零基础-动手学深度学习-10.4. Bahdanau 注意力

seq2seq最大的问题就在于虽然用RNN编码解码能够控制遗忘但是并不能直接对生成词可能就是原句子的词这种情况进行建模,也就是中对一种词完全的关注,因此我们需要上述注意力。
10.4.1. 模型
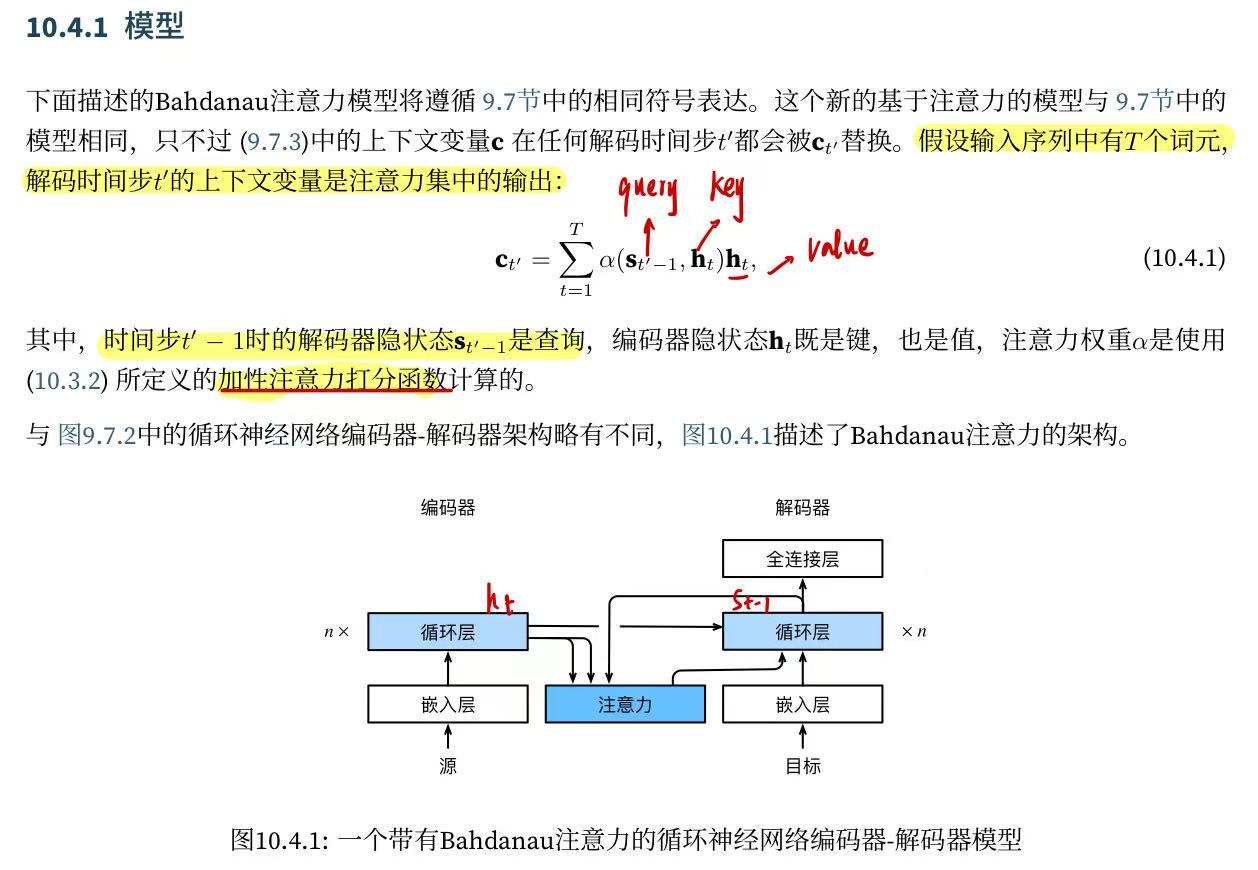
编码器对每次词的输出作为key和value,解码器RNN对上一个词的输出是query,注意力的输出和下一个词的词嵌入合并进入,这里我们就可以发现,这么做可以把编码器只能传入最后一个隐状态的seq2seq改进为可以识别预测和输入之间的权重然后再决定每次的输出的模型。
#初始化
import torch
from torch import nn
from d2l import torch as d2l10.4.2. 定义注意力解码器
下面看看如何定义Bahdanau注意力,实现循环神经网络编码器-解码器。 其实,我们只需重新定义解码器即可。 为了更方便地显示学习的注意力权重, 以下AttentionDecoder类定义了带有注意力机制解码器的基本接口。、
#@save
class AttentionDecoder(d2l.Decoder):"""带有注意力机制解码器的基本接口"""def __init__(self, **kwargs):super(AttentionDecoder, self).__init__(**kwargs)@property#@property 是 Python 的一个内置装饰器,作用是把一个类的方法变成“只读属性”,调用时不需要加括号,用起来像访问普通实例变量一样。def attention_weights(self):#多加了一个这个raise NotImplementedError接下来,让我们在接下来的Seq2SeqAttentionDecoder类中 实现带有Bahdanau注意力的循环神经网络解码器。 首先,初始化解码器的状态,需要下面的输入:
-
编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
-
上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
-
编码器有效长度(排除在注意力池中填充词元)。
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。 因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入。
核心实现就是下面这个函数:encoder其实是没变的
class Seq2SeqAttentionDecoder(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)#init中就是加了这个加性attentionself.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):#enc valid lens就是识别编码器的pad# outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,num_hiddens)outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):# enc_outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,# num_hiddens)enc_outputs, hidden_state, enc_valid_lens = state# 输出X的形状为(num_steps,batch_size,embed_size)X = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:#每一个输入都要作为(key,value)# query的形状为(batch_size,1,num_hiddens)query = torch.unsqueeze(hidden_state[-1], dim=1)#这里意思是h_s再上个时刻RNN最后一次的输出,然后再dim=1维度上加一个1进去# context的形状为(batch_size,1,num_hiddens)context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)#核心在这,context怎么变?# 在特征维度上连结x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)# 将x变形为(1,batch_size,embed_size+num_hiddens)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights)# 全连接层变换后,outputs的形状为# (num_steps,batch_size,vocab_size)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,enc_valid_lens]@propertydef attention_weights(self):#画图用return self._attention_weights接下来,使用包含7个时间步的4个序列输入的小批量测试Bahdanau注意力解码器。
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape输出:(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))10.4.3. 训练
与 9.7.4节类似, 我们在这里指定超参数,实例化一个带有Bahdanau注意力的编码器和解码器, 并对这个模型进行机器翻译训练。 由于新增的注意力机制,训练要比没有注意力机制的 9.7.4节慢得多。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)输出:loss 0.021, 4948.7 tokens/sec on cuda:0模型训练后,我们用它将几个英语句子翻译成法语并计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')输出:go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est paresseux ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((1, 1, -1, num_steps))训练结束后,下面通过可视化注意力权重 会发现,每个查询都会在键值对上分配不同的权重,这说明 在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
# 加上一个包含序列结束词元
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')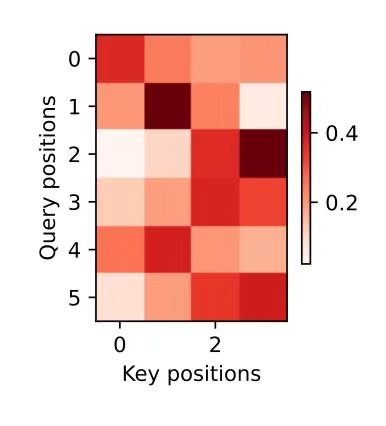
长句子的效果会好一点
10.4.4. 小结
-
在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
-
在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值。