Video-R1论文解读
目录
一、Video-R1
1、概述
2、方法
3、训练过程
4、实验
一、Video-R1
1、概述
这个论文同样是将GRPO引入多模态大语言模型的方法,只不过Video-R1考虑的是视频的时序信息上的问题。
动机:GRPO在视频时序问题上没有前人处理,所以仅依赖单帧的视觉特征会出现“短路推理”,导致推理中失去时序性。另外现有的视频数据集缺乏长链推理的复杂样本,多聚焦在识别任务上,限制模型泛化性。
所以Video-R1,一是提出了一个新的T-GRPO算法可以处理激励模型学习时序依赖,二是构建了一个Video-R1-260k和Video-R1-CoT-165k数据集用于SFT和RL是更加专注时序推理。
2、方法
Kimi k1.5和Skywork R1V都应用了强化学习在图像多模态大模型中,提高了理解能力,VIdeo-UTR模型将GRPO引入视频多模态大模型中发现,对视频的理解只会局限于每一帧的理解的简单拼接,并不会学会时序理解,所以他并不懂视频前后物体移动的关系。比如下图所示,GRPO不会理解视频中有没有青色方块进入。

Video-R1数据集

Video-R1数据集分为两类,先介绍Video-R1-260K,其中图像数据占比较多,图像数据可以实现多任务,包括图表,OCR,数学,知识推理,空间推理等,当然传统图像VQA只占6%。视频数据来自于LLaVA-Video,Next-QA,PerceptionTest,CLEVERER,STAR等
Video-R1-CoT-165K是Video-R1-260K经过Qwen2.5-VL-72B生成CoT标注后过滤得到,用于模型冷启动。
当然对于不同数据采用不同的奖励办法,数据也有多选,数值QA,OCR,自由格式QA,回归五种,这个奖励可以参见下面链接的介绍:
3D-R1、Scene-R1、SpaceR论文解读-CSDN博客
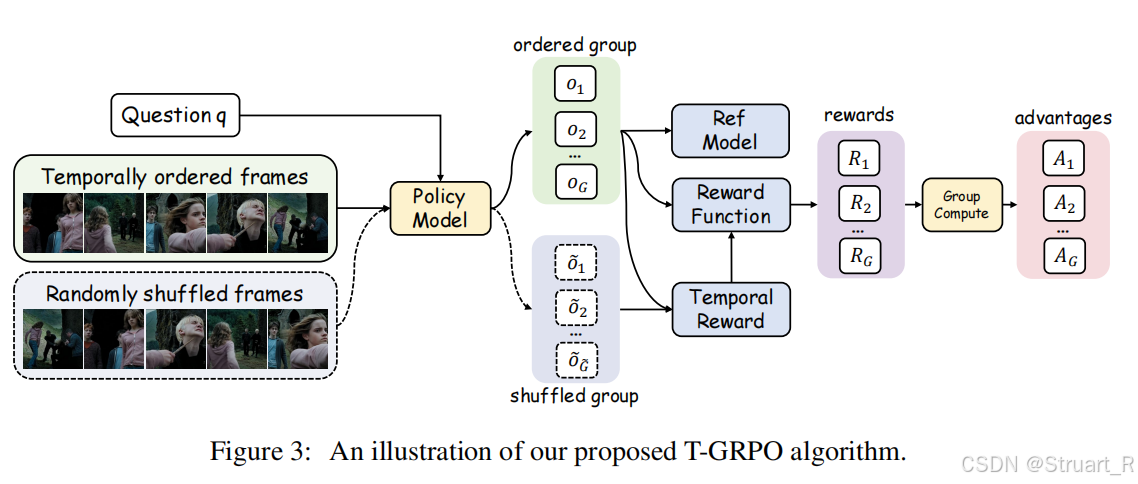
T-GRPO算法
时序对比奖励机制,这个很神奇。
首先以往的视频数据输入不是有序的视频帧输入吗,这里我们同时采用有序帧和乱序帧两组均作为输入,此时就会得到两组输出响应集合,其中
。
之后计算时序奖励,要求是当有序帧组正确率p优于乱序帧组正确率
时才能获得额外奖励,强制模型利用时序信息学到推理内容。(其中α=0.3)
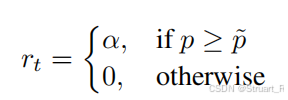
另外计算基础奖励,也就是以往的格式奖励+答案正确性,定义为。
最终奖励为若推理正确,我们引入时序奖励,如果推理错误,那么不引入。只一点与SpaceR的地图规划奖励异曲同工。
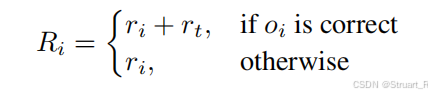
后面同样利用GRPO算法进行优化目标函数,这里不在介绍。T-GRPO训练流程如下:
3、训练过程
主干网络仍然是Qwen2.5-VL-7B-Instruct,训练由两部分组成,先是SFT冷启动,采用CoT-165K的数据集,然后是RL强化训练采用260K的数据。数据均为图像-视频混合数据。
另外在这两个阶段基础上,为了实现更长的上下文输出,所以引入了长上下文奖励,其实就是文本在[320,512]文字量之间,同时推理正确,那么我们加一个,否则不考虑该奖励。这个在以往的方法上,在SpaceR也有涉及。(SpaceR还是后出的,但是就差了一周)

4、实验
结果还是不错的,这个相当于VLA与视频多模态的结合。之前的SpaceR是VLA与3D多模态的结合。

视频通用测试和视频理解指标,这里也能看到强化学习的提升。而且输入帧数越多,模型效果也有提升。
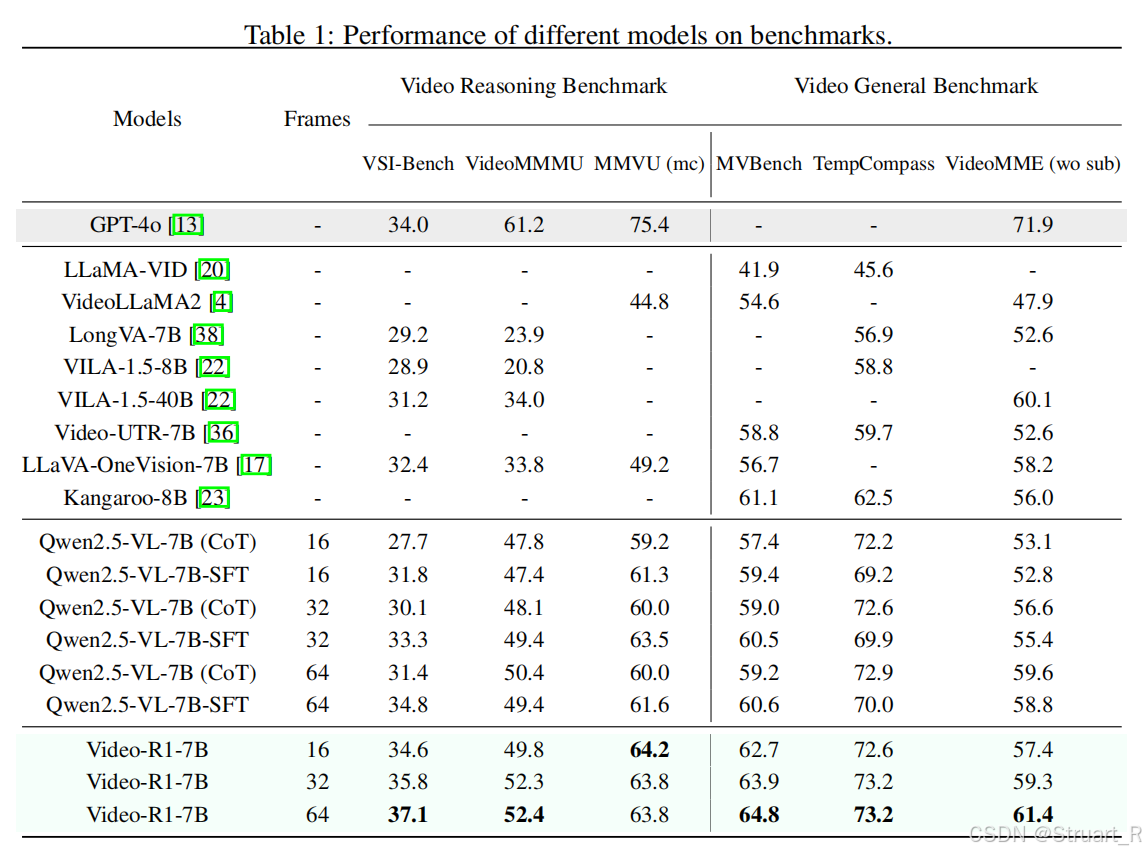
图像数据对Video-R1也很重要,因为图像数据可以聚焦每一张图像的识别,定位等问题,视频数据更注重时序性。
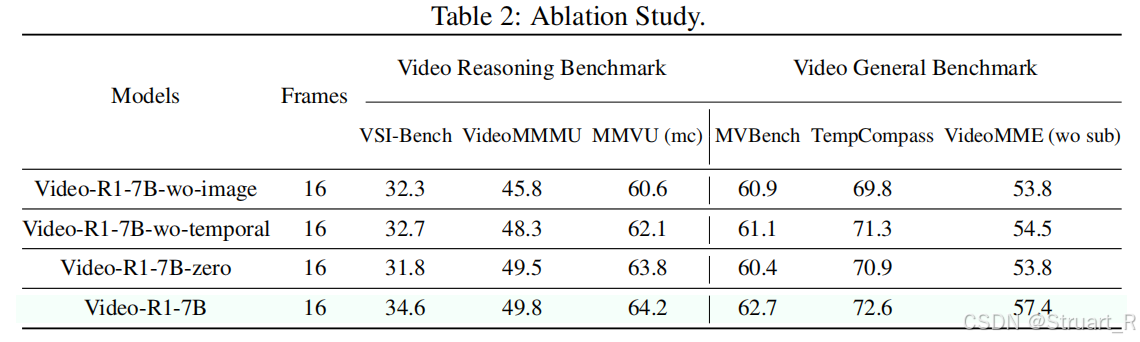
在训练过程中,强化学习也可以逐渐提升模型的准确性和时序性。 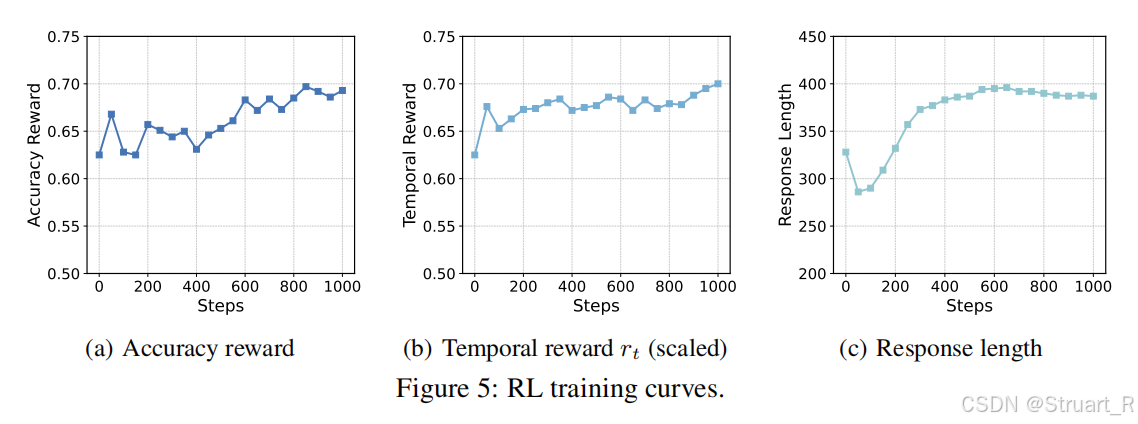
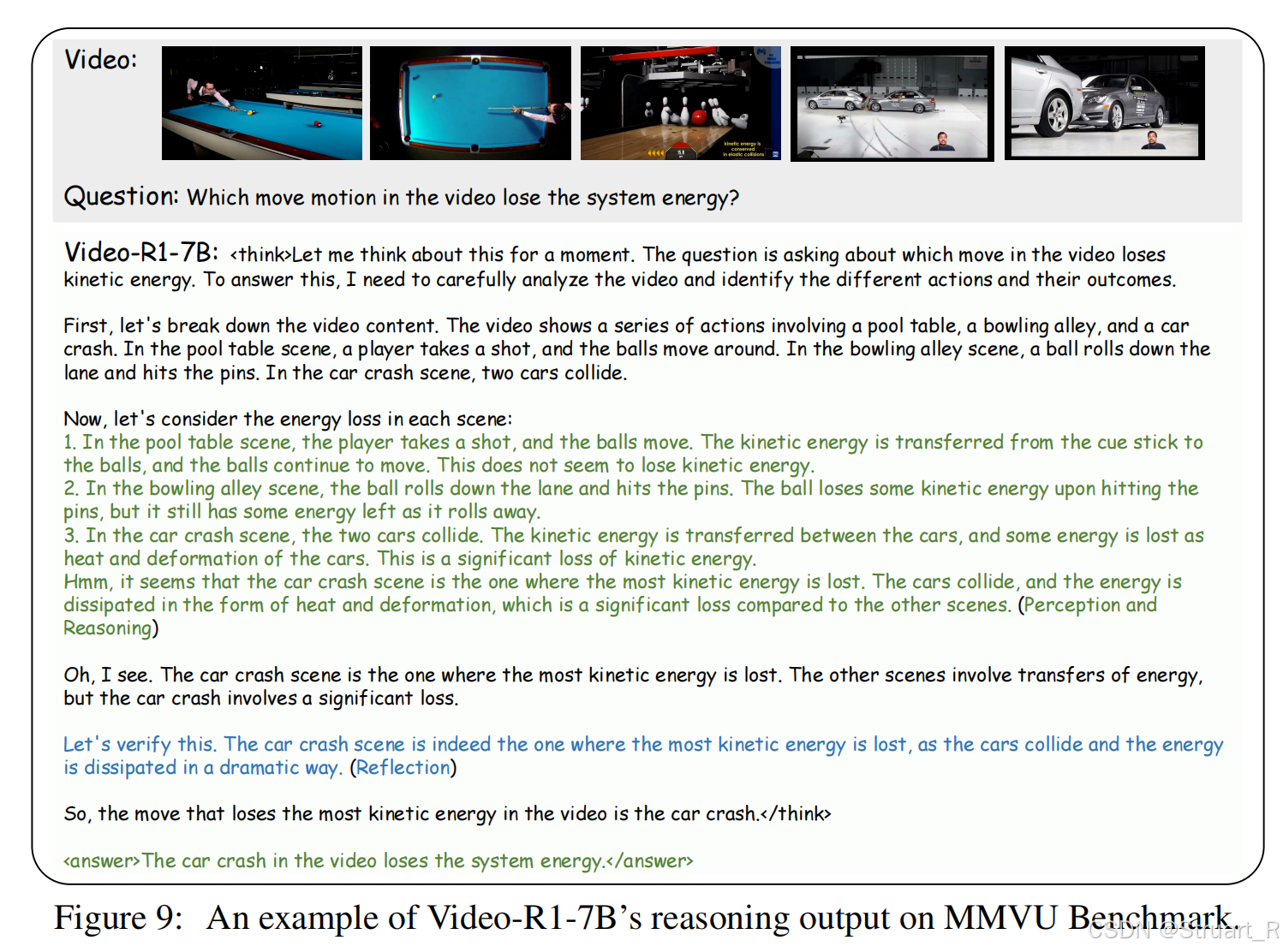
appendix的几个例子蛮好玩的。首先是MMVU数据集这个打台球、打保龄球和车辆碰撞的例子,问你那个例子是损失了能量,就是非动能守恒的。Video-R1先给出了场面描述,然后结合了下他了解到的物理规律,给出了最后一个车祸现场由于碰撞动能转换到热能损失了能量。
MVBench的例子,老友记中罗斯为什么在回答瑞秋之前就离开了,有趣的感情剧,然后CoT给出了每一个选项的理解,认为只有D因为他在情感上没有等到回应所以有点伤心离开了,所以选了D。

参考论文:[2503.21776] Video-R1: Reinforcing Video Reasoning in MLLMs