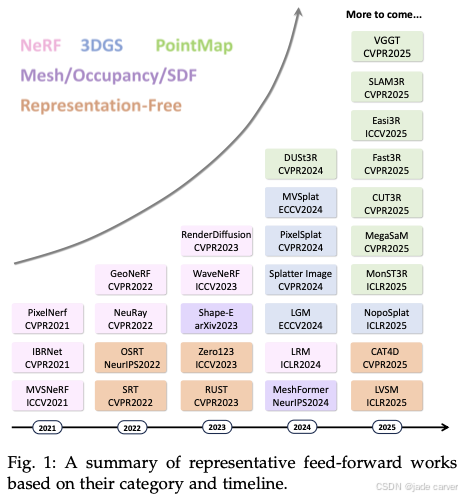
feed-forward系列工作集合与跟进(vggt以后)
自vggt获得cvpr 2025 best paper以后,feed-forward系列工作暂停了一小阶段之后,目前又进入了一个大爆发期,而我们不难看出,自dust3r到vggt基本奠定了feed-forward系列的pipeline,比如对于MVS类的工作,其框架基底是:输入图像,经过transformer以后,输出大家关心的pose、pointmap、confidence、depth等信息;对于3r框架接续3DGS的工作,其框架基底是:输入图像,经过transformer以后,输出N个高斯球对应的属性。目前看来,新推出的方法是基于此之上做了一部分的改变达到提升效果的目的,本文开始收集汇总vggt以后的feed-forward系列工作,方便日后参阅。
一、MVS
1.1 pi3-利用置换等变方法去除3r系列的归纳偏置(开源)
arxiv时间:Thu, 17 Jul 2025 17:59:53 UTC
项目主页:Pi3![]() https://yyfz.github.io/pi3/
https://yyfz.github.io/pi3/
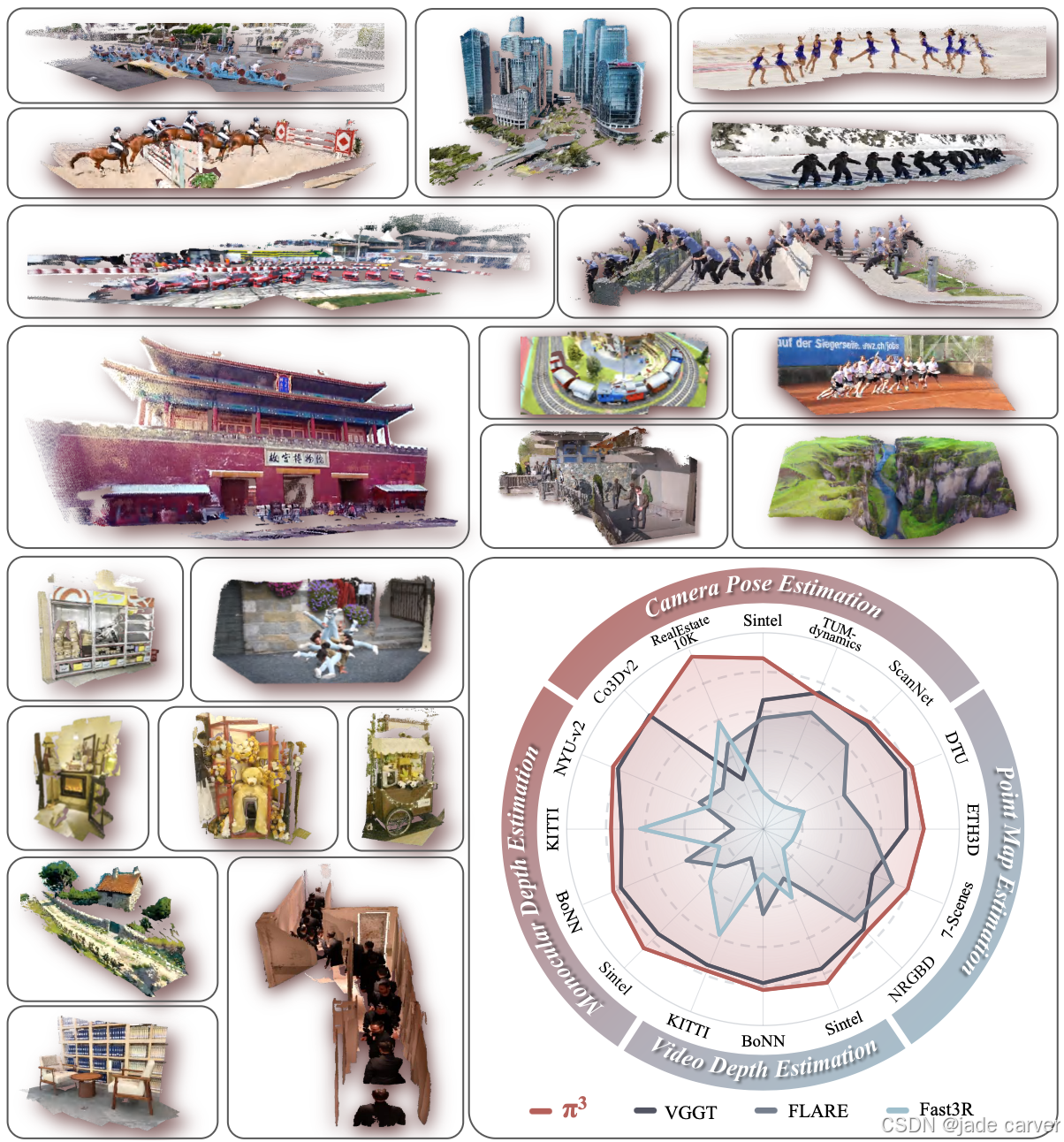
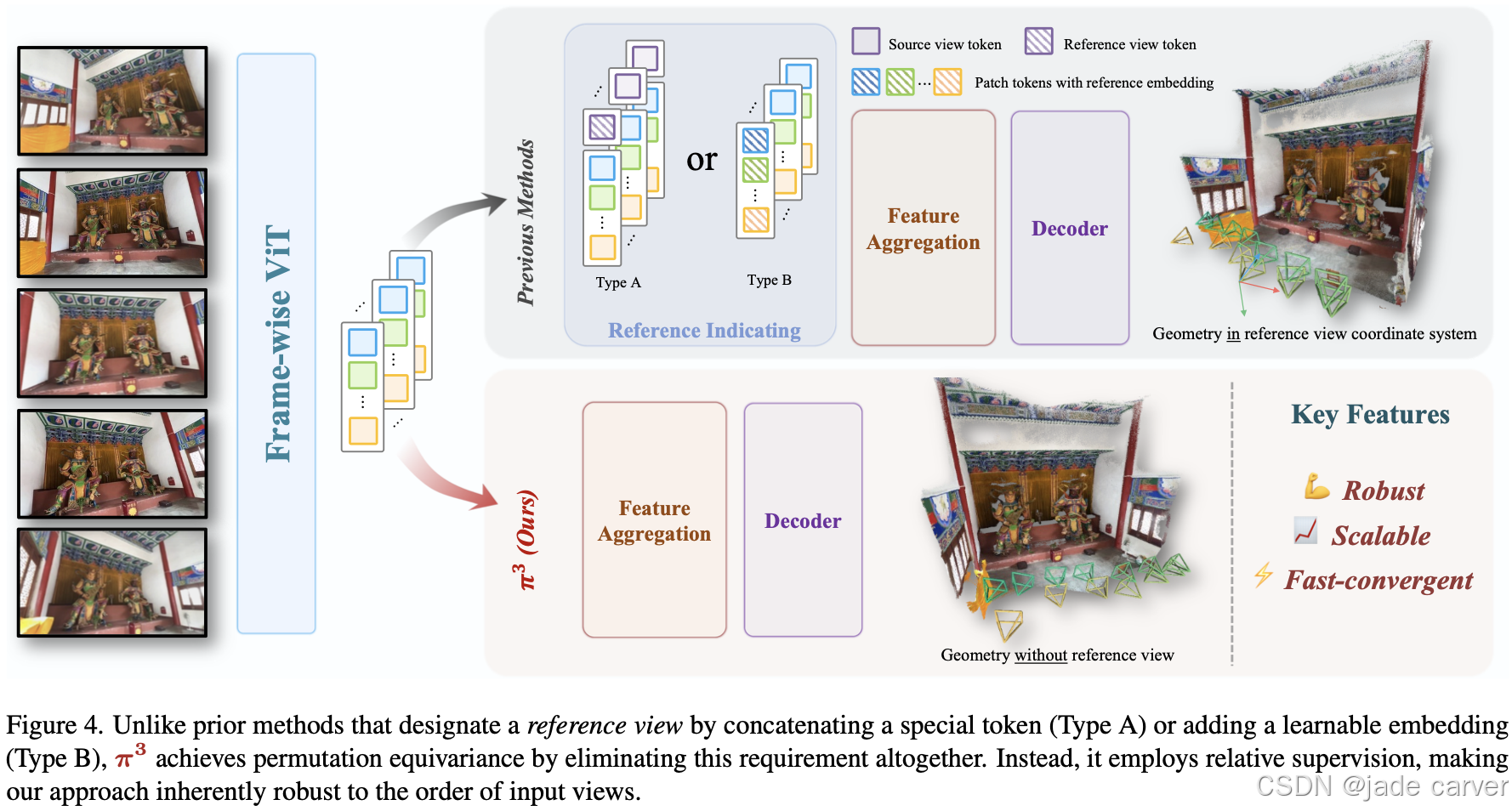
【超越VGGT】π3-利用置换等变方法去除3r系列的归纳偏置_超越 vggt-CSDN博客
1.2 Dens3R: A Foundation Model for 3D Geometry Prediction(未开源)(表面、深度、分割)
时间:Tue, 22 Jul 2025 07:22:30 UTC
主页:Dens3R: A Foundation Model for 3D Geometry PredictionDens3R: A Foundation Model for 3D Geometry Prediction![]() https://g-1nonly.github.io/Dens3R/
https://g-1nonly.github.io/Dens3R/

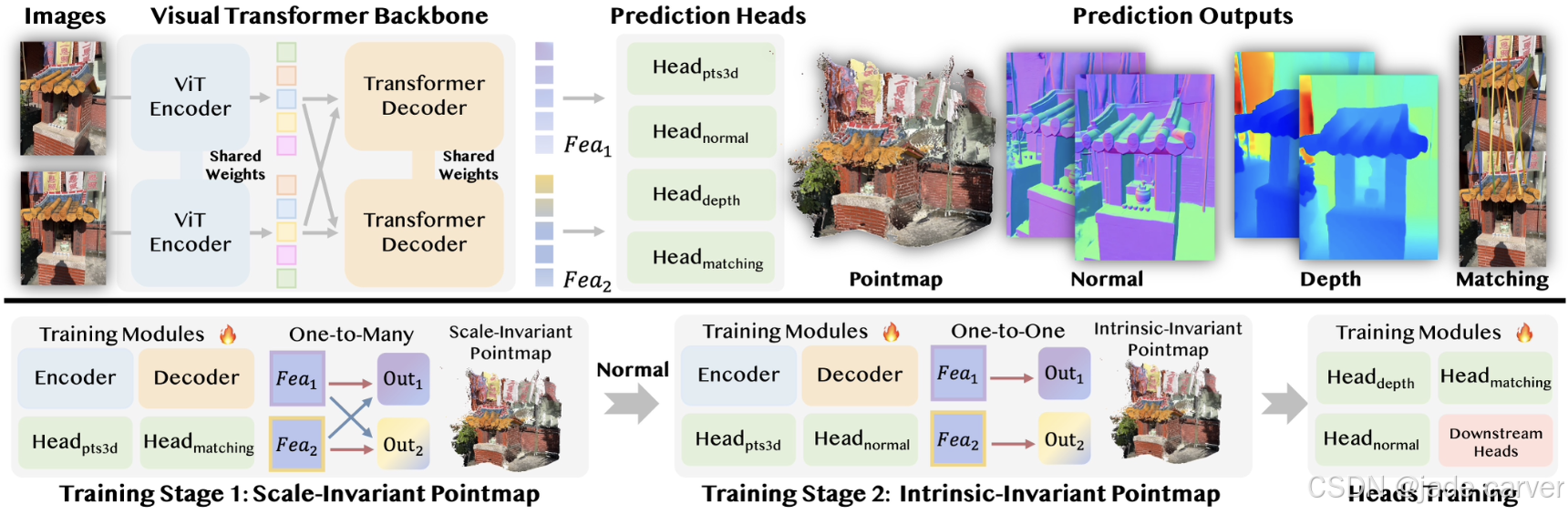
我们提出 Dens3R —— 一种密集视觉Transformer骨干网络,采用共享编码器-解码器架构并配备多个任务专用预测头用于几何推理。该基础模型的训练采用两阶段策略:
阶段一:通过强制多视角间的映射一致性,学习具有尺度不变性的点云图(pointmap);
阶段二:引入表面法线并利用一对一对应关系约束,将表征转化为本征不变性点云图。
基于这一统一骨干网络,可无缝集成各类几何预测头与下游任务分支,支持广泛的应用场景。

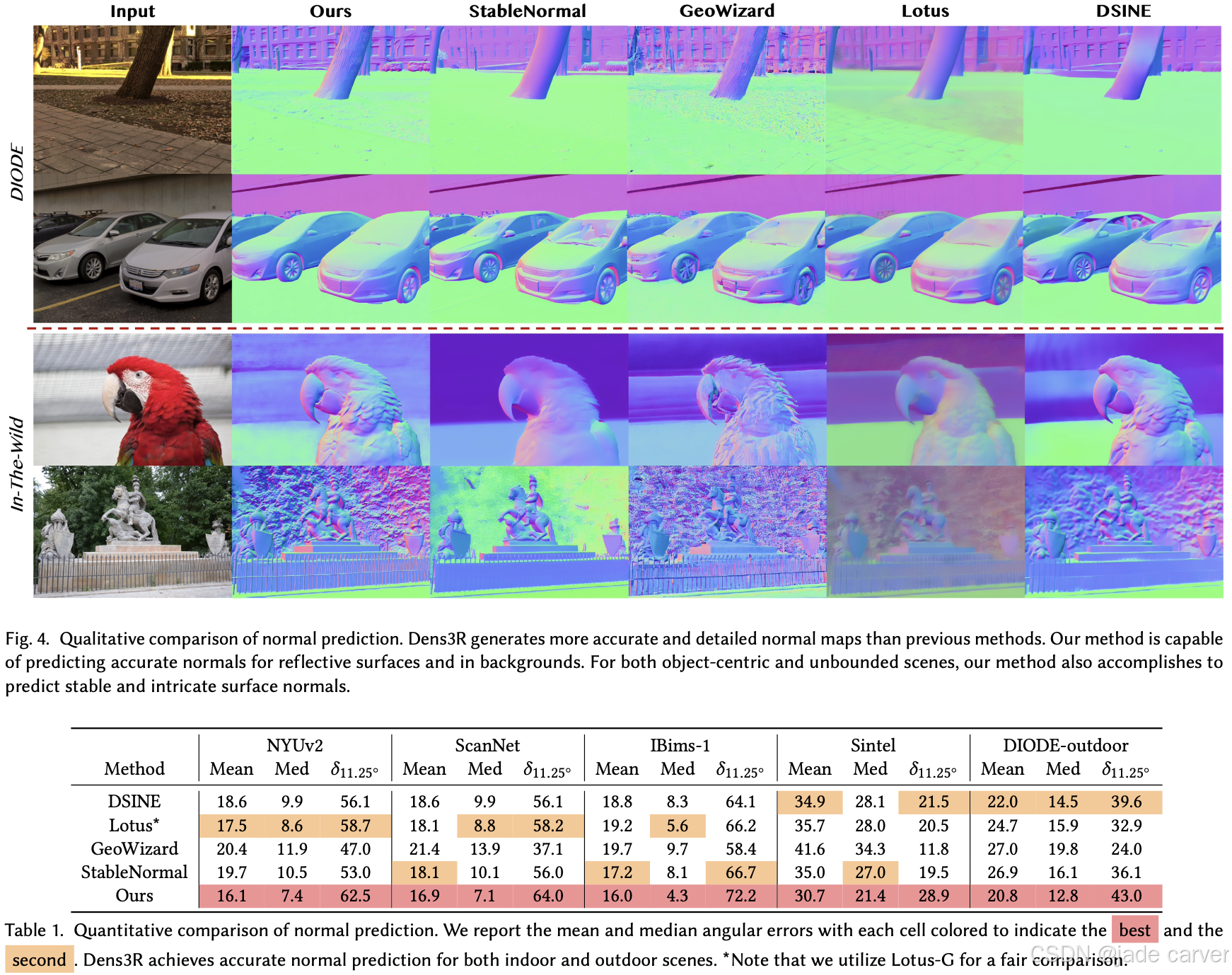
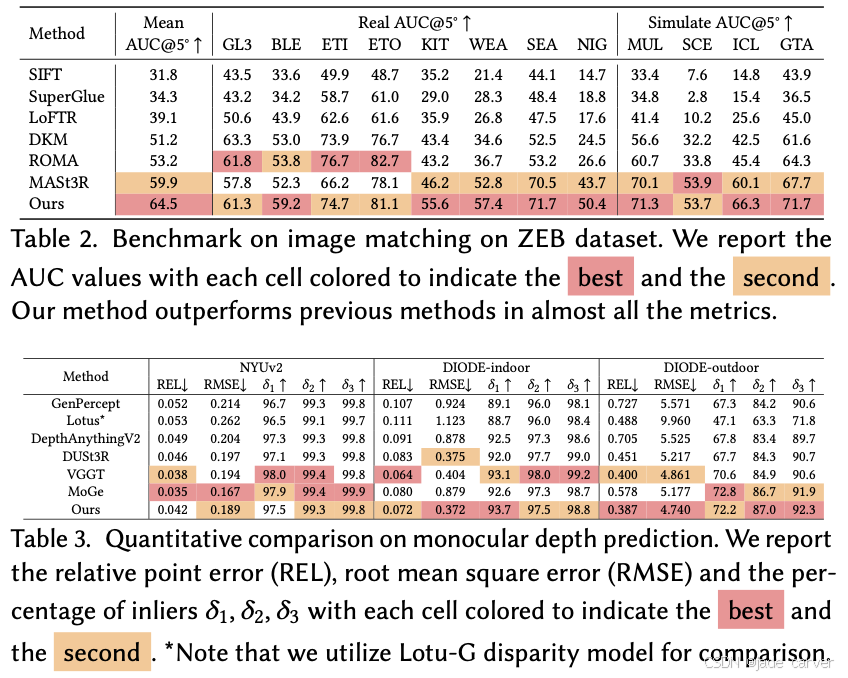
在各种数据的表现:



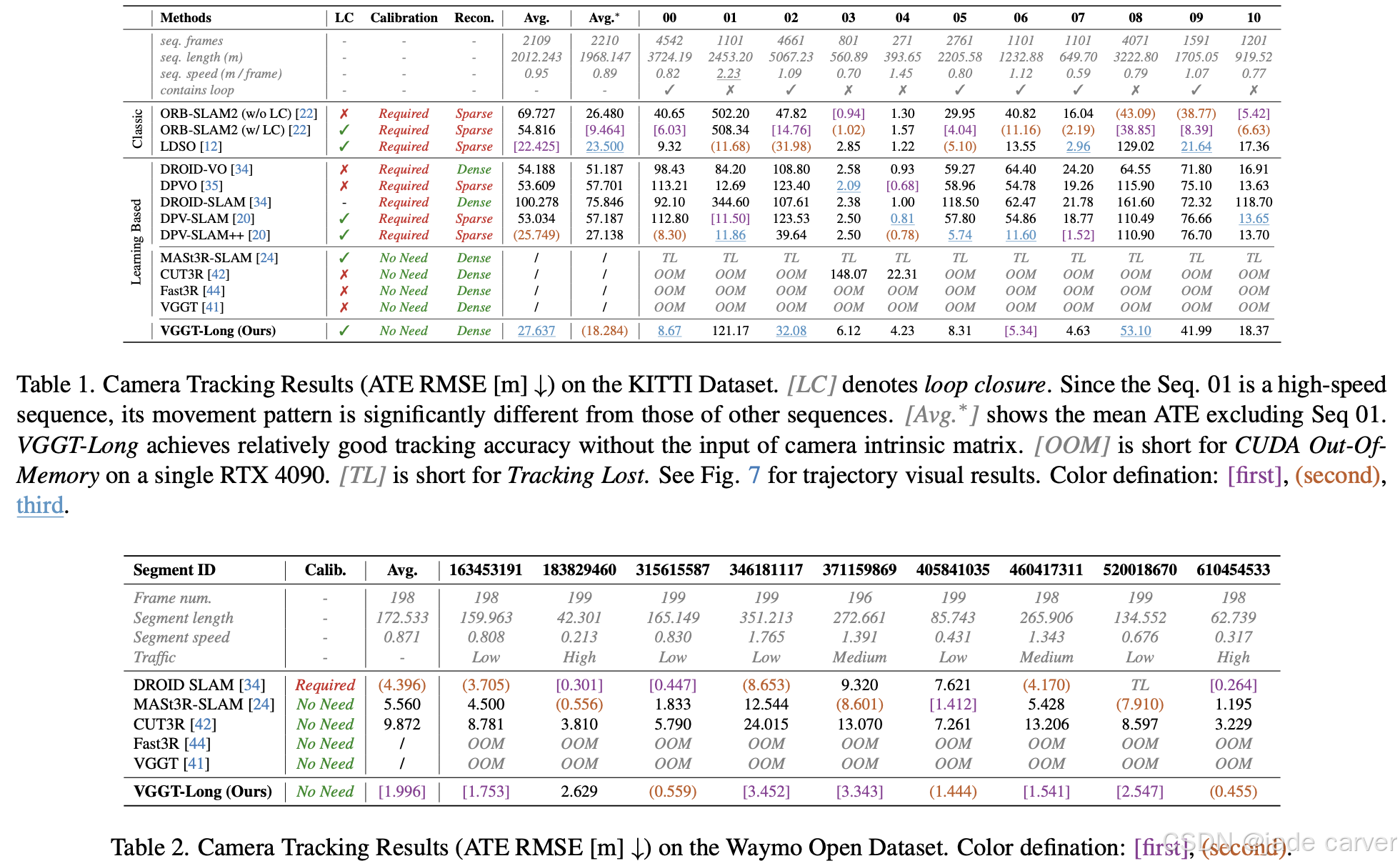
1.3VGGT-Long: Chunk it, Loop it, Align it – Pushing VGGT’s Limits on Kilometer-scale Long RGB Sequences(开源)
arxiv:Tue, 22 Jul 2025 10:39:04 UTC
[2507.16443] VGGT-Long: Chunk it, Loop it, Align it -- Pushing VGGT's Limits on Kilometer-scale Long RGB SequencesAbstract page for arXiv paper 2507.16443: VGGT-Long: Chunk it, Loop it, Align it -- Pushing VGGT's Limits on Kilometer-scale Long RGB Sequences![]() https://arxiv.org/abs/2507.16443
https://arxiv.org/abs/2507.16443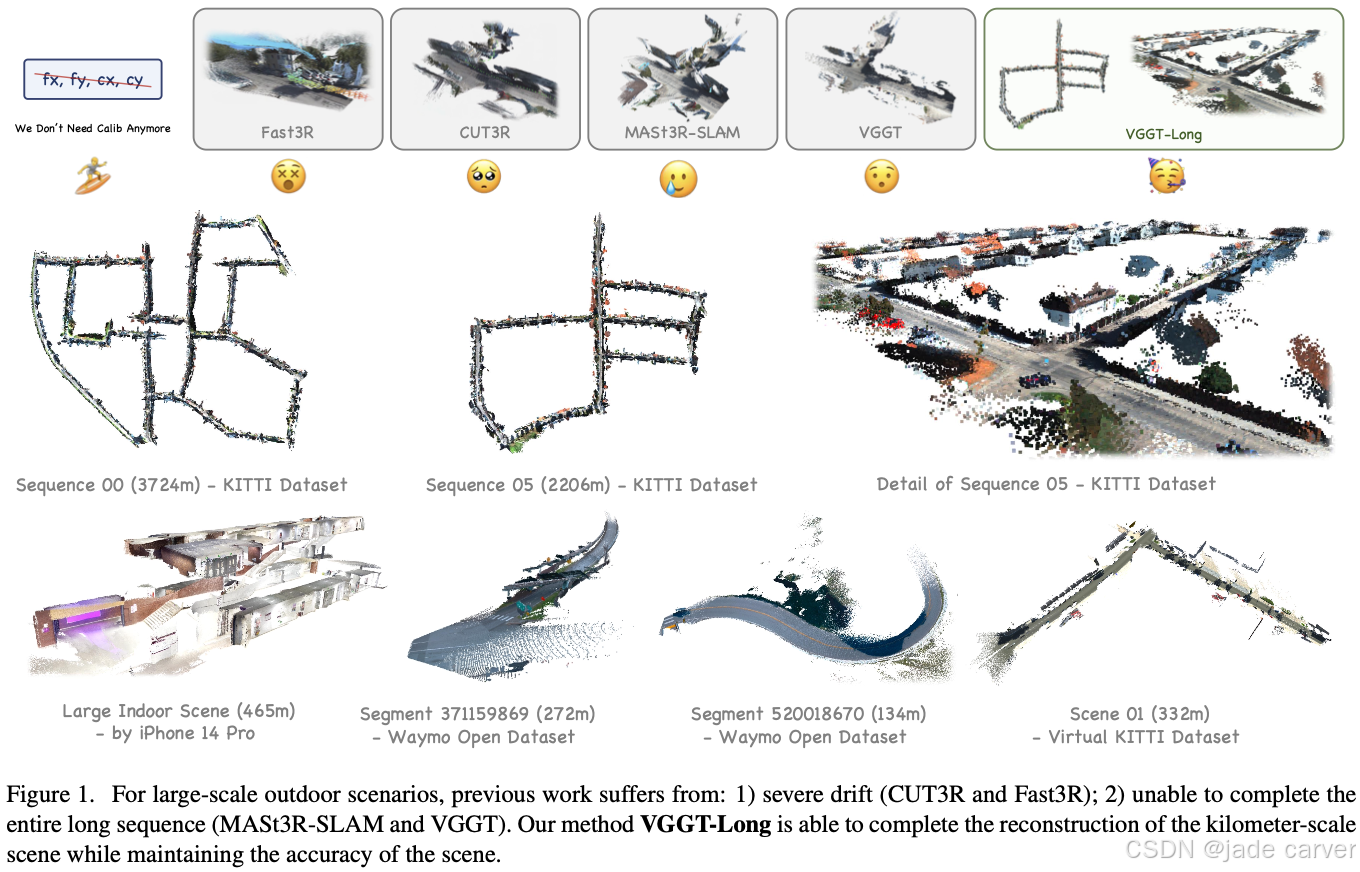
我们提出 VGGT-Long——一个简洁而高效的系统,将单目三维重建的边界突破至千米级无边界户外场景。该方法通过分块处理策略结合重叠区域对齐与轻量级闭环优化,解决了现有模型的可扩展性瓶颈。
在无需相机标定、深度监督或模型重训练的条件下,VGGT-Long 实现了与传统方法相当的轨迹精度与重建质量。我们在 KITTI、Waymo 和 Virtual KITTI 数据集上进行了评估:该系统不仅在基础模型通常失效的长时序 RGB 视频中成功运行,还能在各种环境下生成高精度且几何一致的重建结果。我们的实验证明了基础模型在现实场景中实现可扩展单目三维重建的潜力。
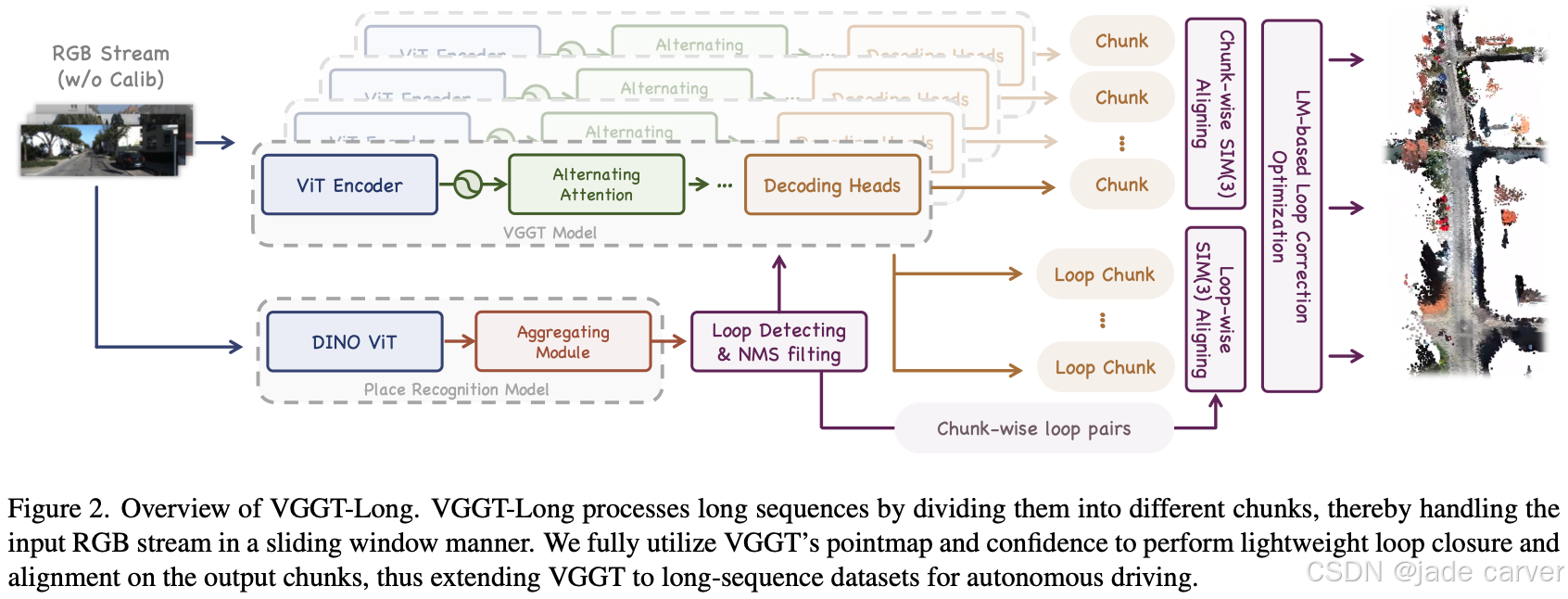
VGGT-Long 通过将长序列分割为多个数据块(chunk)进行处理,采用滑动窗口(sliding window)的方式逐段处理输入的RGB视频流。该方法充分利用 VGGT 生成的点云图(pointmap)与置信度信息,对输出数据块执行轻量级闭环优化(lightweight loop closure)与对齐操作,从而将VGGT的能力扩展至自动驾驶领域的长时序数据集。

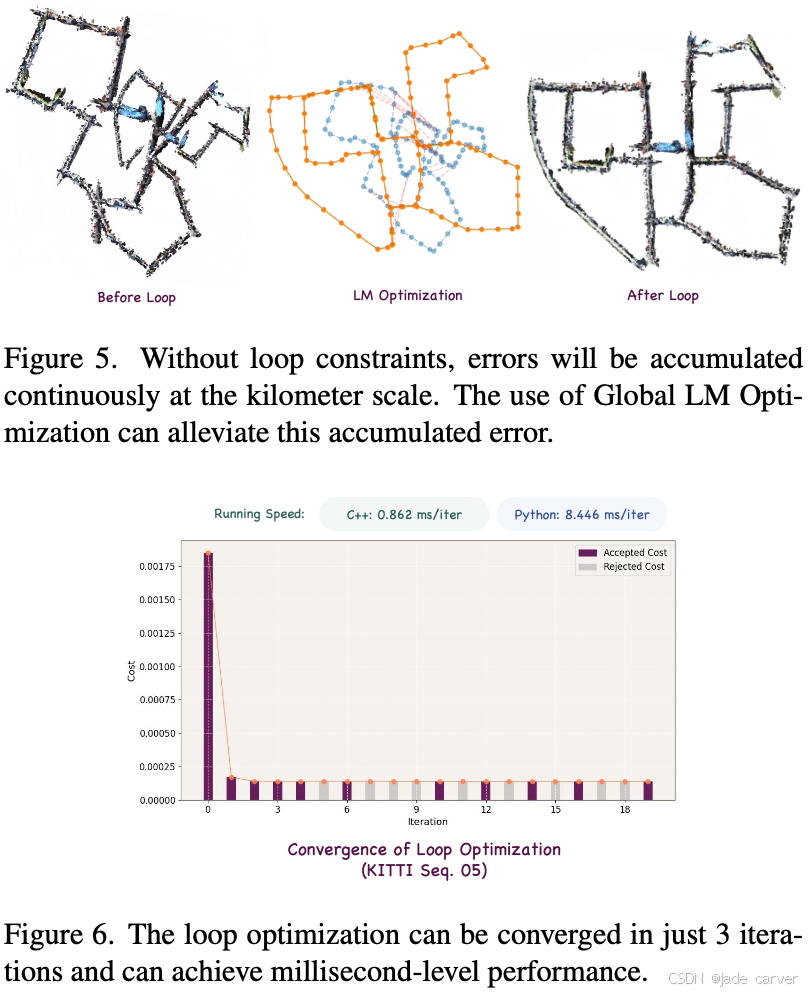
二、动态MVS
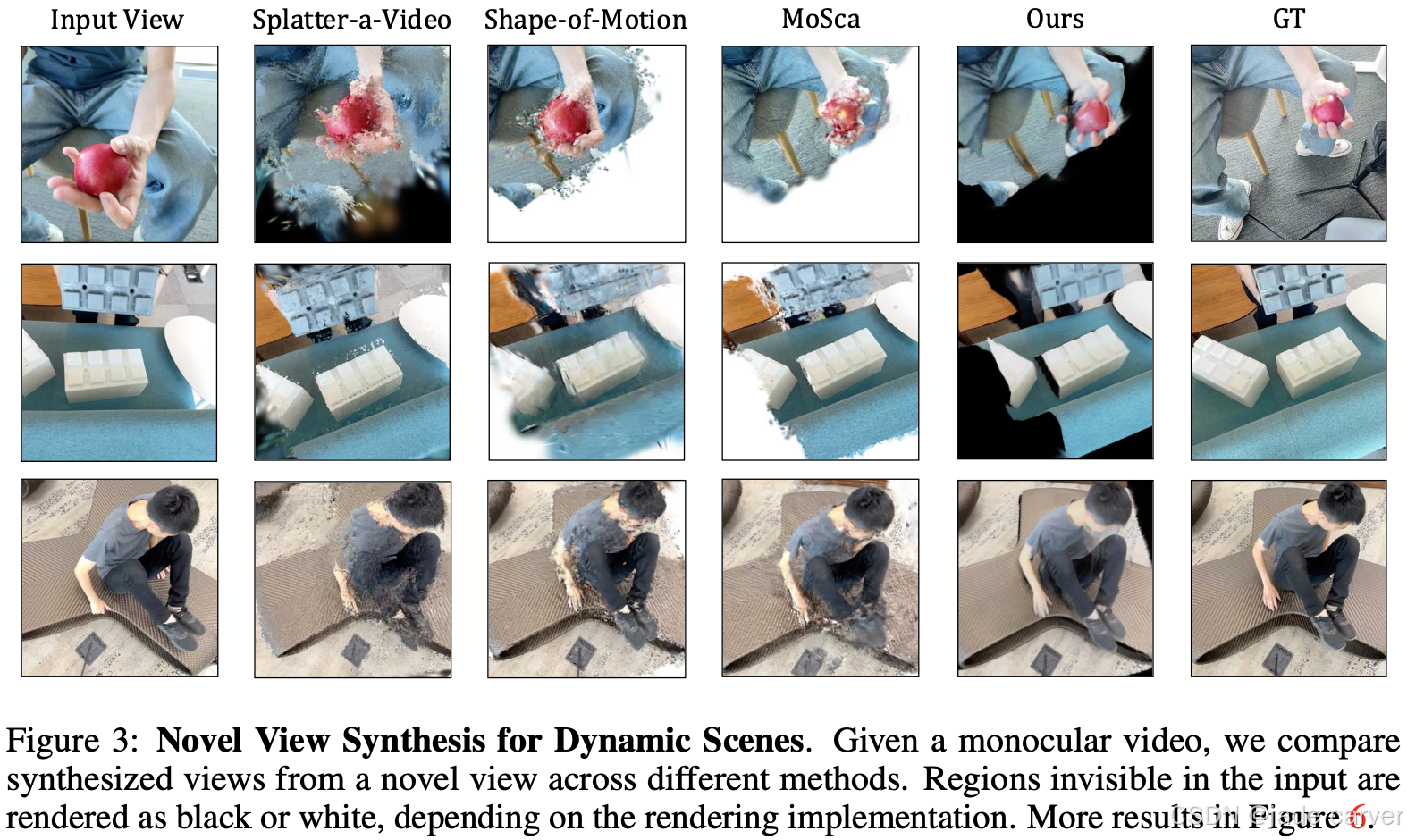
2.1MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second(开源)
arxiv:Mon, 14 Jul 2025 08:49:57 UTC
[2507.10065] MoVieS: Motion-Aware 4D Dynamic View Synthesis in One SecondAbstract page for arXiv paper 2507.10065: MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second![]() https://arxiv.org/abs/2507.10065
https://arxiv.org/abs/2507.10065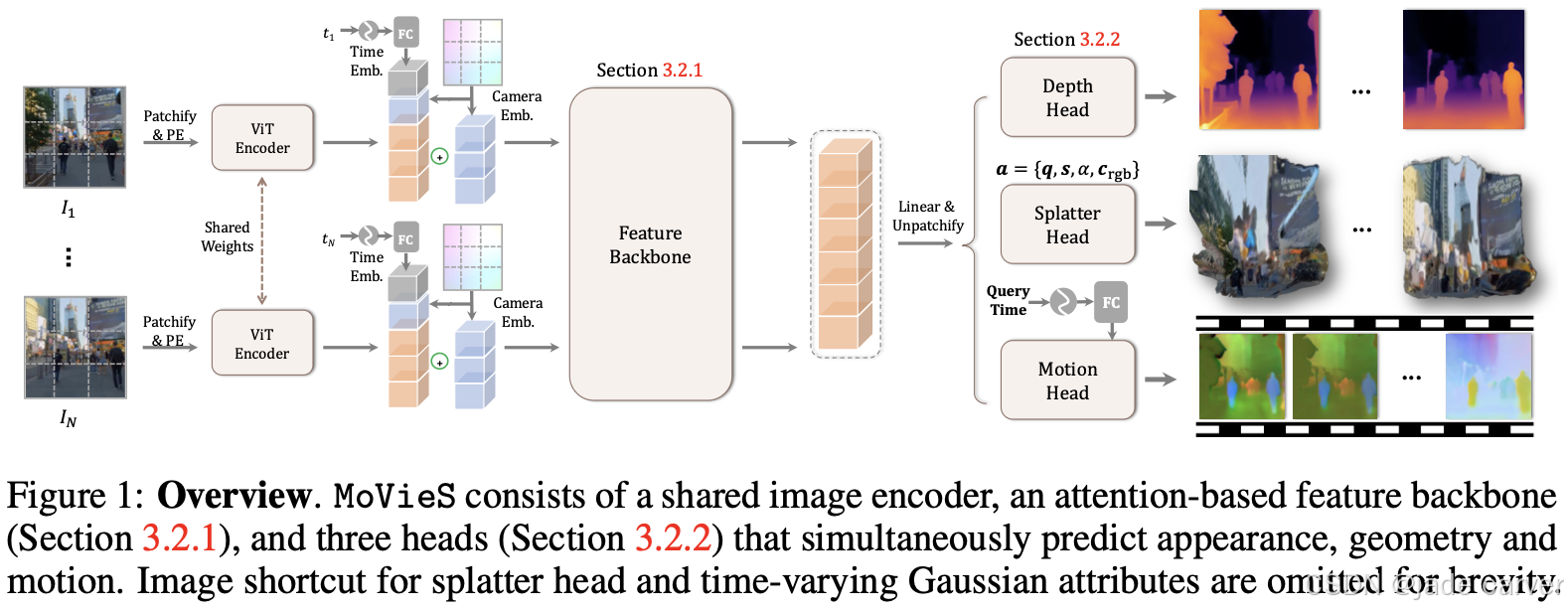
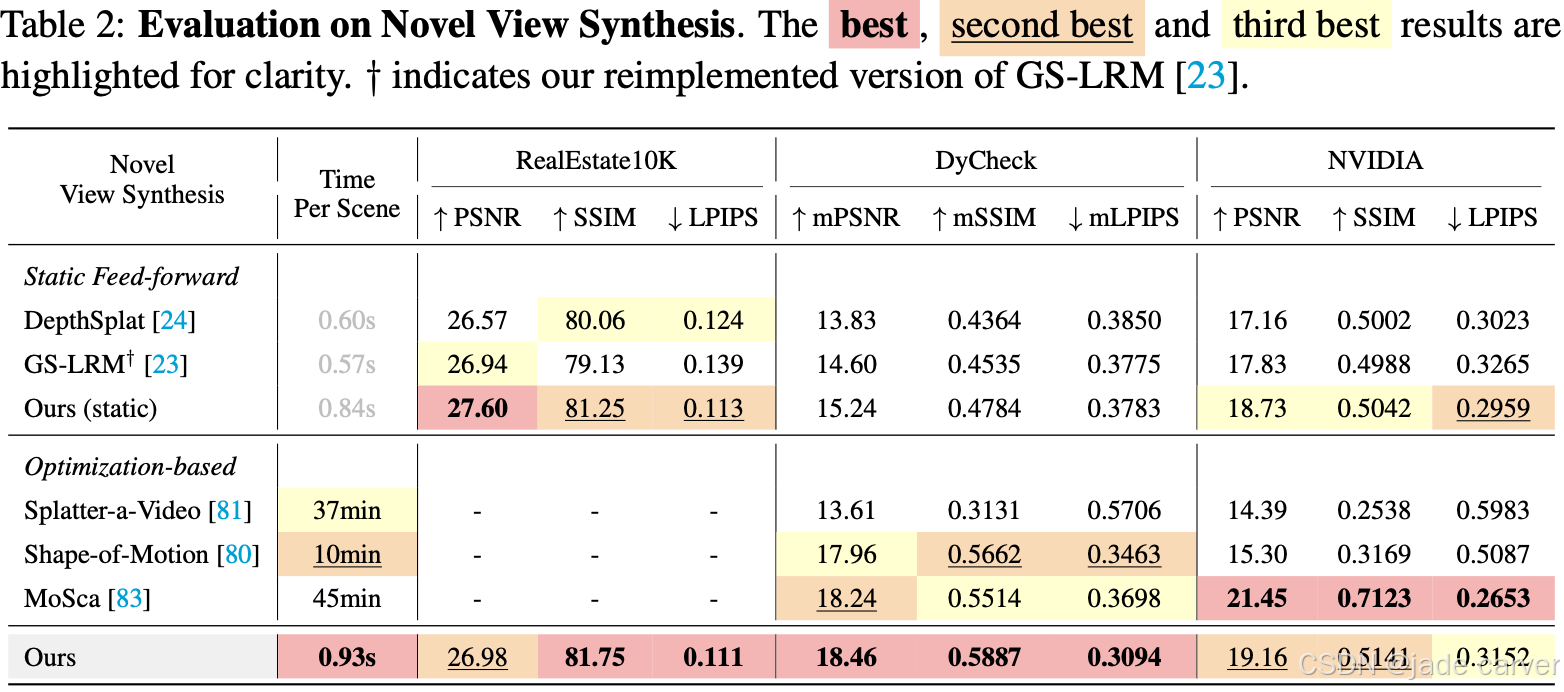
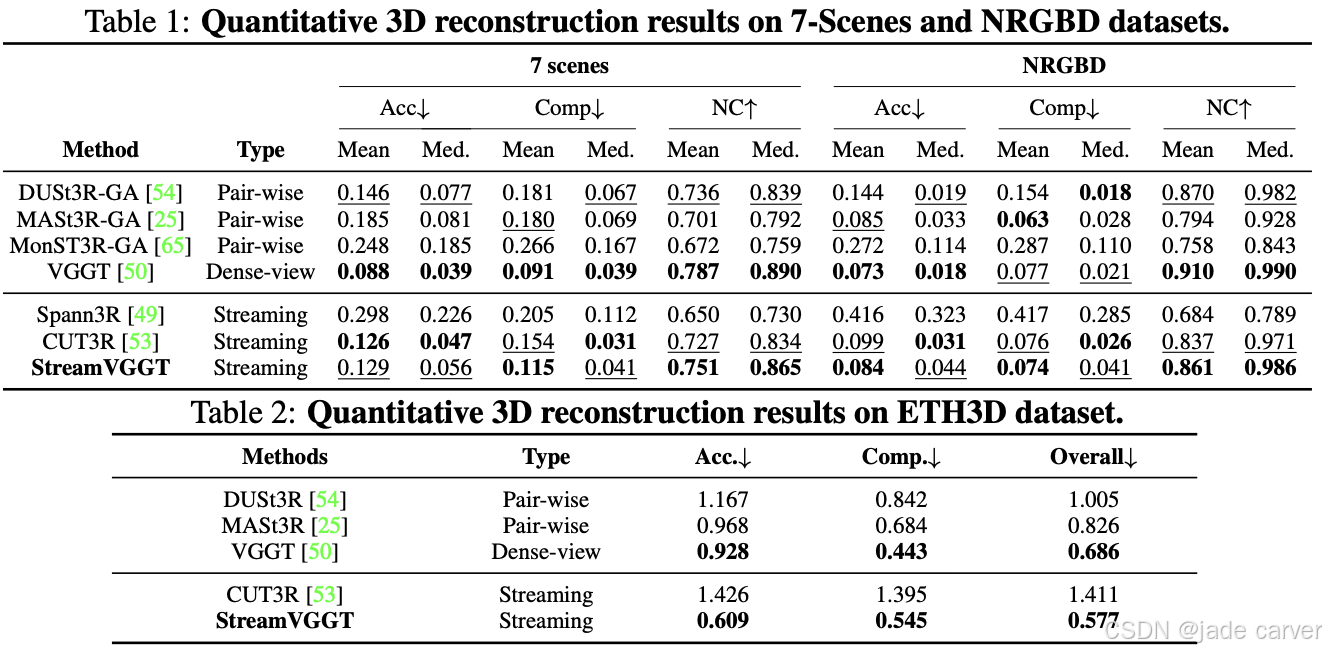
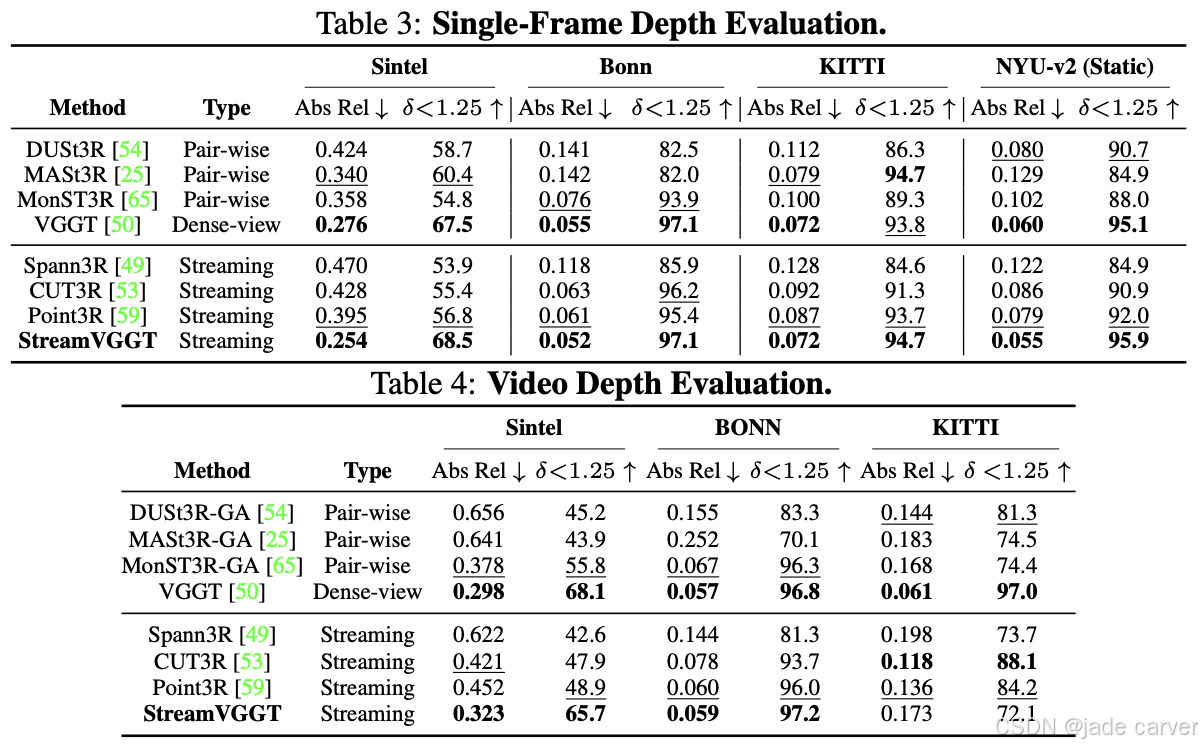
2.2Streaming 4D Visual Geometry Transformer(开源)
arxiv:Tue, 15 Jul 2025 17:59:57 UTC
[2507.11539] Streaming 4D Visual Geometry TransformerAbstract page for arXiv paper 2507.11539: Streaming 4D Visual Geometry Transformer![]() https://arxiv.org/abs/2507.11539
https://arxiv.org/abs/2507.11539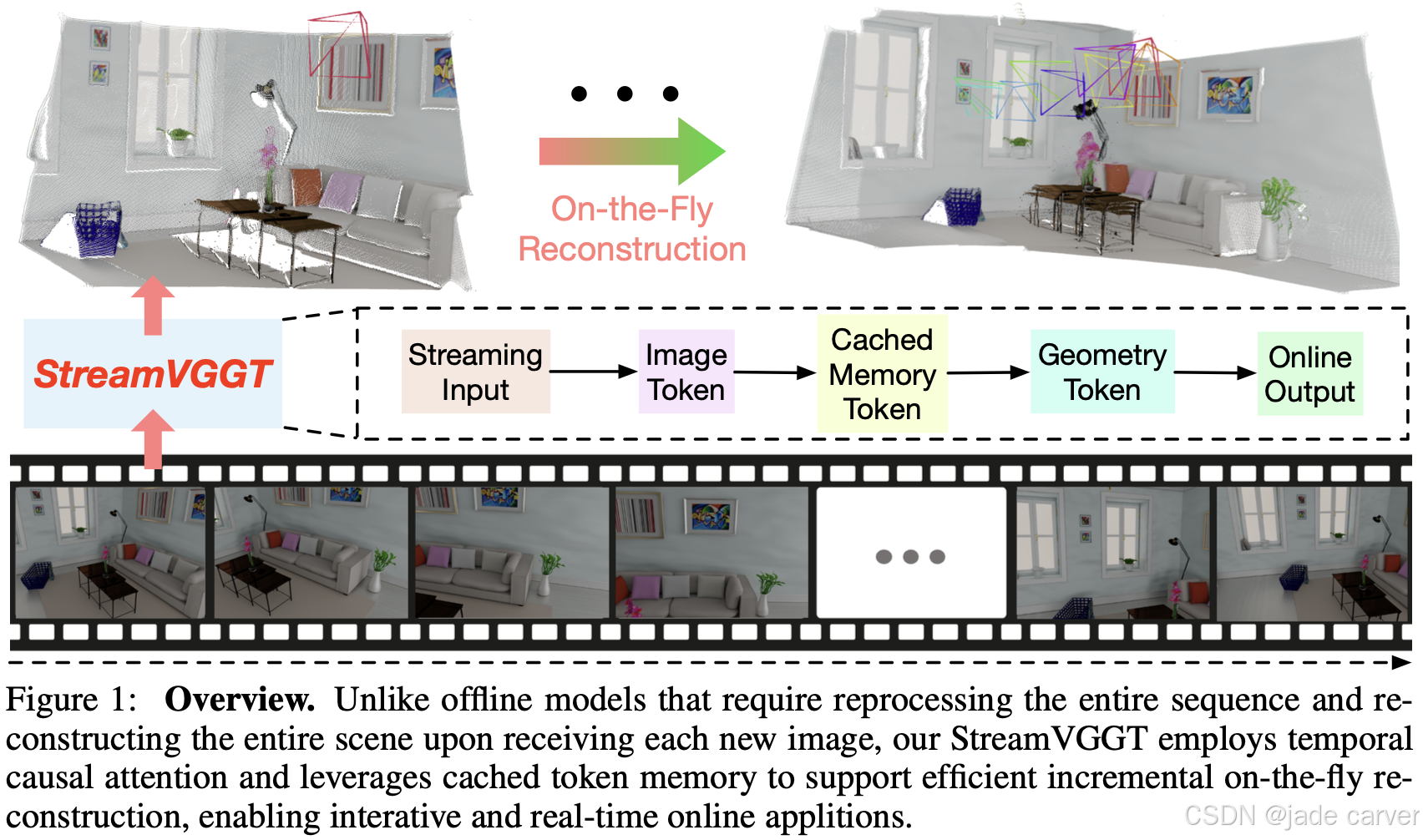
感知与重建视频中的四维时空几何是计算机视觉领域基础而富有挑战性的任务。为支持交互式实时应用,我们提出一种流式四维视觉几何变换器,其设计理念与自回归大语言模型相通。我们探索了一种简洁高效的架构,采用因果变换器以在线方式处理输入序列:通过时序因果注意力机制缓存历史键值作为隐式记忆,实现高效的流式长期四维重建。该设计能通过增量整合历史信息完成实时四维重建,同时保持高质量的空间一致性。
为提升训练效率,我们提出从稠密双向视觉几何基础变换器(VGGT)向因果模型进行知识蒸馏。推理阶段支持迁移大语言模型领域优化的高效注意力算子(如FlashAttention)。在多项四维几何感知基准测试中,本模型在保持竞争力的同时显著提升在线推理速度,为可扩展的交互式四维视觉系统开辟了新路径。
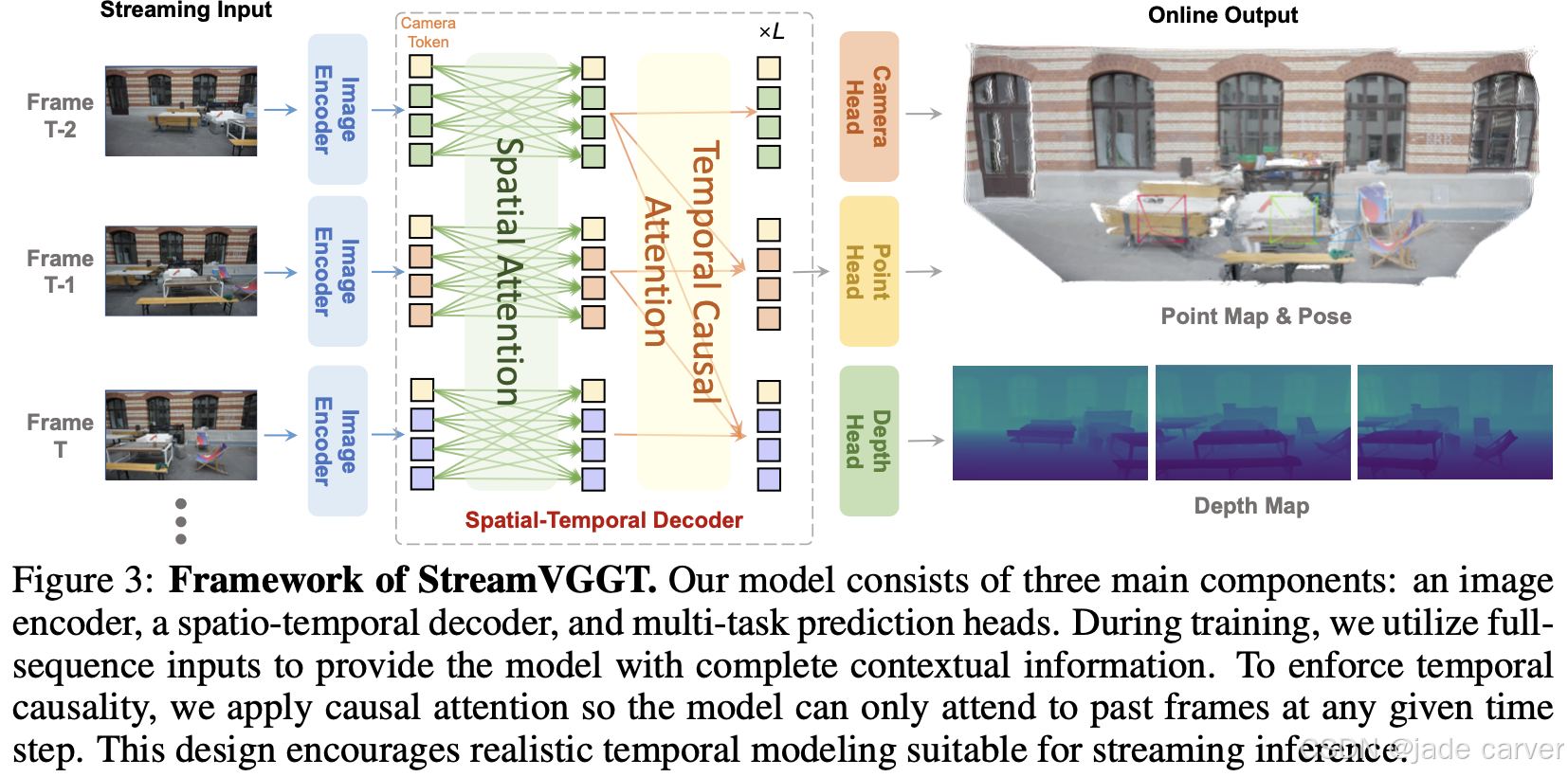
我们的模型由三大核心组件构成:图像编码器、时空解码器以及多任务预测头。在训练阶段,我们采用全序列输入以提供完整的上下文信息;同时通过施加因果注意力机制,强制模型在任意时间步仅能关注历史帧,以此构建符合流式推理需求的时序因果关系。这种设计既保障了训练时的全局信息利用,又确保了推理时的现实时序建模能力。
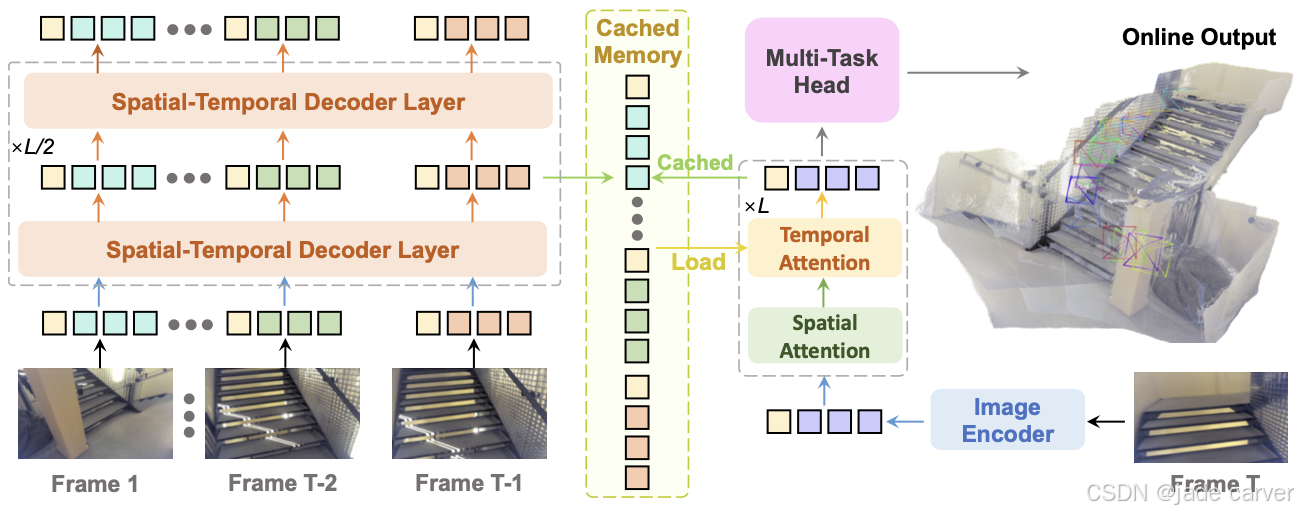
在流式推理过程中,我们通过缓存历史键值对(keys and values)作为隐式记忆库,持续存储历史帧信息。该记忆机制使模型能够高效复用已计算的特征表示,既避免了冗余运算,又实现了跨时间维度的连贯上下文理解。通过这种增量式处理方式,本模型最终达到与全序列推理相当的精度表现。
三、3DGS
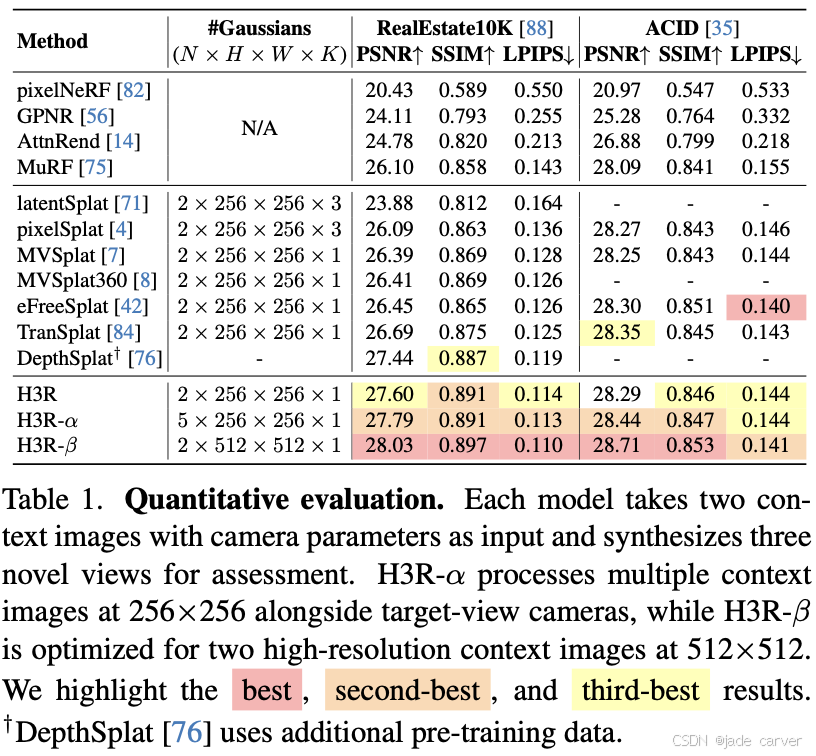
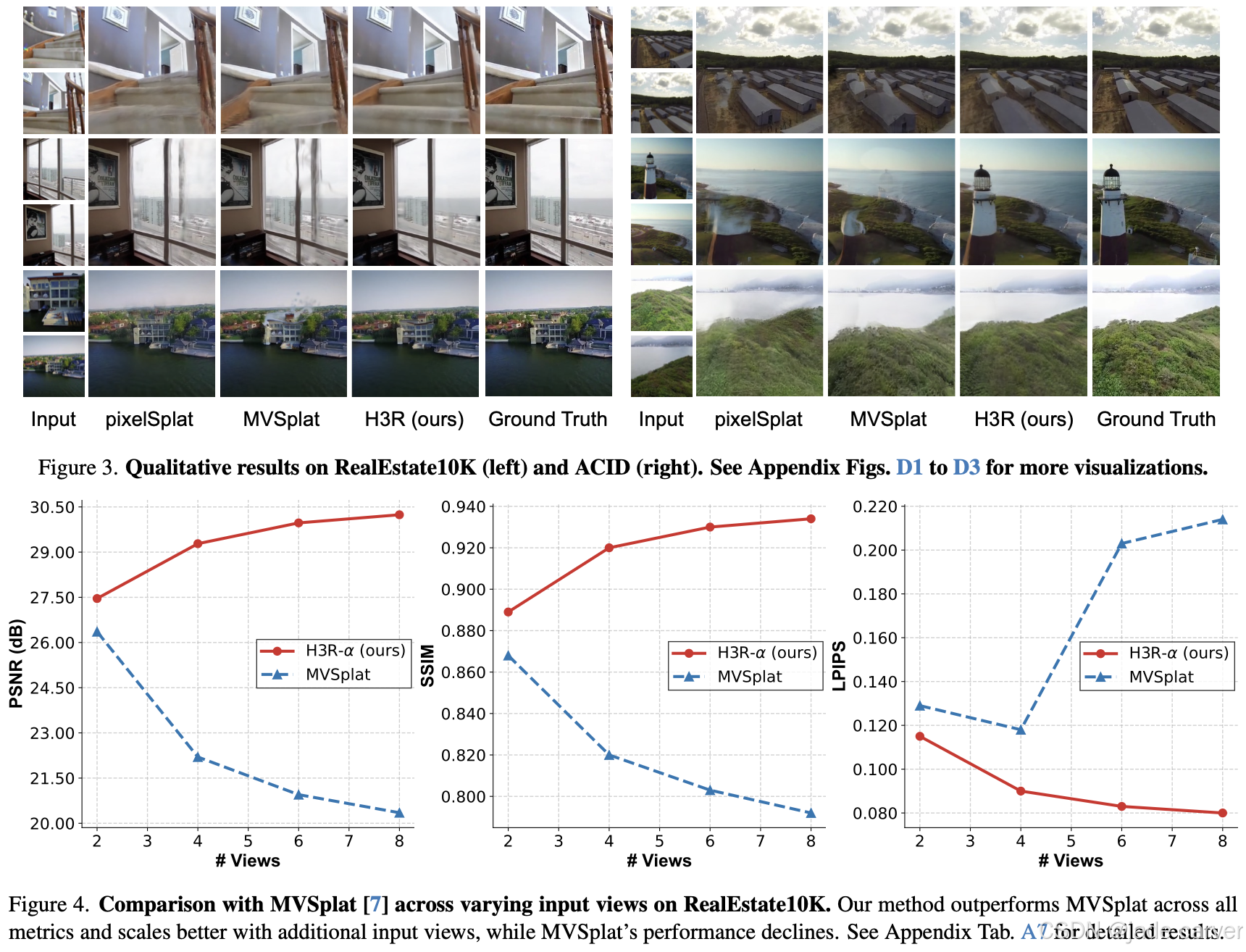
3.1H3R: Hybrid Multi-view Correspondence for Generalizable 3D Reconstruction(未开源)
arxiv: Tue, 5 Aug 2025 05:56:30 UTC
[2508.03118] H3R: Hybrid Multi-view Correspondence for Generalizable 3D ReconstructionAbstract page for arXiv paper 2508.03118: H3R: Hybrid Multi-view Correspondence for Generalizable 3D Reconstruction![]() https://arxiv.org/abs/2508.03118
https://arxiv.org/abs/2508.03118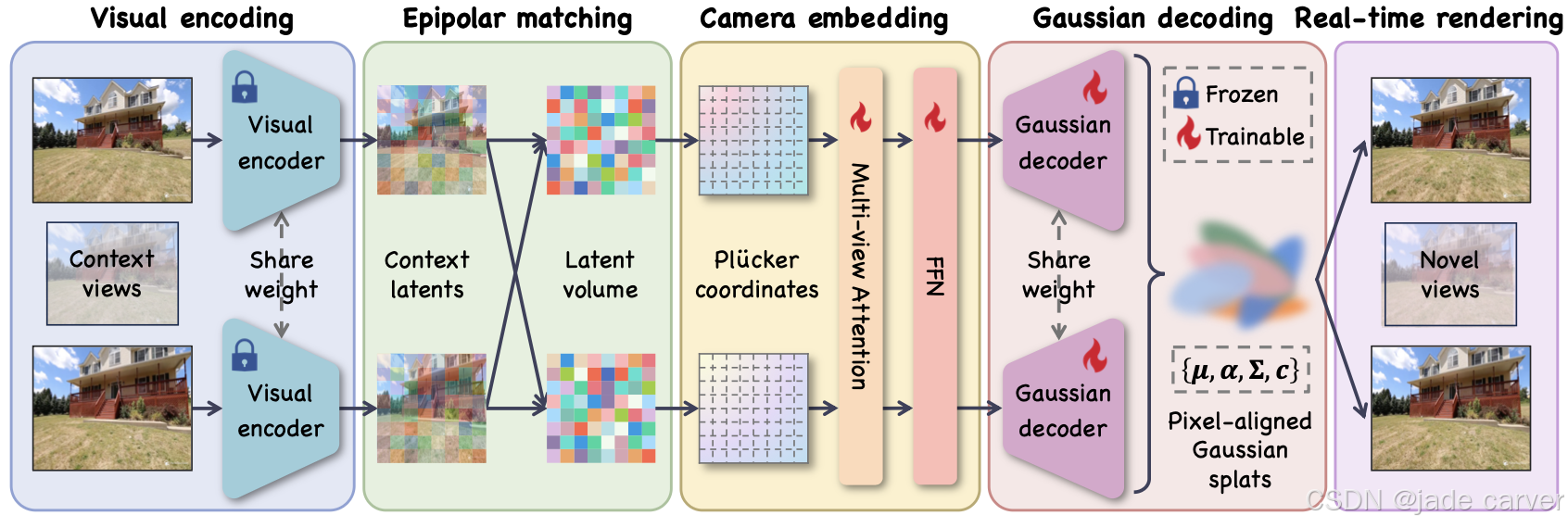
我们的方法无需逐场景优化即可生成像素对齐的高斯分布,实现高保真三维重建。该框架包含五个关键阶段:(i) 视觉编码:采用视觉基础模型从每个上下文视图提取丰富潜在特征,编码对三维重建至关重要的外观与结构信息;(ii) 极线匹配:通过极线几何约束将这些潜在特征对齐并聚合为连贯的潜在体,建立跨视图的空间对应关系;(iii) 相机嵌入:为增强对应关系,引入普吕克坐标表示的相机参数,并应用多视角注意力机制优化潜在特征;(iv) 高斯解码:通过轻量级CNN解码器将优化后的潜在特征转换为像素对齐的高斯分布;(v) 实时渲染:最终生成的高斯泼溅点支持高保真、实时的新颖视角合成。
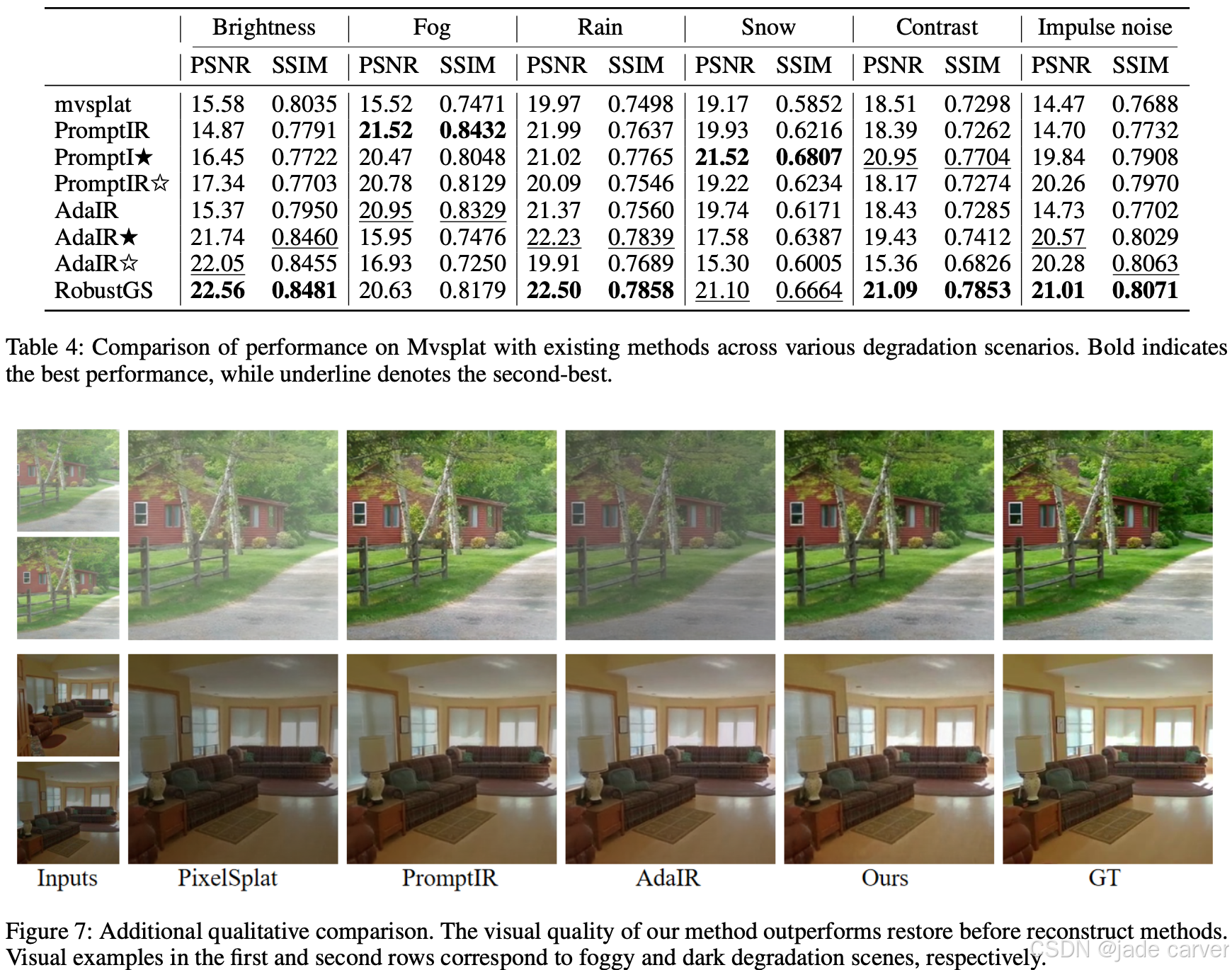
3.2RobustGS: Unified Boosting of Feedforward 3D Gaussian Splatting under Low-Quality Conditions(未开源)
arxiv:Tue, 5 Aug 2025 04:50:29 UTC
[2508.03077] RobustGS: Unified Boosting of Feedforward 3D Gaussian Splatting under Low-Quality ConditionsAbstract page for arXiv paper 2508.03077: RobustGS: Unified Boosting of Feedforward 3D Gaussian Splatting under Low-Quality Conditions![]() https://arxiv.org/abs/2508.03077
https://arxiv.org/abs/2508.03077
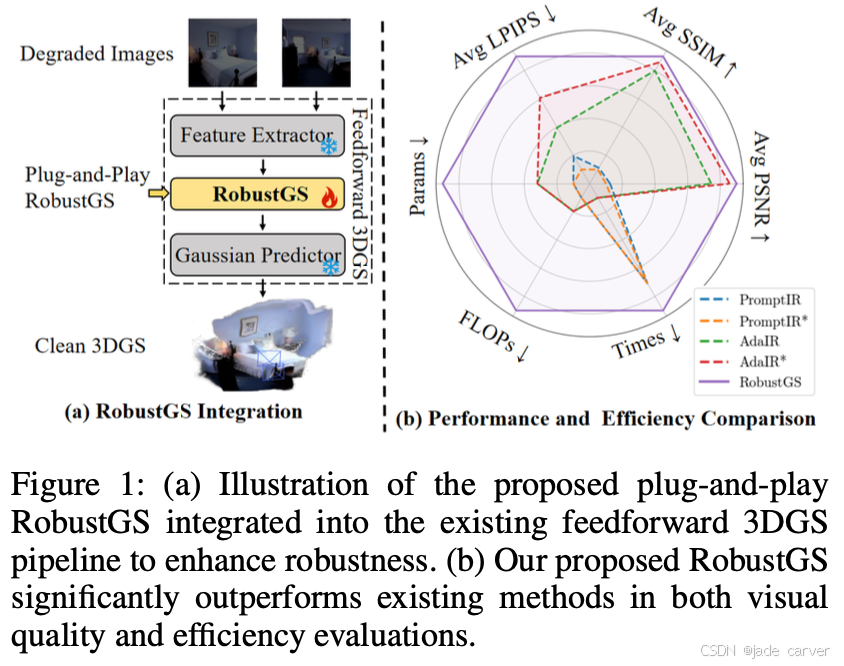
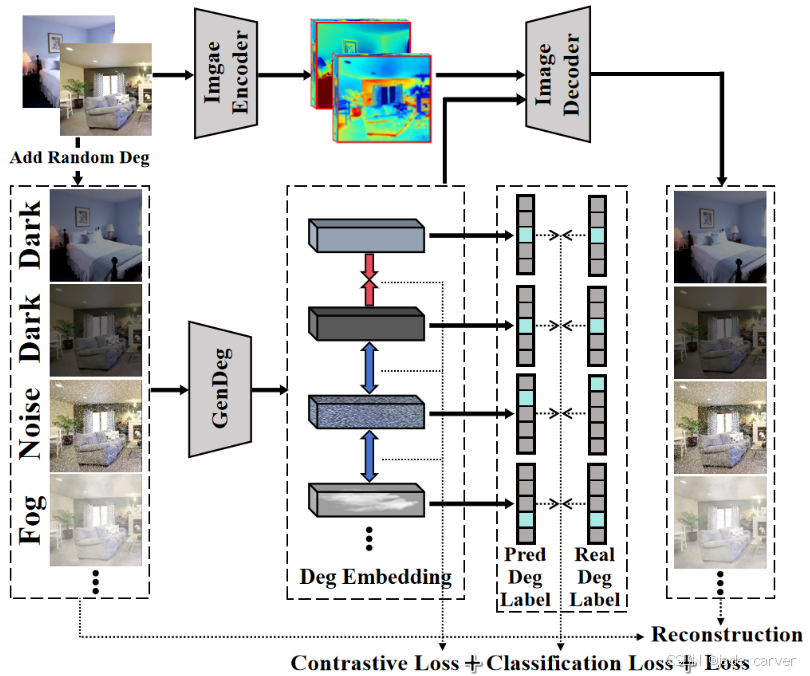
我们为广义退化学习器精心设计的训练流程整合了多重监督信号,以全面提取退化信号的分布特征与类型信息,从而为RobustGS系统奠定基础。
- 广义退化学习器是一个专门设计的模块,用于学习并建模输入数据中的退化信号(如噪声、模糊、低分辨率等影响数据质量的干扰因素)。
- 目标是通过训练,使模型能够识别不同退化类型及其分布特征,从而为后续的RobustGS(一种鲁棒的高斯泼溅或3D重建系统)提供更稳健的输入。
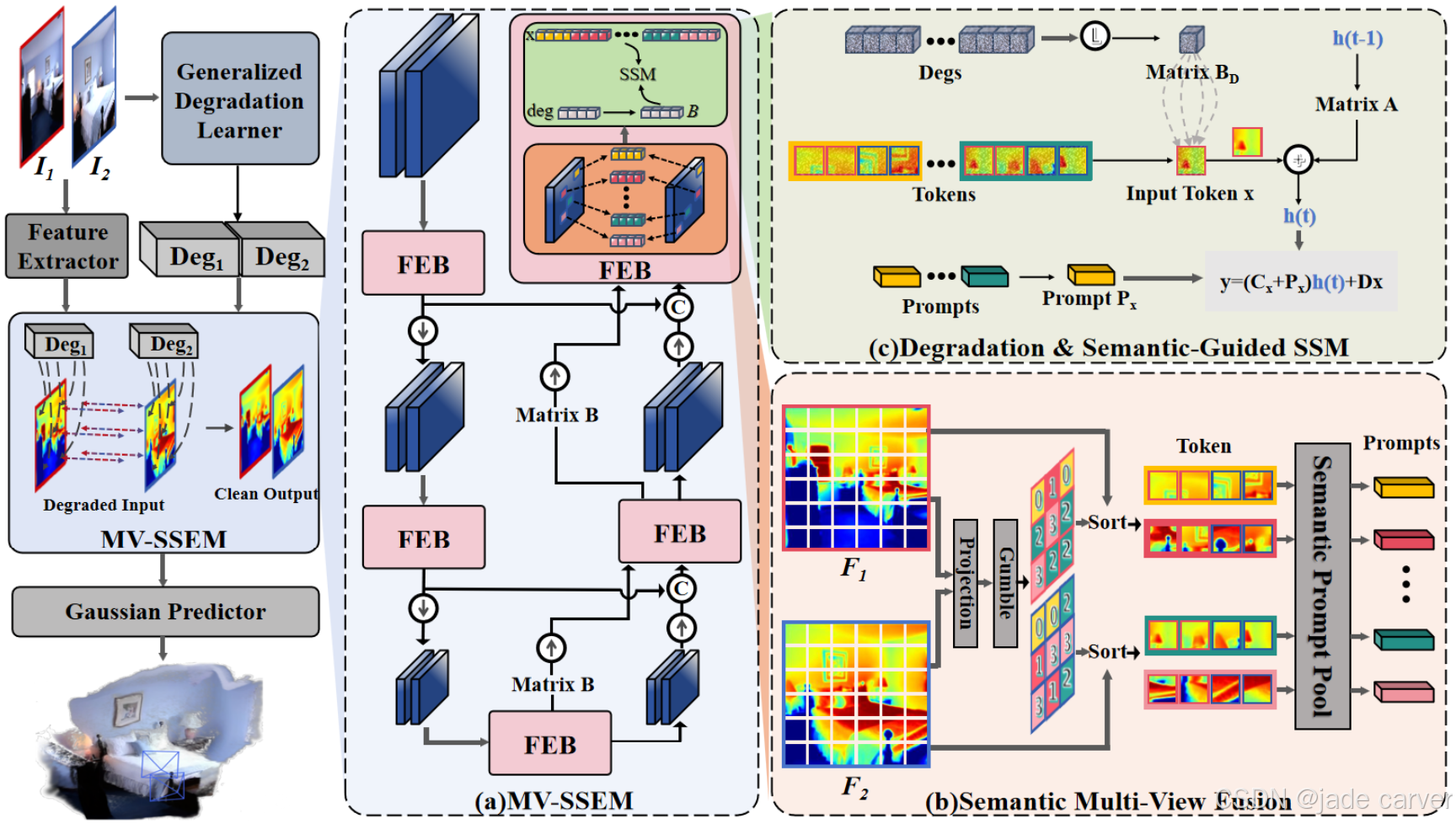
左图:整体流程架构图(其中RobustGS被集成至标准前馈式3D高斯泼溅架构)。主要包含三个核心模块:
(a) 多视角状态空间增强模块(MV-SSEM)
• 由多个特征增强块(FEBs)级联构成
(b) 多视角语义引导模块
• 跨视图提取语义提示(semantic prompts)
• 根据语义相关性重组空间令牌(spatial tokens)
(c) 状态空间模块(SSM)特征增强
• 在退化嵌入(degeneration embeddings)与语义提示联合指导下完成特征优化

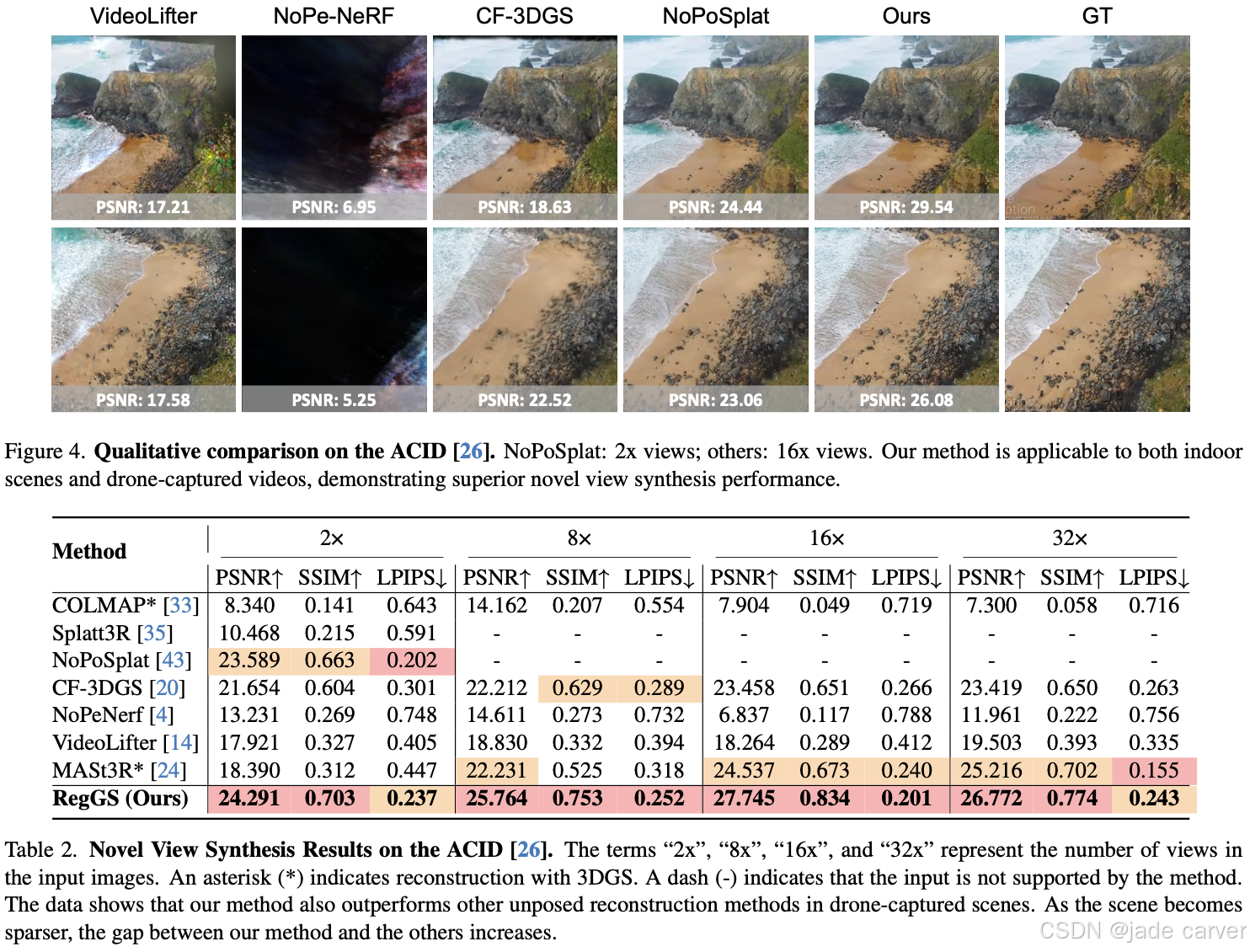
3.3*RegGS: Unposed Sparse Views Gaussian Splatting with 3DGS Registration(开源)
arxiv:Mon, 30 Jun 2025 13:57:24 UTC
https://arxiv.org/abs/2506.23863![]() https://arxiv.org/abs/2506.23863
https://arxiv.org/abs/2506.23863
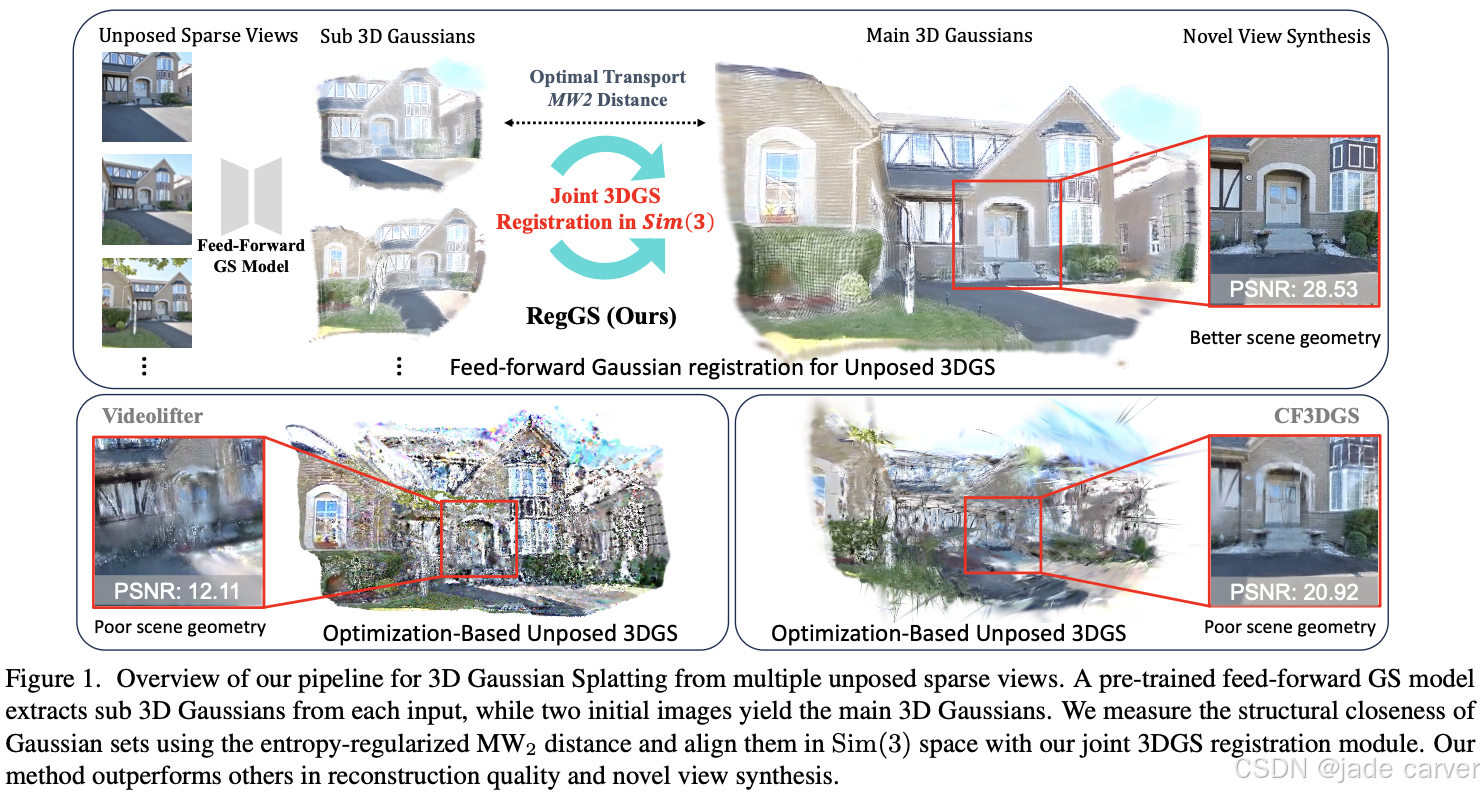
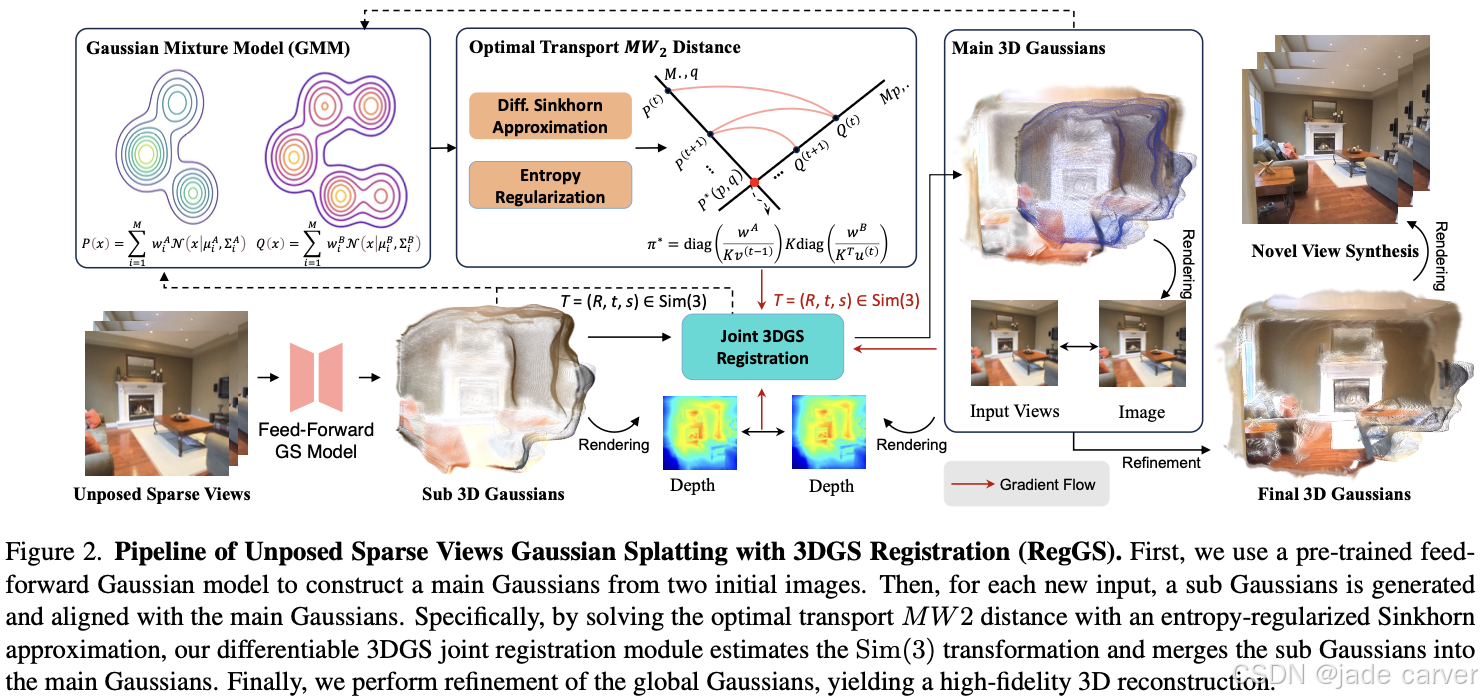
我们提出 RegGS,一种基于 3D 高斯配准(3D Gaussian registration) 的框架,用于重建 无位姿稀疏视图(unposed sparse views)。该框架通过前馈网络生成的局部 3D 高斯(local 3D Gaussians)进行全局对齐,形成一致的 3D 高斯表示。
在技术上,我们采用 熵正则化 Sinkhorn 算法(entropy-regularized Sinkhorn algorithm) 高效求解 最优传输混合 2-Wasserstein 距离(MW2),作为 Sim(3) 空间 下高斯混合模型(GMMs)的对齐度量。此外,我们设计了一个联合 3DGS 配准模块(3DGS registration module),融合 MW2 距离、光度一致性(photometric consistency)和深度几何(depth geometry),实现 由粗到精的配准(coarse-to-fine registration),同时精确估计相机位姿并对齐场景。
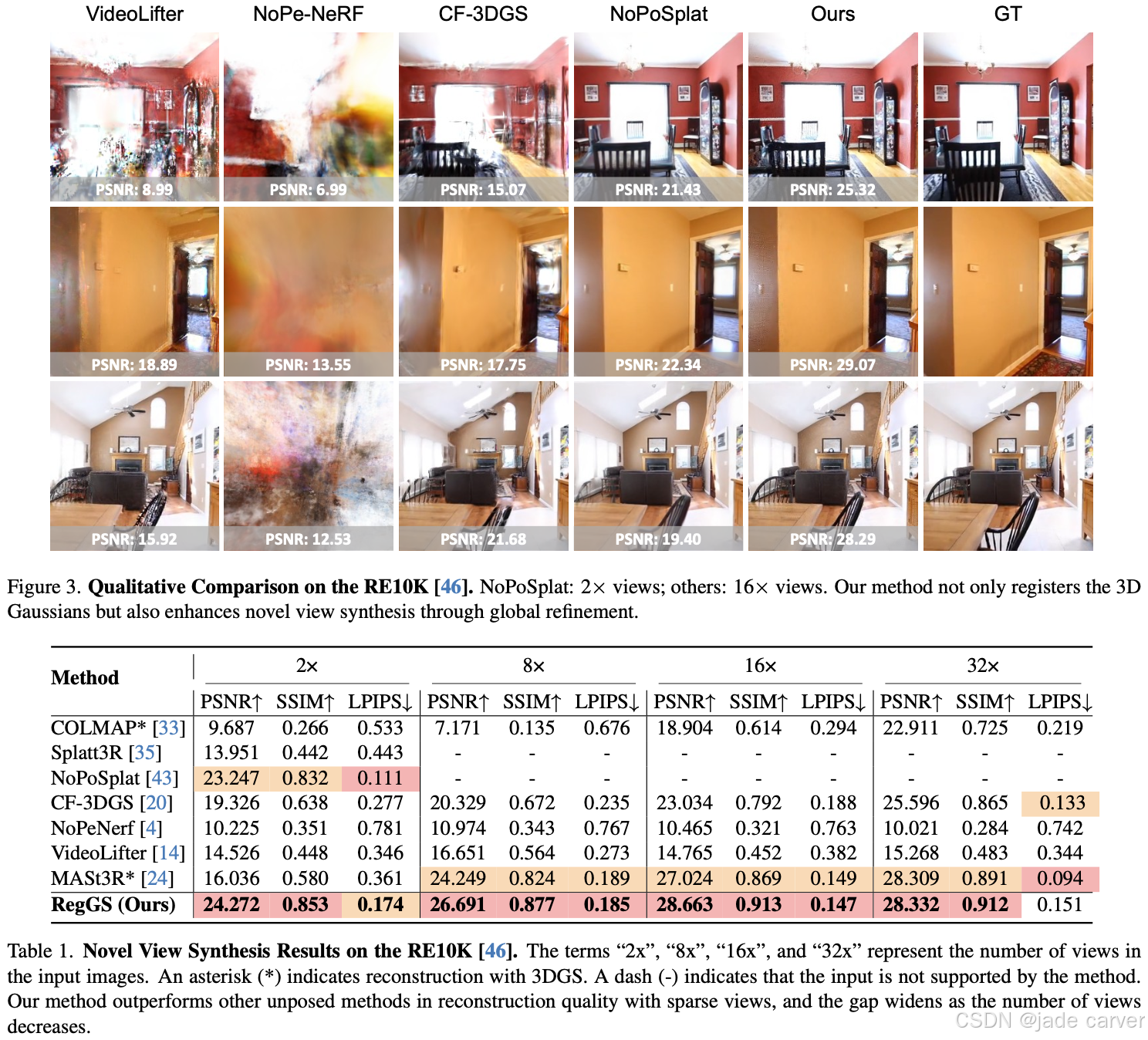
在 RE10K 和 ACID 数据集上的实验表明,RegGS 能够高保真地配准局部高斯分布,实现精准的位姿估计和高质量的新视角合成(novel-view synthesis)。
注释:



3.4No Pose at All: Self-Supervised Pose-Free 3D Gaussian Splatting from Sparse Views(未开源)
arxiv:Sat, 2 Aug 2025 03:19:13 UTC
[2508.01171] No Pose at All: Self-Supervised Pose-Free 3D Gaussian Splatting from Sparse ViewsAbstract page for arXiv paper 2508.01171: No Pose at All: Self-Supervised Pose-Free 3D Gaussian Splatting from Sparse Views![]() https://arxiv.org/abs/2508.01171
https://arxiv.org/abs/2508.01171
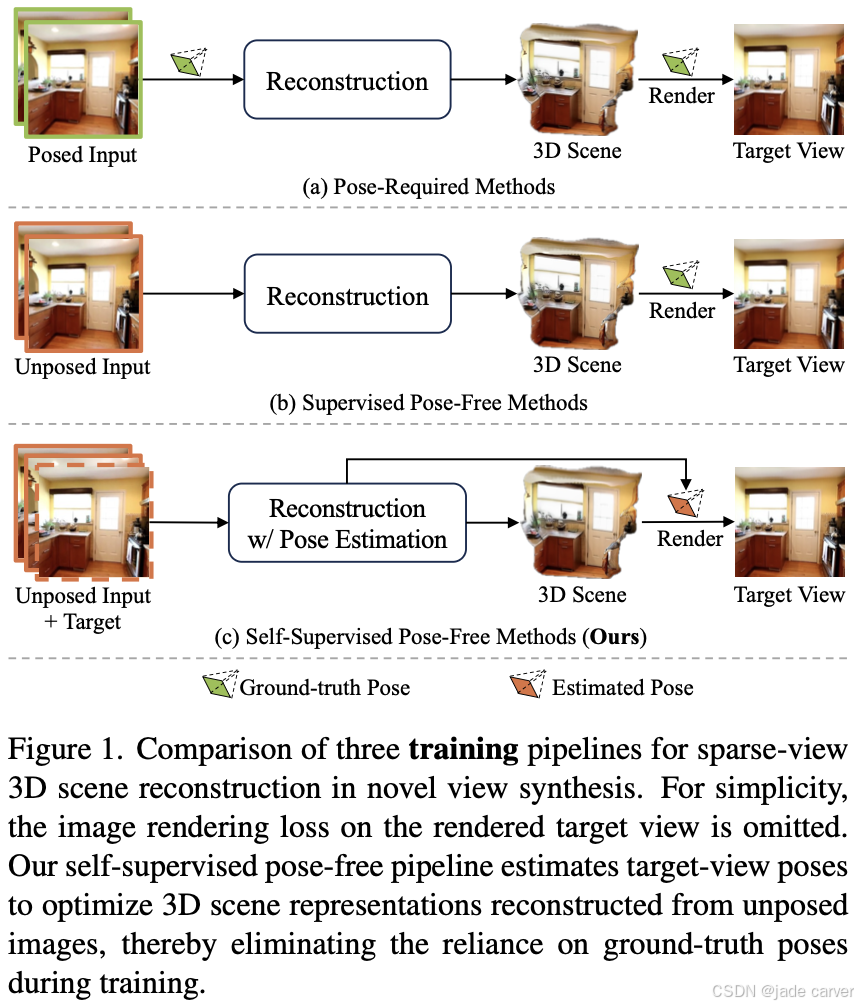
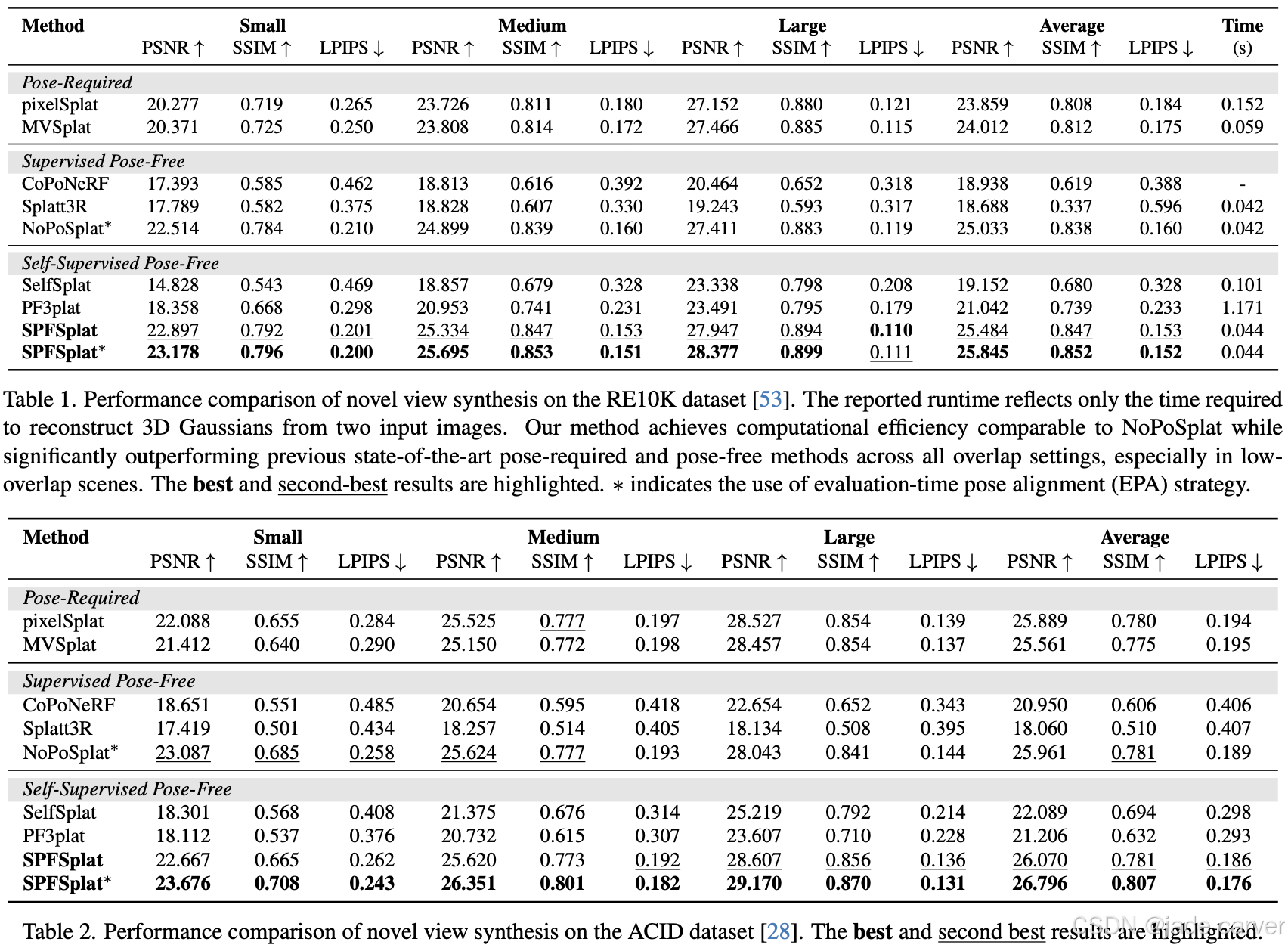
我们提出 SPFSplat——一种面向稀疏多视图图像的高效3D高斯泼溅框架,其训练与推理过程均无需真实相机位姿监督。该框架采用共享特征提取主干网络,通过单次前馈即可从无位姿输入中预测规范空间(canonical space)内的3D高斯基元与相机位姿。
在基于估计新视角位姿的渲染损失基础上,我们引入重投影损失(reprojection loss),以强化像素对齐高斯基元(pixel-aligned Gaussian primitives)的学习,从而增强几何约束。这种免位姿训练范式与高效单步前馈设计,使SPFSplat特别适合实际应用。
值得注意的是,尽管完全缺乏位姿监督,SPFSplat仍能在显著视角变化与有限图像重叠条件下,实现新视角合成任务的最优性能,其相对位姿估计精度甚至超越依赖几何先验的近期方法。
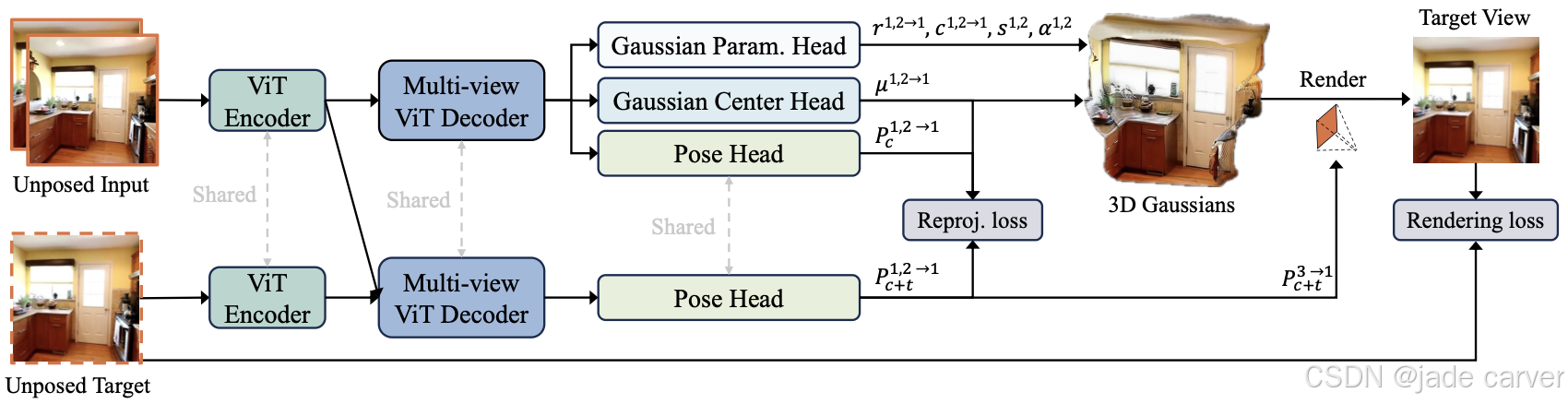
我们提出了一种基于共享ViT主干网络的三头架构,可同时从规范空间(以第一输入视图为参考系)的无位姿图像中预测高斯中心、附加高斯参数和相机位姿。该架构包含两条分支:推理阶段仅使用纯上下文分支(上图),而训练阶段则额外启用带目标分支(下图)以估计目标视图位姿(用于渲染损失监督)。通过引入重投影损失,我们强制高斯中心与对应像素在估计的上下文位姿下对齐,从而实现对3D高斯和相机位姿的联合优化,显著提升几何一致性与重建质量。
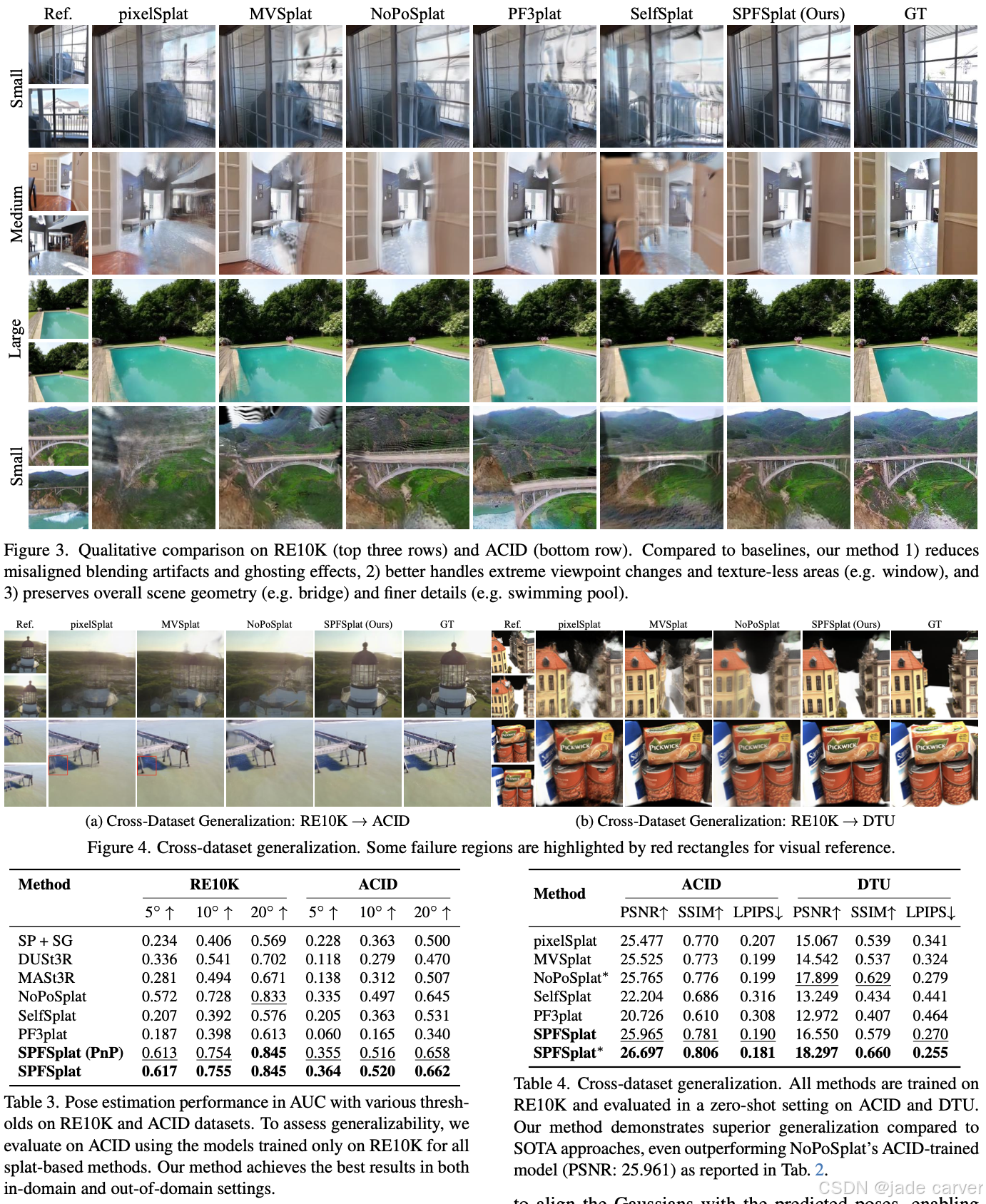

3.5Uni3R: Unified 3D Reconstruction and Semantic Understanding via Generalizable Gaussian Splatting from Unposed Multi-View Images(未开源)(分割、深度估计)
arxiv:Mon, 11 Aug 2025 03:47:38 UTC
https://arxiv.org/abs/2508.03643![]() https://arxiv.org/abs/2508.03643
https://arxiv.org/abs/2508.03643

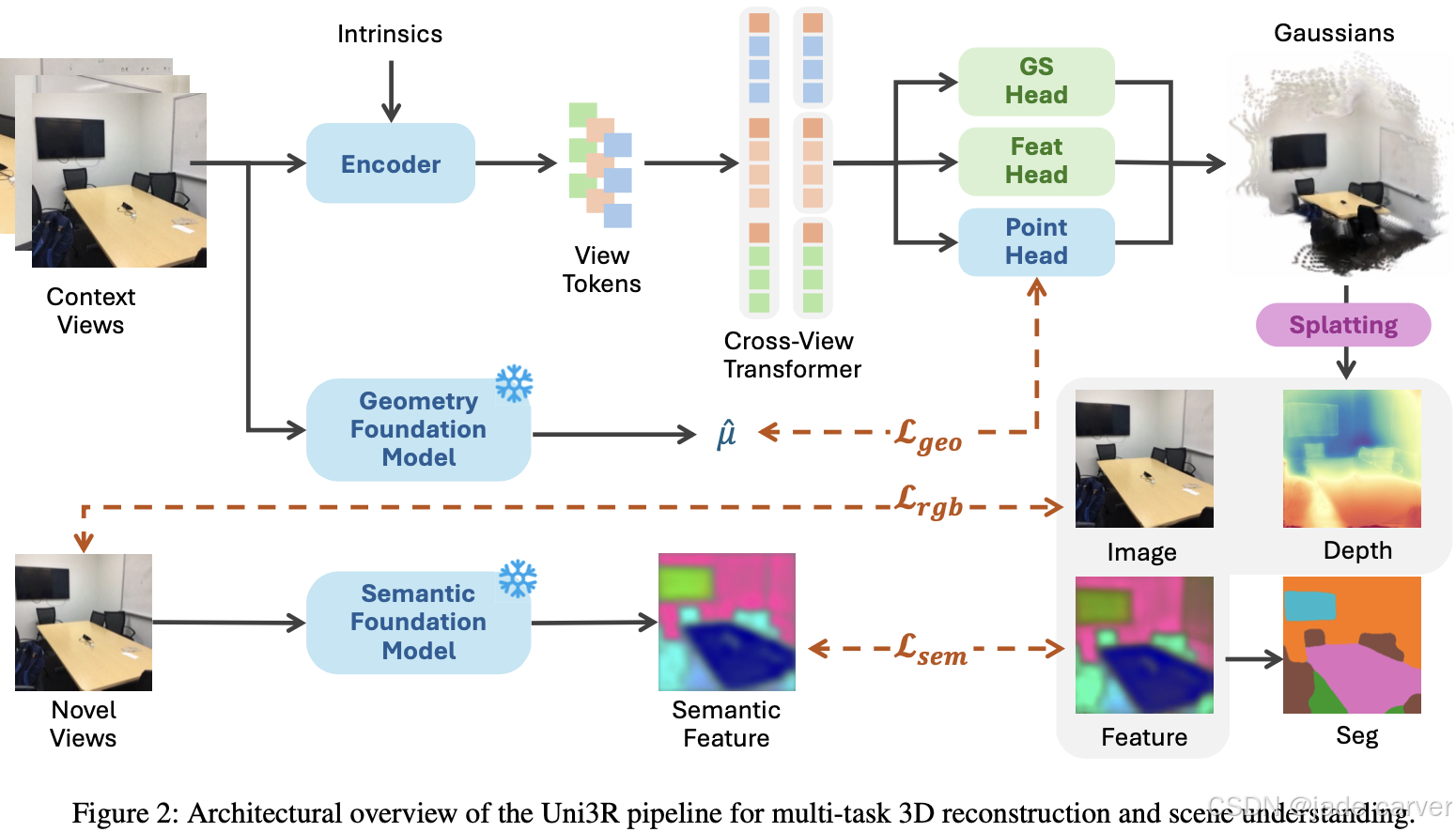
从稀疏二维视图重建并语义解析三维场景始终是计算机视觉领域的核心挑战。传统方法往往将语义理解与重建任务解耦,或依赖昂贵的逐场景优化,严重制约了方法的可扩展性与泛化能力。为此,我们提出Uni3R——一种新颖的前馈式框架,能够直接从无位姿的多视图图像中联合重建开放词汇语义增强的统一三维场景表示。该方法通过跨视图变换器(Cross-View Transformer)鲁棒整合任意多视图输入信息,进而回归出携带语义特征场的三维高斯基元集合。这种统一表征支持:
- 高保真新视角合成
- 开放词汇三维语义分割
- 深度预测
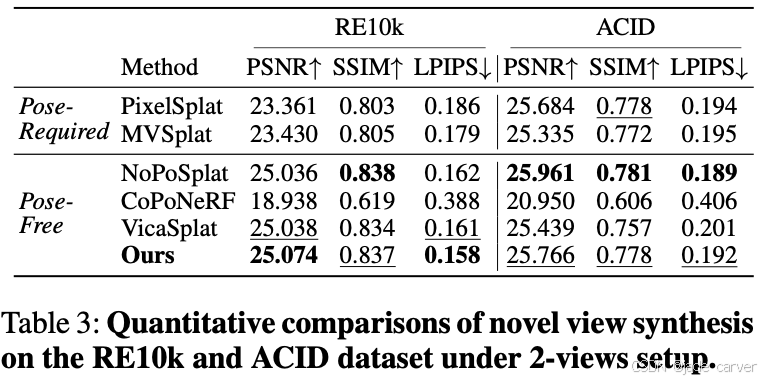
所有任务均在单次前馈中完成。大量实验表明,Uni3R在多项基准测试中确立新标杆(如RE10K数据集25.07 PSNR、ScanNet数据集55.84 mIoU),标志着可泛化的统一三维重建与理解范式取得突破。


四、动态3DGS
4.1
五、深度估计与法线估计
5.1MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details(开源)
moge1:https://arxiv.org/pdf/2410.19115![]() https://arxiv.org/pdf/2410.19115
https://arxiv.org/pdf/2410.19115
arxiv:Thu, 3 Jul 2025 11:40:01 UTC
[2507.02546] MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp DetailsAbstract page for arXiv paper 2507.02546: MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details![]() https://arxiv.org/abs/2507.02546
https://arxiv.org/abs/2507.02546
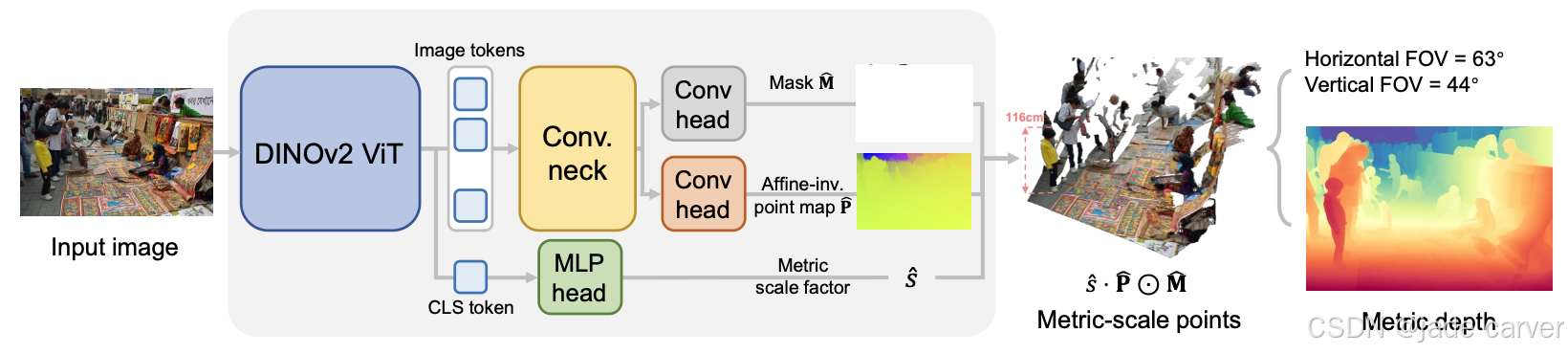
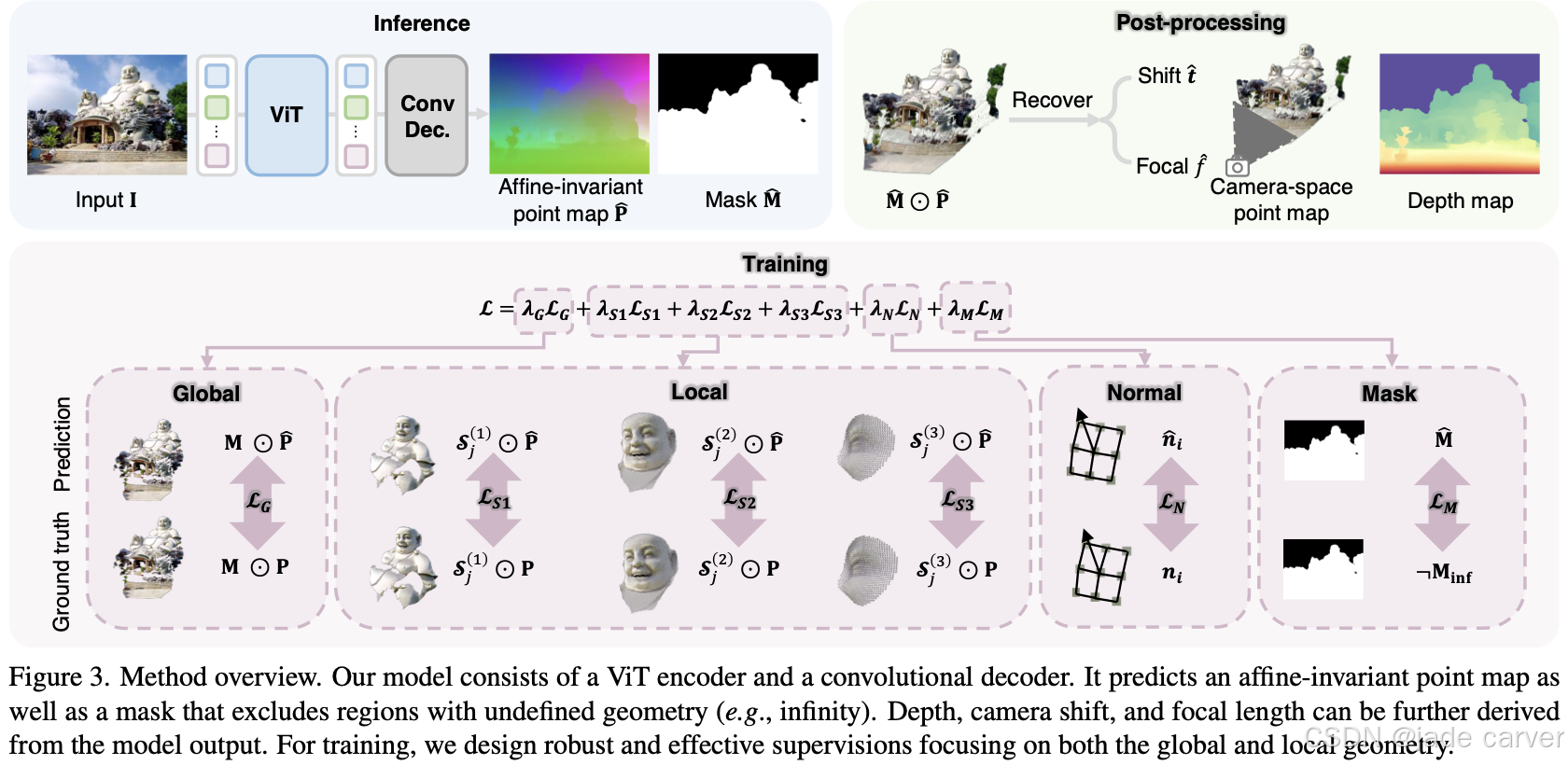
基于将度量多视角几何估计(MGE)分解为仿射不变点图预测[61]和全局尺度恢复这一关键洞见,我们的网络设计在MoGe[61]基础上扩展了一个度量尺度预测头。该设计既保留了仿射不变表示在精确相对几何关系上的优势,又能实现(度量尺度恢复)。
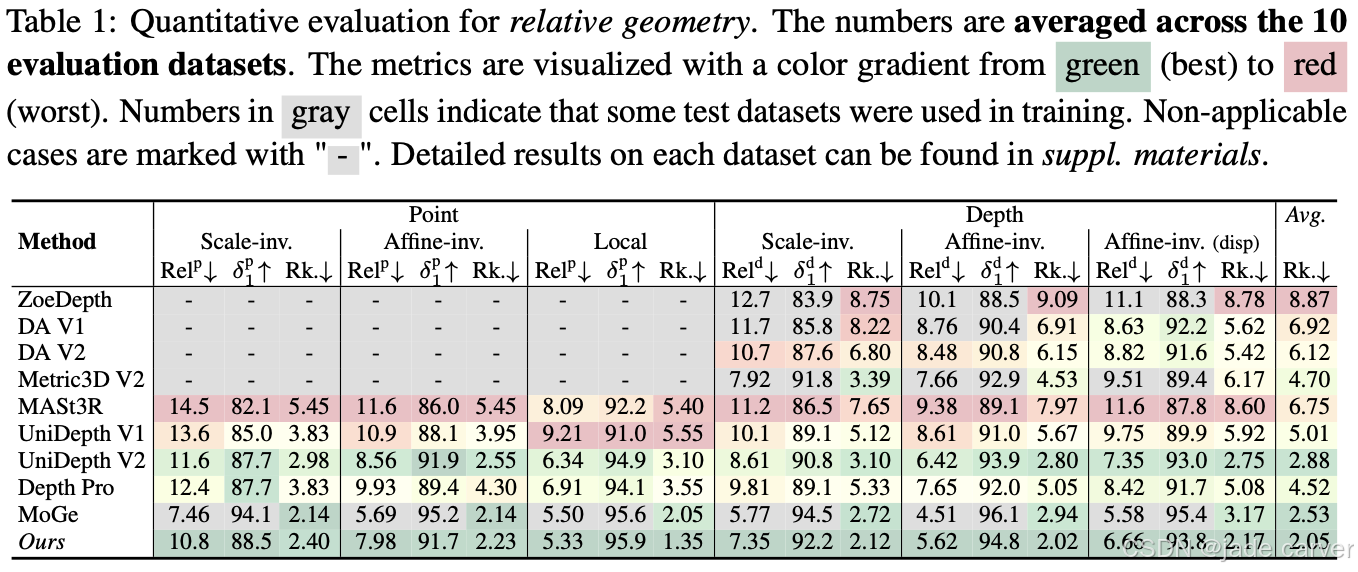
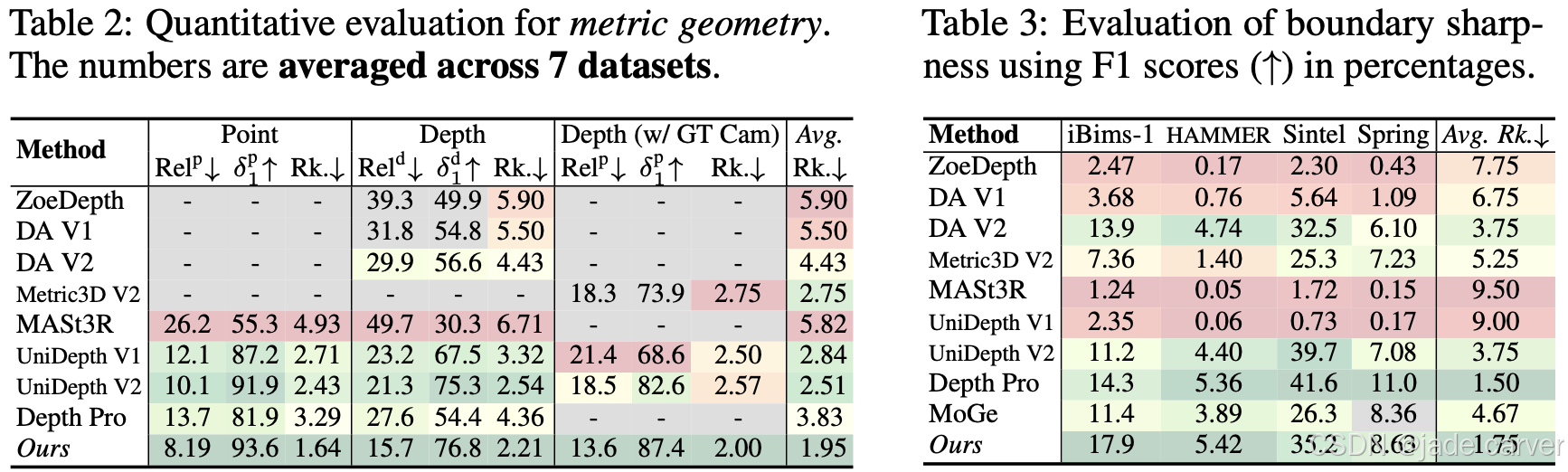

度量尺度点云与视差图的定性对比。前两行选自未见过的度量尺度测试数据集,我们同时在真实值(ground truth)和估计几何结构中标注了关键度量尺寸。我们的度量几何估计结果与真实值最为吻合,并保持了清晰的细节特征。对于开放域输入,本方法能生成细节丰富的合理几何结构,而Depth Pro[7]的结果则存在严重畸变。建议放大查看细节。
六、插件
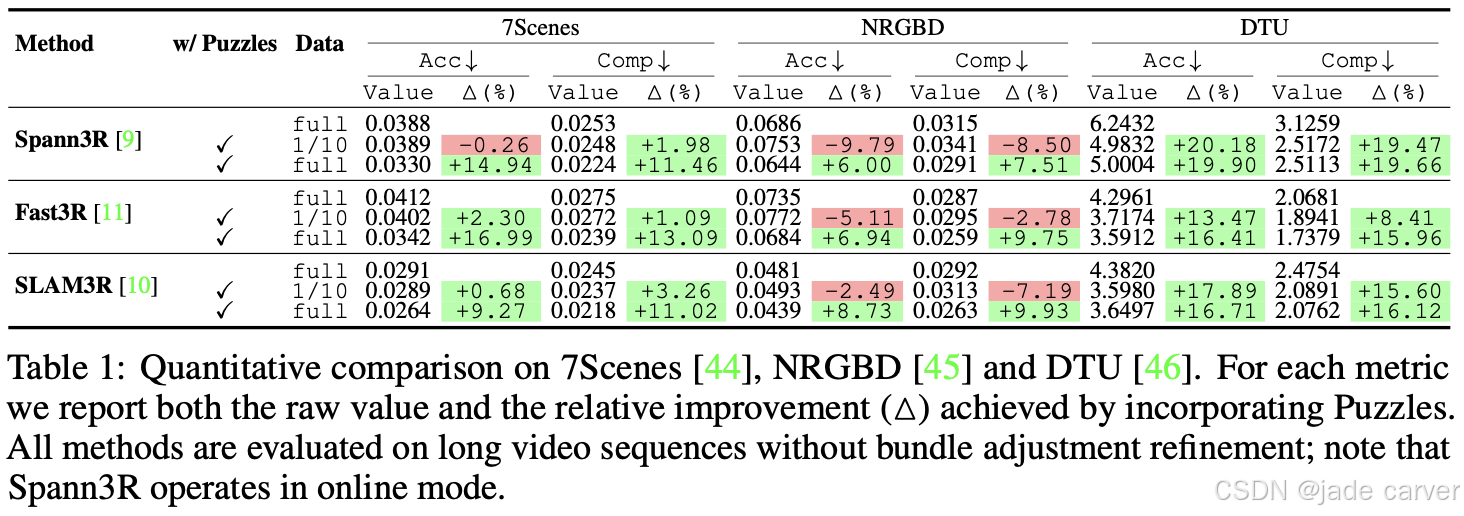
6.1Puzzles: Unbounded Video-Depth Augmentation for Scalable End-to-End 3D Reconstruction(开源)
arxiv:Mon, 30 Jun 2025 13:57:24 UTC
[2506.23863] Puzzles: Unbounded Video-Depth Augmentation for Scalable End-to-End 3D ReconstructionAbstract page for arXiv paper 2506.23863: Puzzles: Unbounded Video-Depth Augmentation for Scalable End-to-End 3D Reconstruction![]() https://arxiv.org/abs/2506.23863
https://arxiv.org/abs/2506.23863
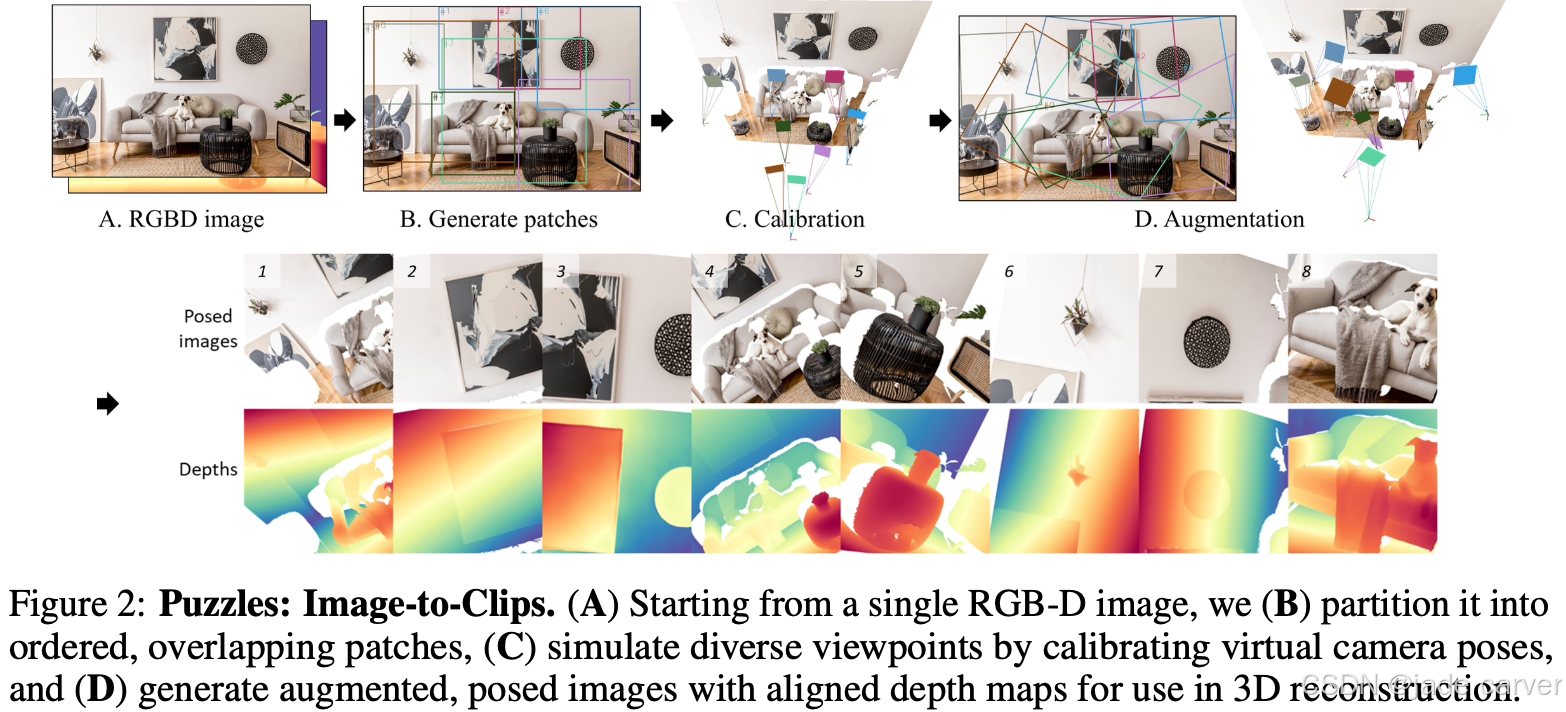


一个box算出来一个pose。
给定单张输入图像(各区块左侧),本文提出的单帧转片段方法通过以下流程生成视角一致的视频片段:有序重叠区块采样(彩色方框标注),模拟6自由度相机轨迹分配(视锥体表示)。
该方法在人体插图、室内场景和户外景观等多种数据上均能实现从单帧生成多样化且逼真的训练序列。
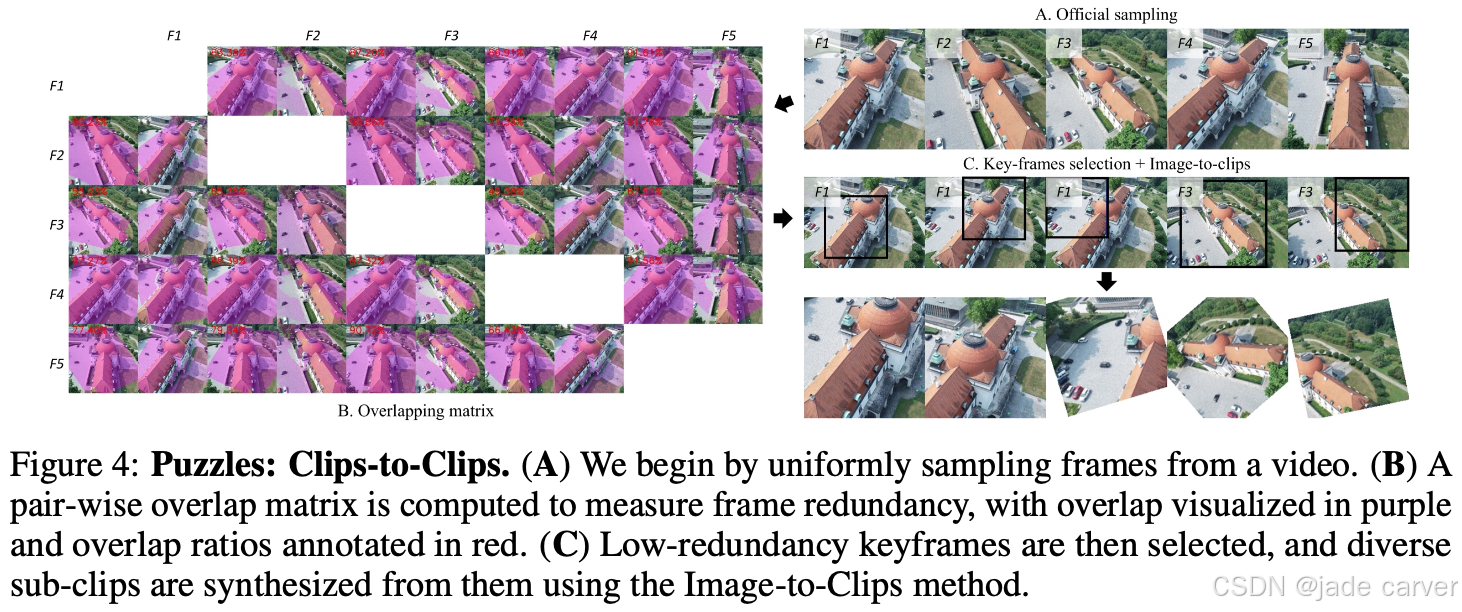
(A) 首先从视频中均匀采样帧序列;(B) 计算帧间重叠矩阵以量化冗余度(重叠区域以紫色标注,重叠率以红色数值标注);(C) 基于低冗余度筛选关键帧后,采用单帧转片段方法生成多样化子片段。
7.表面与mesh
7.1Surf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds(未开源)
arxiv:Wed, 6 Aug 2025 14:53:42 UTC
https://arxiv.org/pdf/2508.04508![]() https://arxiv.org/pdf/2508.04508
https://arxiv.org/pdf/2508.04508
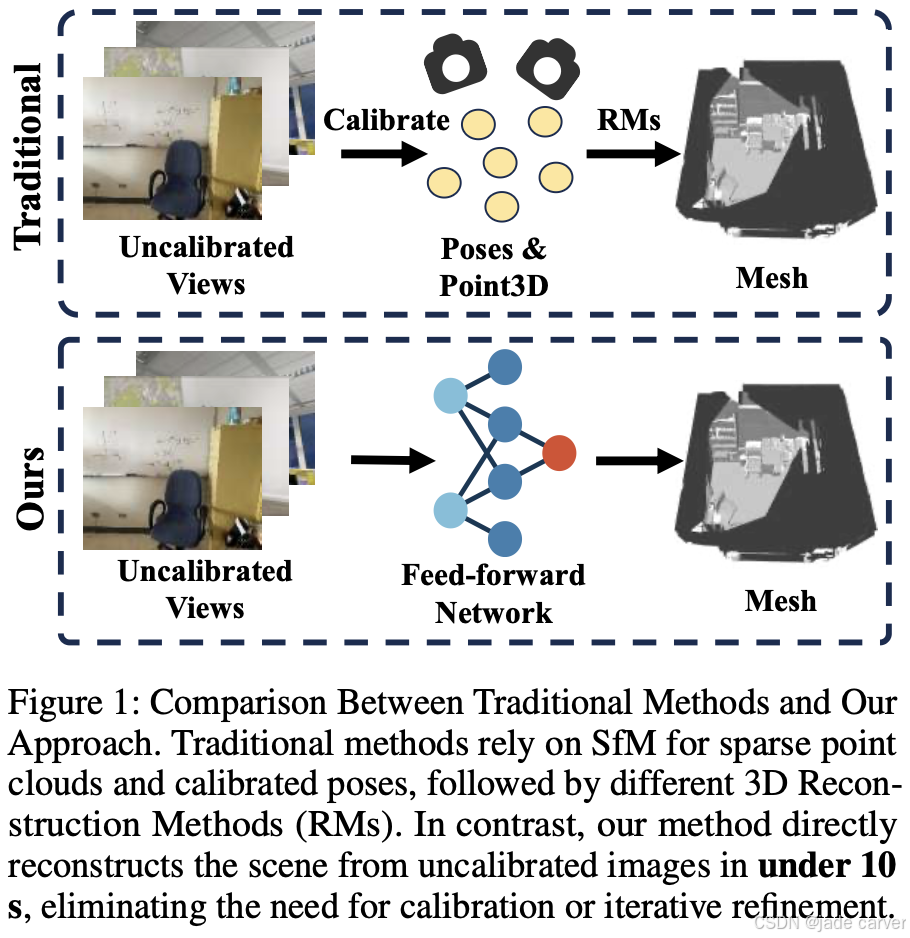
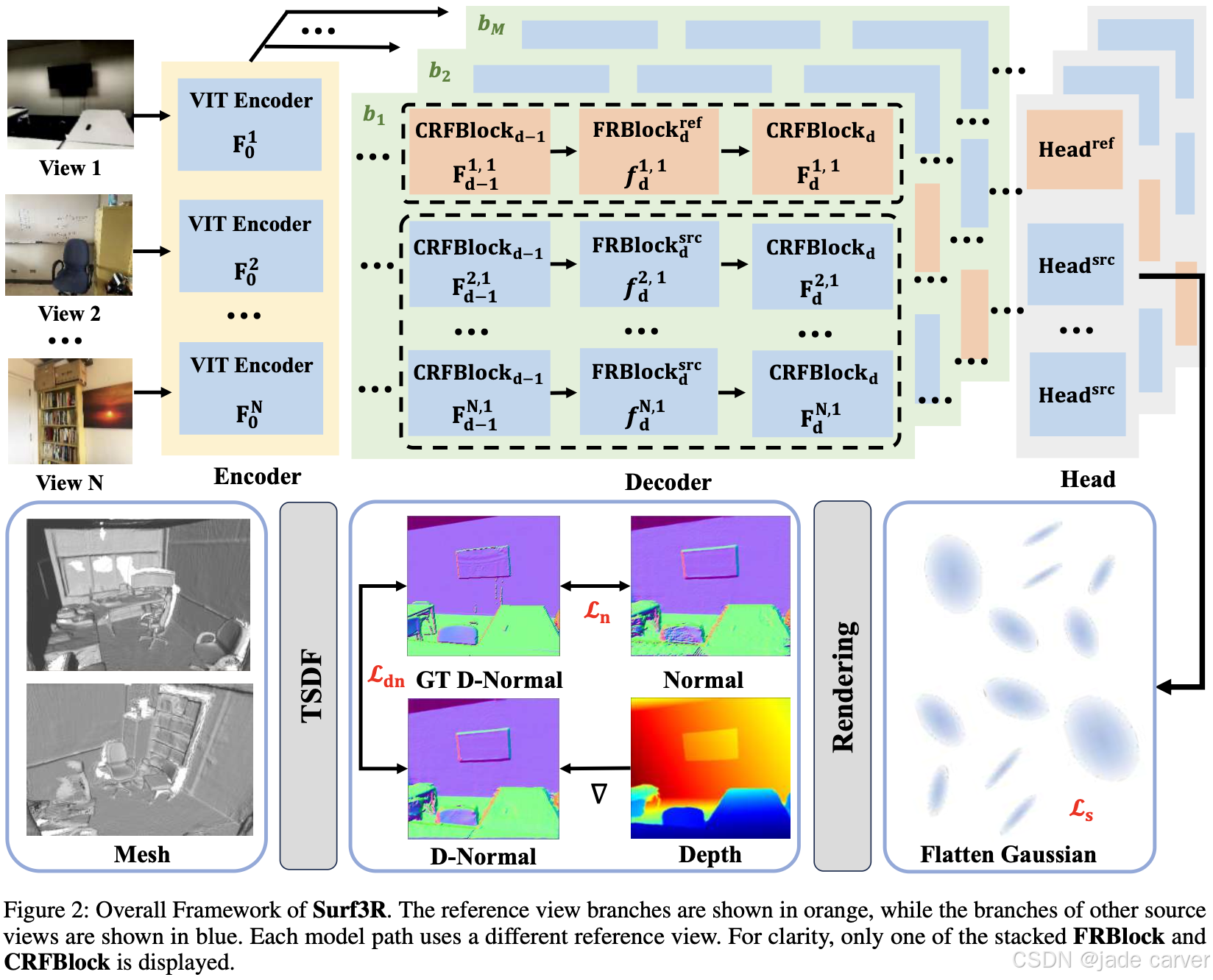
我们提出Surf3R——一种端到端前馈式方法,可在无需相机位姿估计的条件下从稀疏视图重建三维表面,并在10秒内完成全场景重建。该方法采用多分支多视图解码架构,通过多参考视图联合指导重建过程:借助分支级处理、跨视图注意力与分支间融合机制,模型能有效捕捉互补几何线索,且完全规避相机标定需求。
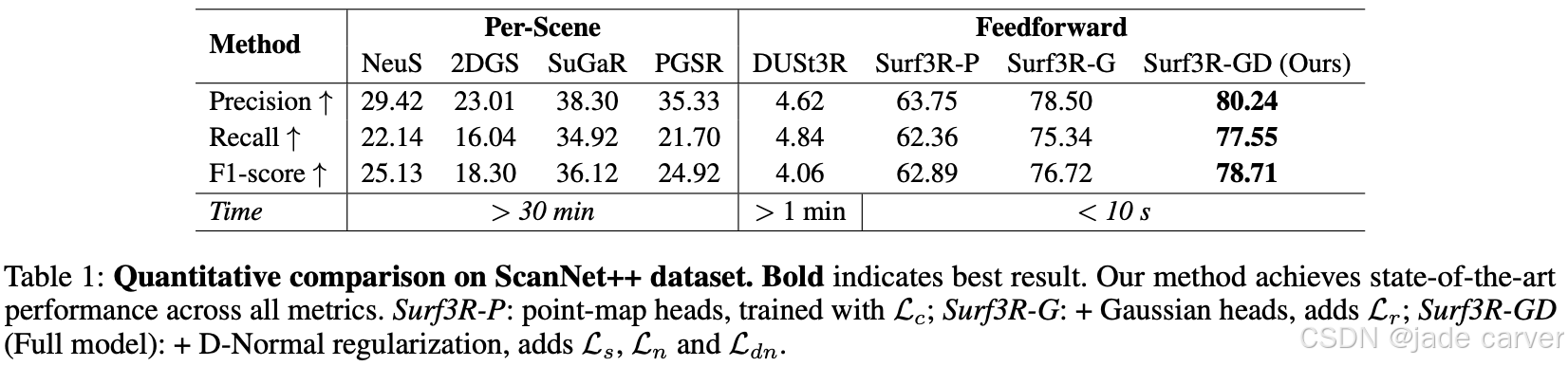
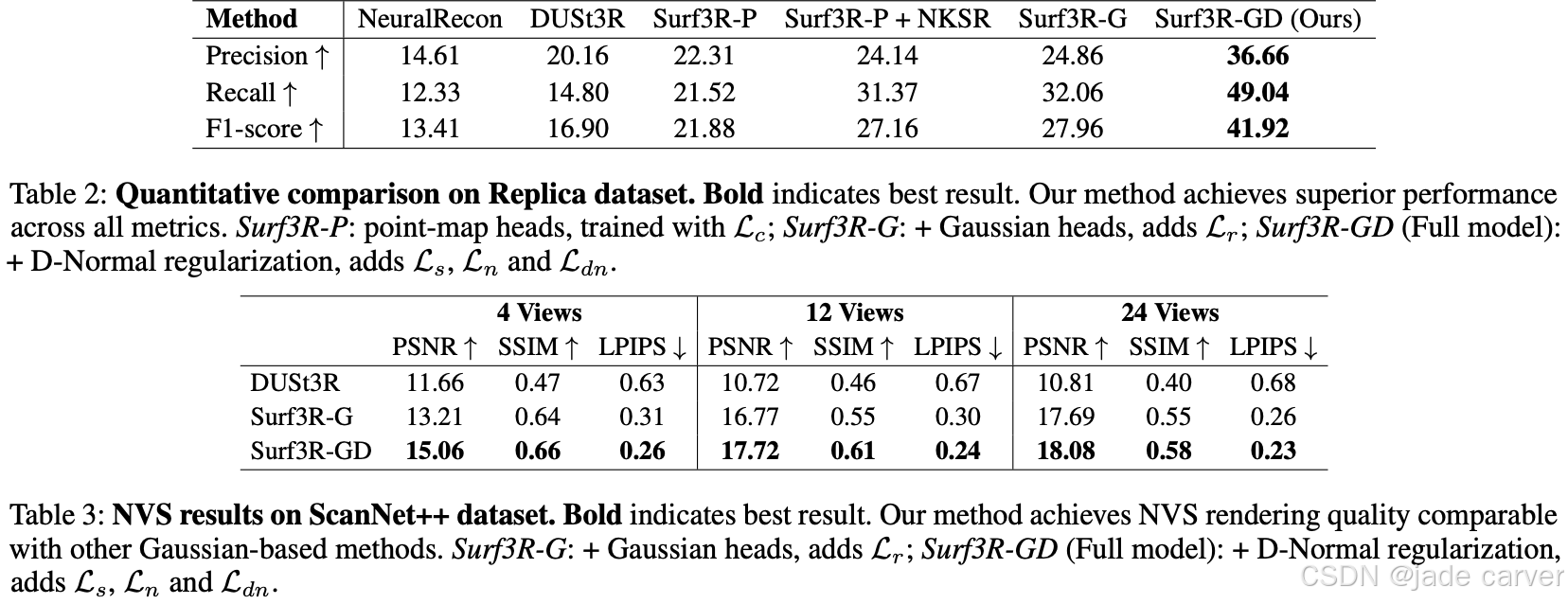
此外,我们基于显式三维高斯表示提出D-Normal正则器,通过将表面法线与其他几何参数耦合进行联合优化,显著提升三维一致性与表面细节精度。实验结果表明,Surf3R在ScanNet++和Replica数据集上多项表面重建指标达到最优性能,同时展现出卓越的泛化能力与效率优势。