【web自动化】-2- 浏览器的操作和元素交互
一、警告框
警告框属于 JavaScript 脚本执行的机制结果
一般的警告框分类一下类型元素标签
- alert
- confirm
- prompt
- input
- ...
不管哪种类型的警告框元素,一旦触发,都会阻止对页面的继续操作
解决警告框的方法:
- 获取警告框元素
- 获取警告框的提示信息
- 关闭警告框
- 通过确认按钮进行关闭
- 通过取消按钮进行关闭
- 针对一些警告框可以输入内容,那么可以使用对应方法进行输入
警告框是悬浮在页面上的一层 所以需要切到警告框这一步操作,尽管有些警告框是没有取消按钮的 但取消是一个关闭警告框的javascrip形式 任何情况都可以使用accept取消关闭警告框。
# 获取警告框元素
driver.find_element(By.XPATH, '//*[@id="alert1"]').click()
# 切入警告框
alert1 = driver.switch_to.alert
# 获取警告框的提示信息
print(alert1.text) # 我被被点击啦!
time.sleep(2)
# 关闭警告框
# - 通过**确认按钮**进行关闭
alert1.dismiss()
# - 通过**取消按钮**进行关闭
alert1.accept()
# 针对需要输入内容的警告框,可以使用send_keys方法进行输入
alert1.send_keys("密码")
# 强制等待
time.sleep(5)二、页面切换
# 查看所有页面
print(driver.window_handles)
# - 自由切换不同的页面
driver.switch_to.window(driver.window_handles[1])
# - 获取单个页面信息
print(driver.current_window_handle)
# 点击珍品拍卖: 页面没有发生切换之前, 驱动还停留在之前页面, 不能操作子页面元素
driver.find_element(By.XPATH, '//*[@id="extra-zhenpin"]/a').click()# 查看所有页面
print(driver.window_handles)
driver.switch_to.window(driver.window_handles[2])
# 点击夺宝岛
driver.find_element(By.XPATH, '//*[@id="nav-duobaodao"]/a').click()
# 获取单个页面信息
print(driver.current_window_handle)
# 查看所有页面
print(driver.window_handles)
# - 创建新的页面
# 创建新页面并直接打开指定网址
driver.execute_script("window.open('https://www.taobao.com');")总结:
- 页面跳转时需要进行切换才能操作子页面
- 切换子页面可以通过: switch_to.window (driver.window_handles [索引值])
- 一旦子页面发生切换,那么当前操作的页面值也会发生变化: driver.current_window_handle
pycharm去实践:
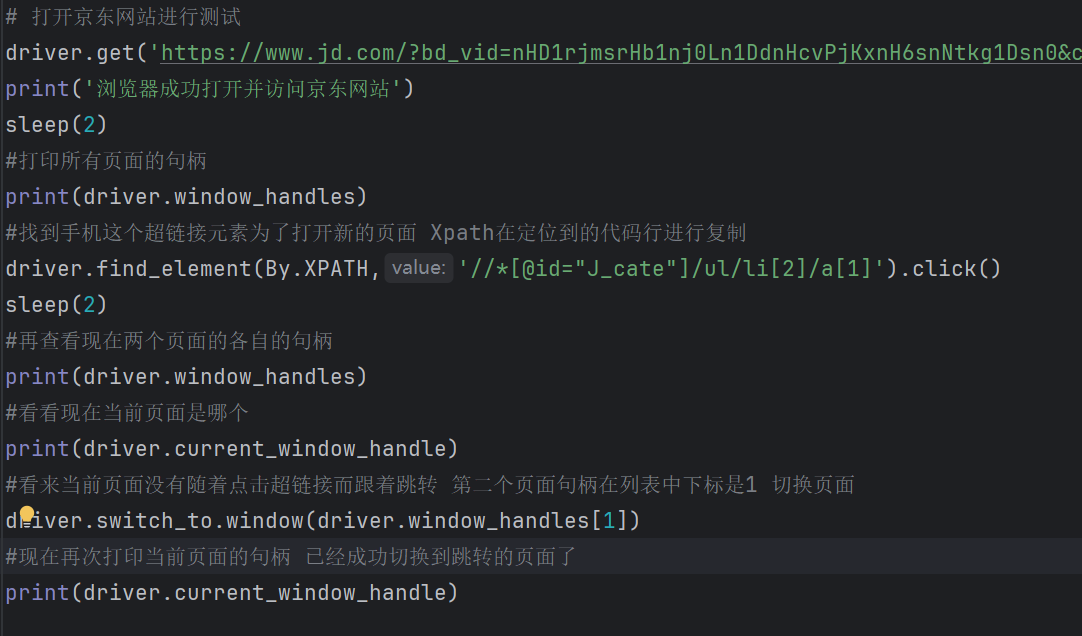
三、通过cookies绕过登录验证
# 创建一个驱动对象: 谷歌
driver = webdriver.Chrome()# 通过驱动对象访问被测页面
driver.get("https://www.baidu.com/")# 页面最大化
driver.maximize_window()# 给页面设置cookie信息
driver.add_cookie({"name": "BAIDUID", "value": "DDC8E5F34358B014:FG=1"})
driver.add_cookie({"name": "BDUSS_BFESS", "value": "BDJ1ROTDIwUVvTmQxIGtckNnT20wTElUY3ZLbFRoRE8ySGF4N0Z4WnFqVWRSvFBQUFBJCQAAAAAAAAAAAEAAAABezHiftts24Lbgvt~M5QAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGoAIGvqACB1Yx"})# 清除页面缓存, 一定要执行刷新操作
time.sleep(2)
driver.refresh()# 强制等待
time.sleep(10)
# - 输入账号
driver.find_element(By.XPATH, '/html/body/form/table/tbody/tr/td[3]/table/tbody/tr[2]/td[2]/input').send_keys("admin")
# - 输入密码
driver.find_element(By.XPATH, '/html/body/form/table/tbody/tr/td[3]/table/tbody/tr[3]/td[2]/input').send_keys("msjy123")
# - 输入验证码
driver.find_element(By.XPATH, '/html/body/form/table/tbody/tr/td[3]/table/tbody/tr[5]/td[2]/input').send_keys("8888")
# - 点击登录后台按钮
driver.find_element(By.XPATH, '//*[@id="login_btn"]').click()
time.sleep(1) # 验证码错误:实际结果的信息是一定的有效期,如果不能在有效期获取文本属性那么输出空值
# 获取实际结果
msg = driver.find_element(By.XPATH, '//*[@id="login_msg"]').text
print(msg)
# 断言实际结果
assert msg == "验证码错误"- 优点:使用不同页面或者不同项目的 cookie 信息都可以自动化的获取保持并且使用
# 获取页面的所有cookie信息
cookies1 = driver.get_cookies()
# 获取的所有cookie信息返回值是一个列表里面嵌套字典,所有cookie的名字是键,值是具体的内容
# [{'domain': '47.107.116.139', 'httpOnly': True, 'name': 'PHPSESSID',
# 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': 'pdh8aj1q8j2tdmt1gftj6ckif2'}]# 将获取到列表中所有的cookie信息添加到页面中
for cookie in cookies1:# 将页面中所有的cookie键值对遍历添加driver.add_cookie(cookie)
else:# 添加完成之后清楚缓存driver.refresh()print(cookies1)- 结合项目实际保持登录状态逻辑处理
- 按照正常流程让页面进行登录操作
- 登录成功之后保持已登录的 cookie 信息
- 下次再进行登录的时候直接使用 cookie 信息
- 完成保持登录的状态
def save_cookies(driver):# 将获取到的cookie信息保持在本地文件cookies = driver.get_cookies()with open("cookies.json", "w") as f:# json文件的数据python中不能直接进行使用,需要进行转化才能使用# json.dumps()将python中的字典转化为json字符串对象f.write(json.dumps(cookies))def load_cookies(driver):# 将保持在本地的文件cookie信息进去读取并使用with open("cookies.json") as f:cookies = json.loads(f.read())for cookie in cookies:# 读取json文件里面所有的cookie信息driver.add_cookie(cookie)else:# for循环正常结束之后,所有cookie信息添加之后进行页面刷新driver.refresh()
在 Python 中,直接将 Python 对象(如 driver.get_cookies() 返回的列表嵌套字典这种复杂结构)写入文件会面临序列化和跨场景复用的问题,而借助 JSON 格式中转有以下关键原因:
⭐ Python 对象 “无法直接写入文件”
文件存储的是字节 / 字符串,而 Python 对象(如列表、字典)是内存中的数据结构,没有 “直接对应” 的文件存储格式。
如果强行尝试直接写,会触发错误。例如:
cookies = [{"name": "a", "value": "1"}, {"name": "b", "value": "2"}]
with open("cookies.txt", "w") as f:f.write(cookies) # 报错:TypeError: write() argument must be str, not list
因为 write() 要求参数是字符串,而 cookies 是列表,类型不匹配。
⭐ JSON 是 “跨语言 / 跨场景” 的通用格式
driver.get_cookies() 拿到的 Cookie 不仅能在 Python 中使用,也可能需要在 ** 其他语言(如 Java、JavaScript)或其他场景(如前端页面、其他自动化工具)** 中复用。
JSON 是一种轻量级、跨语言的通用数据交换格式,几乎所有编程语言都支持 JSON 的解析和生成。将 Cookie 转成 JSON 字符串写入文件后:
- 其他语言可以通过各自的 JSON 库读取并使用这些 Cookie。
- 即使只在 Python 内使用,也能通过
json.loads()可靠地还原为 Python 对象(列表嵌套字典)。
⭐ 保证数据的 “可解析性”
如果直接将 Python 对象的内存表示(如通过 pickle 序列化)写入文件,虽然能存,但存在以下问题:
- 兼容性差:
pickle是 Python 专属的序列化方式,其他语言无法解析。 - 安全性低:
pickle反序列化存在代码执行风险(若文件被篡改,可能注入恶意代码)。
而 JSON 是纯数据格式,没有执行代码的能力,更安全、通用。
⭐ 总结
用 JSON 中转的核心目的是:让复杂 Python 对象(如列表嵌套字典)能以 “通用、安全、跨场景” 的方式持久化到文件,并在需要时可靠还原。虽然多了 “转 JSON 写文件 → 读文件转 Python 对象” 的步骤,但解决了 “Python 对象无法直接写文件” 和 “跨语言 / 跨场景复用” 的关键问题。
优化load_cookies的代码 异常处理机制
def load_cookies(driver):# 当页面没有cookie信息时,需要先正常登录然后再保持cookie# 在下次页面进行访问的时候再使用cookietry:# 将保持在本地的文件cookie信息进去读取并使用with open("cookies.json") as f:cookies = json.loads(f.read())for cookie in cookies:# 读取json文件里面所有的cookie信息driver.add_cookie(cookie)else:# for循环正常结束之后,所有cookie信息添加之后进行页面刷新driver.refresh()except:print("目前页面没有可以使用的cookie信息,需要正常登录获取cookie保持再使用")四、iframe切换
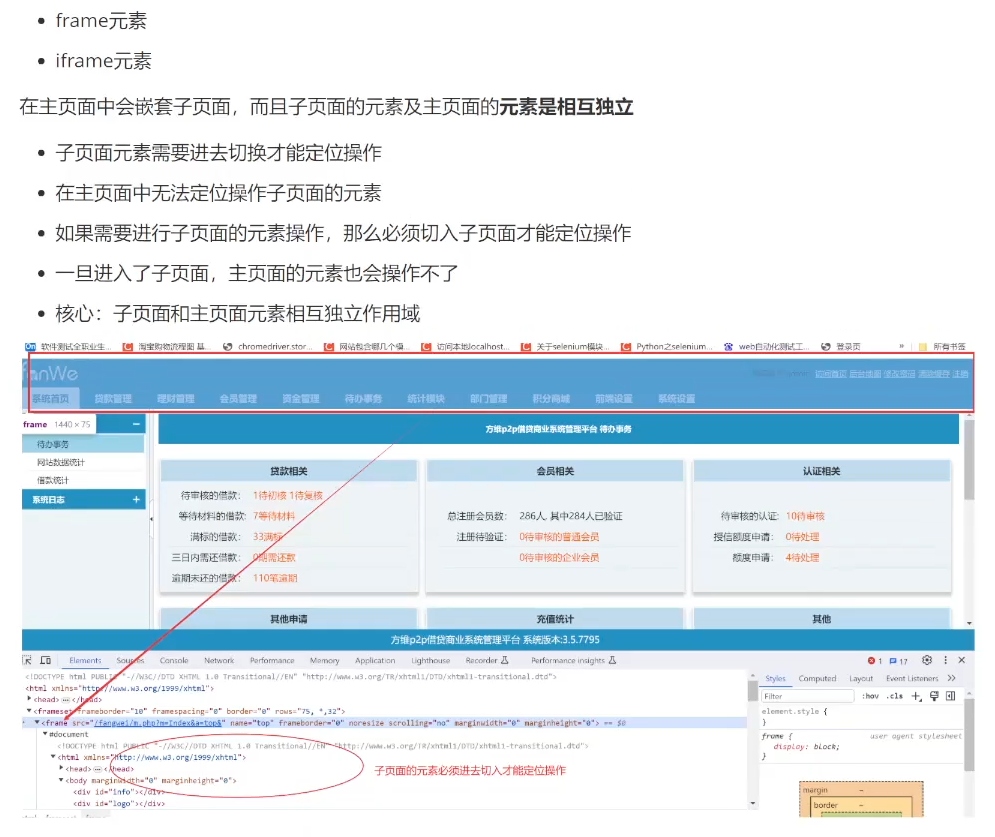

子页面之间需要切换才能定位到不同子页面的元素:
# 使用已经登录的驱动,完成新增贷款页面的脚本设计
import timefrom selenium.webdriver.common.by import Byfrom admin_login import driver# 由于页面结构嵌套子页面,需要进行子页面切换才能完成元素的定位
# 定位子页面元素
frame1 = driver.find_element(By.XPATH, "/html/frameset/frame[1]")
# 切换子页面元素
driver.switch_to.frame(frame1)
# 2.定位贷款管理元素点击
driver.find_element(By.XPATH, '//*[@id="navs"]/ul/li[2]/a').click()# 子页面与子页面之间不能直接进行跳转,需要返回原始主页面才能再次进行切换子页面
# 切回主页面
driver.switch_to.default_content()
# 切换新增按钮的子页面中
time.sleep(1)
frame2 = driver.find_element(By.XPATH, '//*[@id="main-frame"]')
driver.switch_to.frame(frame2)
# 点击新增贷款
driver.find_element(By.XPATH, "/html/body/div[2]/div[3]/input[1]").click()time.sleep(5)五、下拉框
下拉框(按文本选择的方式)
driver.find_element(By.XPATH, '//*[@id="repay_time"]').send_keys("365")
# 日期
sl1 = driver.find_element(By.XPATH, '//*[@id="repay_time_type"]')
select1 = Select(sl1)
select1.select_by_visible_text("天")
下拉框(按 value 属性值/索引选择的方式)
# 分类:
sl1 = driver.find_element(By.XPATH, '/html/body/div[2]/form/table[1]/tbody/tr[8]/td[2]/select')
select1 = Select(sl1)
select1.select_by_value("4")
# 担保机构:
sl1 = driver.find_element(By.XPATH, '/html/body/div[2]/form/table[1]/tbody/tr[9]/td[2]/select')
select1 = Select(sl1)
select1.select_by_index(2)六、文件上传
注意:由于文件上传的按钮 xpath 值可能会发生变化,那么使用该 xpath 定位不到该元素,后期将手写 xpath 进行定位。
# 文件上传:
# 1.点击文件上传按钮
driver.find_element(By.XPATH, '/html/body/div[2]/form/table[1]/tbody/tr[14]/td[2]/span/div[1]/div/div/button').click()
# 2.点击本地上传按钮
time.sleep(2)
driver.find_element(By.XPATH, '/html/body/div[5]/div[1]/div[2]/div/div[1]/ul/li[2]').click()
# 3.点击浏览文件输入文件内容
driver.find_element(By.XPATH, '/html/body/div[5]/div[1]/div[2]/div/div[3]/form/div/div/div/input').send_keys(r"D:\Project234_web\verify.png")
# 4.点击确定按钮
driver.find_element(By.XPATH, '/html/body/div[5]/div[1]/div[3]/span[1]/input').click()七、页面元素定位的 “变化性” 问题
在 Selenium 自动化操作中,当对页面进行不同选项或元素的交互操作时,页面元素的 XPath(一种用于定位页面元素的路径表达式)可能会动态变化。
比如,页面结构调整、元素层级改变等情况,都会导致原本能定位到元素的 XPath 失效。
调试与解决方法
- 调试手段:可以使用 Python 的
input内建函数来进行程序调试。在关键步骤插入input(),让程序暂停执行,此时手动去检查当前页面元素的实际 XPath,看是否与脚本中写的 XPath 一致。 - 解决思路:如果发现 XPath 不一致,就需要修改脚本中的 XPath。更可靠的方式是手写 XPath,通过精准分析页面结构,编写更稳定、不易受页面变化影响的 XPath 来定位具体元素。
- 正反例脚本编写:因为页面元素具有 “多变性”,所以在第一轮 ** 冒烟测试(快速验证核心功能是否可用的测试)脚本编写时,要同时编写正例(符合预期、功能正常的场景)和反例(不符合预期、功能异常的场景)** 脚本。
- 自动化运行与后续步骤:只有当正反例脚本都能成功实现自动化运行(即脚本能稳定控制浏览器完成预期操作、验证结果),才会进入下一步 —— 选择合适的设计模式(如 Page Object 模式,用于优化代码结构、提高可维护性),以及对自动化测试用例进行封装(将测试逻辑模块化,方便复用和管理)。
八、如何手写xpath
手写 XPath 是 Selenium 自动化测试中精准定位页面元素的关键技能,核心是基于 HTML 页面的标签结构、属性、层级关系等编写路径表达式。以下是手写 XPath 的核心方法与示例:
⭐ 基础语法与核心规则
XPath 通过路径、标签名、属性、逻辑关系等定位元素,核心语法规则:
- 路径符号:
/(从根节点开始的绝对路径)、//(从当前节点或任意位置开始的相对路径)。 - 标签匹配:直接写标签名(如
div、input),或用*匹配 “任意标签”。 - 属性筛选:
[@属性名="属性值"](如[@id="username"]匹配id="username"的元素)。
⭐ 常用手写 XPath 方法
1. 按「ID 属性」定位
如果元素有唯一 id,是最优先的定位方式,示例:
//input[@id="username"] <!-- 定位 id 为 username 的 input 标签 -->
2. 按「class 属性」定位
若元素有 class(注意:class 可能有多个值,需精确匹配或包含匹配),示例:
//div[@class="container"] <!-- 定位 class 为 container 的 div 标签 -->
//div[contains(@class, "box")] <!-- 定位 class 包含 box 的 div 标签 -->
3. 按「其他属性」定位
如 name、type 等属性,示例:
//input[@name="password"] <!-- 定位 name 为 password 的 input 标签 -->
//input[@type="submit"] <!-- 定位 type 为 submit 的 input 标签 -->
4. 按「文本内容」定位
通过元素的文本内容匹配(常用于按钮、链接等),示例:
//button[text()="登录"] <!-- 定位文本为“登录”的 button 标签 -->
//a[contains(text(), "注册")] <!-- 定位文本包含“注册”的 a 标签 -->
5. 按「层级关系」定位
结合父子、祖先 - 后代等层级,示例:
- 父子关系(
/表示直接子节点)://div[@class="form"]/input <!-- 定位 class 为 form 的 div 的直接子 input 标签 --> - 祖先 - 后代关系(
//表示任意层级后代)://div[@id="app"]//button <!-- 定位 id 为 app 的 div 下所有层级的 button 标签 -->
6. 按「逻辑组合」定位
用 and、or 组合多个条件,示例:
//input[@type="text" and @name="username"] <!-- 同时满足 type="text" 和 name="username" 的 input 标签 -->
⭐ 实战示例(结合页面结构)
假设页面有如下 HTML 结构:
<div class="login-box"><input id="user" name="username" type="text"><input id="pwd" name="password" type="password"><button class="btn" type="submit">登录</button>
</div>
- 定位用户名输入框(按 id):
//input[@id="user"] - 定位密码输入框(按 name + 类型):
//input[@name="password" and @type="password"] - 定位登录按钮(按文本 + 层级):
//div[@class="login-box"]//button[text()="登录"]