机器学习内容总结
一、机器学习的定义
机器学习是通过处理特定任务,以大量经验数据为基础,依据一定的评判标准,分析数据并不断优化任务完成效果的过程。其核心逻辑是从经验中归纳规律,再运用规律对新问题进行预测,具体表现为利用历史数据训练模型,使模型能对未知的新数据做出预测。
二、机器学习的应用领域
机器学习的应用十分广泛,主要包括模式识别、计算机视觉、数据挖掘、语音识别、统计学习、自然语言处理等。例如 Google Translate(谷歌翻译)就是自然语言处理领域应用机器学习的典型代表,它通过对大量双语数据的学习,实现了不同语言之间的翻译。
三、机器学习基本术语
- 数据集:数据记录的集合称为一个 “数据集”(data set)。
- 样本:数据集中每条记录是关于一个事件或对象的描述,称为 “样本”。
- 特征(属性):反映事件或对象在某方面的表现或性质的事项,例如 “色泽”。如下表所示,“色泽”“根蒂”“敲声” 均为特征:
| 编号 | 色泽 | 根蒂 | 敲声 |
|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 |
| 2 | 乌黑 | 蜷缩 | 沉闷 |
| 3 | 乌黑 | 蜷缩 | 浊响 |
| 4 | 青绿 | 蜷缩 | 沉闷 |
4.属性空间:属性张成的空间称为 “属性空间” 或 “样本空间”。
5.向量表示:一般地,令D={x1,x2,...,xm}表示包含m个示例的数据集,每个样本由d个属性描述,则每个样本xi=(xi1,xi2,...,xid)是d维样本空间X中的一个向量,d称为样本xi的 “维数”。训练集:机器学习中用于训练模型的数据集合,包含标记信息。如下表中 “好瓜” 一列即为标记信息:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
6.测试集:机器学习中用于测试模型的数据集合,如下表中 “好瓜” 结果未知,用于测试模型:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.36 | 0.37 | ? |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | ? |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | ? |
四、机器学习的主要类型
- 监督学习:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,其数据集由 “正确答案”(标记)组成。监督学习又可分为分类和回归:
- 分类:机器学习模型输出的结果被限定为有限的一组值,即离散型数值。例如判断西瓜是否为好瓜,结果只有 “是” 或 “否”。
- 回归:机器学习模型的输出可以是某个范围内的任何数值,即连续型数值。例如预测房屋价格,价格可以是某个区间内的任意数值。
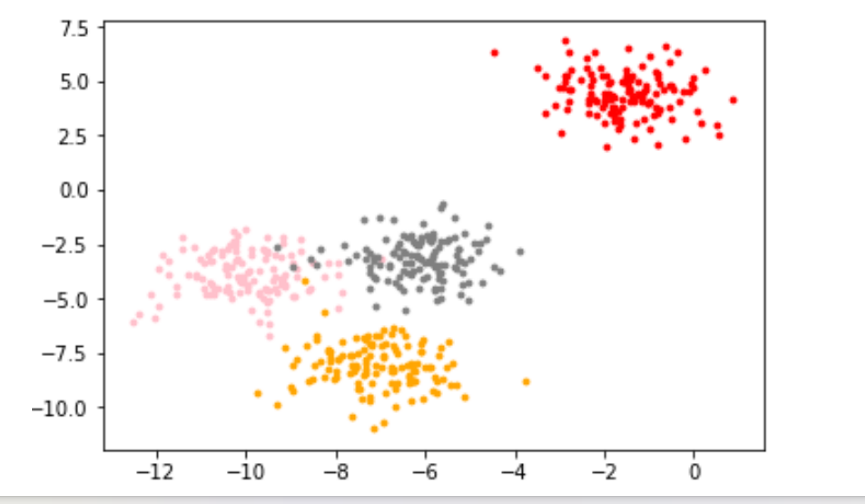
- 无监督学习:提供数据集合但是不提供标记信息的学习过程。其中 “聚类” 是无监督学习的重要算法,例如将样本分成若干类。无监督学习在实际中有很多应用,比如向购买尿布的人推荐葡萄酒,就是基于对交易数据的无监督分析,发现两者之间的关联。
| 交易号码 | 商品 |
|---|---|
| 0 | 豆奶,莴苣 |
| 1 | 莴苣,尿布,葡萄酒,甜菜 |
| 2 | 莴苣,尿布,葡萄酒,橙汁 |
| 3 | 莴苣,豆奶,尿布,葡萄酒 |
| 4 | 莴苣,豆奶,尿布,橙汁 |
“聚类”样本分成四类
3.集成学习:通过构建并结合多个学习器来完成学习任务,以提高学习性能。

五、模型评估与选择
- 评估指标
- 错误率:分类错误的样本数占样本总数的比例。
- 精度:1 减去错误率。
- 残差:学习器的实际预测输出与样本的真实输出之间的差异。
- 训练误差(经验误差):学习器在训练集上的误差。
- 泛化误差:学习器在新样本上的误差。
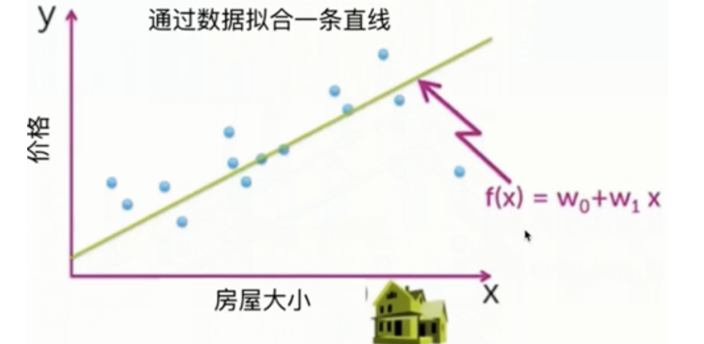
- 损失函数:用来衡量模型预测误差大小的函数,损失函数越小,模型越好。例如通过数据拟合直线来预测房屋价格,损失函数可衡量预测价格与实际价格的偏差。
- 模型常见问题
- 欠拟合:模型没有很好地捕捉到数据特征、特征集过小导致模型不能很好地拟合数据,本质上是对数据特征学习不够。
- 过拟合:把训练数据学习得太彻底,以至于把噪声数据的特征也学习到了,特征集过大,导致在后期测试时不能够很好地识别数据,模型泛化能力太差。
- 模型问题的处理方式
- 过拟合的处理方式:增加训练数据;降维,丢弃一些不能帮助正确预测的特征;采用正则化技术,保留所有特征但减少参数大小;使用集成学习方法,降低单一模型的过拟合风险。
- 欠拟合的处理方式:添加新特征,当特征不足或现有特征与样本标签相关性不强时使用;增加模型复杂度,简单模型学习能力较差,增加复杂度可增强拟合能力;减小正则化系数,正则化用于防止过拟合,模型欠拟合时需针对性减小。
- 选择模型的基本原则
- 奥卡姆剃刀原理:“如无必要,勿增实体”,即 “简单有效原理”。在所有可能选择的模型中,应选择能很好解释已知数据且十分简单的模型,不应一味追求更小的训练误差而使模型复杂化。
- 没有免费的午餐(No Free Lunch,NFL):对于基于迭代的最优化算法,不存在对所有问题都有效的算法。如果一个算法对某些问题有效,那么它在另外一些问题上可能比纯随机搜索算法更差。脱离实际意义谈论算法优劣毫无意义,必须针对具体学习问题。
- 模型评估方法
- 留出法:直接将数据集D划分为两个互斥的部分,一部分作为训练集S,另一部分用作测试集T。通常训练集和测试集的比例为 70%、30%。划分时需注意:尽可能保持数据分布的一致性,在分类任务中可采用 “分层采样”;采用若干次随机划分避免单次使用留出法的不稳定性。
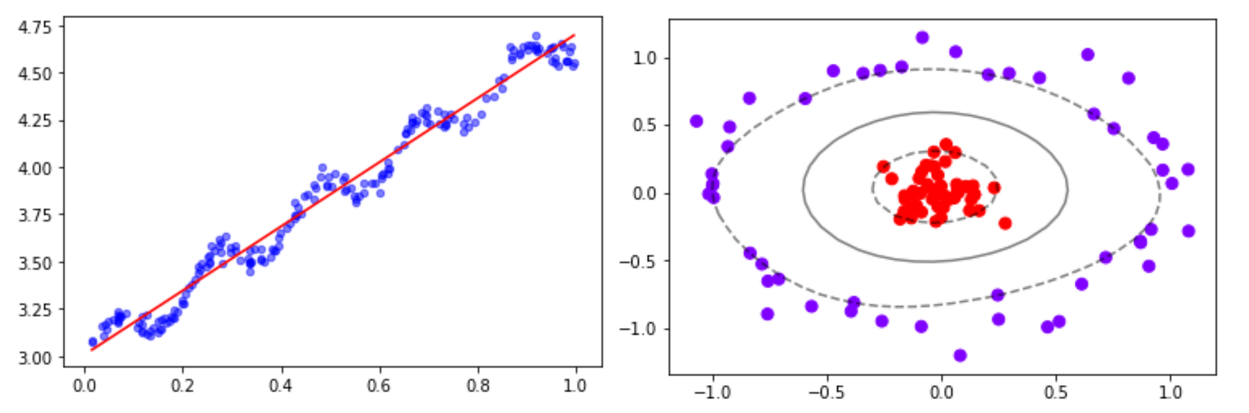
• 左图(带拟合线的散点图):常用来体现模型对数据的拟合趋势。若点大致沿直线分布,说明模型能较好捕捉特征与标签(如“好瓜”)间线性关系;偏离多则可能拟合不佳(欠拟合/过拟合等情况需结合更多指标判断 ),辅助判断模型对数据规律的学习程度。• 右图(带环形分布的散点图):可展示数据集样本分布情况,比如中心红色点密集、外围紫色点分散,能反映数据内在聚类、分布特征,帮助判断模型是否适配数据分布(如复杂分布需更灵活模型 ),也可辅助分析过拟合(若模型过度学习局部密集点噪声 )。
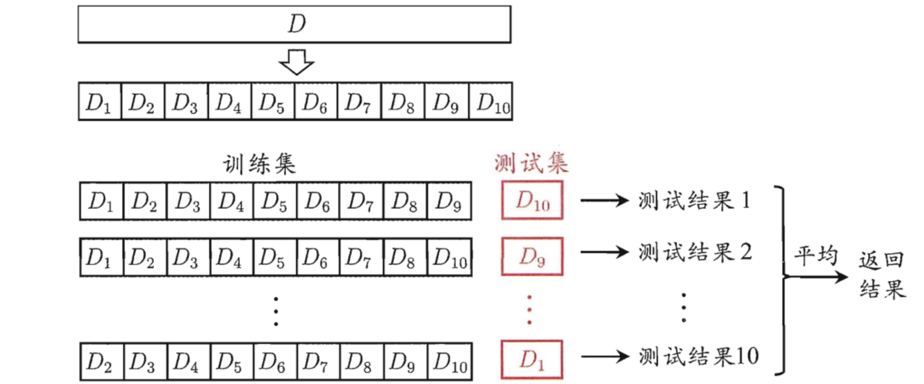
- 交叉验证法:先将数据集D划分为k个大小相似的互斥子集,每次采用k−1个子集的并集作为训练集,剩下的那个子集作为测试集。进行k次训练和测试,最终返回k个测试结果的均值,又称为 “k折交叉验证”。
- 留出法:直接将数据集D划分为两个互斥的部分,一部分作为训练集S,另一部分用作测试集T。通常训练集和测试集的比例为 70%、30%。划分时需注意:尽可能保持数据分布的一致性,在分类任务中可采用 “分层采样”;采用若干次随机划分避免单次使用留出法的不稳定性。
- 其他评估指标
- TP(True positive,真正例):将正类预测为正类数。
- FP(False positive,假正例):将反类预测为正类数。
- TN(True negative,真反例):将反类预测为反类数。
- FN(False negative,假反例):将正类预测为反类数。
- 查准率(精确率)P:P=TP+FPTP。
- 查全率(召回率)R:R=TP+FNTP。
- 一般来说,查准率P高时,查全率R往往偏低;而查全率R高时,查准率P往往偏低。
- P-R 图:直观地显示出学习器在样本总体上的查全率、查准率。在比较时,若一个学习器的 P-R 曲线被另一个学习器的曲线完全 “包住”,则后者的性能优于前者;若曲线交叉,则难以一般性地断言两者孰优孰劣。
通过对今天内容的学习,我对机器学习有了较为全面的认识,从基本概念到模型评估与选择,每个部分都相互关联,共同构成了机器学习的基础框架。。