机器学习之PCA降维
简介
在机器学习中,高维数据常常像一层迷雾,不仅会增加模型的复杂度、拖慢计算速度,还可能因 “维度灾难” 导致模型性能下降。而 PCA(主成分分析)降维算法,就像一把精准的 “数据手术刀”,能在保留关键信息的同时,剥离冗余维度,让数据变得更简洁、更易处理。我们会从最根本的问题出发:为什么要进行降维?
一、主成分分析(PCA)
什么是主成分分析
就是通用的降维工具,数据的特征又叫做数据的维度,减少数据维度(即降维 ),是指在尽可能保留数据关键信息的前提下,降低数据特征数量,简化数据集结构
1.1向量的内积:
内积:
A 与 B 的内积:
假设向量的模等于 1,即
,此时
到\
的投影变成了:
1.2基
定义:基(也称为基底)是描述、刻画向量空间的基本工具。
- 基:
与
是二维空间的一组基 3. 向量
由这一组基完全表示。
- 基的条件: 4. 什么样的向量可以成为基?
- 任何两个线性无关的二维向量都可以成为一组基
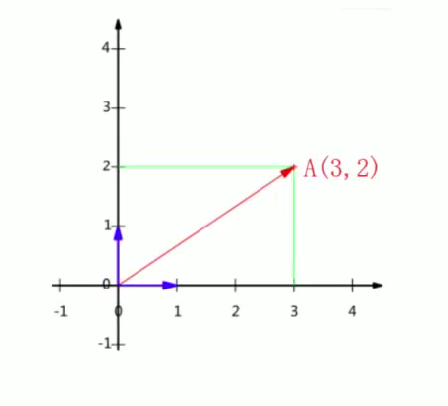
1.3基变换:
新的一组基:
变换成模为的新基:
将(3,2)映射到新的基上:
由于新的基的模是1,所以直接相乘可得结果 (内积的定义):
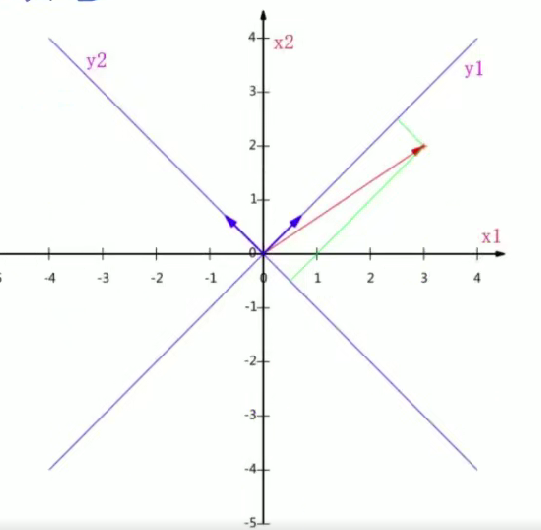
对于多个二维向量:
推广到 m 个 N 维向量的变换:
其中为行,
为列
1.4基变换的含义:
- 两个矩阵相乘的意义是将每一列右边矩阵中的列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。
- 抽象地说,一个矩阵可以表示一种线性变换。
如何选择基才是最优的?或者说,如何才能有效地保留较多的原始数据信息。
方差最大的方向即为最优基。
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。
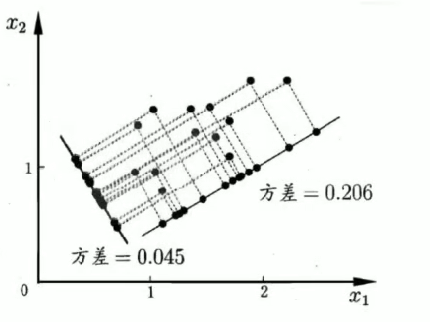
1.5方差公式:
数据特征(维度)减去均值
dim1 均值,处理后:
dim2 均值,处理后:
问题转化
寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。(对于二维变一维来说)
对于三维数据来说,将数据降到二维,寻找的基为方差最大的方向,再次将数据降到一维呢?这个基是什么?必然与降到二维的基无限接近。
- 方差次大。
- 这样的一个基是没有用的,我们应该让两个基线性无关【线性无关才能保留更多的原始信息】
1.6协方差
公式:
原始:
均值为时简化:
-
含义:表征两个字段之间的相关性。
-
当协方差为
时,表示两个字段完全独立。
利用协方差为,选择另一组基,这组基的方向一定与第一组基正交。
1.7协方差矩阵
定义:
假设我们有,
两个字段,组成矩阵:
用乘以其转置,并乘以
:
对于更高维度的数据,上述结论依然成立。
目标
除主对角线上的元素外,都为,并且方差从大到小排列。
1.8协方差矩阵对角化
-
变量说明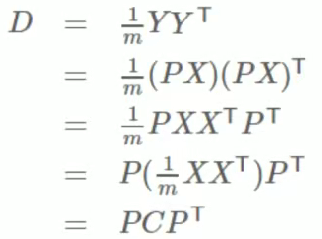
- 原始数据:
→ 协方差矩阵:
- 一组基按行组成的矩阵:
- 基变换后的数据:
→ 协方差矩阵:
- 隐含信息:
- 原始数据:
寻找一个矩阵,满足\
是一个对角矩阵,并且对角元素按从大到小依次排列。
此时,的前
行就是要寻找的基;用\
的前\
行组成的矩阵乘以
,可使\
从
维降到
维,满足 “协方差矩阵对角化 + 方差降序” 的优化条件。、
1.9协方差矩阵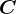 对角化
对角化
-
公式:
,其中
-
实对称矩阵特性: 若
,使得:
-
-
为对角矩阵,对角线元素
是
终极目标找到
核心公式:
终极目标:
-
的定义:
二、计算案例
1. 执行第一步与第二步
数据:
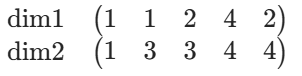
- dim1 均值
,处理后:
- dim2 均值
,处理后:
2. 计算协方差矩阵
协方差矩阵C的计算:
3. 计算协方差矩阵的特征值与特征向量
特征方程为协方差矩阵,这里
求解特征值:
展开行列式得:
解得特征值:
求特征向量:
当时: 经初等变换得:
对应方程:
特征向量: 单位化后:
当时,特征向量:
单位化后
4.矩阵
对角化验证:
计算为协方差矩阵,
:
5.基变换后的数据:
用\的行向量对去均值后的数据
做变换:
三、PCA的优缺点
优点
- 计算方法简单,容易实现。
- 可以减少指标筛选的工作量。
- 消除变量间的多重共线性。
- 在一定程度上能减少噪声数据。
缺点
- 特征必须是连续型变量。
- 无法解释降维后的数据是什么。
- 贡献率小的成分有可能更重要。
四、PCA的API
class PCA:def __init__(self, n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None):self.n_components = n_componentsself.copy = copyself.whiten = whitenself.svd_solver = svd_solverself.tol = tolself.iterated_power = iterated_powerself.random_state = random_state参数解释
n_components:- 作用:用于指定 PCA 降维后的特征维度数目。
- 取值说明:
- 若为整数,比如
n_components=5,就是把原始数据直接降维到 5 维 ,适用于明确知道目标维度的场景,像 10 维数据想降到 5 维分析时设置该整数。 - 若为小数(范围一般 0 到 1 ),例如
n_components=0.9,表示要让降维后的数据累计方差百分比达到 90% ,算法会自动选择合适的维度数来满足这个方差要求,方便在不想手动指定维度,又希望保留一定比例数据信息时使用。
- 若为整数,比如
copy:- 类型:布尔值(
bool),可选True或False,默认True。 - 意义:决定运行 PCA 算法时是否复制原始训练数据。
- 不同取值行为:
copy=True:会复制一份原始训练数据,在副本上进行 PCA 运算,这样原始数据的值在算法运行后不会改变,能保证原始数据的完整性,后续若还需用原始数据做其他操作不受影响。copy=False:直接在原始训练数据上进行降维计算,运行后原始数据的值会被改变,优点是能节省内存(不用额外存副本 ),但要注意后续不能再直接使用原始数据原本的值了。
- 类型:布尔值(
whiten:- 作用:判断是否对数据进行白化操作。
- 白化含义:对白化后的每个特征做归一化,让特征方差都变为 1 ,可以去除特征间的相关性且统一特征尺度。
- 取值与场景:默认
False即不进行白化。一般单纯 PCA 降维本身不需要白化;但如果 PCA 降维后还有后续数据处理(比如作为输入给对特征尺度敏感的模型 ),可考虑设True进行白化,不过会增加计算和存储开销(因为要对数据做额外变换 )。
svd_solver:- 作用:指定奇异值分解(
SVD)的方法,因为 PCA 底层常用 SVD 实现(特征分解是 SVD 特例 )。 - 可选值:有
'auto'、'full'、'arpack'、'randomized'这几个选项。 - 各值特点:
'auto':算法自动根据数据情况选择合适的 SVD 求解器,是常用且方便的选择,一般数据集都适用。'full':传统意义上的 SVD ,使用scipy等库的完整 SVD 实现,在数据量不大、维度不特别高时稳定可靠,但数据量大时可能计算慢。'arpack':借助 ARPACK 库实现的 SVD ,适用于计算部分奇异值(比如数据是稀疏矩阵等情况 ),在特定场景下更高效。'randomized':使用随机算法加速 SVD ,适合数据量大、数据维度多同时主成分数目比例较低的 PCA 降维,能大幅减少计算时间和资源消耗,不过理论精度可能稍低,但实际很多场景下足够用。
- 作用:指定奇异值分解(
tol:- 作用:主要在一些迭代求解 SVD 等过程中使用(比如
svd_solver='arpack'时 ),用于设置收敛 tolerance(容差 ),控制迭代精度,默认0.0,一般不用特意修改,算法会按默认策略处理收敛判断。
- 作用:主要在一些迭代求解 SVD 等过程中使用(比如
iterated_power:- 作用:当
svd_solver='randomized'时,用于设置随机 SVD 中迭代的次数,默认'auto',算法会自动根据情况选择合适的迭代次数来平衡计算效率和精度。
- 作用:当
random_state:- 作用:用于设置随机数生成器的种子,保证结果可复现。
- 场景:当使用像
svd_solver='randomized'等涉及随机过程的求解器时,设置固定random_state(比如random_state=42),每次运行 PCA 得到的结果就会一致,方便调试、对比实验等。
Attributes 属性
-
components_: 类型为array,形状是(n_components, n_features),表示主成分系数矩阵。 -
explained_variance_: 降维后的各主成分的方差值。方差值越大,说明对应的主成分越重要。 -
explained_variance_ratio_: 降维后的各主成分的方差值占总方差值的比例。这个比例越大,主成分越重要。 【一般看比例即可(比如通常关注累计比例是否 \(> 90\%\) )】
五、案例分析
这个案例使用的是银行贷款的案例,使用的算法是基于逻辑回归来完成的,除了PCA降维模块,其他代码分析详细见下面文章
机器学习第三课之逻辑回归(一)LogisticRegression
机器学习第三课之逻辑回归(二)LogisticRegression
机器学习第三课之逻辑回归(三)LogisticRegression
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metricsfrom sklearn.model_selection import cross_val_scoredata=pd.read_csv("creditcard.csv")scaler=StandardScaler()
data["Amount"]=scaler.fit_transform(data[["Amount"]])
data=data.drop(["Time"],axis=1)x=data.iloc[:, :-1]
y=data.iloc[:, -1]pca = PCA(n_components=25)
pca.fit(x)# 打印特征占比相关信息
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)# 执行降维并打印结果
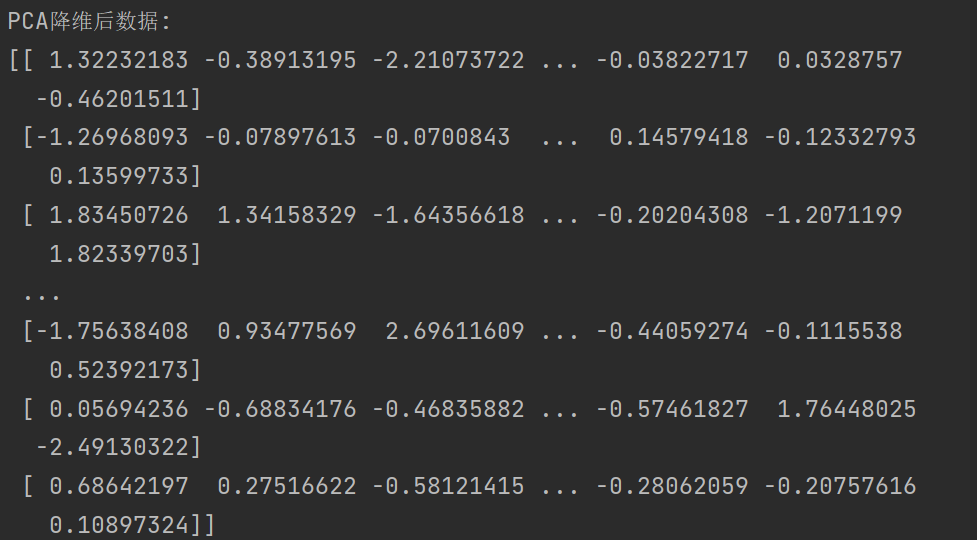
print('PCA降维后数据:')
new_x = pca.transform(x)
print(new_x)x_train_w,x_test_w,y_train_w,y_test_w=train_test_split(new_x,y,test_size=0.2,random_state=0)from imblearn.over_sampling import SMOTE
oversampler=SMOTE(random_state=0)
os_x_train,os_y_train=oversampler.fit_resample(x_train_w,y_train_w)
os_x_train_w,os_x_test_w,os_y_train_w,os_y_test_w=train_test_split(os_x_train,os_y_train,test_size=0.2,random_state=0)scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:lr = LogisticRegression(C=i, penalty="l2", solver='lbfgs', max_iter=10000)# 使用平衡后的数据集进行交叉验证score = cross_val_score(lr,os_x_train_w, os_y_train_w, cv=8, scoring="recall")score_mean = sum(score) / len(score)scores.append(score_mean)print(f"C等于{i}的召回率为{score_mean}")best_c=c_param_range[np.argmax(scores)]
print("最好的c是:",best_c)estimator=LogisticRegression(C=best_c)
estimator.fit(os_x_train_w,os_y_train_w)
test_predicted=estimator.predict(x_test_w)print(metrics.classification_report(y_test_w,test_predicted))PCA 实例化:
pca = PCA(n_components=20)-
创建了一个 PCA(主成分分析)对象,指定
n_components=20表示希望将原始特征降维到 20个主成分。
拟合数据:
pca.fit(x)使用原始特征数据x来训练 PCA 模型。这一步会计算数据的协方差矩阵,然后进行特征分解(或 SVD 分解),得到可以解释数据最大方差的主成分方向。
查看解释方差比例:
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)![]()

explained_variance_ratio_属性存储了每个主成分所解释的方差占总方差的比例- 第一行打印的是前 25 个主成分解释的方差比例之和,反映了降维后保留的信息量
- 第二行打印每个主成分单独的解释方差比例
执行降维转换:
new_x = pca.transform(x)
使用训练好的 PCA 模型对原始特征数据x进行转换,将其映射到新的 20 维主成分空间,得到降维后的特征矩阵new_x打印降维结果:
print('PCA降维后数据:')
print(new_x)输出降维后的数据集,此时数据已从原始维度(根据 creditcard.csv 实际情况,应为 29 维)降至 20维,同时尽可能保留了原始数据的信息。