上下文块嵌入(contextualized-chunk-embeddings)
了解到一种可以更好的用于上下文信息交叉的块嵌入方法(
contextualized-chunk-embeddings),这两种方法对比如下图,可以很明显的观察到它与传统的块嵌入方法区别在于,上下文块嵌入会在块嵌入后有交互,从而学得上下文语义信息,这其实是十分必要的,因为往往文档的内容都是长依赖的,具体方法我们采用Voyage来实现
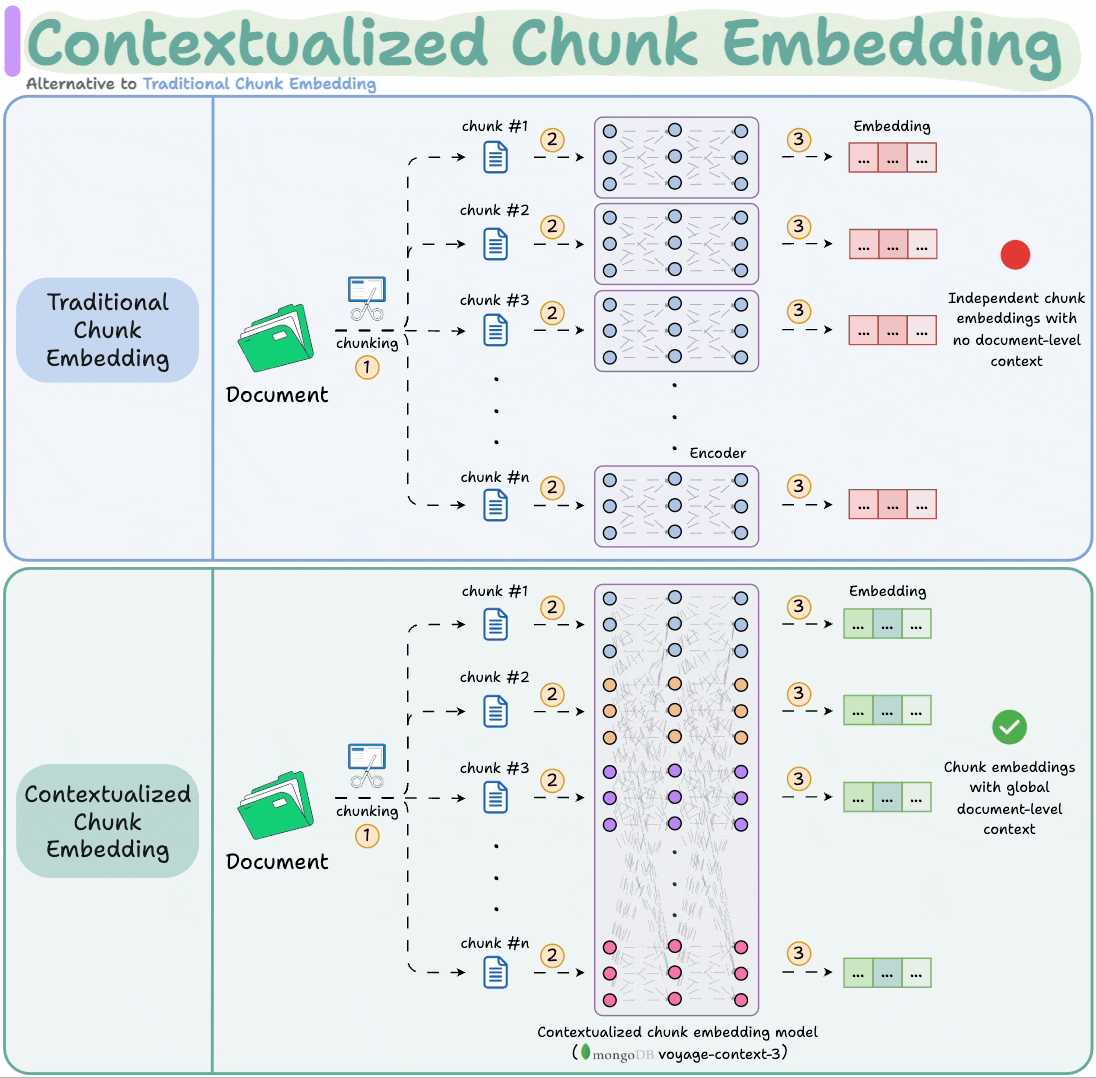
首先,让我解释一下VoyageAI contextualized chunk embeddings的优势以及如何将其集成到项目中:
VoyageAI Contextualized Chunk Embeddings 简介
VoyageAI的上下文化块嵌入模型具有以下优势(来自官网介绍):
- 上下文感知:每个块的嵌入不仅包含其自身内容的信息,还包含文档级别的上下文信息
- 更好的检索质量:通过捕获全局上下文,能够实现更准确的检索结果
- 处理长文档:支持长达32,000个token的上下文长度
使用方法
为了将VoyageAI contextualized chunk embeddings集成到项目中,我们需要进行以下步骤:
1. 创建VoyageAI服务模块
首先,我们需要创建一个VoyageAI服务模块,用于处理嵌入生成:
下面要注意
input_type参数
使用和不使用input_type参数生成的嵌入是兼容的。
当 input_type 为 None 时,嵌入模型直接将输入转换为数值向量。
出于检索/搜索目的,如果“query”用于在数据集合(称为“document”)中搜索相关信息,我们建议通过分别将input_type设置为query或document来指定您的输入是查询还是文档 。在这些情况下,Voyage 会在对输入进行矢量化之前自动在输入前面添加提示,从而创建更适合检索/搜索任务的向量。
# model_service/voyageai_service.py
import os
import voyageai
from typing import List, Optional
from langchain_text_splitters import RecursiveCharacterTextSplitter
from configuration import configclass VoyageAIEmbeddingService:def __init__(self, api_key: Optional[str] = None):self.api_key = api_key or os.getenv("VOYAGE_API_KEY")if not self.api_key:raise ValueError("VoyageAI API key is required")self.client = voyageai.Client(api_key=self.api_key)self.model_name = "voyage-context-3"def embed_documents(self, documents: List[str]) -> List[List[float]]:"""为文档创建上下文化的嵌入"""# 将文档分块并作为上下文组处理inputs = []for doc in documents:# 使用配置的分块器对文档进行分块chunks = config.splitter.split_text(doc)inputs.append(chunks)response = self.client.contextualized_embed(inputs=inputs,model=self.model_name,input_type="document")# 提取所有嵌入embeddings = []for result in response.results:embeddings.extend(result.embeddings)return embeddingsdef embed_queries(self, queries: List[str]) -> List[List[float]]:"""为查询创建嵌入"""# 查询独立处理inputs = [[query] for query in queries]response = self.client.contextualized_embed(inputs=inputs,model=self.model_name,input_type="query")# 提取查询嵌入embeddings = [result.embeddings[0] for result in response.results]return embeddings
返回的嵌入的数据类型。选项:float、int8、uint8、binary、ubinary
为方便起见,可以使用voyageai.default_chunk_fn,目前使用 LangChain 的RecursiveCharacterTextSplitter.split_text方法。我们建议避免块重叠,因此不要使用产生重叠块的函数。
2. 更新配置文件
在配置文件中添加VoyageAI相关配置:
# configuration/config.py
# 添加VoyageAI配置
VOYAGE_API_KEY = os.getenv("VOYAGE_API_KEY")
USE_VOYAGEAI = os.getenv("USE_VOYAGEAI", "false").lower() == "true"
VOYAGE_EMBEDDING_DIM = int(os.getenv("VOYAGE_EMBEDDING_DIM", "1024"))
例如模型:voyage-context-3,维度:1024(默认)、256、512、2048;上下文token数Context Length (tokens) 32000,不知道是否可以调
3. 更新嵌入生成逻辑
修改数据处理流程中的嵌入生成部分:
# craw_flow/data_ingestion.py
def generate_embeddings_flow(self, state: DataIngestionState) -> DataIngestionState:"""Generate embeddings for processed chunks"""logger.info(f"🧠 Generating embeddings for {len(state.chunks)} chunks...")# 检查是否使用VoyageAIif config.USE_VOYAGEAI:try:from model_service.voyageai_service import VoyageAIEmbeddingServicevoyage_client = VoyageAIEmbeddingService(config.VOYAGE_API_KEY)# 按文档分组chunksdocuments = {}for chunk in state.chunks:source = chunk["source"]if source not in documents:documents[source] = []documents[source].append(chunk)# 为每个文档生成上下文化的嵌入all_embeddings = []for source, chunks in documents.items():texts = [chunk["text"] for chunk in chunks]doc_text = " ".join(texts)embeddings = voyage_client.embed_documents([doc_text])all_embeddings.extend(embeddings[:len(chunks)]) # 确保数量匹配except Exception as e:logger.error(f"Error using VoyageAI, falling back to default: {e}")# 回退到默认嵌入方法all_embeddings = self._generate_default_embeddings(state.chunks)else:# 使用默认嵌入方法all_embeddings = self._generate_default_embeddings(state.chunks)# Assign embeddings to chunksupdated_chunks = []for chunk, embedding in zip(state.chunks, all_embeddings):chunk_copy = chunk.copy()chunk_copy["embedding"] = embeddingupdated_chunks.append(chunk_copy)logger.info("✅ Embeddings generation completed")return DataIngestionState(discovered_files=state.discovered_files,collection=state.collection,chunks=updated_chunks,processed_files=state.processed_files)def _generate_default_embeddings(self, chunks):"""默认嵌入生成方法"""texts = [chunk["text"] for chunk in chunks]batch_size = 100all_embeddings = []for i in range(0, len(texts), batch_size):batch_texts = texts[i:i + batch_size]response = openai_client.embeddings.create(model=config.EMBEDDING_MODEL, input=batch_texts)batch_embeddings = [data.embedding for data in response.data]all_embeddings.extend(batch_embeddings)return all_embeddings
4. 查询嵌入生成逻辑
# knowleage_warehouse/search.py
def search_vector_database(query: str, limit: int = 10, min_relevance_threshold: float = 0.3) -> List[Dict[str, Any]]:"""Search vector database for relevant information"""try:collection = get_collection()# Generate query embeddingif config.USE_VOYAGEAI:try:from model_service.voyageai_service import VoyageAIEmbeddingServicevoyage_client = VoyageAIEmbeddingService(config.VOYAGE_API_KEY)query_embedding = voyage_client.embed_queries([query])[0]except Exception as e:logger.error(f"Error using VoyageAI for query embedding, falling back to default: {e}")response = openai_client.embeddings.create(model=config.EMBEDDING_MODEL, input=[query])query_embedding = response.data[0].embeddingelse:response = openai_client.embeddings.create(model=config.EMBEDDING_MODEL, input=[query])query_embedding = response.data[0].embedding# Searchsearch_params = {"metric_type": "L2", "params": {"nprobe": 10}}results = collection.search(data=[query_embedding],anns_field="embedding",param=search_params,limit=limit,output_fields=["text", "source", "content_type"])# Format resultssearch_results = []for hits in results:for hit in hits:if hit.score >= min_relevance_threshold:search_results.append({"text": hit.entity.get("text"),"source": hit.entity.get("source"),"content_type": hit.entity.get("content_type"),"score": hit.score})return search_resultsexcept Exception as e:logger.error(f"Error searching vector database: {e}")return []