【完整源码+数据集+部署教程】肾脏病变实例分割系统源码和数据集:改进yolo11-CARAFE
背景意义
研究背景与意义
肾脏病变的早期诊断与精确分割在医学影像学中具有重要的临床意义。随着影像技术的进步,尤其是计算机视觉和深度学习的快速发展,利用先进的算法对肾脏病变进行自动化检测和分割已成为研究的热点。传统的影像分析方法往往依赖于人工标注和经验判断,存在主观性强、效率低下等问题。因此,基于深度学习的实例分割技术应运而生,能够有效提高肾脏病变的检测精度和效率。
本研究旨在构建一个基于改进YOLOv11的肾脏病变实例分割系统。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广泛应用于各类计算机视觉任务。通过对YOLOv11的改进,我们期望能够在保持高效性的同时,进一步提升对肾脏病变的分割精度。该系统将利用一个包含1100幅图像的多类别数据集,涵盖五种不同类型的肾脏病变。这些图像经过精细标注,能够为模型的训练提供丰富的样本支持。
在医学影像分析领域,实例分割不仅有助于识别病变区域的形状和大小,还能为后续的定量分析提供基础数据。这对于制定个性化的治疗方案、评估治疗效果以及进行疾病预后分析具有重要的临床价值。此外,随着数据集的不断扩展和模型的持续优化,基于深度学习的肾脏病变分割系统将有望在未来的临床实践中发挥更大的作用,为肾脏疾病的早期筛查和干预提供有力支持。通过本研究,我们希望能够推动肾脏病变自动化检测技术的发展,提升医疗服务的质量与效率。
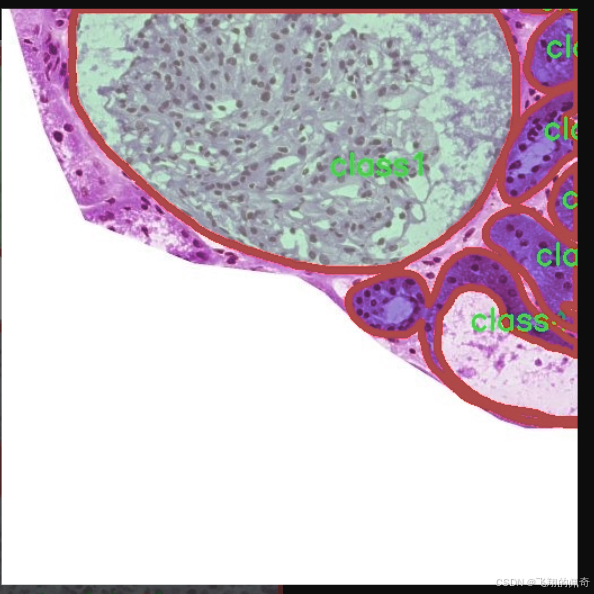
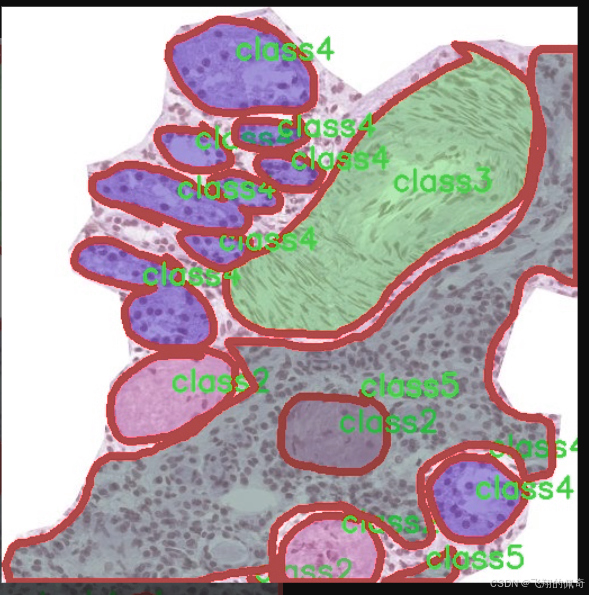
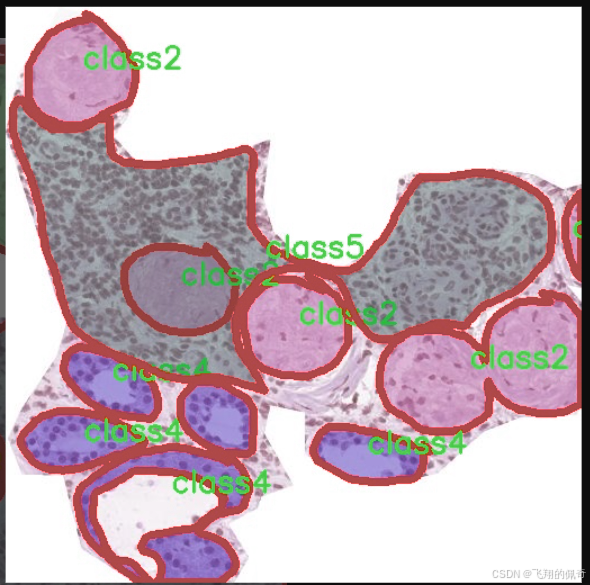
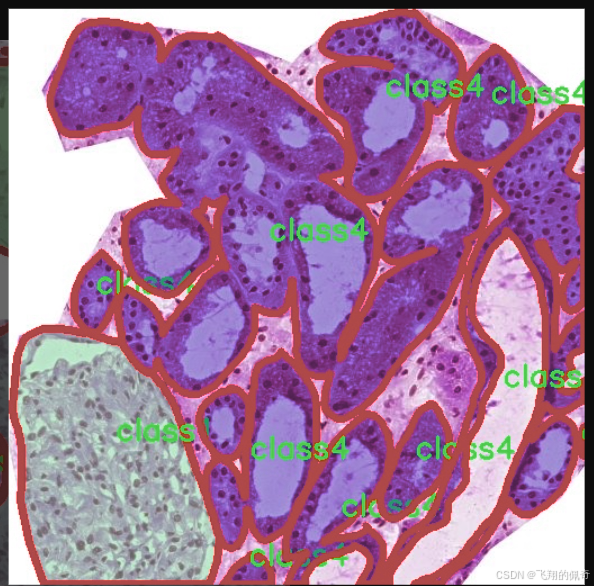
图片效果
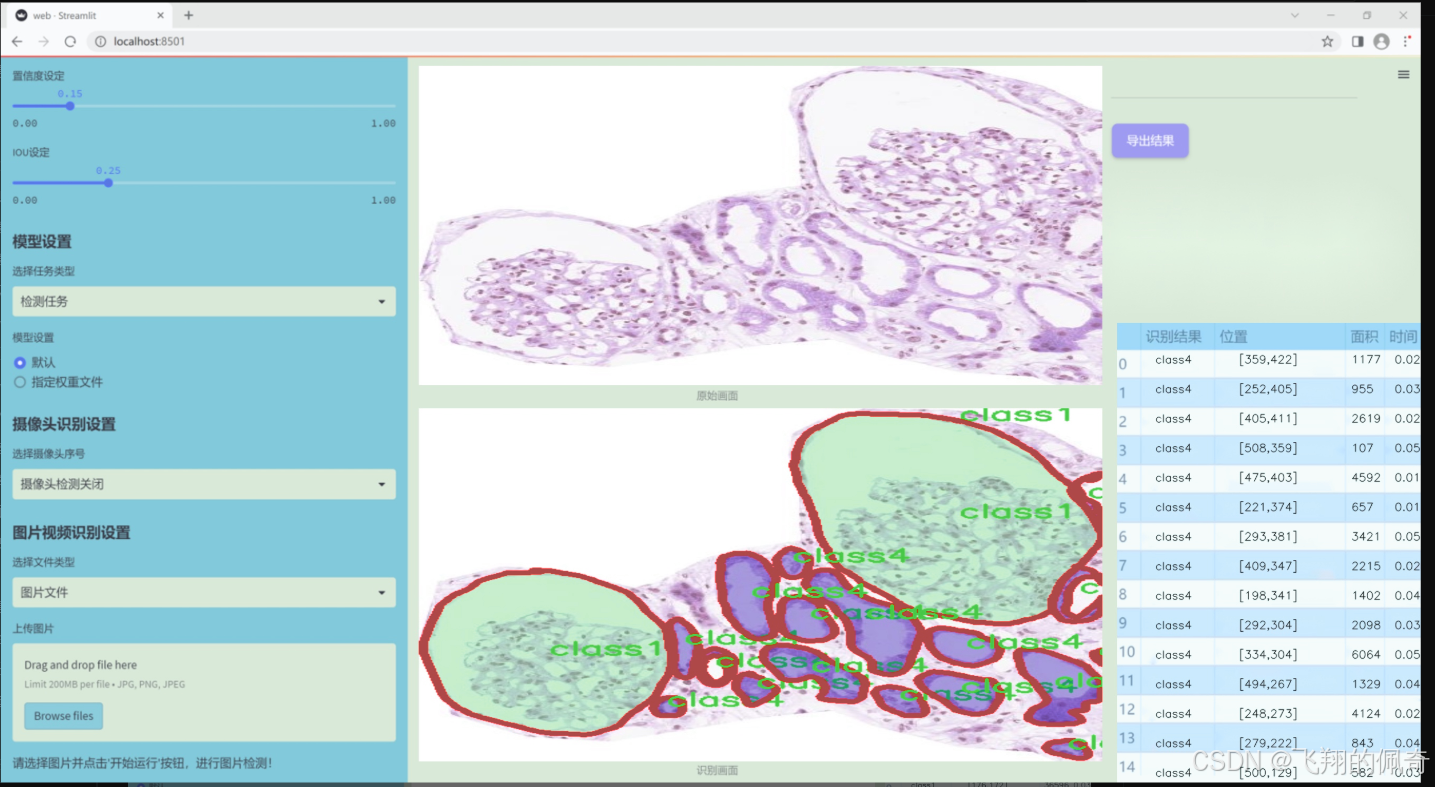
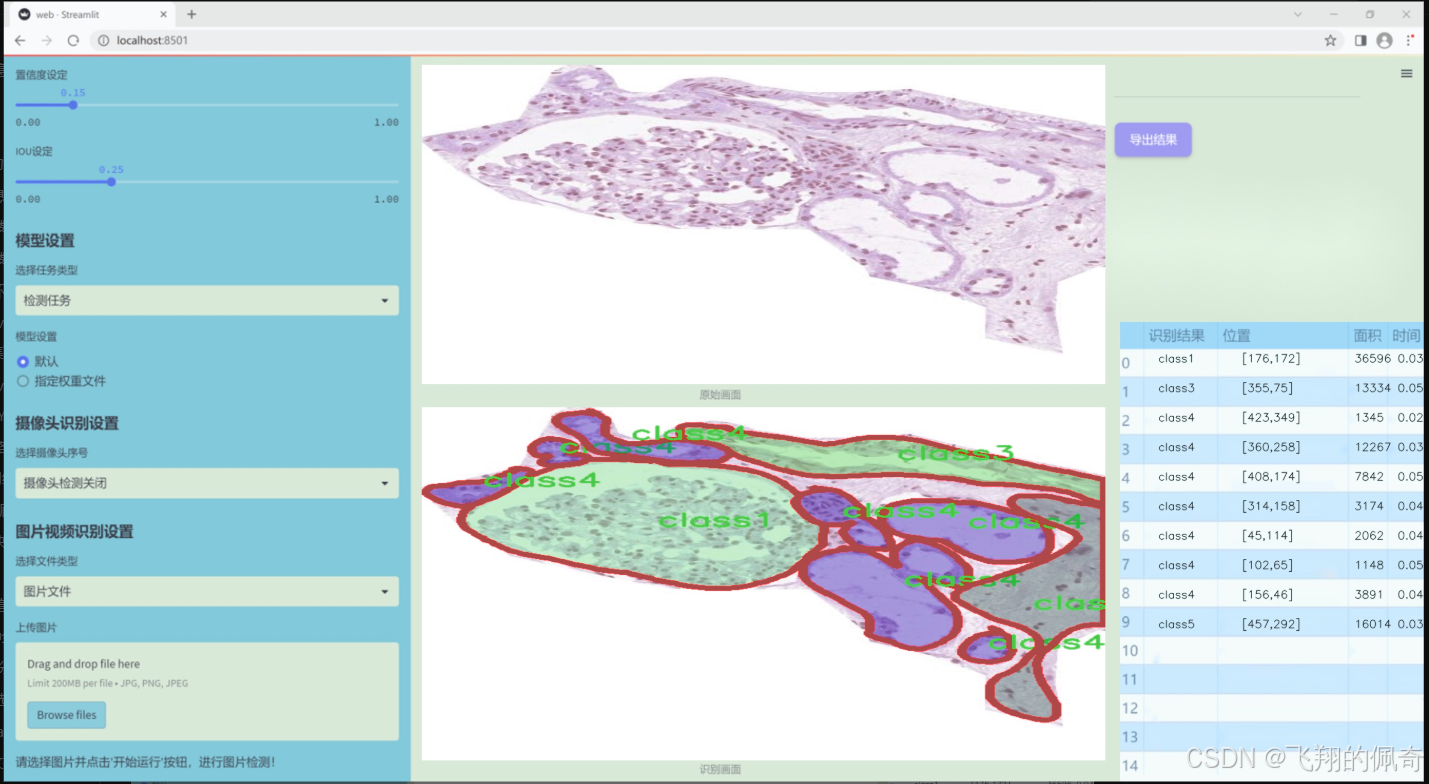
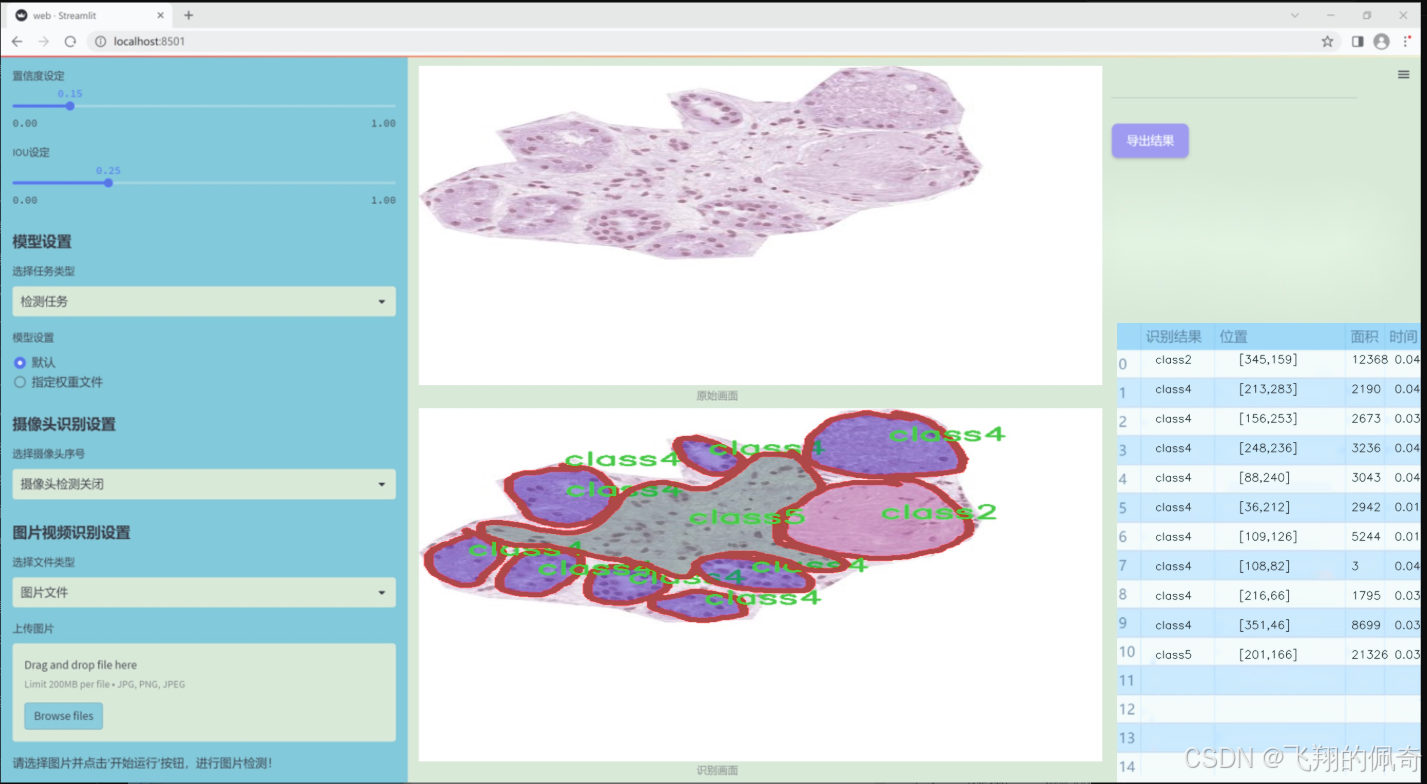
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“kidny_fold3”,旨在为改进YOLOv11的肾脏病变实例分割系统提供强有力的支持。该数据集专注于肾脏病变的检测与分析,涵盖了多种类型的病变,能够有效提升模型在肾脏疾病诊断中的准确性和鲁棒性。数据集中包含五个主要类别,分别为“class1”、“class2”、“class3”、“class4”和“class5”,这些类别代表了不同类型的肾脏病变特征。
在数据集的构建过程中,特别注重样本的多样性和代表性,以确保模型能够适应不同患者的病理特征。每个类别的样本均经过精心标注,确保标注的准确性和一致性。这种细致的标注工作为后续的模型训练提供了坚实的基础,使得YOLOv11能够在实例分割任务中实现更高的精度。
此外,数据集的规模和质量也经过严格把控,包含了大量的图像数据,这些图像不仅涵盖了不同的肾脏病变类型,还考虑了不同的成像条件和角度。这种多样化的图像数据使得模型在训练过程中能够学习到更丰富的特征,从而在实际应用中更好地应对各种复杂情况。
通过使用“kidny_fold3”数据集,本项目旨在推动肾脏病变检测技术的发展,提高临床诊断的效率和准确性,为肾脏疾病患者提供更为精准的医疗服务。数据集的设计与应用不仅为YOLOv11的改进提供了有力支持,也为未来相关研究奠定了基础。
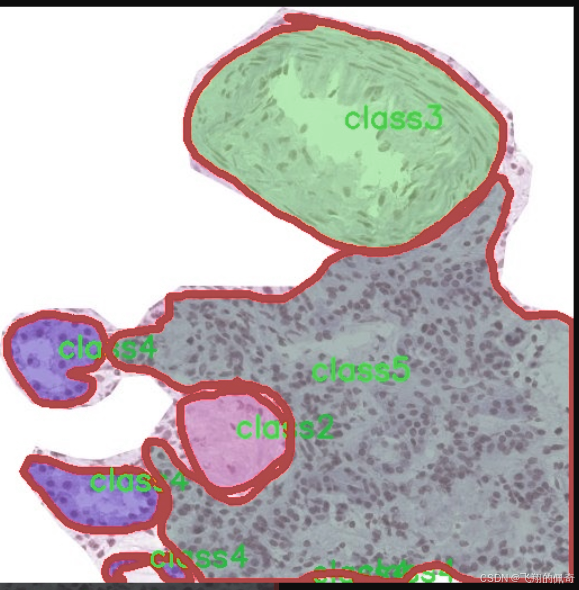
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MF_Attention(nn.Module):
“”"
自注意力机制的实现,源自Transformer模型。
“”"
def init(self, dim, head_dim=32, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False):
super().init()
# 头的维度self.head_dim = head_dim# 缩放因子self.scale = head_dim ** -0.5# 计算头的数量self.num_heads = num_heads if num_heads else dim // head_dimif self.num_heads == 0:self.num_heads = 1# 注意力的维度self.attention_dim = self.num_heads * self.head_dim# 定义Q、K、V的线性变换self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)# 注意力的dropoutself.attn_drop = nn.Dropout(attn_drop)# 输出的线性变换self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)# 输出的dropoutself.proj_drop = nn.Dropout(proj_drop)def forward(self, x):# 获取输入的形状B, H, W, C = x.shapeN = H * W # 计算总的token数量# 计算Q、K、Vqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # 分离Q、K、V# 计算注意力分数attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1) # 归一化attn = self.attn_drop(attn) # 应用dropout# 计算输出x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)x = self.proj(x) # 投影到原始维度x = self.proj_drop(x) # 应用dropoutreturn x
class MetaFormerBlock(nn.Module):
“”"
MetaFormer块的实现,包含自注意力和MLP模块。
“”"
def init(self, dim,
token_mixer=nn.Identity, mlp=Mlp,
norm_layer=partial(LayerNormWithoutBias, eps=1e-6),
drop=0., drop_path=0.,
layer_scale_init_value=None, res_scale_init_value=None):
super().init()
# 归一化层self.norm1 = norm_layer(dim)# 令牌混合器self.token_mixer = token_mixer(dim=dim, drop=drop)# DropPath层self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()# 层缩放self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()# 第二个归一化层self.norm2 = norm_layer(dim)# MLP模块self.mlp = mlp(dim=dim, drop=drop)self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()def forward(self, x):# 交换维度以适应后续操作x = x.permute(0, 2, 3, 1)# 第一部分:归一化 -> 混合 -> 残差连接x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))# 第二部分:归一化 -> MLP -> 残差连接x = self.res_scale2(x) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x))))return x.permute(0, 3, 1, 2) # 恢复原始维度
代码核心部分说明:
MF_Attention: 实现了自注意力机制,包含了Q、K、V的计算和注意力分数的归一化,最后通过线性变换将输出映射回原始维度。
MetaFormerBlock: 组合了自注意力和MLP模块,使用了归一化、残差连接和DropPath技术,增强了模型的表达能力和稳定性。
这个程序文件 metaformer.py 实现了一种名为 MetaFormer 的深度学习模型的组件,主要用于计算机视觉任务。代码中定义了多个类,每个类实现了不同的功能模块,这些模块可以组合在一起形成完整的网络结构。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,这些是 PyTorch 框架的核心组件。接着,定义了一些基础的模块,比如 Scale、SquaredReLU 和 StarReLU。Scale 类用于对输入进行元素级别的缩放,SquaredReLU 和 StarReLU 则是自定义的激活函数,前者是对 ReLU 激活函数的平方变换,后者则结合了缩放和偏置。
接下来是 MF_Attention 类,它实现了基本的自注意力机制,类似于 Transformer 中的自注意力。该类通过线性变换生成查询、键和值,并计算注意力权重,最后通过线性投影将结果映射回原始维度。
RandomMixing 类实现了一种随机混合机制,通过一个随机矩阵对输入进行线性变换,增强模型的多样性。LayerNormGeneral 和 LayerNormWithoutBias 类实现了不同形式的层归一化,前者支持多种输入形状和可选的缩放与偏置,后者则是一个优化过的版本,去掉了偏置以提高效率。
SepConv 类实现了分离卷积,使用了深度可分离卷积的思想,先通过逐点卷积增加通道数,再通过深度卷积处理空间信息,最后再通过逐点卷积恢复通道数。
Pooling 类实现了一种特殊的池化操作,旨在从输入中提取特征并与原始输入进行比较。Mlp 类实现了多层感知机(MLP),用于在 MetaFormer 模型中进行特征变换。
ConvolutionalGLU 类实现了一种卷积门控线性单元(GLU),结合了卷积和门控机制,增强了模型的表达能力。
最后,MetaFormerBlock 和 MetaFormerCGLUBlock 类分别实现了 MetaFormer 的基本块,前者使用普通的 MLP,后者则使用卷积 GLU。每个块都包含了归一化、特征混合、残差连接和可选的 DropPath 操作,形成了一个完整的前向传播过程。
整体来看,这个文件实现了 MetaFormer 模型的多个关键组件,提供了灵活的模块化设计,便于在不同的任务中进行组合和扩展。
10.4 afpn.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv
定义基本的卷积块
class BasicBlock(nn.Module):
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 两个卷积层,第二个卷积层不使用激活函数
self.conv1 = Conv(filter_in, filter_out, 3)
self.conv2 = Conv(filter_out, filter_out, 3, act=False)
def forward(self, x):residual = x # 保存输入用于残差连接out = self.conv1(x) # 第一个卷积out = self.conv2(out) # 第二个卷积out += residual # 残差连接return self.conv1.act(out) # 返回激活后的输出
定义上采样模块
class Upsample(nn.Module):
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
# 包含一个1x1卷积和双线性插值上采样
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1),
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’)
)
def forward(self, x):return self.upsample(x) # 执行上采样
定义下采样模块
class Downsample_x2(nn.Module):
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
# 使用2x2卷积进行下采样
self.downsample = Conv(in_channels, out_channels, 2, 2, 0)
def forward(self, x):return self.downsample(x) # 执行下采样
自适应特征融合模块(ASFF)
class ASFF_2(nn.Module):
def init(self, inter_dim=512):
super(ASFF_2, self).init()
compress_c = 8 # 压缩通道数
# 定义用于计算权重的卷积层
self.weight_level_1 = Conv(inter_dim, compress_c, 1)
self.weight_level_2 = Conv(inter_dim, compress_c, 1)
self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)
self.conv = Conv(inter_dim, inter_dim, 3) # 最后的卷积层
def forward(self, input1, input2):# 计算每个输入的权重level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1) # 连接权重levels_weight = self.weight_levels(levels_weight_v) # 计算最终权重levels_weight = F.softmax(levels_weight, dim=1) # 使用softmax归一化权重# 融合输入特征fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced) # 通过卷积层return out
主体网络结构
class BlockBody_P345(nn.Module):
def init(self, channels=[64, 128, 256, 512]):
super(BlockBody_P345, self).init()
# 定义不同尺度的卷积块和下采样、上采样模块
self.blocks_scalezero1 = nn.Sequential(Conv(channels[0], channels[0], 1))
self.blocks_scaleone1 = nn.Sequential(Conv(channels[1], channels[1], 1))
self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])
self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)
self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])
# 其他尺度的定义省略...def forward(self, x):x0, x1, x2 = x # 输入的三个特征图x0 = self.blocks_scalezero1(x0) # 处理第一个尺度x1 = self.blocks_scaleone1(x1) # 处理第二个尺度# 使用自适应特征融合scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))# 处理后续尺度...return x0, x1, x2 # 返回处理后的特征图
AFPN网络结构
class AFPN_P345(nn.Module):
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 初始化卷积层
self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)
self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)
self.body = BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor]) # 主体网络
# 输出卷积层self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)def forward(self, x):x0, x1, x2 = xx0 = self.conv0(x0) # 处理输入x1 = self.conv1(x1)out0, out1, out2 = self.body([x0, x1, x2]) # 通过主体网络out0 = self.conv00(out0) # 输出处理return [out0, out1, out2] # 返回输出
代码说明:
BasicBlock: 定义了一个基本的卷积块,包含两个卷积层和残差连接。
Upsample/Downsample: 定义了上采样和下采样模块,分别使用卷积和插值方法。
ASFF: 自适应特征融合模块,能够根据输入特征图的权重进行加权融合。
BlockBody_P345: 该类定义了网络的主体结构,使用多个卷积块和自适应特征融合模块。
AFPN_P345: 该类实现了特征金字塔网络的整体结构,包含输入处理和输出生成。
通过这些模块的组合,可以构建一个复杂的神经网络,用于图像处理任务。
这个程序文件 afpn.py 实现了一个用于图像处理的神经网络结构,主要是自适应特征金字塔网络(AFPN)。该网络通过不同尺度的特征融合来提高目标检测或分割任务的性能。文件中定义了多个类,构成了整个网络的基础。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些自定义的模块如 Conv 和不同的块(如 C2f, C3, C3Ghost, C3k2)。这些模块通常用于构建卷积层和其他网络结构。
接下来,定义了几个基础模块,包括 BasicBlock、Upsample、Downsample_x2、Downsample_x4 和 Downsample_x8。这些模块分别实现了基本的卷积操作、上采样和下采样。BasicBlock 采用了残差连接,允许信息在网络中更有效地传播。
然后,定义了多个自适应特征融合模块(ASFF),如 ASFF_2、ASFF_3 和 ASFF_4。这些模块的作用是根据输入特征图的权重动态融合不同尺度的特征,以增强网络对多尺度信息的捕捉能力。每个 ASFF 模块都通过卷积层计算权重,并利用 softmax 函数进行归一化,确保融合后的特征图在不同尺度间的有效性。
BlockBody_P345 和 BlockBody_P2345 类实现了网络的主体结构,分别处理三层和四层特征图。它们通过组合不同的卷积块和 ASFF 模块来构建深层网络。每个块中都包含了多次卷积操作和特征融合,以逐步提取和整合特征。
AFPN_P345 和 AFPN_P2345 类则是网络的顶层结构,负责接收输入特征图并将其传递到主体结构中。这些类还包括了卷积层,用于调整特征图的通道数,并在前向传播中返回处理后的特征图。
最后,AFPN_P345_Custom 和 AFPN_P2345_Custom 类允许用户自定义块类型,提供了更大的灵活性,以便根据具体任务的需求调整网络结构。
整体而言,这个文件实现了一个复杂的深度学习模型,利用多尺度特征融合技术来提高图像处理任务的效果。每个模块的设计都考虑到了特征的有效提取和信息的高效传递,适合用于目标检测、图像分割等计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻