Torch -- 卷积学习day2 -- 卷积扩展、数据集、模型
目录
一、卷积扩展
1、反卷积
2、膨胀卷积
3、可分离卷积
1.空间可分离卷积
2.深度可分离卷积
4、扁平卷积
5、分组卷积
二、数据获取方法
1、开源数据集
2、外包平台
3、自己采集和表注
4. 通过网络爬虫获取
三、模型
1、模型训练
数据增强
好处
方法
2、模型验证
3、测试
一、卷积扩展
1、反卷积
卷积是对输入图像及进行特征提取,这样会导致尺寸会越变越小,而反卷积是进行相反操作。并不会完全还原到跟输入图一样,只是保证了与输入图像尺寸一致,主要用于向上采样。从数学上看,反卷积相当于是将卷积核转换为稀疏矩阵后进行转置计算。也被称为转置卷积。
如图,在2x2的输入图像上使用【步长1、边界全0填充】的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4
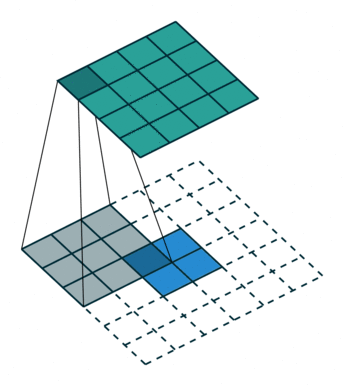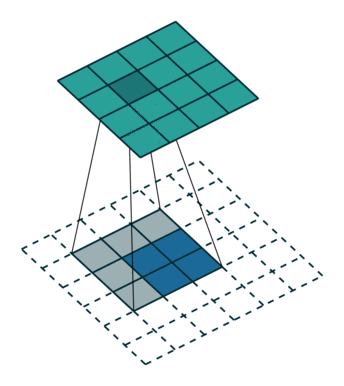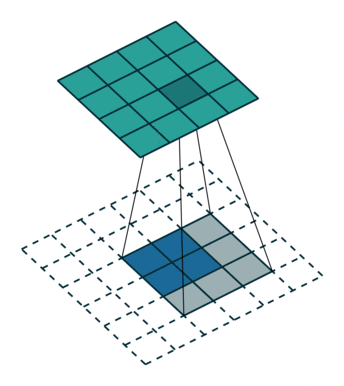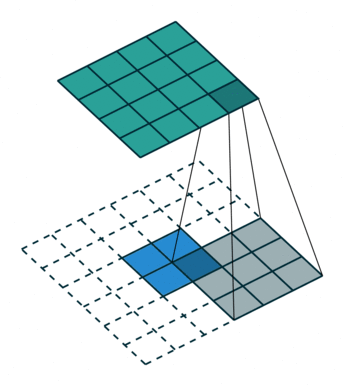
2、膨胀卷积
为扩大感受野,在卷积核的元素之间插入空格“膨胀”内核,形成空洞卷积,并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,内核元素之间没有插入空格,变为标准卷积。图中是L=2的空洞卷积。
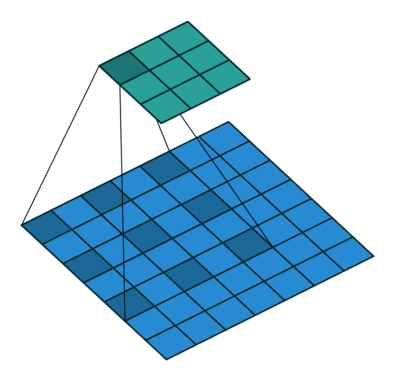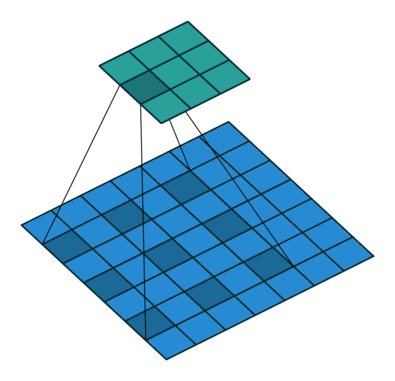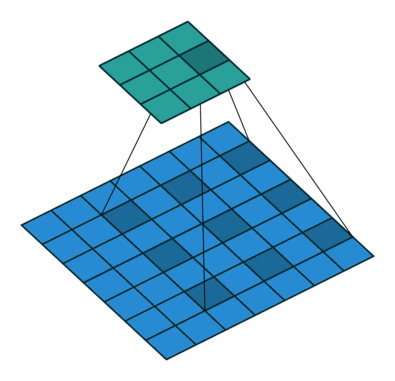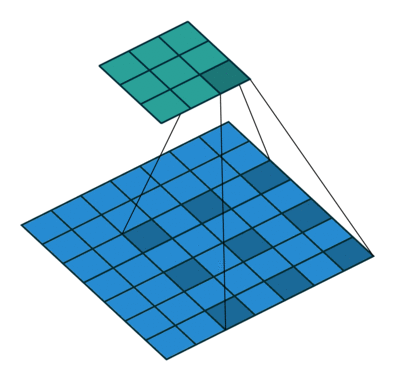
关键API:
dilation=2, #膨胀卷积,在卷积核元素之间插入空洞
示例:
import torch.nn as nn import torch def test01():input = torch.randn(1, 3, 224, 224)conv = nn.Conv2d(in_channels=3,out_channels=128,kernel_size=3,stride=1,dilation=2, #膨胀卷积,在卷积核元素之间插入空洞)out = conv(input)print(out.shape) if __name__ == '__main__':test01()#输出: #torch.Size([1, 128, 220, 220])
3、可分离卷积
(1)大幅降低计算复杂度

(2)减少参数量,防止过拟合

(3)保持/增强模型表达能力
-
解耦空间与通道特征学习:
-
深度卷积:独立处理每个通道的空间特征(如边缘、纹理)
-
逐点卷积:专注通道间的关系组合(如颜色、语义关联)
-
-
实际效果:
-
在轻量级网络(如MobileNet)中,精度损失通常小于5%
-
某些场景下因减少过拟合反而提升泛化能力
-
1.空间可分离卷积
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。在数学中我们可以将矩阵分解:
$$
\left[ \begin{matrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{matrix} \right]= \left[ \begin{matrix} 1 \\ 2 \\ 1 \end{matrix} \right]\times \left[ \begin{matrix} -1 & 0 & 1 \end{matrix} \right]
$$
所以对3x3的卷积核,我们同样可以拆分成 3x1 和 1x3 的两个卷积核,对其进行卷积,且采用可分离卷积的计算量比标准卷积要少。
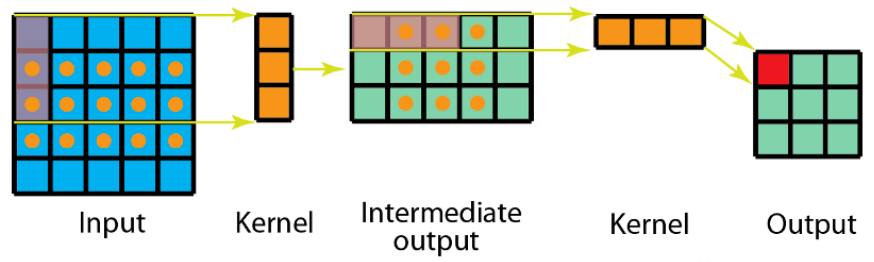
关键API:
kernel_size=(3,1)#垂直卷积 提取垂直方向特征kernel_size=(1,3)#水平卷积 提取水平方向特征
示例:
import torch import torch.nn as nn def test01():input_map = torch.randn(1, 1, 7, 7)conv = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=3,stride=1,)out = conv(input_map)print(out.shape) def test02():input_map = torch.randn(1, 1, 7, 7)conv1 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(3,1), #垂直卷积 提取垂直方向特征stride=1,)out = conv1(input_map)print(out.shape)conv2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(1,3), #水平卷积 提取水平方向特征stride=1,)out = conv2(out)print(out.shape) if __name__ == '__main__':test01()test02()
2.深度可分离卷积
深度可分离卷积由两部组成:深度卷积核1\times1卷积
示例:
import torch import torch.nn as nn def test01():imput_map = torch.randn((1, 8, 7, 7))# 8*8*3*3=576conv = nn.Conv2d(in_channels=8,out_channels=8,kernel_size=3,stride=1,)out = conv(imput_map)print(out.shape) def test02():imput_map = torch.randn((1, 8, 7, 7))# 8*1*3*3=72conv = nn.Conv2d(in_channels=8,out_channels=8,kernel_size=3,stride=1,groups=8, #分组)# 8*8*1*1=64conv1 = nn.Conv2d(in_channels=8,out_channels=8,kernel_size=3,stride=1,)x = conv(imput_map)out = conv1(x)print(out.shape) if __name__ == '__main__':test01()test02()
4、扁平卷积
扁平卷积是将标准卷积拆分成为3个1x1的卷积核,然后再分别对输入层进行卷积计算。
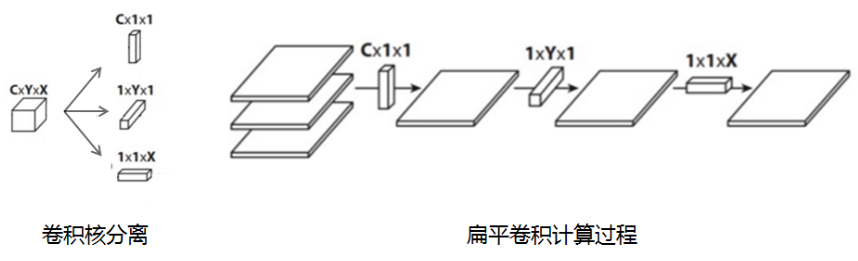
-
标准卷积参数量XYC,计算量为MNCXY
-
拆分卷积参数量(X+Y+C),计算量为MN(C+X+Y)
5、分组卷积
下图中卷积核被分成两个组,前半部负责处理前半部的输入层,后半部负责后半部的输入层,最后将结果组合。
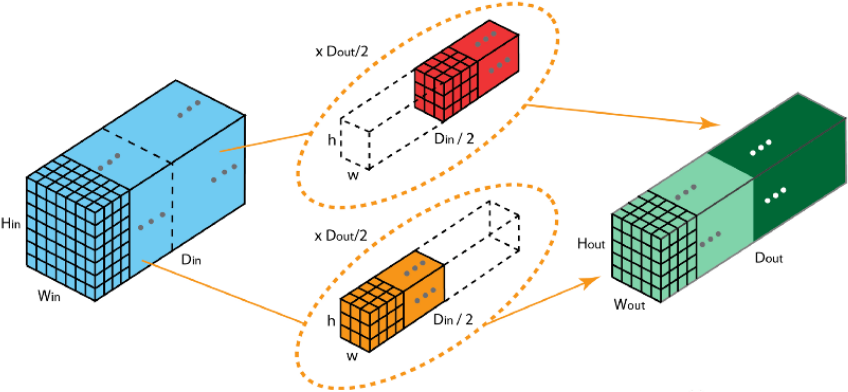
分组卷积中:
-
输入通道被划分为若干组。
-
每组通道只与对应的卷积核计算。
-
不同组之间互相独立,卷积核不共享
示例:
import torch import torch.nn as nn def test01():input_map = torch.randn(1, 128, 32, 32)conv = nn.Conv2d(in_channels=128,out_channels=64,kernel_size=3,stride=1,groups=8 #分组 )out = conv(input_map)name_par=conv.named_parameters()#输出两个参数张量权重参数 (weight)、偏置参数 (bias)for name, param in name_par:print(name, param.shape) if __name__ == '__main__':test01()
二、数据获取方法
-
分类数据:图像分类,一般是以目录的形式分开
-
标注数据:目标检测和图像分割,是有标注数据的
1、开源数据集
免费,成本低
-
PyTorch: Datasets — Torchvision 0.23 documentation
-
kaggle数据集下载网址:Find Open Datasets and Machine Learning Projects | Kaggle
-
Hugging Face数据集:https://huggingface.co/datasets
-
各种网站:
Computer Vision Datasets
https://zhuanlan.zhihu.com/p/648720525
极市开发者平台-计算机视觉算法开发落地平台-极市科技
2、外包平台
效果好,成本高
外包平台(Amazon Mechanical Turk,阿里众包,百度数据众包,京东微工等)
3、自己采集和表注
质量高、效率低、成本高。
labelimg、labelme工具的使用。
pip install labelimg
4. 通过网络爬虫获取
爬虫工具
读取数据集示例:
import torch
import torch.nn as nn
from torchvision.datasets import MNIST,ImageFolder
#读取官方数据集
MNIST_train = MNIST('./data',train=True,download=True)
class_to_index = MNIST_train.class_to_idx
classes = MNIST_train.classes
index_to_class={v:k for k,v in class_to_index.items()}
# 通过字典推导式,将`class_to_index`字典的键值对反转,创建一个新的字典`index_to_class`,它将整数索引映射回类别名称。
print(index_to_class)
print(classes)
print(class_to_index)
print(index_to_class)
print("-"*30)
#读取自定义数据集方式
imagFolder_train = ImageFolder(root='./data/flower/train',transform=None)
print(imagFolder_train.class_to_idx)
三、模型
1、模型训练
-
数据准备阶段
-
定义数据转换(transform):
-
转换为Tensor格式
-
数据标准化(使用MNIST的均值和标准差)
-
调整图像尺寸为32x32
-
-
加载MNIST训练数据集
-
创建DataLoader(批量大小32,打乱数据)
-
-
模型和设备设置
-
检测并使用可用的设备(优先GPU)
-
初始化自定义的NumberModel模型并移至设备
-
-
训练配置
-
设置训练轮次(epochs=10)
-
选择Adam优化器(学习率0.001)
-
使用交叉熵损失函数(求和模式)
-
-
训练循环
-
外层循环遍历每个epoch
-
内层循环遍历每个batch:
-
将数据和标签移至设备
-
前向传播获取模型输出
-
计算预测结果(argmax)
-
计算准确率(累计正确预测数)
-
计算损失值
-
梯度清零
-
反向传播
-
优化器更新参数
-
-
每个epoch结束后:
-
保存模型权重
-
记录准确率和损失到TensorBoard
-
打印当前epoch进度和指标
-
-
-
监控和记录
-
使用TensorBoard的SummaryWriter记录训练准确率
-
控制台打印每个epoch的准确率和损失
-
数据增强
好处
查出更多训练数据:大幅度降低数据采集和标注成本;
提升泛化能力:模型过拟合风险降低,提高模型泛化能力
方法
-
随机旋转

-
镜像

-
缩放
-
图像模糊

-
裁剪

-
翻转
-
饱和度、亮度、灰度、色相

-
噪声、锐化、颜色反转

-
多样本增强
SamplePairing操作:随机选择两张图片分别经过基础数据增强操作处理后,叠加合成一个新的样本,标签为原样本标签中的一种。
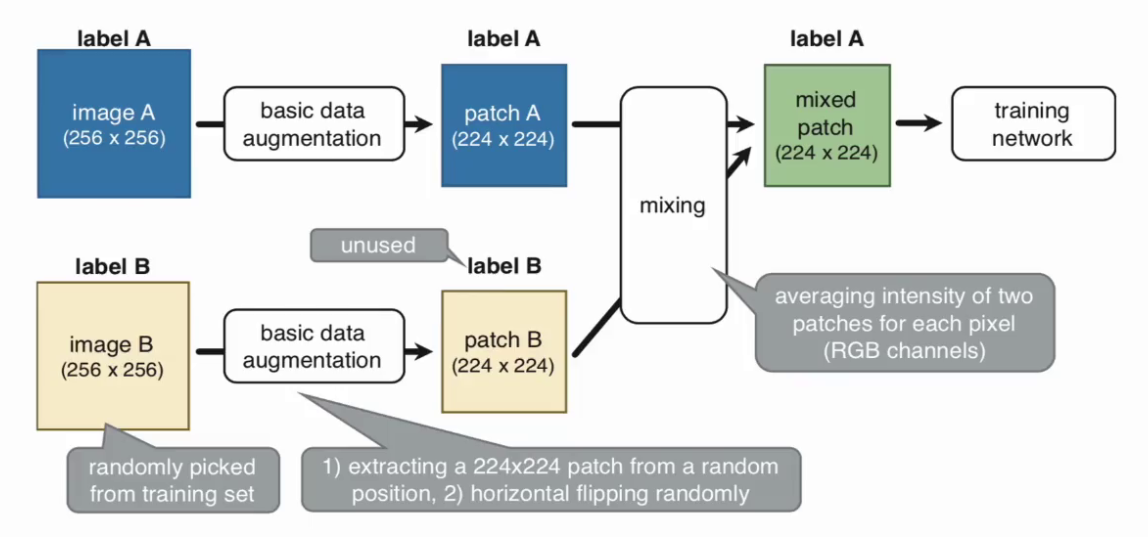
-
①、多样本线性插值:Mixup 标签更平滑

-
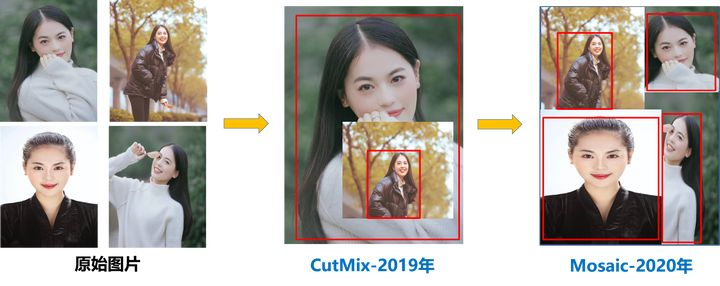
②、直接复制:CutMix, Cutout,直接复制粘贴样本

-
③、Mosic:四张图片合并到一起进行训练
API
transforms.RandomRotation(degrees=15) # 随机旋转±15度 transforms.RandomHorizontalFlip(p=0.5) # 水平翻转概率50% transforms.RandomVerticalFlip(p=0.5) # 垂直翻转 transforms.Resize((32, 32)) # 缩放到32x32 transforms.Lambda(lambda x: x.filter(ImageFilter.GaussianBlur(radius=1))) #图像模糊(需要自定义) transforms.RandomCrop(size=(28, 28), padding=4) # 随机裁剪+边缘填充 transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)
模型训练示例:
import torch.optim as opt
import torch.nn as nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from model import NumberModel
import torch
from torch.utils.tensorboard import SummaryWriter
# tensorboard可视化操作
writer = SummaryWriter()
model_path = "./weight/model.pth"
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),transforms.Resize((32, 32)),# # 随机旋转# transforms.RandomRotation(degrees=15),# # 反转# transforms.RandomHorizontalFlip(p=0.5),# # 裁剪# transforms.RandomCrop(size=(28, 28), padding=4),
])
train_dataset = MNIST(root='./data', train=True, download=False, transform=transform)
data_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NumberModel().to(device)
# 轮次
epochs = 10
# 优化器
optimizer = opt.Adam(model.parameters(), lr=0.001)
# 损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
model.train()
for epoch in range(epochs):acc_total = 0loss_total = 0for batch_idx, (data, target) in enumerate(data_loader):data, target = data.to(device), target.to(device)output = model(data)pre = torch.argmax(output, dim=1)acc_total += torch.sum(pre == target)loss = loss_fn(output, target)loss_total += lossoptimizer.zero_grad()loss.backward()optimizer.step()# 模型的保存torch.save(model.state_dict(), model_path)writer.add_scalar("acc/train", acc_total / len(train_dataset), epoch)print(f"{epoch+1}/{epochs}------>acc:{acc_total / len(train_dataset)}------>losss:{loss_total / len(train_dataset)}")
2、模型验证
-
数据准备阶段
-
定义与训练集相同的数据转换(transform):
-
转换为Tensor格式
-
使用相同的标准化参数(均值0.1307,标准差0.3081)
-
调整图像尺寸为32x32(与训练时一致)
-
-
加载MNIST测试数据集(train=False)
-
创建验证DataLoader(批量大小32,不打乱数据)
-
-
模型加载和设置
-
检测并使用可用的设备(与训练时一致,优先GPU)
-
初始化模型结构(NumberModel)
-
加载训练好的模型权重(model.pth)
-
将模型移至设备
-
设置模型为评估模式(net.eval())
-
-
验证过程
-
使用torch.no_grad()上下文管理器(禁用梯度计算,节省内存)
-
遍历验证集所有batch:
-
将数据和标签移至设备
-
前向传播获取模型输出
-
计算预测结果(argmax)
-
累计正确预测数
-
-
计算并打印整体准确率(正确预测数/验证集总样本数)
-
示例:
import torch
import torch.nn as nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from model import NumberModel
tf = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),transforms.Resize((32, 32)),
])
val_data = MNIST(root='./data',train=False,transform=tf,download=False
)
val_loader = DataLoader(dataset=val_data,batch_size=32,shuffle=False,
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = NumberModel()
# 加载预训练好的权重参数
model_path = "./weight/model.pth"
net.load_state_dict(torch.load(model_path))
net.to(device)
net.eval()
with torch.no_grad():acc_total = 0for idx, (data, target) in enumerate(val_loader):data = data.to(device)target = target.to(device)out = net(data)pre = torch.argmax(out, dim=1)acc_total += torch.sum(pre == target)# print(f'第{idx+1}批次的准确率:{acc_total.item() / len(val_data)}')print(f'总准确率:{acc_total.item() / len(val_data)}')
3、测试
from model import NumberModel
import torch
import cv2 as cv
import numpy as np
model = NumberModel() # 初始化模型结构
model.load_state_dict(torch.load("./weight/model.pth"))# 加载预训练权重
img = cv.imread("./image/0.jpg")
print(img.shape)
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 转为灰度图(单通道)
print(img.shape)
img = cv.resize(img, (32, 32))
print(img.shape)
img = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0)# 增加批次和通道维度
print(img.shape)
out = model(img)# 前向传播,输出预测logits
print(out)
print(out.argmax(dim=1))