就判断为1,0多就判断为0,很简单。
搞定之后计算时间戳,因为我们要找人声存在的时间戳,因此寻找一连串1的开始和结束,由于每个0和1对应的是相应的帧,而每一帧的时间长度我们是知道的,因此找到一个1及其索引后完全可以计算出这个1所在的时间。可以获得一系列存在人声的开始和结束的时间戳。
再然后,发现有若干极其微小的时间碎片,这可能是模型误判,因此去掉所有时间长度小于300ms的时间戳(这个数据是博主自己拍脑门想的,完全可以设计成其他的数字,或者上深度学习用模型学习这个数据的大小,或者用统计方法来做都可以更加精细)。
最后的输出结果:
start: 0.816s, end: 2.496s
start: 3.68s, end: 5.28s
嗯,和前面的结果也差不多,听一下音频,也有完整的人声内容。
值得一说的是,在使用ten-vad的时候,从运行代码到输出结果博主感觉是最快的,silero-vad要慢一些,funasr下的fsmn-vad是最慢的,这可能和框架中间层还有模型本身的优劣有关,不过从这里也确实可以看出ten-vad没吹牛,性能确实相当可以。
总结
上面就是本文主要内容了,感觉如果追求极致性能,尤其是部署的目标平台涉及到资源有限的边缘设备的时候,ten-vad比较合适,或者silero-vad也不错,毕竟老牌方案;而如果是不那么在乎资源性能,并且倾向于云端侧部署,而且后续还希望能够在同一套框架下集成其他语音功能(比如asr),可以选择基于funasr的fsmn-vad,funasr本身就是为了这一套东西而生的,fsmn-vad只是其中所提供的的一个小小预训练模型罢了。