[Chat-LangChain] 会话图(LangGraph) | 大语言模型(LLM)
第二章:会话图(LangGraph)
在第一章中,我们学习了前端用户界面——这是聊天机器人的"面孔",我们在这里输入问题并查看答案。
我们看到了消息如何从聊天窗口传递到聊天机器人的"大脑"。现在,让我们深入探索这个"大脑"本身!
聊天机器人的大脑:解决什么问题?
想象我们向一位超级聪明的朋友提出复杂问题:“什么是LangChain?如何用它构建聊天机器人?”
人类朋友不会直接抛出第一个想到的答案。他们可能会:
理解问题:“好的,这是关于LangChain和构建聊天机器人的”制定研究计划:“首先需要解释LangChain,然后说明如何用它构建聊天机器人”执行研究(步骤1):“查找’什么是LangChain?'相关资料”执行研究(步骤2):“搜索’LangChain构建聊天机器人示例’”整合信息:“已经收集所有必要信息块”- 给出清晰
答案:“这是LangChain的定义,以及用它构建聊天机器人的方法…”
我们的聊天机器人需要实现类似的流程!它不能仅依赖大语言模型(LLM)一次性完成所有操作。
LLM擅长生成文本,但天然不擅长管理工作流,例如规划研究步骤、搜索数据库以及整合不同信息块。
chat-langchain项目的这个模块要解决的核心问题是:我们的聊天机器人如何管理复杂对话和任务,将其分解为步骤、做出决策,并协调不同工具来找到最佳答案?
这就是会话图(使用强大的LangGraph库构建)的用武之地。它是聊天机器人的"大脑"和"工作流管理器"。
什么是会话图(LangGraph)?
LangGraph可以看作聊天机器人行为的流程图或配方。它定义了所有可能的执行步骤,以及步骤间的转移决策逻辑。
核心概念解析:
- 图(Graph):在计算机科学中,"图"是由节点(圆形)和边(连接线)组成的结构
- 节点(步骤/动作):聊天机器人可以执行的独立任务,例如"分析问题"、“搜索信息"或"生成最终答案”
- 边(规则/决策):节点间的连接逻辑,例如"完成问题分析后,如果是LangChain相关的问题,则跳转到’搜索信息’节点"
- LangGraph:专门为对话式AI构建的流程图库,帮助设计包含状态记忆的复杂工作流
- 状态(大脑记忆):当聊天机器人执行流程图时,需要记忆:
- 用户对话历史
- 待解决的研究问题列表
- 已找到的文档资料
- LangGraph负责管理这些"记忆"以实现进度跟踪
简而言之,LangGraph帮助我们构建能够执行多步计划、使用不同工具(如搜索引擎)并做出智能决策的聊天机器人,而不是仅靠猜测生成答案。
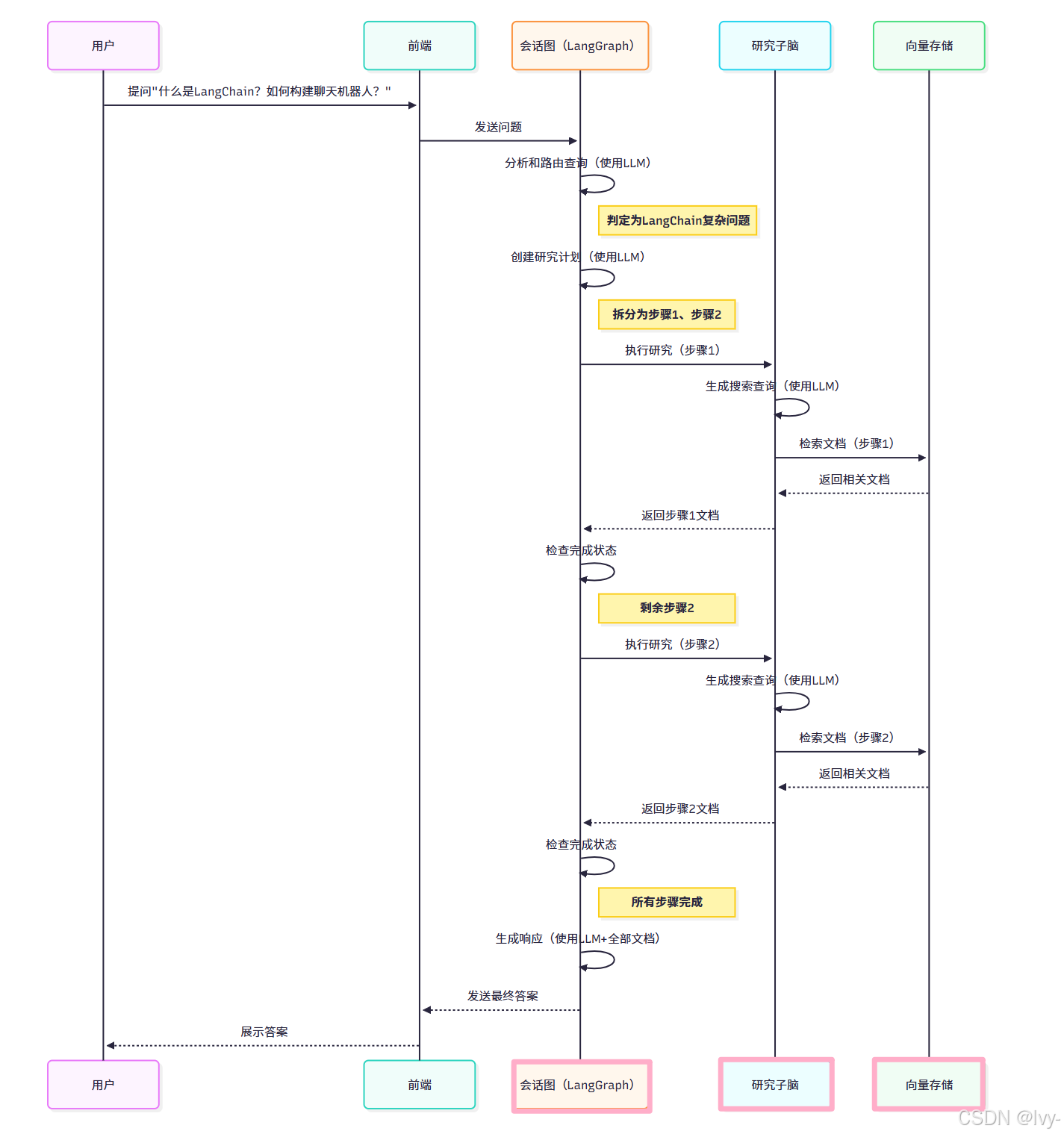
会话图工作原理:以"智能问题"为例
以问题"什么是LangChain?如何用它构建聊天机器人?"为例,演示LangGraph的协调过程:
- 接收消息(来自前端用户界面)
- 分析和路由查询:
- LangGraph"大脑"接收问题
- 使用LLM分类问题类型(普通聊天/需要更多信息/LangChain相关复杂问题)
- 决策:“这是关于LangChain的复杂问题”
- 创建研究计划:
- 判定需要分步研究
- 使用另一个LLM拆分问题:
- 步骤1:“什么是LangChain?”
- 步骤2:“如何用LangChain构建聊天机器人?”
- 执行研究(步骤1):
- 将第一个研究步骤发送给专用"研究子脑"(也是LangGraph构建的流程图)
- 研究子脑生成搜索查询,通过检索过程从向量存储(Weaviate)获取相关文档
- 主脑更新记忆状态(
存储找到的文档)
- 检查完成状态:
- 查看研究计划剩余步骤
- 决策:“步骤2待处理”
- 执行研究(步骤2):
- 重复研究子脑的文档检索过程
- 主脑更新记忆状态
- 检查完成状态:
- 确认所有步骤已完成
- 生成响应:
- 将所有对话历史和检索文档发送给最终LLM
- 生成综合性的最终答案
- 返回前端(通过前端用户界面展示答案)
整个过程由会话图协调管理。
幕后机制:LangGraph工作流
大脑流程图(简化版)
大脑记忆:AgentState
LangGraph通过AgentState类管理记忆状态,定义见backend/retrieval_graph/state.py:
# backend/retrieval_graph/state.py(简化版)
@dataclass(kw_only=True)
class AgentState:messages: Annotated[list[AnyMessage], add_messages] # 全部聊天消息router: Router = field(default_factory=lambda: Router(type="general", logic="")) # 查询类型steps: list[str] = field(default_factory=list) # 研究计划步骤documents: Annotated[list[Document], reduce_docs] = field(default_factory=list) # 检索到的文档answer: str = field(default="") # 最终答案# ...其他状态字段...
messages记录对话历史,steps存储研究计划,documents保存检索结果。
构建大脑:节点与边
主流程图定义在backend/retrieval_graph/graph.py,关键组件:
节点1:analyze_and_route_query(决策器)
async def analyze_and_route_query(state: AgentState, *, config: RunnableConfig) -> dict[str, Router]:# 使用LLM分类问题类型model = load_chat_model(config.query_model).with_structured_output(Router)messages = [{"role": "system", "content": config.router_system_prompt}] + state.messagesresponse = cast(Router, await model.ainvoke(messages))return {"router": response} # 存储分类结果
节点2:create_research_plan(规划器)
async def create_research_plan(state: AgentState, *, config: RunnableConfig) -> dict[str, list[str]]:# 生成分步研究计划model = load_chat_model(config.query_model).with_structured_output(Plan)messages = [{"role": "system", "content": config.research_plan_system_prompt}] + state.messagesresponse = cast(Plan, await model.ainvoke(messages))return {"steps": response["steps"]} # 返回步骤列表
节点3:conduct_research(研究协调器)
async def conduct_research(state: AgentState) -> dict[str, Any]:# 委托研究子脑执行单个步骤result = await researcher_graph.ainvoke({"question": state.steps[0]})return {"documents": result["documents"], "steps": state.steps[1:]} # 更新文档和步骤
节点4:respond(应答生成器)
async def respond(state: AgentState, *, config: RunnableConfig) -> dict[str, list[BaseMessage]]:# 整合信息生成最终答案model = load_chat_model(config.response_model)context = format_docs(state.documents) # 格式化文档prompt = config.response_system_prompt.format(context=context)messages = [{"role": "system", "content": prompt}] + state.messagesresponse = await model.ainvoke(messages)return {"messages": [response], "answer": response.content}
流程图装配
builder = StateGraph(AgentState, input=InputState, config_schema=AgentConfiguration)# 添加所有节点
builder.add_node("analyze_and_route_query", analyze_and_route_query)
builder.add_node("create_research_plan", create_research_plan)
builder.add_node("conduct_research", conduct_research)
builder.add_node("respond", respond)
# ...其他节点...# 定义状态转移逻辑
builder.add_edge(START, "analyze_and_route_query")
builder.add_conditional_edges("analyze_and_route_query",route_query,{"create_research_plan": "create_research_plan","ask_for_more_info": "ask_for_more_info","general": "respond_to_general_query"}
)
# ...更多连接逻辑...graph = builder.compile()
graph.name = "RetrievalGraph"
结论
本章探讨了**会话图(LangGraph)**作为聊天机器人的核心决策系统。
通过节点(执行步骤)、边(转移逻辑)和状态(记忆管理)的协同工作,实现了复杂对话任务的分解与协调。
下一章将深入解析支撑这些功能的大语言模型(LLM)。
第三章:大语言模型(LLM)
第三章:大语言模型(LLM)
在第二章中,我们了解了会话图(LangGraph)作为聊天机器人的"大脑",它像熟练的项目经理般协调回答问题的各个步骤。
但谁是真正执行理解、创造性思维并生成类人文本的智能专家?这正是本章的核心:大语言模型(LLM)。
聊天机器人的专家顾问:解决什么问题?
想象我们正在构建复杂项目:项目经理(LangGraph)负责组织协调,但遇到技术文档理解、解决方案构思或撰写清晰报告等专业任务时,我们需要聘请专家顾问。
大语言模型(LLM)在chat-langchain中解决的核心理念是:我们的聊天机器人如何真正理解问题,通过创造性思维分解任务,并基于复杂信息生成类人化的智能答案?
LLM是系统的"专家顾问"和"对话专家",负责:
- 重述用户问题(
查询分析):用户可能基于上下文提出简短追问,LLM能将其转化为完整清晰的独立问题 生成研究计划:针对复杂问题,LLM可像人类专家般拆解为分步研究计划构建最终答案:整合检索过程获取的信息后,LLM将其转化为清晰易读的答案
什么是大语言模型(LLM)?
大语言模型(LLM)本质上是基于海量互联网文本数据(书籍/文章/网页等)训练的强大人工智能,可视为:
- 超级智能文本生成器:能撰写文章/诗歌/代码/摘要等类人化文本
- 卓越理解者:理解文本含义,识别词语关系,掌握复杂语境
- 对话大师:凭借文本理解和生成能力,实现类人对话和问答
在chat-langchain中,LLM赋予聊天机器人"智能"——实现文本解析、规划和创造的能力。
LLM在chat-langchain中的应用
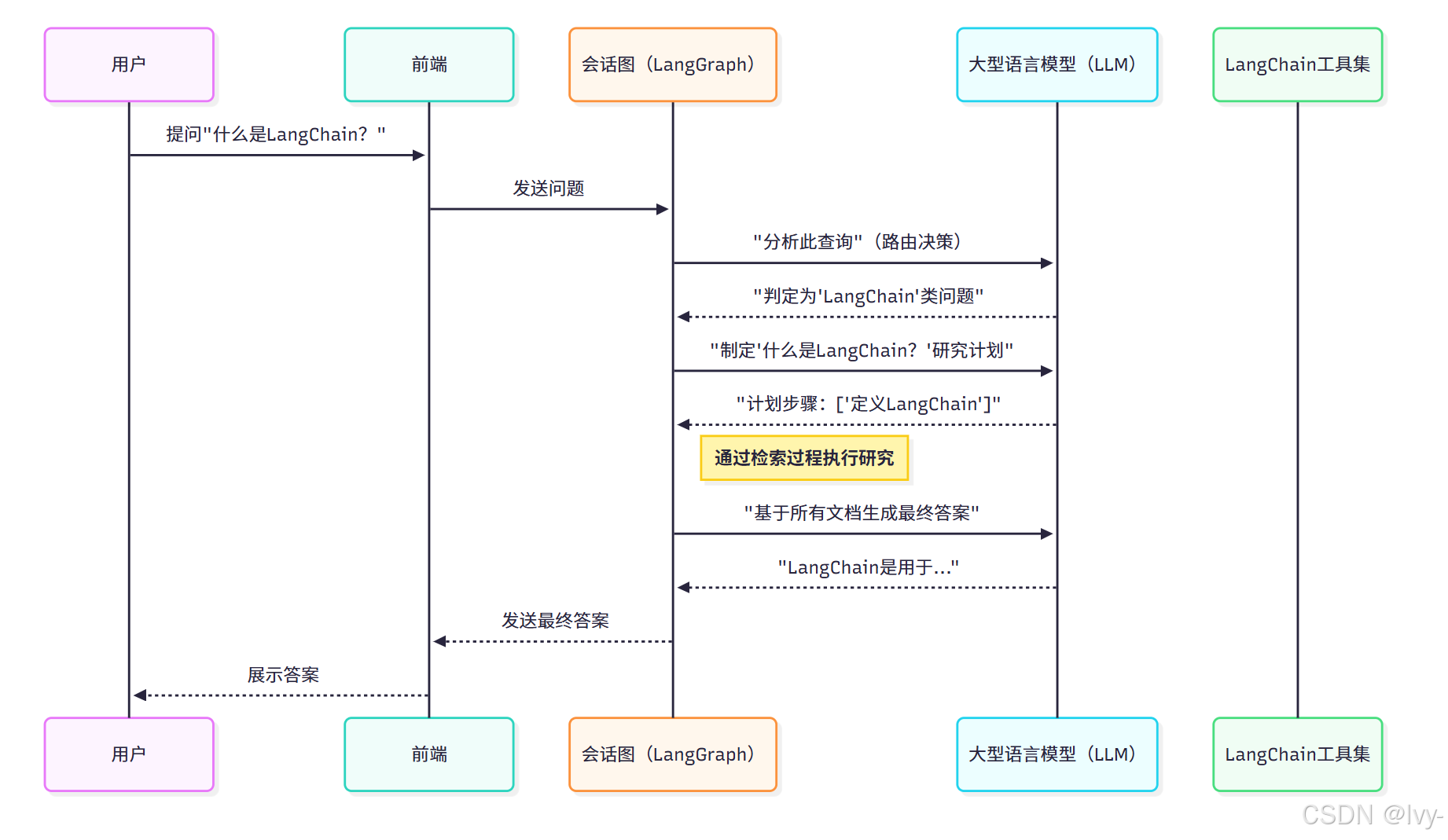
1. 重述用户问题(查询分析)
当用户提出"聊天机器人场景下如何应用?"等简短追问时,LLM会结合:
- 完整对话历史
- 当前简短提问
生成独立清晰的问题:“LangChain如何用于构建聊天机器人?”(参见CONCEPTS.md中的REPHRASE_TEMPLATE提示模板)
2. 生成研究计划
面对"解释LangChain代理及其工具使用机制"等复杂问题,会话图(LangGraph)会请求LLM生成分步计划,例如:
- “什么是LangChain代理?”
- “LangChain代理如何使用工具?”
3. 构建最终答案
当会话图(LangGraph)通过检索过程收集足够信息后,LLM会:
- 整合对话历史
- 融合检索文档
- 生成连贯答案(参见
MODIFY.md中的RESPONSE_TEMPLATE模板)

实现细节:LLM工作机制
工作流中的LLM(简化版)
(LangGraph分解问题,列清单,LLM才是真正执行解答)
1. LLM选择与加载
chat-langchain支持多种LLM服务商(OpenAI/Anthropic/Google等),配置见backend/retrieval_graph/configuration.py:
@dataclass(kw_only=True)
class AgentConfiguration(BaseConfiguration):# 查询分析和计划制定的LLMquery_model: str = field(default="anthropic/claude-3-5-haiku-20241022",metadata={"description": "用于查询处理的语言模型"})# 最终答案生成的LLMresponse_model: str = field(default="anthropic/claude-3-5-haiku-20241022",metadata={"description": "用于生成响应的语言模型"})# 系统提示模板router_system_prompt: str = field(default=prompts.ROUTER_SYSTEM_PROMPT, ...)research_plan_system_prompt: str = field(default=prompts.RESEARCH_PLAN_SYSTEM_PROMPT, ...)response_system_prompt: str = field(default=prompts.RESPONSE_SYSTEM_PROMPT, ...)
通过backend/utils.py的load_chat_model函数加载模型:
def load_chat_model(fully_specified_name: str) -> BaseChatModel:"""根据模型名称加载LLM(如'openai/gpt-4o-mini')"""if "/" in fully_specified_name:服务商, 模型 = fully_specified_name.split("/", maxsplit=1)else:服务商 = ""模型 = fully_specified_namereturn init_chat_model(模型, model_provider=服务商, temperature=0) # 温度参数控制创造性
2. 核心功能实现
查询分析(路由决策)
async def analyze_and_route_query(state: AgentState, config: RunnableConfig) -> dict[str, Router]:配置 = AgentConfiguration.from_runnable_config(config)模型 = load_chat_model(配置.query_model).with_structured_output(Router)消息 = [{"role": "system", "content": 配置.router_system_prompt}] + state.messages响应 = cast(Router, await 模型.ainvoke(消息))return {"router": 响应} # 存储分类结果
研究计划生成
async def create_research_plan(state: AgentState, config: RunnableConfig) -> dict[str, list[str]]:class 计划(TypedDict):steps: list[str]模型 = load_chat_model(配置.query_model).with_structured_output(计划)消息 = [{"role": "system", "content": 配置.research_plan_system_prompt}] + state.messages响应 = cast(计划, await 模型.ainvoke(消息))return {"steps": 响应["steps"]}
最终答案生成
async def respond(state: AgentState, config: RunnableConfig) -> dict[str, list[BaseMessage]]:模型 = load_chat_model(配置.response_model)上下文 = format_docs(state.documents[:20]) # 取前20个相关文档提示 = 配置.response_system_prompt.format(context=上下文)消息 = [{"role": "system", "content": 提示}] + state.messages响应 = await 模型.ainvoke(消息)return {"messages": [响应], "answer": 响应.content}
结论
本章深入解析了大语言模型(LLM)作为chat-langchain系统的智能核心。LLM在查询理解、研究规划和答案生成中发挥关键作用,而会话图(LangGraph)则负责整体协调。下一章将探讨支撑LLM工作的检索过程。
第四章:检索过程